
Top 10 Hadoop-Befehle [mit Verwendungen]
Veröffentlicht: 2021-01-29In dieser Zeit mit riesigen Datenmengen wird es unerlässlich, mit ihnen umzugehen. Die Daten, die von Organisationen mit wachsenden Kunden stammen, sind viel größer, als jedes herkömmliche Datenverwaltungstool speichern kann. Es stellt sich die Frage nach der Verwaltung größerer Datensätze, die von Gigabyte bis Petabyte reichen können, ohne einen einzigen großen Computer oder ein herkömmliches Datenverwaltungstool zu verwenden.
Hier steht das Apache Hadoop-Framework im Rampenlicht. Bevor wir in die Hadoop-Befehlsimplementierung eintauchen, lassen Sie uns kurz das Hadoop-Framework und seine Bedeutung verstehen.
Inhaltsverzeichnis
Was ist Hadoop?
Hadoop wird häufig von großen Unternehmensorganisationen verwendet, um verschiedene Probleme zu lösen, von der täglichen Speicherung großer GB (Gigabyte) an Daten bis hin zu Rechenoperationen mit den Daten.
Traditionell als Open-Source-Software-Framework definiert, das zum Speichern von Daten und Verarbeiten von Anwendungen verwendet wird, hebt sich Hadoop ziemlich stark von den meisten herkömmlichen Datenverwaltungstools ab. Es verbessert die Rechenleistung und erweitert die Datenspeichergrenze, indem es einige Knoten im Framework hinzufügt, wodurch es hochgradig skalierbar wird. Außerdem sind Ihre Daten und Anwendungsprozesse vor diversen Hardwareausfällen geschützt.
Hadoop folgt einer Master-Slave-Architektur, um Daten mit MapReduce und HDFS zu verteilen und zu speichern. Wie in der folgenden Abbildung dargestellt, ist die Architektur auf eine definierte Weise zugeschnitten, um Datenverwaltungsoperationen unter Verwendung von vier primären Knoten auszuführen, nämlich Name, Daten, Master und Slave. Die Kernkomponenten von Hadoop bauen direkt auf dem Framework auf. Andere Komponenten lassen sich direkt in die Segmente integrieren.
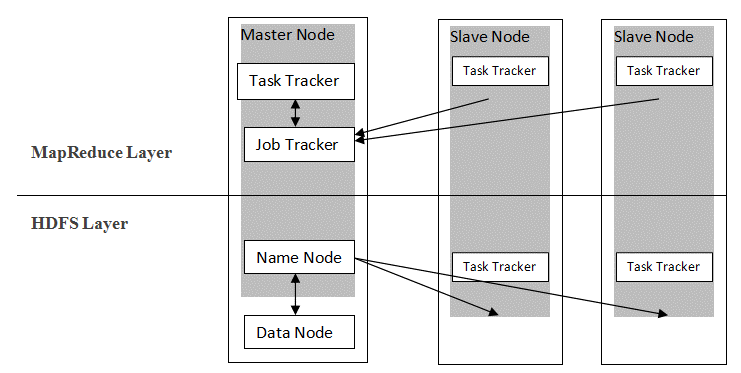 Quelle
Quelle

Hadoop-Befehle
Die wichtigsten Funktionen des Hadoop-Frameworks weisen eine kohärente Natur auf und es wird benutzerfreundlicher, wenn es um die Verwaltung großer Datenmengen durch das Erlernen von Hadoop-Befehlen geht. Im Folgenden finden Sie einige praktische Hadoop-Befehle, mit denen Sie verschiedene Vorgänge ausführen können, z. B. die Verwaltung und Dateiverarbeitung von HDFS-Clustern. Diese Befehlsliste ist häufig erforderlich, um bestimmte Prozessergebnisse zu erzielen.
1. Hadoop-Touchz
hadoop fs -touchz /Verzeichnis/Dateiname
Mit diesem Befehl kann der Benutzer eine neue Datei im HDFS-Cluster erstellen. Das „Verzeichnis“ im Befehl bezieht sich auf den Verzeichnisnamen, in dem der Benutzer die neue Datei erstellen möchte, und der „Dateiname“ bezeichnet den Namen der neuen Datei, die nach Abschluss des Befehls erstellt wird.
2. Hadoop-Testbefehl
hadoop fs -test -[defsz] <Pfad>
Dieser spezielle Befehl erfüllt den Zweck, die Existenz einer Datei im HDFS-Cluster zu testen. Die Zeichen ab „[defsz]“ im Befehl müssen nach Bedarf angepasst werden. Hier ist eine kurze Beschreibung dieser Charaktere:
- d -> Prüft, ob es sich um ein Verzeichnis handelt oder nicht
- e -> Prüft ob es ein Pfad ist oder nicht
- f -> Prüft, ob es sich um eine Datei handelt oder nicht
- s -> Prüft, ob es sich um einen leeren Pfad handelt oder nicht
- r -> Prüft Pfadexistenz und Leseberechtigung
- w -> Prüft Pfadexistenz und Schreibrechte
- z -> Prüft die Dateigröße
3. Hadoop-Textbefehl
hadoop fs -text <src>
Der Textbefehl ist besonders nützlich, um die zugewiesene Zip-Datei im Textformat anzuzeigen. Es verarbeitet Quelldateien und stellt seinen Inhalt in einem einfachen decodierten Textformat bereit.
4. Hadoop-Suchbefehl
hadoop fs -find <Pfad> … <Ausdruck>

