
Eine GraphQL-Einführung: Warum wir eine neue Art von API brauchen (Teil 1)
Veröffentlicht: 2022-03-10In dieser Serie möchte ich Ihnen GraphQL vorstellen. Am Ende sollten Sie nicht nur verstehen, was es ist, sondern auch seine Ursprünge, seine Nachteile und die Grundlagen, wie man damit arbeitet. Anstatt in die Implementierung zu springen, möchte ich in diesem ersten Artikel darauf eingehen, wie und warum wir zu GraphQL (und ähnlichen Tools) gekommen sind, indem ich mir die Lehren aus den letzten 60 Jahren der API-Entwicklung anschaue, von RPC bis heute. Schließlich gibt es, wie Mark Twain farbenfroh beschrieben hat, keine neuen Ideen.
"So etwas wie eine neue Idee gibt es nicht. Es ist unmöglich. Wir nehmen einfach viele alte Ideen und fügen sie in eine Art mentales Kaleidoskop ein."
– Mark Twain in „Mark Twains eigene Autobiografie: Die Kapitel aus der nordamerikanischen Rezension“
Aber zuerst muss ich den Elefanten im Raum ansprechen. Neues ist immer spannend, kann sich aber auch anstrengend anfühlen. Sie haben vielleicht schon von GraphQL gehört und dachten nur: „Warum …“ Oder vielleicht dachten Sie eher so etwas wie: „Warum interessiere ich mich für einen neuen API-Designtrend? RUHE ist … gut.“ Dies sind legitime Fragen, also lassen Sie mich erklären, warum Sie dieser Frage Aufmerksamkeit schenken sollten.
Einführung
Die Vorteile der Bereitstellung neuer Tools für Ihr Team müssen gegen die Kosten abgewogen werden. Es gibt viele Dinge zu messen. Es gibt die Zeit, die zum Lernen benötigt wird, die Zeit, die das Konvertieren von der Feature-Entwicklung wegnimmt, den Aufwand für die Wartung von zwei Systemen. Bei so hohen Kosten muss jede neue Technologie um ein Vielfaches besser, schneller oder produktiver sein . Inkrementelle Verbesserungen sind zwar spannend, aber die Investition nicht wert. Die Arten von APIs, über die ich sprechen möchte, insbesondere GraphQL, sind meiner Meinung nach ein großer Schritt nach vorne und bieten mehr als genug Nutzen, um die Kosten zu rechtfertigen.
Anstatt zuerst Features zu erkunden, ist es hilfreich, sie in einen Kontext zu stellen und zu verstehen, wie sie entstanden sind. Dazu beginne ich mit einer kurzen Zusammenfassung der Geschichte der APIs.
RPC
RPC war wohl das erste große API-Muster, und seine Ursprünge reichen bis in die frühen Computer Mitte der 60er Jahre zurück. Damals waren Computer noch so groß und teuer, dass der Begriff der API-gesteuerten Anwendungsentwicklung, wie wir ihn uns vorstellen, größtenteils nur theoretisch war. Einschränkungen wie Bandbreite/Latenz, Rechenleistung, gemeinsam genutzte Rechenzeit und physische Nähe zwangen Ingenieure dazu, in verteilten Systemen statt in Diensten zu denken , die Daten offen legen. Von ARPANET in den 60er Jahren bis Mitte der 90er Jahre mit Dingen wie CORBA und Javas RMI interagierten die meisten Computer über Remote Procedure Calls (RPC), ein Client-Server-Interaktionsmodell, bei dem ein Client eine Prozedur auslöst (oder Methode) zur Ausführung auf einem entfernten Server.
Es gibt viele nette Dinge über RPC. Sein Hauptprinzip besteht darin, einem Entwickler zu ermöglichen, Code in einer entfernten Umgebung so zu behandeln, als ob er sich in einer lokalen Umgebung befände, wenn auch viel langsamer und weniger zuverlässig, was Kontinuität in ansonsten unterschiedlichen und unterschiedlichen Systemen schafft. Wie viele Dinge, die aus ARPANET herauskamen, war es seiner Zeit voraus, da wir immer noch nach dieser Art von Kontinuität streben, wenn wir mit unzuverlässigen und asynchronen Aktionen wie DB-Zugriffen und externen Dienstaufrufen arbeiten.
Im Laufe der Jahrzehnte wurde enorm viel darüber geforscht, wie man es Entwicklern ermöglichen kann, asynchrones Verhalten wie dieses in den typischen Ablauf eines Programms einzubetten; Wären zu diesem Zeitpunkt Dinge wie Promises, Futures und ScheduledTasks verfügbar gewesen, wäre es möglich, dass unsere API-Landschaft anders aussehen würde.
