
Front-End-Leistung 2021: Planung und Metriken
Veröffentlicht: 2022-03-10Dieser Leitfaden wurde freundlicherweise von unseren Freunden bei LogRocket unterstützt, einem Dienst, der Frontend-Leistungsüberwachung , Sitzungswiedergabe und Produktanalyse kombiniert, um Ihnen zu helfen, bessere Kundenerlebnisse zu schaffen. LogRocket verfolgt Schlüsselmetriken, inkl. DOM abgeschlossen, Zeit bis zum ersten Byte, erste Eingabeverzögerung, Client-CPU und Speicherauslastung. Holen Sie sich noch heute eine kostenlose Testversion von LogRocket.

Inhaltsverzeichnis
- Vorbereitung: Planung und Metriken
Leistungskultur, Core Web Vitals, Leistungsprofile, CrUX, Lighthouse, FID, TTI, CLS, Geräte. - Realistische Ziele setzen
Leistungsbudgets, Leistungsziele, RAIL-Framework, 170-KB-/30-KB-Budgets. - Die Umgebung definieren
Auswahl eines Frameworks, grundlegende Leistungskosten, Webpack, Abhängigkeiten, CDN, Front-End-Architektur, CSR, SSR, CSR + SSR, statisches Rendering, Pre-Rendering, PRPL-Muster. - Asset-Optimierungen
Brotli, AVIF, WebP, responsive Bilder, AV1, adaptives Laden von Medien, Videokomprimierung, Webfonts, Google-Fonts. - Build-Optimierungen
JavaScript-Module, Modul/Nomodule-Muster, Tree-Shaking, Code-Splitting, Scope-Hoisting, Webpack, Differential Serving, Web Worker, WebAssembly, JavaScript-Bundles, React, SPA, Partial Hydration, Import on Interaction, Drittanbieter, Cache. - Lieferoptimierungen
Lazy Loading, Kreuzungsbeobachter, Aufschieben von Rendering und Decodierung, kritisches CSS, Streaming, Ressourcenhinweise, Layoutverschiebungen, Servicemitarbeiter. - Netzwerk, HTTP/2, HTTP/3
OCSP-Stapling, EV/DV-Zertifikate, Verpackung, IPv6, QUIC, HTTP/3. - Testen und Überwachen
Auditing-Workflow, Proxy-Browser, 404-Seite, DSGVO-Cookie-Zustimmungsaufforderungen, Performance-Diagnose-CSS, Barrierefreiheit. - Schnelle Gewinne
- Alles auf einer Seite
- Checkliste herunterladen (PDF, Apple Pages, MS Word)
- Abonnieren Sie unseren E-Mail-Newsletter, um die nächsten Anleitungen nicht zu verpassen.
Vorbereitung: Planung und Metriken
Mikrooptimierungen eignen sich hervorragend, um die Leistung auf Kurs zu halten, aber es ist entscheidend, klar definierte Ziele im Auge zu haben – messbare Ziele, die alle Entscheidungen beeinflussen, die während des gesamten Prozesses getroffen werden. Es gibt ein paar verschiedene Modelle, und die unten besprochenen sind ziemlich eigensinnig – stellen Sie nur sicher, dass Sie frühzeitig Ihre eigenen Prioritäten setzen.
- Etablieren Sie eine Leistungskultur.
In vielen Organisationen wissen Front-End-Entwickler genau, welche häufigen zugrunde liegenden Probleme auftreten und welche Strategien zu ihrer Behebung angewendet werden sollten. Solange es jedoch keine etablierte Unterstützung der Leistungskultur gibt, wird jede Entscheidung zu einem Schlachtfeld von Abteilungen, das die Organisation in Silos auflöst. Sie benötigen eine Beteiligung von Geschäftsinteressenten, und um diese zu erhalten, müssen Sie eine Fallstudie oder einen Machbarkeitsnachweis darüber erstellen, wie Geschwindigkeit – insbesondere Core Web Vitals , die wir später ausführlich behandeln – Metriken und Key Performance Indicators zugute kommt ( KPIs ), die ihnen wichtig sind.Um beispielsweise die Leistung greifbarer zu machen, könnten Sie die Auswirkungen auf die Umsatzleistung offenlegen, indem Sie die Korrelation zwischen der Conversion-Rate und der Zeit bis zum Laden der Anwendung sowie die Rendering-Leistung anzeigen. Oder die Suchbot-Crawling-Rate (PDF, Seiten 27–50).
Ohne eine starke Abstimmung zwischen Entwicklungs-/Design- und Geschäfts-/Marketingteams wird die Leistung nicht langfristig aufrechterhalten. Untersuchen Sie häufige Beschwerden, die beim Kundendienst und im Verkaufsteam eingehen, untersuchen Sie Analysen für hohe Absprungraten und Conversion-Einbrüche. Erfahren Sie, wie die Verbesserung der Leistung dazu beitragen kann, einige dieser häufigen Probleme zu lindern. Passen Sie die Argumentation an die Gruppe der Stakeholder an, mit denen Sie sprechen.
Führen Sie Leistungsexperimente durch und messen Sie die Ergebnisse – sowohl auf Mobilgeräten als auch auf dem Desktop (z. B. mit Google Analytics). Es hilft Ihnen, eine auf das Unternehmen zugeschnittene Fallstudie mit echten Daten aufzubauen. Darüber hinaus wird die Verwendung von Daten aus Fallstudien und Experimenten, die auf WPO Stats veröffentlicht wurden, dazu beitragen, die Sensibilität für Unternehmen zu erhöhen, warum Leistung wichtig ist und welche Auswirkungen sie auf die Benutzererfahrung und Geschäftskennzahlen hat. Es reicht jedoch nicht aus, zu sagen, dass Leistung allein wichtig ist – Sie müssen auch einige messbare und nachverfolgbare Ziele festlegen und diese im Laufe der Zeit beobachten.
Wie man dorthin kommt? In ihrem Vortrag „Building Performance for the Long Term“ teilt Allison McKnight eine umfassende Fallstudie darüber, wie sie dazu beigetragen hat, eine Performance-Kultur bei Etsy zu etablieren (Folien). In jüngerer Zeit hat Tammy Everts über die Gewohnheiten hocheffektiver Leistungsteams in kleinen und großen Organisationen gesprochen.
Bei diesen Gesprächen in Organisationen ist es wichtig, im Hinterkopf zu behalten, dass die Webleistung eine Verteilung ist, genau wie UX ein Spektrum von Erfahrungen ist. Wie Karolina Szczur feststellte, „ist die Erwartung, dass eine einzige Zahl eine angestrebte Bewertung liefern kann, eine fehlerhafte Annahme.“ Daher müssen Leistungsziele granular, nachvollziehbar und greifbar sein.
