
Schnelleres Laden von Bildern mit eingebetteten Bildvorschauen
Veröffentlicht: 2022-03-10Low Quality Image Preview (LQIP) und die SVG-basierte Variante SQIP sind die beiden vorherrschenden Techniken für Lazy Image Loading. Beiden gemeinsam ist, dass Sie zunächst ein qualitativ minderwertiges Vorschaubild erzeugen. Dieses wird unscharf dargestellt und später durch das Originalbild ersetzt. Was wäre, wenn Sie dem Website-Besucher ein Vorschaubild präsentieren könnten, ohne zusätzliche Daten laden zu müssen?
JPEG-Dateien, für die meistens Lazy Loading verwendet wird, haben laut Spezifikation die Möglichkeit, die darin enthaltenen Daten so zu speichern, dass zunächst die groben und dann die detaillierten Bildinhalte angezeigt werden. Anstatt das Bild beim Laden von oben nach unten aufbauen zu lassen (Baseline-Modus), kann sehr schnell ein unscharfes Bild angezeigt werden, das nach und nach immer schärfer wird (Progressiv-Modus).


Neben der besseren Benutzererfahrung durch das schneller angezeigte Erscheinungsbild sind progressive JPEGs normalerweise auch kleiner als ihre Baseline-codierten Gegenstücke. Bei Dateien, die größer als 10 kB sind, besteht laut Stoyan Stefanov vom Yahoo-Entwicklungsteam eine 94-prozentige Wahrscheinlichkeit für ein kleineres Bild, wenn der progressive Modus verwendet wird.
Wenn Ihre Website aus vielen JPEGs besteht, werden Sie feststellen, dass sogar progressive JPEGs nacheinander geladen werden. Das liegt daran, dass moderne Browser nur sechs gleichzeitige Verbindungen zu einer Domain zulassen. Progressive JPEGs alleine sind also nicht die Lösung, um dem User einen möglichst schnellen Eindruck von der Seite zu vermitteln. Im schlimmsten Fall lädt der Browser ein Bild vollständig, bevor er mit dem Laden des nächsten beginnt.
Die hier vorgestellte Idee ist nun, nur so viele Bytes eines progressiven JPEGs vom Server zu laden, dass man sich schnell einen Eindruck vom Bildinhalt verschaffen kann. Später, zu einem von uns definierten Zeitpunkt (z. B. wenn alle Vorschaubilder im aktuellen Viewport geladen sind), soll der Rest des Bildes geladen werden, ohne den bereits angeforderten Teil erneut für die Vorschau anzufordern.

Leider kann man einem img -Tag in einem Attribut nicht mitteilen, wie viel vom Bild zu welchem Zeitpunkt geladen werden soll. Mit Ajax ist dies jedoch möglich, sofern der Server, der das Bild liefert, HTTP Range Requests unterstützt.
Mittels HTTP-Range-Requests kann ein Client dem Server in einem HTTP-Request-Header mitteilen, welche Bytes der angeforderten Datei in der HTTP-Response enthalten sein sollen. Diese Funktion, die von jedem der größeren Server (Apache, IIS, nginx) unterstützt wird, wird hauptsächlich für die Videowiedergabe verwendet. Wenn ein Benutzer zum Ende eines Videos springt, wäre es nicht sehr effizient, das vollständige Video zu laden, bevor der Benutzer endlich den gewünschten Teil sehen kann. Daher werden nur die Videodaten um die vom Benutzer gewünschte Zeit vom Server angefordert, damit der Benutzer das Video so schnell wie möglich ansehen kann.
Wir stehen nun vor den folgenden drei Herausforderungen:
- Erstellen des progressiven JPEG
- Bestimmen Sie den Byte-Offset, bis zu dem die erste HTTP-Bereichsanforderung das Vorschaubild laden muss
- Erstellen des Frontend-JavaScript-Codes
1. Erstellen des progressiven JPEG
Ein progressives JPEG besteht aus mehreren sogenannten Scan-Segmenten, die jeweils einen Teil des endgültigen Bildes enthalten. Der erste Scan zeigt das Bild nur sehr grob, während die später in der Datei folgenden Scans immer mehr Detailinformationen zu den bereits geladenen Daten hinzufügen und schließlich das endgültige Erscheinungsbild formen.
