
Front-End-Performance-Checkliste 2021 (PDF, Apple Pages, MS Word)
Veröffentlicht: 2022-03-10Dieser Leitfaden wurde freundlicherweise von unseren Freunden bei LogRocket unterstützt, einem Dienst, der Frontend-Leistungsüberwachung , Sitzungswiedergabe und Produktanalyse kombiniert, um Ihnen zu helfen, bessere Kundenerlebnisse zu schaffen. LogRocket verfolgt Schlüsselmetriken, inkl. DOM abgeschlossen, Zeit bis zum ersten Byte, erste Eingabeverzögerung, Client-CPU und Speicherauslastung. Holen Sie sich noch heute eine kostenlose Testversion von LogRocket.

Web-Performance ist ein heikles Biest, nicht wahr? Woher wissen wir eigentlich, wo wir in Sachen Performance stehen und wo genau unsere Performance-Engpässe liegen? Ist es teures JavaScript, langsame Bereitstellung von Webfonts, umfangreiche Bilder oder träges Rendering? Haben wir mit Tree-Shaking, Scope-Histing, Code-Splitting und all den ausgefallenen Lademustern mit Schnittpunktbeobachter, progressiver Hydratation, Client-Hinweisen, HTTP/3, Servicemitarbeitern und – oh mein Gott – Edge-Workern genug optimiert? Und vor allem, wo fangen wir überhaupt an, die Leistung zu verbessern und wie etablieren wir langfristig eine Leistungskultur?
Früher war Leistung oft nur ein nachträglicher Einfall . Oft bis zum Ende des Projekts verschoben, lief es auf Minimierung, Verkettung, Asset-Optimierung und möglicherweise ein paar Feinanpassungen an der config des Servers hinaus. Wenn ich jetzt zurückblicke, scheinen sich die Dinge ziemlich verändert zu haben.
Leistung ist nicht nur ein technisches Problem: Sie betrifft alles von der Zugänglichkeit über die Benutzerfreundlichkeit bis hin zur Suchmaschinenoptimierung, und wenn sie in den Arbeitsablauf integriert wird, müssen Designentscheidungen von ihren Auswirkungen auf die Leistung beeinflusst werden. Die Leistung muss kontinuierlich gemessen, überwacht und verfeinert werden, und die wachsende Komplexität des Webs stellt neue Herausforderungen dar, die es schwierig machen, den Überblick über Metriken zu behalten, da die Daten je nach Gerät, Browser, Protokoll, Netzwerktyp und Latenz erheblich variieren ( CDNs, ISPs, Caches, Proxys, Firewalls, Load Balancer und Server spielen alle eine Rolle bei der Leistung).
Wenn wir also eine Übersicht über all die Dinge erstellen, die wir bei der Verbesserung der Leistung beachten müssen – vom Projektstart bis zur endgültigen Veröffentlichung der Website – wie würde das aussehen? Nachfolgend finden Sie eine (hoffentlich unvoreingenommene und objektive) Checkliste für die Front-End-Leistung für 2021 – eine aktualisierte Übersicht über die Probleme, die Sie möglicherweise berücksichtigen müssen, um sicherzustellen, dass Ihre Reaktionszeiten schnell sind, die Benutzerinteraktion reibungslos ist und Ihre Websites dies nicht tun Bandbreite des Benutzers entziehen.
Inhaltsverzeichnis
- Alles auf separaten Seiten
- Vorbereitung: Planung und Metriken
Leistungskultur, Core Web Vitals, Leistungsprofile, CrUX, Lighthouse, FID, TTI, CLS, Geräte. - Realistische Ziele setzen
Leistungsbudgets, Leistungsziele, RAIL-Framework, 170-KB-/30-KB-Budgets. - Die Umgebung definieren
Auswahl eines Frameworks, grundlegende Leistungskosten, Webpack, Abhängigkeiten, CDN, Front-End-Architektur, CSR, SSR, CSR + SSR, statisches Rendering, Pre-Rendering, PRPL-Muster. - Asset-Optimierungen
Brotli, AVIF, WebP, responsive Bilder, AV1, adaptives Laden von Medien, Videokomprimierung, Webfonts, Google-Fonts. - Build-Optimierungen
JavaScript-Module, Modul/Nomodule-Muster, Tree-Shaking, Code-Splitting, Scope-Hoisting, Webpack, Differential Serving, Web Worker, WebAssembly, JavaScript-Bundles, React, SPA, Partial Hydration, Import on Interaction, Drittanbieter, Cache. - Lieferoptimierungen
Lazy Loading, Kreuzungsbeobachter, Aufschieben von Rendering und Decodierung, kritisches CSS, Streaming, Ressourcenhinweise, Layoutverschiebungen, Servicemitarbeiter. - Netzwerk, HTTP/2, HTTP/3
OCSP-Stapling, EV/DV-Zertifikate, Verpackung, IPv6, QUIC, HTTP/3. - Testen und Überwachen
Auditing-Workflow, Proxy-Browser, 404-Seite, DSGVO-Cookie-Zustimmungsaufforderungen, Performance-Diagnose-CSS, Barrierefreiheit. - Schnelle Gewinne
- Checkliste herunterladen (PDF, Apple Pages, MS Word)
- Los geht's!
(Sie können auch einfach die PDF-Checkliste (166 KB) oder die bearbeitbare Apple Pages-Datei (275 KB) oder die .docx-Datei (151 KB) herunterladen. Viel Spaß beim Optimieren!)
Vorbereitung: Planung und Metriken
Mikrooptimierungen eignen sich hervorragend, um die Leistung auf Kurs zu halten, aber es ist entscheidend, klar definierte Ziele im Auge zu haben – messbare Ziele, die alle Entscheidungen beeinflussen, die während des gesamten Prozesses getroffen werden. Es gibt ein paar verschiedene Modelle, und die unten besprochenen sind ziemlich eigensinnig – stellen Sie nur sicher, dass Sie frühzeitig Ihre eigenen Prioritäten setzen.
- Etablieren Sie eine Leistungskultur.
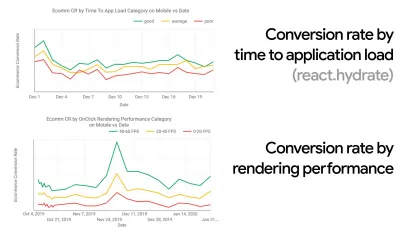
In vielen Organisationen wissen Front-End-Entwickler genau, welche häufigen zugrunde liegenden Probleme auftreten und welche Strategien zu ihrer Behebung angewendet werden sollten. Solange es jedoch keine etablierte Unterstützung der Leistungskultur gibt, wird jede Entscheidung zu einem Schlachtfeld von Abteilungen, das die Organisation in Silos auflöst. Sie benötigen eine Beteiligung von Geschäftsinteressenten, und um diese zu erhalten, müssen Sie eine Fallstudie oder einen Machbarkeitsnachweis darüber erstellen, wie Geschwindigkeit – insbesondere Core Web Vitals , die wir später ausführlich behandeln – Metriken und Key Performance Indicators zugute kommt ( KPIs ), die ihnen wichtig sind.Um beispielsweise die Leistung greifbarer zu machen, könnten Sie die Auswirkungen auf die Umsatzleistung offenlegen, indem Sie die Korrelation zwischen der Conversion-Rate und der Zeit bis zum Laden der Anwendung sowie die Rendering-Leistung anzeigen. Oder die Suchbot-Crawling-Rate (PDF, Seiten 27–50).
Ohne eine starke Abstimmung zwischen Entwicklungs-/Design- und Geschäfts-/Marketingteams wird die Leistung nicht langfristig aufrechterhalten. Untersuchen Sie häufige Beschwerden, die beim Kundendienst und im Verkaufsteam eingehen, untersuchen Sie Analysen für hohe Absprungraten und Conversion-Einbrüche. Erfahren Sie, wie die Verbesserung der Leistung dazu beitragen kann, einige dieser häufigen Probleme zu lindern. Passen Sie die Argumentation an die Gruppe der Stakeholder an, mit denen Sie sprechen.
Führen Sie Leistungsexperimente durch und messen Sie die Ergebnisse – sowohl auf Mobilgeräten als auch auf dem Desktop (z. B. mit Google Analytics). Es hilft Ihnen, eine auf das Unternehmen zugeschnittene Fallstudie mit echten Daten aufzubauen. Darüber hinaus wird die Verwendung von Daten aus Fallstudien und Experimenten, die auf WPO Stats veröffentlicht wurden, dazu beitragen, die Sensibilität für Unternehmen zu erhöhen, warum Leistung wichtig ist und welche Auswirkungen sie auf die Benutzererfahrung und Geschäftskennzahlen hat. Es reicht jedoch nicht aus, zu sagen, dass Leistung allein wichtig ist – Sie müssen auch einige messbare und nachverfolgbare Ziele festlegen und diese im Laufe der Zeit beobachten.
Wie man dorthin kommt? In ihrem Vortrag „Building Performance for the Long Term“ teilt Allison McKnight eine umfassende Fallstudie darüber, wie sie dazu beigetragen hat, eine Performance-Kultur bei Etsy zu etablieren (Folien). In jüngerer Zeit hat Tammy Everts über die Gewohnheiten hocheffektiver Leistungsteams in kleinen und großen Organisationen gesprochen.
Bei diesen Gesprächen in Organisationen ist es wichtig, im Hinterkopf zu behalten, dass die Webleistung eine Verteilung ist, genau wie UX ein Spektrum von Erfahrungen ist. Wie Karolina Szczur feststellte, „ist die Erwartung, dass eine einzige Zahl eine angestrebte Bewertung liefern kann, eine fehlerhafte Annahme.“ Daher müssen Leistungsziele granular, nachvollziehbar und greifbar sein.
- Ziel: Seien Sie mindestens 20 % schneller als Ihr schnellster Konkurrent.
Laut psychologischer Forschung müssen Sie mindestens 20 % schneller sein, wenn Sie möchten, dass Benutzer das Gefühl haben, dass Ihre Website schneller ist als die Website Ihres Konkurrenten. Untersuchen Sie Ihre Hauptkonkurrenten, sammeln Sie Metriken darüber, wie sie auf Mobilgeräten und Desktops abschneiden, und legen Sie Schwellenwerte fest, die Ihnen helfen würden, sie zu übertreffen. Um jedoch genaue Ergebnisse und Ziele zu erhalten, stellen Sie sicher, dass Sie sich zunächst ein gründliches Bild von der Erfahrung Ihrer Benutzer machen, indem Sie Ihre Analysen studieren. Sie können dann die Erfahrung des 90. Perzentils zum Testen nachahmen.Um einen guten ersten Eindruck davon zu bekommen, wie Ihre Konkurrenten abschneiden, können Sie den Chrome UX Report ( CrUX , ein vorgefertigter RUM-Datensatz, Videoeinführung von Ilya Grigorik und eine ausführliche Anleitung von Rick Viscomi) oder Treo, ein RUM-Überwachungstool, verwenden wird von Chrome UX Report unterstützt. Die Daten werden von den Chrome-Browser-Benutzern gesammelt, daher sind die Berichte Chrome-spezifisch, aber sie geben Ihnen eine ziemlich gründliche Verteilung der Leistung, vor allem der Core Web Vitals-Ergebnisse, über ein breites Spektrum Ihrer Besucher. Beachten Sie, dass neue CrUX-Datensätze am zweiten Dienstag jedes Monats veröffentlicht werden.
Alternativ können Sie auch verwenden:
- Chrome UX Report Compare Tool von Addy Osmani,
- Speed Scorecard (bietet auch einen Schätzer für die Auswirkungen auf den Umsatz),
- Real User Experience Testvergleich bzw
- SiteSpeed CI (basierend auf synthetischen Tests).
Hinweis : Wenn Sie Page Speed Insights oder Page Speed Insights API verwenden (nein, es ist nicht veraltet!), können Sie CrUX-Leistungsdaten für bestimmte Seiten anstelle nur der Aggregate abrufen. Diese Daten können viel nützlicher sein, um Leistungsziele für Assets wie „Zielseite“ oder „Produktliste“ festzulegen. Und wenn Sie CI zum Testen der Budgets verwenden, müssen Sie sicherstellen, dass Ihre getestete Umgebung mit CrUX übereinstimmt, wenn Sie CrUX zum Festlegen des Ziels verwendet haben ( danke Patrick Meenan! ).
Wenn Sie Hilfe benötigen, um die Gründe für die Priorisierung der Geschwindigkeit aufzuzeigen, oder wenn Sie den Rückgang der Conversion-Rate oder die Erhöhung der Absprungrate bei geringerer Leistung visualisieren möchten, oder vielleicht müssen Sie sich für eine RUM-Lösung in Ihrer Organisation einsetzen, Sergey Chernyshev hat einen UX-Geschwindigkeitsrechner entwickelt, ein Open-Source-Tool, mit dem Sie Daten simulieren und visualisieren können, um Ihren Standpunkt zu verdeutlichen.

CrUX generiert einen Überblick über die Leistungsverteilung im Laufe der Zeit, wobei der Datenverkehr von Google Chrome-Benutzern erfasst wird. Sie können Ihre eigenen im Chrome UX Dashboard erstellen. (Große Vorschau) 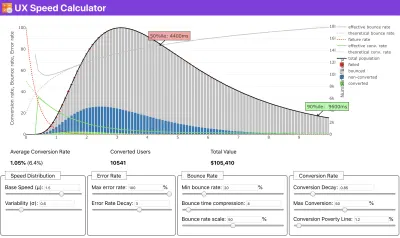
Gerade wenn Sie für Leistung plädieren müssen, um Ihren Standpunkt zu verdeutlichen: UX Speed Calculator visualisiert die Auswirkungen der Leistung auf Absprungraten, Konversion und Gesamtumsatz – basierend auf echten Daten. (Große Vorschau) Manchmal möchten Sie vielleicht etwas tiefer gehen und die Daten aus CrUX mit anderen Daten kombinieren, die Sie bereits haben, um schnell herauszufinden, wo die Verlangsamungen, blinden Flecken und Ineffizienzen liegen – für Ihre Konkurrenten oder für Ihr Projekt. Bei seiner Arbeit hat Harry Roberts eine Site-Speed-Topographie-Tabelle verwendet, mit der er die Leistung nach Schlüsselseitentypen aufschlüsselt und verfolgt, wie unterschiedlich die Schlüsselmetriken auf ihnen sind. Sie können die Tabelle als Google Sheets, Excel, OpenOffice-Dokument oder CSV herunterladen.
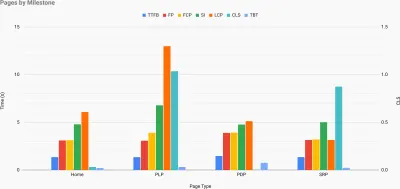
Topografie der Site-Geschwindigkeit, mit Schlüsselmetriken, die für Schlüsselseiten auf der Site dargestellt werden. (Große Vorschau) Und wenn Sie den ganzen Weg gehen wollen, können Sie auf jeder Seite einer Website (über Lightouse Parade) eine Lighthouse-Leistungsprüfung durchführen, wobei die Ausgabe als CSV gespeichert wird. Auf diese Weise können Sie feststellen, welche spezifischen Seiten (oder Arten von Seiten) Ihrer Mitbewerber schlechter oder besser abschneiden und worauf Sie Ihre Bemühungen konzentrieren sollten. (Für Ihre eigene Website ist es jedoch wahrscheinlich besser, Daten an einen Analyseendpunkt zu senden!).

Mit Lighthouse Parade können Sie auf jeder Seite einer Website eine Lighthouse-Leistungsprüfung durchführen, wobei die Ausgabe als CSV gespeichert wird. (Große Vorschau) Sammeln Sie Daten, erstellen Sie eine Tabelle, sparen Sie 20 % und legen Sie Ihre Ziele ( Leistungsbudgets ) auf diese Weise fest. Jetzt haben Sie etwas Messbares zum Testen. Wenn Sie das Budget im Auge behalten und versuchen, nur die minimale Nutzlast herunterzuladen, um eine schnelle Interaktivitätszeit zu erreichen, dann sind Sie auf einem vernünftigen Weg.
Benötigen Sie Ressourcen, um loszulegen?
- Addy Osmani hat einen sehr detaillierten Artikel darüber geschrieben, wie man mit der Leistungsbudgetierung beginnt, wie man die Auswirkungen neuer Funktionen quantifiziert und wo man anfängt, wenn das Budget überschritten wird.
- Der Leitfaden von Lara Hogan zur Herangehensweise an Designs mit einem Leistungsbudget kann Designern hilfreiche Hinweise geben.
- Harry Roberts hat einen Leitfaden zum Einrichten eines Google-Tabellenblatts veröffentlicht, um die Auswirkungen von Skripten von Drittanbietern auf die Leistung mithilfe von Request Map anzuzeigen.
- Jonathan Fieldings Performance Budget Calculator, Katie Hempenius' perf-budget-calculator und Browser Calories können beim Erstellen von Budgets helfen (danke an Karolina Szczur für die Hinweise).
- Performance-Budgets sollten in vielen Unternehmen nicht ehrgeizig, sondern pragmatisch sein und als Haltezeichen dienen, um ein bestimmtes Maß nicht zu überschreiten. In diesem Fall könnten Sie Ihren schlechtesten Datenpunkt in den letzten zwei Wochen als Schwellenwert auswählen und von dort aus weitermachen. Leistungsbudgets, Pragmatisch zeigt Ihnen eine Strategie, um dies zu erreichen.
- Machen Sie außerdem sowohl das Leistungsbudget als auch die aktuelle Leistung sichtbar , indem Sie Dashboards mit Diagrammen einrichten, die die Build-Größen melden. Es gibt viele Tools, mit denen Sie dies erreichen können: Das SiteSpeed.io-Dashboard (Open Source), SpeedCurve und Calibre sind nur einige davon, und Sie finden weitere Tools auf perf.rocks.

Browser-Kalorien helfen Ihnen, ein Leistungsbudget festzulegen und zu messen, ob eine Seite diese Zahlen überschreitet oder nicht. (Große Vorschau) Sobald Sie ein Budget festgelegt haben, integrieren Sie es mit Webpack Performance Hints und Bundlesize, Lighthouse CI, PWMetrics oder Sitespeed CI in Ihren Build-Prozess, um Budgets für Pull-Requests durchzusetzen und einen Bewertungsverlauf in PR-Kommentaren bereitzustellen.
Um Leistungsbudgets dem gesamten Team zugänglich zu machen, integrieren Sie Leistungsbudgets in Lighthouse über Lightwallet oder verwenden Sie LHCI Action für eine schnelle Integration von Github Actions. Und wenn Sie etwas Benutzerdefiniertes benötigen, können Sie webpagetest-charts-api verwenden, eine API von Endpunkten, um Diagramme aus WebPagetest-Ergebnissen zu erstellen.
Leistungsbewusstsein sollte jedoch nicht allein aus Leistungsbudgets resultieren. Genau wie bei Pinterest könnten Sie eine benutzerdefinierte Eslint- Regel erstellen, die den Import aus Dateien und Verzeichnissen verbietet, die bekanntermaßen abhängigkeitsintensiv sind und das Bundle aufblähen würden. Richten Sie eine Liste „sicherer“ Pakete ein, die im gesamten Team geteilt werden kann.
Denken Sie auch an kritische Kundenaufgaben, die für Ihr Unternehmen am vorteilhaftesten sind. Untersuchen, diskutieren und definieren Sie akzeptable Zeitschwellen für kritische Aktionen und legen Sie „UX-fähige“ Benutzerzeitmarken fest, die von der gesamten Organisation genehmigt wurden. In vielen Fällen berühren User Journeys die Arbeit vieler verschiedener Abteilungen, sodass die Abstimmung in Bezug auf akzeptable Zeitpläne dazu beitragen kann, spätere Leistungsdiskussionen zu unterstützen oder zu verhindern. Stellen Sie sicher, dass zusätzliche Kosten für zusätzliche Ressourcen und Funktionen sichtbar und verständlich sind.
Richten Sie Leistungsbemühungen mit anderen Technologieinitiativen aus, die von neuen Funktionen des zu erstellenden Produkts über Refactoring bis hin zum Erreichen neuer globaler Zielgruppen reichen. Jedes Mal, wenn ein Gespräch über die Weiterentwicklung stattfindet, ist auch die Leistung ein Teil dieses Gesprächs. Es ist viel einfacher, Leistungsziele zu erreichen, wenn die Codebasis frisch ist oder gerade umgestaltet wird.
Wie Patrick Meenan vorgeschlagen hat, lohnt es sich außerdem, während des Designprozesses eine Ladesequenz und Kompromisse zu planen . Wenn Sie frühzeitig priorisieren, welche Teile kritischer sind, und die Reihenfolge festlegen, in der sie erscheinen sollen, wissen Sie auch, was sich verzögern kann. Idealerweise spiegelt diese Reihenfolge auch die Reihenfolge Ihrer CSS- und JavaScript-Importe wider, sodass die Handhabung während des Build-Prozesses einfacher wird. Überlegen Sie auch, wie das visuelle Erlebnis in „Zwischen“-Zuständen sein sollte, während die Seite geladen wird (z. B. wenn Webfonts noch nicht geladen sind).
Sobald Sie eine starke Leistungskultur in Ihrem Unternehmen etabliert haben, streben Sie danach, 20 % schneller zu sein als Ihr früheres Ich , um die Prioritäten im Laufe der Zeit im Takt zu halten ( Danke, Guy Podjarny! ). Berücksichtigen Sie jedoch die unterschiedlichen Typen und Nutzungsverhalten Ihrer Kunden (die Tobias Baldauf Kadenz und Kohorten nannte), zusammen mit Bot-Traffic und saisonalen Effekten.
Planen, planen, planen. Es mag verlockend sein, früh in einige schnelle „Low-Hanging-Fruits“-Optimierungen einzusteigen – und es könnte eine gute Strategie für schnelle Erfolge sein – aber es wird sehr schwierig sein, die Leistung als Priorität zu betrachten, ohne zu planen und realistische Unternehmen zu setzen -maßgeschneiderte Leistungsziele.
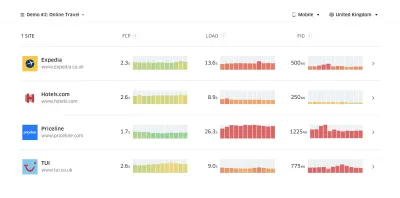
- Wählen Sie die richtigen Metriken.
Nicht alle Kennzahlen sind gleich wichtig. Untersuchen Sie, welche Metriken für Ihre Anwendung am wichtigsten sind: Normalerweise wird sie dadurch definiert, wie schnell Sie mit dem Rendern der wichtigsten Pixel Ihrer Benutzeroberfläche beginnen können und wie schnell Sie für diese gerenderten Pixel eine Eingabereaktionsfähigkeit bereitstellen können. Dieses Wissen gibt Ihnen das beste Optimierungsziel für die laufenden Bemühungen. Letztendlich sind es nicht die Lastereignisse oder Serverreaktionszeiten, die das Erlebnis bestimmen, sondern die Wahrnehmung, wie schnell sich die Benutzeroberfläche anfühlt .Was heißt das? Anstatt sich auf die Ladezeit der gesamten Seite zu konzentrieren (z. B. über onLoad- und DOMContentLoaded- Timings), priorisieren Sie das Laden von Seiten so, wie es von Ihren Kunden wahrgenommen wird. Das bedeutet, sich auf einen etwas anderen Satz von Metriken zu konzentrieren. Tatsächlich ist die Auswahl der richtigen Metrik ein Prozess ohne offensichtliche Gewinner.
Basierend auf den Recherchen von Tim Kadlec und den Anmerkungen von Marcos Iglesias in seinem Vortrag könnten traditionelle Metriken in einige Gruppen eingeteilt werden. Normalerweise benötigen wir alle, um uns ein vollständiges Bild von der Leistung zu machen, und in Ihrem speziellen Fall sind einige von ihnen wichtiger als andere.
- Mengenbasierte Metriken messen die Anzahl der Anfragen, das Gewicht und einen Leistungswert. Gut zum Auslösen von Alarmen und Überwachen von Änderungen im Laufe der Zeit, nicht so gut zum Verständnis der Benutzererfahrung.
- Milestone-Metriken verwenden Zustände in der Lebensdauer des Ladeprozesses, z. B. Time To First Byte und Time To Interactive . Gut, um die Benutzererfahrung und Überwachung zu beschreiben, nicht so gut, um zu wissen, was zwischen den Meilensteinen passiert.
- Rendering-Metriken liefern eine Schätzung, wie schnell Inhalte gerendert werden (z. B. Render-Startzeit , Geschwindigkeitsindex ). Gut zum Messen und Optimieren der Renderleistung, aber nicht so gut zum Messen, wann wichtige Inhalte angezeigt werden und mit denen interagiert werden kann.
- Benutzerdefinierte Metriken messen ein bestimmtes, benutzerdefiniertes Ereignis für den Benutzer, z. B. Twitters Zeit bis zum ersten Tweet und Pinterests PinnerWaitTime. Gut um das Nutzererlebnis genau zu beschreiben, weniger gut um die Metriken zu skalieren und mit Mitbewerbern zu vergleichen.
Um das Bild zu vervollständigen, würden wir normalerweise bei all diesen Gruppen nach nützlichen Metriken Ausschau halten. Normalerweise sind die spezifischsten und relevantesten:
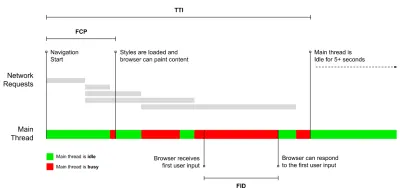
- Zeit bis zur Interaktivität (TTI)
Der Punkt, an dem sich das Layout stabilisiert hat, wichtige Webfonts sichtbar sind und der Haupt-Thread ausreichend verfügbar ist, um Benutzereingaben zu verarbeiten – im Grunde die Zeitmarke, an der ein Benutzer mit der Benutzeroberfläche interagieren kann. Die Schlüsselmetriken, um zu verstehen, wie lange ein Benutzer warten muss, um die Website ohne Verzögerung zu nutzen. Boris Schapira hat einen ausführlichen Beitrag darüber geschrieben, wie man TTI zuverlässig misst. - First Input Delay (FID) oder Eingangsreaktion
Die Zeit von der ersten Interaktion eines Benutzers mit Ihrer Website bis zu dem Zeitpunkt, an dem der Browser tatsächlich in der Lage ist, auf diese Interaktion zu reagieren . Ergänzt TTI sehr gut, da es den fehlenden Teil des Bildes beschreibt: was passiert, wenn ein Benutzer tatsächlich mit der Website interagiert. Nur als RUM-Metrik gedacht. Es gibt eine JavaScript-Bibliothek zum Messen von FID im Browser. - Größte zufriedene Farbe (LCP)
Markiert den Punkt in der Ladezeitachse der Seite, an dem der wichtige Inhalt der Seite wahrscheinlich geladen wurde. Die Annahme ist, dass das wichtigste Element der Seite das größte ist, das im Darstellungsbereich des Benutzers sichtbar ist. Wenn Elemente sowohl über als auch unter der Falte gerendert werden, wird nur der sichtbare Teil als relevant angesehen. - Gesamtsperrzeit ( TBT )
Eine Metrik, die dabei hilft, den Schweregrad zu quantifizieren, wie nicht interaktiv eine Seite ist , bevor sie zuverlässig interaktiv wird (das heißt, der Haupt-Thread war mindestens 5 Sekunden lang frei von Aufgaben, die länger als 50 ms ( lange Aufgaben ) ausgeführt wurden). Die Metrik misst die Gesamtzeit zwischen dem ersten Malen und der Time to Interactive (TTI), bei der der Hauptthread lange genug blockiert war, um eine Eingabereaktion zu verhindern. Kein Wunder also, dass eine niedrige TBT ein guter Indikator für gute Leistung ist. (Danke, Artem, Phil) - Kumulative Layoutverschiebung ( CLS )
Die Metrik hebt hervor, wie oft Benutzer beim Zugriff auf die Website unerwartete Layoutverschiebungen ( Reflows ) erleben. Es untersucht instabile Elemente und ihre Auswirkungen auf das Gesamterlebnis. Je niedriger die Punktzahl, desto besser. - Geschwindigkeitsindex
Misst, wie schnell der Seiteninhalt visuell ausgefüllt wird; Je niedriger die Punktzahl, desto besser. Der Geschwindigkeitsindexwert wird basierend auf der Geschwindigkeit des visuellen Fortschritts berechnet, ist jedoch lediglich ein berechneter Wert. Es reagiert auch empfindlich auf die Größe des Darstellungsbereichs, sodass Sie eine Reihe von Testkonfigurationen definieren müssen, die zu Ihrer Zielgruppe passen. Beachten Sie, dass es weniger wichtig wird, da LCP zu einer relevanteren Metrik wird ( Danke, Boris, Artem! ). - Aufgewandte CPU-Zeit
Eine Metrik, die zeigt, wie oft und wie lange der Haupt-Thread blockiert ist und an Malen, Rendern, Skripten und Laden arbeitet. Eine hohe CPU-Zeit ist ein klarer Indikator für ein fehlerhaftes Erlebnis, dh wenn der Benutzer eine merkliche Verzögerung zwischen seiner Aktion und einer Antwort erlebt. Mit WebPageTest können Sie auf der Registerkarte „Chrome“ die Option „Capture Dev Tools Timeline“ auswählen, um die Aufschlüsselung des Hauptthreads anzuzeigen, während er auf jedem Gerät mit WebPageTest ausgeführt wird. - CPU-Kosten auf Komponentenebene
Genau wie bei der aufgewendeten CPU-Zeit untersucht diese von Stoyan Stefanov vorgeschlagene Metrik die Auswirkungen von JavaScript auf die CPU . Die Idee ist, die Anzahl der CPU-Befehle pro Komponente zu verwenden, um ihre Auswirkungen auf das Gesamterlebnis isoliert zu verstehen. Könnte mit Puppeteer und Chrome implementiert werden. - Frustindex
Während viele der oben aufgeführten Metriken erklären, wann ein bestimmtes Ereignis eintritt, betrachtet der FrustrationIndex von Tim Vereecke die Lücken zwischen den Metriken, anstatt sie einzeln zu betrachten. Es betrachtet die wichtigsten Meilensteine, die vom Endbenutzer wahrgenommen werden, wie z. B. „Titel ist sichtbar“, „Erster Inhalt ist sichtbar“, „Visuell fertig“ und „Seite sieht fertig aus“, und berechnet eine Punktzahl, die den Grad der Frustration beim Laden einer Seite angibt. Je größer die Lücke, desto größer die Wahrscheinlichkeit, dass ein Benutzer frustriert wird. Potenziell ein guter KPI für die Benutzererfahrung. Tim hat einen ausführlichen Beitrag über FrustrationIndex und seine Funktionsweise veröffentlicht. - Auswirkungen auf die Anzeigengewichtung
Wenn Ihre Website von Werbeeinnahmen abhängt, ist es hilfreich, die Gewichtung des werbebezogenen Codes zu verfolgen. Das Skript von Paddy Ganti konstruiert zwei URLs (eine normale und eine, die die Werbung blockiert), veranlasst die Generierung eines Videovergleichs über WebPageTest und meldet ein Delta. - Abweichungsmetriken
Wie von Wikipedia-Ingenieuren angemerkt, können Daten darüber, wie viel Varianz in Ihren Ergebnissen vorhanden ist, Sie darüber informieren, wie zuverlässig Ihre Instrumente sind und wie viel Aufmerksamkeit Sie Abweichungen und Ausreißern schenken sollten. Eine große Varianz ist ein Indikator für erforderliche Anpassungen im Setup. Es hilft auch zu verstehen, ob bestimmte Seiten schwieriger zuverlässig zu messen sind, z. B. aufgrund von Skripten von Drittanbietern, die erhebliche Abweichungen verursachen. Es kann auch eine gute Idee sein, die Browserversion zu verfolgen, um Leistungseinbußen zu verstehen, wenn eine neue Browserversion eingeführt wird. - Benutzerdefinierte Metriken
Benutzerdefinierte Metriken werden durch Ihre Geschäftsanforderungen und das Kundenerlebnis definiert. Sie müssen wichtige Pixel, kritische Skripte, notwendiges CSS und relevante Assets identifizieren und messen, wie schnell sie dem Benutzer bereitgestellt werden. Dafür können Sie Hero Rendering Times überwachen oder die Performance API verwenden, um bestimmte Zeitstempel für Ereignisse zu markieren, die für Ihr Unternehmen wichtig sind. Außerdem können Sie mit WebPagetest benutzerdefinierte Metriken sammeln, indem Sie am Ende eines Tests beliebiges JavaScript ausführen.
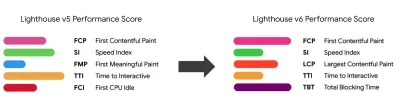
Beachten Sie, dass der First Meaningful Paint (FMP) nicht in der obigen Übersicht erscheint. Früher gab es einen Einblick, wie schnell der Server Daten ausgibt. Langes FMP deutete normalerweise darauf hin, dass JavaScript den Haupt-Thread blockiert, könnte aber auch mit Back-End-/Server-Problemen zusammenhängen. Die Metrik wurde jedoch kürzlich verworfen, da sie in etwa 20 % der Fälle nicht genau zu sein scheint. Es wurde effektiv durch LCP ersetzt, das sowohl zuverlässiger als auch einfacher zu begründen ist. Es wird in Lighthouse nicht mehr unterstützt. Überprüfen Sie die neuesten benutzerorientierten Leistungsmetriken und Empfehlungen, um sicherzustellen, dass Sie auf der sicheren Seite sind ( Danke, Patrick Meenan ).
Steve Souders hat eine detaillierte Erklärung vieler dieser Metriken. Es ist wichtig zu beachten, dass die Zeit bis zur Interaktion zwar durch die Ausführung automatisierter Audits in der sogenannten Laborumgebung gemessen wird, die Verzögerung der ersten Eingabe jedoch die tatsächliche Benutzererfahrung darstellt, wobei tatsächliche Benutzer eine merkliche Verzögerung erfahren. Im Allgemeinen ist es wahrscheinlich eine gute Idee, immer beide zu messen und zu verfolgen.
Abhängig vom Kontext Ihrer Anwendung können sich die bevorzugten Metriken unterscheiden: Beispielsweise sind für die Benutzeroberfläche von Netflix TV die Reaktionsfähigkeit auf Tasteneingaben, die Speichernutzung und TTI kritischer, und für Wikipedia sind erste/letzte visuelle Änderungen und die Metriken für verbrauchte CPU-Zeit wichtiger.
Hinweis : Sowohl FID als auch TTI berücksichtigen das Scrollverhalten nicht; Das Scrollen kann unabhängig voneinander erfolgen, da es sich um einen Off-Main-Thread handelt, sodass diese Metriken für viele Websites, die Inhalte konsumieren, möglicherweise viel weniger wichtig sind ( Danke, Patrick! ).
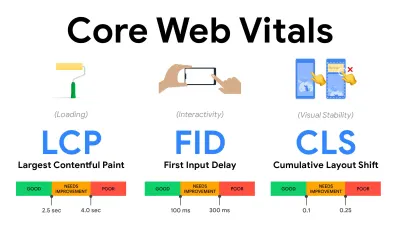
- Messen und optimieren Sie die Core Web Vitals .
Lange Zeit waren Leistungsmetriken recht technisch und konzentrierten sich auf die technische Sichtweise darauf, wie schnell Server reagieren und wie schnell Browser laden. Die Metriken haben sich im Laufe der Jahre geändert – es wurde versucht, einen Weg zu finden, die tatsächliche Benutzererfahrung zu erfassen, anstatt Server-Timings. Im Mai 2020 hat Google Core Web Vitals angekündigt, eine Reihe neuer nutzerorientierter Leistungskennzahlen, die jeweils eine bestimmte Facette der Nutzererfahrung darstellen.Für jeden von ihnen empfiehlt Google eine Reihe akzeptabler Geschwindigkeitsziele. Mindestens 75 % aller Seitenaufrufe sollten den Bereich „Gut“ überschreiten, um diese Bewertung zu bestehen. Diese Metriken gewannen schnell an Bedeutung, und da Core Web Vitals im Mai 2021 zu Ranking-Signalen für die Google-Suche wurden ( Aktualisierung des Page Experience-Ranking-Algorithmus ), haben viele Unternehmen ihre Aufmerksamkeit auf ihre Leistungswerte gerichtet.
Lassen Sie uns jeden der Core Web Vitals einzeln aufschlüsseln, zusammen mit nützlichen Techniken und Tools , um Ihre Erfahrungen mit diesen Metriken im Hinterkopf zu optimieren. (Es ist erwähnenswert, dass Sie am Ende bessere Core Web Vitals-Ergebnisse erhalten, wenn Sie einem allgemeinen Rat in diesem Artikel folgen.)
- Largest Contentful Paint ( LCP ) < 2,5 Sek.
Misst das Laden einer Seite und meldet die Renderzeit des größten Bild- oder Textblocks , der im Darstellungsbereich sichtbar ist. Daher ist LCP von allem betroffen, was das Rendern wichtiger Informationen verzögert – seien es langsame Serverantwortzeiten, blockierendes CSS, In-Flight-JavaScript (Erstanbieter oder Drittanbieter), Laden von Webschriften, teure Rendering- oder Malvorgänge, Faulheit -geladene Bilder, Skelettbildschirme oder clientseitiges Rendering.
Für eine gute Erfahrung sollte LCP innerhalb von 2,5 Sekunden nach dem ersten Laden der Seite erfolgen. Das bedeutet, dass wir den ersten sichtbaren Teil der Seite so früh wie möglich rendern müssen. Das erfordert maßgeschneidertes kritisches CSS für jede Vorlage, das Orchestrieren der<head>-Reihenfolge und das Vorabrufen kritischer Assets (wir werden sie später behandeln).Der Hauptgrund für einen niedrigen LCP-Score sind in der Regel Bilder. Ein LCP in <2,5 s auf Fast 3G bereitzustellen – gehostet auf einem gut optimierten Server, alles statisch ohne clientseitiges Rendering und mit einem Bild, das von einem dedizierten Bild-CDN kommt – bedeutet, dass die maximale theoretische Bildgröße nur etwa 144 KB beträgt . Aus diesem Grund sind reaktionsschnelle Bilder ebenso wichtig wie das frühzeitige Vorladen kritischer Bilder (mit
preload).Kurzer Tipp : Um herauszufinden, was auf einer Seite als LCP gilt, können Sie in DevTools den Mauszeiger über das LCP-Badge unter „Timings“ im Performance Panel bewegen ( Danke, Tim Kadlec !).
- Erste Eingangsverzögerung ( FID ) < 100 ms.
Misst die Reaktionsfähigkeit der Benutzeroberfläche, dh wie lange der Browser mit anderen Aufgaben beschäftigt war , bevor er auf ein diskretes Benutzereingabeereignis wie Tippen oder Klicken reagieren konnte. Es wurde entwickelt, um Verzögerungen zu erfassen, die dadurch entstehen, dass der Haupt-Thread ausgelastet ist, insbesondere während des Ladens der Seite.
Das Ziel ist es, bei jeder Interaktion innerhalb von 50–100 ms zu bleiben. Um dorthin zu gelangen, müssen wir lange Aufgaben identifizieren (blockiert den Haupt-Thread für > 50 ms) und sie aufteilen, ein Bündel durch Code in mehrere Teile aufteilen, die JavaScript-Ausführungszeit reduzieren, den Datenabruf optimieren und die Skriptausführung von Drittanbietern verschieben , verschieben Sie JavaScript in den Hintergrund-Thread mit Web-Workern und verwenden Sie die progressive Hydratation, um die Rehydrierungskosten in SPAs zu reduzieren.Kurzer Tipp : Im Allgemeinen besteht eine zuverlässige Strategie zum Erzielen eines besseren FID-Scores darin , die Arbeit am Hauptthread zu minimieren, indem größere Bundles in kleinere aufgeteilt werden und das bereitgestellt wird, was der Benutzer benötigt, wenn er es benötigt, sodass Benutzerinteraktionen nicht verzögert werden . Wir werden weiter unten im Detail darauf eingehen.
- Kumulative Layoutverschiebung ( CLS ) < 0,1.
Misst die visuelle Stabilität der Benutzeroberfläche, um reibungslose und natürliche Interaktionen zu gewährleisten, dh die Gesamtsumme aller individuellen Layout-Verschiebungen für jede unerwartete Layout-Verschiebung, die während der Lebensdauer der Seite auftritt. Eine individuelle Layoutverschiebung tritt immer dann auf, wenn ein bereits sichtbares Element seine Position auf der Seite verändert. Es wird basierend auf der Größe des Inhalts und der Entfernung, die es bewegt hat, bewertet.
Also jedes Mal, wenn eine Verschiebung auftritt – z. B. wenn Fallback-Fonts und Web-Fonts unterschiedliche Font-Metriken haben oder Anzeigen, Einbettungen oder Iframes spät eintreffen oder Bild-/Videodimensionen nicht reserviert sind oder spätes CSS Neuzeichnungen erzwingt oder Änderungen von eingefügt werden spätes JavaScript – es wirkt sich auf den CLS-Score aus. Der empfohlene Wert für ein gutes Erlebnis ist ein CLS < 0,1.
Es ist erwähnenswert, dass sich Core Web Vitals im Laufe der Zeit mit einem vorhersehbaren jährlichen Zyklus weiterentwickeln sollen . Für das Update im ersten Jahr erwarten wir möglicherweise, dass First Contentful Paint zu Core Web Vitals befördert wird, einen niedrigeren FID-Schwellenwert und eine bessere Unterstützung für Single-Page-Anwendungen. Wir könnten auch sehen, dass die Reaktion auf Benutzereingaben nach der Last mehr Gewicht gewinnt, zusammen mit Überlegungen zu Sicherheit, Datenschutz und Zugänglichkeit (!).
Im Zusammenhang mit Core Web Vitals gibt es viele nützliche Ressourcen und Artikel, die einen Blick wert sind:
- Mit dem Web Vitals Leaderboard können Sie Ihre Punktzahlen mit der Konkurrenz auf Mobilgeräten, Tablets, Desktops sowie über 3G und 4G vergleichen.
- Core SERP Vitals, eine Chrome-Erweiterung, die die Core Web Vitals von CrUX in den Google-Suchergebnissen anzeigt.
- Layout Shift GIF Generator, der CLS mit einem einfachen GIF visualisiert (auch über die Befehlszeile verfügbar).
- Die Web-Vitals-Bibliothek kann Core Web Vitals sammeln und an Google Analytics, Google Tag Manager oder einen anderen Analyse-Endpunkt senden.
- Analyse von Web Vitals mit WebPageTest, in der Patrick Meenan untersucht, wie WebPageTest Daten über Core Web Vitals offenlegt.
- Optimizing with Core Web Vitals, ein 50-minütiges Video mit Addy Osmani, in dem er in einer E-Commerce-Fallstudie aufzeigt, wie Core Web Vitals verbessert werden kann.
- Cumulative Layout Shift in Practice und Cumulative Layout Shift in the Real World sind umfassende Artikel von Nic Jansma, die so ziemlich alles über CLS abdecken und wie es mit Schlüsselkennzahlen wie Bounce Rate, Session Time oder Rage Clicks korreliert.
- What Forces Reflow, mit einem Überblick über Eigenschaften oder Methoden, wenn sie in JavaScript angefordert/aufgerufen werden, die den Browser dazu veranlassen, den Stil und das Layout synchron zu berechnen.
- CSS-Trigger zeigt, welche CSS-Eigenschaften Layout, Paint und Composite auslösen.
- Layout-Instabilität beheben ist eine exemplarische Vorgehensweise zur Verwendung von WebPageTest zum Identifizieren und Beheben von Layout-Instabilitätsproblemen.
- Cumulative Layout Shift, The Layout Instability Metric, ein weiterer sehr detaillierter Leitfaden von Boris Schapira über CLS, wie es berechnet wird, wie man es misst und wie man es optimiert.
- How To Improve Core Web Vitals, ein detaillierter Leitfaden von Simon Hearne zu jeder der Metriken (einschließlich anderer Web Vitals wie FCP, TTI, TBT), wann sie auftreten und wie sie gemessen werden.
Sind Core Web Vitals also die ultimativen Metriken, denen man folgen sollte ? Nicht ganz. Sie sind in der Tat bereits in den meisten RUM-Lösungen und -Plattformen verfügbar, darunter Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in der Filmstreifenansicht bereits), Newrelic, Shopify, Next.js, alle Google-Tools (PageSpeed Insights, Lighthouse + CI, Search Konsole usw.) und viele andere.
Wie Katie Sylor-Miller erklärt, sind einige der Hauptprobleme mit Core Web Vitals jedoch der Mangel an browserübergreifender Unterstützung, wir messen nicht wirklich den gesamten Lebenszyklus der Benutzererfahrung, außerdem ist es schwierig, Änderungen in FID und zu korrelieren CLS mit Geschäftsergebnissen.
Da wir davon ausgehen sollten, dass sich Core Web Vitals weiterentwickeln wird, erscheint es nur vernünftig, Web Vitals immer mit Ihren maßgeschneiderten Metriken zu kombinieren , um besser zu verstehen, wo Sie in Bezug auf die Leistung stehen.
- Largest Contentful Paint ( LCP ) < 2,5 Sek.
- Sammeln Sie Daten auf einem für Ihre Zielgruppe repräsentativen Gerät.
Um genaue Daten zu sammeln, müssen wir die Geräte zum Testen sorgfältig auswählen. In den meisten Unternehmen bedeutet dies, sich mit Analysen zu befassen und Benutzerprofile basierend auf den gängigsten Gerätetypen zu erstellen. Analysen allein liefern jedoch oft kein vollständiges Bild. Ein erheblicher Teil der Zielgruppe verlässt die Website möglicherweise (und kehrt nicht zurück), nur weil ihre Erfahrung zu langsam ist, und ihre Geräte werden aus diesem Grund wahrscheinlich nicht als die beliebtesten Geräte in Analysen angezeigt. Es kann also eine gute Idee sein, zusätzlich zu gängigen Geräten in Ihrer Zielgruppe zu recherchieren.Laut IDC sind im Jahr 2020 weltweit 84,8 % aller ausgelieferten Mobiltelefone Android-Geräte. Ein durchschnittlicher Verbraucher rüstet sein Telefon alle 2 Jahre auf, und in den USA beträgt der Austauschzyklus für Telefone 33 Monate. Die durchschnittlichen Bestseller-Telefone auf der ganzen Welt kosten weniger als 200 US-Dollar.
Ein repräsentatives Gerät ist also ein Android-Gerät, das mindestens 24 Monate alt ist, 200 US-Dollar oder weniger kostet und mit langsamem 3G, 400 ms RTT und 400 kbps Übertragung läuft, um nur etwas pessimistischer zu sein. Dies kann für Ihr Unternehmen natürlich ganz anders sein, aber das ist eine ziemlich gute Annäherung an die Mehrheit der Kunden da draußen. Tatsächlich könnte es eine gute Idee sein, sich die aktuellen Amazon-Bestseller für Ihren Zielmarkt anzusehen. ( Danke an Tim Kadlec, Henri Helvetica und Alex Russell für die Hinweise! ).
Überprüfen Sie beim Erstellen einer neuen Website oder App immer zuerst die aktuellen Amazon-Bestseller für Ihren Zielmarkt. (Große Vorschau) Welche Testgeräte wählen Sie dann? Diejenigen, die gut zu dem oben skizzierten Profil passen. Es ist eine gute Option, ein etwas älteres Moto G4/G5 Plus, ein Samsung-Mittelklassegerät (Galaxy A50, S8), ein gutes Mittelklassegerät wie ein Nexus 5X, ein Xiaomi Mi A3 oder ein Xiaomi Redmi Note zu wählen 7 und ein langsames Gerät wie Alcatel 1X oder Cubot X19, vielleicht in einem offenen Gerätelabor. Zum Testen auf langsameren thermisch gedrosselten Geräten können Sie auch ein Nexus 4 erwerben, das nur etwa 100 US-Dollar kostet.
Überprüfen Sie auch die in jedem Gerät verwendeten Chipsätze und stellen Sie einen Chipsatz nicht überrepräsentiert dar : Ein paar Generationen von Snapdragon und Apple sowie Low-End-Rockchip, Mediatek würden ausreichen (danke, Patrick!) .
Wenn Sie kein Gerät zur Hand haben, emulieren Sie das mobile Erlebnis auf dem Desktop, indem Sie es in einem gedrosselten 3G-Netzwerk (z. B. 300 ms RTT, 1,6 Mbps down, 0,8 Mbps up) mit einer gedrosselten CPU (5-fache Verlangsamung) testen. Wechseln Sie schließlich zu normalem 3G, langsamem 4G (z. B. 170 ms RTT, 9 Mbit/s Down, 9 Mbit/s Up) und Wi-Fi. Um die Auswirkungen auf die Leistung sichtbarer zu machen, könnten Sie sogar dienstags 2G einführen oder ein gedrosseltes 3G/4G-Netzwerk in Ihrem Büro für schnellere Tests einrichten.
Denken Sie daran, dass wir auf einem mobilen Gerät im Vergleich zu Desktop-Computern mit einer 4- bis 5-fachen Verlangsamung rechnen sollten. Mobilgeräte haben unterschiedliche GPUs, CPU, Speicher und unterschiedliche Akkueigenschaften. Deshalb ist es wichtig, ein gutes Profil eines durchschnittlichen Geräts zu haben und immer auf einem solchen Gerät zu testen.
- Synthetische Testwerkzeuge sammeln Labordaten in einer reproduzierbaren Umgebung mit vordefinierten Geräte- und Netzwerkeinstellungen (z. B. Lighthouse , Calibre , WebPageTest ) und
- Real User Monitoring ( RUM ) Tools werten Benutzerinteraktionen kontinuierlich aus und sammeln Felddaten (z. B. SpeedCurve , New Relic – die Tools bieten auch synthetische Tests).
- Verwenden Sie Lighthouse CI, um Lighthouse-Ergebnisse im Laufe der Zeit zu verfolgen (es ist ziemlich beeindruckend),
- Führen Sie Lighthouse in GitHub Actions aus, um neben jeder PR einen Lighthouse-Bericht zu erhalten.
- Führen Sie auf jeder Seite einer Website (über Lightouse Parade) eine Lighthouse-Leistungsprüfung durch, wobei die Ausgabe als CSV gespeichert wird.
- Verwenden Sie Lighthouse Scores Calculator und Lighthouse-Metrikgewichte, wenn Sie mehr ins Detail gehen müssen.
- Lighthouse ist auch für Firefox verfügbar, aber unter der Haube verwendet es die PageSpeed Insights API und generiert einen Bericht basierend auf einem Headless Chrome 79 User-Agent.

