
Eine GraphQL-Einführung: Die Evolution des API-Designs (Teil 2)
Veröffentlicht: 2022-03-10In Teil 1 haben wir uns angesehen, wie sich APIs in den letzten Jahrzehnten entwickelt haben und wie jede einzelne der nächsten Platz gemacht hat. Wir haben auch über einige der besonderen Nachteile der Verwendung von REST für die Entwicklung mobiler Clients gesprochen. In diesem Artikel möchte ich untersuchen, wohin das API-Design für mobile Clients zu gehen scheint – mit besonderem Schwerpunkt auf GraphQL.
Es gibt natürlich viele Leute, Unternehmen und Projekte, die versucht haben, die Mängel von REST im Laufe der Jahre zu beheben: HAL, Swagger/OpenAPI, OData JSON API und Dutzende anderer kleinerer oder interner Projekte haben alle versucht, Ordnung in die spezifikationslose Welt von REST. Anstatt die Welt für das zu nehmen, was sie ist, und inkrementelle Verbesserungen vorzuschlagen oder zu versuchen, genügend unterschiedliche Teile zusammenzusetzen, um REST zu dem zu machen, was ich brauche, würde ich gerne ein Gedankenexperiment wagen. Angesichts eines Verständnisses der Techniken, die in der Vergangenheit funktioniert haben und nicht funktionierten, möchte ich die heutigen Einschränkungen und unsere immens ausdrucksstärkeren Sprachen nutzen, um zu versuchen, die API zu skizzieren, die wir wollen. Lassen Sie uns von der Entwicklererfahrung rückwärts arbeiten und nicht von der Implementierung vorwärts (ich betrachte Sie SQL).
Minimaler HTTP-Verkehr
Wir wissen, dass die Kosten für jede (HTTP/1)-Netzwerkanfrage hoch sind, was auf einige Maßnahmen von der Latenz bis zur Akkulaufzeit zurückzuführen ist. Idealerweise benötigen Kunden unserer neuen API eine Möglichkeit, alle Daten, die sie benötigen, in so wenigen Roundtrips wie möglich anzufordern.
Minimale Nutzlasten
Wir wissen auch, dass der durchschnittliche Client in Bezug auf Bandbreite, CPU und Arbeitsspeicher nur eingeschränkte Ressourcen hat. Daher sollte unser Ziel darin bestehen, nur die Informationen zu senden, die unser Client benötigt. Dazu benötigen wir wahrscheinlich eine Möglichkeit, mit der der Client nach bestimmten Daten fragen kann.
Für Menschen lesbar
Wir haben aus den SOAP-Tagen gelernt, dass es nicht einfach ist, mit einer API zu interagieren, die Leute werden bei ihrer Erwähnung das Gesicht verziehen. Entwicklungsteams möchten die gleichen Tools verwenden, auf die wir uns seit Jahren verlassen, wie curl , wget und Charles und die Netzwerkregisterkarte unserer Browser.
Werkzeugreich
Eine andere Sache, die wir von XML-RPC und SOAP gelernt haben, ist, dass insbesondere Client/Server-Verträge und Typsysteme erstaunlich nützlich sind. Wenn überhaupt möglich, hätte jede neue API die Leichtigkeit eines Formats wie JSON oder YAML mit der Selbstprüfungsfähigkeit von strukturierteren und typsichereren Verträgen.
Bewahrung des lokalen Denkens
Im Laufe der Jahre haben wir uns auf einige Leitprinzipien für die Organisation großer Codebasen geeinigt – das wichtigste ist die „Trennung von Bedenken“. Leider neigt dies bei den meisten Projekten dazu, in Form einer zentralisierten Datenzugriffsebene zusammenzubrechen. Wenn möglich, sollten verschiedene Teile einer Anwendung die Möglichkeit haben, ihre eigenen Datenanforderungen zusammen mit ihren anderen Funktionen zu verwalten.
Da wir eine clientzentrierte API entwerfen, beginnen wir damit, wie es aussehen könnte, Daten in einer solchen API abzurufen. Wenn wir wissen, dass wir sowohl minimale Roundtrips machen müssen als auch in der Lage sein müssen, Felder herauszufiltern, die wir nicht wollen, brauchen wir eine Möglichkeit, sowohl große Datensätze zu durchlaufen als auch nur die Teile davon anzufordern, die es sind nützlich für uns. Eine Abfragesprache scheint hier gut zu passen.
