
Flaky Tests: Einen lebenden Albtraum beim Testen loswerden
Veröffentlicht: 2022-03-10Es gibt eine Fabel, über die ich in diesen Tagen oft nachdenke. Die Fabel wurde mir als Kind erzählt. Es heißt „The Boy Who Cried Wolf“ von Aesop. Es geht um einen Jungen, der die Schafe seines Dorfes hütet. Er langweilt sich und tut so, als ob ein Wolf die Herde angreift und die Dorfbewohner um Hilfe ruft – nur damit sie enttäuscht feststellen, dass es sich um einen Fehlalarm handelt, und den Jungen in Ruhe lassen. Als dann tatsächlich ein Wolf auftaucht und der Junge um Hilfe ruft, glauben die Dorfbewohner, dass es sich um einen weiteren Fehlalarm handelt, und kommen nicht zur Rettung, und die Schafe werden schließlich vom Wolf gefressen.
Die Moral der Geschichte lässt sich am besten vom Autor selbst zusammenfassen:
„Einem Lügner wird nicht geglaubt, selbst wenn er die Wahrheit sagt.“
Ein Wolf greift die Schafe an und der Junge schreit um Hilfe, aber nach zahlreichen Lügen glaubt ihm niemand mehr. Diese Moral lässt sich auf das Testen übertragen: Die Geschichte von Aesop ist eine schöne Allegorie für ein passendes Muster, über das ich gestolpert bin: unbeständige Tests, die keinen Wert liefern.
Front-End-Tests: Warum sich überhaupt die Mühe machen?
Die meiste Zeit verbringe ich mit Front-End-Tests. Es sollte Sie also nicht überraschen, dass die Codebeispiele in diesem Artikel hauptsächlich aus den Frontend-Tests stammen, auf die ich bei meiner Arbeit gestoßen bin. In den meisten Fällen können sie jedoch leicht in andere Sprachen übersetzt und auf andere Frameworks angewendet werden. Ich hoffe also, dass der Artikel für Sie nützlich ist – unabhängig davon, über welches Fachwissen Sie verfügen.
Es lohnt sich, sich daran zu erinnern, was Front-End-Tests bedeuten. Im Wesentlichen handelt es sich beim Front-End-Testen um eine Reihe von Verfahren zum Testen der Benutzeroberfläche einer Webanwendung, einschließlich ihrer Funktionalität.
Ich habe als Qualitätssicherungsingenieur angefangen und kenne den Schmerz endloser manueller Tests aus einer Checkliste kurz vor einer Veröffentlichung. Neben dem Ziel, sicherzustellen, dass eine Anwendung bei aufeinanderfolgenden Updates fehlerfrei bleibt, war ich bestrebt, die Arbeitsbelastung durch Tests zu verringern, die durch Routineaufgaben verursacht werden, für die Sie eigentlich keinen Menschen benötigen. Jetzt, als Entwickler, finde ich das Thema immer noch relevant, zumal ich versuche, Benutzern und Mitarbeitern gleichermaßen direkt zu helfen. Und es gibt vor allem ein Problem beim Testen, das uns Alpträume beschert hat.
Die Wissenschaft der schuppigen Tests
Ein ungleichmäßiger Test ist ein Test, der nicht jedes Mal das gleiche Ergebnis liefert, wenn die gleiche Analyse durchgeführt wird. Der Build schlägt nur gelegentlich fehl: Einmal wird er bestanden, ein anderes Mal fehlgeschlagen, das nächste Mal erneut bestanden, ohne dass Änderungen am Build vorgenommen wurden.
Wenn ich mich an meine Prüfungsalbträume erinnere, kommt mir ein Fall besonders in den Sinn. Es war in einem UI-Test. Wir haben ein benutzerdefiniertes Kombinationsfeld (dh eine auswählbare Liste mit Eingabefeld) erstellt:
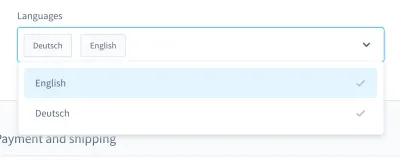
Mit diesem Kombinationsfeld können Sie nach einem Produkt suchen und eines oder mehrere der Ergebnisse auswählen. Viele Tage lief dieser Test gut, aber irgendwann änderten sich die Dinge. Bei einem der etwa zehn Builds in unserem Continuous Integration (CI)-System ist der Test zum Suchen und Auswählen eines Produkts in diesem Kombinationsfeld fehlgeschlagen.