Glücklicherweise gibt es viele großartige Optionen, mit denen Sie die Datenerfassung automatisieren und anhand dieser Metriken messen können, wie Ihre Website im Laufe der Zeit abschneidet. Denken Sie daran, dass ein gutes Leistungsbild eine Reihe von Leistungsmetriken, Labordaten und Felddaten abdeckt:
Ersteres ist während der Entwicklung besonders nützlich, da es Ihnen hilft, Leistungsprobleme zu identifizieren, zu isolieren und zu beheben, während Sie am Produkt arbeiten. Letzteres ist nützlich für die langfristige Wartung , da es Ihnen hilft, Ihre Leistungsengpässe zu verstehen, wenn sie live auftreten – wenn Benutzer tatsächlich auf die Website zugreifen.
Durch die Nutzung integrierter RUM-APIs wie Navigation Timing, Resource Timing, Paint Timing, Long Tasks usw. bieten synthetische Testwerkzeuge und RUM zusammen ein vollständiges Bild der Leistung Ihrer Anwendung. Sie könnten Calibre, Treo, SpeedCurve, mPulse und Boomerang, Sitespeed.io verwenden, die alle großartige Optionen für die Leistungsüberwachung sind. Darüber hinaus können Sie mit dem Server-Timing-Header sogar die Back-End- und Front-End-Leistung an einem Ort überwachen.
Hinweis : Es ist immer sicherer, Drosselklappen auf Netzwerkebene außerhalb des Browsers zu wählen, da beispielsweise DevTools aufgrund der Art und Weise, wie es implementiert ist, Probleme bei der Interaktion mit HTTP/2-Push hat ( danke, Yoav, Patrick !). Für Mac OS können wir Network Link Conditioner verwenden, für Windows Windows Traffic Shaper, für Linux netem und für FreeBSD dummynet.
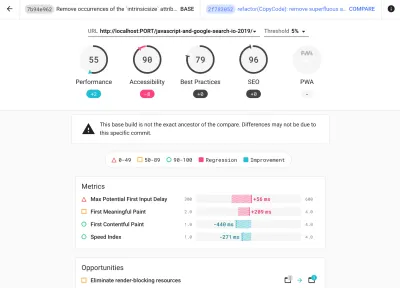
Da Sie wahrscheinlich in Lighthouse testen werden, denken Sie daran, dass Sie Folgendes tun können:
- Richten Sie zum Testen „saubere“ und „Kunden“-Profile ein.
Beim Ausführen von Tests in passiven Überwachungstools ist es eine gängige Strategie, Antiviren- und Hintergrund-CPU-Aufgaben zu deaktivieren, Bandbreitenübertragungen im Hintergrund zu entfernen und mit einem sauberen Benutzerprofil ohne Browsererweiterungen zu testen, um verzerrte Ergebnisse zu vermeiden (in Firefox und in Chrome).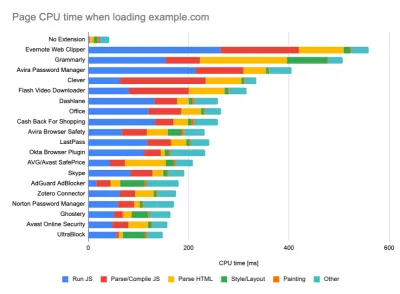
Der Bericht von DebugBear hebt die 20 langsamsten Erweiterungen hervor, darunter Passwortmanager, Werbeblocker und beliebte Anwendungen wie Evernote und Grammarly. (Große Vorschau) Es ist jedoch auch eine gute Idee, zu untersuchen, welche Browsererweiterungen Ihre Kunden häufig verwenden, und dies auch mit dedizierten „Kunden“-Profilen zu testen. Tatsächlich können einige Erweiterungen tiefgreifende Auswirkungen auf die Leistung Ihrer Anwendung haben (Chrome Extension Performance Report 2020), und wenn Ihre Benutzer sie häufig verwenden, sollten Sie dies möglicherweise im Voraus berücksichtigen. Daher sind "saubere" Profilergebnisse allein zu optimistisch und können in realen Szenarien zerstört werden.
- Teilen Sie die Leistungsziele mit Ihren Kollegen.
Stellen Sie sicher, dass die Leistungsziele jedem Mitglied Ihres Teams bekannt sind, um spätere Missverständnisse zu vermeiden. Jede Entscheidung – sei es Design, Marketing oder irgendetwas dazwischen – hat Auswirkungen auf die Leistung , und die Verteilung von Verantwortung und Eigenverantwortung auf das gesamte Team würde spätere leistungsorientierte Entscheidungen rationalisieren. Ordnen Sie Designentscheidungen dem Leistungsbudget und den früh definierten Prioritäten zu.
Realistische Ziele setzen
- 100 Millisekunden Reaktionszeit, 60 fps.
Damit sich eine Interaktion reibungslos anfühlt, hat die Benutzeroberfläche 100 ms Zeit, um auf Benutzereingaben zu reagieren. Länger als das, und der Benutzer nimmt die App als verzögert wahr. Das RAIL, ein benutzerzentriertes Leistungsmodell, gibt Ihnen gesunde Ziele : Um eine Antwort von <100 Millisekunden zu ermöglichen, muss die Seite spätestens alle <50 Millisekunden die Kontrolle an den Haupt-Thread zurückgeben. Die geschätzte Eingangslatenz sagt uns, ob wir diesen Schwellenwert erreichen, und idealerweise sollte er unter 50 ms liegen. Für Hochdruckpunkte wie Animationen ist es am besten, nichts anderes zu tun, wo Sie können, und das absolute Minimum, wo Sie es nicht können.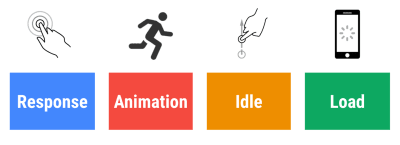
RAIL, ein benutzerorientiertes Leistungsmodell. Außerdem sollte jeder Frame der Animation in weniger als 16 Millisekunden abgeschlossen sein, wodurch 60 Frames pro Sekunde erreicht werden (1 Sekunde ÷ 60 = 16,6 Millisekunden) – vorzugsweise unter 10 Millisekunden. Da der Browser Zeit benötigt, um den neuen Frame auf dem Bildschirm anzuzeigen, sollte Ihr Code die Ausführung beenden, bevor er die 16,6-Millisekunden-Marke erreicht. Wir fangen an, Gespräche über 120 fps zu führen (z. B. laufen die Bildschirme des iPad Pro mit 120 Hz) und Surma hat einige Rendering-Performance-Lösungen für 120 fps behandelt, aber das ist wahrscheinlich noch kein Ziel, das wir uns ansehen.
Seien Sie pessimistisch in Bezug auf die Leistungserwartungen, aber optimistisch im Schnittstellendesign und nutzen Sie die Leerlaufzeit mit Bedacht (überprüfen Sie Idle, Idle-Til-Urgent und React-Idle). Offensichtlich beziehen sich diese Ziele eher auf die Laufzeitleistung als auf die Ladeleistung.
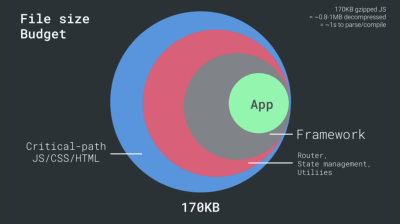
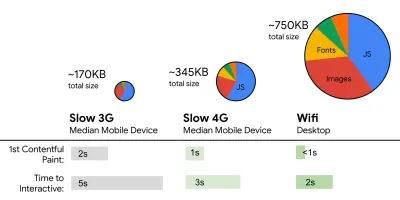
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s bei 3G, kritisches Dateigrößenbudget < 170 KB (gzipped).
Obwohl es sehr schwierig zu erreichen sein mag, wäre ein gutes Endziel eine Zeit bis zur Interaktion unter 5 Sekunden, und für wiederholte Besuche sollten Sie unter 2 Sekunden anstreben (nur mit einem Servicemitarbeiter erreichbar). Streben Sie den größten Contentful Paint von weniger als 2,5 Sekunden an und minimieren Sie die Gesamtblockierzeit und die kumulative Layoutverschiebung . Eine akzeptable erste Eingangsverzögerung liegt unter 100 ms–70 ms. Wie oben erwähnt, betrachten wir als Basis ein 200-Dollar-Android-Telefon (z. B. Moto G4) in einem langsamen 3G-Netzwerk, das mit 400 ms RTT und 400 kbps Übertragungsgeschwindigkeit emuliert wird.Wir haben zwei Hauptbeschränkungen, die effektiv ein vernünftiges Ziel für die schnelle Bereitstellung von Inhalten im Web formen. Einerseits haben wir Einschränkungen bei der Netzwerkbereitstellung aufgrund von TCP Slow Start. Die ersten 14 KB des HTML-Codes – 10 TCP-Pakete mit jeweils 1460 Byte, was ungefähr 14,25 KB entspricht, wenn auch nicht wörtlich zu nehmen – ist der kritischste Teil der Nutzlast und der einzige Teil des Budgets, der im ersten Roundtrip geliefert werden kann ( das ist alles, was Sie aufgrund der mobilen Weckzeiten in 1 Sekunde bei 400 ms RTT erhalten).
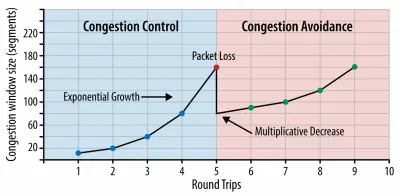
Bei TCP-Verbindungen beginnen wir mit einem kleinen Überlastungsfenster und verdoppeln es für jeden Roundtrip. Beim allerersten Roundtrip können wir 14 KB unterbringen. Aus: High Performance Browser Networking von Ilya Grigorik. (Große Vorschau) ( Anmerkung : Da TCP die Netzwerkverbindung im Allgemeinen erheblich unterauslastet, hat Google die TCP-Flaschenhalsbandbreite und RRT ( BBR ) entwickelt, einen verzögerungsgesteuerten TCP-Flusssteuerungsalgorithmus für TCP. Entwickelt für das moderne Web, reagiert er auf tatsächliche Überlastung, Anstelle von Paketverlusten wie bei TCP ist es deutlich schneller, mit höherem Durchsatz und geringerer Latenz – und der Algorithmus funktioniert anders. ( Danke, Victor, Barry! )
Auf der anderen Seite haben wir aufgrund von JavaScript-Parsing und Ausführungszeiten Hardwarebeschränkungen für Speicher und CPU (wir werden später ausführlich darauf eingehen). Um die im ersten Absatz genannten Ziele zu erreichen, müssen wir das kritische Dateigrößenbudget für JavaScript berücksichtigen. Es gibt unterschiedliche Meinungen darüber, wie hoch dieses Budget sein sollte (und es hängt stark von der Art Ihres Projekts ab), aber ein Budget von 170 KB, das bereits mit JavaScript gzippt ist, würde bis zu 1 Sekunde dauern, um es auf einem Mittelklasse-Telefon zu analysieren und zu kompilieren. Unter der Annahme, dass 170 KB beim Dekomprimieren auf das Dreifache (0,7 MB) erweitert werden, könnte dies bereits der Todesstoß für eine "anständige" Benutzererfahrung auf einem Moto G4 / G5 Plus sein.
Im Fall der Wikipedia-Website ist die Codeausführung im Jahr 2020 für Wikipedia-Benutzer weltweit um 19 % schneller geworden. Wenn also Ihre Web-Performance-Metriken im Jahresvergleich stabil bleiben, ist dies normalerweise ein Warnzeichen, da Sie tatsächlich einen Rückschritt machen, wenn sich die Umgebung weiter verbessert (Details in einem Blog-Beitrag von Gilles Dubuc).
Wenn Sie auf wachsende Märkte wie Südostasien, Afrika oder Indien abzielen möchten, müssen Sie sich mit ganz anderen Einschränkungen befassen. Addy Osmani behandelt die wichtigsten Einschränkungen von Feature-Phones, wie z. B. wenige kostengünstige, hochwertige Geräte, die Nichtverfügbarkeit hochwertiger Netzwerke und teure mobile Daten – zusammen mit PRPL-30-Budget- und Entwicklungsrichtlinien für diese Umgebungen.
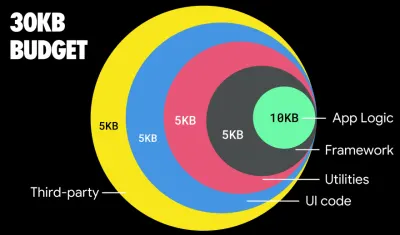
Laut Addy Osmani beträgt eine empfohlene Größe für Lazy-Loaded-Routen ebenfalls weniger als 35 KB. (Große Vorschau) 
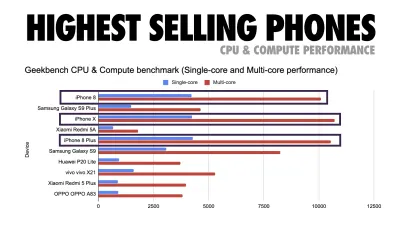
Addy Osmani schlägt ein PRPL-30-Leistungsbudget (30 KB gezipptes + verkleinertes Anfangspaket) vor, wenn es auf ein Feature-Phone abzielt. (Große Vorschau) Tatsächlich empfiehlt Alex Russell von Google, gzipped 130–170 KB als vernünftige Obergrenze anzustreben. In realen Szenarien sind die meisten Produkte nicht einmal annähernd so groß: Die durchschnittliche Paketgröße liegt heute bei etwa 452 KB, was einem Anstieg von 53,6 % im Vergleich zu Anfang 2015 entspricht. Auf einem Mittelklasse-Mobilgerät macht das 12 bis 20 Sekunden für Time aus -Zu-Interaktiv .
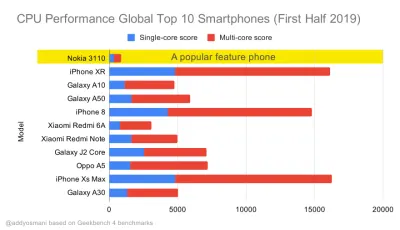
Geekbench-CPU-Leistungsbenchmarks für die meistverkauften Smartphones weltweit im Jahr 2019. JavaScript betont die Single-Core-Leistung (denken Sie daran, dass es von Natur aus mehr Single-Threaded ist als der Rest der Webplattform) und CPU-gebunden ist. Aus Addys Artikel „Schnelles Laden von Webseiten auf einem 20-Dollar-Feature-Phone“. (Große Vorschau) Wir könnten aber auch über das Budget der Bundle-Größe hinausgehen. Zum Beispiel könnten wir Leistungsbudgets basierend auf den Aktivitäten des Haupt-Threads des Browsers festlegen, dh Malzeit vor dem Start des Renderns, oder Front-End-CPU-Hogs aufspüren. Tools wie Calibre, SpeedCurve und Bundlesize können Ihnen dabei helfen, Ihr Budget im Griff zu behalten, und können in Ihren Build-Prozess integriert werden.
Schließlich sollte ein Leistungsbudget wahrscheinlich kein fester Wert sein . Abhängig von der Netzwerkverbindung sollten sich die Leistungsbudgets anpassen, aber die Nutzlast auf einer langsameren Verbindung ist viel "teurer", unabhängig davon, wie sie verwendet wird.
Hinweis : Es mag seltsam klingen, in Zeiten von weit verbreitetem HTTP/2, kommendem 5G und HTTP/3, sich schnell entwickelnden Mobiltelefonen und florierenden SPAs so starre Budgets festzulegen. Sie klingen jedoch vernünftig, wenn wir uns mit der unvorhersehbaren Natur des Netzwerks und der Hardware befassen, einschließlich allem, von überlasteten Netzwerken über sich langsam entwickelnde Infrastruktur bis hin zu Datenbeschränkungen, Proxy-Browsern, Save-Data-Modus und hinterhältigen Roaming-Gebühren.
Die Umgebung definieren
- Wählen Sie Ihre Build-Tools aus und richten Sie sie ein.
Achte heutzutage nicht zu sehr auf das, was angeblich cool ist. Halten Sie sich zum Erstellen an Ihre Umgebung, sei es Grunt, Gulp, Webpack, Parcel oder eine Kombination von Tools. Solange Sie die gewünschten Ergebnisse erzielen und keine Probleme haben, Ihren Build-Prozess aufrechtzuerhalten, geht es Ihnen gut.Unter den Build-Tools gewinnt Rollup immer mehr an Zugkraft, ebenso wie Snowpack, aber Webpack scheint das etablierteste zu sein, mit buchstäblich Hunderten von Plugins, die verfügbar sind, um die Größe Ihrer Builds zu optimieren. Achten Sie auf die Webpack-Roadmap 2021.
Eine der bemerkenswertesten Strategien, die kürzlich erschienen sind, ist Granular Chunking mit Webpack in Next.js und Gatsby, um doppelten Code zu minimieren. Standardmäßig können Module, die nicht an jedem Einstiegspunkt gemeinsam genutzt werden, für Routen angefordert werden, die ihn nicht verwenden. Dies führt zu einem Overhead, da mehr Code als nötig heruntergeladen wird. Mit dem granularen Chunking in Next.js können wir eine serverseitige Build-Manifestdatei verwenden , um zu bestimmen, welche ausgegebenen Chunks von verschiedenen Einstiegspunkten verwendet werden.
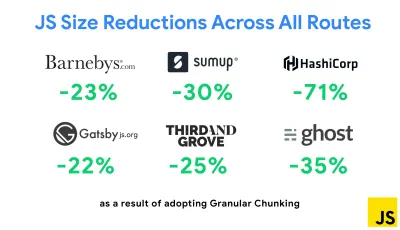
Um doppelten Code in Webpack-Projekten zu reduzieren, können wir granulares Chunking verwenden, das standardmäßig in Next.js und Gatsby aktiviert ist. Bildnachweis: Addy Osmani. (Große Vorschau) Mit SplitChunksPlugin werden abhängig von einer Reihe von Bedingungen mehrere Split-Chunks erstellt, um zu verhindern, dass duplizierter Code über mehrere Routen abgerufen wird. Dies verbessert die Seitenladezeit und das Caching während der Navigation. Ausgeliefert in Next.js 9.2 und in Gatsby v2.20.7.
Der Einstieg in Webpack kann jedoch schwierig sein. Wenn Sie also in Webpack eintauchen möchten, gibt es einige großartige Ressourcen:
- Die Webpack-Dokumentation ist – offensichtlich – ein guter Ausgangspunkt, ebenso wie Webpack – The Confusing Bits von Raja Rao und An Annotated Webpack Config von Andrew Welch.
- Sean Larkin hat einen kostenlosen Kurs zu Webpack: The Core Concepts und Jeffrey Way hat einen fantastischen kostenlosen Kurs zu Webpack für alle veröffentlicht. Beide sind großartige Einführungen, um in Webpack einzutauchen.
- Webpack Fundamentals ist ein sehr umfassender 4-stündiger Kurs mit Sean Larkin, veröffentlicht von FrontendMasters.
- Webpack-Beispiele enthält Hunderte von gebrauchsfertigen Webpack-Konfigurationen, kategorisiert nach Thema und Zweck. Bonus: Es gibt auch einen Webpack-Konfigurationskonfigurator, der eine grundlegende Konfigurationsdatei generiert.
- awesome-webpack ist eine kuratierte Liste nützlicher Webpack-Ressourcen, Bibliotheken und Tools, einschließlich Artikeln, Videos, Kursen, Büchern und Beispielen für Angular-, React- und Framework-unabhängige Projekte.
- Der Weg zu schnellen Produktions-Asset-Builds mit Webpack ist Etsys Fallstudie darüber, wie das Team von der Verwendung eines RequireJS-basierten JavaScript-Build-Systems zur Verwendung von Webpack wechselte und wie es seine Builds optimierte und dabei über 13.200 Assets in durchschnittlich 4 Minuten verwaltete.
- Webpack-Leistungstipps ist ein Goldminen-Thread von Ivan Akulov, der viele leistungsorientierte Tipps enthält, darunter auch solche, die sich speziell auf Webpack konzentrieren.
- awesome-webpack-perf ist ein Goldminen-GitHub-Repo mit nützlichen Webpack-Tools und Plugins für die Leistung. Auch gepflegt von Ivan Akulov.
- Verwenden Sie standardmäßig die progressive Verbesserung.
Dennoch ist es nach all diesen Jahren eine sichere Sache, die progressive Verbesserung als Leitprinzip Ihrer Front-End-Architektur und -Bereitstellung beizubehalten. Entwerfen und erstellen Sie zuerst das Kernerlebnis und verbessern Sie dann das Erlebnis mit erweiterten Funktionen für leistungsfähige Browser, um belastbare Erlebnisse zu schaffen. Wenn Ihre Website auf einem langsamen Computer mit einem schlechten Bildschirm in einem schlechten Browser in einem suboptimalen Netzwerk schnell läuft, dann wird sie nur auf einem schnellen Computer mit einem guten Browser in einem anständigen Netzwerk schneller laufen.Tatsächlich scheinen wir mit dem adaptiven Modulserving die progressive Verbesserung auf eine andere Ebene zu heben, „leichte“ Kernerlebnisse für Low-End-Geräte bereitzustellen und mit ausgefeilteren Funktionen für High-End-Geräte zu verbessern. Die progressive Verbesserung wird wahrscheinlich in absehbarer Zeit nicht verschwinden.
- Wählen Sie eine starke Leistungsbaseline.
Bei so vielen Unbekannten, die sich auf das Laden auswirken – das Netzwerk, thermische Drosselung, Cache-Eviction, Skripte von Drittanbietern, Parser-Blockierungsmuster, Festplatten-E/A, IPC-Latenz, installierte Erweiterungen, Antivirensoftware und Firewalls, Hintergrund-CPU-Aufgaben, Hardware- und Speichereinschränkungen, Unterschiede beim L2/L3-Caching, RTTS – JavaScript hat die höchsten Kosten der Erfahrung, neben Webfonts, die standardmäßig das Rendern blockieren, und Bildern, die oft zu viel Speicher verbrauchen. Da sich die Leistungsengpässe vom Server zum Client verlagern, müssen wir als Entwickler all diese Unbekannten viel detaillierter berücksichtigen.Mit einem Budget von 170 KB, das bereits den kritischen Pfad HTML/CSS/JavaScript, Router, Zustandsverwaltung, Dienstprogramme, Framework und die Anwendungslogik enthält, müssen wir die Netzwerkübertragungskosten, die Parsing-/Kompilierungszeit und die Laufzeitkosten gründlich untersuchen des Rahmens unserer Wahl. Glücklicherweise haben wir in den letzten Jahren eine enorme Verbesserung gesehen, wie schnell Browser Skripte parsen und kompilieren können. Die Ausführung von JavaScript ist jedoch immer noch der Hauptengpass, daher kann es von großer Bedeutung sein, auf die Skriptausführungszeit und das Netzwerk zu achten.
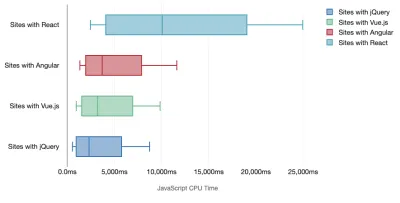
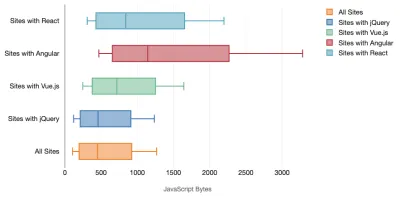
Tim Kadlec hat eine fantastische Recherche zur Leistungsfähigkeit moderner Frameworks durchgeführt und diese in dem Artikel „JavaScript-Frameworks haben ihren Preis“ zusammengefasst. Wir sprechen oft über die Auswirkungen eigenständiger Frameworks, aber wie Tim anmerkt, ist es in der Praxis nicht ungewöhnlich, mehrere Frameworks zu verwenden . Vielleicht eine ältere Version von jQuery, die langsam auf ein modernes Framework migriert wird, zusammen mit einigen Legacy-Anwendungen, die eine ältere Version von Angular verwenden. Daher ist es sinnvoller, die kumulativen Kosten von JavaScript-Bytes und CPU-Ausführungszeit zu untersuchen, die Benutzererfahrungen selbst auf High-End-Geräten leicht kaum nutzbar machen können.
Im Allgemeinen priorisieren moderne Frameworks weniger leistungsstarke Geräte nicht , sodass sich die Erfahrungen auf einem Telefon und auf dem Desktop in Bezug auf die Leistung oft dramatisch unterscheiden. Untersuchungen zufolge verbringen Websites mit React oder Angular mehr Zeit auf der CPU als andere (was natürlich nicht unbedingt heißt, dass React auf der CPU teurer ist als Vue.js).
Laut Tim ist eines offensichtlich: „Wenn Sie ein Framework zum Erstellen Ihrer Website verwenden, gehen Sie einen Kompromiss in Bezug auf die anfängliche Leistung ein – selbst in den besten Szenarien.“
- Bewerten Sie Frameworks und Abhängigkeiten.
Nun braucht nicht jedes Projekt ein Framework und nicht jede Seite einer Single-Page-Anwendung muss ein Framework laden. Im Fall von Netflix „reduzierte das Entfernen von React, mehreren Bibliotheken und dem entsprechenden App-Code von der Client-Seite die Gesamtmenge an JavaScript um über 200 KB, was zu einer über 50-prozentigen Reduzierung der Time-to-Interactivity von Netflix für die abgemeldete Homepage führte ." Das Team nutzte dann die Zeit, die Benutzer auf der Zielseite verbrachten, um React für nachfolgende Seiten vorab abzurufen, auf denen Benutzer wahrscheinlich landen würden (lesen Sie weiter für Details).Was also, wenn Sie ein vorhandenes Framework auf kritischen Seiten vollständig entfernen? Mit Gatsby können Sie gatsby-plugin-no-javascript überprüfen, das alle von Gatsby erstellten JavaScript-Dateien aus den statischen HTML-Dateien entfernt. Auf Vercel können Sie auch das Deaktivieren von Laufzeit-JavaScript in der Produktion für bestimmte Seiten zulassen (experimentell).
Sobald ein Framework ausgewählt ist, bleiben wir mindestens ein paar Jahre dabei. Wenn wir also eines verwenden müssen, müssen wir sicherstellen, dass unsere Wahl fundiert und wohlüberlegt ist – und das gilt insbesondere für wichtige Leistungsmetriken, die wir verwenden Wert darauf legen.
Die Daten zeigen, dass Frameworks standardmäßig ziemlich teuer sind: 58,6 % der React-Seiten liefern mehr als 1 MB JavaScript, und 36 % der Vue.js-Seitenladevorgänge haben einen First Contentful Paint von <1,5 s. Laut einer Studie von Ankur Sethi „ wird Ihre React-Anwendung auf einem durchschnittlichen Telefon in Indien nie schneller als etwa 1,1 Sekunden laden , egal wie stark Sie sie optimieren. Ihre Angular-App benötigt immer mindestens 2,7 Sekunden zum Hochfahren Benutzer Ihrer Vue-App müssen mindestens 1 Sekunde warten, bevor sie sie verwenden können." Möglicherweise zielen Sie ohnehin nicht auf Indien als Ihren Hauptmarkt ab, aber Benutzer, die mit suboptimalen Netzwerkbedingungen auf Ihre Website zugreifen, werden eine vergleichbare Erfahrung machen.
Natürlich ist es möglich, SPAs schnell zu machen, aber sie sind nicht sofort einsatzbereit, also müssen wir den Zeit- und Arbeitsaufwand berücksichtigen, der erforderlich ist, um sie schnell zu machen und zu halten . Es wird wahrscheinlich einfacher sein, wenn Sie sich frühzeitig für geringe Basisleistungskosten entscheiden.
Wie wählen wir also einen Rahmen aus ? Es ist eine gute Idee, zumindest die Gesamtkosten für Größe + anfängliche Ausführungszeiten zu berücksichtigen, bevor Sie sich für eine Option entscheiden. leichte Optionen wie Preact, Inferno, Vue, Svelte, Alpine oder Polymer können die Arbeit gut erledigen. Die Größe Ihrer Baseline definiert die Einschränkungen für den Code Ihrer Anwendung.
Wie von Seb Markbage angemerkt, besteht eine gute Möglichkeit, die Anlaufkosten für Frameworks zu messen, darin, zuerst eine Ansicht zu rendern, sie dann zu löschen und dann erneut zu rendern, da dies Aufschluss darüber gibt, wie das Framework skaliert. Das erste Rendern neigt dazu, einen Haufen faul kompilierten Codes aufzuwärmen, von dem ein größerer Baum profitieren kann, wenn er skaliert. Das zweite Rendering ist im Grunde eine Emulation dessen, wie sich die Wiederverwendung von Code auf einer Seite auf die Leistungsmerkmale auswirkt, wenn die Seite an Komplexität zunimmt.
Sie könnten so weit gehen, Ihre Kandidaten (oder jede JavaScript-Bibliothek im Allgemeinen) auf dem 12-Punkte-Bewertungssystem von Sacha Greif zu bewerten, indem Sie Funktionen, Zugänglichkeit, Stabilität, Leistung, Paket-Ökosystem , Community, Lernkurve, Dokumentation, Werkzeuge und Erfolgsbilanz untersuchen , Team, Kompatibilität, Sicherheit zum Beispiel.
Perf Track verfolgt die Framework-Leistung im großen Maßstab. (Große Vorschau) Sie können sich auch auf Daten verlassen, die über einen längeren Zeitraum im Web gesammelt wurden. Beispielsweise verfolgt Perf Track die Framework-Leistung in großem Maßstab und zeigt ursprungsaggregierte Core Web Vitals -Ergebnisse für Websites, die in Angular, React, Vue, Polymer, Preact, Ember, Svelte und AMP erstellt wurden. Sie können sogar Websites angeben und vergleichen, die mit Gatsby, Next.js oder Create React App erstellt wurden, sowie Websites, die mit Nuxt.js (Vue) oder Sapper (Svelte) erstellt wurden.
Ein guter Ausgangspunkt ist die Auswahl eines guten Standardstapels für Ihre Anwendung. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI und PWA Starter Kit bieten vernünftige Standardwerte für schnelles Laden auf durchschnittlicher mobiler Hardware. Werfen Sie auch einen Blick auf die web.dev Framework-spezifischen Performance-Anleitungen für React und Angular ( Danke, Phillip! ).
Und vielleicht könnten Sie einen etwas erfrischenderen Ansatz zum Erstellen von Single-Page-Anwendungen insgesamt wählen – Turbolinks, eine 15-KB-JavaScript-Bibliothek, die HTML anstelle von JSON zum Rendern von Ansichten verwendet. Wenn Sie also einem Link folgen, ruft Turbolinks automatisch die Seite ab, tauscht ihren
<body>aus und fügt ihren<head>zusammen, ohne dass die Kosten für das Laden einer vollständigen Seite anfallen. Sie können schnelle Details und die vollständige Dokumentation über den Stack (Hotwire) überprüfen.
- Clientseitiges Rendering oder serverseitiges Rendering? Beide!
Das ist ein ziemlich hitziges Gespräch. Der ultimative Ansatz wäre, eine Art progressives Booten einzurichten: Verwenden Sie serverseitiges Rendering, um ein schnelles First Contentful Paint zu erhalten, aber fügen Sie auch etwas minimal notwendiges JavaScript hinzu, um die Zeit bis zur Interaktion nahe am First Contentful Paint zu halten. Wenn JavaScript zu spät nach dem FCP kommt, sperrt der Browser den Haupt-Thread, während spät entdecktes JavaScript analysiert, kompiliert und ausgeführt wird, wodurch die Interaktivität der Website oder Anwendung Handschellen erhält.Um dies zu vermeiden, unterteilen Sie die Ausführung von Funktionen immer in separate, asynchrone Aufgaben und verwenden Sie nach Möglichkeit
requestIdleCallback. Erwägen Sie das verzögerte Laden von Teilen der Benutzeroberfläche mithilfe der dynamischenimport()-Unterstützung von WebPack, um die Kosten für das Laden, Analysieren und Kompilieren zu vermeiden, bis die Benutzer sie wirklich brauchen ( danke Addy! ).Wie oben erwähnt, sagt uns Time to Interactive (TTI) die Zeit zwischen Navigation und Interaktivität. Im Detail wird die Metrik definiert, indem das erste Fünf-Sekunden-Fenster nach dem Rendern des anfänglichen Inhalts betrachtet wird, in dem keine JavaScript-Aufgaben länger als 50 ms dauern ( Long Tasks ). Wenn eine Aufgabe über 50 ms auftritt, beginnt die Suche nach einem Fünf-Sekunden-Fenster von vorne. Infolgedessen geht der Browser zunächst davon aus, dass er Interactive erreicht hat, nur um zu Frozen zu wechseln, nur um schließlich wieder zu Interactive zu wechseln.
Sobald wir Interactive erreicht haben, können wir dann – entweder bei Bedarf oder wenn es die Zeit erlaubt – unwesentliche Teile der App booten. Wie Paul Lewis feststellte, haben Frameworks leider kein einfaches Prioritätskonzept, das Entwicklern offengelegt werden kann, und daher ist progressives Booten mit den meisten Bibliotheken und Frameworks nicht einfach zu implementieren.
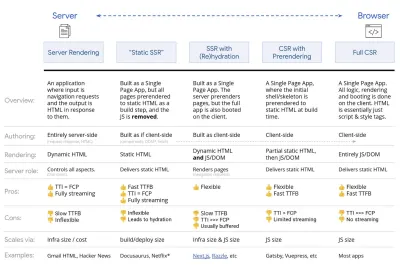
Trotzdem kommen wir ans Ziel. Heutzutage gibt es ein paar Möglichkeiten, die wir untersuchen können, und Houssein Djirdeh und Jason Miller bieten einen hervorragenden Überblick über diese Optionen in ihrem Vortrag über Rendering im Web und Jasons und Addys Artikel über moderne Front-End-Architekturen. Die folgende Übersicht basiert auf ihrer herausragenden Arbeit.
- Vollständiges serverseitiges Rendern (SSR)
Bei klassischem SSR wie WordPress werden alle Anfragen komplett auf dem Server abgewickelt. Der angeforderte Inhalt wird als fertige HTML-Seite zurückgegeben und kann sofort von Browsern gerendert werden. Daher können SSR-Apps beispielsweise die DOM-APIs nicht wirklich nutzen. Die Lücke zwischen First Contentful Paint und Time to Interactive ist normalerweise gering, und die Seite kann sofort gerendert werden, während HTML an den Browser gestreamt wird.Dadurch werden zusätzliche Roundtrips für das Abrufen von Daten und das Templating auf dem Client vermieden, da dies verarbeitet wird, bevor der Browser eine Antwort erhält. Am Ende haben wir jedoch eine längere Server-Denkzeit und folglich eine längere Zeit bis zum ersten Byte, und wir nutzen nicht die reaktionsschnellen und reichhaltigen Funktionen moderner Anwendungen.
- Statisches Rendering
Wir erstellen das Produkt als Einzelseitenanwendung, aber alle Seiten werden in statischem HTML mit minimalem JavaScript als Build-Schritt vorgerendert. Das bedeutet, dass wir beim statischen Rendering vorab individuelle HTML-Dateien für jede mögliche URL produzieren, was sich nicht viele Anwendungen leisten können. Da der HTML-Code für eine Seite jedoch nicht spontan generiert werden muss, können wir eine konstant schnelle Time To First Byte erreichen. So können wir schnell eine Zielseite anzeigen und dann ein SPA-Framework für nachfolgende Seiten vorab abrufen. Netflix hat diesen Ansatz übernommen und das Laden und die Time-to-Interactive um 50 % reduziert. - Serverseitiges Rendering mit (Re)Hydration (Universal Rendering, SSR + CSR)
Wir können versuchen, das Beste aus beiden Welten zu nutzen – den SSR- und den CSR-Ansatz. Mit Hydratation im Mix enthält die vom Server zurückgegebene HTML-Seite auch ein Skript, das eine vollwertige clientseitige Anwendung lädt. Idealerweise erreicht man schnell ein First Contentful Paint (wie SSR) und setzt dann das Rendern mit (Re-)Hydration fort. Leider ist das selten der Fall. Häufiger sieht die Seite fertig aus, kann aber nicht auf Benutzereingaben reagieren, was zu wütenden Klicks und Abbrüchen führt.Mit React können wir das
ReactDOMServer-Modul auf einem Node-Server wie Express verwenden und dann die MethoderenderToString, um die Komponenten der obersten Ebene als statische HTML-Zeichenfolge zu rendern.Mit Vue.js können wir den vue-server-renderer verwenden, um eine Vue-Instanz mit
renderToStringin HTML zu rendern. In Angular können wir@nguniversalverwenden, um Client-Anfragen in vollständig vom Server gerenderte HTML-Seiten umzuwandeln. Ein vollständig vom Server gerendertes Erlebnis kann auch mit Next.js (React) oder Nuxt.js (Vue) erreicht werden.Der Ansatz hat seine Schattenseiten. Infolgedessen gewinnen wir die volle Flexibilität von clientseitigen Apps und bieten gleichzeitig ein schnelleres serverseitiges Rendering, aber am Ende haben wir auch eine längere Lücke zwischen First Contentful Paint und Time To Interactive und eine längere First Input Delay. Die Rehydrierung ist sehr teuer, und normalerweise reicht diese Strategie allein nicht aus, da sie die Time To Interactive stark verzögert.
- Streaming serverseitiges Rendering mit progressiver Hydration (SSR + CSR)
Um die Lücke zwischen Time To Interactive und First Contentful Paint zu minimieren, rendern wir mehrere Anfragen gleichzeitig und senden Inhalte in Blöcken, sobald sie generiert werden. Wir müssen also nicht auf die vollständige HTML-Zeichenfolge warten, bevor wir Inhalte an den Browser senden, und verbessern somit die Zeit bis zum ersten Byte.In React können wir anstelle von
renderToString()renderToNodeStream() verwenden, um die Antwort weiterzuleiten und den HTML-Code in Blöcken zu senden. In Vue können wir renderToStream() verwenden, das geleitet und gestreamt werden kann. Mit React Suspense verwenden wir möglicherweise auch asynchrones Rendering für diesen Zweck.Auf der Client-Seite booten wir nicht die gesamte Anwendung auf einmal, sondern nach und nach Komponenten . Abschnitte der Anwendungen werden zunächst in eigenständige Skripte mit Code-Splitting zerlegt und dann schrittweise (in der Reihenfolge unserer Prioritäten) hydriert. Tatsächlich können wir kritische Komponenten zuerst hydratisieren, während der Rest später hydratisiert werden könnte. Die Rolle von clientseitigem und serverseitigem Rendering kann dann pro Komponente unterschiedlich definiert werden. Wir können dann auch die Hydratation einiger Komponenten verschieben, bis sie sichtbar werden oder für die Benutzerinteraktion benötigt werden oder wenn der Browser inaktiv ist.
Für Vue hat Markus Oberlehner einen Leitfaden zur Reduzierung der Zeit bis zur Interaktion von SSR-Apps mithilfe von Hydration bei Benutzerinteraktion sowie vue-lazy-hydratation, einem Early-Stage-Plugin, das die Komponentenhydratation bei Sichtbarkeit oder spezifischer Benutzerinteraktion ermöglicht, veröffentlicht. Das Angular-Team arbeitet mit Ivy Universal an progressiver Flüssigkeitszufuhr. Sie können auch eine teilweise Hydration mit Preact und Next.js implementieren.
- Trisomorphes Rendering
Wenn Servicemitarbeiter vorhanden sind, können wir Streaming-Server-Rendering für anfängliche/Nicht-JS-Navigationen verwenden und dann den Servicemitarbeiter das Rendern von HTML für Navigationen übernehmen lassen, nachdem es installiert wurde. In diesem Fall rendert der Servicemitarbeiter Inhalte vorab und aktiviert SPA-Navigationen zum Rendern neuer Ansichten in derselben Sitzung. Funktioniert gut, wenn Sie den gleichen Templating- und Routing-Code zwischen dem Server, der Client-Seite und dem Servicemitarbeiter teilen können.
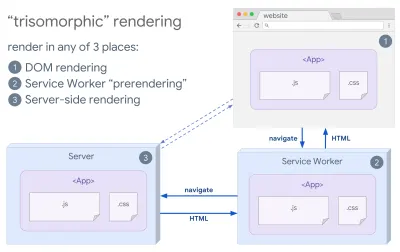
Trisomorphes Rendering mit dem gleichen Code-Rendering an 3 beliebigen Stellen: auf dem Server, im DOM oder in einem Service-Worker. (Bildquelle: Google Developers) (Große Vorschau) - CSR mit Prerendering
Prerendering ähnelt serverseitigem Rendering, aber anstatt Seiten auf dem Server dynamisch zu rendern, rendern wir die Anwendung zur Erstellungszeit in statisches HTML. Während statische Seiten ohne viel clientseitiges JavaScript vollständig interaktiv sind, funktioniert das Vorab-Rendering anders . Grundsätzlich erfasst es den Anfangszustand einer clientseitigen Anwendung als statisches HTML zur Erstellungszeit, während beim Vorab-Rendering die Anwendung auf dem Client gestartet werden muss, damit die Seiten interaktiv sind.Mit Next.js können wir den statischen HTML-Export verwenden, indem wir eine App vorab in statisches HTML rendern. In Gatsby verwendet ein Open-Source-Generator für statische Sites, der React verwendet, während des Builds die
renderToStaticMarkupMethode anstelle derrenderToStringMethode, wobei der Haupt-JS-Chunk vorab geladen und zukünftige Routen vorab abgerufen werden, ohne DOM-Attribute, die für einfache statische Seiten nicht benötigt werden.Für Vue können wir Vuepress verwenden, um dasselbe Ziel zu erreichen. Sie können den Prerender-Loader auch mit Webpack verwenden. Navi bietet auch statisches Rendering.
Das Ergebnis ist eine bessere „Time to First Byte“ und „First Contentful Paint“, und wir verringern die Lücke zwischen „Time To Interactive“ und „First Contentful Paint“. Wir können den Ansatz nicht verwenden, wenn erwartet wird, dass sich der Inhalt stark ändert. Außerdem müssen alle URLs im Voraus bekannt sein, um alle Seiten zu generieren. Einige Komponenten werden möglicherweise mithilfe von Prerendering gerendert, aber wenn wir etwas Dynamisches benötigen, müssen wir uns darauf verlassen, dass die App den Inhalt abruft.
- Vollständiges clientseitiges Rendering (CSR)
Die gesamte Logik, das Rendering und das Booten erfolgen auf dem Client. Das Ergebnis ist normalerweise eine große Lücke zwischen Time To Interactive und First Contentful Paint. Infolgedessen fühlen sich Anwendungen oft träge an, da die gesamte App auf dem Client gestartet werden muss, um etwas zu rendern.Da JavaScript Leistungseinbußen mit sich bringt, da die Menge an JavaScript mit einer Anwendung wächst, ist ein aggressives Code-Splitting und Zurückstellen von JavaScript absolut notwendig, um die Auswirkungen von JavaScript zu zähmen. Für solche Fälle ist ein serverseitiges Rendering normalerweise ein besserer Ansatz, falls nicht viel Interaktivität erforderlich ist. Wenn dies nicht möglich ist, sollten Sie das App Shell-Modell verwenden.
Im Allgemeinen ist SSR schneller als CSR. Dennoch ist es eine ziemlich häufige Implementierung für viele Apps da draußen.
Also clientseitig oder serverseitig? Im Allgemeinen ist es eine gute Idee, die Verwendung vollständig clientseitiger Frameworks auf Seiten zu beschränken , die sie unbedingt benötigen. Für fortgeschrittene Anwendungen ist es auch keine gute Idee, sich allein auf serverseitiges Rendern zu verlassen. Sowohl Server- als auch Client-Rendering sind eine Katastrophe, wenn sie schlecht gemacht werden.
Unabhängig davon, ob Sie zu CSR oder SSR neigen, stellen Sie sicher, dass Sie wichtige Pixel so schnell wie möglich rendern, und minimieren Sie die Lücke zwischen diesem Rendering und Time To Interactive. Erwägen Sie das Vorab-Rendering, wenn sich Ihre Seiten nicht stark ändern, und verschieben Sie das Booten von Frameworks, wenn Sie können. Streamen Sie HTML in Blöcken mit serverseitigem Rendering und implementieren Sie progressive Hydration für clientseitiges Rendering – und hydratisieren Sie bei Sichtbarkeit, Interaktion oder während der Leerlaufzeit, um das Beste aus beiden Welten zu erhalten.
- Vollständiges serverseitiges Rendern (SSR)