Wie genau die einzelnen Scans aussehen, bestimmt das Programm, das die JPEGs erzeugt. In Kommandozeilenprogrammen wie cjpeg aus dem mozjpeg-Projekt können Sie sogar festlegen, welche Daten diese Scans enthalten. Dies erfordert jedoch tiefergehende Kenntnisse, die den Rahmen dieses Artikels sprengen würden. Dazu verweise ich auf meinen Artikel „JPG endlich verstehen“, der die Grundlagen der JPEG-Komprimierung vermittelt. Die genauen Parameter, die dem Programm in einem Scan-Skript übergeben werden müssen, sind in der Wizard.txt des mozjpeg-Projekts erklärt. Die von mozjpeg standardmäßig verwendeten Parameter des Scanskripts (sieben Scans) sind meiner Meinung nach ein guter Kompromiss zwischen schneller progressiver Struktur und Dateigröße und können daher übernommen werden.
Um unser anfängliches JPEG in ein progressives JPEG umzuwandeln, verwenden wir jpegtran aus dem mozjpeg-Projekt. Dies ist ein Werkzeug, um verlustfreie Änderungen an einem vorhandenen JPEG vorzunehmen. Vorkompilierte Builds für Windows und Linux sind hier verfügbar: https://mozjpeg.codelove.de/binaries.html. Wer aus Sicherheitsgründen lieber auf Nummer sicher gehen möchte, baut sie lieber selbst.
Von der Kommandozeile aus erstellen wir nun unser progressives JPEG:
$ jpegtran input.jpg > progressive.jpgDass wir ein progressives JPEG bauen wollen, wird von jpegtran vorausgesetzt und muss nicht explizit angegeben werden. Die Bilddaten werden in keiner Weise verändert. Lediglich die Anordnung der Bilddaten innerhalb der Datei wird geändert.
Metadaten, die für das Erscheinungsbild des Bildes irrelevant sind (zB Exif-, IPTC- oder XMP-Daten), sollten idealerweise aus dem JPEG entfernt werden, da die entsprechenden Segmente nur dann von Metadaten-Decodern gelesen werden können, wenn sie dem Bildinhalt vorangestellt sind. Da wir sie aus diesem Grund nicht hinter die Bilddaten in der Datei verschieben können, würden sie bereits mit dem Vorschaubild ausgeliefert und vergrößern die erste Anfrage entsprechend. Mit dem Kommandozeilenprogramm exiftool können Sie diese Metadaten ganz einfach entfernen:
$ exiftool -all= progressive.jpgWer kein Kommandozeilen-Tool verwenden möchte, kann auch den Online-Kompressionsdienst compress-or-die.com verwenden, um ein progressives JPEG ohne Metadaten zu erzeugen.
2. Bestimmen Sie den Byte-Offset, bis zu dem die erste HTTP-Bereichsanforderung das Vorschaubild laden muss
Eine JPEG-Datei ist in verschiedene Segmente unterteilt, die jeweils unterschiedliche Bestandteile enthalten (Bilddaten, Metadaten wie IPTC, Exif und XMP, eingebettete Farbprofile, Quantisierungstabellen usw.). Jedes dieser Segmente beginnt mit einer Markierung, die durch ein hexadezimales FF -Byte eingeleitet wird. Darauf folgt ein Byte, das die Art des Segments angibt. Beispielsweise vervollständigt D8 den Marker zum SOI-Marker FF D8 (Start Of Image), mit dem jede JPEG-Datei beginnt.
Jeder Start eines Scans wird durch die SOS-Markierung (Start Of Scan, hexadezimal FF DA ) gekennzeichnet. Da die Daten hinter dem SOS-Marker entropiecodiert sind (JPEGs verwenden die Huffman-Codierung), wird vor dem SOS-Segment ein weiteres Segment mit den Huffman-Tabellen (DHT, hexadezimal FF C4 ) zur Dekodierung benötigt. Der für uns interessante Bereich innerhalb einer progressiven JPEG-Datei besteht daher aus abwechselnden Huffman-Tabellen/Scan-Datensegmenten. Wenn wir also den ersten sehr groben Scan eines Bildes anzeigen wollen, müssen wir alle Bytes bis zum zweiten Auftreten eines DHT-Segments (hexadezimal FF C4 ) vom Server anfordern.
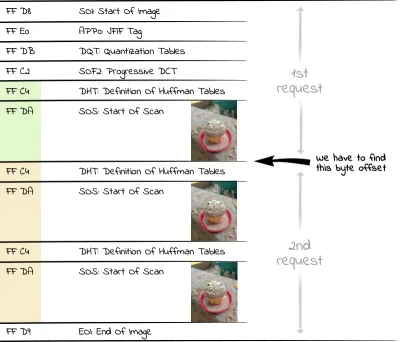
In PHP können wir den folgenden Code verwenden, um die Anzahl der für alle Scans erforderlichen Bytes in ein Array einzulesen:
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }Zur gefundenen Position müssen wir den Wert zwei addieren, da der Browser die letzte Zeile des Vorschaubildes nur rendert, wenn er auf einen neuen Marker stößt (der wie eben erwähnt aus zwei Bytes besteht).