Der Screenshot des Fehlers zeigt, dass die Ergebnisliste trotz erfolgreicher Suche nicht gefiltert wird:
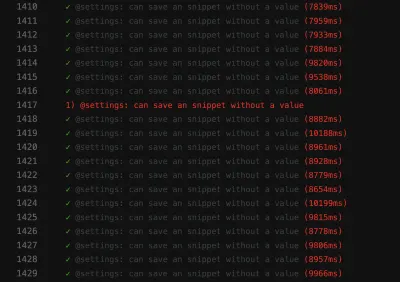
Ein fehlerhafter Test wie dieser kann die Continuous Deployment-Pipeline blockieren und die Funktionsbereitstellung langsamer als nötig machen. Außerdem ist ein ungleichmäßiger Test problematisch, weil er nicht mehr deterministisch ist – und damit unbrauchbar. Schließlich würde man einem genausowenig vertrauen wie einem Lügner.
Darüber hinaus sind fehlerhafte Tests teuer in der Reparatur und erfordern oft Stunden oder sogar Tage zum Debuggen. Auch wenn End-to-End-Tests anfälliger für Fehler sind, habe ich sie bei allen Arten von Tests erlebt: Unit-Tests, Funktionstests, End-to-End-Tests und alles dazwischen.
Ein weiteres erhebliches Problem bei unzuverlässigen Tests ist die Einstellung, die sie uns Entwicklern vermitteln. Als ich anfing, in der Testautomatisierung zu arbeiten, hörte ich oft, wie Entwickler als Antwort auf einen fehlgeschlagenen Test sagten:
„Ahh, dieser Aufbau. Macht nichts, lass es einfach wieder los. Irgendwann wird es vorbei sein.“
Das ist für mich eine riesige rote Fahne . Es zeigt mir, dass der Fehler im Build nicht ernst genommen wird. Es wird davon ausgegangen, dass ein fehlerhafter Test kein echter Fehler ist, sondern „nur“ fehlerhaft ist, ohne dass er behandelt oder gar debuggt werden muss. Der Test wird später sowieso wieder bestanden, oder? Nö! Wird ein solcher Commit gemergt, haben wir im schlimmsten Fall einen neuen flockigen Test im Produkt.
Die Ursachen
Daher sind flockige Tests problematisch. Was sollen wir dagegen tun? Nun, wenn wir das Problem kennen, können wir eine Gegenstrategie entwickeln.
Ursachen begegnen mir oft im Alltag. Sie können in den Tests selbst gefunden werden . Die Tests können suboptimal geschrieben sein, falsche Annahmen enthalten oder schlechte Praktiken enthalten. Aber nicht nur das. Flockige Tests können ein Hinweis auf etwas viel Schlimmeres sein.
In den folgenden Abschnitten gehen wir auf die häufigsten ein, denen ich begegnet bin.
1. Testseitige Ursachen
In einer idealen Welt sollte der Anfangszustand Ihrer Anwendung makellos und zu 100 % vorhersehbar sein. In Wirklichkeit wissen Sie nie, ob die ID, die Sie in Ihrem Test verwendet haben, immer dieselbe ist.
Sehen wir uns zwei Beispiele für einen einzigen Fehler meinerseits an. Fehler Nummer eins war die Verwendung einer ID in meinen Testvorrichtungen:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }Fehler Nummer zwei war die Suche nach einem eindeutigen Selektor zur Verwendung in einem UI-Test und der Gedanke: „Ok, diese ID scheint eindeutig zu sein. Ich werde es benutzen.“
<!-- This is a text field I took from a project I worked on --> <input type="text" />Wenn ich den Test jedoch auf einer anderen Installation oder später auf mehreren Builds in CI ausführen würde, könnten diese Tests fehlschlagen. Unsere Anwendung würde die IDs neu generieren und sie zwischen Builds ändern. Die erste mögliche Ursache ist also in fest codierten IDs zu suchen.