- Wie viel können wir statisch servieren?
Unabhängig davon, ob Sie an einer großen Anwendung oder einer kleinen Website arbeiten, sollten Sie überlegen, welche Inhalte statisch von einem CDN (dh JAM Stack) bereitgestellt werden könnten, anstatt dynamisch im laufenden Betrieb generiert zu werden. Selbst wenn Sie Tausende von Produkten und Hunderte von Filtern mit zahlreichen Personalisierungsoptionen haben, möchten Sie Ihre wichtigen Zielseiten möglicherweise dennoch statisch bereitstellen und diese Seiten vom Rahmen Ihrer Wahl entkoppeln.Es gibt viele Static-Site-Generatoren und die von ihnen generierten Seiten sind oft sehr schnell. Je mehr Inhalte wir im Voraus erstellen können, anstatt Seitenaufrufe auf einem Server oder Client zum Zeitpunkt der Anfrage zu generieren, desto bessere Leistung erzielen wir.
In Building Partially Hydrated, Progressively Enhanced Static Websites zeigt Markus Oberlehner, wie man Websites mit einem Static-Site-Generator und einem SPA erstellt und dabei eine progressive Verbesserung und eine minimale JavaScript-Bundle-Größe erreicht. Markus verwendet Eleventy und Preact als seine Tools und zeigt, wie man die Tools einrichtet, partielle Hydration, Lazy Hydration, Client-Eintragsdatei hinzufügt, Babel für Preact konfiguriert und Preact mit Rollup bündelt – von Anfang bis Ende.
Da JAMStack heutzutage auf großen Websites verwendet wird, tauchte ein neuer Leistungsaspekt auf: die Build-Zeit . Tatsächlich kann das Erstellen von Tausenden von Seiten mit jeder neuen Bereitstellung Minuten dauern, daher ist es vielversprechend, inkrementelle Builds in Gatsby zu sehen, die die Build-Zeiten um das 60-fache verbessern, mit einer Integration in beliebte CMS-Lösungen wie WordPress, Contentful, Drupal, Netlify CMS und andere.
Inkrementelle statische Regenerierung mit Next.js. (Bildnachweis: Prisma.io) (Große Vorschau) Außerdem kündigte Next.js eine vorzeitige und inkrementelle statische Generierung an, die es uns ermöglicht, neue statische Seiten zur Laufzeit hinzuzufügen und vorhandene Seiten zu aktualisieren, nachdem sie bereits erstellt wurden, indem sie im Hintergrund neu gerendert werden, wenn der Datenverkehr eingeht .
Benötigen Sie einen noch leichteren Ansatz? In seinem Vortrag über Eleventy, Alpine und Tailwind: Toward a Lightweight Jamstack erklärt Nicola Goutay die Unterschiede zwischen CSR, SSR und allem dazwischen und zeigt, wie man einen leichteren Ansatz verwendet – zusammen mit einem GitHub-Repo, das den Ansatz zeigt in der Praxis.
- Erwägen Sie die Verwendung von PRPL-Muster und App-Shell-Architektur.
Unterschiedliche Frameworks haben unterschiedliche Auswirkungen auf die Leistung und erfordern unterschiedliche Optimierungsstrategien, daher müssen Sie alle Grundlagen des Frameworks, auf das Sie sich verlassen, klar verstehen. Sehen Sie sich beim Erstellen einer Web-App das PRPL-Muster und die Anwendungs-Shell-Architektur an. Die Idee ist ganz einfach: Pushen Sie den minimalen Code, der benötigt wird, um interaktiv zu werden, damit die anfängliche Route schnell gerendert wird, verwenden Sie dann Service Worker zum Caching und Pre-Caching von Ressourcen und laden Sie dann asynchron die Routen, die Sie benötigen.
- Haben Sie die Leistung Ihrer APIs optimiert?
APIs sind Kommunikationskanäle für eine Anwendung, um Daten über Endpunkte für interne Anwendungen und Anwendungen von Drittanbietern verfügbar zu machen . Beim Entwerfen und Erstellen einer API benötigen wir ein angemessenes Protokoll, um die Kommunikation zwischen dem Server und Anfragen von Drittanbietern zu ermöglichen. Representational State Transfer ( REST ) ist eine etablierte, logische Wahl: Es definiert eine Reihe von Einschränkungen, denen Entwickler folgen, um Inhalte auf performante, zuverlässige und skalierbare Weise zugänglich zu machen. Webdienste, die den REST-Einschränkungen entsprechen, werden als RESTful-Webdienste bezeichnet.Wie bei den guten alten HTTP-Anforderungen wird beim Abrufen von Daten von einer API jede Verzögerung in der Serverantwort an den Endbenutzer weitergegeben, wodurch das Rendern verzögert wird. Wenn eine Ressource Daten von einer API abrufen möchte, muss sie die Daten vom entsprechenden Endpunkt anfordern. Eine Komponente, die Daten aus mehreren Ressourcen rendert, z. B. ein Artikel mit Kommentaren und Autorenfotos in jedem Kommentar, benötigt möglicherweise mehrere Roundtrips zum Server, um alle Daten abzurufen, bevor sie gerendert werden können. Darüber hinaus ist die über REST zurückgegebene Datenmenge oft größer als zum Rendern dieser Komponente erforderlich ist.
Wenn viele Ressourcen Daten von einer API benötigen, kann die API zu einem Leistungsengpass werden. GraphQL bietet eine leistungsfähige Lösung für diese Probleme. An sich ist GraphQL eine Abfragesprache für Ihre API und eine serverseitige Laufzeit zum Ausführen von Abfragen unter Verwendung eines Typsystems, das Sie für Ihre Daten definieren. Im Gegensatz zu REST kann GraphQL alle Daten in einer einzigen Anfrage abrufen, und die Antwort wird genau das sein, was erforderlich ist, ohne dass Daten zu viel oder zu wenig abgerufen werden, wie dies normalerweise bei REST der Fall ist.
Da GraphQL außerdem Schemas verwendet (Metadaten, die angeben, wie die Daten strukturiert sind), kann es Daten bereits in der bevorzugten Struktur organisieren, sodass wir beispielsweise mit GraphQL den JavaScript-Code entfernen könnten, der für den Umgang mit der Zustandsverwaltung und der Produktion verwendet wird einen saubereren Anwendungscode, der auf dem Client schneller ausgeführt wird.
Wenn Sie mit GraphQL beginnen möchten oder auf Leistungsprobleme stoßen, könnten diese Artikel sehr hilfreich sein:
- A GraphQL Primer: Why We Need A New Art of API von Eric Baer,
- A GraphQL Primer: The Evolution Of API Design von Eric Baer,
- Entwerfen eines GraphQL-Servers für optimale Leistung von Leonardo Losoviz,
- GraphQL-Leistung erklärt von Wojciech Trocki.
- Werden Sie AMP oder Instant Articles verwenden?
Abhängig von den Prioritäten und der Strategie Ihrer Organisation möchten Sie vielleicht die Verwendung von Googles AMP oder Facebooks Instant Articles oder Apples Apple News in Betracht ziehen. Sie können auch ohne sie eine gute Leistung erzielen, aber AMP bietet mit einem kostenlosen Content Delivery Network (CDN) ein solides Leistungsgerüst, während Instant Articles Ihre Sichtbarkeit und Leistung auf Facebook steigern.Der scheinbar offensichtliche Vorteil dieser Technologien für Benutzer ist die garantierte Leistung , sodass sie manchmal sogar AMP-/Apple News/Instant Pages-Links gegenüber „normalen“ und möglicherweise aufgeblähten Seiten bevorzugen. Bei inhaltsintensiven Websites, die mit vielen Inhalten von Drittanbietern zu tun haben, könnten diese Optionen möglicherweise dazu beitragen, die Renderzeiten drastisch zu verkürzen.
Es sei denn, sie tun es nicht. Laut Tim Kadlec zum Beispiel „sind AMP-Dokumente tendenziell schneller als ihre Gegenstücke, aber sie bedeuten nicht unbedingt, dass eine Seite performant ist.
Ein Vorteil für den Website-Betreiber liegt auf der Hand: Auffindbarkeit dieser Formate auf ihren jeweiligen Plattformen und erhöhte Sichtbarkeit in Suchmaschinen.
Naja, zumindest war das früher so. Da AMP für Top Stories nicht mehr erforderlich ist, wechseln Publisher möglicherweise von AMP zu einem traditionellen Stack ( danke, Barry! ).
Dennoch könnten Sie auch progressive Web-AMPs erstellen, indem Sie AMPs als Datenquelle für Ihre PWA wiederverwenden. Nachteil? Offensichtlich versetzt eine Präsenz in einem ummauerten Garten Entwickler in die Lage, eine separate Version ihres Inhalts zu erstellen und zu pflegen, und im Falle von Instant Articles und Apple News ohne tatsächliche URLs (danke Addy, Jeremy!) .
- Wählen Sie Ihr CDN mit Bedacht aus.
Wie oben erwähnt, können Sie abhängig davon, wie viele dynamische Daten Sie haben, möglicherweise einen Teil des Inhalts an einen Generator für statische Websites „auslagern“, ihn an ein CDN senden und von dort eine statische Version bereitstellen, wodurch Anfragen an die vermieden werden Server. Tatsächlich sind einige dieser Generatoren tatsächlich Website-Compiler mit vielen automatisierten Optimierungen, die sofort einsatzbereit sind. Wenn Compiler im Laufe der Zeit Optimierungen hinzufügen, wird die kompilierte Ausgabe mit der Zeit kleiner und schneller.Beachten Sie, dass CDNs auch dynamische Inhalte bereitstellen (und auslagern) können. Es ist also nicht notwendig, Ihr CDN auf statische Assets zu beschränken. Überprüfen Sie noch einmal, ob Ihr CDN Komprimierung und Konvertierung durchführt (z. B. Bildoptimierung und Größenänderung am Rand), ob es Unterstützung für Server-Worker, A/B-Tests sowie Edge-Side-Includes bietet, die statische und dynamische Teile von Seiten zusammenstellen am Rand des CDN (d. h. dem Server, der dem Benutzer am nächsten ist) und andere Aufgaben. Überprüfen Sie auch, ob Ihr CDN HTTP über QUIC (HTTP/3) unterstützt.
Katie Hempenius hat einen fantastischen Leitfaden für CDNs geschrieben, der Einblicke in die Auswahl eines guten CDNs, seine Feinabstimmung und all die kleinen Dinge gibt, die bei der Bewertung eines CDNs zu beachten sind. Im Allgemeinen ist es eine gute Idee, Inhalte so aggressiv wie möglich zwischenzuspeichern und CDN-Leistungsfunktionen wie Brotli, TLS 1.3, HTTP/2 und HTTP/3 zu aktivieren.
Hinweis : Basierend auf Untersuchungen von Patrick Meenan und Andy Davies wird die HTTP/2-Priorisierung auf vielen CDNs effektiv gebrochen, seien Sie also vorsichtig bei der Auswahl eines CDN. Patrick hat mehr Details in seinem Vortrag über die HTTP/2-Priorisierung ( Danke, Barry! ).
CDNPerf misst die Abfragegeschwindigkeit für CDNs, indem täglich 300 Millionen Tests gesammelt und analysiert werden. (Große Vorschau) Bei der Auswahl eines CDN können Sie diese Vergleichsseiten mit einer detaillierten Übersicht ihrer Funktionen nutzen:
- CDN-Vergleich, eine CDN-Vergleichsmatrix für Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai und viele andere.
- CDN Perf misst die Abfragegeschwindigkeit für CDNs, indem täglich 300 Millionen Tests gesammelt und analysiert werden, wobei alle Ergebnisse auf RUM-Daten von Benutzern auf der ganzen Welt basieren. Sehen Sie sich auch den DNS-Leistungsvergleich und den Cloud-Leistungsvergleich an.
- CDN Planet Guides bietet einen Überblick über CDNs zu bestimmten Themen wie Serve Stale, Purge, Origin Shield, Prefetch und Compression.
- Web Almanac: CDN Adoption and Usage bietet Einblicke in die wichtigsten CDN-Anbieter, ihre RTT- und TLS-Verwaltung, TLS-Aushandlungszeit, HTTP/2-Einführung und andere. (Leider sind die Daten nur von 2019).
Asset-Optimierungen
- Verwenden Sie Brotli für die Klartextkomprimierung.
Im Jahr 2015 führte Google Brotli ein, ein neues verlustfreies Open-Source-Datenformat, das jetzt in allen modernen Browsern unterstützt wird. Die Open-Source-Brotli-Bibliothek, die einen Encoder und Decoder für Brotli implementiert, verfügt über 11 vordefinierte Qualitätsstufen für den Encoder, wobei eine höhere Qualitätsstufe mehr CPU im Austausch für ein besseres Komprimierungsverhältnis erfordert. Eine langsamere Komprimierung führt letztendlich zu höheren Komprimierungsraten, dennoch dekomprimiert Brotli schnell. Es ist jedoch erwähnenswert, dass Brotli mit der Komprimierungsstufe 4 sowohl kleiner ist als auch schneller komprimiert als Gzip.In der Praxis scheint Brotli viel effektiver zu sein als Gzip. Die Meinungen und Erfahrungen gehen auseinander, aber wenn Ihre Website bereits mit Gzip optimiert ist, erwarten Sie möglicherweise mindestens einstellige Verbesserungen und bestenfalls zweistellige Verbesserungen bei der Größenreduzierung und den FCP-Timings. Sie können auch die Einsparungen bei der Brotli-Komprimierung für Ihre Website schätzen.
Browser akzeptieren Brotli nur, wenn der Benutzer eine Website über HTTPS besucht. Brotli wird weitgehend unterstützt, und viele CDNs unterstützen es (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (derzeit nur als Pass-Through), Cloudflare, CDN77) und Sie können Brotli auch auf CDNs aktivieren, die es noch nicht unterstützen (mit einem Servicemitarbeiter).
Der Haken ist, dass viele Hosting-Anbieter es nicht in vollem Umfang nutzen können, weil es teuer ist, alle Assets mit Brotli auf einer hohen Komprimierungsstufe zu komprimieren, nur weil es enorme Kosten verursacht. Tatsächlich ist Brotli auf der höchsten Komprimierungsstufe so langsam, dass potenzielle Gewinne in der Dateigröße durch die Zeit zunichte gemacht werden könnten, die der Server benötigt, um mit dem Senden der Antwort zu beginnen, während er auf die dynamische Komprimierung des Assets wartet. (Aber wenn Sie während der Build-Zeit Zeit mit statischer Komprimierung haben, werden natürlich höhere Komprimierungseinstellungen bevorzugt.)
Vergleich der Backendzeiten verschiedener Komprimierungsverfahren. Es überrascht nicht, dass Brotli (vorerst) langsamer als gzip ist. (Große Vorschau) Dies könnte sich jedoch ändern. Das Brotli-Dateiformat enthält ein integriertes statisches Wörterbuch und unterstützt nicht nur verschiedene Zeichenfolgen in mehreren Sprachen, sondern unterstützt auch die Option, mehrere Transformationen auf diese Wörter anzuwenden, was seine Vielseitigkeit erhöht. In seiner Forschung hat Felix Hanau einen Weg entdeckt, die Komprimierung auf den Ebenen 5 bis 9 zu verbessern, indem er „eine spezialisiertere Teilmenge des Wörterbuchs als die Standardeinstellung“ verwendet und sich auf den
Content-TypeHeader verlässt, um dem Kompressor mitzuteilen, ob er a verwenden soll Wörterbuch für HTML, JavaScript oder CSS. Das Ergebnis war eine „vernachlässigbare Auswirkung auf die Leistung (1 % bis 3 % mehr CPU im Vergleich zu 12 % normalerweise) bei der Komprimierung von Webinhalten mit hohen Komprimierungsstufen und einem Ansatz mit eingeschränkter Wörterbuchverwendung“.
Mit dem verbesserten Wörterbuchansatz können wir Assets auf höheren Komprimierungsstufen schneller komprimieren und dabei nur 1 % bis 3 % mehr CPU verbrauchen. Normalerweise würde die Komprimierungsstufe 6 über 5 die CPU-Auslastung um bis zu 12 % erhöhen. (Große Vorschau) Darüber hinaus können wir mit der Forschung von Elena Kirilenko eine schnelle und effiziente Brotli-Rekomprimierung unter Verwendung früherer Komprimierungsartefakte erreichen. Laut Elena „können wir, sobald wir ein über Brotli komprimiertes Asset haben und versuchen, dynamische Inhalte on-the-fly zu komprimieren, bei denen die Inhalte Inhalten ähneln, die uns im Voraus zur Verfügung stehen, erhebliche Verbesserungen bei den Komprimierungszeiten erzielen. "
Wie oft ist es der Fall? ZB bei Auslieferung von JavaScript-Bundle-Subsets (zB wenn Teile des Codes bereits auf dem Client gecacht sind oder bei dynamischem Bundle-Serving mit WebBundles). Oder mit dynamischem HTML basierend auf im Voraus bekannten Vorlagen oder dynamisch unterteilten WOFF2-Schriftarten . Laut Elena können wir eine Verbesserung der Komprimierung um 5,3 % und eine Verbesserung der Komprimierungsgeschwindigkeit um 39 % erzielen, wenn 10 % des Inhalts entfernt werden, und um 3,2 % bessere Komprimierungsraten und eine um 26 % schnellere Komprimierung, wenn 50 % des Inhalts entfernt werden.
Die Brotli-Komprimierung wird immer besser, wenn Sie also die Kosten für die dynamische Komprimierung statischer Assets umgehen können, ist es definitiv die Mühe wert. Es versteht sich von selbst, dass Brotli für jede Klartext-Nutzlast verwendet werden kann – HTML, CSS, SVG, JavaScript, JSON und so weiter.
Hinweis : Anfang 2021 werden etwa 60 % der HTTP-Antworten ohne textbasierte Komprimierung übermittelt, wobei 30,82 % mit Gzip und 9,1 % mit Brotli komprimiert werden (sowohl auf Mobilgeräten als auch auf Desktops). Beispielsweise sind 23,4 % der Angular-Seiten nicht komprimiert (über gzip oder Brotli). Das Einschalten der Komprimierung ist jedoch oft einer der einfachsten Gewinne, um die Leistung mit einem einfachen Umlegen eines Schalters zu verbessern.
Die Strategie? Komprimieren Sie statische Assets mit Brotli+Gzip auf der höchsten Stufe vor und komprimieren Sie (dynamisches) HTML on the fly mit Brotli auf Stufe 4–6. Stellen Sie sicher, dass der Server die Inhaltsaushandlung für Brotli oder Gzip ordnungsgemäß verarbeitet.
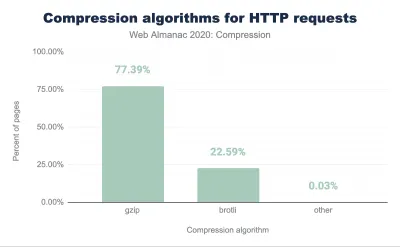
- Verwenden wir adaptives Laden von Medien und Client-Hinweise?
Es kommt aus dem Land der alten Nachrichten, aber es ist immer eine gute Erinnerung, responsive Bilder mitsrcset,sizesund dem<picture>Element zu verwenden. Insbesondere für Websites mit einem hohen Medienaufkommen können wir mit adaptivem Laden von Medien (in diesem Beispiel React + Next.js) noch einen Schritt weiter gehen, um langsamen Netzwerken und Geräten mit geringem Arbeitsspeicher ein leichtes Erlebnis und einem schnellen Netzwerk und einem hohen Niveau ein volles Erlebnis zu bieten -Speichergeräte. Im Kontext von React können wir dies mit Client-Hinweisen auf dem Server und React-Adaptive-Hooks auf dem Client erreichen.Die Zukunft von responsiven Bildern könnte sich mit der breiteren Einführung von Client-Hinweisen dramatisch ändern. Client-Hinweise sind HTTP-Anforderungs-Header-Felder, z. B.
DPR,Viewport-Width,Width,Save-Data,Accept(um Bildformatpräferenzen anzugeben) und andere. Sie sollen den Server über die Besonderheiten des Browsers, Bildschirms, der Verbindung usw. des Benutzers informieren.Infolgedessen kann der Server entscheiden, wie er das Layout mit Bildern in geeigneter Größe füllt, und nur diese Bilder in den gewünschten Formaten bereitstellen. Mit Client-Hinweisen verschieben wir die Ressourcenauswahl vom HTML-Markup in die Anfrage-Antwort-Aushandlung zwischen Client und Server.
Adaptive Medienbereitstellung wird verwendet. Wir senden einen Platzhalter mit Text an Benutzer, die offline sind, ein Bild mit niedriger Auflösung an 2G-Benutzer, ein Bild mit hoher Auflösung an 3G-Benutzer und ein HD-Video an 4G-Benutzer. Über Schnelles Laden von Webseiten auf einem 20-Dollar-Feature-Phone. (Große Vorschau) Wie Ilya Grigorik vor einiger Zeit bemerkte, vervollständigen Client-Hinweise das Bild – sie sind keine Alternative zu responsiven Bildern. „Das
<picture>-Element bietet die notwendige Art-Direction-Steuerung im HTML-Markup. Client-Hinweise stellen Anmerkungen zu resultierenden Bildanforderungen bereit, die eine Automatisierung der Ressourcenauswahl ermöglichen. Service Worker bietet vollständige Anforderungs- und Antwortverwaltungsfunktionen auf dem Client.“Ein Servicemitarbeiter könnte beispielsweise neue Header-Werte für Client-Hinweise an die Anfrage anhängen , die URL umschreiben und die Bildanfrage auf ein CDN verweisen, die Antwort basierend auf Konnektivität und Benutzereinstellungen anpassen usw. Dies gilt nicht nur für Bild-Assets, sondern auch für so ziemlich alle anderen Anfragen auch.
Bei Clients, die Client-Hinweise unterstützen, konnte man 42 % Byte-Einsparungen bei Bildern und 1 MB+ weniger Bytes für das 70. Perzentil messen. Beim Smashing Magazine konnten wir ebenfalls eine Verbesserung von 19-32 % messen. Client-Hinweise werden in Chromium-basierten Browsern unterstützt, in Firefox werden sie jedoch noch geprüft.
Wenn Sie jedoch sowohl das normale responsive Bild-Markup als auch das
<meta>-Tag für Client-Hinweise bereitstellen, wertet ein unterstützender Browser das responsive Bild-Markup aus und fordert die entsprechende Bildquelle mithilfe der Client-Hinweis-HTTP-Header an. - Verwenden wir responsive Bilder für Hintergrundbilder?
Das sollten wir auf jeden Fall! Mitimage-set, das jetzt in Safari 14 und in den meisten modernen Browsern außer Firefox unterstützt wird, können wir auch responsive Hintergrundbilder bereitstellen:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Grundsätzlich können wir Hintergrundbilder mit niedriger Auflösung mit einem
1x-Deskriptor und Bilder mit höherer Auflösung mit2x-Deskriptor und sogar ein Bild in Druckqualität mit 600-600dpi-Deskriptor bedingt liefern. Aber Vorsicht: Browser liefern keine speziellen Informationen über Hintergrundbilder an Hilfstechnologien, daher wären diese Fotos im Idealfall nur Dekoration. - Verwenden wir WebP?
Die Bildkomprimierung wird oft als schneller Gewinn angesehen, wird in der Praxis jedoch immer noch zu wenig genutzt. Natürlich blockieren Bilder nicht das Rendern, aber sie tragen stark zu schlechten LCP-Ergebnissen bei, und sehr oft sind sie einfach zu schwer und zu groß für das Gerät, auf dem sie konsumiert werden.Wir könnten also zumindest das WebP-Format für unsere Bilder verwenden. Tatsächlich näherte sich die WebP-Saga letztes Jahr dem Ende, als Apple die Unterstützung für WebP in Safari 14 hinzufügte. Nach vielen Jahren der Diskussionen und Debatten wird WebP also ab heute in allen modernen Browsern unterstützt. So können wir WebP-Bilder bei Bedarf mit dem
<picture>-Element und einem JPEG-Fallback (siehe Code-Snippet von Andreas Bovens) oder mithilfe der Inhaltsverhandlung (unter Verwendung vonAccept-Headern) bereitstellen.WebP ist jedoch nicht ohne Nachteile . Während WebP-Bilddateien im Vergleich zu entsprechenden Guetzli und Zopfli größer sind, unterstützt das Format kein progressives Rendering wie JPEG, weshalb Benutzer das fertige Bild mit einem guten alten JPEG möglicherweise schneller sehen, obwohl WebP-Bilder durch das Netzwerk möglicherweise schneller werden. Mit JPEG können wir mit der Hälfte oder sogar einem Viertel der Daten ein "anständiges" Benutzererlebnis bieten und den Rest später laden, anstatt ein halbleeres Bild zu haben, wie es bei WebP der Fall ist.
Ihre Entscheidung hängt davon ab, was Sie wollen: Mit WebP reduzieren Sie die Nutzlast und mit JPEG verbessern Sie die wahrgenommene Leistung. Sie können mehr über WebP im WebP Rewind-Vortrag von Pascal Massimino von Google erfahren.
Für die Konvertierung in WebP können Sie WebP Converter, cwebp oder libwebp verwenden. Ire Aderinokun hat auch ein sehr detailliertes Tutorial zum Konvertieren von Bildern in WebP – und Josh Comeau in seinem Artikel über die Einführung moderner Bildformate.

