
Gradientenabstieg in der logistischen Regression [Erklärt für Anfänger]
Veröffentlicht: 2021-01-08In diesem Artikel werden wir den sehr beliebten Gradientenabstiegsalgorithmus in der logistischen Regression diskutieren. Wir werden uns ansehen, was die logistische Regression ist, und uns dann schrittweise zur Gleichung für die logistische Regression, ihrer Kostenfunktion und schließlich zum Gradientenabstiegsalgorithmus bewegen.
Inhaltsverzeichnis
Was ist logistische Regression?
Die logistische Regression ist einfach ein Klassifizierungsalgorithmus, der verwendet wird, um diskrete Kategorien vorherzusagen, z. B. um vorherzusagen, ob eine E-Mail „Spam“ oder „Kein Spam“ ist; Vorhersagen, ob eine gegebene Ziffer eine '9' oder 'nicht 9' ist usw. Nun, wenn Sie sich den Namen ansehen, müssen Sie denken, warum heißt es Regression?
Der Grund dafür ist, dass die Idee der logistischen Regression entwickelt wurde, indem einige Elemente des grundlegenden linearen Regressionsalgorithmus optimiert wurden, der bei Regressionsproblemen verwendet wird.
Die logistische Regression kann auch auf Klassifizierungsprobleme mit mehreren Klassen (mehr als zwei Klassen) angewendet werden. Es wird jedoch empfohlen, diesen Algorithmus nur für binäre Klassifikationsprobleme zu verwenden.
Sigmoid-Funktion
Klassifikationsprobleme sind keine Probleme mit linearen Funktionen. Die Ausgabe ist auf bestimmte diskrete Werte beschränkt, z. B. 0 und 1 für ein binäres Klassifikationsproblem. Es macht keinen Sinn, dass eine lineare Funktion unsere Ausgabewerte als größer als 1 oder kleiner als 0 vorhersagt. Wir brauchen also eine geeignete Funktion, um unsere Ausgabewerte darzustellen.
Die Sigmoid-Funktion löst unser Problem. Auch als logistische Funktion bekannt, ist es eine S-förmige Funktion, die jede reelle Wertzahl auf ein (0,1)-Intervall abbildet, was es sehr nützlich macht, jede zufällige Funktion in eine klassifikationsbasierte Funktion umzuwandeln. Eine Sigmoid-Funktion sieht so aus:

Sigmoid-Funktion
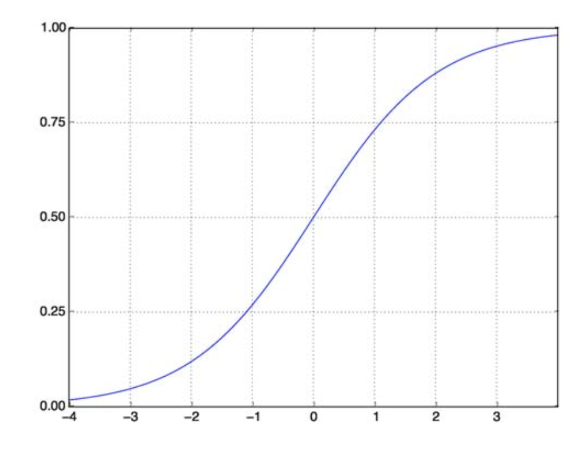
Quelle
Nun ist die mathematische Form der Sigmoidfunktion für parametrisierten Vektor und Eingabevektor X:
(z) = 11+exp(-z) wobei z = TX
(z) gibt uns die Wahrscheinlichkeit, dass die Ausgabe 1 ist. Wie wir alle wissen, reicht der Wahrscheinlichkeitswert von 0 bis 1. Nun, das ist nicht die Ausgabe, die wir für unser diskretbasiertes (nur 0 und 1) Klassifizierungsproblem wollen . Jetzt können wir also die vorhergesagte Wahrscheinlichkeit mit 0,5 vergleichen. Wenn die Wahrscheinlichkeit > 0,5 ist, haben wir y=1. Wenn die Wahrscheinlichkeit < 0,5 ist, haben wir analog y=0.