Die zweite Ursache kann sich aus zufällig (oder anderweitig) generierten Demodaten ergeben. Sicher, Sie denken vielleicht, dass dieser „Fehler“ gerechtfertigt ist – schließlich ist die Datengenerierung zufällig – aber denken Sie darüber nach, diese Daten zu debuggen. Es kann sehr schwierig sein zu erkennen, ob ein Fehler in den Tests selbst oder in den Demodaten steckt.
Als nächstes kommt eine testseitige Ursache, mit der ich schon oft gekämpft habe: Tests mit übergreifenden Abhängigkeiten . Einige Tests können möglicherweise nicht unabhängig voneinander oder in zufälliger Reihenfolge ausgeführt werden, was problematisch ist. Außerdem könnten frühere Tests nachfolgende stören. Diese Szenarien können durch die Einführung von Nebenwirkungen zu fehlerhaften Tests führen.
Vergessen Sie jedoch nicht, dass es bei Tests darum geht, Annahmen zu hinterfragen . Was passiert, wenn Ihre Annahmen von Anfang an fehlerhaft sind? Ich habe diese oft erlebt, mein Favorit waren fehlerhafte Annahmen über die Zeit.
Ein Beispiel ist die Verwendung ungenauer Wartezeiten, insbesondere in UI-Tests – beispielsweise durch die Verwendung fester Wartezeiten . Die folgende Zeile stammt aus einem Nightwatch.js-Test.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Eine weitere falsche Annahme bezieht sich auf die Zeit selbst. Ich habe einmal entdeckt, dass ein fehlerhafter PHPUnit-Test nur in unseren nächtlichen Builds fehlschlug. Nach einigem Debugging fand ich heraus, dass die Zeitverschiebung zwischen gestern und heute der Übeltäter war. Ein weiteres gutes Beispiel sind Ausfälle aufgrund von Zeitzonen .
Falsche Annahmen hören hier nicht auf. Wir können auch falsche Annahmen über die Reihenfolge der Daten haben. Stellen Sie sich ein Raster oder eine Liste mit mehreren Einträgen mit Informationen vor, z. B. eine Liste mit Währungen:
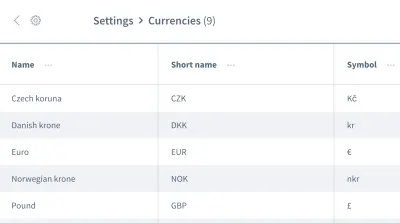
Wir wollen mit den Informationen des ersten Eintrags, der Währung „Tschechische Krone“, arbeiten. Können Sie sicher sein, dass Ihre Anwendung dieses Datenelement bei jeder Ausführung Ihres Tests immer als ersten Eintrag platziert? Könnte es sein, dass der „Euro“ oder eine andere Währung bei einigen Gelegenheiten der erste Eintrag sein wird?
Gehen Sie nicht davon aus, dass Ihre Daten in der Reihenfolge kommen, in der Sie sie benötigen. Ähnlich wie bei fest codierten IDs kann sich eine Reihenfolge je nach Design der Anwendung zwischen Builds ändern.
2. Umweltseitige Ursachen
Die nächste Kategorie von Ursachen bezieht sich auf alles außerhalb Ihrer Tests. Konkret sprechen wir über die Umgebung, in der die Tests ausgeführt werden, die CI- und Docker-bezogenen Abhängigkeiten außerhalb Ihrer Tests – all diese Dinge, die Sie zumindest in Ihrer Rolle als Tester kaum beeinflussen können.
Eine häufige umgebungsseitige Ursache sind Ressourcenlecks : Oft ist dies eine Anwendung unter Last, die zu unterschiedlichen Ladezeiten oder unerwartetem Verhalten führt. Große Tests können leicht Lecks verursachen und viel Speicher verbrauchen. Ein weiteres häufiges Problem ist die fehlende Bereinigung .
Die Inkompatibilität zwischen Abhängigkeiten bereitet mir besonders Alpträume. Ein Albtraum trat auf, als ich mit Nightwatch.js für UI-Tests arbeitete. Nightwatch.js verwendet WebDriver, der natürlich von Chrome abhängt. Als Chrome mit einem Update nach vorne sprintete, gab es ein Problem mit der Kompatibilität: Chrome, WebDriver und Nightwatch.js selbst funktionierten nicht mehr zusammen, was dazu führte, dass unsere Builds von Zeit zu Zeit fehlschlugen.