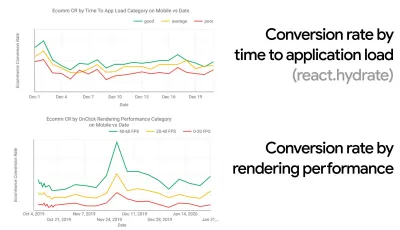
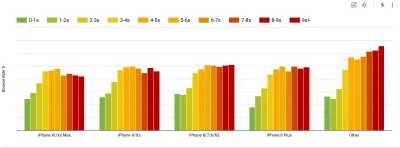
- Ziel: Seien Sie mindestens 20 % schneller als Ihr schnellster Konkurrent.
Laut psychologischer Forschung müssen Sie mindestens 20 % schneller sein, wenn Sie möchten, dass Benutzer das Gefühl haben, dass Ihre Website schneller ist als die Website Ihres Konkurrenten. Untersuchen Sie Ihre Hauptkonkurrenten, sammeln Sie Metriken darüber, wie sie auf Mobilgeräten und Desktops abschneiden, und legen Sie Schwellenwerte fest, die Ihnen helfen würden, sie zu übertreffen. Um jedoch genaue Ergebnisse und Ziele zu erhalten, stellen Sie sicher, dass Sie sich zunächst ein gründliches Bild von der Erfahrung Ihrer Benutzer machen, indem Sie Ihre Analysen studieren. Sie können dann die Erfahrung des 90. Perzentils zum Testen nachahmen.Um einen guten ersten Eindruck davon zu bekommen, wie Ihre Konkurrenten abschneiden, können Sie den Chrome UX Report ( CrUX , ein vorgefertigter RUM-Datensatz, Videoeinführung von Ilya Grigorik und eine ausführliche Anleitung von Rick Viscomi) oder Treo, ein RUM-Überwachungstool, verwenden wird von Chrome UX Report unterstützt. Die Daten werden von den Chrome-Browser-Benutzern gesammelt, daher sind die Berichte Chrome-spezifisch, aber sie geben Ihnen eine ziemlich gründliche Verteilung der Leistung, vor allem der Core Web Vitals-Ergebnisse, über ein breites Spektrum Ihrer Besucher. Beachten Sie, dass neue CrUX-Datensätze am zweiten Dienstag jedes Monats veröffentlicht werden.
Alternativ können Sie auch verwenden:
- Chrome UX Report Compare Tool von Addy Osmani,
- Speed Scorecard (bietet auch einen Schätzer für die Auswirkungen auf den Umsatz),
- Real User Experience Testvergleich bzw
- SiteSpeed CI (basierend auf synthetischen Tests).
Hinweis : Wenn Sie Page Speed Insights oder Page Speed Insights API verwenden (nein, es ist nicht veraltet!), können Sie CrUX-Leistungsdaten für bestimmte Seiten anstelle nur der Aggregate abrufen. Diese Daten können viel nützlicher sein, um Leistungsziele für Assets wie „Zielseite“ oder „Produktliste“ festzulegen. Und wenn Sie CI zum Testen der Budgets verwenden, müssen Sie sicherstellen, dass Ihre getestete Umgebung mit CrUX übereinstimmt, wenn Sie CrUX zum Festlegen des Ziels verwendet haben ( danke Patrick Meenan! ).
Wenn Sie Hilfe benötigen, um die Gründe für die Priorisierung der Geschwindigkeit aufzuzeigen, oder wenn Sie den Rückgang der Conversion-Rate oder die Erhöhung der Absprungrate bei geringerer Leistung visualisieren möchten, oder vielleicht müssen Sie sich für eine RUM-Lösung in Ihrer Organisation einsetzen, Sergey Chernyshev hat einen UX-Geschwindigkeitsrechner entwickelt, ein Open-Source-Tool, mit dem Sie Daten simulieren und visualisieren können, um Ihren Standpunkt zu verdeutlichen.
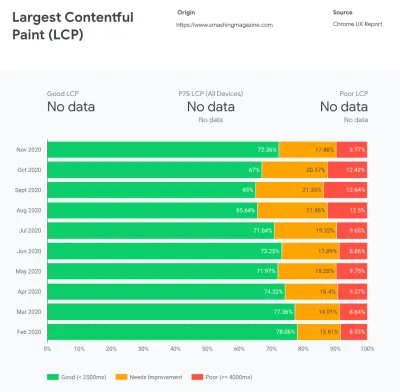
CrUX generiert einen Überblick über die Leistungsverteilung im Laufe der Zeit, wobei der Datenverkehr von Google Chrome-Benutzern erfasst wird. Sie können Ihre eigenen im Chrome UX Dashboard erstellen. (Große Vorschau) 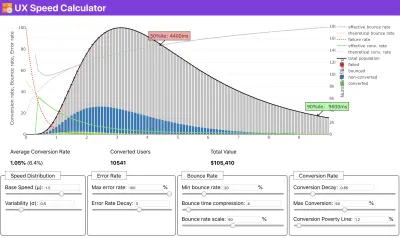
Gerade wenn Sie für Leistung plädieren müssen, um Ihren Standpunkt zu verdeutlichen: UX Speed Calculator visualisiert die Auswirkungen der Leistung auf Absprungraten, Konversion und Gesamtumsatz – basierend auf echten Daten. (Große Vorschau) Manchmal möchten Sie vielleicht etwas tiefer gehen und die Daten aus CrUX mit anderen Daten kombinieren, die Sie bereits haben, um schnell herauszufinden, wo die Verlangsamungen, blinden Flecken und Ineffizienzen liegen – für Ihre Konkurrenten oder für Ihr Projekt. Bei seiner Arbeit hat Harry Roberts eine Site-Speed-Topographie-Tabelle verwendet, mit der er die Leistung nach Schlüsselseitentypen aufschlüsselt und verfolgt, wie unterschiedlich die Schlüsselmetriken auf ihnen sind. Sie können die Tabelle als Google Sheets, Excel, OpenOffice-Dokument oder CSV herunterladen.
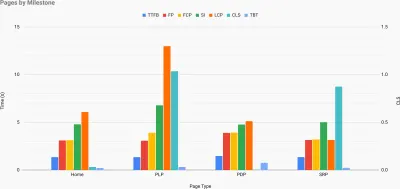
Topografie der Site-Geschwindigkeit, mit Schlüsselmetriken, die für Schlüsselseiten auf der Site dargestellt werden. (Große Vorschau) Und wenn Sie den ganzen Weg gehen wollen, können Sie auf jeder Seite einer Website (über Lightouse Parade) eine Lighthouse-Leistungsprüfung durchführen, wobei die Ausgabe als CSV gespeichert wird. Auf diese Weise können Sie feststellen, welche spezifischen Seiten (oder Arten von Seiten) Ihrer Mitbewerber schlechter oder besser abschneiden und worauf Sie Ihre Bemühungen konzentrieren sollten. (Für Ihre eigene Website ist es jedoch wahrscheinlich besser, Daten an einen Analyseendpunkt zu senden!).