Kostenfunktion
Nachdem wir nun unsere diskreten Vorhersagen haben, ist es an der Zeit zu prüfen, ob unsere Vorhersagen tatsächlich richtig sind oder nicht. Dazu haben wir eine Kostenfunktion. Die Kostenfunktion ist lediglich die Summe aller Fehler, die in den Vorhersagen über den gesamten Datensatz gemacht wurden. Natürlich können wir die in der linearen Regression verwendete Kostenfunktion nicht verwenden. Die neue Kostenfunktion für die logistische Regression lautet also:
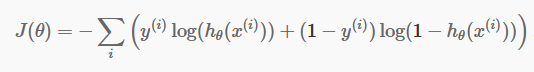 Quelle
Quelle
Keine Angst vor der Gleichung. Es ist sehr einfach. Für jede Iteration i berechnet es den Fehler, den wir in unserer Vorhersage gemacht haben, und addiert dann alle Fehler, um unsere Kostenfunktion J() zu definieren.
Die beiden Terme in der Klammer stehen eigentlich für die beiden Fälle: y=0 und y=1. Wenn y = 0, verschwindet der erste Term und wir haben nur den zweiten Term übrig. In ähnlicher Weise verschwindet der zweite Term, wenn y = 1, und es bleibt nur der erste Term übrig.
Gradientenabstiegsalgorithmus
Wir haben unsere Kostenfunktion erfolgreich berechnet. Aber wir müssen den Verlust minimieren, um einen guten Vorhersagealgorithmus zu erstellen. Dazu haben wir den Gradientenabstiegsalgorithmus.
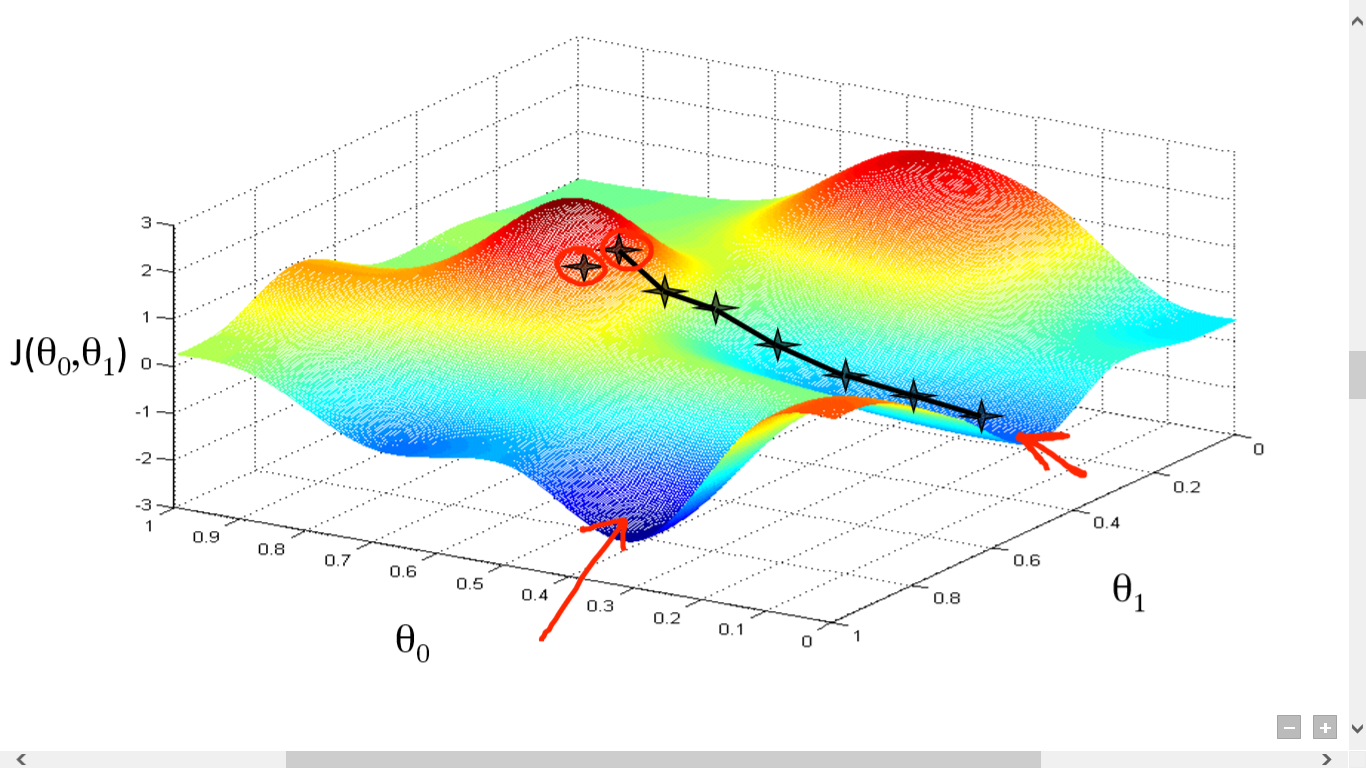 Quelle
Quelle
Hier haben wir einen Graphen zwischen J() und gezeichnet. Unser Ziel ist es, den tiefsten Punkt (globales Minimum) dieser Funktion zu finden. Jetzt ist der tiefste Punkt dort, wo J() minimal ist.
