
Erkennung gefälschter Nachrichten beim maschinellen Lernen [Erklärt mit Codierungsbeispiel]
Veröffentlicht: 2021-02-08Fake News sind eines der größten Probleme im aktuellen Zeitalter des Internets und der sozialen Medien. Während es ein Segen ist, dass die Nachrichten innerhalb weniger Stunden von einem Ende der Welt zum anderen fließen, ist es auch schmerzhaft zu sehen, wie viele Menschen und Gruppen gefälschte Nachrichten verbreiten.
Techniken des maschinellen Lernens, die die Verarbeitung natürlicher Sprache und Deep Learning verwenden, können verwendet werden, um dieses Problem bis zu einem gewissen Grad anzugehen. Wir werden in diesem Tutorial ein Modell zur Erkennung gefälschter Nachrichten mithilfe von maschinellem Lernen erstellen.
Am Ende dieses Artikels werden Sie Folgendes wissen:
- Umgang mit Textdaten
- NLP-Verarbeitungstechniken
- Zählvektorisierung & TF-IDF
- Vorhersagen treffen und Nachrichtentext klassifizieren
Nehmen Sie online an den KI- und ML - Kursen der weltbesten Universitäten teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & KI, um Ihre Karriere zu beschleunigen.
Inhaltsverzeichnis
Daten & Problem
Wir werden die Challenge-Daten von Kaggle Fake News verwenden, um einen Klassifikator zu erstellen. Der Datensatz besteht aus 4 Merkmalen und 1 binären Ziel. Die 4 Funktionen sind wie folgt:
- id : eindeutige ID für einen Nachrichtenartikel
- title : Der Titel eines Nachrichtenartikels
- Autor : Autor des Nachrichtenartikels
- text : der Text des Artikels; könnte unvollständig sein
Und das Ziel ist „Label“, das die Binärwerte 0 und 1 enthält. Wobei 0 bedeutet, dass es sich um eine zuverlässige Nachrichtenquelle handelt, oder mit anderen Worten, keine Fälschung. 1 bedeutet, dass es sich um eine potenziell gefälschte Nachricht handelt und nicht zuverlässig ist. Der Datensatz, den wir haben, bestand aus 20800 Instanzen. Lassen Sie uns gleich eintauchen.

Datenvorverarbeitung und -bereinigung
| pandas als pd importieren df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
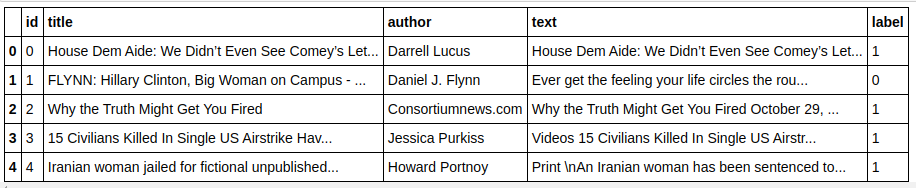
| X=df.drop( 'label' ,axis= 1 ) # Funktionen y=df[ 'label' ] # Ziel |
Wir müssen jetzt Instanzen mit fehlenden Daten löschen.
| df=df.dropna() |
![]()
Wie wir sehen können, wurden alle Instanzen mit fehlenden Daten gelöscht.
| Nachrichten=df.copy() messages.reset_index(inplace= True ) Nachrichten.Kopf ( 10 ) |
Schauen wir uns die Daten einmal an.
| Nachrichten['Text'][6] |

Wie wir sehen können, müssen die folgenden Schritte ausgeführt werden:
- Entfernen von Stoppwörtern: Es gibt viele Wörter, die keinem Text einen Mehrwert verleihen, unabhängig von den Daten. Zum Beispiel „ich“, „ein“, „bin“ usw. Diese Wörter haben keinen Informationswert und können daher entfernt werden, um die Größe unseres Korpus zu reduzieren, sodass wir uns nur auf Wörter/Token konzentrieren können, die einen tatsächlichen Wert haben .
- Wortstämme : Wortstämme und Lemmatisierung sind die Techniken, um die Wörter auf ihre Stämme oder Wurzeln zu reduzieren. Der Hauptvorteil dieses Schritts besteht darin, die Größe des Vokabulars zu reduzieren. Beispielsweise werden Wörter wie Play, Playing, Played auf „Play“ reduziert. Stemming kürzt die Wörter nur auf das kürzeste Wort und berücksichtigt nicht den grammatikalischen Aspekt des Textes. Die Lemmatisierung hingegen berücksichtigt auch die Grammatik und liefert daher viel bessere Ergebnisse. Die Lemmatisierung ist jedoch normalerweise langsamer als die Stammbildung, da sie sich auf das Wörterbuch beziehen und den grammatikalischen Aspekt berücksichtigen muss.