Apropos Abhängigkeiten : Eine ehrenvolle Erwähnung geht an alle npm-Probleme, wie fehlende Berechtigungen oder npm-Downdown. All dies habe ich bei der Beobachtung von CI erlebt.
Wenn es zu Fehlern in UI-Tests aufgrund von Umgebungsproblemen kommt, denken Sie daran, dass Sie den gesamten Anwendungsstapel benötigen, damit sie ausgeführt werden können. Je mehr Dinge involviert sind, desto größer ist das Fehlerpotential . JavaScript-Tests sind daher die am schwierigsten zu stabilisierenden Tests in der Webentwicklung, da sie eine große Menge an Code abdecken.
3. Produktseitige Ursachen
Zu guter Letzt müssen wir bei diesem dritten Bereich wirklich vorsichtig sein – einem Bereich mit echten Fehlern. Ich spreche von produktseitigen Ursachen für Schuppenbildung. Eines der bekanntesten Beispiele sind die Rennbedingungen in einer Anwendung. In diesem Fall muss der Fehler im Produkt behoben werden, nicht im Test! Der Versuch, den Test oder die Umgebung zu reparieren, hat in diesem Fall keinen Sinn.
Möglichkeiten zur Bekämpfung von Schuppenbildung
Wir haben drei Ursachen für Schuppenbildung identifiziert. Darauf können wir unsere Gegenstrategie aufbauen! Natürlich haben Sie bereits viel gewonnen, wenn Sie die drei Ursachen im Auge behalten, wenn Sie auf schuppige Tests stoßen. Sie wissen bereits, worauf Sie achten müssen und wie Sie die Tests verbessern können. Darüber hinaus gibt es jedoch einige Strategien, die uns beim Entwerfen, Schreiben und Debuggen von Tests helfen werden, und wir werden sie in den folgenden Abschnitten gemeinsam betrachten.
Konzentrieren Sie sich auf Ihr Team
Ihr Team ist wohl der wichtigste Faktor . Geben Sie als ersten Schritt zu, dass Sie ein Problem mit flockigen Tests haben. Das Engagement des gesamten Teams ist entscheidend! Dann müssen Sie als Team entscheiden, wie Sie mit unzuverlässigen Tests umgehen.
In den Jahren, in denen ich im Technologiebereich gearbeitet habe, bin ich auf vier Strategien gestoßen, die von Teams verwendet werden, um Schuppenbildung entgegenzuwirken:

- Tun Sie nichts und akzeptieren Sie das flockige Testergebnis.
Natürlich ist diese Strategie überhaupt keine Lösung. Der Test bringt keinen Wert, weil Sie ihm nicht mehr vertrauen können – selbst wenn Sie die Schuppenbildung akzeptieren. Also können wir diesen ziemlich schnell überspringen. - Wiederholen Sie den Test, bis er bestanden ist.
Diese Strategie war zu Beginn meiner Karriere üblich, was zu der bereits erwähnten Reaktion führte. Es gab eine gewisse Akzeptanz bei der Wiederholung von Tests, bis sie bestanden wurden. Diese Strategie erfordert kein Debuggen, ist aber faul. Zusätzlich zum Verbergen der Symptome des Problems verlangsamt es Ihre Testsuite noch mehr, was die Lösung unbrauchbar macht. Es kann jedoch einige Ausnahmen von dieser Regel geben, die ich später erläutern werde. - Löschen und vergessen Sie den Test.
Dieser ist selbsterklärend: Löschen Sie einfach den flockigen Test, damit er Ihre Testsuite nicht mehr stört. Sicher, es wird Ihnen Geld sparen, weil Sie den Test nicht mehr debuggen und reparieren müssen. Dies geht jedoch auf Kosten des Verlusts eines Teils der Testabdeckung und des Verlusts potenzieller Fehlerbehebungen. Der Test existiert aus einem bestimmten Grund! Erschießen Sie den Boten nicht, indem Sie den Test löschen. - Quarantäne und Reparatur.