Ein ausführlicher Vortrag über WebP: WebP Rewind von Pascal Massimino. (Große Vorschau) Sketch unterstützt nativ WebP, und WebP-Bilder können mithilfe eines WebP-Plugins für Photoshop aus Photoshop exportiert werden. Aber auch andere Optionen sind verfügbar.
Wenn Sie WordPress oder Joomla verwenden, gibt es Erweiterungen, die Ihnen helfen, die Unterstützung für WebP einfach zu implementieren, wie Optimus und Cache Enabler für WordPress und Joomlas eigene unterstützte Erweiterung (über Cody Arsenault). Sie können das
<picture>-Element auch mit React, styled components oder gatsby-image abstrahieren.Ah — schamloser Stecker! — Jeremy Wagner hat sogar ein tolles Buch über WebP veröffentlicht, das Sie vielleicht lesen möchten, wenn Sie sich für alles rund um WebP interessieren.
- Verwenden wir AVIF?
Sie haben vielleicht die große Neuigkeit gehört: AVIF ist gelandet. Es ist ein neues Bildformat, das von den Keyframes von AV1-Videos abgeleitet ist. Es ist ein offenes, lizenzfreies Format, das verlustbehaftete und verlustfreie Komprimierung, Animation, verlustbehafteten Alphakanal unterstützt und mit scharfen Linien und Volltonfarben umgehen kann (was bei JPEG ein Problem war), während es bei beiden bessere Ergebnisse liefert.Tatsächlich schneidet AVIF im Vergleich zu WebP und JPEG deutlich besser ab und ermöglicht eine mittlere Dateigrößeneinsparung von bis zu 50 % bei gleichem DSSIM ((Dis)ähnlichkeit zwischen zwei oder mehr Bildern unter Verwendung eines Algorithmus, der das menschliche Sehvermögen annähert). Tatsächlich stellt Malte Ubl in seinem ausführlichen Beitrag über das Optimieren des Ladens von Bildern fest, dass AVIF „sehr konstant JPEG deutlich übertrifft. Dies unterscheidet sich von WebP, das nicht immer kleinere Bilder als JPEG erzeugt und tatsächlich ein Verlust aufgrund fehlender Unterstützung für progressives Laden."

Wir können AVIF als progressive Erweiterung verwenden und WebP oder JPEG oder PNG für ältere Browser bereitstellen. (Große Vorschau). Siehe Klartextansicht unten. Ironischerweise kann AVIF sogar noch besser abschneiden als große SVGs, obwohl es natürlich nicht als Ersatz für SVGs angesehen werden sollte. Es ist auch eines der ersten Bildformate, das HDR-Farbunterstützung unterstützt; bietet eine höhere Helligkeit, Farbbittiefe und Farbskalen. Der einzige Nachteil ist, dass AVIF derzeit (noch?) keine progressive Bilddecodierung unterstützt und, ähnlich wie bei Brotli, eine Codierung mit hoher Komprimierungsrate derzeit ziemlich langsam ist, obwohl die Decodierung schnell ist.
AVIF wird derzeit in Chrome, Firefox und Opera unterstützt, und die Unterstützung in Safari wird voraussichtlich bald folgen (da Apple Mitglied der Gruppe ist, die AV1 erstellt hat).
Wie präsentiert man Bilder heutzutage am besten ? Für Illustrationen und Vektorgrafiken ist (komprimiertes) SVG zweifellos die beste Wahl. Für Fotos verwenden wir Content-Negotiation-Methoden mit dem
picture. Wenn AVIF unterstützt wird, senden wir ein AVIF-Bild; Wenn dies nicht der Fall ist, greifen wir zuerst auf WebP zurück, und wenn WebP ebenfalls nicht unterstützt wird, wechseln wir als Fallback zu JPEG oder PNG (falls erforderlich unter Anwendung von@mediaBedingungen):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Ehrlich gesagt ist es jedoch wahrscheinlicher, dass wir einige Bedingungen innerhalb des
pictureverwenden:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Sie können sogar noch weiter gehen, indem Sie animierte Bilder mit statischen Bildern für Kunden austauschen, die sich für weniger Bewegung entscheiden, mit
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>In den paar Monaten hat AVIF einiges an Zugkraft gewonnen:
- Wir können WebP/AVIF-Fallbacks im Bereich „Rendering“ in DevTools testen.
- Wir können Squoosh, AVIF.io und libavif verwenden, um AVIF-Dateien zu codieren, zu decodieren, zu komprimieren und zu konvertieren.
- Wir können die AVIF Preact-Komponente von Jake Archibald verwenden, die eine AVIF-Datei in einem Worker decodiert und das Ergebnis auf einer Leinwand anzeigt.
- Um AVIF nur an unterstützende Browser zu liefern, können wir ein PostCSS-Plugin zusammen mit einem 315B-Skript verwenden, um AVIF in Ihren CSS-Deklarationen zu verwenden.
- Wir können schrittweise neue Bildformate mit CSS und Cloudlare Workers bereitstellen, um das zurückgegebene HTML-Dokument dynamisch zu ändern, indem wir Informationen aus dem
accept-Header ableiten, und dann die Klassenwebp/avifusw. nach Bedarf hinzufügen. - AVIF ist bereits in Cloudinary verfügbar (mit Nutzungsbeschränkungen), Cloudflare unterstützt AVIF bei der Bildgrößenanpassung und Sie können AVIF mit benutzerdefinierten AVIF-Headern in Netlify aktivieren.
- Wenn es um Animationen geht, schneidet AVIF genauso gut ab wie
<img src=mp4>von Safari und übertrifft GIF und WebP insgesamt, aber MP4 schneidet immer noch besser ab. - Im Allgemeinen gilt für Animationen AVC1 (h264) > HVC1 > WebP > AVIF > GIF, vorausgesetzt, dass Chromium-basierte Browser jemals
<img src=mp4>unterstützen werden. - Weitere Details zu AVIF finden Sie in AVIF for Next Generation Image Coding Talk von Aditya Mavlankar von Netflix und The AVIF Image Format Talk von Kornel Lesinski von Cloudflare.
- Eine großartige Referenz für alles AVIF: Jake Archibalds umfassender Beitrag zu AVIF ist gelandet.
Ist die Zukunft also AVIF ? Jon Sneyers ist anderer Meinung: AVIF schneidet 60 % schlechter ab als JPEG XL, ein weiteres kostenloses und offenes Format, das von Google und Cloudinary entwickelt wurde. Tatsächlich scheint JPEG XL auf ganzer Linie viel besser zu sein. Allerdings befindet sich JPEG XL noch in der Endphase der Standardisierung und funktioniert noch in keinem Browser. (Nicht zu verwechseln mit Microsofts JPEG-XR aus dem guten alten Internet Explorer 9 mal).
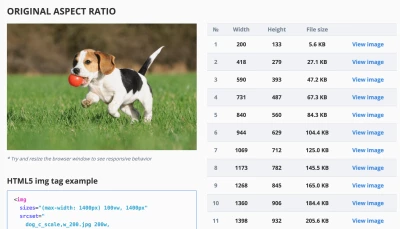
- Sind JPEG/PNG/SVGs richtig optimiert?
Wenn Sie an einer Zielseite arbeiten, auf der es wichtig ist, dass ein Hero-Bild blitzschnell geladen wird, stellen Sie sicher, dass JPEGs progressiv und mit mozJPEG (das die Start-Rendering-Zeit durch Manipulieren der Scan-Ebenen verbessert) oder Guetzli, Googles Open-Source, komprimiert sind Encoder, der sich auf die Wahrnehmungsleistung konzentriert und Erkenntnisse aus Zopfli und WebP nutzt. Einziger Nachteil: langsame Verarbeitungszeiten (eine Minute CPU pro Megapixel).Für PNG können wir Pingo verwenden und für SVG können wir SVGO oder SVGOMG verwenden. Und wenn Sie schnell alle SVG-Assets von einer Website in der Vorschau anzeigen und kopieren oder herunterladen müssen, kann svg-grabber das auch für Sie tun.
Jeder einzelne Artikel zur Bildoptimierung würde es erwähnen, aber Vektor-Assets sauber und straff zu halten, ist immer erwähnenswert. Achten Sie darauf, ungenutzte Assets zu bereinigen, unnötige Metadaten zu entfernen und die Anzahl der Pfadpunkte im Bildmaterial (und damit im SVG-Code) zu reduzieren. ( Danke Jeremy! )
Es gibt aber auch nützliche Online-Tools:
- Verwenden Sie Squoosh, um Bilder mit den optimalen Komprimierungsstufen (verlustbehaftet oder verlustfrei) zu komprimieren, zu skalieren und zu manipulieren.
- Verwenden Sie Guetzli.it, um JPEG-Bilder mit Guetzli zu komprimieren und zu optimieren, was gut für Bilder mit scharfen Kanten und Volltonfarben funktioniert (aber möglicherweise etwas langsamer ist)).
- Verwenden Sie den Responsive Image Breakpoints Generator oder einen Dienst wie Cloudinary oder Imgix, um die Bildoptimierung zu automatisieren. Außerdem bringt die alleinige Verwendung von
srcsetundsizesin vielen Fällen erhebliche Vorteile. - Um die Effizienz Ihres responsiven Markups zu überprüfen, können Sie Imaging-Heap verwenden, ein Befehlszeilentool, das die Effizienz über Darstellungsfenstergrößen und Gerätepixelverhältnisse hinweg misst.
- Sie können Ihren GitHub-Workflows eine automatische Bildkomprimierung hinzufügen, sodass kein Bild unkomprimiert in die Produktion gelangen kann. Die Aktion verwendet mozjpeg und libvips, die mit PNGs und JPGs funktionieren.
- Um den Speicher intern zu optimieren, könnten Sie das neue Lepton-Format von Dropbox verwenden, um JPEGs verlustfrei um durchschnittlich 22 % zu komprimieren.
- Verwenden Sie BlurHash, wenn Sie frühzeitig ein Platzhalterbild anzeigen möchten. BlurHash nimmt ein Bild und gibt Ihnen eine kurze Zeichenfolge (nur 20-30 Zeichen!), die den Platzhalter für dieses Bild darstellt. Die Zeichenfolge ist kurz genug, dass sie problemlos als Feld in einem JSON-Objekt hinzugefügt werden kann.
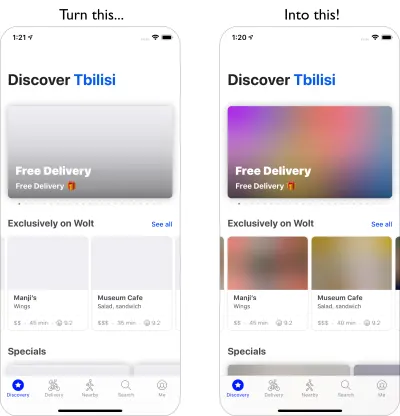
BlurHash ist eine winzige, kompakte Darstellung eines Platzhalters für ein Bild. (Große Vorschau) Manchmal reicht die Optimierung von Bildern allein nicht aus. Um die zum Starten des Renderns eines kritischen Bilds benötigte Zeit zu verkürzen, laden Sie weniger wichtige Bilder verzögert und verschieben Sie das Laden von Skripts, nachdem kritische Bilder bereits gerendert wurden. Der kugelsicherste Weg ist hybrides Lazy-Loading, wenn wir natives Lazy-Loading und Lazyload verwenden, eine Bibliothek, die alle Sichtbarkeitsänderungen erkennt, die durch Benutzerinteraktionen ausgelöst werden (mit IntersectionObserver, die wir später untersuchen werden). Zusätzlich:
- Erwägen Sie, kritische Bilder vorab zu laden, damit ein Browser sie nicht zu spät entdeckt. Wenn Sie bei Hintergrundbildern noch aggressiver vorgehen möchten, können Sie das Bild mit
<img src>als normales Bild hinzufügen und es dann vom Bildschirm ausblenden. - Erwägen Sie das Austauschen von Bildern mit dem Größenattribut, indem Sie je nach Medienabfrage unterschiedliche Bildanzeigeabmessungen angeben, z. B. um
sizeszu manipulieren, um Quellen in einer Lupenkomponente auszutauschen. - Überprüfen Sie Inkonsistenzen beim Herunterladen von Bildern, um unerwartete Downloads für Vorder- und Hintergrundbilder zu verhindern. Achten Sie auf Bilder, die standardmäßig geladen werden, aber möglicherweise nie angezeigt werden – z. B. in Karussells, Akkordeons und Bildergalerien.
- Achten Sie darauf, bei Bildern immer
widthundheighteinzustellen. Achten Sie auf die Eigenschaft „aspect-ratio“ in CSS und das Attribut „intrinsicsize“, mit dem wir Seitenverhältnisse und Abmessungen für Bilder festlegen können, damit der Browser frühzeitig einen vordefinierten Layout-Slot reservieren kann, um Layoutsprünge während des Ladens der Seite zu vermeiden.
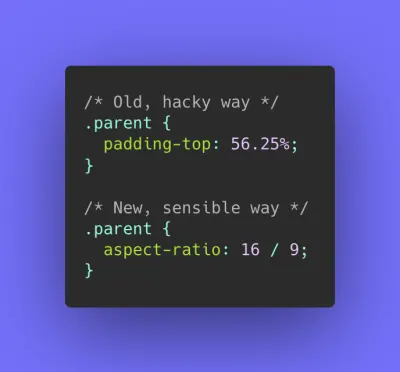
Sollte jetzt nur noch eine Frage von Wochen oder Monaten sein, wenn das Seitenverhältnis in Browsern landet. In Safari Technical Preview 118 bereits. Derzeit hinter der Flagge in Firefox und Chrome. (Große Vorschau) Wenn Sie abenteuerlustig sind, können Sie HTTP/2-Streams mit Edge-Workern zerhacken und neu anordnen, im Grunde ein Echtzeitfilter, der auf dem CDN lebt, um Bilder schneller durch das Netzwerk zu senden. Edge-Worker verwenden JavaScript-Streams, die Chunks verwenden, die Sie steuern können (im Grunde handelt es sich um JavaScript, das auf dem CDN-Edge ausgeführt wird und die Streaming-Antworten ändern kann), sodass Sie die Bereitstellung von Bildern steuern können.
Bei einem Servicemitarbeiter ist es zu spät, da Sie nicht kontrollieren können, was auf dem Draht ist, aber bei Edge-Mitarbeitern funktioniert es. Sie können sie also zusätzlich zu statischen JPEGs verwenden, die nach und nach für eine bestimmte Zielseite gespeichert werden.
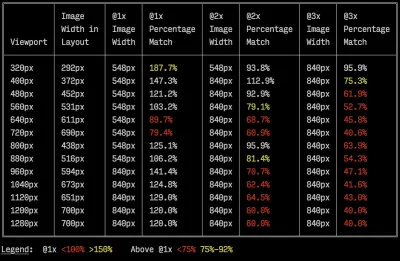
Eine Beispielausgabe von Imaging-Heap, einem Befehlszeilentool, das die Effizienz über Darstellungsfenstergrößen und Gerätepixelverhältnisse hinweg misst. (Bildquelle) (Große Vorschau) Nicht gut genug? Nun, Sie können auch die wahrgenommene Leistung für Bilder mit der Technik mit mehreren Hintergrundbildern verbessern. Denken Sie daran, dass das Spielen mit Kontrasten und das Verwischen unnötiger Details (oder das Entfernen von Farben) die Dateigröße ebenfalls reduzieren können. Ah, Sie müssen ein kleines Foto vergrößern, ohne an Qualität zu verlieren? Erwägen Sie die Verwendung von Letsenhance.io.
Diese Optimierungen decken bisher nur die Grundlagen ab. Addy Osmani hat einen sehr detaillierten Leitfaden zur wesentlichen Bildoptimierung veröffentlicht, der sehr tief in die Details der Bildkomprimierung und des Farbmanagements eingeht. Beispielsweise könnten Sie unnötige Teile des Bildes unkenntlich machen (indem Sie einen Gaußschen Unschärfefilter darauf anwenden), um die Dateigröße zu verringern, und schließlich könnten Sie sogar damit beginnen, Farben zu entfernen oder das Bild in Schwarzweiß umzuwandeln, um die Größe noch weiter zu verringern . Für Hintergrundbilder kann auch der Export von Fotos aus Photoshop mit 0 bis 10 % Qualität absolut akzeptabel sein.
Auf Smashing Magazine verwenden wir das Postfix
-optfür Bildnamen – zum Beispielbrotli-compression-opt.png; Immer wenn ein Bild dieses Postfix enthält, weiß jeder im Team, dass das Bild bereits optimiert wurde.Ah, und verwenden Sie JPEG-XR nicht im Web – „die Verarbeitung der Dekodierung von JPEG-XRs auf der Softwareseite auf der CPU macht die potenziell positiven Auswirkungen der Einsparungen bei der Bytegröße zunichte und überwiegt sogar, insbesondere im Kontext von SPAs“ (nicht aber mit Cloudinary/Googles JPEG XL zu verwechseln).

- Sind Videos richtig optimiert?
Bisher haben wir Bilder abgedeckt, aber wir haben ein Gespräch über gute alte GIFs vermieden. Trotz unserer Liebe zu GIFs ist es wirklich an der Zeit, sie endgültig aufzugeben (zumindest in unseren Websites und Apps). Anstatt schwere animierte GIFs zu laden, die sich sowohl auf die Rendering-Leistung als auch auf die Bandbreite auswirken, ist es eine gute Idee, entweder zu animiertem WebP zu wechseln (wobei GIF ein Fallback ist) oder sie vollständig durch sich wiederholende HTML5-Videos zu ersetzen.Im Gegensatz zu Bildern laden Browser
<video>-Inhalte nicht vorab, aber HTML5-Videos sind in der Regel viel leichter und kleiner als GIFs. Keine Option? Nun, zumindest können wir GIFs mit Lossy GIF, Gifsicle oder Giflossy verlustbehaftete Komprimierung hinzufügen.Tests von Colin Bendell zeigen, dass Inline-Videos innerhalb von
img-Tags in Safari Technology Preview mindestens 20-mal schneller angezeigt und 7-mal schneller dekodiert werden als das GIF-Äquivalent, zusätzlich zu einer Bruchteil der Dateigröße. In anderen Browsern wird es jedoch nicht unterstützt.Im Land der guten Nachrichten haben sich Videoformate im Laufe der Jahre massiv weiterentwickelt. Lange Zeit hatten wir gehofft, dass WebM das Format werden würde, das sie alle beherrscht, und dass WebP (das im Grunde ein Standbild innerhalb des WebM-Videocontainers ist) ein Ersatz für veraltete Bildformate werden würde. Tatsächlich unterstützt Safari jetzt WebP, aber obwohl WebP und WebM heutzutage Unterstützung erhalten, kam es nicht wirklich zum Durchbruch.
Dennoch könnten wir WebM für die meisten modernen Browser da draußen verwenden:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Aber vielleicht könnten wir es noch einmal durchgehen. Im Jahr 2018 hat die Alliance of Open Media ein neues vielversprechendes Videoformat namens AV1 veröffentlicht. AV1 hat eine ähnliche Komprimierung wie der H.265-Codec (die Weiterentwicklung von H.264), aber im Gegensatz zu letzterem ist AV1 kostenlos. Die H.265-Lizenzpreise veranlassten die Browseranbieter, stattdessen ein vergleichbar leistungsfähiges AV1 einzusetzen: AV1 (genau wie H.265) komprimiert doppelt so gut wie WebM .

AV1 hat gute Chancen, der ultimative Standard für Videos im Web zu werden. (Bildnachweis: Wikimedia.org) (Große Vorschau) Tatsächlich verwendet Apple derzeit das HEIF-Format und HEVC (H.265), und alle Fotos und Videos auf dem neuesten iOS werden in diesen Formaten gespeichert, nicht in JPEG. Während HEIF und HEVC (H.265) (noch?) Nicht richtig im Internet verfügbar sind, ist es AV1 – und es gewinnt an Browserunterstützung. Daher ist das Hinzufügen der
AV1-Quelle in Ihrem<video>-Tag sinnvoll, da anscheinend alle Browser-Anbieter an Bord sind.Derzeit ist die am weitesten verbreitete und unterstützte Codierung H.264, die von MP4-Dateien bereitgestellt wird. Stellen Sie also vor der Bereitstellung der Datei sicher, dass Ihre MP4s mit einer Multipass-Codierung verarbeitet, mit dem frei0r iirblur-Effekt (falls zutreffend) und unscharf gemacht wurden moov-Atom-Metadaten werden an den Kopf der Datei verschoben, während Ihr Server Byte-Serving akzeptiert. Boris Schapira gibt genaue Anleitungen für FFmpeg, um Videos maximal zu optimieren. Natürlich würde es auch helfen, das WebM-Format als Alternative bereitzustellen.
Müssen Sie Videos schneller rendern, aber die Videodateien sind immer noch zu groß ? Wenn Sie zum Beispiel ein großes Hintergrundvideo auf einer Zielseite haben? Eine gängige Technik besteht darin, den allerersten Frame zuerst als Standbild anzuzeigen oder ein stark optimiertes, kurzes Schleifensegment anzuzeigen, das als Teil des Videos interpretiert werden könnte, und dann, wenn das Video ausreichend gepuffert ist, mit der Wiedergabe zu beginnen das eigentliche Video. Doug Sillars hat eine detaillierte Anleitung zur Leistung von Hintergrundvideos geschrieben, die in diesem Fall hilfreich sein könnte. ( Danke, Guy Podjarny! ).
Für das obige Szenario möchten Sie möglicherweise ansprechende Posterbilder bereitstellen . Standardmäßig erlauben
videonur ein Bild als Poster, was nicht unbedingt optimal ist. Wir können Responsive Video Poster verwenden, eine JavaScript-Bibliothek, die es Ihnen ermöglicht, verschiedene Posterbilder für verschiedene Bildschirme zu verwenden und gleichzeitig ein Übergangs-Overlay und eine vollständige Gestaltungskontrolle für Video-Platzhalter hinzuzufügen.Die Untersuchung zeigt, dass die Qualität des Videostreams das Zuschauerverhalten beeinflusst. Tatsächlich brechen die Zuschauer das Video ab, wenn die Startverzögerung etwa 2 Sekunden überschreitet. Über diesen Punkt hinaus führt eine Erhöhung der Verzögerung um 1 Sekunde zu einer Erhöhung der Abbruchrate um etwa 5,8 %. Daher ist es nicht verwunderlich, dass die durchschnittliche Videostartzeit 12,8 Sekunden beträgt, wobei 40 % der Videos mindestens 1 Unterbrechung und 20 % mindestens 2 Sekunden Unterbrechung der Videowiedergabe aufweisen. Tatsächlich sind Videoställe bei 3G unvermeidlich, da Videos schneller abgespielt werden, als das Netzwerk Inhalte liefern kann.
Also, was ist die Lösung? Normalerweise können Geräte mit kleinem Bildschirm die 720p und 1080p, die wir für den Desktop bereitstellen, nicht verarbeiten. Laut Doug Sillars können wir entweder kleinere Versionen unserer Videos erstellen und Javascript verwenden, um die Quelle für kleinere Bildschirme zu erkennen, um eine schnelle und reibungslose Wiedergabe auf diesen Geräten zu gewährleisten. Alternativ können wir Streaming-Video verwenden. HLS-Videostreams liefern ein Video in angemessener Größe an das Gerät, wodurch die Notwendigkeit entfällt, unterschiedliche Videos für unterschiedliche Bildschirme zu erstellen. Es verhandelt auch die Netzwerkgeschwindigkeit und passt die Videobitrate an die Geschwindigkeit des von Ihnen verwendeten Netzwerks an.
Um die Verschwendung von Bandbreite zu vermeiden, konnten wir die Videoquelle nur für Geräte hinzufügen, die das Video tatsächlich gut wiedergeben können. Alternativ können wir das
autoplay-Attribut vollständig aus demvideoTag entfernen und JavaScript verwenden, umautoplayfür größere Bildschirme einzufügen. Außerdem müssen wir demvideopreload="none"hinzufügen, um den Browser anzuweisen, keine der Videodateien herunterzuladen, bis er die Datei tatsächlich benötigt:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Dann können wir speziell auf Browser abzielen, die AV1 tatsächlich unterstützen:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Wir könnten dann das
autoplayüber einem bestimmten Schwellenwert (z. B. 1000 Pixel) erneut hinzufügen:/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>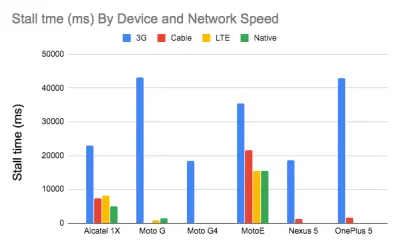
Anzahl der Blockierungen nach Gerät und Netzwerkgeschwindigkeit. Schnellere Geräte in schnelleren Netzwerken haben praktisch keine Verzögerungen. Nach Recherchen von Doug Sillars. (Große Vorschau) Die Leistung der Videowiedergabe ist eine eigene Geschichte, und wenn Sie detailliert darauf eingehen möchten, werfen Sie einen Blick auf eine andere Serie von Doug Sillars über den aktuellen Stand von Video und Best Practices für die Videobereitstellung, die Details zu den Metriken der Videobereitstellung enthält , Videovorladen, Komprimierung und Streaming. Schließlich können Sie mit Stream or Not überprüfen, wie langsam oder schnell Ihr Video-Streaming sein wird.
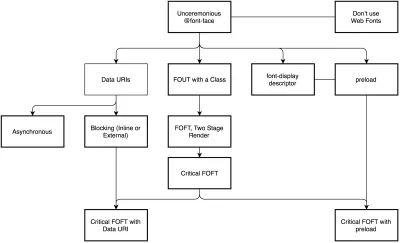
- Ist die Bereitstellung von Webfonts optimiert?
Die erste Frage, die es wert ist, gestellt zu werden, ist, ob wir überhaupt mit der Verwendung von UI-Systemschriften davonkommen können – wir müssen nur sicherstellen, dass sie auf verschiedenen Plattformen korrekt angezeigt werden. Wenn dies nicht der Fall ist, besteht eine hohe Wahrscheinlichkeit, dass die von uns bereitgestellten Webfonts Glyphen und zusätzliche Funktionen und Gewichtungen enthalten, die nicht verwendet werden. Wir können unseren Type Foundry bitten, Webfonts zu unterteilen, oder, wenn wir Open-Source-Schriften verwenden, sie selbst mit Glyphhanger oder Fontsquirrel unterteilen. Wir können sogar unseren gesamten Workflow mit Peter Mullers Subfont automatisieren, einem Befehlszeilentool, das Ihre Seite statisch analysiert, um die optimalsten Webfont-Subsets zu generieren und sie dann in unsere Seiten einzufügen.WOFF2-Unterstützung ist großartig, und wir können WOFF als Fallback für Browser verwenden, die es nicht unterstützen – oder vielleicht könnten ältere Browser Systemschriftarten bereitstellen. Es gibt viele, viele, viele Optionen für das Laden von Web-Fonts, und wir können eine der Strategien aus Zach Leathermans „Comprehensive Guide to Font-Loading Strategies“ auswählen (Code-Snippets sind auch als Rezepte zum Laden von Web-Fonts verfügbar).
Die wahrscheinlich besseren Optionen, die man heute in Betracht ziehen sollte, sind Critical FOFT mit
preloadund die „The Compromise“-Methode. Beide verwenden ein zweistufiges Rendering zum schrittweisen Bereitstellen von Webfonts – zuerst ein kleines Supersubset, das erforderlich ist, um die Seite schnell und genau mit dem Webfont zu rendern, und dann den Rest der Familie asynchron zu laden. Der Unterschied besteht darin, dass die „The Compromise“-Technik Polyfill nur dann asynchron lädt, wenn Schriftartladeereignisse nicht unterstützt werden, sodass Sie das Polyfill nicht standardmäßig laden müssen. Benötigen Sie einen schnellen Gewinn? Zach Leatherman hat ein schnelles 23-minütiges Tutorial und eine Fallstudie, um Ihre Schriftarten in Ordnung zu bringen.Im Allgemeinen kann es eine gute Idee sein, den
preloadRessourcenhinweis zu verwenden, um Schriftarten vorab zu laden, aber fügen Sie die Hinweise in Ihrem Markup nach dem Link zu kritischem CSS und JavaScript ein. Beipreloadgibt es ein Puzzle von Prioritäten, also ziehen Sie in Erwägung,rel="preload"-Elemente direkt vor den externen Blockierungsskripten in das DOM einzufügen. Laut Andy Davies „werden mithilfe eines Skripts injizierte Ressourcen vor dem Browser verborgen, bis das Skript ausgeführt wird, und wir können dieses Verhalten verwenden, um zu verzögern, wenn der Browser denpreloadHinweis entdeckt.“ Andernfalls kostet Sie das Laden von Schriftarten in der ersten Renderzeit.
Wenn alles kritisch ist, ist nichts kritisch. Laden Sie nur eine oder maximal zwei Schriftarten jeder Familie vor. (Bildnachweis: Zach Leatherman – Folie 93) (Große Vorschau) Es ist eine gute Idee, wählerisch zu sein und Dateien auszuwählen, die am wichtigsten sind, z. B. diejenigen, die für das Rendern kritisch sind oder die Ihnen helfen würden, sichtbare und störende Textumbrüche zu vermeiden. Im Allgemeinen rät Zach, ein oder zwei Schriftarten jeder Familie vorab zu laden – es ist auch sinnvoll, das Laden einiger Schriftarten zu verzögern, wenn sie weniger kritisch sind.
Es ist ziemlich üblich geworden, den Wert
local()(der sich namentlich auf eine lokale Schriftart bezieht) zu verwenden, wenn einefont-familyin der@font-faceRegel definiert wird:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }Die Idee ist vernünftig: Einige beliebte Open-Source-Schriftarten wie Open Sans sind mit einigen Treibern oder Apps vorinstalliert. Wenn die Schriftart also lokal verfügbar ist, muss der Browser die Webschriftart nicht herunterladen und kann die lokale anzeigen Schriftart sofort. Wie Bram Stein bemerkte: „Obwohl eine lokale Schriftart mit dem Namen einer Webschriftart übereinstimmt, handelt es sich höchstwahrscheinlich nicht um dieselbe Schriftart . Viele Webschriftarten unterscheiden sich von ihrer „Desktop“-Version. Der Text wird möglicherweise anders gerendert, einige Zeichen fallen möglicherweise aus zurück zu anderen Schriftarten, OpenType-Funktionen können vollständig fehlen oder die Zeilenhöhe kann unterschiedlich sein."
Da sich Schriftarten im Laufe der Zeit weiterentwickeln, kann sich die lokal installierte Version außerdem stark von der Webschriftart unterscheiden, wobei die Zeichen sehr unterschiedlich aussehen. Laut Bram ist es daher besser, lokal installierte Schriftarten und Webschriftarten niemals in
@font-faceRegeln zu mischen. Google Fonts ist diesem Beispiel gefolgt, indem eslocal()in den CSS-Ergebnissen für alle Benutzer außer Android-Anfragen für Roboto deaktiviert hat.Niemand wartet gerne darauf, dass der Inhalt angezeigt wird. Mit dem
font-displayCSS-Deskriptor können wir das Ladeverhalten von Fonts steuern und ermöglichen, dass Inhalte sofort (mitfont-display: optional) oder fast sofort (mit einem Timeout von 3s, solange der Font erfolgreich heruntergeladen wird – mit) lesbar sindfont-display: swap). (Nun, es ist ein bisschen komplizierter als das.)Wenn Sie jedoch die Auswirkungen von Textumbrüchen minimieren möchten, könnten wir die Font Loading API (unterstützt in allen modernen Browsern) verwenden. Konkret bedeutet das, dass wir für jede Schriftart ein
FontFaceObjekt erstellen, dann versuchen, sie alle abzurufen und sie erst dann auf die Seite anwenden. Auf diese Weise gruppieren wir alle Repaints , indem wir alle Schriftarten asynchron laden und dann genau einmal von Fallback-Schriftarten auf die Webschriftart umschalten. Sehen Sie sich Zachs Erklärung ab 32:15 und das Code-Snippet an:/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));Um einen sehr frühen Abruf der Schriftarten mit verwendeter Font Loading API zu initiieren, schlägt Adrian Bece vor, ein geschütztes Leerzeichen
nbsp;am oberen Rand desbodyund verstecken Sie ihn visuell mitaria-visibility: hiddenund einer.hidden-Klasse:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>Dies geht mit CSS einher, das verschiedene Schriftfamilien für verschiedene Ladezustände deklariert hat, wobei die Änderung von der Font Loading API ausgelöst wird, sobald die Schriftarten erfolgreich geladen wurden:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }Wenn Sie sich jemals gefragt haben, warum Lighthouse trotz all Ihrer Optimierungen immer noch vorschlägt, Render-Blocking-Ressourcen (Schriftarten) zu eliminieren, bietet Adrian Bece im selben Artikel einige Techniken, um Lighthouse glücklich zu machen, zusammen mit einem Gatsby Omni Font Loader, einer performanten asynchronen Schriftart Lade- und Flash Of Unstyled Text (FOUT)-Handling-Plugin für Gatsby.
Viele von uns verwenden möglicherweise ein CDN oder einen Drittanbieter-Host, um Webfonts zu laden. Im Allgemeinen ist es immer besser, alle Ihre statischen Assets selbst zu hosten, wenn Sie können, also ziehen Sie die Verwendung von google-webfonts-helper in Betracht, eine problemlose Möglichkeit, Google Fonts selbst zu hosten. Und wenn dies nicht möglich ist, können Sie die Google Font-Dateien möglicherweise über den Seitenursprung weiterleiten.
Es ist jedoch erwähnenswert, dass Google einiges an Vorarbeit leistet, sodass ein Server möglicherweise etwas angepasst werden muss, um Verzögerungen zu vermeiden ( danke, Barry! ).
Dies ist sehr wichtig, zumal seit Chrome v86 (veröffentlicht im Oktober 2020) standortübergreifende Ressourcen wie Schriftarten nicht mehr auf demselben CDN geteilt werden können – aufgrund des partitionierten Browser-Cache. Dieses Verhalten war jahrelang Standard in Safari.