Wir müssen unsere Daten nicht auf die gleiche Weise befragen wie Sie es mit einer Datenbank tun, daher scheint eine imperative Sprache wie SQL das falsche Werkzeug zu sein. Tatsächlich besteht unser Hauptziel darin, bereits bestehende Beziehungen zu durchqueren und Felder zu begrenzen, was wir mit etwas relativ Einfachem und Aussagekräftigem tun können sollten. Die Branche hat sich für nicht-binäre Daten ziemlich gut auf JSON eingestellt, also beginnen wir mit einer JSON-ähnlichen deklarativen Abfragesprache. Wir sollten in der Lage sein, die benötigten Daten zu beschreiben, und der Server sollte JSON mit diesen Feldern zurückgeben.

Eine deklarative Abfragesprache erfüllt die Anforderung sowohl für minimale Nutzlasten als auch für minimalen HTTP-Datenverkehr, aber es gibt noch einen weiteren Vorteil, der uns bei einem anderen unserer Designziele helfen wird. Viele deklarative Sprachen, Abfragen und andere, können effizient manipuliert werden, als ob sie Daten wären. Wenn wir sorgfältig entwerfen, ermöglicht unsere Abfragesprache Entwicklern, große Anfragen zu zerlegen und sie so neu zu kombinieren, wie es für ihr Projekt sinnvoll ist. Die Verwendung einer Abfragesprache wie dieser würde uns dabei helfen, unser ultimatives Ziel der Bewahrung des lokalen Denkens zu erreichen.
Es gibt viele aufregende Dinge, die Sie tun können, sobald Ihre Abfragen zu „Daten“ werden. Beispielsweise könnten Sie alle Anfragen abfangen und sie stapeln, ähnlich wie ein virtuelles DOM DOM-Aktualisierungen stapelt, Sie könnten auch einen Compiler verwenden, um die kleinen Abfragen zur Erstellungszeit zu extrahieren, um die Daten vorab zwischenzuspeichern, oder Sie könnten ein ausgeklügeltes Cache-System erstellen wie Apollo Cache.
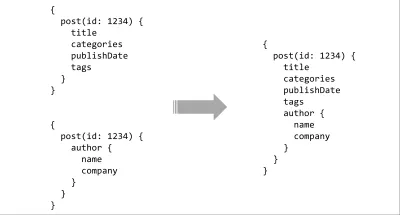
Der letzte Punkt auf der API-Wunschliste sind Werkzeuge. Einiges davon erhalten wir bereits durch die Verwendung einer Abfragesprache, aber die wahre Stärke kommt, wenn Sie es mit einem Typsystem kombinieren. Mit einem einfachen typisierten Schema auf dem Server gibt es nahezu unbegrenzte Möglichkeiten für umfangreiche Tools. Abfragen können statisch analysiert und anhand des Vertrags validiert werden, IDE-Integrationen können Hinweise oder automatische Vervollständigung liefern, Compiler können Build-Time-Optimierungen an Abfragen vornehmen oder mehrere Schemas können zu einer zusammenhängenden API-Oberfläche zusammengefügt werden.

Das Entwerfen einer API, die eine Abfragesprache und ein Typsystem kombiniert, mag nach einem dramatischen Vorschlag klingen, aber die Leute experimentieren seit Jahren in verschiedenen Formen damit. XML-RPC drängte Mitte der 90er Jahre auf getippte Antworten und sein Nachfolger SOAP dominierte jahrelang! In jüngerer Zeit gibt es Dinge wie Meteors MongoDB-Abstraktion, RethinkDBs (RIP) Horizon, Netflixs erstaunliches Falcor, das sie seit Jahren für Netflix.com verwenden, und zuletzt gibt es Facebooks GraphQL. Für den Rest dieses Essays werde ich mich auf GraphQL konzentrieren, da andere Projekte wie Falcor ähnliche Dinge tun, die Meinung der Community es jedoch überwältigend zu bevorzugen scheint.
Was ist GraphQL?
Zuerst muss ich sagen, dass ich ein bisschen gelogen habe. Die API, die wir oben konstruiert haben, war GraphQL. GraphQL ist nur ein Typsystem für Ihre Daten, eine Abfragesprache, um sie zu durchlaufen – der Rest sind nur Details. In GraphQL beschreiben Sie Ihre Daten als Diagramm von Verbindungen, und Ihr Client fragt speziell nach der Teilmenge der Daten, die er benötigt. Es wird viel über all die unglaublichen Dinge gesprochen und geschrieben, die GraphQL ermöglicht, aber die Kernkonzepte sind sehr überschaubar und unkompliziert.