- Alles außer alphabetischen Werten entfernen: Nicht-alphabetische Werte sind hier nicht sehr nützlich, daher können sie entfernt werden. Sie können jedoch weiter untersuchen, ob das Vorhandensein numerischer oder anderer Datentypen Auswirkungen auf das Ziel hat.
- Wörter klein schreiben: Wörter klein schreiben, um den Wortschatz zu reduzieren.
- Tokenisieren Sie die Sätze: Generieren von Tokens aus Sätzen.
| aus sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer aus nltk.corpus import stopwords aus nltk.stem.porter import PorterStemmer importieren re ps = PorterStemmer() corpus = [] für i in range(0, len(messages)): review = re.sub('[^a-zA-Z]', ' ', messages['text'][i]) review = review.lower() review = review.split() review = [ps.stem(word) for word in review if not word in stopwords.words('english')] review = ' '.join(review) corpus.append (Überprüfung) |
Werfen wir nun einen Blick auf unseren Korpus.
| Korpus[ 3 ] |
![]()
Wie wir sehen können, werden die Wörter jetzt zu Wurzelwörtern gekürzt.
TF-IDF-Vektorisierer
Jetzt müssen wir die Wörter in numerische Daten vektorisieren, was auch als Vektorisierung bezeichnet wird. Der einfachste Weg zum Vektorisieren ist die Verwendung des Bag of Words. Bag of Words erstellt jedoch eine spärliche Matrix und daher wird viel Verarbeitungsspeicher benötigt. Darüber hinaus berücksichtigt BoW nicht die Häufigkeit von Wörtern, was es zu einem schlechten Algorithmus macht.
TF-IDF (Term Frequency – Inverse Document Frequency) ist eine weitere Möglichkeit, Wörter zu vektorisieren, die Worthäufigkeiten berücksichtigt. Beispielsweise sind gängige Wörter wie „wir“, „unser“, „der“ in jedem Dokument/jeder Instanz enthalten, daher ist der BoW-Wert zu hoch und daher irreführend. Dies führt zu einem schlechten Modell. TF-IDF ist die Multiplikation von Term Frequency und Inverse Document Frequency.
Term Frequency berücksichtigt die Häufigkeit von Wörtern in einem Dokument und Inverse Document Frequency berücksichtigt die Wörter, die im gesamten Korpus vorhanden sind. Die Wörter, die im gesamten Korpus vorhanden sind, haben eine geringere Bedeutung, da der IDF-Wert viel niedriger ist. Die Wörter, die speziell in einem Dokument vorhanden sind, haben einen hohen IDF-Wert, was den Gesamt-TF-IDF-Wert hoch macht.
| ## TFi df Vektorisierer aus sklearn.feature_extraction.text import TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
Im obigen Code importieren wir den TF-IDF-Vektorisierer aus dem Merkmalsextraktionsmodul von Sklearn. Wir erstellen sein Objekt, indem wir max_features als 5000 und ngram_range als (1,3) übergeben. Der Parameter max_features definiert die maximale Anzahl von Feature-Vektoren, die wir erstellen möchten, und der Parameter ngram_range definiert die ngram-Kombinationen, die wir einbeziehen möchten. In unserem Fall erhalten wir 3 Kombinationen aus 1 Wort, 2 Wörtern und 3 Wörtern. Werfen wir einen Blick auf einige der erstellten Funktionen.

| tfidf_v.get_feature_names()[: 20 ] |

Wie wir sehen können, werden mehrere Arten von Kombinationen gebildet. Es gibt Feature-Namen mit 1 Token, 2 Token und auch mit 3 Token.
Erstellen eines Datenrahmens
| ## Unterteilen Sie den Datensatz in Trainieren und Testen aus sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, column=tfidf_v.get_feature_names()) count_df.head() |
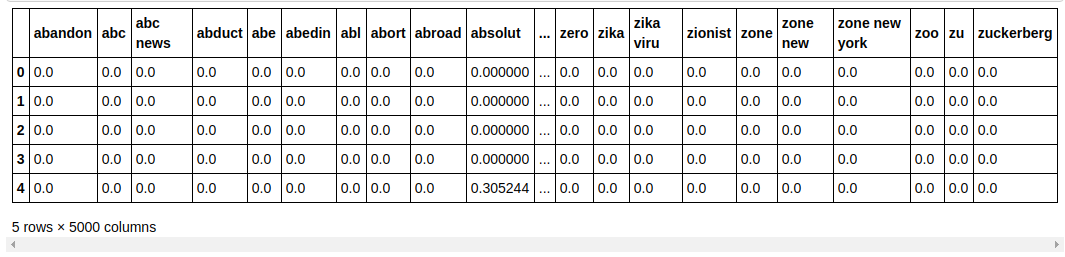
Wir teilen den Datensatz in Trainieren und Testen auf, damit wir die Leistung des Modells mit unsichtbaren Daten testen können. Wir erstellen dann einen neuen Datenrahmen, der die neuen Merkmalsvektoren enthält.