Aber wenn es gar nicht geht, gibt es eine Möglichkeit, mit dem Snippet von Harry Roberts zu den schnellstmöglichen Google Fonts zu gelangen:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harrys Strategie besteht darin, zuerst den Ursprung der Schriften präventiv aufzuwärmen. Dann initiieren wir einen asynchronen Abruf mit hoher Priorität für die CSS-Datei. Anschließend initiieren wir einen asynchronen Abruf mit niedriger Priorität, der erst nach der Ankunft auf die Seite angewendet wird (mit einem Print-Stylesheet-Trick). Wenn schließlich JavaScript nicht unterstützt wird, greifen wir auf die ursprüngliche Methode zurück.
Apropos Google Fonts: Sie können bis zu 90 % der Größe von Google Fonts-Anfragen reduzieren, indem Sie nur die benötigten Zeichen mit
&textdeklarieren. Außerdem wurde die Unterstützung für die Schriftanzeige kürzlich auch zu Google Fonts hinzugefügt, sodass wir sie sofort verwenden können.Aber ein kurzes Wort der Vorsicht. Wenn Sie
font-display: optionalverwenden, ist es möglicherweise nicht optimal, auchpreloadzu verwenden, da dies diese Webfont-Anforderung frühzeitig auslöst (was zu einer Netzwerküberlastung führt, wenn Sie andere kritische Pfadressourcen haben, die abgerufen werden müssen). Verwenden Siepreconnectfür schnellere ursprungsübergreifende Zeichensatzanforderungen, aber seien Sie beimpreloadvorsichtig, da das Vorladen von Zeichensätzen von einem anderen Ursprung zu Netzwerkkonflikten führen wird. Alle diese Techniken werden in Zachs Rezepten zum Laden von Webfonts behandelt.Andererseits kann es eine gute Idee sein, Webfonts abzulehnen (oder zumindest in der zweiten Stufe zu rendern), wenn der Benutzer „Bewegung reduzieren“ in den Barrierefreiheitseinstellungen aktiviert oder sich für den Datensparmodus entschieden hat (siehe Kopfzeile „
Save-Data“). , oder wenn der Benutzer eine langsame Verbindung hat (über die Netzwerkinformations-API).Wir können auch die CSS-Medienabfrage „prefers
prefers-reduced-data“ verwenden, um Schriftartdeklarationen nicht zu definieren, wenn der Benutzer sich für den Datensparmodus entschieden hat (es gibt auch andere Anwendungsfälle). Die Medienabfrage würde im Grunde zeigen, ob derSave-DataAnforderungsheader von der Client-Hinweis-HTTP-Erweiterung ein-/ausgeschaltet ist, um die Verwendung mit CSS zu ermöglichen. Derzeit nur in Chrome und Edge hinter einem Flag unterstützt.Metriken? Um die Leistung beim Laden von Webfonts zu messen, berücksichtigen Sie die Metrik All Text Visible (der Moment, in dem alle Fonts geladen wurden und alle Inhalte in Webfonts angezeigt werden), Time to Real Italics sowie Web Font Reflow Count nach dem ersten Rendern. Offensichtlich ist die Leistung umso besser, je niedriger beide Metriken sind.
Was ist mit variablen Schriftarten , fragen Sie sich vielleicht? Es ist wichtig zu beachten, dass variable Schriftarten möglicherweise erhebliche Leistungsüberlegungen erfordern. Sie geben uns einen viel breiteren Gestaltungsspielraum für typografische Entscheidungen, aber das geht auf Kosten einer einzigen seriellen Anfrage im Gegensatz zu einer Reihe individueller Dateianfragen.
Während variable Schriftarten die kombinierte Gesamtdateigröße von Schriftartdateien drastisch reduzieren, kann diese einzelne Anforderung langsam sein und die Wiedergabe aller Inhalte auf einer Seite blockieren. Es ist also immer noch wichtig, die Schriftart zu unterteilen und in Zeichensätze aufzuteilen. Positiv ist jedoch, dass wir mit einer variablen Schriftart standardmäßig genau einen Reflow erhalten, sodass kein JavaScript erforderlich ist, um Repaints zu gruppieren.
Nun, was würde dann eine kugelsichere Strategie zum Laden von Webfonts ausmachen? Schriften unterteilen und für das 2-Stufen-Rendering vorbereiten, sie mit einem
font-displayDeskriptor deklarieren, die API zum Laden von Schriften verwenden, um Neuzeichnungen zu gruppieren und Schriften im Cache eines dauerhaften Dienstmitarbeiters zu speichern. Fügen Sie beim ersten Besuch das Vorladen von Skripten direkt vor den blockierenden externen Skripten ein. Bei Bedarf können Sie auf Bram Steins Font Face Observer zurückgreifen. Und wenn Sie daran interessiert sind, die Leistung beim Laden von Schriftarten zu messen, untersucht Andreas Marschke die Leistungsverfolgung mit der Schriftart-API und der UserTiming-API.Vergessen Sie schließlich nicht,
unicode-rangeeinzuschließen, um eine große Schriftart in kleinere sprachspezifische Schriftarten zu zerlegen, und verwenden Sie den Font-Style-Matcher von Monica Dinculescu, um eine störende Verschiebung im Layout aufgrund von Größenunterschieden zwischen dem Fallback und dem zu minimieren Web-Schriftarten.Um eine Webschriftart für eine Fallback-Schriftart zu emulieren, können wir alternativ @font-face-Deskriptoren verwenden, um Schriftartmetriken zu überschreiben (Demo, aktiviert in Chrome 87). (Beachten Sie jedoch, dass Anpassungen bei komplizierten Schriftstapeln kompliziert sind.)
Sieht die Zukunft rosig aus? Mit der progressiven Zeichensatzanreicherung sind wir möglicherweise in der Lage, „nur den erforderlichen Teil des Zeichensatzes auf einer bestimmten Seite herunterzuladen und für nachfolgende Anforderungen für diesen Zeichensatz den ursprünglichen Download dynamisch mit zusätzlichen Glyphensätzen zu ‚patchen‘, wie dies auf den nachfolgenden Seiten erforderlich ist Ansichten", wie Jason Pamental es erklärt. Die inkrementelle Transfer-Demo ist bereits verfügbar und in Arbeit.
Build-Optimierungen
- Haben wir unsere Prioritäten definiert?
Es ist eine gute Idee, zuerst zu wissen, womit Sie es zu tun haben. Führen Sie eine Bestandsaufnahme aller Ihrer Assets (JavaScript, Bilder, Schriftarten, Skripte von Drittanbietern und „teure“ Module auf der Seite, wie z. B. Karussells, komplexe Infografiken und Multimedia-Inhalte) durch und unterteilen Sie sie in Gruppen.Richten Sie eine Tabelle ein . Definieren Sie das grundlegende Kernerlebnis für ältere Browser (dh vollständig zugängliche Kerninhalte), das erweiterte Erlebnis für leistungsfähige Browser (dh ein erweitertes, vollständiges Erlebnis) und die Extras (Assets, die nicht unbedingt erforderlich sind und verzögert geladen werden können, wie z Webschriftarten, unnötige Stile, Karussellskripte, Videoplayer, Widgets für soziale Medien, große Bilder). Vor Jahren haben wir einen Artikel zum Thema „Improving Smashing Magazine’s Performance“ veröffentlicht, der diesen Ansatz ausführlich beschreibt.
Bei der Leistungsoptimierung müssen wir unsere Prioritäten widerspiegeln. Laden Sie sofort das Kernerlebnis , dann die Erweiterungen und dann die Extras .
- Verwenden Sie native JavaScript-Module in der Produktion?
Erinnern Sie sich an die gute alte Senf-Schnitt-Technik, um das Kernerlebnis an ältere Browser und ein verbessertes Erlebnis an moderne Browser zu senden? Eine aktualisierte Variante der Technik könnte ES2017+<script type="module">verwenden, auch als module/nomodule-Muster bekannt (auch von Jeremy Wagner als differentielles Serving eingeführt).Die Idee ist, zwei separate JavaScript-Bundles zu kompilieren und bereitzustellen: das „normale“ Build, das eine mit Babel-Transformationen und Polyfills und sie nur für ältere Browser bereitzustellen, die sie tatsächlich benötigen, und ein weiteres Bundle (gleiche Funktionalität), das keine Transformationen enthält oder Polyfills.
Infolgedessen tragen wir dazu bei, die Blockierung des Haupt-Threads zu reduzieren, indem wir die Menge an Skripts reduzieren, die der Browser verarbeiten muss. Jeremy Wagner hat einen umfassenden Artikel über differenzielles Serving und wie Sie es in Ihrer Build-Pipeline einrichten, von der Einrichtung von Babel bis hin zu den erforderlichen Anpassungen in Webpack und den Vorteilen dieser Arbeit veröffentlicht.
Native JavaScript-Modulskripte werden standardmäßig zurückgestellt, sodass der Browser während der HTML-Analyse das Hauptmodul herunterlädt.

Native JavaScript-Module werden standardmäßig zurückgestellt. So ziemlich alles über native JavaScript-Module. (Große Vorschau) Ein Hinweis zur Warnung: Das module/nomodule-Muster kann auf einigen Clients nach hinten losgehen, daher sollten Sie eine Problemumgehung in Betracht ziehen: Jeremys weniger riskantes differentielles Serving-Muster, das jedoch den Preload-Scanner umgeht, was die Leistung auf eine Weise beeinträchtigen könnte, die dies möglicherweise nicht tut antizipieren. ( Danke Jeremy! )
Tatsächlich unterstützt Rollup Module als Ausgabeformat, sodass wir sowohl Code bündeln als auch Module in der Produktion bereitstellen können. Parcel verfügt über Modulunterstützung in Parcel 2. Für Webpack automatisiert module-nomodule-plugin die Generierung von module/nomodule-Skripten.
Hinweis : Es sei darauf hingewiesen, dass die Funktionserkennung allein nicht ausreicht, um eine fundierte Entscheidung über die an diesen Browser zu sendende Nutzlast zu treffen. Alleine können wir die Gerätefähigkeit nicht von der Browserversion ableiten. Zum Beispiel laufen billige Android-Telefone in Entwicklungsländern meistens mit Chrome und werden trotz ihrer begrenzten Speicher- und CPU-Fähigkeiten den Senf schneiden.
Letztendlich werden wir mit dem Device Memory Client Hints Header in der Lage sein, Low-End-Geräte zuverlässiger anzusprechen. Zum Zeitpunkt des Schreibens wird der Header nur in Blink unterstützt (er gilt allgemein für Client-Hinweise). Da der Gerätespeicher auch über eine JavaScript-API verfügt, die in Chrome verfügbar ist, könnte eine Option darin bestehen, die Funktion basierend auf der API zu erkennen und auf das Modul-/Kein-Modul-Muster zurückzugreifen, wenn es nicht unterstützt wird ( Danke, Yoav! ).
- Verwenden Sie Tree-Shaking, Scope Hoisting und Code-Splitting?
Tree-Shaking ist eine Möglichkeit, Ihren Build-Prozess zu bereinigen, indem nur Code eingefügt wird, der tatsächlich in der Produktion verwendet wird, und ungenutzte Importe in Webpack eliminieren. Mit Webpack und Rollup haben wir auch Scope Hoisting, mit dem beide Tools erkennen können, wo dieimportabgeflacht und in eine Inline-Funktion umgewandelt werden kann, ohne den Code zu beeinträchtigen. Mit Webpack können wir auch JSON Tree Shaking verwenden.Code-Splitting ist eine weitere Webpack-Funktion, die Ihre Codebasis in „Blöcke“ aufteilt, die bei Bedarf geladen werden. Nicht das gesamte JavaScript muss sofort heruntergeladen, geparst und kompiliert werden. Sobald Sie Trennpunkte in Ihrem Code definiert haben, kann sich Webpack um die Abhängigkeiten und ausgegebenen Dateien kümmern. Es ermöglicht Ihnen, den anfänglichen Download klein zu halten und Code bei Bedarf anzufordern, wenn er von der Anwendung angefordert wird. Alexander Kondrov hat eine fantastische Einführung in das Code-Splitting mit Webpack und React.
Erwägen Sie die Verwendung von preload-webpack-plugin, das Routen nimmt, die Sie im Code aufgeteilt haben, und dann den Browser auffordert, sie mit
<link rel="preload">oder<link rel="prefetch">zu laden. Webpack-Inline-Direktiven geben auch eine gewisse Kontrolle überpreload/prefetch. (Achten Sie jedoch auf Priorisierungsprobleme.)Wo werden Splitpunkte definiert? Durch Nachverfolgen, welche Teile von CSS/JavaScript verwendet werden und welche nicht. Umar Hansa erklärt, wie Sie Code Coverage von Devtools verwenden können, um dies zu erreichen.
Bei Einzelseitenanwendungen benötigen wir einige Zeit, um die App zu initialisieren, bevor wir die Seite rendern können. Ihre Einstellung erfordert Ihre benutzerdefinierte Lösung, aber Sie können nach Modulen und Techniken Ausschau halten, um die anfängliche Renderzeit zu beschleunigen. Hier erfahren Sie beispielsweise, wie Sie die React-Leistung debuggen und häufige React-Leistungsprobleme beseitigen, und wie Sie die Leistung in Angular verbessern. Im Allgemeinen treten die meisten Leistungsprobleme beim ersten Bootstrap der App auf.
Also, was ist der beste Weg, Code-Split aggressiv, aber nicht zu aggressiv zu machen? Laut Phil Walton „könnten wir zusätzlich zum Code-Splitting über dynamische Importe auch Code-Splitting auf Paketebene verwenden, bei der jedes importierte Knotenmodul basierend auf seinem Paketnamen in einen Chunk gesteckt wird.“ Phil bietet auch ein Tutorial zum Erstellen an.
- Können wir die Ausgabe von Webpack verbessern?
Da Webpack oft als mysteriös angesehen wird, gibt es viele Webpack-Plugins, die sich als nützlich erweisen können, um die Ausgabe von Webpack weiter zu reduzieren. Nachfolgend sind einige der obskureren aufgeführt, die möglicherweise etwas mehr Aufmerksamkeit erfordern.Einer der interessantesten stammt aus dem Thread von Ivan Akulov. Stellen Sie sich vor, Sie haben eine Funktion, die Sie einmal aufrufen, ihr Ergebnis in einer Variablen speichern und diese Variable dann nicht verwenden. Beim Tree-Shaking wird die Variable entfernt, aber nicht die Funktion, da sie sonst verwendet werden könnte. Wenn die Funktion jedoch nirgendwo verwendet wird, möchten Sie sie möglicherweise entfernen. Stellen Sie dazu dem Funktionsaufruf
/*#__PURE__*/voran, was von Uglify und Terser unterstützt wird – fertig!
Um eine solche Funktion zu entfernen, wenn ihr Ergebnis nicht verwendet wird, stellen Sie dem Funktionsaufruf /*#__PURE__*/. Via Ivan Akulov.(Große Vorschau)Hier sind einige der anderen Tools, die Ivan empfiehlt:
- purgecss-webpack-plugin entfernt ungenutzte Klassen, insbesondere wenn Sie Bootstrap oder Tailwind verwenden.
-
optimization.splitChunks: 'all'mit split-chunks-plugin. Dies würde dazu führen, dass Webpack Ihre Eintragspakete für ein besseres Caching automatisch durch Code aufteilt. -
optimization.runtimeChunk: true. Dies würde die Laufzeit von Webpack in einen separaten Chunk verschieben – und auch das Caching verbessern. - google-fonts-webpack-plugin lädt Schriftdateien herunter, damit Sie sie von Ihrem Server aus bereitstellen können.
- workbox-webpack-plugin ermöglicht es Ihnen, einen Service Worker mit einem Precaching-Setup für alle Ihre Webpack-Assets zu generieren. Sehen Sie sich auch die Service Worker Packages an, eine umfassende Anleitung mit Modulen, die sofort angewendet werden können. Oder verwenden Sie preload-webpack-plugin, um
preload/prefetchfür alle JavaScript-Chunks zu generieren. - speed-measure-webpack-plugin misst die Build-Geschwindigkeit Ihres Webpacks und gibt Aufschluss darüber, welche Schritte des Build-Prozesses am zeitaufwändigsten sind.
- Duplicate-Package-Checker-Webpack-Plugin warnt, wenn Ihr Bundle mehrere Versionen desselben Pakets enthält.
- Verwenden Sie Bereichsisolierung und kürzen Sie CSS-Klassennamen dynamisch zum Zeitpunkt der Kompilierung.
- Können Sie JavaScript in einen Web Worker auslagern?
Um die negativen Auswirkungen auf Time-to-Interactive zu reduzieren, könnte es eine gute Idee sein, sich mit der Auslagerung von schwerem JavaScript in einen Web Worker zu befassen.Da die Codebasis weiter wächst, werden die Leistungsengpässe der Benutzeroberfläche auftauchen und die Erfahrung des Benutzers verlangsamen. Das liegt daran, dass DOM-Vorgänge neben Ihrem JavaScript im Hauptthread ausgeführt werden. Mit Webworkern können wir diese teuren Vorgänge in einen Hintergrundprozess verschieben, der in einem anderen Thread ausgeführt wird. Typische Anwendungsfälle für Webworker sind das Vorabrufen von Daten und Progressive Web Apps, um einige Daten im Voraus zu laden und zu speichern, damit Sie sie später bei Bedarf verwenden können. Und Sie könnten Comlink verwenden, um die Kommunikation zwischen der Hauptseite und dem Arbeiter zu optimieren. Es gibt noch einiges zu tun, aber wir kommen dorthin.
Es gibt einige interessante Fallstudien zu Webworkern, die unterschiedliche Ansätze zur Übertragung von Frameworks und App-Logik auf Webworker zeigen. Fazit: Im Allgemeinen gibt es noch einige Herausforderungen, aber es gibt bereits einige gute Anwendungsfälle ( Danke, Ivan Akulov! ).
Ab Chrome 80 wurde ein neuer Modus für Webworker mit Leistungsvorteilen von JavaScript-Modulen ausgeliefert, genannt Modulworker. Wir können das Laden und Ausführen von Skripts so ändern, dass sie mit
script type="module"übereinstimmen, und wir können auch dynamische Importe für Lazy-Loading-Code verwenden, ohne die Ausführung des Workers zu blockieren.Wie man anfängt? Hier sind einige Ressourcen, die einen Blick wert sind:
- Surma hat eine hervorragende Anleitung zum Ausführen von JavaScript außerhalb des Haupt-Threads des Browsers und auch Wann sollten Sie Web Worker verwenden? veröffentlicht.
- Sehen Sie sich auch Surmas Vortrag über die Off-the-Main-Thread-Architektur an.
- A Quest to Guarantee Responsiveness von Shubhie Panicker und Jason Miller geben einen detaillierten Einblick, wie man Webworker einsetzt und wann man sie vermeidet.
- Benutzern aus dem Weg gehen: Weniger Jank mit Web-Workern hebt nützliche Muster für die Arbeit mit Web-Workern hervor, effektive Methoden zur Kommunikation zwischen Mitarbeitern, zur Handhabung komplexer Datenverarbeitung außerhalb des Haupt-Threads sowie zum Testen und Debuggen.
- Mit Workerize können Sie ein Modul in einen Web Worker verschieben und automatisch exportierte Funktionen als asynchrone Proxys widerspiegeln.
- Wenn Sie Webpack verwenden, können Sie workerize-loader verwenden. Alternativ können Sie auch das Worker-Plugin verwenden.

Verwenden Sie Web Worker, wenn Code für lange Zeit blockiert, aber vermeiden Sie sie, wenn Sie sich auf das DOM verlassen, Eingabeantworten verarbeiten und nur minimale Verzögerungen benötigen. (über Addy Osmani) (Große Vorschau) Beachten Sie, dass Web Worker keinen Zugriff auf das DOM haben, da das DOM nicht „thread-sicher“ ist und der Code, den sie ausführen, in einer separaten Datei enthalten sein muss.
- Können Sie "heiße Pfade" an WebAssembly auslagern?
Wir könnten rechenintensive Aufgaben an WebAssembly ( WASM ) auslagern, ein binäres Befehlsformat, das als portables Ziel für die Kompilierung von Hochsprachen wie C/C++/Rust entwickelt wurde. Die Browserunterstützung ist bemerkenswert und wurde kürzlich praktikabel, da Funktionsaufrufe zwischen JavaScript und WASM immer schneller werden. Außerdem wird es sogar in der Edge-Cloud von Fastly unterstützt.Natürlich soll WebAssembly JavaScript nicht ersetzen, aber es kann es ergänzen, wenn Sie CPU-Hogs bemerken. Für die meisten Web-Apps ist JavaScript besser geeignet, und WebAssembly wird am besten für rechenintensive Web-Apps wie Spiele verwendet.
Wenn Sie mehr über WebAssembly erfahren möchten:
- Lin Clark hat eine ausführliche Serie zu WebAssembly geschrieben, und Milica Mihajlija bietet einen allgemeinen Überblick darüber, wie man nativen Code im Browser ausführt, warum man das tun sollte und was das alles für JavaScript und die Zukunft der Webentwicklung bedeutet.
- How We Used WebAssembly To Speed Up Our Web App By 20X (Fallstudie) hebt eine Fallstudie hervor, die zeigt, wie langsame JavaScript-Berechnungen durch kompiliertes WebAssembly ersetzt wurden und erhebliche Leistungsverbesserungen brachten.
- Patrick Hamann hat über die wachsende Rolle von WebAssembly gesprochen, und er entlarvt einige Mythen über WebAssembly, untersucht seine Herausforderungen und wir können es heute praktisch in Anwendungen einsetzen.
- Google Codelabs bietet eine Einführung in WebAssembly, einen 60-minütigen Kurs, in dem Sie lernen, wie Sie nativen Code in C in WebAssembly kompilieren und ihn dann direkt aus JavaScript aufrufen.
- Alex Danilo hat WebAssembly und seine Funktionsweise bei seinem Google I/O-Vortrag erklärt. Außerdem teilte Benedek Gagyi eine praktische Fallstudie zu WebAssembly mit, insbesondere dazu, wie das Team es als Ausgabeformat für seine C++-Codebasis für iOS, Android und die Website verwendet.
Sie sind sich immer noch nicht sicher , wann Sie Web Workers, Web Assembly, Streams oder vielleicht die WebGL-JavaScript-API verwenden sollen, um auf die GPU zuzugreifen? Accelerating JavaScript ist eine kurze, aber hilfreiche Anleitung, die erklärt, wann man was und warum verwendet – auch mit einem praktischen Flussdiagramm und vielen nützlichen Ressourcen.
- Stellen wir Legacy-Code nur für Legacy-Browser bereit?
Da ES2017 in modernen Browsern bemerkenswert gut unterstützt wird, können wirbabelEsmPluginverwenden, um nur ES2017+-Funktionen zu transpilieren, die von den modernen Browsern, auf die Sie abzielen, nicht unterstützt werden.Houssein Djirdeh und Jason Miller haben kürzlich einen umfassenden Leitfaden zum Transpilieren und Servieren von modernem und veraltetem JavaScript veröffentlicht, in dem detailliert beschrieben wird, wie es mit Webpack und Rollup funktioniert, sowie die erforderlichen Tools. Sie können auch abschätzen, wie viel JavaScript Sie auf Ihrer Website oder in App-Bundles einsparen können.
JavaScript-Module werden in allen gängigen Browsern unterstützt, verwenden Sie also use
script type="module", damit Browser mit ES-Modulunterstützung die Datei laden können, während ältere Browser Legacy-Builds mitscript nomoduleladen könnten.Heutzutage können wir modulbasiertes JavaScript schreiben, das nativ im Browser läuft, ohne Transpiler oder Bundler.
<link rel="modulepreload">Header bietet eine Möglichkeit, das frühe (und hochpriorisierte) Laden von Modulskripten zu initiieren. Im Grunde genommen ist es eine raffinierte Methode, die Bandbreitennutzung zu maximieren, indem dem Browser mitgeteilt wird, was er abrufen muss, damit er während dieser langen Roundtrips nichts zu tun hat. Außerdem hat Jake Archibald einen lesenswerten ausführlichen Artikel mit Fallstricken und Dingen, die man bei ES-Modulen beachten sollte, veröffentlicht.
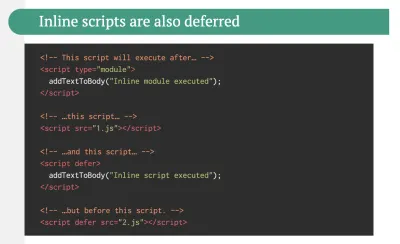
- Identifizieren und überschreiben Sie Legacy-Code mit inkrementeller Entkopplung .
Langlebige Projekte neigen dazu, Staub und veralteten Code zu sammeln. Sehen Sie sich Ihre Abhängigkeiten noch einmal an und schätzen Sie ab, wie viel Zeit erforderlich wäre, um Legacy-Code umzugestalten oder neu zu schreiben, der in letzter Zeit Probleme verursacht hat. Natürlich ist es immer ein großes Unterfangen, aber sobald Sie die Auswirkungen des Legacy-Codes kennen, könnten Sie mit der schrittweisen Entkopplung beginnen.Richten Sie zunächst Metriken ein, die nachverfolgen, ob das Verhältnis von Legacy-Code-Aufrufen konstant bleibt oder sinkt, nicht steigt. Halten Sie das Team öffentlich davon ab, die Bibliothek zu verwenden, und stellen Sie sicher, dass Ihr CI Entwickler benachrichtigt, wenn es in Pull-Anforderungen verwendet wird. Polyfills könnten beim Übergang von Legacy-Code zu einer neu geschriebenen Codebasis helfen, die standardmäßige Browserfunktionen verwendet.
- Identifizieren und entfernen Sie unbenutztes CSS/JS .
Die CSS- und JavaScript-Codeabdeckung in Chrome ermöglicht es Ihnen, zu erfahren, welcher Code ausgeführt/angewendet wurde und welcher nicht. Sie können mit der Aufzeichnung der Abdeckung beginnen, Aktionen auf einer Seite ausführen und dann die Ergebnisse der Codeabdeckung untersuchen. Sobald Sie unbenutzten Code entdeckt haben, suchen Sie diese Module und laden Sie sie verzögert mitimport()(siehe den gesamten Thread). Wiederholen Sie dann das Abdeckungsprofil und überprüfen Sie, ob es jetzt beim anfänglichen Laden weniger Code versendet.Sie können Puppeteer verwenden, um die Codeabdeckung programmgesteuert zu erfassen. Mit Chrome können Sie auch Code-Coverage-Ergebnisse exportieren. Wie Andy Davies angemerkt hat, möchten Sie vielleicht Code-Coverage für moderne und ältere Browser sammeln.
Es gibt viele andere Anwendungsfälle und Tools für Puppetter, die möglicherweise etwas mehr Aufmerksamkeit erfordern:
- Anwendungsfälle für Puppeteer, wie z. B. automatisches visuelles Diffing oder Überwachung von nicht verwendetem CSS bei jedem Build,
- Web-Performance-Rezepte mit Puppeteer,
- Nützliche Tools zum Aufzeichnen und Generieren von Pupeeteer- und Playwright-Skripten,
- Außerdem können Sie Tests sogar direkt in DevTools aufzeichnen,
- Umfassender Überblick über Puppeteer von Nitay Neeman mit Beispielen und Anwendungsfällen.
Wir können Puppeteer Recorder und Puppeteer Sandbox verwenden, um Browserinteraktionen aufzuzeichnen und Puppeteer- und Playwright-Skripte zu generieren. (Große Vorschau) Darüber hinaus können Ihnen purgecss, UnCSS und Helium dabei helfen, ungenutzte Stile aus CSS zu entfernen. Und wenn Sie sich nicht sicher sind, ob irgendwo ein verdächtiger Code verwendet wird, können Sie dem Rat von Harry Roberts folgen: Erstellen Sie ein 1×1px großes transparentes GIF für eine bestimmte Klasse und legen Sie es in einem
dead/-Verzeichnis ab, z. B./assets/img/dead/comments.gif.Danach legen Sie dieses bestimmte Bild als Hintergrund für den entsprechenden Selektor in Ihrem CSS fest, lehnen sich zurück und warten ein paar Monate, ob die Datei in Ihren Protokollen erscheint. Wenn es keine Einträge gibt, hatte niemand diese Legacy-Komponente auf seinem Bildschirm gerendert: Sie können wahrscheinlich fortfahren und alles löschen.
Für die I-feel-adventurous- Abteilung könnten Sie sogar das Sammeln von nicht verwendetem CSS über eine Reihe von Seiten automatisieren, indem Sie DevTools mithilfe von DevTools überwachen.
- Kürzen Sie die Größe Ihrer JavaScript-Pakete.
Wie Addy Osmani angemerkt hat, besteht eine hohe Wahrscheinlichkeit, dass Sie vollständige JavaScript-Bibliotheken versenden, wenn Sie nur einen Bruchteil benötigen, zusammen mit veralteten Polyfills für Browser, die sie nicht benötigen, oder einfach nur mit doppeltem Code. Um den Overhead zu vermeiden, sollten Sie die Verwendung von webpack-libs-optimizations in Betracht ziehen, die ungenutzte Methoden und Polyfills während des Build-Prozesses entfernen.Überprüfen und überprüfen Sie die Polyfills , die Sie an ältere Browser und an moderne Browser senden, und gehen Sie strategischer damit um. Schauen Sie sich polyfill.io an, einen Dienst, der eine Anfrage für eine Reihe von Browserfunktionen akzeptiert und nur die Polyfills zurückgibt, die vom anfragenden Browser benötigt werden.
Fügen Sie auch Bundle-Audits in Ihren regulären Arbeitsablauf ein. Es könnte einige leichte Alternativen zu schweren Bibliotheken geben, die Sie vor Jahren hinzugefügt haben, z. B. könnte Moment.js (jetzt eingestellt) ersetzt werden durch:
- Native Internationalisierungs-API,
- Day.js mit einer vertrauten Moment.js-API und Mustern,
- date-fns oder
- Luxon.
- Sie können auch Skypack Discover verwenden, das von Menschen überprüfte Paketempfehlungen mit einer qualitätsorientierten Suche kombiniert.
Die Untersuchungen von Benedikt Rotsch zeigten, dass ein Wechsel von Moment.js zu date-fns etwa 300 ms für First Paint auf 3G und einem Low-End-Mobiltelefon einsparen könnte.
Bei der Bündelprüfung könnte Bundlephobia helfen, die Kosten für das Hinzufügen eines npm-Pakets zu Ihrem Bündel zu ermitteln. size-limit erweitert die grundlegende Überprüfung der Bundle-Größe um Details zur JavaScript-Ausführungszeit. Sie können diese Kosten sogar in ein benutzerdefiniertes Lighthouse-Audit integrieren. Das gilt auch für Frameworks. Durch Entfernen oder Trimmen des Vue MDC-Adapters (Materialkomponenten für Vue) sinken die Stile von 194 KB auf 10 KB.
Es gibt viele weitere Tools, die Ihnen helfen, eine fundierte Entscheidung über die Auswirkungen Ihrer Abhängigkeiten und praktikable Alternativen zu treffen:
- webpack-bundle-analyzer
- Quellkarten-Explorer
- Bündel Buddy
- Bündelphobie
- Die Webpack-Analyse zeigt, warum ein bestimmtes Modul im Paket enthalten ist.
- Der Bundle-Wizard erstellt auch eine Karte der Abhängigkeiten für die gesamte Seite.
- Webpack-Größen-Plugin
- Importkosten für visuellen Code
Alternativ zum Versand des gesamten Frameworks können Sie Ihr Framework kürzen und in ein reines JavaScript-Bundle kompilieren, das keinen zusätzlichen Code erfordert. Svelte tut es, ebenso wie das Rawact Babel-Plugin, das React.js-Komponenten zur Build-Zeit in native DOM-Operationen transpiliert. Warum? Nun, wie die Betreuer erklären, „react-dom enthält Code für alle möglichen Komponenten/HTMLElemente, die gerendert werden können, einschließlich Code für inkrementelles Rendering, Scheduling, Event-Handling usw. Aber es gibt Anwendungen, die (anfänglich) nicht alle diese Features benötigen Seite laden). Für solche Anwendungen kann es sinnvoll sein, native DOM-Operationen zu verwenden, um die interaktive Benutzeroberfläche zu erstellen."
- Verwenden wir Teilhydratation?
Angesichts der Menge an JavaScript, die in Anwendungen verwendet wird, müssen wir Wege finden, so wenig wie möglich an den Client zu senden. Eine Möglichkeit, dies zu tun – und wir haben es bereits kurz behandelt – ist die teilweise Flüssigkeitszufuhr. Die Idee ist ganz einfach: Anstatt SSR zu machen und dann die gesamte App an den Client zu senden, würden nur kleine Teile des JavaScripts der App an den Client gesendet und dann hydriert. Wir können es uns als mehrere winzige React-Apps mit mehreren Renderwurzeln auf einer ansonsten statischen Website vorstellen.Im Artikel „Der Fall der Teilhydratation (mit Next und Preact)“ erklärt Lukas Bombach, wie das Team hinter Welt.de, einer der Nachrichtenagenturen in Deutschland, mit der Teilhydratation eine bessere Performance erzielt hat. Sie können auch das GitHub-Repo mit der nächsten Superleistung mit Erklärungen und Code-Snippets überprüfen.
Sie könnten auch alternative Optionen in Betracht ziehen:
- teilweise Hydratation mit Preact und Eleventy,
- progressive Hydratation in React GitHub Repo,
- Lazy-Hydration in Vue.js (GitHub-Repo),
- Importieren Sie auf Interaktionsmuster, um nicht kritische Ressourcen (z. B. Komponenten, Einbettungen) zu laden, wenn ein Benutzer mit der Benutzeroberfläche interagiert, die sie benötigt.
Jason Miller hat funktionierende Demos darüber veröffentlicht, wie die progressive Flüssigkeitszufuhr mit React implementiert werden könnte, damit Sie sie sofort verwenden können: Demo 1, Demo 2, Demo 3 (auch auf GitHub verfügbar). Außerdem können Sie in die Bibliothek der vorgerenderten React-Komponenten schauen.
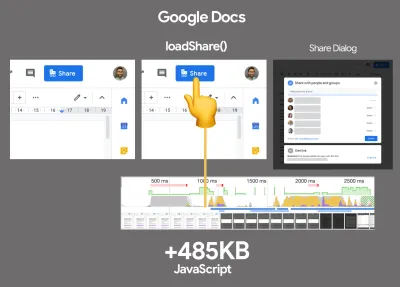
Der Import bei Interaktion für Erstanbietercode sollte nur durchgeführt werden, wenn Sie vor der Interaktion keine Ressourcen vorab abrufen können. (Große Vorschau) - Haben wir die Strategie für React/SPA optimiert?
Kämpfen Sie mit der Leistung Ihrer Single-Page-Anwendung? Jeremy Wagner hat die Auswirkungen der clientseitigen Framework-Leistung auf eine Vielzahl von Geräten untersucht und einige der Implikationen und Richtlinien hervorgehoben, die wir bei der Verwendung beachten sollten.Als Ergebnis hier ist eine SPA-Strategie, die Jeremy für das React-Framework vorschlägt (aber sie sollte sich für andere Frameworks nicht wesentlich ändern):
- Refaktorieren Sie zustandsbehaftete Komponenten wann immer möglich in zustandslose Komponenten.
- Rendern Sie nach Möglichkeit zustandslose Komponenten vor, um die Antwortzeit des Servers zu minimieren. Nur auf dem Server rendern.
- Erwägen Sie für zustandsbehaftete Komponenten mit einfacher Interaktivität das Pre- oder Server-Rendering dieser Komponente und ersetzen Sie ihre Interaktivität durch Framework-unabhängige Ereignis-Listener .
- Wenn Sie zustandsbehaftete Komponenten auf dem Client hydratisieren müssen, verwenden Sie Lazy Hydration für Sichtbarkeit oder Interaktion.
- Planen Sie für langsam hydratisierte Komponenten ihre Hydratation während der Leerlaufzeit des Haupt-Threads mit
requestIdleCallback.
Es gibt ein paar andere Strategien, die Sie vielleicht verfolgen oder überprüfen möchten:
- Leistungsüberlegungen für CSS-in-JS in React-Apps
- Reduzieren Sie die Next.js-Bundle-Größe, indem Sie Polyfills nur bei Bedarf laden, indem Sie dynamische Importe und Lazy Hydration verwenden.
- Secrets of JavaScript: A tale of React, Performance Optimization and Multi-threading, eine lange 7-teilige Serie zur Verbesserung der Herausforderungen der Benutzeroberfläche mit React,
- Wie man die Leistung von React misst und wie man React-Anwendungen profiliert.
- Erstellen von Mobile-First-Webanimationen in React, ein fantastischer Vortrag von Alex Holachek, zusammen mit Folien und GitHub-Repo ( danke für den Tipp, Addy! ).
- webpack-libs-optimizations ist ein fantastisches GitHub-Repo mit vielen nützlichen Webpack-spezifischen leistungsbezogenen Optimierungen. Verwaltet von Ivan Akulov.
- Reagieren Sie Leistungsverbesserungen in Notion, eine Anleitung von Ivan Akulov zur Verbesserung der Leistung in React, mit vielen nützlichen Hinweisen, um die App um etwa 30 % schneller zu machen.
- React Refresh Webpack Plugin (experimentell) ermöglicht Hot Reloading, das den Komponentenstatus beibehält, und unterstützt Hooks und Funktionskomponenten.
- Achten Sie auf React Server-Komponenten in Null-Bundle-Größe, eine neue vorgeschlagene Art von Komponenten, die keinen Einfluss auf die Bundle-Größe haben. Das Projekt befindet sich derzeit in der Entwicklung, aber jedes Feedback aus der Community wird sehr geschätzt (großartige Erklärung von Sophie Alpert).
- Verwenden Sie Predictive Prefetching für JavaScript-Blöcke?
Wir könnten Heuristiken verwenden, um zu entscheiden, wann JavaScript-Chunks vorab geladen werden sollen. Guess.js ist eine Reihe von Tools und Bibliotheken, die Google Analytics-Daten verwenden, um zu bestimmen, welche Seite ein Benutzer von einer bestimmten Seite am ehesten als nächstes besuchen wird. Basierend auf Benutzernavigationsmustern, die von Google Analytics oder anderen Quellen gesammelt wurden, erstellt Guess.js ein maschinelles Lernmodell, um JavaScript vorherzusagen und vorab abzurufen, das auf jeder nachfolgenden Seite erforderlich sein wird.Daher erhält jedes interaktive Element eine Wahrscheinlichkeitsbewertung für das Engagement, und basierend auf dieser Bewertung entscheidet ein clientseitiges Skript, eine Ressource im Voraus abzurufen. Sie können die Technik in Ihre Next.js-Anwendung, Angular und React integrieren, und es gibt ein Webpack-Plugin, das den Einrichtungsprozess ebenfalls automatisiert.
Offensichtlich veranlassen Sie den Browser möglicherweise dazu, unnötige Daten zu verbrauchen und unerwünschte Seiten vorab abzurufen. Daher ist es eine gute Idee, bei der Anzahl der vorab abgerufenen Anforderungen recht konservativ zu sein. Ein guter Anwendungsfall wäre das Vorabrufen von Validierungsskripten, die beim Checkout erforderlich sind, oder das spekulative Vorabrufen, wenn ein kritischer Call-to-Action in den Darstellungsbereich gelangt.
Brauchen Sie etwas weniger Anspruchsvolles? DNStradamus führt ein DNS-Prefetching für ausgehende Links durch, wie sie im Ansichtsfenster erscheinen. Quicklink, InstantClick und Instant.page sind kleine Bibliotheken, die während der Leerlaufzeit automatisch Links im Ansichtsfenster vorab abrufen, um zu versuchen, die Navigation auf der nächsten Seite schneller zu laden. Quicklink ermöglicht das Vorabrufen von React Router-Routen und Javascript; Außerdem ist es datenschonend, sodass es bei 2G oder bei
Data-Savernicht vorab abgerufen wird. Gleiches gilt für Instant.page, wenn der Modus so eingestellt ist, dass Viewport Prefetching verwendet wird (was eine Standardeinstellung ist).Wenn Sie sich ausführlich mit der Wissenschaft des Predictive Prefetching befassen möchten, hält Divya Tagtachian einen großartigen Vortrag über The Art of Predictive Prefetch, der alle Optionen von Anfang bis Ende abdeckt.
- Profitieren Sie von Optimierungen für Ihre Ziel-JavaScript-Engine.
Untersuchen Sie, welche JavaScript-Engines in Ihrer Benutzerbasis dominieren, und erkunden Sie dann Möglichkeiten zur Optimierung für sie. Verwenden Sie beispielsweise bei der Optimierung für V8, das in Blink-Browsern, Node.js-Laufzeitumgebung und Electron verwendet wird, Skript-Streaming für monolithische Skripte.Skript-Streaming ermöglicht das Parsen von
asyncoderdefer scriptsin einem separaten Hintergrund-Thread, sobald der Download beginnt, wodurch in einigen Fällen die Seitenladezeiten um bis zu 10 % verbessert werden. Verwenden Sie praktischerweise<script defer>im<head>, damit die Browser die Ressource frühzeitig entdecken und sie dann im Hintergrund-Thread parsen können.Vorbehalt : Opera Mini unterstützt keine Skriptverzögerung, wenn Sie also für Indien oder Afrika entwickeln, wird die
deferignoriert, was dazu führt, dass das Rendern blockiert wird, bis das Skript ausgewertet wurde (danke Jeremy!) .Sie können sich auch in das Code-Caching von V8 einklinken, indem Sie Bibliotheken von Code trennen, der sie verwendet, oder umgekehrt, Bibliotheken und ihre Verwendung in einem einzigen Skript zusammenführen, kleine Dateien zusammenfassen und Inline-Skripte vermeiden. Oder vielleicht sogar v8-compile-cache verwenden.
Wenn es um JavaScript im Allgemeinen geht, gibt es auch einige Praktiken, die es wert sind, beachtet zu werden:
- Clean Code-Konzepte für JavaScript, eine große Sammlung von Mustern zum Schreiben von lesbarem, wiederverwendbarem und umgestaltbarem Code.
- Sie können Daten aus JavaScript mit der CompressionStream-API komprimieren, z. B. zu gzip, bevor Sie Daten hochladen (Chrome 80+).
- Detached Window Memory Leaks und Fixing Memory Leaks in Web Apps sind detaillierte Anleitungen zum Auffinden und Beheben kniffliger JavaScript-Speicherlecks. Außerdem können Sie queryObjects(SomeConstructor) aus der DevTools-Konsole verwenden ( Danke, Mathias! ).
- Reexporte sind schlecht für die Lade- und Laufzeitleistung, und ihre Vermeidung kann dazu beitragen, die Paketgröße erheblich zu reduzieren.
- Wir können die Bildlaufleistung mit passiven Ereignis-Listenern verbessern, indem wir ein Flag im
optionssetzen. So können Browser die Seite sofort scrollen, anstatt nachdem der Listener fertig ist. (über Kayce Basques). - Wenn Sie
scrollodertouch*-Listener haben, übergeben Siepassive: truean addEventListener. Dies teilt dem Browser mit, dass Sie nicht vorhaben,event.preventDefault()intern aufzurufen, sodass er die Art und Weise optimieren kann, wie er diese Ereignisse verarbeitet. (über Ivan Akulov) - Wir können eine bessere JavaScript-Planung mit isInputPending() erreichen, einer neuen API, die versucht, die Lücke zwischen Laden und Reaktionsfähigkeit mit den Konzepten von Interrupts für Benutzereingaben im Web zu schließen, und es JavaScript ermöglicht, auf Eingaben zu prüfen, ohne nachzugeben der Browser.
- Sie können einen Ereignis-Listener auch automatisch entfernen, nachdem er ausgeführt wurde.
- Firefox's kürzlich veröffentlichtes Warp, ein bedeutendes Update für SpiderMonkey (geliefert in Firefox 83), Baseline Interpreter und es sind auch einige JIT-Optimierungsstrategien verfügbar.
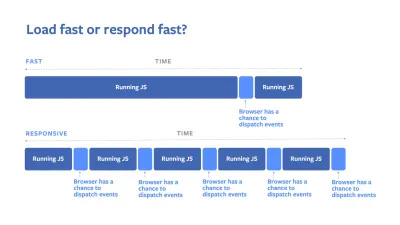
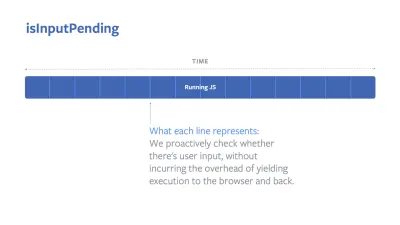
- Ziehen Sie es immer vor, Assets von Drittanbietern selbst zu hosten.
Auch hier hosten Sie Ihre statischen Assets standardmäßig selbst. Es ist üblich anzunehmen, dass, wenn viele Websites dasselbe öffentliche CDN und dieselbe Version einer JavaScript-Bibliothek oder einer Webschriftart verwenden, die Besucher auf unserer Website mit den bereits in ihrem Browser zwischengespeicherten Skripten und Schriftarten landen würden, was ihre Erfahrung erheblich beschleunigt . Es ist jedoch sehr unwahrscheinlich, dass dies geschieht.Aus Sicherheitsgründen haben Browser zur Vermeidung von Fingerabdrücken partitioniertes Caching implementiert, das bereits 2013 in Safari und letztes Jahr in Chrome eingeführt wurde. Wenn also zwei Sites auf die exakt gleiche Ressourcen-URL eines Drittanbieters verweisen, wird der Code einmal pro Domain heruntergeladen und der Cache wird aus Datenschutzgründen auf diese Domain "sandboxed" ( danke, David Calhoun! ). Daher führt die Verwendung eines öffentlichen CDN nicht automatisch zu einer besseren Leistung.
Darüber hinaus ist es erwähnenswert, dass Ressourcen nicht so lange im Cache des Browsers verbleiben, wie wir vielleicht erwarten, und Assets von Erstanbietern eher im Cache verbleiben als Assets von Drittanbietern. Daher ist Self-Hosting in der Regel zuverlässiger und sicherer und auch leistungsstärker.
- Beschränken Sie die Auswirkungen von Skripten von Drittanbietern.
Bei allen Leistungsoptimierungen können wir Skripte von Drittanbietern, die aus Geschäftsanforderungen stammen, oft nicht kontrollieren. Die Metriken von Drittanbieter-Skripten werden nicht von der Endbenutzererfahrung beeinflusst, sodass ein einzelnes Skript allzu oft dazu führt, dass ein langer Schwanz von unausstehlichen Drittanbieter-Skripten aufgerufen wird, wodurch eine dedizierte Leistungsbemühung ruiniert wird. Um die Leistungsnachteile, die diese Skripte mit sich bringen, einzudämmen und abzumildern, reicht es nicht aus, ihr Laden und Ausführen zu verzögern und Verbindungen über Ressourcenhinweise, dhdns-prefetchoderpreconnect, aufzuwärmen.Derzeit werden 57 % der gesamten Ausführungszeit von JavaScript-Code für Code von Drittanbietern aufgewendet. Der Median der mobilen Website greift auf 12 Domains von Drittanbietern zu , mit einem Median von 37 verschiedenen Anfragen (oder ungefähr 3 Anfragen an jeden Drittanbieter).
Darüber hinaus laden diese Drittanbieter oft Skripte von Viertanbietern zum Mitmachen ein, was zu einem enormen Leistungsengpass führt, der manchmal bis zu den Skripten von Achtanbietern auf einer Seite reicht. Die regelmäßige Prüfung Ihrer Abhängigkeiten und Tag-Manager kann also kostspielige Überraschungen mit sich bringen.
Ein weiteres Problem, wie Yoav Weiss in seinem Vortrag über Skripte von Drittanbietern erläuterte, besteht darin, dass diese Skripte in vielen Fällen dynamische Ressourcen herunterladen. Die Ressourcen ändern sich zwischen Seitenladevorgängen, sodass wir nicht unbedingt wissen, von welchen Hosts die Ressourcen heruntergeladen werden und um welche Ressourcen es sich handelt.
Das Verschieben, wie oben gezeigt, könnte jedoch nur ein Anfang sein, da Skripte von Drittanbietern auch Bandbreite und CPU-Zeit von Ihrer App stehlen. Wir könnten etwas aggressiver vorgehen und sie erst laden, wenn unsere App initialisiert wurde.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In einem fantastischen Beitrag zum Thema „Reducing the Site-Speed Impact of Third-Party Tags“ untersucht Andy Davies eine Strategie zur Minimierung des Fußabdrucks von Drittanbietern – von der Ermittlung ihrer Kosten bis hin zur Reduzierung ihrer Auswirkungen.
Laut Andy gibt es zwei Möglichkeiten, wie Tags die Website-Geschwindigkeit beeinflussen – sie konkurrieren um Netzwerkbandbreite und Verarbeitungszeit auf den Geräten der Besucher, und je nachdem, wie sie implementiert sind, können sie auch das HTML-Parsing verzögern. Der erste Schritt besteht also darin, die Auswirkungen von Drittanbietern zu identifizieren, indem die Website mit und ohne Skripts mit WebPageTest getestet wird. Mit der Request Map von Simon Hearne können wir auch Drittanbieter auf einer Seite visualisieren, zusammen mit Details zu ihrer Größe, ihrem Typ und dem, was ihre Last ausgelöst hat.
Hosten Sie vorzugsweise selbst und verwenden Sie einen einzelnen Hostnamen, aber verwenden Sie auch eine Anforderungszuordnung, um Aufrufe von Viertanbietern offenzulegen und zu erkennen, wenn sich die Skripts ändern. Sie können den Ansatz von Harry Roberts für die Prüfung Dritter verwenden und Tabellenkalkulationen wie diese erstellen (überprüfen Sie auch Harrys Prüfungsablauf).
Anschließend können wir leichtgewichtige Alternativen zu bestehenden Skripten untersuchen und Duplikate und Hauptschuldige langsam durch leichtere Optionen ersetzen. Vielleicht könnten einige der Skripte durch ihr Fallback-Tracking-Pixel anstelle des vollständigen Tags ersetzt werden.