Mit dieser Strategie hatte ich den größten Erfolg. In diesem Fall würden wir den Test vorübergehend überspringen und uns von der Testsuite ständig daran erinnern lassen, dass ein Test übersprungen wurde. Um sicherzustellen, dass der Fix nicht übersehen wird, würden wir ein Ticket für den nächsten Sprint planen. Bot-Erinnerungen funktionieren auch gut. Sobald das Problem, das die Flockigkeit verursacht, behoben wurde, werden wir den Test wieder integrieren (d. h. überspringen). Leider werden wir die Abdeckung vorübergehend verlieren, aber es wird mit einem Fix zurückkommen, sodass dies nicht lange dauern wird.
Diese Strategien helfen uns, mit Testproblemen auf Workflow-Ebene umzugehen, und ich bin nicht der einzige, der darauf gestoßen ist. Sam Saffron kommt in seinem Artikel zu einem ähnlichen Schluss. Aber in unserer täglichen Arbeit helfen sie uns nur begrenzt. Wie gehen wir also vor, wenn eine solche Aufgabe auf uns zukommt?
Halten Sie Tests isoliert
Halten Sie bei der Planung Ihrer Testfälle und -struktur Ihre Tests immer isoliert von anderen Tests, damit sie in einer unabhängigen oder zufälligen Reihenfolge ausgeführt werden können. Der wichtigste Schritt besteht darin , zwischen den Tests eine saubere Installation wiederherzustellen . Testen Sie außerdem nur den Workflow, den Sie testen möchten, und erstellen Sie Scheindaten nur für den Test selbst. Ein weiterer Vorteil dieser Abkürzung ist, dass sie die Testleistung verbessert . Wenn Sie diese Punkte befolgen, stehen Ihnen keine Nebeneffekte aus anderen Tests oder Datenresten im Wege.
Das folgende Beispiel stammt aus den UI-Tests einer E-Commerce-Plattform und befasst sich mit dem Login des Kunden in der Storefront des Shops. (Der Test ist in JavaScript geschrieben und verwendet das Cypress-Framework.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Der erste Schritt besteht darin, die Anwendung auf eine saubere Installation zurückzusetzen. Dies wird als erster Schritt im beforeEach Lebenszyklus-Hook ausgeführt, um sicherzustellen, dass das Zurücksetzen bei jeder Gelegenheit ausgeführt wird. Anschließend werden die Testdaten speziell für den Test erstellt – für diesen Testfall würde ein Kunde über einen benutzerdefinierten Befehl erstellt. Anschließend können wir mit dem einen Workflow beginnen, den wir testen wollen: dem Login des Kunden.
Optimieren Sie die Teststruktur weiter
Wir können einige andere kleine Änderungen vornehmen, um unsere Teststruktur stabiler zu machen. Die erste ist ganz einfach: Beginnen Sie mit kleineren Tests. Wie gesagt, je mehr man in einem Test macht, desto mehr kann schief gehen. Halten Sie die Tests so einfach wie möglich und vermeiden Sie jede Menge Logik.
Wenn es darum geht, keine Reihenfolge von Daten anzunehmen (z. B. wenn es um die Reihenfolge der Einträge in einer Liste beim UI-Testen geht), können wir einen Test so entwerfen, dass er unabhängig von jeder Reihenfolge funktioniert. Um das Beispiel des Rasters mit darin enthaltenen Informationen zurückzubringen, würden wir keine Pseudo-Selektoren oder andere CSS verwenden, die eine starke Abhängigkeit von der Reihenfolge haben. Anstelle des Selektors nth-child(3) könnten wir Text oder andere Dinge verwenden, für die die Reihenfolge keine Rolle spielt. Zum Beispiel könnten wir eine Aussage wie „Finde mir das Element mit dieser einen Textzeichenfolge in dieser Tabelle“ verwenden.
Warte ab! Testwiederholungen sind manchmal in Ordnung?
Die Wiederholung von Tests ist ein umstrittenes Thema, und das zu Recht. Ich betrachte es immer noch als Anti-Pattern, wenn der Test blind wiederholt wird, bis er erfolgreich ist. Es gibt jedoch eine wichtige Ausnahme: Wenn Sie Fehler nicht kontrollieren können, kann ein erneuter Versuch ein letzter Ausweg sein (z. B. um Fehler aus externen Abhängigkeiten auszuschließen). In diesem Fall können wir die Fehlerquelle nicht beeinflussen. Seien Sie dabei jedoch besonders vorsichtig: Werden Sie nicht blind für Flockigkeit, wenn Sie einen Test wiederholen, und verwenden Sie Benachrichtigungen , um Sie daran zu erinnern, wenn ein Test übersprungen wird.