Da uns in diesem Beispiel das erste Vorschaubild interessiert, finden wir in $positions[1] die richtige Position, bis zu der wir die Datei per HTTP Range Request anfordern müssen. Um ein Bild mit besserer Auflösung anzufordern, könnten wir eine spätere Position im Array verwenden, zB $positions[3] .

3. Erstellen des Frontend-JavaScript-Codes
Zunächst definieren wir ein img -Tag, dem wir die gerade ausgewertete Byte-Position übergeben:
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> Wie so oft bei Lazy-Load-Bibliotheken definieren wir das src -Attribut nicht direkt, damit der Browser beim Parsen des HTML-Codes nicht sofort damit beginnt, das Bild vom Server anzufordern.
Mit folgendem JavaScript-Code laden wir nun das Vorschaubild:
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); Dieser Code erstellt eine Ajax-Anforderung, die den Server in einem HTTP-Bereichsheader anweist, die Datei von Anfang an bis zu der in data-bytes angegebenen Position zurückzugeben ... und nicht mehr. Wenn der Server HTTP Range Requests versteht, liefert er die binären Bilddaten in einer HTTP-206-Antwort (HTTP 206 = Partial Content) in Form eines Blobs zurück, aus dem wir mit createObjectURL eine browserinterne URL generieren können. Wir verwenden diese URL als src für unser img -Tag. Damit haben wir unser Vorschaubild geladen.
Wir speichern den Blob zusätzlich beim DOM-Objekt in der Eigenschaft src_part , da wir diese Daten sofort benötigen.
Im Netzwerk-Tab der Entwicklerkonsole können Sie überprüfen, dass wir nicht das komplette Image geladen haben, sondern nur einen kleinen Teil. Außerdem soll das Laden der Blob-URL mit einer Größe von 0 Bytes angezeigt werden.
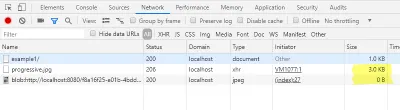
Da wir bereits den JPEG-Header der Originaldatei laden, hat das Vorschaubild die richtige Größe. Daher können wir je nach Anwendung die Höhe und Breite des img -Tags weglassen.
Alternative: Vorschaubild inline laden
Aus Performancegründen ist es auch möglich, die Daten des Vorschaubildes als Daten-URI direkt im HTML-Quellcode zu übergeben. Dadurch sparen wir uns den Aufwand für die Übertragung der HTTP-Header, aber durch die base64-Kodierung werden die Bilddaten um ein Drittel größer. Dies relativiert sich, wenn Sie den HTML-Code mit einer Inhaltskodierung wie gzip oder brotli ausliefern , für kleine Vorschaubilder sollten Sie aber trotzdem Daten-URIs verwenden.
Viel wichtiger ist, dass die Vorschaubilder sofort zur Verfügung stehen und es für den Nutzer keine spürbare Verzögerung beim Aufbau der Seite gibt.
Zunächst müssen wir die Daten-URI erstellen, die wir dann im img -Tag als src verwenden. Dazu erstellen wir die Daten-URI über PHP, wobei dieser Code auf dem gerade erstellten Code basiert, der die Byte-Offsets der SOS-Marker ermittelt:
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); Die erstellte Daten-URI wird nun direkt als src in das `img`-Tag eingefügt:
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">Natürlich muss auch der JavaScript-Code angepasst werden:
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> Anstatt die Daten per Ajax-Request anzufordern, wo wir sofort einen Blob erhalten würden, müssen wir in diesem Fall den Blob selbst aus der Daten-URI erstellen. Dazu befreien wir den Daten-URI von dem Teil, der keine Bilddaten enthält: data:image/jpeg;base64 . Die restlichen base64-kodierten Daten dekodieren wir mit dem atob Befehl. Um aus den nun binären String-Daten einen Blob zu erstellen, müssen wir die Daten in ein Uint8-Array übertragen, das dafür sorgt, dass die Daten nicht als UTF-8-codierter Text behandelt werden. Aus diesem Array können wir nun einen binären Blob mit den Bilddaten des Vorschaubildes erzeugen.