Zwei Dinge sind erforderlich, um den tiefsten Punkt zu finden:
- Ableitung – um die Richtung des nächsten Schritts zu finden.
- (Lernrate) – Größe des nächsten Schritts
Die Idee ist, dass Sie zuerst einen beliebigen Punkt aus der Funktion auswählen. Dann müssen Sie die Ableitung von J()wrt berechnen. Dies zeigt in Richtung des lokalen Minimums. Multiplizieren Sie nun diesen resultierenden Gradienten mit der Lernrate. Die Lernrate hat keinen festen Wert und ist problembezogen festzulegen.
Jetzt müssen Sie das Ergebnis von subtrahieren, um das neue zu erhalten.
Diese Aktualisierung von sollte gleichzeitig für alle (i) erfolgen .
Wiederholen Sie diese Schritte, bis Sie das lokale oder globale Minimum erreichen. Durch das Erreichen des globalen Minimums haben Sie den geringstmöglichen Verlust in Ihrer Vorhersage erreicht.
Derivate zu nehmen ist einfach. Nur die grundlegende Rechnung, die Sie in Ihrer High School gemacht haben müssen, reicht aus. Das Hauptproblem ist die Lernrate( ). Eine gute Lernrate zu erreichen ist wichtig und oft schwierig.
Wenn Sie eine sehr kleine Lernrate nehmen, wird jeder Schritt zu klein sein, und Sie werden daher viel Zeit benötigen, um das lokale Minimum zu erreichen.

Wenn Sie nun dazu neigen, einen sehr hohen Wert für die Lernrate zu nehmen, werden Sie das Minimum überschreiten und nie wieder konvergieren. Es gibt keine spezifische Regel für die perfekte Lernrate.
Sie müssen es optimieren, um das beste Modell vorzubereiten.
Die Gleichung für Gradient Descent lautet:
Wiederholen bis zur Konvergenz:
Wir können den Gradientenabstiegsalgorithmus also wie folgt zusammenfassen:
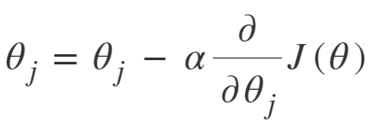
- Beginnen Sie mit zufällig
- Schleife bis zur Konvergenz:
- Gradient berechnen
- Aktualisieren
- Zurückkehren
Stochastischer Gradientenabstiegsalgorithmus
Jetzt ist der Gradientenabstiegsalgorithmus ein feiner Algorithmus zur Minimierung der Kostenfunktion, insbesondere für kleine bis mittlere Daten. Aber wenn wir mit größeren Datensätzen umgehen müssen, erweist sich der Gradient-Descent-Algorithmus als langsam in der Berechnung. Der Grund ist einfach: Es muss den Gradienten berechnen und die Werte gleichzeitig für jeden Parameter aktualisieren, und das auch für jedes Trainingsbeispiel.
Denken Sie also an all diese Berechnungen! Es ist massiv, und daher bestand Bedarf an einem leicht modifizierten Gradientenabstiegsalgorithmus, nämlich dem stochastischen Gradientenabstiegsalgorithmus (SGD).
Der einzige Unterschied zwischen SGD und Normal Gradient Descent besteht darin, dass wir uns bei SGD nicht mit der gesamten Trainingsinstanz auf einmal befassen. In SGD berechnen wir den Gradienten der Kostenfunktion für nur ein einzelnes zufälliges Beispiel bei jeder Iteration.
Dadurch wird die für Berechnungen benötigte Zeit erheblich verkürzt, insbesondere bei großen Datensätzen. Der von SGD eingeschlagene Weg ist sehr willkürlich und verrauscht (obwohl uns ein verrauschter Weg die Chance geben kann, globale Minima zu erreichen).
Aber das ist in Ordnung, da wir uns um den eingeschlagenen Weg keine Gedanken machen müssen.
Wir müssen nur einen minimalen Verlust in einer schnelleren Zeit erreichen.