Das folgende Beispiel habe ich in unserem CI mit GitLab verwendet. Andere Umgebungen haben möglicherweise eine andere Syntax zum Erreichen von Wiederholungsversuchen, aber dies sollte Ihnen einen Vorgeschmack geben:
test: script: rspec retry: max: 2 when: runner_system_failureIn diesem Beispiel konfigurieren wir, wie viele Wiederholungen durchgeführt werden sollen, wenn der Job fehlschlägt. Interessant ist die Möglichkeit, es erneut zu versuchen, wenn ein Fehler im Runner-System vorliegt (z. B. wenn der Jobaufbau fehlgeschlagen ist). Wir entscheiden uns dafür, unseren Job nur dann zu wiederholen, wenn etwas im Docker-Setup fehlschlägt.
Beachten Sie, dass dadurch der gesamte Job wiederholt wird, wenn er ausgelöst wird. Wenn Sie nur den fehlerhaften Test wiederholen möchten, müssen Sie in Ihrem Testframework nach einer Funktion suchen, die dies unterstützt. Unten sehen Sie ein Beispiel von Cypress, das die Wiederholung eines einzelnen Tests seit Version 5 unterstützt:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Sie können Testwiederholungen in der Konfigurationsdatei von Cypress, cypress.json , aktivieren. Dort können Sie die Wiederholungsversuche im Testrunner- und Headless-Modus definieren.
Dynamische Wartezeiten verwenden
Dieser Punkt ist für alle Arten von Tests wichtig, insbesondere aber für UI-Tests. Ich kann es nicht genug betonen: Verwenden Sie niemals feste Wartezeiten – zumindest nicht ohne einen sehr guten Grund. Wenn Sie es tun, bedenken Sie die möglichen Ergebnisse. Im besten Fall wählen Sie zu lange Wartezeiten, wodurch die Testsuite langsamer wird als nötig. Im schlimmsten Fall warten Sie nicht lange genug, sodass der Test nicht fortgesetzt wird, da die Anwendung noch nicht bereit ist, wodurch der Test fehlerhaft fehlschlägt. Meiner Erfahrung nach ist dies die häufigste Ursache für flockige Tests.
Verwenden Sie stattdessen dynamische Wartezeiten. Es gibt viele Möglichkeiten, dies zu tun, aber Cypress handhabt sie besonders gut.
Alle Cypress-Befehle besitzen eine implizite Wartemethode: Sie prüfen bereits, ob das Element, auf das der Befehl angewendet wird, für die angegebene Zeit im DOM existiert – was auf die Wiederholungsfähigkeit von Cypress hinweist. Es prüft jedoch nur die Existenz und nicht mehr. Ich empfehle daher, noch einen Schritt weiter zu gehen und auf Änderungen in der Benutzeroberfläche Ihrer Website oder Anwendung zu warten, die ein echter Benutzer auch sehen würde, z. B. Änderungen in der Benutzeroberfläche selbst oder in der Animation.
Dieses Beispiel verwendet eine explizite Wartezeit für das Element mit dem Selektor .offcanvas . Der Test würde nur fortgesetzt, wenn das Element bis zum angegebenen Timeout sichtbar ist, das Sie konfigurieren können:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Eine weitere nette Möglichkeit in Cypress für dynamisches Warten sind seine Netzwerkfunktionen. Ja, wir können auf Anfragen und die Ergebnisse ihrer Antworten warten. Diese Art des Wartens verwende ich besonders oft. Im folgenden Beispiel definieren wir die zu wartende Anfrage, verwenden einen wait -Befehl, um auf die Antwort zu warten, und bestätigen ihren Statuscode:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);Auf diese Weise können wir genau so lange warten, wie es unsere Anwendung benötigt, wodurch die Tests stabiler und weniger anfällig für Abplatzungen aufgrund von Ressourcenlecks oder anderen Umweltproblemen werden.
Fehlerhafte Tests debuggen
Wir wissen jetzt, wie man flockige Tests durch Design verhindern kann. Aber was ist, wenn Sie es bereits mit einem flockigen Test zu tun haben? Wie können Sie es loswerden?