Eine weitere großartige Sache bei RPC ist, dass, da es nicht durch die Datenstruktur eingeschränkt ist, hochspezialisierte Methoden für Clients geschrieben werden können, die genau die benötigten Informationen anfordern und abrufen, was zu minimalem Netzwerk-Overhead und geringeren Nutzlasten führen kann.
Es gibt jedoch Dinge, die RPC erschweren. Erstens erfordert Kontinuität Kontext . RPC schafft von Natur aus eine ziemlich starke Kopplung zwischen lokalen und entfernten Systemen – Sie verlieren die Grenzen zwischen Ihrem lokalen und Ihrem entfernten Code. Für einige Domänen ist dies in Ordnung oder wird sogar bevorzugt, wie bei Client-SDKs, aber für APIs, bei denen der Client-Code nicht gut verstanden wird, kann es erheblich weniger flexibel sein als etwas, das stärker datenorientiert ist.
Noch wichtiger ist jedoch das Potenzial für die Verbreitung von API-Methoden . Theoretisch stellt ein RPC-Dienst eine kleine durchdachte API bereit, die jede Aufgabe bewältigen kann. In der Praxis kann eine große Anzahl externer Endpunkte ohne viel Struktur anwachsen. Es erfordert ein enormes Maß an Disziplin, um sich überschneidende APIs und Duplikate im Laufe der Zeit zu verhindern, wenn Teammitglieder kommen und gehen und Projekte sich drehen.
Es ist wahr, dass mit den richtigen Werkzeugen und Dokumentationen Änderungen, wie die von mir erwähnten, bewältigt werden können, aber in meiner Zeit beim Schreiben von Software bin ich auf wenige Dienste mit automatischer Dokumentation und disziplinierten Diensten gestoßen, daher ist dies für mich ein bisschen ein Ablenkungsmanöver.
SEIFE
Der nächste große API-Typ war SOAP, das Ende der 90er Jahre bei Microsoft Research geboren wurde. SOAP ( Simple Object Access Protocol) ist eine ehrgeizige Protokollspezifikation für die XML-basierte Kommunikation zwischen Anwendungen. Das erklärte Ziel von SOAP war es, einige der praktischen Nachteile von RPC, insbesondere XML-RPC, anzugehen, indem eine gut strukturierte Grundlage für komplexe Webdienste geschaffen wurde. Tatsächlich bedeutete dies lediglich, XML ein Verhaltenstypsystem hinzuzufügen. Leider hat es mehr Hindernisse geschaffen als es gelöst hat, wie die Tatsache zeigt, dass heute nur sehr wenige neue SOAP-Endpunkte geschrieben werden.
"SOAP ist das, was die meisten Leute als mäßigen Erfolg bezeichnen würden."
— Don-Box
SOAP hatte trotz seiner unerträglichen Ausführlichkeit und seiner schrecklichen Namen einige gute Dinge zu bieten. Die durchsetzbaren Verträge in WSDL und WADL (ausgesprochen „wizdle“ und „waddle“) zwischen dem Client und dem Server garantierten vorhersagbare, typsichere Ergebnisse, und die WSDL könnte verwendet werden, um Dokumentation zu generieren oder Integrationen mit IDEs und anderen Tools zu erstellen.
Die große Offenbarung von SOAP in Bezug auf die API-Entwicklung war die allmähliche und möglicherweise unbeabsichtigte Einführung von mehr ressourcenorientierten Aufrufen. SOAP-Endpunkte ermöglichen es Ihnen, Daten mit einer vorgegebenen Struktur anzufordern, anstatt über die Methoden nachzudenken, die zum Generieren der Daten erforderlich sind (vorausgesetzt, sie sind so geschrieben).
Der bedeutendste Nachteil von SOAP ist, dass es so ausführlich ist; es ist fast unmöglich, ohne viel Werkzeug zu verwenden . Sie benötigen Tools zum Schreiben von Tests, Tools zum Überprüfen der Antworten von einem Server und Tools zum Analysieren aller Daten. Viele ältere Systeme verwenden immer noch SOAP, aber der Bedarf an Tools macht es für die meisten neuen Projekte zu umständlich, und die Anzahl der für die XML-Struktur benötigten Bytes macht es zu einer schlechten Wahl für mobile Geräte oder gesprächige verteilte Systeme.
Für weitere Informationen lohnt es sich, die SOAP-Spezifikation sowie die überraschend interessante Geschichte von SOAP von Don Box, einem der ursprünglichen Teammitglieder, zu lesen.