Damit wir den folgenden Code für diese Inline-Version nicht anpassen müssen, fügen wir das Attribut data-bytes am img -Tag hinzu, das im vorherigen Beispiel den Byte-Offset enthält, ab dem der zweite Teil des Bildes geladen werden muss .
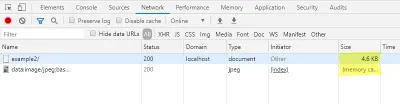
Im Netzwerk-Reiter der Entwicklerkonsole können Sie hier auch prüfen, dass das Laden des Vorschaubildes keine zusätzliche Anfrage erzeugt, während die Dateigröße der HTML-Seite zugenommen hat.
Laden des endgültigen Bildes
In einem zweiten Schritt laden wir als Beispiel den Rest der Bilddatei nach zwei Sekunden:
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); Im Header Range geben wir diesmal an, dass wir das Bild von der Endposition des Vorschaubildes bis zum Ende der Datei anfordern wollen. Die Antwort auf die erste Anfrage wird in der Eigenschaft src_part des DOM-Objekts gespeichert. Wir verwenden die Antworten beider Anfragen, um per new Blob() einen neuen Blob zu erstellen, der die Daten des gesamten Bildes enthält. Die daraus generierte Blob-URL wird wieder als src des DOM-Objekts verwendet. Jetzt ist das Bild vollständig geladen.
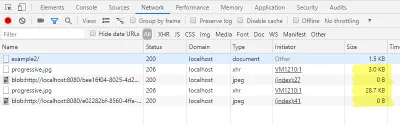
Außerdem können wir jetzt die geladenen Größen im Netzwerk-Tab der Entwicklerkonsole erneut überprüfen.
Prototyp
Unter folgender URL habe ich einen Prototyp bereitgestellt, bei dem Sie mit verschiedenen Parametern experimentieren können: https://embedded-image-preview.cerdmann.com/prototype/
Das GitHub-Repository für den Prototyp finden Sie hier: https://github.com/McSodbrenner/embedded-image-preview
Überlegungen zum Schluss
Mit der hier vorgestellten Embedded Image Preview (EIP) Technologie können wir mit Hilfe von Ajax und HTTP Range Requests qualitativ unterschiedliche Vorschaubilder aus progressiven JPEGs laden. Die Daten dieser Vorschaubilder werden nicht verworfen, sondern wiederverwendet, um das gesamte Bild anzuzeigen.
Außerdem müssen keine Vorschaubilder erstellt werden. Serverseitig muss lediglich der Byte-Offset ermittelt und gespeichert werden, bei dem das Vorschaubild endet. In einem CMS-System sollte es möglich sein, diese Nummer als Attribut zu einem Bild zu speichern und bei der Ausgabe im img -Tag zu berücksichtigen. Denkbar wäre sogar ein Workflow, der den Dateinamen des Bildes um den Offset ergänzt, zB progressive-8343.jpg , um den Offset nicht neben der Bilddatei speichern zu müssen. Dieser Offset könnte durch den JavaScript-Code extrahiert werden.
Da die Vorschaubilddaten wiederverwendet werden, könnte diese Technik eine bessere Alternative zu dem üblichen Ansatz sein, ein Vorschaubild und dann ein WebP zu laden (und einen JPEG-Fallback für nicht WebP-unterstützende Browser bereitzustellen). Das Vorschaubild macht oft die Speichervorteile des WebP zunichte, das den progressiven Modus nicht unterstützt.
Derzeit sind Vorschaubilder in normalem LQIP von minderer Qualität, da davon ausgegangen wird, dass das Laden der Vorschaudaten zusätzliche Bandbreite benötigt. Wie Robin Osborne bereits 2018 in einem Blogbeitrag klarstellte, macht es wenig Sinn, Platzhalter zu zeigen, die Ihnen keine Vorstellung vom endgültigen Bild geben. Mit der hier vorgeschlagenen Technik können wir bedenkenlos etwas mehr vom endgültigen Bild als Vorschaubild zeigen, indem wir dem Benutzer einen späteren Scan des progressiven JPEG präsentieren.
Bei einer schwachen Netzwerkverbindung des Benutzers kann es je nach Anwendung sinnvoll sein, nicht das gesamte JPEG zu laden, sondern zB die letzten beiden Scans wegzulassen. Dadurch entsteht ein viel kleineres JPEG mit nur leicht reduzierter Qualität. Der User wird es uns danken und wir müssen keine zusätzliche Datei auf dem Server hinterlegen.
Nun wünsche ich Ihnen viel Spaß beim Ausprobieren des Prototypen und freue mich auf Ihre Kommentare.