Laden von YouTube mit Fassaden, z. B. lite-youtube-embed, das deutlich kleiner ist als ein echter YouTube-Player. (Bildquelle) (Große Vorschau) Wenn es nicht realisierbar ist, können wir Ressourcen von Drittanbietern zumindest mit Fassaden faul laden, dh ein statisches Element, das ähnlich aussieht wie das tatsächlich eingebettete Drittanbieter-Element, aber nicht funktionsfähig ist und daher das Laden der Seite viel weniger belastet. Der Trick besteht also darin , die eigentliche Einbettung nur bei Interaktion zu laden .
Zum Beispiel können wir verwenden:
- lite-vimeo-embed für den Vimeo-Player,
- lite-vimeo für den Vimeo-Player,
- lite-youtube-embed für den YouTube-Player,
- React-Live-Chat-Loader für einen Live-Chat (Fallstudie und eine weitere Fallstudie),
- lazyframe für iframes.
Einer der Gründe, warum Tag-Manager normalerweise groß sind, liegt in den vielen gleichzeitig laufenden Experimenten, zusammen mit vielen Benutzersegmenten, Seiten-URLs, Websites usw., so dass laut Andy eine Reduzierung beides reduzieren kann die Downloadgröße und die Zeit, die benötigt wird, um das Skript im Browser auszuführen.
Und dann gibt es Anti-Flicker-Schnipsel. Drittanbieter wie Google Optimize, Visual Web Optimizer (VWO) und andere sind sich einig, sie zu verwenden. Diese Snippets werden normalerweise zusammen mit laufenden A/B-Tests eingefügt : Um ein Flackern zwischen den verschiedenen Testszenarien zu vermeiden, verbergen sie den
bodydes Dokuments mitopacity: 0und fügen dann eine Funktion hinzu, die nach einigen Sekunden aufgerufen wird, um dieopacitywiederherzustellen . Dies führt häufig zu massiven Verzögerungen beim Rendern aufgrund massiver clientseitiger Ausführungskosten.
Bei Verwendung von A/B-Tests sehen Kunden häufig ein Flackern wie dieses. Anti-Flicker-Snippets verhindern das, kosten aber auch Performance. Über Andy Davies. (Große Vorschau) Behalten Sie daher im Auge, wie oft das Anti-Flacker-Timeout ausgelöst wird, und reduzieren Sie das Timeout. Die Standardeinstellung blockiert die Anzeige Ihrer Seite um bis zu 4 Sekunden, was die Konversionsraten ruiniert. Laut Tim Kadlec „lassen Freunde nicht zu, dass Freunde clientseitige A/B-Tests durchführen“. Serverseitige A/B-Tests auf CDNs (z. B. Edge Computing oder Edge Slice Rerendering) sind immer eine performantere Option.
Wenn Sie mit dem allmächtigen Google Tag Manager zu tun haben, gibt Barry Pollard einige Richtlinien, um die Auswirkungen des Google Tag Manager einzudämmen. Außerdem untersucht Christian Schaefer Strategien zum Laden von Anzeigen.
Achtung: Einige Widgets von Drittanbietern verstecken sich vor Überwachungstools, sodass sie möglicherweise schwieriger zu erkennen und zu messen sind. Um Drittanbieter einem Stresstest zu unterziehen, untersuchen Sie Bottom-Up-Zusammenfassungen auf der Seite Leistungsprofil in DevTools, testen Sie, was passiert, wenn eine Anforderung blockiert wird oder das Zeitlimit überschritten wurde – für letzteres können Sie den Blackhole-Server
blackhole.webpagetest.orgvon WebPageTest verwenden, den Sie verwenden kann auf bestimmte Domains in Ihrerhosts-Datei verweisen.Welche Möglichkeiten haben wir dann? Erwägen Sie die Verwendung von Servicemitarbeitern, indem Sie den Download der Ressource mit einem Timeout beschleunigen , und wenn die Ressource nicht innerhalb eines bestimmten Timeouts geantwortet hat, geben Sie eine leere Antwort zurück, um den Browser anzuweisen, mit der Analyse der Seite fortzufahren. Sie können auch Anfragen von Drittanbietern protokollieren oder blockieren, die nicht erfolgreich sind oder bestimmte Kriterien nicht erfüllen. Wenn Sie können, laden Sie das Skript des Drittanbieters von Ihrem eigenen Server und nicht vom Server des Anbieters und laden Sie es faul.
Eine weitere Möglichkeit besteht darin, eine Content Security Policy (CSP) einzurichten , um die Auswirkungen von Skripten von Drittanbietern einzuschränken, z. B. das Verbieten des Downloads von Audio oder Video. Die beste Möglichkeit besteht darin, Skripte über
<iframe>einzubetten, sodass die Skripte im Kontext des iframe ausgeführt werden und daher keinen Zugriff auf das DOM der Seite haben und keinen beliebigen Code auf Ihrer Domain ausführen können. Iframes können mit demsandbox-Attribut weiter eingeschränkt werden, sodass Sie alle Funktionen deaktivieren können, die iframe möglicherweise ausführt, z. B. das Ausführen von Skripts, das Verhindern von Warnungen, das Senden von Formularen, Plugins, den Zugriff auf die obere Navigation usw. verhindern.Sie können Drittanbieter auch über In-Browser-Performance-Linting mit Funktionsrichtlinien in Schach halten, eine relativ neue Funktion, mit der Sie
Opt-in oder Deaktivierung bestimmter Browserfunktionen auf Ihrer Website. (Als Nebenbemerkung könnte es auch verwendet werden, um übergroße und nicht optimierte Bilder, undimensionierte Medien, Synchronisierungsskripte und andere zu vermeiden). Derzeit in Blink-basierten Browsern unterstützt. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Da viele Skripte von Drittanbietern in iFrames ausgeführt werden, müssen Sie wahrscheinlich ihre Berechtigungen gründlich einschränken. Sandbox-iFrames sind immer eine gute Idee, und jede der Einschränkungen kann über eine Reihe von
allow-Werten für dassandboxAttribut aufgehoben werden. Sandboxing wird fast überall unterstützt, also beschränken Sie Skripte von Drittanbietern auf das absolute Minimum dessen, was sie tun dürfen.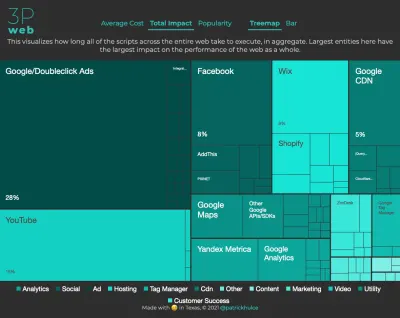
ThirdPartyWeb.Today gruppiert alle Skripte von Drittanbietern nach Kategorie (Analyse, Soziales, Werbung, Hosting, Tag-Manager usw.) und visualisiert, wie lange die Ausführung der Skripte der Entität (im Durchschnitt) dauert. (Große Vorschau) Erwägen Sie die Verwendung eines Kreuzungsbeobachters; Dies würde es ermöglichen, dass Anzeigen mit Iframes versehen werden, während sie weiterhin Ereignisse senden oder die Informationen erhalten, die sie vom DOM benötigen (z. B. Anzeigensichtbarkeit). Achten Sie auf neue Richtlinien wie Funktionsrichtlinien, Ressourcengrößenbeschränkungen und CPU-/Bandbreitenpriorität, um schädliche Webfunktionen und Skripte einzuschränken, die den Browser verlangsamen würden, z. B. synchrone Skripte, synchrone XHR-Anforderungen, document.write und veraltete Implementierungen.
Wenn Sie sich für einen Drittanbieterdienst entscheiden, sollten Sie sich schließlich Patrick Hulces ThirdPartyWeb.Today ansehen, einen Dienst, der alle Skripte von Drittanbietern nach Kategorien gruppiert (Analytik, Soziales, Werbung, Hosting, Tag-Manager usw.) und visualisiert, wie lange die Skripte der Entität sind ausführen (im Durchschnitt). Offensichtlich haben die größten Entitäten die schlimmsten Auswirkungen auf die Leistung der Seiten, auf denen sie sich befinden. Durch einfaches Überfliegen der Seite erhalten Sie eine Vorstellung von der Leistungsbilanz, die Sie erwarten sollten.
Ah, und vergessen Sie nicht die üblichen Verdächtigen: Anstelle von Drittanbieter-Widgets zum Teilen können wir statische Social-Sharing-Buttons (z. B. von SSBG) und statische Links zu interaktiven Karten anstelle von interaktiven Karten verwenden.
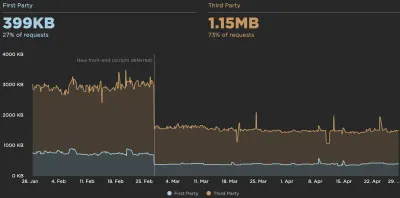
- Legen Sie die HTTP-Cache-Header richtig fest.
Caching scheint eine so offensichtliche Sache zu sein, aber es könnte ziemlich schwierig sein, es richtig zu machen. Wir müssen noch einmal überprüfen, obexpires,max-age,cache-controlund andere HTTP-Cache-Header richtig eingestellt wurden. Ohne geeignete HTTP-Cache-Header setzen Browser sie automatisch auf 10 % der verstrichenen Zeit seit derlast-modified, was zu einem potenziellen Unter- und Über-Caching führt.Im Allgemeinen sollten Ressourcen entweder für eine sehr kurze Zeit (wenn sie sich wahrscheinlich ändern) oder auf unbestimmte Zeit (wenn sie statisch sind) zwischengespeichert werden können – Sie können bei Bedarf einfach ihre Version in der URL ändern. Sie können es eine Cache-Forever-Strategie nennen, bei der wir
Cache-ControlundExpires-Header an den Browser weiterleiten könnten, damit Assets nur in einem Jahr ablaufen. Daher würde der Browser nicht einmal eine Anfrage für das Asset stellen, wenn er es im Cache hat.Ausnahme sind API-Antworten (z. B.
/api/user). Um das Caching zu verhindern, können wirprivate, no storeund nichtmax-age=0, no-storeverwenden:Cache-Control: private, no-storeVerwenden Sie
Cache-control: immutable, um eine erneute Validierung langer expliziter Cache-Lebensdauern zu vermeiden, wenn Benutzer auf die Schaltfläche „Neu laden“ klicken. Für den Reload-Fall speichertimmutableHTTP-Requests und verbessert die Ladezeit des dynamischen HTML, da sie nicht mehr mit der Vielzahl von 304-Antworten konkurrieren.Ein typisches Beispiel, bei dem wir
immutableverwenden möchten, sind CSS/JavaScript-Assets mit einem Hash in ihrem Namen. Für sie möchten wir wahrscheinlich so lange wie möglich zwischenspeichern und sicherstellen, dass sie nie erneut validiert werden:Cache-Control: max-age: 31556952, immutableLaut den Untersuchungen von Colin
immutablereduziert Immutable 304max-ageimmer noch erneut validieren und bei der Aktualisierung blockieren. Es wird in Firefox, Edge und Safari unterstützt und Chrome diskutiert das Problem noch.Laut Web Almanac „ist seine Nutzung auf 3,5 % gestiegen und wird häufig in den Antworten von Drittanbietern von Facebook und Google verwendet.“

Cache-Control: Immutable reduziert 304s um etwa 50 %, laut Colin Bendells Forschung bei Cloudinary. (Große Vorschau) Erinnerst du dich an das gute alte „stale-while-revalidate“? Wenn wir die Caching-Zeit mit dem
Cache-Control-Antwortheader angeben (z. B.Cache-Control: max-age=604800), ruft der Browser nach Ablauf vonmax-ageden angeforderten Inhalt erneut ab, wodurch die Seite langsamer geladen wird. Diese Verlangsamung kann mitstale-while-revalidatevermieden werden; Es definiert im Grunde ein zusätzliches Zeitfenster, in dem ein Cache ein veraltetes Asset verwenden kann, solange es asynchron im Hintergrund erneut validiert wird. Somit „verbirgt“ es die Latenz (sowohl im Netzwerk als auch auf dem Server) vor Clients.Von Juni bis Juli 2019 haben Chrome und Firefox die Unterstützung von „
stale-while-revalidate“ im HTTP-Cache-Control-Header eingeführt, sodass die nachfolgenden Seitenladelatenzen verbessert werden sollten, da sich veraltete Assets nicht mehr im kritischen Pfad befinden. Ergebnis: Null RTT für wiederholte Aufrufe.Seien Sie vorsichtig mit dem Vary-Header, insbesondere in Bezug auf CDNs, und achten Sie auf die HTTP-Darstellungsvarianten, die dazu beitragen, einen zusätzlichen Roundtrip zur Validierung zu vermeiden, wenn sich eine neue Anfrage leicht (aber nicht wesentlich) von früheren Anfragen unterscheidet ( Danke, Guy und Mark ! ).
Stellen Sie außerdem sicher, dass Sie keine unnötigen Header senden (z. B.
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectionund andere) und dass Sie nützliche Sicherheits- und Leistungsheader (wie z wieContent-Security-Policy,X-Content-Type-Optionsund andere). Denken Sie schließlich an die Leistungskosten von CORS-Anforderungen in Single-Page-Anwendungen.Hinweis : Wir gehen oft davon aus, dass zwischengespeicherte Assets sofort abgerufen werden, aber Untersuchungen zeigen, dass das Abrufen eines Objekts aus dem Cache Hunderte von Millisekunden dauern kann. Laut Simon Hearne „ist das Netzwerk manchmal möglicherweise schneller als der Cache, und das Abrufen von Assets aus dem Cache kann bei einer großen Anzahl von zwischengespeicherten Assets (nicht der Dateigröße) und den Geräten des Benutzers kostspielig sein. Beispiel: Chrome OS durchschnittlicher Cache-Abruf verdoppelt sich von ~50ms mit 5 zwischengespeicherten Ressourcen bis zu ~100ms mit 25 Ressourcen".
Außerdem gehen wir oft davon aus, dass die Paketgröße kein großes Problem darstellt und die Benutzer es einmal herunterladen und dann die zwischengespeicherte Version verwenden. Gleichzeitig pushen wir mit CI/CD Code mehrmals am Tag in die Produktion, der Cache wird jedes Mal ungültig, also gehen wir beim Caching strategisch vor.
Wenn es um Caching geht, gibt es viele Ressourcen, die es wert sind, gelesen zu werden:
- Cache-Control for Civilians, ein tiefer Einblick in alles, was mit Harry Roberts gecached wird.
- Herokus Einführung in HTTP-Caching-Header,
- Caching Best Practices von Jake Archibald,
- HTTP-Caching-Primer von Ilya Grigorik,
- Halten Sie die Dinge frisch mit stale-while-revalidate von Jeff Posnick.
- CS Visualized: CORS von Lydia Hallie ist eine großartige Erklärung für CORS, wie es funktioniert und wie man es versteht.
- Apropos CORS, hier ist eine kleine Auffrischung zur Same-Origin-Policy von Eric Portis.
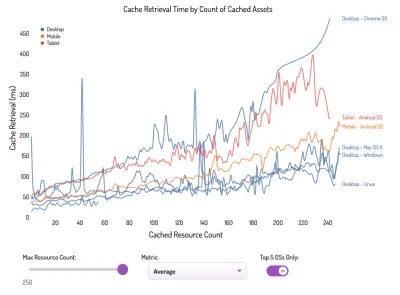
Lieferoptimierungen
- Verwenden wir
defer, um kritisches JavaScript asynchron zu laden?
Wenn der Benutzer eine Seite anfordert, ruft der Browser den HTML-Code ab und erstellt das DOM, ruft dann das CSS ab und erstellt das CSSOM und generiert dann einen Rendering-Baum, indem er das DOM und das CSSOM abgleicht. Wenn irgendein JavaScript aufgelöst werden muss, beginnt der Browser nicht mit dem Rendern der Seite , bis es aufgelöst ist, wodurch das Rendern verzögert wird. Als Entwickler müssen wir dem Browser explizit mitteilen, dass er nicht warten und mit dem Rendern der Seite beginnen soll. Bei Skripten erreichen Sie dies mit den Attributendeferundasyncin HTML.In der Praxis stellt sich heraus, dass es besser ist,
deferstattasynczu verwenden. Ah, wo ist nochmal der Unterschied ? Laut Steveasyncwerden asynchrone Skripte sofort ausgeführt, sobald sie ankommen – sobald das Skript fertig ist. Wenn das sehr schnell passiert, zum Beispiel wenn sich das Skript bereits im Cache befindet, kann es tatsächlich den HTML-Parser blockieren. Mitdeferführt der Browser keine Skripts aus, bis HTML analysiert wurde. Daher ist es besser,deferzu verwenden, es sei denn, Sie müssen JavaScript ausführen, bevor Sie mit dem Rendern beginnen. Außerdem werden mehrere asynchrone Dateien in einer nicht deterministischen Reihenfolge ausgeführt.Es ist erwähnenswert, dass es einige Missverständnisse über
asyncunddefergibt. Am wichtigsten ist, dassasyncnicht bedeutet, dass der Code ausgeführt wird, wenn das Skript bereit ist; es bedeutet, dass es immer dann ausgeführt wird, wenn das Skript bereit ist und alle vorherigen Synchronisierungsarbeiten abgeschlossen sind. Mit den Worten von Harry Roberts: „Wenn Sie einasyncSkript nach Synchronisierungsskripts einfügen, ist IhrasyncSkript nur so schnell wie Ihr langsamstes Synchronisierungsskript.“Außerdem wird nicht empfohlen, sowohl
asyncals auchdeferzu verwenden. Moderne Browser unterstützen beides, aber wann immer beide Attribute verwendet werden, gewinntasyncimmer.Wenn Sie mehr ins Detail gehen möchten, hat Milica Mihajlija einen sehr detaillierten Leitfaden zum schnelleren Erstellen des DOM geschrieben, der auf die Details von spekulativem Parsing, Async und Defer eingeht.
- Lazy load teure Komponenten mit IntersectionObserver und Prioritätshinweisen.
Im Allgemeinen wird empfohlen, alle teuren Komponenten wie schweres JavaScript, Videos, iFrames, Widgets und möglicherweise Bilder träge zu laden. Natives Lazy-Loading ist bereits für Bilder und Iframes mit demloadingAttribut verfügbar (nur Chromium). Unter der Haube verschiebt dieses Attribut das Laden der Ressource, bis sie eine berechnete Entfernung vom Darstellungsbereich erreicht.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Dieser Schwellenwert hängt von einigen Dingen ab, von der Art der abgerufenen Bildressource bis zum effektiven Verbindungstyp. Experimente, die mit Chrome auf Android durchgeführt wurden, deuten jedoch darauf hin, dass auf 4G 97,5 % der Bilder, die unter der Falte liegen und Lazy-Loaded sind, innerhalb von 10 ms, nachdem sie sichtbar wurden, vollständig geladen wurden, also sollte es sicher sein.
Wir können auch das
importance(highoderlow) für ein<script>-,<img>- oder<link>-Element (nur Blink) verwenden. Tatsächlich ist es eine großartige Möglichkeit, Bilder in Karussells zu depriorisieren und Skripts neu zu priorisieren. Manchmal benötigen wir jedoch möglicherweise eine etwas detailliertere Steuerung.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Die leistungsstärkste Methode für etwas ausgefeilteres verzögertes Laden ist die Verwendung der Intersection Observer-API, die eine Möglichkeit bietet , Änderungen an der Überschneidung eines Zielelements mit einem übergeordneten Element oder mit dem Ansichtsfenster eines Dokuments der obersten Ebene asynchron zu beobachten . Grundsätzlich müssen Sie ein neues
IntersectionObserver-Objekt erstellen, das eine Callback-Funktion und eine Reihe von Optionen erhält. Dann fügen wir ein zu beobachtendes Ziel hinzu.Die Callback-Funktion wird ausgeführt, wenn das Ziel sichtbar oder unsichtbar wird. Wenn sie also den Ansichtsbereich abfängt, können Sie einige Aktionen ausführen, bevor das Element sichtbar wird. Tatsächlich haben wir eine granulare Kontrolle darüber, wann der Rückruf des Beobachters aufgerufen werden soll, mit
rootMargin(Rand um die Wurzel) undthreshold(eine einzelne Zahl oder ein Array von Zahlen, die angeben, auf welchen Prozentsatz der Sichtbarkeit des Ziels wir abzielen).Alejandro Garcia Anglada hat ein praktisches Tutorial veröffentlicht, wie man es tatsächlich implementiert, Rahul Nanwani schrieb einen ausführlichen Beitrag über das verzögerte Laden von Vorder- und Hintergrundbildern, und Google Fundamentals bietet ebenfalls ein detailliertes Tutorial über das verzögerte Laden von Bildern und Videos mit Intersection Observer.
Erinnern Sie sich an kunstgesteuertes Geschichtenerzählen mit langen Lesevorgängen mit sich bewegenden und klebrigen Objekten? Auch mit Intersection Observer lässt sich performantes Scrollytelling realisieren.
Überprüfen Sie noch einmal, was Sie sonst noch faul laden könnten. Sogar Lazy-Loading-Übersetzungsstrings und Emojis könnten helfen. Auf diese Weise gelang es Mobile Twitter, eine 80 % schnellere JavaScript-Ausführung aus der neuen Internationalisierungspipeline zu erreichen.
Ein kurzes Wort der Vorsicht: Es ist erwähnenswert, dass Lazy Loading eher eine Ausnahme als die Regel sein sollte. Es ist wahrscheinlich nicht sinnvoll, irgendetwas träge zu laden, was die Leute tatsächlich schnell sehen sollen, z. B. Produktseitenbilder, Heldenbilder oder ein Skript, das erforderlich ist, damit die Hauptnavigation interaktiv wird.