Mit Lighthouse Parade können Sie auf jeder Seite einer Website eine Lighthouse-Leistungsprüfung durchführen, wobei die Ausgabe als CSV gespeichert wird. (Große Vorschau) Sammeln Sie Daten, erstellen Sie eine Tabelle, sparen Sie 20 % und legen Sie Ihre Ziele ( Leistungsbudgets ) auf diese Weise fest. Jetzt haben Sie etwas Messbares zum Testen. Wenn Sie das Budget im Auge behalten und versuchen, nur die minimale Nutzlast herunterzuladen, um eine schnelle Interaktivitätszeit zu erreichen, dann sind Sie auf einem vernünftigen Weg.
Benötigen Sie Ressourcen, um loszulegen?
- Addy Osmani hat einen sehr detaillierten Artikel darüber geschrieben, wie man mit der Leistungsbudgetierung beginnt, wie man die Auswirkungen neuer Funktionen quantifiziert und wo man anfängt, wenn das Budget überschritten wird.
- Der Leitfaden von Lara Hogan zur Herangehensweise an Designs mit einem Leistungsbudget kann Designern hilfreiche Hinweise geben.
- Harry Roberts hat einen Leitfaden zum Einrichten eines Google-Tabellenblatts veröffentlicht, um die Auswirkungen von Skripten von Drittanbietern auf die Leistung mithilfe von Request Map anzuzeigen.
- Jonathan Fieldings Performance Budget Calculator, Katie Hempenius' perf-budget-calculator und Browser Calories können beim Erstellen von Budgets helfen (danke an Karolina Szczur für die Hinweise).
- Performance-Budgets sollten in vielen Unternehmen nicht ehrgeizig, sondern pragmatisch sein und als Haltezeichen dienen, um ein bestimmtes Maß nicht zu überschreiten. In diesem Fall könnten Sie Ihren schlechtesten Datenpunkt in den letzten zwei Wochen als Schwellenwert auswählen und von dort aus weitermachen. Leistungsbudgets, Pragmatisch zeigt Ihnen eine Strategie, um dies zu erreichen.
- Machen Sie außerdem sowohl das Leistungsbudget als auch die aktuelle Leistung sichtbar , indem Sie Dashboards mit Diagrammen einrichten, die die Build-Größen melden. Es gibt viele Tools, mit denen Sie dies erreichen können: Das SiteSpeed.io-Dashboard (Open Source), SpeedCurve und Calibre sind nur einige davon, und Sie finden weitere Tools auf perf.rocks.

Browser-Kalorien helfen Ihnen, ein Leistungsbudget festzulegen und zu messen, ob eine Seite diese Zahlen überschreitet oder nicht. (Große Vorschau) Sobald Sie ein Budget festgelegt haben, integrieren Sie es mit Webpack Performance Hints und Bundlesize, Lighthouse CI, PWMetrics oder Sitespeed CI in Ihren Build-Prozess, um Budgets für Pull-Requests durchzusetzen und einen Bewertungsverlauf in PR-Kommentaren bereitzustellen.
Um Leistungsbudgets dem gesamten Team zugänglich zu machen, integrieren Sie Leistungsbudgets in Lighthouse über Lightwallet oder verwenden Sie LHCI Action für eine schnelle Integration von Github Actions. Und wenn Sie etwas Benutzerdefiniertes benötigen, können Sie webpagetest-charts-api verwenden, eine API von Endpunkten, um Diagramme aus WebPagetest-Ergebnissen zu erstellen.
Leistungsbewusstsein sollte jedoch nicht allein aus Leistungsbudgets resultieren. Genau wie bei Pinterest könnten Sie eine benutzerdefinierte Eslint- Regel erstellen, die den Import aus Dateien und Verzeichnissen verbietet, die bekanntermaßen abhängigkeitsintensiv sind und das Bundle aufblähen würden. Richten Sie eine Liste „sicherer“ Pakete ein, die im gesamten Team geteilt werden kann.
Denken Sie auch an kritische Kundenaufgaben, die für Ihr Unternehmen am vorteilhaftesten sind. Untersuchen, diskutieren und definieren Sie akzeptable Zeitschwellen für kritische Aktionen und legen Sie „UX-fähige“ Benutzerzeitmarken fest, die von der gesamten Organisation genehmigt wurden. In vielen Fällen berühren User Journeys die Arbeit vieler verschiedener Abteilungen, sodass die Abstimmung in Bezug auf akzeptable Zeitpläne dazu beitragen kann, spätere Leistungsdiskussionen zu unterstützen oder zu verhindern. Stellen Sie sicher, dass zusätzliche Kosten für zusätzliche Ressourcen und Funktionen sichtbar und verständlich sind.
Richten Sie Leistungsbemühungen mit anderen Technologieinitiativen aus, die von neuen Funktionen des zu erstellenden Produkts über Refactoring bis hin zum Erreichen neuer globaler Zielgruppen reichen. Jedes Mal, wenn ein Gespräch über die Weiterentwicklung stattfindet, ist auch die Leistung ein Teil dieses Gesprächs. Es ist viel einfacher, Leistungsziele zu erreichen, wenn die Codebasis frisch ist oder gerade umgestaltet wird.
Wie Patrick Meenan vorgeschlagen hat, lohnt es sich außerdem, während des Designprozesses eine Ladesequenz und Kompromisse zu planen . Wenn Sie frühzeitig priorisieren, welche Teile kritischer sind, und die Reihenfolge festlegen, in der sie erscheinen sollen, wissen Sie auch, was sich verzögern kann. Idealerweise spiegelt diese Reihenfolge auch die Reihenfolge Ihrer CSS- und JavaScript-Importe wider, sodass die Handhabung während des Build-Prozesses einfacher wird. Überlegen Sie auch, wie das visuelle Erlebnis in „Zwischen“-Zuständen sein sollte, während die Seite geladen wird (z. B. wenn Webfonts noch nicht geladen sind).
Sobald Sie eine starke Leistungskultur in Ihrem Unternehmen etabliert haben, streben Sie danach, 20 % schneller zu sein als Ihr früheres Ich , um die Prioritäten im Laufe der Zeit im Takt zu halten ( Danke, Guy Podjarny! ). Berücksichtigen Sie jedoch die unterschiedlichen Typen und Nutzungsverhalten Ihrer Kunden (die Tobias Baldauf Kadenz und Kohorten nannte), zusammen mit Bot-Traffic und saisonalen Effekten.
Planen, planen, planen. Es mag verlockend sein, früh in einige schnelle „Low-Hanging-Fruits“-Optimierungen einzusteigen – und es könnte eine gute Strategie für schnelle Erfolge sein – aber es wird sehr schwierig sein, die Leistung als Priorität zu betrachten, ohne zu planen und realistische Unternehmen zu setzen -maßgeschneiderte Leistungsziele.