Dieser Befehl wird im Allgemeinen verwendet, um nach Dateien im HDFS-Cluster zu suchen. Es scannt den angegebenen Ausdruck im Befehl mit allen Dateien im Cluster und zeigt die Dateien an, die mit dem definierten Ausdruck übereinstimmen.
Lesen Sie: Top Hadoop-Tools
5. Hadoop Getmerge-Befehl
hadoop fs -getmerge <src> <localdest>
Der Getmerge-Befehl ermöglicht das Zusammenführen einer oder mehrerer Dateien in einem bestimmten Verzeichnis auf dem HDFS-Dateisystem-Cluster. Es sammelt die Dateien in einer einzigen Datei, die sich im lokalen Dateisystem befindet. „src“ und „localdest“ stehen für die Bedeutung von Quelle-Ziel und lokalem Ziel.
6. Hadoop-Zählbefehl
hadoop fs -count [Optionen] <Pfad>
So offensichtlich wie sein Name, zählt der Hadoop-Befehl count die Anzahl der Dateien und Bytes in einem bestimmten Verzeichnis. Es stehen verschiedene Optionen zur Verfügung, die die Ausgabe gemäß den Anforderungen modifizieren. Diese sind wie folgt:
- q -> Kontingent zeigt das Limit für die Gesamtzahl der Namen und die Nutzung des Speicherplatzes
- u -> zeigt nur Kontingent und Nutzung an
- h -> gibt die Größe einer Datei an
- v -> Zeigt den Header an
7. Hadoop-AppendToFile-Befehl
hadoop fs -appendToFile <localsrc> <dest>
Es ermöglicht dem Benutzer, den Inhalt einer oder mehrerer Dateien in einer einzigen Datei an die angegebene Zieldatei im HDFS-Dateisystem-Cluster anzuhängen. Bei Ausführung dieses Befehls werden die angegebenen Quelldateien gemäß dem im Befehl angegebenen Dateinamen an die Zielquelle angehängt.
8. Hadoop-ls-Befehl
hadoop fs -ls /Pfad
Der Befehl ls in Hadoop zeigt die Liste der Dateien/Inhalte in einem bestimmten Verzeichnis, dh Pfad. Wenn Sie „R“ vor /Pfad hinzufügen, zeigt die Ausgabe Details des Inhalts wie Namen, Größe, Besitzer usw. für jede Datei, die im angegebenen Verzeichnis angegeben ist.
9. Hadoop-mkdir-Befehl
hadoop fs -mkdir /Pfad/Verzeichnisname
Die einzigartige Funktion dieses Befehls ist die Erstellung eines Verzeichnisses im HDFS-Dateisystem-Cluster, wenn das Verzeichnis nicht existiert. Wenn das angegebene Verzeichnis vorhanden ist, zeigt die Ausgabenachricht außerdem einen Fehler an, der auf die Existenz des Verzeichnisses hinweist.
10. Hadoop-chmod-Befehl
hadoop fs -chmod [-R] <Modus> <Pfad>
Dieser Befehl wird verwendet, wenn die Berechtigungen für den Zugriff auf eine bestimmte Datei geändert werden müssen. Bei Eingabe des chmod-Befehls wird die Berechtigung der angegebenen Datei geändert. Beachten Sie jedoch, dass die Berechtigung geändert wird, wenn der Dateieigentümer diesen Befehl ausführt.
Lesen Sie auch: Impala Hadoop-Tutorial
Fazit
Beginnend mit dem wichtigen Problem der Datenspeicherung, mit dem die großen Organisationen in der heutigen Welt konfrontiert sind, erörterte dieser Artikel die Lösung für die begrenzte Datenspeicherung durch die Einführung von Hadoop und ihre Auswirkungen auf die Durchführung von Datenverwaltungsvorgängen mithilfe von Hadoop-Befehlen. Für Einsteiger in Hadoop wird ein Überblick über das Framework mit seinen Komponenten und seiner Architektur beschrieben.

Nach der Lektüre dieses Artikels kann man sich leicht auf sein Wissen in Bezug auf das Hadoop-Framework und seine angewandten Befehle verlassen. Die exklusive PG-Zertifizierung von upGrad in Big Data: upGrad bietet ein branchenspezifisches 7,5-monatiges Programm für die PG-Zertifizierung in Big Data, in dem Sie Big Data mit IIIT-Bangalore organisieren, analysieren und interpretieren.
Es wurde sorgfältig für Berufstätige entwickelt und hilft den Studenten, praktisches Wissen zu erwerben und ihren Einstieg in Big Data-Rollen zu fördern.
Programm-Highlights:
- Erlernen relevanter Sprachen und Tools
- Erlernen fortgeschrittener Konzepte der verteilten Programmierung, Big-Data-Plattformen, Datenbanken, Algorithmen und Web-Mining
- Ein akkreditiertes Zertifikat des IIIT Bangalore
- Unterstützung bei der Platzierung, um in Top-MNCs aufgenommen zu werden
- 1:1-Mentoring, um Ihre Fortschritte zu verfolgen und Sie an jedem Punkt zu unterstützen
- Arbeiten an Live-Projekten und Aufgaben
Eignung : Hintergrund in Mathematik/Softwaretechnik/Statistik/Analytik
Sehen Sie sich unsere anderen Softwareentwicklungskurse bei upGrad an.