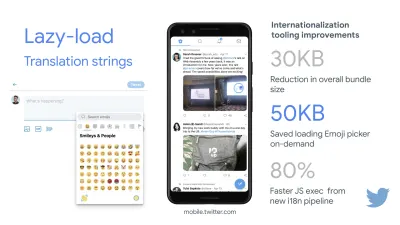
- Bilder nach und nach laden.
Sie könnten sogar Lazy Loading auf die nächste Stufe heben, indem Sie Ihren Seiten progressives Laden von Bildern hinzufügen. Ähnlich wie bei Facebook, Pinterest, Medium und Wolt könnten Sie zuerst Bilder mit niedriger Qualität oder sogar verschwommen laden und sie dann, während die Seite weiter geladen wird, durch die Versionen in voller Qualität ersetzen, indem Sie die BlurHash-Technik oder LQIP (Low Quality Image Placeholders) verwenden. Technik.Die Meinungen gehen auseinander, ob diese Techniken die Benutzererfahrung verbessern oder nicht, aber es verbessert definitiv die Zeit bis zum First Contentful Paint. Wir können es sogar automatisieren, indem wir SQIP verwenden, das eine Version eines Bildes mit niedriger Qualität als SVG-Platzhalter oder Gradient Image Placeholders mit linearen CSS-Verläufen erstellt.
Diese Platzhalter könnten in HTML eingebettet werden, da sie sich natürlich gut mit Textkomprimierungsmethoden komprimieren lassen. Dean Hume hat in seinem Artikel beschrieben, wie diese Technik mit Intersection Observer implementiert werden kann.
Zurückfallen? Wenn der Browser den Schnittmengenbeobachter nicht unterstützt, können wir immer noch ein Polyfill laden oder die Bilder sofort laden. Und es gibt sogar eine Bibliothek dafür.
Willst du schicker werden? Sie könnten Ihre Bilder nachzeichnen und primitive Formen und Kanten verwenden, um einen einfachen SVG-Platzhalter zu erstellen, ihn zuerst zu laden und dann vom Platzhalter-Vektorbild zum (geladenen) Bitmap-Bild überzugehen.
- Verzögern Sie das Rendern mit
content-visibility?
Bei einem komplexen Layout mit vielen Inhaltsblöcken, Bildern und Videos kann das Decodieren von Daten und das Rendern von Pixeln ein ziemlich teurer Vorgang sein – insbesondere auf Low-End-Geräten. Mitcontent-visibility: autokönnen wir den Browser auffordern, das Layout der untergeordneten Elemente zu überspringen, während sich der Container außerhalb des Ansichtsfensters befindet.Beispielsweise könnten Sie das Rendern der Fußzeile und der späten Abschnitte beim anfänglichen Laden überspringen:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Beachten Sie, dass content-visibility: auto; verhält sich wie overflow: hidden; , aber Sie können es beheben, indem Sie
padding-leftundpadding-rightanstelle des standardmäßigenmargin-left: auto;,margin-right: auto;und eine deklarierte Breite. Das Padding ermöglicht grundsätzlich, dass Elemente die Content-Box überlaufen und in die Padding-Box eintreten, ohne das Box-Modell als Ganzes zu verlassen und abgeschnitten zu werden.Denken Sie auch daran, dass Sie einige CLS einführen könnten, wenn neuer Inhalt schließlich gerendert wird, daher ist es eine gute Idee, "
contain-intrinsic-size" mit einem Platzhalter in der richtigen Größe zu verwenden ( danke, Una! ).Thijs Terluin hat viel mehr Details über beide Eigenschaften und wie
contain-intrinsic-sizeEigengröße vom Browser berechnet wird, Malte Ubl zeigt, wie Sie sie berechnen können, und ein kurzes Erklärvideo von Jake und Surma erklärt, wie das alles funktioniert.Und wenn Sie etwas detaillierter werden müssen, können Sie mit CSS Containment Layout-, Stil- und Malarbeiten für Nachkommen eines DOM-Knotens manuell überspringen, wenn Sie nur Größe, Ausrichtung oder berechnete Stile für andere Elemente benötigen – oder das Element gerade ist außerhalb der Leinwand.


content-visibility: auto auf aufgeteilte Inhaltsbereiche zu einer 7-fachen Steigerung der Renderleistung beim anfänglichen Laden. (Große Vorschau)- Verzögern Sie die Dekodierung mit
decoding="async"?
Manchmal erscheinen Inhalte außerhalb des Bildschirms, aber wir möchten sicherstellen, dass sie verfügbar sind, wenn Kunden sie brauchen – idealerweise nichts im kritischen Pfad blockieren, sondern asynchron decodieren und rendern. Wir könnendecoding="async", um dem Browser die Erlaubnis zu erteilen, das Bild aus dem Haupt-Thread zu dekodieren, wodurch eine Auswirkung der CPU-Zeit auf den Benutzer vermieden wird, die zum Dekodieren des Bildes verwendet wird (über Malte Ubl):<img decoding="async" … />Alternativ können wir für Offscreen-Bilder zuerst einen Platzhalter anzeigen und, wenn sich das Bild im Ansichtsfenster befindet, mit IntersectionObserver einen Netzwerkaufruf auslösen, damit das Bild im Hintergrund heruntergeladen wird. Außerdem können wir das Rendern bis zum Decodieren mit img.decode() verschieben oder das Bild herunterladen, wenn die Image Decode API nicht verfügbar ist.
Beim Rendern des Bildes können wir beispielsweise Einblendanimationen verwenden. Katie Hempenius und Addy Osmani teilen weitere Einblicke in ihrem Vortrag Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Generieren und bedienen Sie kritisches CSS?
Um sicherzustellen, dass Browser so schnell wie möglich mit dem Rendern Ihrer Seite beginnen, ist es üblich geworden, alle CSS zu sammeln, die erforderlich sind, um mit dem Rendern des ersten sichtbaren Teils der Seite zu beginnen (bekannt als „Critical CSS“ oder „Above-the-Fold-CSS“. ") und fügen Sie es inline in den<head>der Seite ein, wodurch Roundtrips reduziert werden. Aufgrund der begrenzten Größe der ausgetauschten Pakete während der langsamen Startphase liegt Ihr Budget für kritisches CSS bei etwa 14 KB.Wenn Sie darüber hinausgehen, benötigt der Browser zusätzliche Roundtrips, um mehr Stile abzurufen. CriticalCSS und Critical ermöglichen es Ihnen, kritisches CSS für jede von Ihnen verwendete Vorlage auszugeben. Unserer Erfahrung nach war jedoch kein automatisches System besser als die manuelle Sammlung kritischer CSS für jede Vorlage, und tatsächlich ist dies der Ansatz, zu dem wir kürzlich zurückgekehrt sind.
Sie können dann kritisches CSS einbetten und den Rest mit dem critters Webpack-Plug-in lazy-loaden. Erwägen Sie nach Möglichkeit die Verwendung des von der Filament Group verwendeten bedingten Inlining-Ansatzes oder konvertieren Sie Inline-Code spontan in statische Assets.
Wenn Sie derzeit Ihr vollständiges CSS asynchron mit Bibliotheken wie loadCSS laden, ist dies nicht wirklich erforderlich. Mit
media="print"können Sie den Browser dazu verleiten, das CSS asynchron abzurufen, aber nach dem Laden auf die Bildschirmumgebung anzuwenden. ( Danke Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Beim Sammeln aller kritischen CSS für jede Vorlage ist es üblich, nur den „above-the-fold“-Bereich zu erkunden. Bei komplexen Layouts kann es jedoch eine gute Idee sein, auch die Grundlagen des Layouts einzubeziehen, um massive Kosten für Neuberechnungen und Neuzeichnungen zu vermeiden, die Ihrer Core Web Vitals-Punktzahl als Folge schaden würden.
Was ist, wenn ein Benutzer eine URL erhält, die direkt auf die Mitte der Seite verweist, aber das CSS noch nicht heruntergeladen wurde? Dabei ist es üblich geworden, unkritische Inhalte auszublenden, zB mit
opacity: 0;in eingebettetem CSS undopacity: 1in der vollständigen CSS-Datei und zeigt sie an, wenn CSS verfügbar ist. Es hat jedoch einen großen Nachteil , da Benutzer mit langsamen Verbindungen den Inhalt der Seite möglicherweise nie lesen können. Deshalb ist es besser, den Inhalt immer sichtbar zu halten, auch wenn er vielleicht nicht richtig gestylt ist.Kritisches CSS (und andere wichtige Assets) in einer separaten Datei auf der Root-Domain abzulegen, hat aufgrund des Cachings Vorteile, manchmal sogar mehr als Inlining. Chrome öffnet spekulativ eine zweite HTTP-Verbindung zur Stammdomäne, wenn die Seite angefordert wird, wodurch die Notwendigkeit einer TCP-Verbindung zum Abrufen dieses CSS entfällt. Das bedeutet, dass Sie eine Reihe kritischer -CSS-Dateien (z. B. kritische-homepage.css , kritische-produkt-seite.css usw.) erstellen und sie von Ihrem Stammverzeichnis aus bereitstellen könnten, ohne sie inline zu müssen. ( Danke Philipp! )
Ein Wort der Vorsicht: Mit HTTP/2 könnte kritisches CSS in einer separaten CSS-Datei gespeichert und über einen Server-Push bereitgestellt werden, ohne das HTML aufzublähen. Der Haken ist, dass das Server-Pushing mit vielen Fallstricken und Race-Conditions über Browser hinweg mühsam war. Es wurde nie durchgehend unterstützt und hatte einige Caching-Probleme (siehe Folie 114 ff. der Präsentation von Hooman Beheshti).
Der Effekt könnte in der Tat negativ sein und die Netzwerkpuffer aufblähen, wodurch verhindert wird, dass echte Frames im Dokument geliefert werden. Daher war es nicht verwunderlich, dass Chrome plant, die Unterstützung für Server Push vorerst zu entfernen.
- Experimentieren Sie mit der Neugruppierung Ihrer CSS-Regeln.
Wir haben uns an kritisches CSS gewöhnt, aber es gibt ein paar Optimierungen, die darüber hinausgehen könnten. Harry Roberts führte eine bemerkenswerte Forschung mit ziemlich überraschenden Ergebnissen durch. Beispielsweise könnte es eine gute Idee sein, die Haupt-CSS-Datei in ihre einzelnen Medienabfragen aufzuteilen. Auf diese Weise ruft der Browser kritisches CSS mit hoher Priorität und alles andere mit niedriger Priorität ab – vollständig abseits des kritischen Pfads.Vermeiden Sie es außerdem,
<link rel="stylesheet" />vorasyncSnippets zu platzieren. Wenn Skripts nicht von Stylesheets abhängen, sollten Sie Blockierungsskripts über Blockierungsstilen platzieren. Wenn dies der Fall ist, teilen Sie dieses JavaScript in zwei Teile und laden Sie es auf beiden Seiten Ihres CSS.Scott Jehl löste ein weiteres interessantes Problem, indem er eine Inline-CSS-Datei mit einem Servicemitarbeiter zwischenspeicherte, ein häufiges Problem, das Ihnen bekannt ist, wenn Sie kritisches CSS verwenden. Grundsätzlich fügen wir dem
styleein ID-Attribut hinzu, damit es mit JavaScript leicht zu finden ist, dann findet ein kleines Stück JavaScript dieses CSS und verwendet die Cache-API, um es in einem lokalen Browser-Cache zu speichern (mit einem Inhaltstyp vontext/css) zur Verwendung auf nachfolgenden Seiten. Um Inlining auf nachfolgenden Seiten zu vermeiden und stattdessen die zwischengespeicherten Assets extern zu referenzieren, setzen wir dann beim ersten Besuch einer Website ein Cookie. Voila!Es ist erwähnenswert, dass dynamisches Styling auch teuer sein kann, aber normalerweise nur in Fällen, in denen Sie sich auf Hunderte von gleichzeitig gerenderten zusammengesetzten Komponenten verlassen. Wenn Sie also CSS-in-JS verwenden, stellen Sie sicher, dass Ihre CSS-in-JS-Bibliothek die Ausführung optimiert, wenn Ihr CSS keine Abhängigkeiten von Design oder Requisiten aufweist, und überkomponieren Sie keine formatierten Komponenten . Aggelos Arvanitakis gibt weitere Einblicke in die Leistungskosten von CSS-in-JS.
- Streamen Sie Antworten?
Streams werden oft vergessen und vernachlässigt und bieten eine Schnittstelle zum Lesen oder Schreiben asynchroner Datenblöcke, von denen zu einem bestimmten Zeitpunkt möglicherweise nur eine Teilmenge im Speicher verfügbar ist. Grundsätzlich erlauben sie der Seite, die die ursprüngliche Anfrage gestellt hat, mit der Arbeit an der Antwort zu beginnen, sobald der erste Datenblock verfügbar ist, und verwenden Parser, die für das Streaming optimiert sind, um den Inhalt nach und nach anzuzeigen.Wir könnten einen Stream aus mehreren Quellen erstellen. Anstatt beispielsweise eine leere UI-Shell bereitzustellen und sie von JavaScript füllen zu lassen, können Sie den Service-Worker einen Stream erstellen lassen, bei dem die Shell aus einem Cache stammt, der Text jedoch aus dem Netzwerk. Wie Jeff Posnick bemerkte, wenn Ihre Web-App von einem CMS unterstützt wird, das HTML durch Zusammenfügen von Teilvorlagen auf dem Server rendert, wird dieses Modell direkt in die Verwendung von Streaming-Antworten übersetzt, wobei die Vorlagenlogik im Service-Worker statt auf Ihrem Server repliziert wird. Der Artikel The Year of Web Streams von Jake Archibald hebt hervor, wie genau man es aufbauen könnte. Der Leistungsschub ist deutlich spürbar.
Ein wichtiger Vorteil des Streamens der gesamten HTML-Antwort besteht darin, dass HTML, das während der anfänglichen Navigationsanforderung gerendert wird, den Streaming-HTML-Parser des Browsers voll ausnutzen kann. HTML-Blöcke, die nach dem Laden der Seite in ein Dokument eingefügt werden (wie es bei Inhalten üblich ist, die über JavaScript gefüllt werden), können diese Optimierung nicht nutzen.
Browserunterstützung? Immer noch auf dem Weg dorthin mit teilweiser Unterstützung in Chrome, Firefox, Safari und Edge, die die API und Service Workers unterstützen, die in allen modernen Browsern unterstützt werden. Und wenn Sie wieder abenteuerlustig sind, können Sie eine experimentelle Implementierung von Streaming-Anfragen testen, die es Ihnen ermöglicht, mit dem Senden der Anfrage zu beginnen, während Sie noch den Text generieren. Verfügbar in Chrome 85.
- Erwägen Sie, Ihre Komponenten verbindungsbewusst zu machen.
Daten können teuer sein, und mit wachsender Nutzlast müssen wir Benutzer respektieren, die sich für Dateneinsparungen entscheiden, während sie auf unsere Websites oder Apps zugreifen. Der Clienthinweis-Anforderungsheader von Save-Data ermöglicht es uns, die Anwendung und die Nutzlast für Benutzer mit eingeschränkten Kosten und Leistung anzupassen.Tatsächlich könnten Sie Anforderungen für Bilder mit hoher DPI in Bilder mit niedriger DPI umschreiben, Webschriftarten entfernen, ausgefallene Parallaxeneffekte, Miniaturansichten in der Vorschau anzeigen und unendlich scrollen, die automatische Wiedergabe von Videos deaktivieren, Server-Pushs deaktivieren, die Anzahl der angezeigten Elemente reduzieren und die Bildqualität herabstufen oder Sie können sogar ändern, wie Sie Markup bereitstellen. Tim Vereecke hat einen sehr ausführlichen Artikel über Data-S(h)aver-Strategien mit vielen Optionen zur Datenspeicherung veröffentlicht.
Wer nutzt
save-data, fragen Sie sich vielleicht? 18 % der weltweiten Android-Chrome-Nutzer haben den Lite-Modus aktiviert (mit aktiviertemSave-Data), und die Zahl dürfte höher sein. Laut den Untersuchungen von Simon Hearne ist die Opt-in-Rate auf billigeren Geräten am höchsten, aber es gibt viele Ausreißer. Zum Beispiel: Benutzer in Kanada haben eine Opt-in-Rate von über 34 % (im Vergleich zu ~ 7 % in den USA) und Benutzer des neuesten Samsung-Flaggschiffs haben eine Opt-in-Rate von fast 18 % weltweit.Wenn der Datenspeichermodus aktiviert ist, bietet Chrome Mobile ein optimiertes Erlebnis, dh ein Proxy-
Save-Datamit zurückgestellten Skripten , erzwungenerfont-display: swapund erzwungenem Lazy Loading. Es ist einfach sinnvoller, das Erlebnis selbst aufzubauen, anstatt sich auf den Browser zu verlassen, um diese Optimierungen vorzunehmen.Der Header wird derzeit nur in Chromium, in der Android-Version von Chrome oder über die Data Saver-Erweiterung auf einem Desktop-Gerät unterstützt. Schließlich können Sie die Netzwerkinformations-API auch verwenden, um kostspielige JavaScript-Module, hochauflösende Bilder und Videos basierend auf dem Netzwerktyp bereitzustellen. Die Network Information API und insbesondere
navigator.connection.effectiveType. EffectiveType verwendenRTT,downlink,effectiveType-Werte (und einige andere), um eine Darstellung der Verbindung und der Daten bereitzustellen, die Benutzer verarbeiten können.Max Bock spricht in diesem Zusammenhang von Connection-Aware Components und Addy Osmani von Adaptive Module Serving. Beispielsweise könnten wir mit React eine Komponente schreiben, die für verschiedene Verbindungstypen unterschiedlich rendert. Wie Max vorgeschlagen hat, könnte eine
<Media />-Komponente in einem Nachrichtenartikel Folgendes ausgeben:-
Offline: ein Platzhalter mitalt-Text, -
2G/save-dataModus: ein Bild mit niedriger Auflösung, -
3Gauf Nicht-Retina-Bildschirm: ein Bild mit mittlerer Auflösung, -
3Gauf Retina-Bildschirmen: hochauflösendes Retina-Bild, -
4G: ein HD-Video.
Dean Hume bietet eine praktische Implementierung einer ähnlichen Logik unter Verwendung eines Servicemitarbeiters. Für ein Video könnten wir standardmäßig ein Videoposter anzeigen und dann bei besseren Verbindungen das "Play"-Symbol sowie die Videoplayer-Shell, Metadaten des Videos usw. anzeigen. Als Fallback für nicht unterstützende Browser könnten wir auf das
canplaythroughEreignis lauschen undPromise.race()verwenden, um das Laden der Quelle zu verzögern, wenn dascanplaythroughEreignis nicht innerhalb von 2 Sekunden ausgelöst wird.Wenn Sie etwas tiefer eintauchen möchten, finden Sie hier ein paar Ressourcen für den Einstieg:
- Addy Osmani zeigt, wie man adaptives Serving in React implementiert.
- React Adaptive Loading Hooks & Utilities bietet Codeschnipsel für React,
- Netanel Basel untersucht verbindungsbewusste Komponenten in Angular,
- Theodore Vorilas teilt mit, wie das Bereitstellen adaptiver Komponenten mithilfe der Netzwerkinformations-API in Vue funktioniert.
- Umar Hansa zeigt, wie man teures JavaScript selektiv herunterlädt/ausführt.
-
- Erwägen Sie, Ihre Komponenten gerätespeicherfähig zu machen.
Die Netzwerkverbindung gibt uns jedoch nur eine Perspektive auf den Kontext des Benutzers. Darüber hinaus könnten Sie mit der Device Memory API auch Ressourcen basierend auf dem verfügbaren Gerätespeicher dynamisch anpassen.navigator.deviceMemorygibt zurück, wie viel RAM das Gerät in Gigabyte hat, abgerundet auf die nächste Zweierpotenz. Die API verfügt auch über einen Client-Hinweis-Header,Device-Memory, der denselben Wert meldet.Bonus : Umar Hansa zeigt, wie man teure Skripte mit dynamischen Importen aufschiebt, um die Erfahrung basierend auf Gerätespeicher, Netzwerkkonnektivität und Hardware-Parallelität zu ändern.
- Wärmen Sie die Verbindung auf, um die Lieferung zu beschleunigen.
Verwenden Sie Ressourcenhinweise, um Zeit zu sparen beidns-prefetch(der eine DNS-Suche im Hintergrund durchführt),preconnect(der den Browser auffordert, den Verbindungs-Handshake (DNS, TCP, TLS) im Hintergrund zu starten),prefetch(der den Browser fragt um eine Ressource anzufordern) undpreload(was unter anderem Ressourcen vorab abruft, ohne sie auszuführen). Gut unterstützt in modernen Browsern, mit baldiger Unterstützung für Firefox.Erinnerst du dich an
prerender? Der Ressourcenhinweis, der verwendet wird, um den Browser aufzufordern, die gesamte Seite für die nächste Navigation im Hintergrund aufzubauen. Die Implementierungsprobleme waren ziemlich problematisch und reichten von einem enormen Speicherbedarf und Bandbreitenverbrauch bis hin zu mehreren registrierten Analysetreffern und Anzeigenimpressionen.Es überrascht nicht, dass es veraltet war, aber das Chrome-Team hat es als NoState-Prefetch-Mechanismus zurückgebracht. Tatsächlich behandelt Chrome den
prerenderHinweis stattdessen als NoState Prefetch, sodass wir ihn heute noch verwenden können. Wie Katie Hempenius in diesem Artikel erklärt, „ruft NoState Prefetch wie beim Prerendering Ressourcen im Voraus ab , aber im Gegensatz zum Prerendering führt es kein JavaScript aus und rendert keinen Teil der Seite im Voraus.“NoState Prefetch verwendet nur ~45 MB Arbeitsspeicher und abgerufene Unterressourcen werden mit einer
IDLE-Netzpriorität abgerufen. Seit Chrome 69 fügt NoState Prefetch allen Anfragen den Header Purpose: Prefetch hinzu, um sie vom normalen Surfen unterscheidbar zu machen.Achten Sie auch auf Prerendering-Alternativen und -Portale, eine neue Anstrengung in Richtung datenschutzbewusstes Prerendering, das die eingefügte
previewdes Inhalts für nahtlose Navigationen bereitstellt.Die Verwendung von Ressourcenhinweisen ist wahrscheinlich der einfachste Weg, um die Leistung zu steigern , und es funktioniert tatsächlich gut. Wann was verwenden? Wie Addy Osmani erklärt hat, ist es sinnvoll, Ressourcen vorab zu laden, von denen wir wissen, dass sie sehr wahrscheinlich auf der aktuellen Seite und für zukünftige Navigationen über mehrere Navigationsgrenzen hinweg verwendet werden, z. B. Webpack-Pakete, die für Seiten benötigt werden, die der Benutzer noch nicht besucht hat.
Addys Artikel über „Loading Priorities in Chrome“ zeigt, wie genau Chrome Ressourcenhinweise interpretiert. Wenn Sie also entschieden haben, welche Assets für das Rendern wichtig sind, können Sie ihnen eine hohe Priorität zuweisen. Um zu sehen, wie Ihre Anfragen priorisiert werden, können Sie eine „Prioritäts“-Spalte in der Chrome DevTools-Netzwerkanfragetabelle (sowie in Safari) aktivieren.
Heutzutage verwenden wir meistens zumindest
preconnectunddns-prefetch, und wir werden vorsichtig sein, wenn wirprefetch,preloadundprerender. Beachten Sie, dass selbst beipreconnectunddns-prefetchder Browser eine Begrenzung für die Anzahl der Hosts hat, die er parallel nachschlagen/verbinden wird, daher ist es eine sichere Sache, sie nach Priorität zu ordnen ( danke Philip Tellis! ).Da Schriftarten normalerweise wichtige Elemente auf einer Seite sind, ist es manchmal eine gute Idee, den Browser aufzufordern, kritische Schriftarten mit
preloadherunterzuladen. Überprüfen Sie jedoch noch einmal, ob dies tatsächlich der Leistung zugute kommt, da es beim Vorladen von Schriftarten ein Rätsel der Prioritäten gibt: Da daspreloadals sehr wichtig angesehen wird, kann es sogar noch kritischere Ressourcen wie kritisches CSS überspringen. ( Danke Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Da
<link rel="preload">einmediaakzeptiert, könnten Sie sich dafür entscheiden, Ressourcen basierend auf@mediaselektiv herunterzuladen, wie oben gezeigt.Darüber hinaus können wir die Attribute
imagesrcsetundimagesizesverwenden, um spät entdeckte Heldenbilder oder Bilder, die über JavaScript geladen werden, schneller vorzuladen, z. B. Filmplakate:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>Wir können den JSON auch als fetch vorladen , sodass er erkannt wird, bevor JavaScript ihn anfordern kann:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>Wir könnten JavaScript auch dynamisch laden, effektiv für eine verzögerte Ausführung des Skripts.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);Ein paar Fallstricke, die Sie im Hinterkopf behalten sollten: Das
preloadist gut, um die Startzeit des Downloads eines Assets näher an die ursprüngliche Anfrage zu verschieben, aber vorgeladene Assets landen im Speicher-Cache , der an die Seite gebunden ist, die die Anfrage stellt.preloadspielt gut mit dem HTTP-Cache: Eine Netzwerkanfrage wird nie gesendet, wenn das Element bereits im HTTP-Cache vorhanden ist.Daher ist es nützlich für spät entdeckte Ressourcen, Hero-Bilder, die über
background-imagegeladen werden, wichtiges CSS (oder JavaScript) inlinieren und den Rest des CSS (oder JavaScript) vorab laden.
Wichtige Bilder frühzeitig vorladen; Sie müssen nicht auf JavaScript warten, um sie zu entdecken. (Bildnachweis: „Preload Late-Discovered Hero Images Faster“ von Addy Osmani) (Große Vorschau) Ein
preload-Tag kann ein Preload erst initiieren, nachdem der Browser das HTML vom Server empfangen hat und der Lookahead-Parser daspreload-Tag gefunden hat. Das Vorladen über den HTTP-Header könnte etwas schneller sein, da wir nicht darauf warten müssen, dass der Browser den HTML-Code analysiert, um die Anfrage zu starten (es wird jedoch diskutiert).Frühe Hinweise werden noch weiter helfen, indem sie das Vorladen ermöglichen, noch bevor die Antwortheader für den HTML-Code gesendet werden (auf der Roadmap in Chromium, Firefox). Außerdem helfen uns Prioritätshinweise dabei, Ladeprioritäten für Skripte anzuzeigen.
Achtung : Wenn Sie
preloadverwenden, muss esasdefiniert werden oder es wird nichts geladen, und vorgeladene Schriftarten ohne dascrossoriginAttribut werden doppelt abgerufen. Wenn Sieprefetchverwenden, achten Sie auf dieAgeHeader-Probleme in Firefox.
- Verwenden Sie Service Worker für Caching und Netzwerk-Fallbacks.
Keine Leistungsoptimierung über ein Netzwerk kann schneller sein als ein lokal gespeicherter Cache auf dem Computer eines Benutzers (es gibt jedoch Ausnahmen). Wenn Ihre Website über HTTPS läuft, können wir statische Assets in einem Service-Worker-Cache zwischenspeichern und Offline-Fallbacks (oder sogar Offline-Seiten) speichern und sie vom Computer des Benutzers abrufen, anstatt zum Netzwerk zu gehen.Wie von Phil Walton vorgeschlagen, können wir mit Servicemitarbeitern kleinere HTML-Nutzlasten senden, indem wir unsere Antworten programmgesteuert generieren. Ein Servicemitarbeiter kann nur das absolute Minimum an Daten, die er benötigt, vom Server anfordern (z. B. einen Teil des HTML-Inhalts, eine Markdown-Datei, JSON-Daten usw.) und diese Daten dann programmgesteuert in ein vollständiges HTML-Dokument umwandeln . Sobald also ein Benutzer eine Site besucht und der Service Worker installiert ist, wird der Benutzer nie wieder eine vollständige HTML-Seite anfordern. Die Auswirkungen auf die Leistung können ziemlich beeindruckend sein.
Browserunterstützung? Service-Mitarbeiter werden weitgehend unterstützt und der Fallback ist sowieso das Netzwerk. Hilft es , die Leistung zu steigern ? Oh ja, das tut es. Und es wird immer besser, z. B. mit Background Fetch, das auch Hintergrund-Uploads/Downloads über einen Servicemitarbeiter ermöglicht.
Es gibt eine Reihe von Anwendungsfällen für einen Servicemitarbeiter. Sie könnten beispielsweise die Funktion „Für Offline speichern“ implementieren, beschädigte Bilder handhaben, Nachrichten zwischen Registerkarten einführen oder verschiedene Caching-Strategien basierend auf Anforderungstypen bereitstellen. Im Allgemeinen besteht eine gängige zuverlässige Strategie darin, die App-Shell im Cache des Servicemitarbeiters zusammen mit einigen kritischen Seiten zu speichern, z. B. Offline-Seite, Titelseite und alles andere, was in Ihrem Fall wichtig sein könnte.
Es gibt jedoch ein paar Fallstricke zu beachten. Wenn ein Servicemitarbeiter vorhanden ist, müssen wir uns vor Reichweitenanfragen in Safari hüten (wenn Sie Workbox für einen Servicemitarbeiter verwenden, verfügt es über ein Bereichsanfragemodul). Wenn Sie jemals über
DOMException: Quota exceeded.Fehler in der Browserkonsole, dann schauen Sie in Gerardos Artikel Wenn 7 KB gleich 7 MB sind.Wie Gerardo schreibt: „Wenn Sie eine progressive Web-App erstellen und einen aufgeblähten Cache-Speicher feststellen, wenn Ihr Servicemitarbeiter statische Assets zwischenspeichert, die von CDNs bereitgestellt werden, stellen Sie sicher, dass der richtige CORS-Antwort-Header für ursprungsübergreifende Ressourcen vorhanden ist. Sie speichern keine undurchsichtigen Antworten Mit Ihrem Servicemitarbeiter entscheiden Sie sich unbeabsichtigt für Cross-Origin-Bild-Assets für den CORS-Modus, indem Sie das
crossoriginAttribut zum<img>-Tag hinzufügen.“Es gibt viele großartige Ressourcen , um mit Servicemitarbeitern zu beginnen:
- Service Worker Mindset, das Ihnen hilft zu verstehen, wie Servicemitarbeiter hinter den Kulissen arbeiten und was Sie beim Aufbau verstehen müssen.
- Chris Ferdinandi bietet eine großartige Artikelserie über Servicemitarbeiter, die erklärt, wie Offline-Anwendungen erstellt werden, und eine Vielzahl von Szenarien abdeckt, vom Offline-Speichern kürzlich angesehener Seiten bis zum Festlegen eines Ablaufdatums für Elemente in einem Servicemitarbeiter-Cache.
- Fallstricke und Best Practices für Servicemitarbeiter, mit einigen Tipps zum Umfang, zur Verzögerung der Registrierung eines Servicemitarbeiters und zum Zwischenspeichern von Servicemitarbeitern.
- Großartige Serie von Ire Aderinokun über „Offline First“ mit Service Worker, mit einer Strategie zum Precaching der App-Shell.
- Service Worker: Eine Einführung mit praktischen Tipps zur Verwendung von Service Worker für reichhaltige Offline-Erlebnisse, regelmäßige Hintergrundsynchronisierungen und Push-Benachrichtigungen.
- Es lohnt sich immer, auf das Offline-Kochbuch des guten alten Jake Archibald mit einer Reihe von Rezepten zum Backen Ihres eigenen Servicemitarbeiters zu verweisen.
- Workbox ist eine Reihe von Service-Worker-Bibliotheken, die speziell für die Entwicklung progressiver Web-Apps entwickelt wurden.
- Führen Sie Server-Worker auf dem CDN/Edge aus, z. B. für A/B-Tests?
Zu diesem Zeitpunkt sind wir daran gewöhnt, Service Worker auf dem Client auszuführen, aber mit CDNs, die sie auf dem Server implementieren, könnten wir sie auch verwenden, um die Leistung am Edge zu optimieren.Wenn beispielsweise HTML in A/B-Tests seinen Inhalt für verschiedene Benutzer variieren muss, könnten wir Service Worker auf den CDN-Servern einsetzen, um die Logik zu handhaben. Wir könnten auch HTML-Rewriting streamen, um Websites zu beschleunigen, die Google Fonts verwenden.
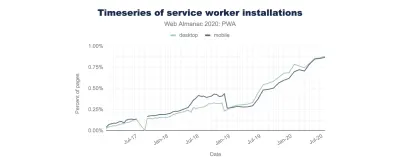
- Optimieren Sie die Renderleistung.
Wenn die Anwendung träge ist, macht sich das sofort bemerkbar. Wir müssen also sicherstellen, dass beim Scrollen der Seite oder beim Animieren eines Elements keine Verzögerung auftritt und dass Sie konstant 60 Frames pro Sekunde erreichen. Wenn das nicht möglich ist, dann ist zumindest eine konsistente Bildrate pro Sekunde einem gemischten Bereich von 60 bis 15 vorzuziehen. Verwenden Sie CSS'will-change, um den Browser darüber zu informieren, welche Elemente und Eigenschaften sich ändern.Wann immer Sie feststellen, debuggen Sie unnötige Repaints in DevTools:
- Messen Sie die Laufzeit-Rendering-Leistung. Sehen Sie sich einige nützliche Tipps an, wie Sie es verstehen können.
- Um loszulegen, lesen Sie den kostenlosen Udacity-Kurs von Paul Lewis zur Browser-Rendering-Optimierung und den Artikel von Georgy Marchuk über Browser-Painting und Überlegungen zur Web-Performance.
- Aktivieren Sie Paint Flashing in „Weitere Tools → Rendern → Paint Flashing“ in Firefox DevTools.
- Aktivieren Sie in React DevTools „Updates hervorheben“ und aktivieren Sie „Aufzeichnen, warum jede Komponente gerendert wird“.
- Sie können auch Why Did You Render verwenden, sodass Sie beim erneuten Rendern einer Komponente durch einen Blitz über die Änderung informiert werden.
Verwenden Sie ein Mauerwerk-Layout? Denken Sie daran, dass Sie möglicherweise sehr bald ein Mauerwerk-Layout nur mit CSS-Raster erstellen können.
Wenn Sie tiefer in das Thema eintauchen möchten, hat Nolan Lawson in seinem Artikel Tricks zur genauen Messung der Layoutleistung geteilt, und Jason Miller hat auch alternative Techniken vorgeschlagen. Wir haben auch einen kleinen Artikel von Sergey Chikuyonok darüber, wie man GPU-Animationen richtig macht.