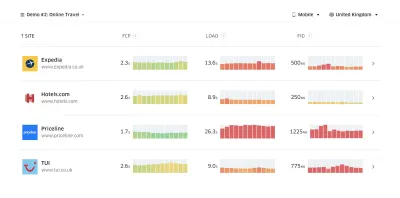
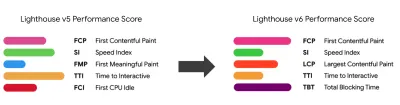
- Wählen Sie die richtigen Metriken.
Nicht alle Kennzahlen sind gleich wichtig. Untersuchen Sie, welche Metriken für Ihre Anwendung am wichtigsten sind: Normalerweise wird sie dadurch definiert, wie schnell Sie mit dem Rendern der wichtigsten Pixel Ihrer Benutzeroberfläche beginnen können und wie schnell Sie für diese gerenderten Pixel eine Eingabereaktionsfähigkeit bereitstellen können. Dieses Wissen gibt Ihnen das beste Optimierungsziel für die laufenden Bemühungen. Letztendlich sind es nicht die Lastereignisse oder Serverreaktionszeiten, die das Erlebnis bestimmen, sondern die Wahrnehmung, wie schnell sich die Benutzeroberfläche anfühlt .Was heißt das? Anstatt sich auf die Ladezeit der gesamten Seite zu konzentrieren (z. B. über onLoad- und DOMContentLoaded- Timings), priorisieren Sie das Laden von Seiten so, wie es von Ihren Kunden wahrgenommen wird. Das bedeutet, sich auf einen etwas anderen Satz von Metriken zu konzentrieren. Tatsächlich ist die Auswahl der richtigen Metrik ein Prozess ohne offensichtliche Gewinner.
Basierend auf den Recherchen von Tim Kadlec und den Anmerkungen von Marcos Iglesias in seinem Vortrag könnten traditionelle Metriken in einige Gruppen eingeteilt werden. Normalerweise benötigen wir alle, um uns ein vollständiges Bild von der Leistung zu machen, und in Ihrem speziellen Fall sind einige von ihnen wichtiger als andere.
- Mengenbasierte Metriken messen die Anzahl der Anfragen, das Gewicht und einen Leistungswert. Gut zum Auslösen von Alarmen und Überwachen von Änderungen im Laufe der Zeit, nicht so gut zum Verständnis der Benutzererfahrung.
- Milestone-Metriken verwenden Zustände in der Lebensdauer des Ladeprozesses, z. B. Time To First Byte und Time To Interactive . Gut, um die Benutzererfahrung und Überwachung zu beschreiben, nicht so gut, um zu wissen, was zwischen den Meilensteinen passiert.
- Rendering-Metriken liefern eine Schätzung, wie schnell Inhalte gerendert werden (z. B. Render-Startzeit , Geschwindigkeitsindex ). Gut zum Messen und Optimieren der Renderleistung, aber nicht so gut zum Messen, wann wichtige Inhalte angezeigt werden und mit denen interagiert werden kann.
- Benutzerdefinierte Metriken messen ein bestimmtes, benutzerdefiniertes Ereignis für den Benutzer, z. B. Twitters Zeit bis zum ersten Tweet und Pinterests PinnerWaitTime. Gut um das Nutzererlebnis genau zu beschreiben, weniger gut um die Metriken zu skalieren und mit Mitbewerbern zu vergleichen.
Um das Bild zu vervollständigen, würden wir normalerweise bei all diesen Gruppen nach nützlichen Metriken Ausschau halten. Normalerweise sind die spezifischsten und relevantesten:
- Zeit bis zur Interaktivität (TTI)
Der Punkt, an dem sich das Layout stabilisiert hat, wichtige Webfonts sichtbar sind und der Haupt-Thread ausreichend verfügbar ist, um Benutzereingaben zu verarbeiten – im Grunde die Zeitmarke, an der ein Benutzer mit der Benutzeroberfläche interagieren kann. Die Schlüsselmetriken, um zu verstehen, wie lange ein Benutzer warten muss, um die Website ohne Verzögerung zu nutzen. Boris Schapira hat einen ausführlichen Beitrag darüber geschrieben, wie man TTI zuverlässig misst. - First Input Delay (FID) oder Eingangsreaktion
Die Zeit von der ersten Interaktion eines Benutzers mit Ihrer Website bis zu dem Zeitpunkt, an dem der Browser tatsächlich in der Lage ist, auf diese Interaktion zu reagieren . Ergänzt TTI sehr gut, da es den fehlenden Teil des Bildes beschreibt: was passiert, wenn ein Benutzer tatsächlich mit der Website interagiert. Nur als RUM-Metrik gedacht. Es gibt eine JavaScript-Bibliothek zum Messen von FID im Browser. - Größte zufriedene Farbe (LCP)
Markiert den Punkt in der Ladezeitachse der Seite, an dem der wichtige Inhalt der Seite wahrscheinlich geladen wurde. Die Annahme ist, dass das wichtigste Element der Seite das größte ist, das im Darstellungsbereich des Benutzers sichtbar ist. Wenn Elemente sowohl über als auch unter der Falte gerendert werden, wird nur der sichtbare Teil als relevant angesehen. - Gesamtsperrzeit ( TBT )
Eine Metrik, die dabei hilft, den Schweregrad zu quantifizieren, wie nicht interaktiv eine Seite ist , bevor sie zuverlässig interaktiv wird (das heißt, der Haupt-Thread war mindestens 5 Sekunden lang frei von Aufgaben, die länger als 50 ms ( lange Aufgaben ) ausgeführt wurden). Die Metrik misst die Gesamtzeit zwischen dem ersten Malen und der Time to Interactive (TTI), bei der der Hauptthread lange genug blockiert war, um eine Eingabereaktion zu verhindern. Kein Wunder also, dass eine niedrige TBT ein guter Indikator für gute Leistung ist. (Danke, Artem, Phil) - Kumulative Layoutverschiebung ( CLS )
Die Metrik hebt hervor, wie oft Benutzer beim Zugriff auf die Website unerwartete Layoutverschiebungen ( Reflows ) erleben. Es untersucht instabile Elemente und ihre Auswirkungen auf das Gesamterlebnis. Je niedriger die Punktzahl, desto besser. - Geschwindigkeitsindex
Misst, wie schnell der Seiteninhalt visuell ausgefüllt wird; Je niedriger die Punktzahl, desto besser. Der Geschwindigkeitsindexwert wird basierend auf der Geschwindigkeit des visuellen Fortschritts berechnet, ist jedoch lediglich ein berechneter Wert. Es reagiert auch empfindlich auf die Größe des Darstellungsbereichs, sodass Sie eine Reihe von Testkonfigurationen definieren müssen, die zu Ihrer Zielgruppe passen. Beachten Sie, dass es weniger wichtig wird, da LCP zu einer relevanteren Metrik wird ( Danke, Boris, Artem! ). - Aufgewandte CPU-Zeit