SICH AUSRUHEN
Schließlich sind wir beim API-Entwurfsmuster du jour angelangt: REST. REST, eingeführt in einer Doktorarbeit von Roy Fielding im Jahr 2000, hat das Pendel in eine ganz andere Richtung geschwungen. REST ist in vielerlei Hinsicht das Gegenteil von SOAP, und wenn man sie Seite an Seite betrachtet, hat man das Gefühl, dass seine Dissertation ein bisschen ein Wutausbruch war.
SOAP verwendet HTTP als dummen Transport und baut seine Struktur im Anforderungs- und Antworttext auf. REST hingegen verwirft die Client-Server-Verträge, Tools, XML und maßgeschneiderte Header und ersetzt sie durch HTTPs-Semantik, da es sich um eine Struktur handelt, die sich dafür entscheidet, stattdessen HTTP-Verben zu verwenden, die mit Daten und URIs interagieren, die auf eine Ressource in einer Hierarchie von verweisen Daten.
| SEIFE | SICH AUSRUHEN | |
|---|---|---|
| HTTP-Verben | GET, PUT, POST, PATCH, LÖSCHEN | |
| Datei Format | XML | Irgendwas du willst |
| Client/Server-Verträge | Den ganzen Tag, jeden Tag! | Wer braucht die |
| Geben Sie System ein | JavaScript hat unsigned short richtig? | |
| URLs | Vorgänge beschreiben | Benannte Ressourcen |
REST ändert das API-Design vollständig und explizit von der Modellierung von Interaktionen zur einfachen Modellierung der Daten einer Domäne. Da Sie bei der Arbeit mit einer REST-API vollständig ressourcenorientiert sind, müssen Sie nicht mehr wissen oder sich darum kümmern, was erforderlich ist, um ein bestimmtes Datenelement abzurufen. Sie müssen auch nichts über die Implementierung der Backend-Dienste wissen.

Die Einfachheit war nicht nur ein Segen für Entwickler, sondern da URLs stabile Informationen darstellen, können sie leicht zwischengespeichert werden, ihre Zustandslosigkeit erleichtert die horizontale Skalierung und da sie die Daten modelliert, anstatt die Bedürfnisse der Verbraucher vorwegzunehmen, kann sie die Oberfläche von APIs drastisch reduzieren .
REST ist großartig und seine Allgegenwart ist ein erstaunlicher Erfolg, aber wie alle Lösungen davor ist REST nicht ohne Fehler. Um konkret über einige seiner Mängel zu sprechen, gehen wir ein einfaches Beispiel durch. Nehmen wir an, wir müssten die Zielseite eines Blogs erstellen, die eine Liste von Blog-Posts und den Namen ihres Autors anzeigt.
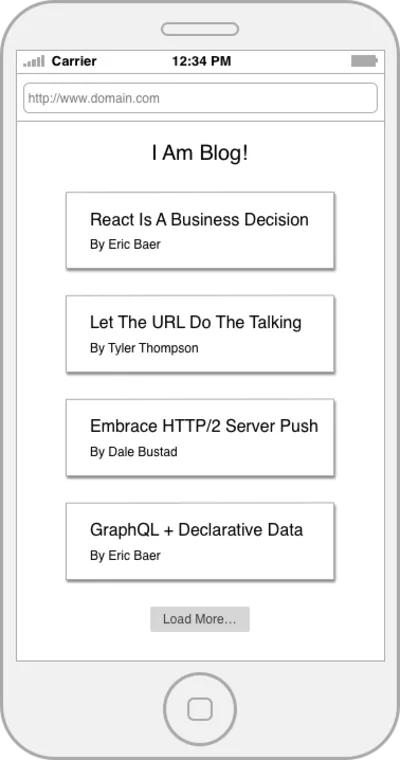
Lassen Sie uns den Code schreiben, der die Homepage-Daten von einer einfachen REST-API abrufen kann. Wir beginnen mit ein paar Funktionen, die unsere Ressourcen verpacken.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);Lasst uns jetzt orchestrieren!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Unser Code wird also Folgendes tun:
- Alle Beiträge abrufen;
- Rufen Sie die Details zu jedem Beitrag ab;
- Holen Sie sich die Autorenressource für jeden Beitrag.