Um diese Konzepte konkreter zu machen und zu veranschaulichen, wie GraphQL versucht, einige der Probleme in Teil 1 anzugehen, wird im Rest dieses Beitrags eine GraphQL-API erstellt, die den Blog in Teil 1 dieser Serie unterstützen kann. Bevor Sie sich mit dem Code befassen, sollten Sie einige Dinge über GraphQL beachten.
GraphQL ist eine Spezifikation (keine Implementierung)
GraphQL ist nur eine Spezifikation. Es definiert ein Typsystem zusammen mit einer einfachen Abfragesprache, und das war's. Als erstes fällt dabei auf, dass GraphQL in keiner Weise an eine bestimmte Sprache gebunden ist. Es gibt über zwei Dutzend Implementierungen von Haskell bis C++, von denen JavaScript nur eine ist. Kurz nachdem die Spezifikation angekündigt wurde, veröffentlichte Facebook eine Referenzimplementierung in JavaScript, aber da sie es nicht intern verwenden, können Implementierungen in Sprachen wie Go und Clojure noch besser oder schneller sein.
Die Spezifikation von GraphQL erwähnt keine Clients oder Daten
Wenn Sie die Spezifikation lesen, werden Sie feststellen, dass zwei Dinge auffällig fehlen. Erstens werden über die Abfragesprache hinaus keine Client-Integrationen erwähnt. Tools wie Apollo, Relay, Loka und dergleichen sind aufgrund des Designs von GraphQL möglich, aber in keiner Weise Bestandteil oder Voraussetzung für die Verwendung. Zweitens wird keine bestimmte Datenschicht erwähnt. Derselbe GraphQL-Server kann Daten aus einer heterogenen Gruppe von Quellen abrufen und tut dies häufig auch. Es kann zwischengespeicherte Daten von Redis anfordern, eine Adresssuche von der USPS-API durchführen und protobuff-basierte Microservices aufrufen, und der Client würde den Unterschied nie erkennen.
Progressive Offenlegung der Komplexität
GraphQL hat für viele Menschen einen seltenen Schnittpunkt von Leistungsfähigkeit und Einfachheit erreicht. Es macht einen fantastischen Job, die einfachen Dinge einfach und die schwierigen Dinge möglich zu machen. Einen Server zum Laufen zu bringen und eingegebene Daten über HTTP bereitzustellen, kann nur ein paar Codezeilen in fast jeder Sprache sein, die Sie sich vorstellen können.
Beispielsweise kann ein GraphQL-Server eine vorhandene REST-API umschließen, und seine Clients können Daten mit regulären GET-Anforderungen abrufen, genau wie Sie mit anderen Diensten interagieren würden. Hier können Sie eine Demo sehen. Oder, wenn das Projekt einen ausgefeilteren Satz von Tools benötigt, ist es möglich, GraphQL zu verwenden, um Dinge wie Authentifizierung auf Feldebene, Pub/Sub-Abonnements oder vorkompilierte/zwischengespeicherte Abfragen zu erledigen.
Eine Beispiel-App
Das Ziel dieses Beispiels ist es, die Leistungsfähigkeit und Einfachheit von GraphQL in ~70 Zeilen JavaScript zu demonstrieren, nicht das Schreiben eines umfangreichen Tutorials. Ich werde auf die Syntax und Semantik nicht zu sehr ins Detail gehen, aber der gesamte Code hier ist lauffähig, und es gibt einen Link zu einer herunterladbaren Version des Projekts am Ende des Artikels. Wenn Sie nach diesem Durchlauf etwas tiefer graben möchten, habe ich eine Sammlung von Ressourcen in meinem Blog, die Ihnen helfen werden, größere, robustere Dienste aufzubauen.
Für die Demo verwende ich JavaScript, aber die Schritte sind in jeder Sprache sehr ähnlich. Beginnen wir mit einigen Beispieldaten mit dem erstaunlichen Mocky.io.
Autoren
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Beiträge
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] Der erste Schritt besteht darin, ein neues Projekt mit express und der express-graphql Middleware zu erstellen.

bash npm init -y && npm install --save graphql express express-graphql Und um eine index.js -Datei mit einem Express-Server zu erstellen.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Um mit GraphQL zu arbeiten, können wir damit beginnen, die Daten in der REST-API zu modellieren. Fügen Sie in einer neuen Datei namens schema.js Folgendes hinzu:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Der obige Code ordnet die Typen in den JSON-Antworten unserer API den Typen von GraphQL zu. Ein GraphQLObjectType entspricht einem JavaScript Object , ein GraphQLString entspricht einem JavaScript- String und so weiter. Der einzige besondere Typ, auf den Sie achten sollten, ist das GraphQLSchema in den letzten paar Zeilen. Das GraphQLSchema ist der Root-Level-Export eines GraphQL – der Ausgangspunkt für Abfragen zum Durchlaufen des Diagramms. In diesem einfachen Beispiel definieren wir nur die query ; Hier würden Sie Mutationen (Schreibvorgänge) und Abonnements definieren.