Eine Metrik, die zeigt, wie oft und wie lange der Haupt-Thread blockiert ist und an Malen, Rendern, Skripten und Laden arbeitet. Eine hohe CPU-Zeit ist ein klarer Indikator für ein fehlerhaftes Erlebnis, dh wenn der Benutzer eine merkliche Verzögerung zwischen seiner Aktion und einer Antwort erlebt. Mit WebPageTest können Sie auf der Registerkarte „Chrome“ die Option „Capture Dev Tools Timeline“ auswählen, um die Aufschlüsselung des Hauptthreads anzuzeigen, während er auf jedem Gerät mit WebPageTest ausgeführt wird. - CPU-Kosten auf Komponentenebene
Genau wie bei der aufgewendeten CPU-Zeit untersucht diese von Stoyan Stefanov vorgeschlagene Metrik die Auswirkungen von JavaScript auf die CPU . Die Idee ist, die Anzahl der CPU-Befehle pro Komponente zu verwenden, um ihre Auswirkungen auf das Gesamterlebnis isoliert zu verstehen. Könnte mit Puppeteer und Chrome implementiert werden. - Frustindex
Während viele der oben aufgeführten Metriken erklären, wann ein bestimmtes Ereignis eintritt, betrachtet der FrustrationIndex von Tim Vereecke die Lücken zwischen den Metriken, anstatt sie einzeln zu betrachten. Es betrachtet die wichtigsten Meilensteine, die vom Endbenutzer wahrgenommen werden, wie z. B. „Titel ist sichtbar“, „Erster Inhalt ist sichtbar“, „Visuell fertig“ und „Seite sieht fertig aus“, und berechnet eine Punktzahl, die den Grad der Frustration beim Laden einer Seite angibt. Je größer die Lücke, desto größer die Wahrscheinlichkeit, dass ein Benutzer frustriert wird. Potenziell ein guter KPI für die Benutzererfahrung. Tim hat einen ausführlichen Beitrag über FrustrationIndex und seine Funktionsweise veröffentlicht. - Auswirkungen auf die Anzeigengewichtung
Wenn Ihre Website von Werbeeinnahmen abhängt, ist es hilfreich, die Gewichtung des werbebezogenen Codes zu verfolgen. Das Skript von Paddy Ganti konstruiert zwei URLs (eine normale und eine, die die Werbung blockiert), veranlasst die Generierung eines Videovergleichs über WebPageTest und meldet ein Delta. - Abweichungsmetriken
Wie von Wikipedia-Ingenieuren angemerkt, können Daten darüber, wie viel Varianz in Ihren Ergebnissen vorhanden ist, Sie darüber informieren, wie zuverlässig Ihre Instrumente sind und wie viel Aufmerksamkeit Sie Abweichungen und Ausreißern schenken sollten. Eine große Varianz ist ein Indikator für erforderliche Anpassungen im Setup. Es hilft auch zu verstehen, ob bestimmte Seiten schwieriger zuverlässig zu messen sind, z. B. aufgrund von Skripten von Drittanbietern, die erhebliche Abweichungen verursachen. Es kann auch eine gute Idee sein, die Browserversion zu verfolgen, um Leistungseinbußen zu verstehen, wenn eine neue Browserversion eingeführt wird. - Benutzerdefinierte Metriken
Benutzerdefinierte Metriken werden durch Ihre Geschäftsanforderungen und das Kundenerlebnis definiert. Sie müssen wichtige Pixel, kritische Skripte, notwendiges CSS und relevante Assets identifizieren und messen, wie schnell sie dem Benutzer bereitgestellt werden. Dafür können Sie Hero Rendering Times überwachen oder die Performance API verwenden, um bestimmte Zeitstempel für Ereignisse zu markieren, die für Ihr Unternehmen wichtig sind. Außerdem können Sie mit WebPagetest benutzerdefinierte Metriken sammeln, indem Sie am Ende eines Tests beliebiges JavaScript ausführen.
Beachten Sie, dass der First Meaningful Paint (FMP) nicht in der obigen Übersicht erscheint. Früher gab es einen Einblick, wie schnell der Server Daten ausgibt. Langes FMP deutete normalerweise darauf hin, dass JavaScript den Haupt-Thread blockiert, könnte aber auch mit Back-End-/Server-Problemen zusammenhängen. Die Metrik wurde jedoch kürzlich verworfen, da sie in etwa 20 % der Fälle nicht genau zu sein scheint. Es wurde effektiv durch LCP ersetzt, das sowohl zuverlässiger als auch einfacher zu begründen ist. Es wird in Lighthouse nicht mehr unterstützt. Überprüfen Sie die neuesten benutzerorientierten Leistungsmetriken und Empfehlungen, um sicherzustellen, dass Sie auf der sicheren Seite sind ( Danke, Patrick Meenan ).

Steve Souders hat eine detaillierte Erklärung vieler dieser Metriken. Es ist wichtig zu beachten, dass die Zeit bis zur Interaktion zwar durch die Ausführung automatisierter Audits in der sogenannten Laborumgebung gemessen wird, die Verzögerung der ersten Eingabe jedoch die tatsächliche Benutzererfahrung darstellt, wobei tatsächliche Benutzer eine merkliche Verzögerung erfahren. Im Allgemeinen ist es wahrscheinlich eine gute Idee, immer beide zu messen und zu verfolgen.
Abhängig vom Kontext Ihrer Anwendung können sich die bevorzugten Metriken unterscheiden: Beispielsweise sind für die Benutzeroberfläche von Netflix TV die Reaktionsfähigkeit auf Tasteneingaben, die Speichernutzung und TTI kritischer, und für Wikipedia sind erste/letzte visuelle Änderungen und die Metriken für verbrauchte CPU-Zeit wichtiger.
Hinweis : Sowohl FID als auch TTI berücksichtigen das Scrollverhalten nicht; Das Scrollen kann unabhängig voneinander erfolgen, da es sich um einen Off-Main-Thread handelt, sodass diese Metriken für viele Websites, die Inhalte konsumieren, möglicherweise viel weniger wichtig sind ( Danke, Patrick! ).
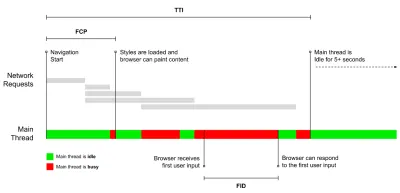
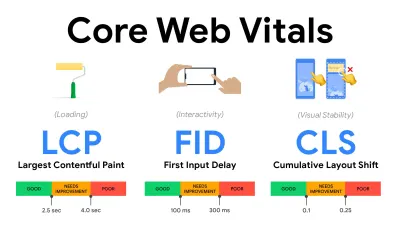
- Messen und optimieren Sie die Core Web Vitals .