Das Schöne ist, dass dies ziemlich einfach zu begründen ist, gut organisiert ist und die konzeptionellen Grenzen jeder Ressource gut gezogen sind. Das Schlimme hier ist, dass wir gerade acht Netzwerkanfragen gestellt haben, von denen viele nacheinander passieren.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Ja, Sie könnten dieses Beispiel kritisieren, indem Sie vorschlagen, dass die API einen paginierten /posts -Endpunkt haben könnte, aber das ist Haarspalterei. Tatsache bleibt, dass Sie oft eine Sammlung von API-Aufrufen durchführen müssen, die voneinander abhängen, um eine vollständige Anwendung oder Seite zu rendern.
Die Entwicklung von REST-Clients und -Servern ist sicherlich besser als das, was davor kam, oder zumindest idiotensicherer, aber in den zwei Jahrzehnten seit Fieldings Artikel hat sich viel verändert. Damals waren alle Computer aus beigem Plastik; Jetzt sind sie aus Aluminium! Aber im Ernst, das Jahr 2000 war nahe dem Höhepunkt der Explosion des Personal Computing. Jedes Jahr verdoppelten sich Prozessoren in ihrer Geschwindigkeit und Netzwerke wurden unglaublich schnell schneller. Die Marktdurchdringung des Internets lag bei etwa 45 %, wobei es nur nach oben ging.
Dann, um 2008 herum, wurde Mobile Computing zum Mainstream. Bei Mobilgeräten sind wir in Bezug auf Geschwindigkeit/Leistung über Nacht effektiv um ein Jahrzehnt zurückgegangen. Im Jahr 2017 haben wir fast 80 % inländische und über 50 % weltweite Smartphone-Durchdringung, und es ist an der Zeit, einige unserer Annahmen zum API-Design zu überdenken.
Die Schwächen von REST
Das Folgende ist ein kritischer Blick auf REST aus der Perspektive eines Client-Anwendungsentwicklers, insbesondere eines, der im mobilen Bereich arbeitet. GraphQL und APIs im GraphQL-Stil sind nicht neu und lösen keine Probleme, die außerhalb des Verständnisses von REST-Entwicklern liegen. Der bedeutendste Beitrag von GraphQL ist seine Fähigkeit, diese Probleme systematisch und mit einem Integrationsgrad zu lösen, der anderswo nicht ohne Weiteres verfügbar ist. Mit anderen Worten, es handelt sich um eine „Batterien inklusive“-Lösung.
Die Hauptautoren von REST, einschließlich Fielding, veröffentlichten Ende 2017 ein Papier (Reflections on the REST Architectural Style and „Principled Design of the Modern Web Architecture“), in dem sie über zwei Jahrzehnte REST und die vielen Muster nachdenken, die es inspiriert hat. Es ist kurz und absolut lesenswert für alle, die sich für API-Design interessieren.
Lassen Sie uns mit etwas historischem Kontext und einer Referenz-App einen Blick auf die drei Hauptschwächen von REST werfen.
REST ist gesprächig
REST-Dienste neigen dazu, zumindest etwas „gesprächig“ zu sein, da mehrere Roundtrips zwischen Client und Server erforderlich sind, um genügend Daten zum Rendern einer Anwendung zu erhalten. Diese Kaskade von Anfragen hat verheerende Auswirkungen auf die Leistung, insbesondere auf Mobilgeräten. Zurück zum Blog-Beispiel: Selbst im besten Fall mit einem neuen Telefon und einem zuverlässigen Netzwerk mit einer 4G-Verbindung haben Sie fast 0,5 Sekunden nur für den Latenz-Overhead aufgewendet, bevor das erste Datenbyte heruntergeladen wird.
55 ms 4G-Latenz * 8 Anfragen = 440 ms Overhead
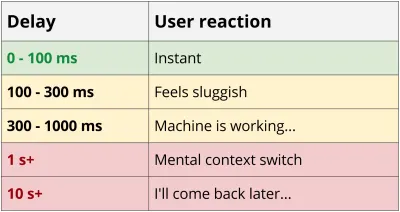
Ein weiteres Problem bei Chatty-Diensten besteht darin, dass das Herunterladen einer großen Anfrage in vielen Fällen weniger Zeit in Anspruch nimmt als viele kleine. Die reduzierte Leistung kleiner Anfragen hat viele Gründe, darunter TCP Slow Start, fehlende Header-Komprimierung und gzip-Effizienz, und wenn Sie neugierig darauf sind, empfehle ich Ihnen dringend, Ilya Grigoriks High-Performance Browser Networking zu lesen. Auch der MaxCDN-Blog bietet eine tolle Übersicht.