Beim Debuggen hat es mir sehr geholfen , den fehlerhaften Test in eine Schleife zu stecken, um Flockigkeit aufzudecken. Wenn Sie beispielsweise einen Test 50 Mal ausführen und er jedes Mal bestanden wird, können Sie sicherer sein, dass der Test stabil ist – vielleicht hat Ihre Lösung funktioniert. Wenn nicht, kann man zumindest mehr Einblick in den flockigen Test bekommen.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) In CI ist es besonders schwierig, mehr Einblick in diesen schuppigen Test zu bekommen. Um Hilfe zu erhalten, prüfen Sie, ob Ihr Testframework weitere Informationen zu Ihrem Build abrufen kann. Wenn es um Frontend-Tests geht, können Sie in Ihren Tests normalerweise eine console.log verwenden:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Dieses Beispiel stammt aus einem Jest-Einheitentest, in dem ich eine console.log verwende, um die HTML-Ausgabe der getesteten Komponente zu erhalten. Wenn Sie diese Protokollierungsmöglichkeit im Testrunner von Cypress nutzen, können Sie die Ausgabe sogar in den Entwicklertools Ihrer Wahl überprüfen. Wenn es um Cypress in CI geht, können Sie diese Ausgabe außerdem mithilfe eines Plugins im Protokoll Ihres CI überprüfen.
Schauen Sie sich immer die Funktionen Ihres Testframeworks an, um Unterstützung bei der Protokollierung zu erhalten. Beim UI-Testen bieten die meisten Frameworks Screenshot-Funktionen – zumindest bei einem Fehler wird automatisch ein Screenshot erstellt. Einige Frameworks bieten sogar Videoaufzeichnungen , was eine große Hilfe sein kann, um einen Einblick in das zu bekommen, was in Ihrem Test passiert.
Bekämpfe schuppige Alpträume!
Es ist wichtig, ständig nach fehlerhaften Tests zu suchen, sei es, indem man sie von vornherein verhindert oder indem man sie debuggt und repariert, sobald sie auftreten. Wir müssen sie ernst nehmen, denn sie können auf Probleme in Ihrer Bewerbung hinweisen.
Erkennen der roten Fahnen
Am besten ist es natürlich, flockige Tests von vornherein zu verhindern. Um es kurz zusammenzufassen, hier sind einige rote Fahnen:
- Der Test ist umfangreich und enthält viel Logik.
- Der Test deckt viel Code ab (z. B. in UI-Tests).
- Der Test nutzt feste Wartezeiten.
- Der Test hängt von vorherigen Tests ab.
- Der Test behauptet Daten, die nicht zu 100 % vorhersehbar sind, wie z. B. die Verwendung von IDs, Zeiten oder Demodaten, insbesondere zufällig generierte.
Wenn Sie die Hinweise und Strategien aus diesem Artikel im Hinterkopf behalten, können Sie fehlerhafte Tests verhindern, bevor sie auftreten. Und wenn sie kommen, wissen Sie, wie Sie sie debuggen und beheben können.
Diese Schritte haben mir wirklich geholfen, das Vertrauen in unsere Testsuite zurückzugewinnen. Unsere Testsuite scheint im Moment stabil zu sein. Es könnte in Zukunft Probleme geben – nichts ist 100 % perfekt. Dieses Wissen und diese Strategien werden mir helfen, damit umzugehen. So werde ich zuversichtlicher in meine Fähigkeit, gegen diese schuppigen Prüfungsalbträume anzukämpfen .
Ich hoffe, ich konnte zumindest einige Ihrer Schmerzen und Bedenken bezüglich Schuppenbildung lindern!
Weiterführende Lektüre
Wenn Sie mehr zu diesem Thema erfahren möchten, finden Sie hier einige nützliche Ressourcen und Artikel, die mir sehr geholfen haben:
- Artikel über „Flake“, Cypress.io
- „Das Wiederholen Ihrer Tests ist eigentlich eine gute Sache (wenn Ihr Ansatz richtig ist)“, Filip Hric, Cypress.io
- „Testschuppung: Methoden zur Identifizierung und Behandlung von schuppigen Tests“, Jason Palmer, Spotify R&D Engineering
- „Unregelmäßige Tests bei Google und wie wir sie abmildern“, John Micco, Google Testing Blog