Lange Zeit waren Leistungsmetriken recht technisch und konzentrierten sich auf die technische Sichtweise darauf, wie schnell Server reagieren und wie schnell Browser laden. Die Metriken haben sich im Laufe der Jahre geändert – es wurde versucht, einen Weg zu finden, die tatsächliche Benutzererfahrung zu erfassen, anstatt Server-Timings. Im Mai 2020 hat Google Core Web Vitals angekündigt, eine Reihe neuer nutzerorientierter Leistungskennzahlen, die jeweils eine bestimmte Facette der Nutzererfahrung darstellen.Für jeden von ihnen empfiehlt Google eine Reihe akzeptabler Geschwindigkeitsziele. Mindestens 75 % aller Seitenaufrufe sollten den Bereich „Gut“ überschreiten, um diese Bewertung zu bestehen. Diese Metriken gewannen schnell an Bedeutung, und da Core Web Vitals im Mai 2021 zu Ranking-Signalen für die Google-Suche wurden ( Aktualisierung des Page Experience-Ranking-Algorithmus ), haben viele Unternehmen ihre Aufmerksamkeit auf ihre Leistungswerte gerichtet.
Lassen Sie uns jeden der Core Web Vitals einzeln aufschlüsseln, zusammen mit nützlichen Techniken und Tools , um Ihre Erfahrungen mit diesen Metriken im Hinterkopf zu optimieren. (Es ist erwähnenswert, dass Sie am Ende bessere Core Web Vitals-Ergebnisse erhalten, wenn Sie einem allgemeinen Rat in diesem Artikel folgen.)
- Largest Contentful Paint ( LCP ) < 2,5 Sek.
Misst das Laden einer Seite und meldet die Renderzeit des größten Bild- oder Textblocks , der im Darstellungsbereich sichtbar ist. Daher ist LCP von allem betroffen, was das Rendern wichtiger Informationen verzögert – seien es langsame Serverantwortzeiten, blockierendes CSS, In-Flight-JavaScript (Erstanbieter oder Drittanbieter), Laden von Webschriften, teure Rendering- oder Malvorgänge, Faulheit -geladene Bilder, Skelettbildschirme oder clientseitiges Rendering.
Für eine gute Erfahrung sollte LCP innerhalb von 2,5 Sekunden nach dem ersten Laden der Seite erfolgen. Das bedeutet, dass wir den ersten sichtbaren Teil der Seite so früh wie möglich rendern müssen. Das erfordert maßgeschneidertes kritisches CSS für jede Vorlage, das Orchestrieren der<head>-Reihenfolge und das Vorabrufen kritischer Assets (wir werden sie später behandeln).Der Hauptgrund für einen niedrigen LCP-Score sind in der Regel Bilder. Ein LCP in <2,5 s auf Fast 3G bereitzustellen – gehostet auf einem gut optimierten Server, alles statisch ohne clientseitiges Rendering und mit einem Bild, das von einem dedizierten Bild-CDN kommt – bedeutet, dass die maximale theoretische Bildgröße nur etwa 144 KB beträgt . Aus diesem Grund sind reaktionsschnelle Bilder ebenso wichtig wie das frühzeitige Vorladen kritischer Bilder (mit
preload).Kurzer Tipp : Um herauszufinden, was auf einer Seite als LCP gilt, können Sie in DevTools den Mauszeiger über das LCP-Badge unter „Timings“ im Performance Panel bewegen ( Danke, Tim Kadlec !).
- Erste Eingangsverzögerung ( FID ) < 100 ms.
Misst die Reaktionsfähigkeit der Benutzeroberfläche, dh wie lange der Browser mit anderen Aufgaben beschäftigt war , bevor er auf ein diskretes Benutzereingabeereignis wie Tippen oder Klicken reagieren konnte. Es wurde entwickelt, um Verzögerungen zu erfassen, die dadurch entstehen, dass der Haupt-Thread ausgelastet ist, insbesondere während des Ladens der Seite.
Das Ziel ist es, bei jeder Interaktion innerhalb von 50–100 ms zu bleiben. Um dorthin zu gelangen, müssen wir lange Aufgaben identifizieren (blockiert den Haupt-Thread für > 50 ms) und sie aufteilen, ein Bündel durch Code in mehrere Teile aufteilen, die JavaScript-Ausführungszeit reduzieren, den Datenabruf optimieren und die Skriptausführung von Drittanbietern verschieben , verschieben Sie JavaScript in den Hintergrund-Thread mit Web-Workern und verwenden Sie die progressive Hydratation, um die Rehydrierungskosten in SPAs zu reduzieren.Kurzer Tipp : Im Allgemeinen besteht eine zuverlässige Strategie zum Erzielen eines besseren FID-Scores darin , die Arbeit am Hauptthread zu minimieren, indem größere Bundles in kleinere aufgeteilt werden und das bereitgestellt wird, was der Benutzer benötigt, wenn er es benötigt, sodass Benutzerinteraktionen nicht verzögert werden . Wir werden weiter unten im Detail darauf eingehen.
- Kumulative Layoutverschiebung ( CLS ) < 0,1.
Misst die visuelle Stabilität der Benutzeroberfläche, um reibungslose und natürliche Interaktionen zu gewährleisten, dh die Gesamtsumme aller individuellen Layout-Verschiebungen für jede unerwartete Layout-Verschiebung, die während der Lebensdauer der Seite auftritt. Eine individuelle Layoutverschiebung tritt immer dann auf, wenn ein bereits sichtbares Element seine Position auf der Seite verändert. Es wird basierend auf der Größe des Inhalts und der Entfernung, die es bewegt hat, bewertet.
Also jedes Mal, wenn eine Verschiebung auftritt – z. B. wenn Fallback-Fonts und Web-Fonts unterschiedliche Font-Metriken haben oder Anzeigen, Einbettungen oder Iframes spät eintreffen oder Bild-/Videodimensionen nicht reserviert sind oder spätes CSS Neuzeichnungen erzwingt oder Änderungen von eingefügt werden spätes JavaScript – es wirkt sich auf den CLS-Score aus. Der empfohlene Wert für ein gutes Erlebnis ist ein CLS < 0,1.
Es ist erwähnenswert, dass sich Core Web Vitals im Laufe der Zeit mit einem vorhersehbaren jährlichen Zyklus weiterentwickeln sollen . Für das Update im ersten Jahr erwarten wir möglicherweise, dass First Contentful Paint zu Core Web Vitals befördert wird, einen niedrigeren FID-Schwellenwert und eine bessere Unterstützung für Single-Page-Anwendungen. Wir könnten auch sehen, dass die Reaktion auf Benutzereingaben nach der Last mehr Gewicht gewinnt, zusammen mit Überlegungen zu Sicherheit, Datenschutz und Zugänglichkeit (!).
Im Zusammenhang mit Core Web Vitals gibt es viele nützliche Ressourcen und Artikel, die einen Blick wert sind:
- Mit dem Web Vitals Leaderboard können Sie Ihre Punktzahlen mit der Konkurrenz auf Mobilgeräten, Tablets, Desktops sowie über 3G und 4G vergleichen.