Als Nächstes fügen wir das Schema unserem Express-Server in der Datei index.js . Dazu fügen wir die express-graphql Middleware hinzu und übergeben ihr das Schema.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Obwohl wir keine Daten zurückgeben, haben wir zu diesem Zeitpunkt einen funktionierenden GraphQL-Server, der sein Schema für Clients bereitstellt. Um das Starten der Anwendung zu erleichtern, werden wir der package.json auch ein Startskript hinzufügen.
"scripts": { "start": "nodemon index.js" }, Wenn Sie das Projekt ausführen und zu https://localhost:5000/ gehen, sollte ein Datenexplorer namens GraphiQL angezeigt werden. GraphiQL wird standardmäßig geladen, solange der HTTP- Accept -Header nicht auf application/json gesetzt ist. Der Aufruf derselben URL mit fetch oder cURL unter Verwendung von application/json gibt ein JSON-Ergebnis zurück. Fühlen Sie sich frei, mit der integrierten Dokumentation herumzuspielen und eine Abfrage zu schreiben.

Das Einzige, was noch zu tun ist, um den Server fertigzustellen, ist, die zugrunde liegenden Daten mit dem Schema zu verbinden. Dazu müssen wir resolve definieren. In GraphQL wird eine Abfrage von oben nach unten ausgeführt, wobei eine resolve aufgerufen wird, während sie den Baum durchquert. Zum Beispiel für die folgende Abfrage:
query homepage { posts { title } } GraphQL ruft zuerst posts.resolve(parentData) und dann posts.title.resolve(parentData) . Beginnen wir damit, den Resolver in unserer Liste mit Blogbeiträgen zu definieren.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Ich verwende hier das isomorphic-fetch Paket, um eine HTTP-Anfrage zu stellen, da es schön demonstriert, wie man ein Promise von einem Resolver zurückgibt, aber Sie können alles verwenden, was Sie wollen. Diese Funktion gibt ein Array von Posts an den Blog-Typ zurück. Die Standardauflösungsfunktion für die JavaScript-Implementierung von GraphQL ist parentData.<fieldName> . Der Standard-Resolver für das Namensfeld des Autors wäre beispielsweise:
rawAuthorObject => rawAuthorObject.nameDieser Single-Override-Resolver sollte die Daten für das gesamte Post-Objekt bereitstellen. Wir müssen noch den Resolver für Author definieren, aber wenn Sie eine Abfrage ausführen, um die für die Homepage erforderlichen Daten abzurufen, sollte es funktionieren.
Da das Autorenattribut in unserer Posts-API nur die Autoren-ID ist, gibt GraphQL, wenn es nach einem Objekt sucht, das Name und Unternehmen definiert, und einen String findet, einfach null zurück. Um den Autor einzubinden, müssen wir unser Post-Schema so ändern, dass es wie folgt aussieht:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Jetzt haben wir einen voll funktionsfähigen GraphQL-Server, der eine REST-API umschließt. Die vollständige Quelle kann von diesem Github-Link heruntergeladen oder von diesem GraphQL-Launchpad ausgeführt werden.
Sie fragen sich vielleicht, welche Tools Sie verwenden müssen, um einen solchen GraphQL-Endpunkt zu nutzen. Es gibt viele Optionen wie Relay und Apollo, aber für den Anfang denke ich, dass der einfache Ansatz der beste ist. Wenn Sie viel mit GraphiQL herumgespielt haben, ist Ihnen vielleicht aufgefallen, dass es eine lange URL hat. Diese URL ist nur eine URI-codierte Version Ihrer Abfrage. Um eine GraphQL-Abfrage in JavaScript zu erstellen, können Sie Folgendes tun:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Oder, wenn Sie möchten, können Sie die URL wie folgt direkt aus GraphiQL kopieren und einfügen:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageDa wir einen GraphQL-Endpunkt und eine Möglichkeit haben, ihn zu verwenden, können wir ihn mit unserer RESTish-API vergleichen. Der Code, den wir schreiben mussten, um unsere Daten mit einer REST-API abzurufen, sah folgendermaßen aus:
Verwenden einer RESTish-API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Verwenden einer GraphQL-API
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Zusammenfassend haben wir GraphQL verwendet, um:
- Reduzieren Sie neun Anfragen (Liste der Posts, vier Blog-Posts und den Autor jedes Posts).