Dieses Problem liegt technisch gesehen nicht bei REST, sondern bei HTTP, insbesondere HTTP/1. HTTP/2 löst praktisch das Problem der Geschwätzigkeit unabhängig vom API-Stil und wird von Clients wie Browsern und nativen SDKs umfassend unterstützt. Leider war der Rollout auf der API-Seite langsam. Unter den Top-10.000-Websites liegt die Akzeptanz seit Ende 2017 bei etwa 20 % (und steigt). Sogar Node.js hat zu meiner großen Überraschung HTTP/2-Unterstützung in ihrer 8.x-Version erhalten. Wenn Sie die Möglichkeit haben, aktualisieren Sie bitte Ihre Infrastruktur! Lassen Sie uns in der Zwischenzeit nicht verweilen, da dies nur ein Teil der Gleichung ist.
Abgesehen von HTTP hat der letzte Punkt, warum Geschwätzigkeit wichtig ist, damit zu tun, wie mobile Geräte und insbesondere ihre Funkgeräte funktionieren. Das lange und kurze daran ist, dass der Betrieb des Radios einer der batterieintensivsten Teile eines Telefons ist, sodass das Betriebssystem es bei jeder Gelegenheit ausschaltet. Das Starten des Funkgeräts entleert nicht nur die Batterie, sondern fügt jeder Anforderung noch mehr Overhead hinzu.
TMI (Überholen)
Das nächste Problem mit Diensten im REST-Stil besteht darin, dass sie viel mehr Informationen senden, als benötigt werden. In unserem Blog-Beispiel brauchen wir nur den Titel jedes Posts und den Namen des Autors, was nur etwa 17 % dessen ausmacht, was zurückgegeben wurde. Das ist ein 6-facher Verlust für eine sehr einfache Nutzlast. In einer realen API kann diese Art von Overhead enorm sein. E-Commerce-Websites beispielsweise stellen ein einzelnes Produkt oft in Tausenden von JSON-Zeilen dar. Wie das Problem der Chattiness können REST-Dienste dieses Szenario heute bewältigen, indem sie „sparse fieldsets“ verwenden, um Teile der Daten bedingt einzuschließen oder auszuschließen. Leider ist die Unterstützung dafür lückenhaft, unvollständig oder problematisch für das Netzwerk-Caching.
Werkzeuge und Selbstbeobachtung
Das letzte, was REST-APIs fehlen, sind Mechanismen zur Selbstprüfung. Ohne einen Vertrag mit Informationen über die Rückgabetypen oder die Struktur eines Endpunkts gibt es keine Möglichkeit, zuverlässig Dokumentation zu generieren, Tools zu erstellen oder mit den Daten zu interagieren. Es ist möglich, innerhalb von REST zu arbeiten, um dieses Problem in unterschiedlichem Maße zu lösen. Projekte, die OpenAPI, OData oder JSON API vollständig implementieren, sind oft sauber, gut spezifiziert und in unterschiedlichem Maße gut dokumentiert, aber Backends wie dieses sind selten. Sogar Hypermedia, eine relativ niedrig hängende Frucht, wird, obwohl sie jahrzehntelang bei Konferenzgesprächen angepriesen wurde, immer noch nicht oft gut gemacht, wenn überhaupt.
Fazit
Jeder der API-Typen ist fehlerhaft, aber jedes Muster ist fehlerhaft. Dieses Schreiben ist kein Urteil über die phänomenale Grundlagenarbeit, die die Giganten der Softwarebranche geleistet haben, sondern nur eine nüchterne Bewertung jedes dieser Muster, angewendet in ihrer „reinen“ Form aus der Perspektive eines Client-Entwicklers. Ich hoffe, dass Sie, anstatt von diesem Denken wegzukommen, dass ein Muster wie REST oder RPC gebrochen ist, dass Sie darüber nachdenken können, wie sie jeweils Kompromisse eingegangen sind und auf welche Bereiche eine Ingenieurorganisation ihre Bemühungen konzentrieren könnte, um ihre eigenen APIs zu verbessern .
Im nächsten Artikel werde ich GraphQL untersuchen und wie es darauf abzielt, einige der oben genannten Probleme anzugehen. Die Innovation bei GraphQL und ähnlichen Tools liegt in ihrem Integrationsgrad und nicht in ihrer Implementierung. Bitte, wenn Sie oder Ihr Team nicht nach einer API mit „Batterien inklusive“ suchen, sollten Sie sich etwas wie die neue OpenAPI-Spezifikation ansehen, die heute helfen kann, eine stärkere Grundlage zu schaffen!
Wenn Ihnen dieser Artikel gefallen hat (oder wenn Sie ihn gehasst haben) und mir Feedback geben möchten, finden Sie mich bitte auf Twitter unter @ebaerbaerbaer oder LinkedIn unter ericjbaer.