- Core SERP Vitals, eine Chrome-Erweiterung, die die Core Web Vitals von CrUX in den Google-Suchergebnissen anzeigt.
- Layout Shift GIF Generator, der CLS mit einem einfachen GIF visualisiert (auch über die Befehlszeile verfügbar).
- Die Web-Vitals-Bibliothek kann Core Web Vitals sammeln und an Google Analytics, Google Tag Manager oder einen anderen Analyse-Endpunkt senden.
- Analyse von Web Vitals mit WebPageTest, in der Patrick Meenan untersucht, wie WebPageTest Daten über Core Web Vitals offenlegt.
- Optimizing with Core Web Vitals, ein 50-minütiges Video mit Addy Osmani, in dem er in einer E-Commerce-Fallstudie aufzeigt, wie Core Web Vitals verbessert werden kann.
- Cumulative Layout Shift in Practice und Cumulative Layout Shift in the Real World sind umfassende Artikel von Nic Jansma, die so ziemlich alles über CLS abdecken und wie es mit Schlüsselkennzahlen wie Bounce Rate, Session Time oder Rage Clicks korreliert.
- What Forces Reflow, mit einem Überblick über Eigenschaften oder Methoden, wenn sie in JavaScript angefordert/aufgerufen werden, die den Browser dazu veranlassen, den Stil und das Layout synchron zu berechnen.
- CSS-Trigger zeigt, welche CSS-Eigenschaften Layout, Paint und Composite auslösen.
- Layout-Instabilität beheben ist eine exemplarische Vorgehensweise zur Verwendung von WebPageTest zum Identifizieren und Beheben von Layout-Instabilitätsproblemen.
- Cumulative Layout Shift, The Layout Instability Metric, ein weiterer sehr detaillierter Leitfaden von Boris Schapira über CLS, wie es berechnet wird, wie man es misst und wie man es optimiert.
- How To Improve Core Web Vitals, ein detaillierter Leitfaden von Simon Hearne zu jeder der Metriken (einschließlich anderer Web Vitals wie FCP, TTI, TBT), wann sie auftreten und wie sie gemessen werden.
Sind Core Web Vitals also die ultimativen Metriken, denen man folgen sollte ? Nicht ganz. Sie sind in der Tat bereits in den meisten RUM-Lösungen und -Plattformen verfügbar, darunter Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in der Filmstreifenansicht bereits), Newrelic, Shopify, Next.js, alle Google-Tools (PageSpeed Insights, Lighthouse + CI, Search Konsole usw.) und viele andere.
Wie Katie Sylor-Miller erklärt, sind einige der Hauptprobleme mit Core Web Vitals jedoch der Mangel an browserübergreifender Unterstützung, wir messen nicht wirklich den gesamten Lebenszyklus der Benutzererfahrung, außerdem ist es schwierig, Änderungen in FID und zu korrelieren CLS mit Geschäftsergebnissen.
Da wir davon ausgehen sollten, dass sich Core Web Vitals weiterentwickeln wird, erscheint es nur vernünftig, Web Vitals immer mit Ihren maßgeschneiderten Metriken zu kombinieren , um besser zu verstehen, wo Sie in Bezug auf die Leistung stehen.
- Largest Contentful Paint ( LCP ) < 2,5 Sek.
- Sammeln Sie Daten auf einem für Ihre Zielgruppe repräsentativen Gerät.
Um genaue Daten zu sammeln, müssen wir die Geräte zum Testen sorgfältig auswählen. In den meisten Unternehmen bedeutet dies, sich mit Analysen zu befassen und Benutzerprofile basierend auf den gängigsten Gerätetypen zu erstellen. Analysen allein liefern jedoch oft kein vollständiges Bild. Ein erheblicher Teil der Zielgruppe verlässt die Website möglicherweise (und kehrt nicht zurück), nur weil ihre Erfahrung zu langsam ist, und ihre Geräte werden aus diesem Grund wahrscheinlich nicht als die beliebtesten Geräte in Analysen angezeigt. Es kann also eine gute Idee sein, zusätzlich zu gängigen Geräten in Ihrer Zielgruppe zu recherchieren.Laut IDC sind im Jahr 2020 weltweit 84,8 % aller ausgelieferten Mobiltelefone Android-Geräte. Ein durchschnittlicher Verbraucher rüstet sein Telefon alle 2 Jahre auf, und in den USA beträgt der Austauschzyklus für Telefone 33 Monate. Die durchschnittlichen Bestseller-Telefone auf der ganzen Welt kosten weniger als 200 US-Dollar.
Ein repräsentatives Gerät ist also ein Android-Gerät, das mindestens 24 Monate alt ist, 200 US-Dollar oder weniger kostet und mit langsamem 3G, 400 ms RTT und 400 kbps Übertragung läuft, um nur etwas pessimistischer zu sein. Dies kann für Ihr Unternehmen natürlich ganz anders sein, aber das ist eine ziemlich gute Annäherung an die Mehrheit der Kunden da draußen. Tatsächlich könnte es eine gute Idee sein, sich die aktuellen Amazon-Bestseller für Ihren Zielmarkt anzusehen. ( Danke an Tim Kadlec, Henri Helvetica und Alex Russell für die Hinweise! ).
Überprüfen Sie beim Erstellen einer neuen Website oder App immer zuerst die aktuellen Amazon-Bestseller für Ihren Zielmarkt. (Große Vorschau) Welche Testgeräte wählen Sie dann? Diejenigen, die gut zu dem oben skizzierten Profil passen. Es ist eine gute Option, ein etwas älteres Moto G4/G5 Plus, ein Samsung-Mittelklassegerät (Galaxy A50, S8), ein gutes Mittelklassegerät wie ein Nexus 5X, ein Xiaomi Mi A3 oder ein Xiaomi Redmi Note zu wählen 7 und ein langsames Gerät wie Alcatel 1X oder Cubot X19, vielleicht in einem offenen Gerätelabor. Zum Testen auf langsameren thermisch gedrosselten Geräten können Sie auch ein Nexus 4 erwerben, das nur etwa 100 US-Dollar kostet.
Überprüfen Sie auch die in jedem Gerät verwendeten Chipsätze und stellen Sie einen Chipsatz nicht überrepräsentiert dar : Ein paar Generationen von Snapdragon und Apple sowie Low-End-Rockchip, Mediatek würden ausreichen (danke, Patrick!) .
Wenn Sie kein Gerät zur Hand haben, emulieren Sie das mobile Erlebnis auf dem Desktop, indem Sie es in einem gedrosselten 3G-Netzwerk (z. B. 300 ms RTT, 1,6 Mbps down, 0,8 Mbps up) mit einer gedrosselten CPU (5-fache Verlangsamung) testen. Wechseln Sie schließlich zu normalem 3G, langsamem 4G (z. B. 170 ms RTT, 9 Mbit/s Down, 9 Mbit/s Up) und Wi-Fi. Um die Auswirkungen auf die Leistung sichtbarer zu machen, könnten Sie sogar dienstags 2G einführen oder ein gedrosseltes 3G/4G-Netzwerk in Ihrem Büro für schnellere Tests einrichten.