Browser können Transformation und Opazität kostengünstig animieren. CSS-Trigger ist nützlich, um zu überprüfen, ob CSS Re-Layouts oder Reflows auslöst. (Bildnachweis: Addy Osmani) (Große Vorschau) Hinweis : Änderungen an GPU-zusammengesetzten Ebenen sind am kostengünstigsten. Wenn Sie also davonkommen, indem Sie nur das Zusammensetzen über
opacityundtransformauslösen, sind Sie auf dem richtigen Weg. Auch Anna Migas hat in ihrem Vortrag Debugging UI Rendering Performance viele praktische Ratschläge gegeben. Und um zu verstehen, wie die Malleistung in devtools debuggt wird, sehen Sie sich das Auditvideo zur Malleistung von Umar an. - Haben Sie die wahrgenommene Leistung optimiert?
Während die Reihenfolge, wie Komponenten auf der Seite erscheinen, und die Strategie, wie wir Assets für den Browser bereitstellen, von Bedeutung ist, sollten wir auch die Rolle der wahrgenommenen Leistung nicht unterschätzen. Das Konzept beschäftigt sich mit psychologischen Aspekten des Wartens, im Grunde hält es Kunden beschäftigt oder beschäftigt, während etwas anderes passiert. Hier kommen Wahrnehmungsmanagement, präventiver Start, vorzeitiger Abschluss und Toleranzmanagement ins Spiel.Was soll das alles heißen? Beim Laden von Assets können wir versuchen, dem Kunden immer einen Schritt voraus zu sein, sodass sich die Erfahrung schnell anfühlt, während im Hintergrund ziemlich viel passiert. Um den Kunden zu beschäftigen, können wir Skelettbildschirme (Implementierungsdemo) testen, anstatt Indikatoren zu laden, Übergänge/Animationen hinzufügen und die UX im Grunde betrügen, wenn es nichts mehr zu optimieren gibt.
In ihrer Fallstudie zu The Art of UI Skeletons teilt Kumar McMillan einige Ideen und Techniken zur Simulation dynamischer Listen, Text und des endgültigen Bildschirms sowie zur Berücksichtigung des Skelett-Denkens mit React.
Beachten Sie jedoch: Skelettbildschirme sollten vor der Bereitstellung getestet werden, da einige Tests gezeigt haben, dass Skelettbildschirme nach allen Metriken am schlechtesten abschneiden können.
- Verhindern Sie Layoutverschiebungen und Neulackierungen?
Im Bereich der wahrgenommenen Leistung ist wahrscheinlich eine der störenderen Erfahrungen Layoutverschiebungen oder Umbrüche , die durch neu skalierte Bilder und Videos, Webschriftarten, eingefügte Anzeigen oder spät entdeckte Skripte verursacht werden, die Komponenten mit tatsächlichen Inhalten füllen. Infolgedessen beginnt ein Kunde möglicherweise mit dem Lesen eines Artikels, nur um durch einen Layoutsprung über dem Lesebereich unterbrochen zu werden. Die Erfahrung ist oft abrupt und ziemlich verwirrend: und das ist wahrscheinlich ein Fall von Ladeprioritäten, die überdacht werden müssen.Die Community hat einige Techniken und Workarounds entwickelt, um Reflows zu vermeiden. Im Allgemeinen ist es eine gute Idee, das Einfügen neuer Inhalte über vorhandene Inhalte zu vermeiden , es sei denn, dies geschieht als Reaktion auf eine Benutzerinteraktion. Legen Sie Breiten- und Höhenattribute für Bilder immer fest, sodass moderne Browser das Feld zuweisen und den Platz standardmäßig reservieren (Firefox, Chrome).
Sowohl für Bilder als auch für Videos können wir einen SVG-Platzhalter verwenden, um das Anzeigefeld zu reservieren, in dem die Medien erscheinen. Das bedeutet, dass der Bereich ordnungsgemäß reserviert wird, wenn Sie auch sein Seitenverhältnis beibehalten müssen. Wir können auch Platzhalter oder Fallback-Bilder für Anzeigen und dynamische Inhalte verwenden sowie Layout-Slots vorab zuweisen.
Anstatt Bilder mit externen Skripts zu laden, sollten Sie natives Lazy-Loading oder hybrides Lazy-Loading verwenden, wenn wir ein externes Skript nur dann laden, wenn natives Lazy-Loading nicht unterstützt wird.
Wie oben erwähnt, gruppieren Sie Webfont-Repaints immer und wechseln Sie von allen Fallback-Fonts zu allen Webfonts gleichzeitig – stellen Sie nur sicher, dass dieser Wechsel nicht zu abrupt ist, indem Sie die Zeilenhöhe und den Abstand zwischen den Fonts mit dem Font-Style-Matcher anpassen .
Um Schriftartmetriken für eine Fallback-Schriftart zu überschreiben , um eine Webschriftart zu emulieren, können wir @font-face-Deskriptoren verwenden, um Schriftartmetriken zu überschreiben (Demo, aktiviert in Chrome 87). (Beachten Sie jedoch, dass Anpassungen bei komplizierten Schriftstapeln kompliziert sind.)
Für spätes CSS können wir sicherstellen, dass layoutkritisches CSS in den Header jeder Vorlage eingebunden wird . Darüber hinaus: Bei langen Seiten verschiebt der vertikale Scrollbalken den Hauptinhalt um 16 Pixel nach links. Um eine Bildlaufleiste frühzeitig anzuzeigen, können wir
overflow-y: scrollonhtmlhinzufügen, um beim ersten Malen eine Bildlaufleiste zu erzwingen. Letzteres ist hilfreich, da Bildlaufleisten nicht triviale Layoutverschiebungen verursachen können, da der Inhalt "above the fold" bei Änderungen der Breite neu fließt. Sollte jedoch hauptsächlich auf Plattformen mit Nicht-Overlay-Bildlaufleisten wie Windows auftreten. Aber: breaksposition: stickyweil diese Elemente niemals aus dem Container scrollen.Wenn Sie es mit Kopfzeilen zu tun haben, die beim Scrollen fest oder klebrig oben auf der Seite positioniert werden, reservieren Sie Platz für die Kopfzeile, wenn sie verklemmt wird, z. B. mit einem Platzhalterelement oder einem
margin-topauf dem Inhalt. Eine Ausnahme sollten Cookie-Consent-Banner sein, die keine Auswirkungen auf CLS haben sollten, aber manchmal tun sie es: es hängt von der Implementierung ab. In diesem Twitter-Thread finden Sie einige interessante Strategien und Erkenntnisse.Bei einer Registerkartenkomponente, die unterschiedlich viele Texte enthalten kann, können Sie Layoutverschiebungen mit CSS-Rasterstapeln verhindern. Indem wir den Inhalt jeder Registerkarte im selben Rasterbereich platzieren und jeweils einen davon ausblenden, können wir sicherstellen, dass der Container immer die Höhe des größeren Elements einnimmt, sodass keine Layoutverschiebungen auftreten.
Ah, und natürlich kann unendliches Scrollen und "Mehr laden" auch zu Layoutverschiebungen führen, wenn sich Inhalte unterhalb der Liste befinden (z. B. Fußzeile). Um CLS zu verbessern, reservieren Sie genügend Platz für Inhalte, die geladen würden, bevor der Benutzer zu diesem Teil der Seite scrollt, entfernen Sie die Fußzeile oder alle DOM-Elemente am unteren Rand der Seite, die durch das Laden von Inhalten nach unten gedrückt werden könnten. Daten und Bilder für „Below-the-Fold“-Inhalte vorab abrufen, sodass sie bereits da sind, wenn ein Nutzer so weit scrollt. Sie können Listenvirtualisierungsbibliotheken wie das React-Window verwenden, um auch lange Listen zu optimieren ( Danke, Addy Osmani! ).
Um sicherzustellen, dass die Auswirkungen von Umbrüchen eingedämmt werden, messen Sie die Layoutstabilität mit der Layout Instability API. Damit können Sie den Cumulative Layout Shift ( CLS ) Score berechnen und ihn als Anforderung in Ihre Tests aufnehmen, sodass Sie immer dann, wenn eine Regression auftritt, diese nachverfolgen und beheben können.
Um den Layout-Shift-Score zu berechnen, betrachtet der Browser die Ansichtsfenstergröße und die Bewegung instabiler Elemente im Ansichtsfenster zwischen zwei gerenderten Frames. Im Idealfall wäre die Punktzahl nahe
0. Es gibt einen großartigen Leitfaden von Milica Mihajlija und Philip Walton darüber, was CLS ist und wie man es misst. Dies ist ein guter Ausgangspunkt, um die wahrgenommene Leistung zu messen und aufrechtzuerhalten und Unterbrechungen zu vermeiden, insbesondere bei geschäftskritischen Aufgaben.Schneller Tipp : Um herauszufinden, was eine Layoutverschiebung in DevTools verursacht hat, können Sie Layoutverschiebungen unter „Erfahrung“ im Leistungsbereich untersuchen.
Bonus : Wenn Sie Reflows und Repaints reduzieren möchten, sehen Sie sich Charis Theodoulou's guide to Minimizing DOM Reflow/Layout Thrashing und Paul Irish's list of What forces layout/reflow sowie CSSTriggers.com an, eine Referenztabelle zu CSS-Eigenschaften, die Layout, Paint auslösen und Compositing.
Netzwerk und HTTP/2
- Ist OCSP-Heften aktiviert?
Indem Sie OCSP-Stapling auf Ihrem Server aktivieren, können Sie Ihre TLS-Handshakes beschleunigen. Das Online Certificate Status Protocol (OCSP) wurde als Alternative zum Certificate Revocation List (CRL)-Protokoll erstellt. Beide Protokolle werden verwendet, um zu prüfen, ob ein SSL-Zertifikat widerrufen wurde.Das OCSP-Protokoll erfordert jedoch nicht, dass der Browser Zeit für das Herunterladen und anschließende Durchsuchen einer Liste nach Zertifikatsinformationen aufwendet, wodurch die für einen Handshake erforderliche Zeit reduziert wird.
- Haben Sie die Auswirkungen des Widerrufs von SSL-Zertifikaten verringert?
In seinem Artikel „The Performance Cost of EV Certificates“ bietet Simon Hearne einen großartigen Überblick über gängige Zertifikate und die Auswirkungen, die die Wahl eines Zertifikats auf die Gesamtleistung haben kann.Wie Simon schreibt, gibt es in der Welt von HTTPS einige Arten von Zertifikatvalidierungsebenen, die zum Sichern des Datenverkehrs verwendet werden:
- Die Domänenvalidierung (DV) validiert, dass der Antragsteller des Zertifikats Eigentümer der Domäne ist.
- Die Organisationsvalidierung (OV) validiert, dass eine Organisation die Domain besitzt,
- Extended Validation (EV) validiert mit strenger Validierung, dass eine Organisation Eigentümer der Domäne ist.
Es ist wichtig zu beachten, dass alle diese Zertifikate in Bezug auf die Technologie gleich sind; sie unterscheiden sich nur in den Informationen und Eigenschaften, die in diesen Zertifikaten angegeben sind.
EV-Zertifikate sind teuer und zeitaufwändig, da sie einen Menschen erfordern, um ein Zertifikat zu überprüfen und seine Gültigkeit sicherzustellen. DV-Zertifikate hingegen werden oft kostenlos zur Verfügung gestellt – zB von Let’s Encrypt – einer offenen, automatisierten Zertifizierungsstelle, die in viele Hosting-Provider und CDNs gut integriert ist. Tatsächlich betreibt es zum Zeitpunkt des Schreibens über 225 Millionen Websites (PDF), obwohl es nur 2,69 % der Seiten (geöffnet in Firefox) ausmacht.
Was ist dann das Problem? Das Problem ist, dass EV-Zertifikate das oben erwähnte OCSP-Stapling nicht vollständig unterstützen . Während das Heften es dem Server ermöglicht, bei der Zertifizierungsstelle zu überprüfen, ob das Zertifikat widerrufen wurde, und diese Informationen dann zum Zertifikat hinzuzufügen ("heften"), muss der Client ohne Heften die ganze Arbeit erledigen, was zu unnötigen Anfragen während der TLS-Aushandlung führt . Bei schlechten Verbindungen kann dies zu spürbaren Leistungseinbußen (1000 ms+) führen.
EV-Zertifikate sind keine gute Wahl für die Webleistung und können sich viel stärker auf die Leistung auswirken als DV-Zertifikate. Stellen Sie für eine optimale Webleistung immer ein OCSP-geheftetes DV-Zertifikat bereit. Sie sind auch viel billiger als EV-Zertifikate und einfacher zu erwerben. Nun, zumindest bis CRLite verfügbar ist.
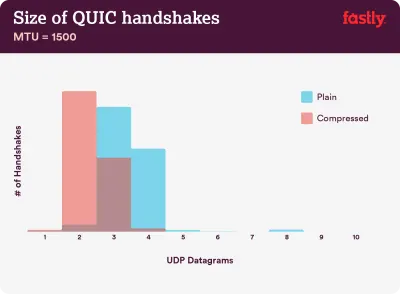
Komprimierung ist wichtig: 40–43 % der unkomprimierten Zertifikatsketten sind zu groß, um in einen einzelnen QUIC-Flight von 3 UDP-Datagrammen zu passen. (Bildnachweis:) Fastly) (Große Vorschau) Hinweis : Bei QUIC/HTTP/3 ist es erwähnenswert, dass die TLS-Zertifikatkette der einzige Inhalt mit variabler Größe ist, der die Byteanzahl im QUIC-Handshake dominiert. Die Größe variiert zwischen einigen hundert Bytes und über 10 KB.
Daher ist es auf QUIC/HTTP/3 sehr wichtig, TLS-Zertifikate klein zu halten, da große Zertifikate mehrere Handshakes verursachen. Außerdem müssen wir sicherstellen, dass die Zertifikate komprimiert sind, da die Zertifikatsketten sonst zu groß wären, um in einen einzelnen QUIC-Flug zu passen.
Weitere Details und Hinweise zum Problem und zu den Lösungen finden Sie unter:
- EV-Zertifikate machen das Web langsam und unzuverlässig von Aaron Peters,
- Die Auswirkungen des Widerrufs von SSL-Zertifikaten auf die Webleistung von Matt Hobbs,
- Die Leistungskosten von EV-Zertifikaten von Simon Hearne,
- Erfordert der QUIC-Handshake eine schnelle Komprimierung? von Patrick McManus.
- Haben Sie IPv6 schon eingeführt?
Da uns bei IPv4 der Speicherplatz ausgeht und große Mobilfunknetze IPv6 schnell übernehmen (die USA haben fast eine IPv6-Einführungsschwelle von 50 % erreicht), ist es eine gute Idee, Ihr DNS auf IPv6 zu aktualisieren, um für die Zukunft kugelsicher zu bleiben. Stellen Sie einfach sicher, dass Dual-Stack-Unterstützung im gesamten Netzwerk bereitgestellt wird – IPv6 und IPv4 können gleichzeitig nebeneinander ausgeführt werden. Schließlich ist IPv6 nicht abwärtskompatibel. Studien zeigen auch, dass IPv6 diese Websites aufgrund von Nachbarerkennung (NDP) und Routenoptimierung um 10 bis 15 % schneller gemacht hat. - Stellen Sie sicher, dass alle Assets über HTTP/2 (oder HTTP/3) laufen.
Da Google in den letzten Jahren auf ein sichereres HTTPS-Web gedrängt hat, ist eine Umstellung auf eine HTTP/2-Umgebung definitiv eine gute Investition. Tatsächlich laufen laut Web Almanac bereits 64 % aller Anfragen über HTTP/2.Es ist wichtig zu verstehen, dass HTTP/2 nicht perfekt ist und Probleme mit der Priorisierung hat, aber sehr gut unterstützt wird; und in den meisten Fällen sind Sie damit besser dran.
Ein Wort der Vorsicht: HTTP/2 Server Push wird aus Chrome entfernt. Wenn Ihre Implementierung also auf Server Push angewiesen ist, müssen Sie sie möglicherweise erneut aufrufen. Stattdessen schauen wir uns vielleicht Early Hints an, die als Experiment bereits in Fastly integriert sind.
Wenn Sie immer noch HTTP verwenden, besteht die zeitaufwändigste Aufgabe darin, zuerst zu HTTPS zu migrieren und dann Ihren Build-Prozess so anzupassen, dass er für HTTP/2-Multiplexing und -Parallelisierung geeignet ist. HTTP/2 auf Gov.uk zu bringen ist eine fantastische Fallstudie, um genau das zu tun und dabei einen Weg durch CORS, SRI und WPT zu finden. Für den Rest dieses Artikels gehen wir davon aus, dass Sie entweder zu HTTP/2 wechseln oder bereits zu HTTP/2 gewechselt haben.
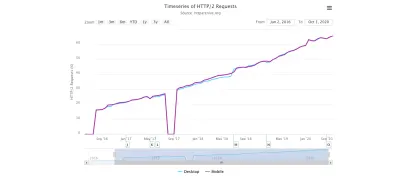
- Stellen Sie HTTP/2 ordnungsgemäß bereit.
Auch hier kann die Bereitstellung von Assets über HTTP/2 von einer teilweisen Überarbeitung Ihrer bisherigen Art der Bereitstellung von Assets profitieren. Sie müssen eine feine Balance zwischen dem Verpacken von Modulen und dem parallelen Laden vieler kleiner Module finden. Am Ende des Tages ist die beste Anfrage immer noch keine Anfrage, aber das Ziel ist es, eine feine Balance zwischen schneller Erstlieferung von Assets und Caching zu finden.Einerseits möchten Sie möglicherweise vermeiden, Assets insgesamt zu verketten, anstatt Ihre gesamte Schnittstelle in viele kleine Module zu zerlegen, sie im Rahmen des Build-Prozesses zu komprimieren und parallel zu laden. Eine Änderung an einer Datei erfordert nicht, dass das gesamte Stylesheet oder JavaScript erneut heruntergeladen werden muss. Es minimiert auch die Parsing-Zeit und hält die Nutzlast einzelner Seiten gering.
Auf der anderen Seite spielt die Verpackung immer noch eine Rolle. Durch die Verwendung vieler kleiner Skripte leidet die Gesamtkomprimierung und die Kosten für das Abrufen von Objekten aus dem Cache steigen. Die Komprimierung eines großen Pakets profitiert von der Wiederverwendung des Wörterbuchs, während kleine separate Pakete dies nicht tun. Es gibt Standardarbeit, um das anzugehen, aber es ist noch weit entfernt. Zweitens sind Browser für solche Arbeitsabläufe noch nicht optimiert . Beispielsweise löst Chrome die Interprozesskommunikation (IPCs) linear zur Anzahl der Ressourcen aus, sodass das Einbeziehen von Hunderten von Ressourcen Browserlaufzeitkosten verursacht.
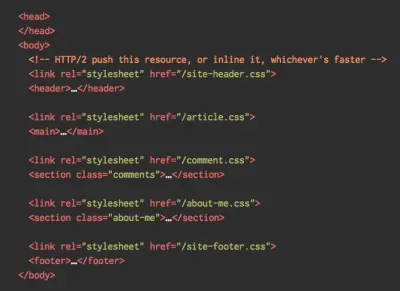
Um die besten Ergebnisse mit HTTP/2 zu erzielen, sollten Sie CSS schrittweise laden, wie von Jake Archibald von Chrome vorgeschlagen. Trotzdem können Sie versuchen, CSS progressiv zu laden. Tatsächlich blockiert In-Body-CSS das Rendern für Chrome nicht mehr. Aber es gibt einige Priorisierungsprobleme, daher ist es nicht so einfach, aber es lohnt sich, damit zu experimentieren.
Sie könnten mit der Koaleszenz von HTTP/2-Verbindungen davonkommen, die es Ihnen ermöglicht, Domain-Sharding zu verwenden und gleichzeitig von HTTP/2 zu profitieren, aber dies in der Praxis zu erreichen, ist schwierig und wird im Allgemeinen nicht als gute Praxis angesehen. Auch HTTP/2 und Subresource Integrity kommen nicht immer miteinander aus.
Was ist zu tun? Nun, wenn Sie über HTTP/2 laufen, scheint das Senden von etwa 6–10 Paketen ein anständiger Kompromiss zu sein (und ist für ältere Browser nicht allzu schlecht). Experimentieren und messen Sie, um die richtige Balance für Ihre Website zu finden.
- Senden wir alle Assets über eine einzige HTTP/2-Verbindung?
Einer der Hauptvorteile von HTTP/2 besteht darin, dass wir Assets über eine einzige Verbindung über das Kabel senden können. Manchmal haben wir jedoch etwas falsch gemacht – z. B. ein CORS-Problem oder dascrossoriginAttribut falsch konfiguriert, sodass der Browser gezwungen wäre, eine neue Verbindung zu öffnen.Um zu überprüfen, ob alle Anforderungen eine einzelne HTTP/2-Verbindung verwenden oder etwas falsch konfiguriert ist, aktivieren Sie die Spalte „Verbindungs-ID“ in DevTools → Netzwerk. Hier teilen sich beispielsweise alle Anfragen dieselbe Verbindung (286) – außer manifest.json, die eine separate öffnet (451).
- Unterstützen Ihre Server und CDNs HTTP/2?
Verschiedene Server und CDNs unterstützen HTTP/2 (noch) unterschiedlich. Verwenden Sie den CDN-Vergleich, um Ihre Optionen zu prüfen, oder sehen Sie schnell nach, wie Ihre Server funktionieren und welche Funktionen unterstützt werden.Konsultieren Sie Pat Meenans unglaubliche Forschung zu HTTP/2-Prioritäten (Video) und Testserverunterstützung für HTTP/2-Priorisierung. Laut Pat wird empfohlen, die BBR-Überlastungskontrolle zu aktivieren und
tcp_notsent_lowatauf 16 KB zu setzen, damit die HTTP/2-Priorisierung zuverlässig auf Linux 4.9-Kerneln und höher funktioniert ( danke, Yoav! ). Andy Davies führte eine ähnliche Untersuchung zur HTTP/2-Priorisierung über Browser, CDNs und Cloud-Hosting-Dienste hinweg durch.Überprüfen Sie währenddessen, ob Ihr Kernel TCP BBR unterstützt, und aktivieren Sie es, wenn möglich. Es wird derzeit auf der Google Cloud Platform, Amazon Cloudfront, Linux (z. B. Ubuntu) verwendet.
- Wird die HPACK-Komprimierung verwendet?
Wenn Sie HTTP/2 verwenden, überprüfen Sie, ob Ihre Server die HPACK-Komprimierung für HTTP-Antwortheader implementieren, um unnötigen Overhead zu reduzieren. Einige HTTP/2-Server unterstützen die Spezifikation möglicherweise nicht vollständig, wobei HPACK ein Beispiel ist. H2spec ist ein großartiges (wenn auch sehr technisch detailliertes) Tool, um dies zu überprüfen. Der Komprimierungsalgorithmus von HPACK ist ziemlich beeindruckend und funktioniert. - Stellen Sie sicher, dass die Sicherheit auf Ihrem Server kugelsicher ist.
Alle Browser-Implementierungen von HTTP/2 laufen über TLS, daher möchten Sie wahrscheinlich vermeiden, dass Sicherheitswarnungen oder einige Elemente auf Ihrer Seite nicht funktionieren. Überprüfen Sie noch einmal, ob Ihre Sicherheitsheader richtig eingestellt sind, beseitigen Sie bekannte Schwachstellen und überprüfen Sie Ihr HTTPS-Setup.Stellen Sie außerdem sicher, dass alle externen Plugins und Tracking-Skripte über HTTPS geladen werden, dass Cross-Site-Scripting nicht möglich ist und dass sowohl HTTP Strict Transport Security-Header als auch Content Security Policy-Header richtig gesetzt sind.
- Unterstützen Ihre Server und CDNs HTTP/3?
Während HTTP/2 dem Web eine Reihe signifikanter Leistungsverbesserungen gebracht hat, ließ es auch einiges an Verbesserungspotenzial übrig – insbesondere Head-of-Line-Blocking in TCP, das sich in einem langsamen Netzwerk mit erheblichem Paketverlust bemerkbar machte. HTTP/3 löst diese Probleme endgültig (Artikel).Um HTTP/2-Probleme anzugehen, hat die IETF zusammen mit Google, Akamai und anderen an einem neuen Protokoll gearbeitet, das kürzlich als HTTP/3 standardisiert wurde.
Robin Marx hat HTTP/3 sehr gut erklärt, und die folgende Erklärung basiert auf seiner Erklärung. Im Kern ist HTTP/3 in Bezug auf die Funktionen HTTP/2 sehr ähnlich , aber unter der Haube funktioniert es ganz anders. HTTP/3 bietet eine Reihe von Verbesserungen: schnellere Handshakes, bessere Verschlüsselung, zuverlässigere unabhängige Streams, bessere Verschlüsselung und Flusskontrolle. Ein bemerkenswerter Unterschied besteht darin, dass HTTP/3 QUIC als Transportschicht verwendet, wobei QUIC-Pakete auf UDP-Diagrammen gekapselt sind und nicht auf TCP.
QUIC integriert TLS 1.3 vollständig in das Protokoll, während es in TCP darüber geschichtet ist. Im typischen TCP-Stack haben wir einige Roundtrip-Zeiten an Overhead, da TCP und TLS ihre eigenen separaten Handshakes ausführen müssen, aber mit QUIC können beide kombiniert und in nur einem einzigen Roundtrip abgeschlossen werden. Da TLS 1.3 es uns ermöglicht, Verschlüsselungsschlüssel für eine nachfolgende Verbindung einzurichten, können wir ab der zweiten Verbindung bereits Daten der Anwendungsschicht im ersten Roundtrip senden und empfangen, der als „0-RTT“ bezeichnet wird.
Außerdem wurde der Header-Komprimierungsalgorithmus von HTTP/2 zusammen mit seinem Priorisierungssystem komplett neu geschrieben. Außerdem unterstützt QUIC die Verbindungsmigration von Wi-Fi zum Mobilfunknetz über Verbindungs-IDs im Header jedes QUIC-Pakets. Die meisten Implementierungen erfolgen im Userspace, nicht im Kernelspace (wie bei TCP), also sollten wir damit rechnen, dass sich das Protokoll in Zukunft weiterentwickeln wird.
Würde das alles einen großen Unterschied machen? Wahrscheinlich ja, insbesondere mit Auswirkungen auf die Ladezeiten auf Mobilgeräten, aber auch darauf, wie wir Endbenutzern Assets bereitstellen. Während sich bei HTTP/2 mehrere Anfragen eine Verbindung teilen, teilen sich Anfragen bei HTTP/3 ebenfalls eine Verbindung, streamen aber unabhängig voneinander, sodass sich ein verworfenes Paket nicht mehr auf alle Anfragen auswirkt, sondern nur noch auf einen Stream.
Das bedeutet, dass bei einem großen JavaScript-Bundle die Verarbeitung von Assets zwar verlangsamt wird, wenn ein Stream angehalten wird, die Auswirkungen jedoch weniger signifikant sind, wenn mehrere Dateien parallel gestreamt werden (HTTP/3). Die Verpackung spielt also immer noch eine Rolle .
HTTP/3 ist noch in Arbeit. Chrome, Firefox und Safari haben bereits Implementierungen. Einige CDNs unterstützen bereits QUIC und HTTP/3. Ende 2020 begann Chrome mit der Bereitstellung von HTTP/3 und IETF QUIC, und tatsächlich laufen alle Google-Dienste (Google Analytics, YouTube usw.) bereits über HTTP/3. LiteSpeed Web Server unterstützt HTTP/3, aber weder Apache, nginx noch IIS unterstützen es noch, aber es wird sich wahrscheinlich 2021 schnell ändern.
Fazit : Wenn Sie die Möglichkeit haben, HTTP/3 auf dem Server und in Ihrem CDN zu verwenden, ist dies wahrscheinlich eine sehr gute Idee. Der Hauptvorteil ergibt sich aus dem gleichzeitigen Abrufen mehrerer Objekte, insbesondere bei Verbindungen mit hoher Latenz. Wir wissen es noch nicht genau, da in diesem Bereich noch nicht viel geforscht wird, aber die ersten Ergebnisse sind sehr vielversprechend.
Wenn Sie mehr in die Besonderheiten und Vorteile des Protokolls eintauchen möchten, finden Sie hier einige gute Ausgangspunkte, die Sie überprüfen sollten:
- HTTP/3 Explained, eine gemeinsame Anstrengung zur Dokumentation der HTTP/3- und QUIC-Protokolle. Verfügbar in verschiedenen Sprachen, auch als PDF.
- Verbesserung der Webleistung mit HTTP/3 mit Daniel Stenberg.
- An Academic's Guide to QUIC with Robin Marx führt grundlegende Konzepte der QUIC- und HTTP/3-Protokolle ein, erklärt, wie HTTP/3 Head-of-Line-Blocking und Verbindungsmigration handhabt und wie HTTP/3 so konzipiert ist, dass es immergrün ist (Danke, Simon !).
- Sie können auf HTTP3Check.net überprüfen, ob Ihr Server auf HTTP/3 läuft.
Testen und Überwachen
- Haben Sie Ihren Revisionsworkflow optimiert?
Es mag nicht nach einer großen Sache klingen, aber wenn Sie die richtigen Einstellungen zur Hand haben, können Sie beim Testen einiges an Zeit sparen. Erwägen Sie die Verwendung des Alfred-Workflows von Tim Kadlec für WebPageTest, um einen Test an die öffentliche Instanz von WebPageTest zu senden. Tatsächlich hat WebPageTest viele obskure Funktionen, also nehmen Sie sich die Zeit, um zu lernen, wie man ein WebPageTest Waterfall View-Diagramm liest und wie man ein WebPageTest Connection View-Diagramm liest, um Leistungsprobleme schneller zu diagnostizieren und zu lösen.Sie können WebPageTest auch von einer Google-Tabelle aus steuern und Zugänglichkeits-, Leistungs- und SEO-Ergebnisse in Ihr Travis-Setup mit Lighthouse CI oder direkt in Webpack integrieren.
Werfen Sie einen Blick auf das kürzlich veröffentlichte AutoWebPerf, ein modulares Tool, das die automatische Erfassung von Leistungsdaten aus mehreren Quellen ermöglicht. Beispielsweise könnten wir einen täglichen Test auf Ihren kritischen Seiten einrichten, um die Felddaten aus der CrUX-API und Labordaten aus einem Lighthouse-Bericht von PageSpeed Insights zu erfassen.
Und wenn Sie etwas schnell debuggen müssen, Ihr Build-Prozess jedoch bemerkenswert langsam zu sein scheint, denken Sie daran, dass „das Entfernen von Leerzeichen und das Verstümmeln von Symbolen 95 % der Größenreduzierung im minimierten Code für die meisten JavaScript ausmachen – nicht aufwändige Codetransformationen. Sie können Deaktivieren Sie einfach die Komprimierung, um Uglify-Builds um das 3- bis 4-fache zu beschleunigen."
- Haben Sie in Proxy-Browsern und Legacy-Browsern getestet?
Das Testen in Chrome und Firefox reicht nicht aus. Sehen Sie sich an, wie Ihre Website in Proxy-Browsern und älteren Browsern funktioniert. UC Browser und Opera Mini haben beispielsweise einen bedeutenden Marktanteil in Asien (bis zu 35 % in Asien). Messen Sie die durchschnittliche Internetgeschwindigkeit in Ihren Interessensländern, um später große Überraschungen zu vermeiden. Testen Sie mit Netzwerkdrosselung und emulieren Sie ein Gerät mit hoher DPI. BrowserStack eignet sich hervorragend zum Testen auf realen Remote- Geräten und ergänzt es mit mindestens ein paar echten Geräten in Ihrem Büro – es lohnt sich.
- Haben Sie die Leistung Ihrer 404-Seiten getestet?
Normalerweise denken wir nicht lange nach, wenn es um 404-Seiten geht. Wenn ein Client eine Seite anfordert, die auf dem Server nicht vorhanden ist, antwortet der Server schließlich mit einem 404-Statuscode und der zugehörigen 404-Seite. Da ist nicht so viel dran, oder?Ein wichtiger Aspekt von 404-Antworten ist die tatsächliche Größe des Antworttexts , die an den Browser gesendet wird. Laut der 404-Seiten-Recherche von Matt Hobbs stammt die überwiegende Mehrheit der 404-Antworten von fehlenden Favicons, WordPress-Upload-Anfragen, defekten JavaScript-Anfragen, Manifest-Dateien sowie CSS- und Schriftdateien. Jedes Mal, wenn ein Kunde ein Asset anfordert, das nicht existiert, erhält er eine 404-Antwort – und oft ist diese Antwort riesig.
Achten Sie darauf, die Caching-Strategie für Ihre 404-Seiten zu prüfen und zu optimieren. Unser Ziel ist es, dem Browser HTML nur dann bereitzustellen, wenn er eine HTML-Antwort erwartet, und für alle anderen Antworten eine kleine Fehlernutzlast zurückzugeben. Laut Matt „haben wir die Möglichkeit, die 404-Seiten-Antwort auf dem CDN zwischenzuspeichern, wenn wir ein CDN vor unserem Ursprung platzieren den Ursprungsserver zwingen, auf jede 404-Anfrage zu antworten, anstatt das CDN mit einer zwischengespeicherten Version antworten zu lassen."
404-Fehler können nicht nur Ihre Leistung beeinträchtigen, sondern auch Traffic kosten. Daher ist es eine gute Idee, eine 404-Fehlerseite in Ihre Lighthouse-Testsuite aufzunehmen und deren Punktzahl im Laufe der Zeit zu verfolgen.
- Haben Sie die Leistung Ihrer DSGVO-Zustimmungsaufforderungen getestet?
In Zeiten von GDPR und CCPA ist es üblich geworden, sich auf Drittanbieter zu verlassen, um Optionen für EU-Kunden bereitzustellen, um sich für das Tracking zu entscheiden oder es abzulehnen. Wie bei jedem anderen Skript von Drittanbietern kann ihre Leistung jedoch einen ziemlich verheerenden Einfluss auf den gesamten Leistungsaufwand haben.Natürlich wird die tatsächliche Zustimmung wahrscheinlich die Auswirkungen von Skripten auf die Gesamtleistung ändern, also sollten wir, wie Boris Schapira bemerkte, ein paar verschiedene Webleistungsprofile untersuchen:
- Die Zustimmung wurde vollständig verweigert,
- Die Zustimmung wurde teilweise verweigert,
- Die Zustimmung wurde vollständig erteilt.
- Der Benutzer hat nicht auf die Einwilligungsaufforderung reagiert (oder die Aufforderung wurde von einem Inhaltsblocker blockiert),
Normalerweise sollten Cookie-Zustimmungsaufforderungen keinen Einfluss auf CLS haben, aber manchmal tun sie das, also erwägen Sie die Verwendung der kostenlosen und Open-Source-Optionen Osano oder cookie-consent-box.
Im Allgemeinen lohnt es sich, die Popup-Performance zu untersuchen, da Sie den horizontalen oder vertikalen Offset des Mausereignisses bestimmen und das Popup relativ zum Anker richtig positionieren müssen. Noam Rosenthal teilt die Erkenntnisse des Wikimedia-Teams im Artikel Web performance case study: Wikipedia page previews (auch als Video und Protokoll verfügbar).
- Führen Sie ein Leistungsdiagnose-CSS?
Obwohl wir alle Arten von Überprüfungen einschließen können, um sicherzustellen, dass nicht performanter Code bereitgestellt wird, ist es oft nützlich, sich einen schnellen Überblick über einige der niedrig hängenden Früchte zu verschaffen, die leicht gelöst werden könnten. Dafür könnten wir das brillante Performance Diagnostics CSS von Tim Kadlec verwenden (inspiriert von Harry Roberts 'Snippet, das verzögert geladene Bilder, Bilder ohne Größe, Bilder im Legacy-Format und synchrone Skripte hervorhebt.Sie möchten zB sicherstellen, dass keine Bilder "above the fold" geladen werden. Sie können das Snippet an Ihre Bedürfnisse anpassen, z. B. um nicht verwendete Webfonts hervorzuheben oder Icon-Fonts zu erkennen. Ein großartiges kleines Tool, um sicherzustellen, dass Fehler beim Debuggen sichtbar sind, oder um das aktuelle Projekt sehr schnell zu prüfen.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Haben Sie die Auswirkungen auf die Zugänglichkeit getestet?
Wenn der Browser mit dem Laden einer Seite beginnt, erstellt er ein DOM, und wenn eine unterstützende Technologie wie ein Screenreader ausgeführt wird, erstellt er auch einen Barrierefreiheitsbaum. Der Bildschirmleser muss dann den Barrierefreiheitsbaum abfragen, um die Informationen abzurufen und sie dem Benutzer zur Verfügung zu stellen – manchmal standardmäßig und manchmal bei Bedarf. Und manchmal braucht es Zeit.Wenn wir von schneller Time to Interactive sprechen, meinen wir normalerweise einen Indikator dafür, wie schnell ein Benutzer mit der Seite interagieren kann, indem er auf Links und Schaltflächen klickt oder tippt. Bei Screenreadern ist der Kontext etwas anders. In diesem Fall bedeutet schnelle Interaktivität, wie viel Zeit vergeht, bis der Screenreader die Navigation auf einer bestimmten Seite ankündigen kann und ein Screenreader-Benutzer tatsächlich die Tastatur drücken kann, um zu interagieren.
Leonie Watson hat einen aufschlussreichen Vortrag über die Leistung der Barrierefreiheit und insbesondere über die Auswirkungen langsamer Ladevorgänge auf Verzögerungen bei der Ankündigung von Screenreadern gehalten. Screenreader sind an schnelle Ansagen und schnelle Navigation gewöhnt und daher möglicherweise noch weniger geduldig als sehende Benutzer.
Große Seiten und DOM-Manipulationen mit JavaScript führen zu Verzögerungen bei Screenreader-Ankündigungen. Ein ziemlich unerforschter Bereich, der etwas Aufmerksamkeit und Tests gebrauchen könnte, da Screenreader auf buchstäblich jeder Plattform verfügbar sind (Jaws, NVDA, Voiceover, Narrator, Orca).
- Ist eine kontinuierliche Überwachung eingerichtet?
Eine private Instanz von WebPagetest ist für schnelle und unbegrenzte Tests immer von Vorteil. Ein kontinuierliches Überwachungstool – wie Sitespeed, Calibre und SpeedCurve – mit automatischen Benachrichtigungen gibt Ihnen jedoch ein detaillierteres Bild Ihrer Leistung. Legen Sie Ihre eigenen Benutzer-Timing-Marken fest, um geschäftsspezifische Metriken zu messen und zu überwachen. Erwägen Sie auch das Hinzufügen automatisierter Leistungsregressionswarnungen, um Änderungen im Laufe der Zeit zu überwachen.Erwägen Sie die Verwendung von RUM-Lösungen, um Leistungsänderungen im Laufe der Zeit zu überwachen. Für automatisierte Unit-Test-ähnliche Lasttest-Tools können Sie k6 mit seiner Skript-API verwenden. Schauen Sie sich auch SpeedTracker, Lighthouse und Calibre an.
Schnelle Gewinne
Diese Liste ist ziemlich umfangreich, und das Abschließen aller Optimierungen kann eine ganze Weile dauern. Was würden Sie also tun, wenn Sie nur 1 Stunde Zeit hätten, um signifikante Verbesserungen zu erzielen? Lassen Sie uns alles auf 17 niedrig hängende Früchte reduzieren . Messen Sie natürlich vor Beginn und nach Abschluss die Ergebnisse, einschließlich „Last Contentful Paint“ und „Time To Interactive“ über eine 3G- und Kabelverbindung.
- Messen Sie die Erfahrung in der realen Welt und setzen Sie sich angemessene Ziele. Versuchen Sie, mindestens 20 % schneller zu sein als Ihr schnellster Konkurrent. Bleiben Sie innerhalb des größten Contentful Paint < 2,5 s, eine erste Eingabeverzögerung < 100 ms, Zeit bis zur Interaktivität < 5 s bei langsamem 3G, für wiederholte Besuche, TTI < 2 s. Optimieren Sie mindestens für First Contentful Paint und Time To Interactive.
- Optimieren Sie Bilder mit Squoosh, mozjpeg, guetzli, pingo und SVGOMG und stellen Sie AVIF/WebP mit einem Bild-CDN bereit.
- Bereiten Sie kritisches CSS für Ihre Hauptvorlagen vor und integrieren Sie sie in den
<head>jeder Vorlage. Arbeiten Sie für CSS/JS innerhalb eines kritischen Dateigrößenbudgets von max. 170 KB gzippt (0,7 MB dekomprimiert). - Trimmen, Optimieren, Verzögern und Lazy-Load von Skripten. Investieren Sie in die Konfiguration Ihres Bundlers, um Redundanzen zu entfernen und leichte Alternativen zu prüfen.
- Hosten Sie Ihre statischen Assets immer selbst und ziehen Sie es immer vor, Assets von Drittanbietern selbst zu hosten. Begrenzen Sie die Auswirkungen von Skripten von Drittanbietern. Verwenden Sie Fassaden, laden Sie Widgets bei der Interaktion und achten Sie auf Anti-Flicker-Snippets.
- Seien Sie wählerisch bei der Auswahl eines Frameworks. Identifizieren Sie für Single-Page-Anwendungen kritische Seiten und stellen Sie sie statisch bereit oder rendern Sie sie zumindest vor, verwenden Sie progressive Hydratation auf Komponentenebene und importieren Sie Module bei Interaktion.
- Clientseitiges Rendern allein ist keine gute Wahl für die Leistung. Rendern Sie vor, wenn sich Ihre Seiten nicht stark ändern, und verschieben Sie das Booten von Frameworks, wenn Sie können. Verwenden Sie nach Möglichkeit serverseitiges Streaming-Rendering.
- Stellen Sie Legacy-Code nur für Legacy-Browser mit
<script type="module">und module/nomodule-Muster bereit. - Experimentieren Sie mit der Neugruppierung Ihrer CSS-Regeln und testen Sie In-Body-CSS.
- Fügen Sie Ressourcenhinweise hinzu, um die Bereitstellung mit schnellerem
dns-lookup,preconnect,prefetch,preloadundprerenderzu beschleunigen. - Unterteilen Sie Webschriftarten und laden Sie sie asynchron, und nutzen Sie die
font-displayin CSS für ein schnelles erstes Rendern. - Überprüfen Sie, ob HTTP-Cache-Header und Sicherheitsheader richtig eingestellt sind.
- Aktivieren Sie die Brotli-Komprimierung auf dem Server. (Wenn das nicht möglich ist, stellen Sie zumindest sicher, dass die Gzip-Komprimierung aktiviert ist.)
- Aktivieren Sie die TCP-BBR-Überlastung, solange Ihr Server auf der Linux-Kernel-Version 4.9+ läuft.
- Aktivieren Sie nach Möglichkeit OCSP-Stapling und IPv6. Stellen Sie immer ein OCSP-geheftetes DV-Zertifikat bereit.
- Aktivieren Sie die HPACK-Komprimierung für HTTP/2 und wechseln Sie zu HTTP/3, falls verfügbar.
- Cache-Assets wie Schriftarten, Stile, JavaScript und Bilder in einem Service-Worker-Cache.
Checkliste herunterladen (PDF, Apple Pages)
Mit dieser Checkliste sollten Sie auf jede Art von Front-End-Performance-Projekt vorbereitet sein. Sie können gerne das druckfertige PDF der Checkliste sowie ein bearbeitbares Apple Pages-Dokument herunterladen, um die Checkliste an Ihre Bedürfnisse anzupassen:
- Checkliste PDF herunterladen (PDF, 166 KB)
- Checkliste in Apple Pages herunterladen (.pages, 275 KB)
- Download der Checkliste in MS Word (.docx, 151 KB)
Wenn Sie Alternativen benötigen, können Sie auch die Frontend-Checkliste von Dan Rublic, die "Designer's Web Performance Checklist" von Jon Yablonski und die FrontendChecklist überprüfen.
Los geht's!
Einige der Optimierungen könnten den Rahmen Ihrer Arbeit oder Ihres Budgets sprengen oder angesichts des Legacy-Codes, mit dem Sie sich befassen müssen, einfach übertrieben sein. Das ist gut! Verwenden Sie diese Checkliste als allgemeinen (und hoffentlich umfassenden) Leitfaden und erstellen Sie Ihre eigene Liste von Problemen, die für Ihren Kontext gelten. Am wichtigsten ist jedoch, dass Sie Ihre eigenen Projekte testen und messen, um Probleme zu identifizieren, bevor Sie sie optimieren. Allen frohe Leistungsergebnisse im Jahr 2021!
Ein großes Dankeschön an Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov und Rodney Rehm für die Durchsicht dieses Artikels sowie unserer fantastischen Community, die Techniken und Lehren aus ihrer Arbeit in der Leistungsoptimierung geteilt hat, die jeder nutzen kann . Du bist wirklich der Hammer!