Wir können den Gradientenabstiegsalgorithmus also wie folgt zusammenfassen:
- Schleife bis zur Konvergenz:
- Wählen Sie einen einzelnen Datenpunkt ' i'
- Berechnen Sie den Gradienten über diesem einzelnen Punkt
- Aktualisieren
- Zurückkehren
Mini-Batch-Gradientenabstiegsalgorithmus
Mini-Batch Gradient Descent ist eine weitere geringfügige Modifikation des Gradient Descent-Algorithmus. Es liegt etwas zwischen Normal Gradient Descent und Stochastic Gradient Descent.
Mini-Batch Gradient Descent nimmt nur einen kleineren Batch des gesamten Datensatzes und minimiert dann den Verlust darauf.
Dieser Prozess ist effizienter als die beiden obigen Gradientenabstiegsalgorithmen. Jetzt kann die Stapelgröße natürlich beliebig sein.
Aber Forscher haben gezeigt, dass es besser ist, wenn Sie es innerhalb von 1 bis 100 halten, wobei 32 die beste Stapelgröße ist.
Daher wird die Stapelgröße = 32 in den meisten Frameworks standardmäßig beibehalten.
- Schleife bis zur Konvergenz:
- Wählen Sie einen Stapel von ' b ' Datenpunkten aus
- Berechnen Sie den Gradienten über diesen Stapel
- Aktualisieren
- Zurückkehren
Fazit
Jetzt haben Sie das theoretische Verständnis der logistischen Regression. Sie haben gelernt, logistische Funktionen mathematisch darzustellen. Sie wissen, wie man den vorhergesagten Fehler mit der Kostenfunktion misst.
Sie wissen auch, wie Sie diesen Verlust mit dem Gradientenabstiegsalgorithmus minimieren können.
Endlich wissen Sie, welche Variante des Gradientenabstiegsalgorithmus Sie für Ihr Problem wählen sollten. upGrad bietet ein PG-Diplom in maschinellem Lernen und KI und einen Master of Science in maschinellem Lernen und KI , das Sie beim Aufbau einer Karriere unterstützen kann. Diese Kurse erklären die Notwendigkeit des maschinellen Lernens und weitere Schritte zum Sammeln von Wissen in diesem Bereich, die verschiedene Konzepte abdecken, die von Gradientenabstiegsalgorithmen bis hin zu neuronalen Netzwerken reichen.
Was ist ein Gradientenabstiegsalgorithmus?
Der Gradientenabstieg ist ein Optimierungsalgorithmus zum Finden des Minimums einer Funktion. Angenommen, Sie möchten das Minimum einer Funktion f(x) zwischen zwei Punkten (a, b) und (c, d) auf dem Graphen von y = f(x) finden. Dann beinhaltet der Gradientenabstieg drei Schritte: (1) Wähle einen Punkt in der Mitte zwischen zwei Endpunkten, (2) berechne den Gradienten ∇f(x) (3) bewege dich in Richtung entgegengesetzt zum Gradienten, dh von (c, d) nach (a, b). Man kann sich das so vorstellen, dass der Algorithmus die Steigung der Funktion an einem Punkt herausfindet und sich dann in die der Steigung entgegengesetzte Richtung bewegt.
Was ist die Sigmoidfunktion?
Die Sigmoidfunktion oder Sigmoidkurve ist eine Art mathematische Funktion, die nicht linear ist und in ihrer Form dem Buchstaben S (daher der Name) sehr ähnlich ist. Es wird in Operations Research, Statistik und anderen Disziplinen verwendet, um bestimmte Formen von realwertigem Wachstum zu modellieren. Es wird auch in einer Vielzahl von Anwendungen in der Informatik und im Ingenieurwesen eingesetzt, insbesondere in Bereichen im Zusammenhang mit neuronalen Netzen und künstlicher Intelligenz. Sigmoid-Funktionen werden als Teil der Eingaben für Reinforcement-Learning-Algorithmen verwendet, die auf künstlichen neuronalen Netzen basieren.
Was ist der stochastische Gradientenabstiegsalgorithmus?
Der stochastische Gradientenabstieg ist eine der beliebtesten Variationen des klassischen Gradientenabstiegsalgorithmus, um die lokalen Minima der Funktion zu finden. Der Algorithmus wählt zufällig die Richtung aus, in die die Funktion als nächstes gehen wird, um den Wert zu minimieren, und die Richtung wird wiederholt, bis ein lokales Minimum erreicht ist. Das Ziel ist, dass der Algorithmus durch kontinuierliche Wiederholung dieses Prozesses zum globalen oder lokalen Minimum der Funktion konvergiert.