- Reduzieren Sie die gesendete Datenmenge um einen erheblichen Prozentsatz.
- Verwenden Sie unglaubliche Entwicklertools, um unsere Abfragen zu erstellen.
- Schreiben Sie viel saubereren Code in unserem Client.
Fehler in GraphQL
Obwohl ich glaube, dass der Hype gerechtfertigt ist, gibt es keine Wunderwaffe, und so großartig GraphQL auch ist, es ist nicht ohne Fehler.
Datenintegrität
GraphQL wirkt manchmal wie ein Tool, das speziell für gute Daten entwickelt wurde. Es funktioniert oft am besten als eine Art Gateway, das unterschiedliche Dienste oder stark normalisierte Tabellen zusammenfügt. Wenn die Daten, die von den von Ihnen genutzten Diensten zurückkommen, chaotisch und unstrukturiert sind, kann das Hinzufügen einer Datentransformationspipeline unter GraphQL eine echte Herausforderung sein. Der Geltungsbereich einer GraphQL-Auflösungsfunktion sind nur ihre eigenen Daten und die ihrer Kinder. Wenn eine Orchestrierungsaufgabe Zugriff auf Daten in einem gleichgeordneten oder übergeordneten Element im Baum benötigt, kann dies eine besondere Herausforderung darstellen.
Komplexe Fehlerbehandlung
Eine GraphQL-Anforderung kann eine beliebige Anzahl von Abfragen ausführen, und jede Abfrage kann eine beliebige Anzahl von Diensten treffen. Wenn ein Teil der Anfrage fehlschlägt, gibt GraphQL standardmäßig Teildaten zurück, anstatt die gesamte Anfrage fehlschlagen zu lassen. Partielle Daten sind technisch wahrscheinlich die richtige Wahl und können unglaublich nützlich und effizient sein. Der Nachteil ist, dass die Fehlerbehandlung nicht mehr so einfach ist wie die Überprüfung des HTTP-Statuscodes. Dieses Verhalten kann abgeschaltet werden, aber meistens enden Clients mit komplizierteren Fehlerfällen.
Caching
Obwohl es oft eine gute Idee ist, statische GraphQL-Abfragen zu verwenden, ist für Organisationen wie Github, die beliebige Abfragen zulassen, das Netzwerk-Caching mit Standard-Tools wie Varnish oder Fastly nicht mehr möglich.
Hohe CPU-Kosten
Das Analysieren, Validieren und Typ-Checken einer Abfrage ist ein CPU-gebundener Prozess, der zu Leistungsproblemen in Single-Threaded-Sprachen wie JavaScript führen kann.
Dies ist nur ein Problem für die Abfrageauswertung zur Laufzeit.
Abschließende Gedanken
Die Funktionen von GraphQL sind keine Revolution – einige von ihnen gibt es schon seit fast 30 Jahren. Was GraphQL leistungsfähig macht, ist, dass der Grad an Politur, Integration und Benutzerfreundlichkeit es zu mehr als der Summe seiner Teile macht.
Viele der Dinge, die GraphQL leistet, können mit Mühe und Disziplin mit REST oder RPC erreicht werden, aber GraphQL bringt hochmoderne APIs in die enorme Anzahl von Projekten, die möglicherweise nicht die Zeit, die Ressourcen oder die Tools haben, um dies selbst zu tun. Es stimmt auch, dass GraphQL keine Wunderwaffe ist, aber seine Mängel sind in der Regel geringfügig und gut verständlich. Als jemand, der einen einigermaßen komplizierten GraphQL-Server aufgebaut hat, kann ich leicht sagen, dass die Vorteile die Kosten leicht überwiegen.
Dieser Aufsatz konzentriert sich fast ausschließlich darauf, warum GraphQL existiert und welche Probleme es löst. Wenn dies Ihr Interesse geweckt hat, mehr über seine Semantik und seine Verwendung zu erfahren, ermutige ich Sie, auf die für Sie am besten geeignete Weise zu lernen, sei es durch Blogs, YouTube oder einfach nur durch das Lesen der Quelle (How To GraphQL ist besonders gut).
Wenn Ihnen dieser Artikel gefallen hat (oder wenn Sie ihn gehasst haben) und mir Feedback geben möchten, finden Sie mich bitte auf Twitter unter @ebaerbaerbaer oder LinkedIn unter ericjbaer.