Denken Sie daran, dass wir auf einem mobilen Gerät im Vergleich zu Desktop-Computern mit einer 4- bis 5-fachen Verlangsamung rechnen sollten. Mobilgeräte haben unterschiedliche GPUs, CPU, Speicher und unterschiedliche Akkueigenschaften. Deshalb ist es wichtig, ein gutes Profil eines durchschnittlichen Geräts zu haben und immer auf einem solchen Gerät zu testen.
- Synthetische Testwerkzeuge sammeln Labordaten in einer reproduzierbaren Umgebung mit vordefinierten Geräte- und Netzwerkeinstellungen (z. B. Lighthouse , Calibre , WebPageTest ) und
- Real User Monitoring ( RUM ) Tools werten Benutzerinteraktionen kontinuierlich aus und sammeln Felddaten (z. B. SpeedCurve , New Relic – die Tools bieten auch synthetische Tests).
- Verwenden Sie Lighthouse CI, um Lighthouse-Ergebnisse im Laufe der Zeit zu verfolgen (es ist ziemlich beeindruckend),
- Führen Sie Lighthouse in GitHub Actions aus, um neben jeder PR einen Lighthouse-Bericht zu erhalten.
- Führen Sie auf jeder Seite einer Website (über Lightouse Parade) eine Lighthouse-Leistungsprüfung durch, wobei die Ausgabe als CSV gespeichert wird.
- Verwenden Sie Lighthouse Scores Calculator und Lighthouse-Metrikgewichte, wenn Sie mehr ins Detail gehen müssen.
- Lighthouse ist auch für Firefox verfügbar, aber unter der Haube verwendet es die PageSpeed Insights API und generiert einen Bericht basierend auf einem Headless Chrome 79 User-Agent.

Glücklicherweise gibt es viele großartige Optionen, mit denen Sie die Datenerfassung automatisieren und anhand dieser Metriken messen können, wie Ihre Website im Laufe der Zeit abschneidet. Denken Sie daran, dass ein gutes Leistungsbild eine Reihe von Leistungsmetriken, Labordaten und Felddaten abdeckt:
Ersteres ist während der Entwicklung besonders nützlich, da es Ihnen hilft, Leistungsprobleme zu identifizieren, zu isolieren und zu beheben, während Sie am Produkt arbeiten. Letzteres ist nützlich für die langfristige Wartung , da es Ihnen hilft, Ihre Leistungsengpässe zu verstehen, wenn sie live auftreten – wenn Benutzer tatsächlich auf die Website zugreifen.
Durch die Nutzung integrierter RUM-APIs wie Navigation Timing, Resource Timing, Paint Timing, Long Tasks usw. bieten synthetische Testwerkzeuge und RUM zusammen ein vollständiges Bild der Leistung Ihrer Anwendung. Sie könnten Calibre, Treo, SpeedCurve, mPulse und Boomerang, Sitespeed.io verwenden, die alle großartige Optionen für die Leistungsüberwachung sind. Darüber hinaus können Sie mit dem Server-Timing-Header sogar die Back-End- und Front-End-Leistung an einem Ort überwachen.
Hinweis : Es ist immer sicherer, Drosselklappen auf Netzwerkebene außerhalb des Browsers zu wählen, da beispielsweise DevTools aufgrund der Art und Weise, wie es implementiert ist, Probleme bei der Interaktion mit HTTP/2-Push hat ( danke, Yoav, Patrick !). Für Mac OS können wir Network Link Conditioner verwenden, für Windows Windows Traffic Shaper, für Linux netem und für FreeBSD dummynet.
Da Sie wahrscheinlich in Lighthouse testen werden, denken Sie daran, dass Sie Folgendes tun können:
- Richten Sie zum Testen „saubere“ und „Kunden“-Profile ein.
Beim Ausführen von Tests in passiven Überwachungstools ist es eine gängige Strategie, Antiviren- und Hintergrund-CPU-Aufgaben zu deaktivieren, Bandbreitenübertragungen im Hintergrund zu entfernen und mit einem sauberen Benutzerprofil ohne Browsererweiterungen zu testen, um verzerrte Ergebnisse zu vermeiden (in Firefox und in Chrome).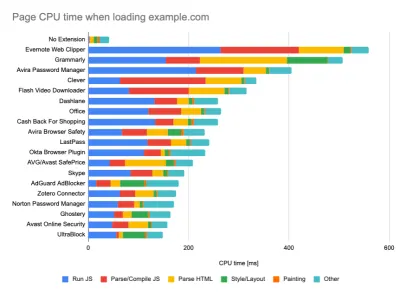
Der Bericht von DebugBear hebt die 20 langsamsten Erweiterungen hervor, darunter Passwortmanager, Werbeblocker und beliebte Anwendungen wie Evernote und Grammarly. (Große Vorschau) Es ist jedoch auch eine gute Idee, zu untersuchen, welche Browsererweiterungen Ihre Kunden häufig verwenden, und dies auch mit dedizierten „Kunden“-Profilen zu testen. Tatsächlich können einige Erweiterungen tiefgreifende Auswirkungen auf die Leistung Ihrer Anwendung haben (Chrome Extension Performance Report 2020), und wenn Ihre Benutzer sie häufig verwenden, sollten Sie dies möglicherweise im Voraus berücksichtigen. Daher sind "saubere" Profilergebnisse allein zu optimistisch und können in realen Szenarien zerstört werden.
- Teilen Sie die Leistungsziele mit Ihren Kollegen.
Stellen Sie sicher, dass die Leistungsziele jedem Mitglied Ihres Teams bekannt sind, um spätere Missverständnisse zu vermeiden. Jede Entscheidung – sei es Design, Marketing oder irgendetwas dazwischen – hat Auswirkungen auf die Leistung , und die Verteilung von Verantwortung und Eigenverantwortung auf das gesamte Team würde spätere leistungsorientierte Entscheidungen rationalisieren. Ordnen Sie Designentscheidungen dem Leistungsbudget und den früh definierten Prioritäten zu.
Inhaltsverzeichnis
- Vorbereitung: Planung und Metriken
- Realistische Ziele setzen
- Die Umgebung definieren
- Asset-Optimierungen
- Build-Optimierungen
- Lieferoptimierungen
- Netzwerk, HTTP/2, HTTP/3
- Testen und Überwachen
- Schnelle Gewinne
- Alles auf einer Seite
- Checkliste herunterladen (PDF, Apple Pages, MS Word)
- Abonnieren Sie unseren E-Mail-Newsletter, um die nächsten Anleitungen nicht zu verpassen.