Modellierung & Tuning
MultinomialNB-Algorithmus
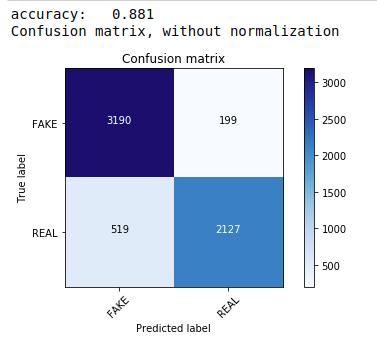
Zuerst verwenden wir das Multinomial Naive Bayes Theorem, das der gebräuchlichste und einfachste Algorithmus ist, der für die Textdatenklassifizierung bevorzugt wird. Wir passen die Trainingsdaten an und sagen die Testdaten voraus. Später berechnen und zeichnen wir die Konfusionsmatrix und erhalten eine Genauigkeit von 88,1%.
| aus sklearn.naive_bayes import MultinomialNB aus sklearn - Importmetriken importiere numpy als np itertools importieren aus sklearn.metrics import plot_confusion_matrix classifier=MultinomialNB() classifier.fit(X_Zug, y_Zug) pred = classifier.predict(X_test) score = metrics.accuracy_score(y_test, pred) print( „Genauigkeit: %0.3f“ % Punktzahl) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, klassen=[ 'FAKE' , 'REAL' ]) |
Multinomialer Klassifikator mit Hyperparameter-Tuning
MultinomialNB hat einen Parameter Alpha, der weiter abgestimmt werden kann. Daher führen wir eine Schleife durch, um mehrere MultinomialNB-Klassifikatoren mit unterschiedlichen Alpha-Werten auszuprobieren und ihre Genauigkeitswerte zu überprüfen. Und wir prüfen, ob die aktuelle Punktzahl höher ist als die vorherige Punktzahl. Wenn dies der Fall ist, setzen wir den Klassifikator auf den aktuellen.
| vorheriger_score = 0 für alpha in np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(alpha=alpha) sub_classifier.fit(X_Zug,y_Zug) y_pred=sub_classifier.predict(X_test) score = metrics.accuracy_score(y_test, y_pred) wenn Punktzahl>vorherige_Punktzahl: classifier=sub_classifier print( „Alpha: {}, Ergebnis: {}“ .format(alpha,Ergebnis)) |
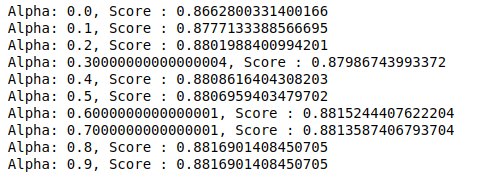
Daher können wir sehen, dass ein Alpha-Wert von 0,9 oder 0,8 die höchste Genauigkeitsbewertung ergab.
Interpretieren der Ergebnisse
Sehen wir uns nun an, was diese Klassifikatorkoeffizientenwerte bedeuten. Wir speichern zuerst alle Merkmalsnamen in einer anderen Variablen.
| ## Funktionsnamen abrufen _ feature_names = cv.get_feature_names() |
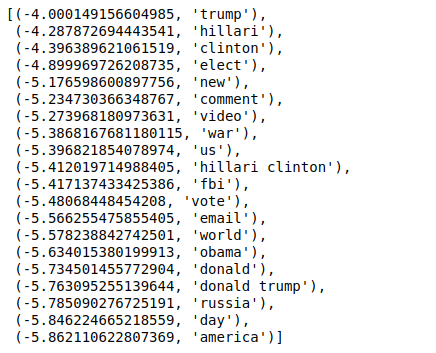
Wenn wir nun die Werte in umgekehrter Reihenfolge sortieren, erhalten wir Werte mit einem Mindestwert von -4. Diese bezeichnen die Wörter, die am realsten oder am wenigsten falsch sind.
| ### Am realsten sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
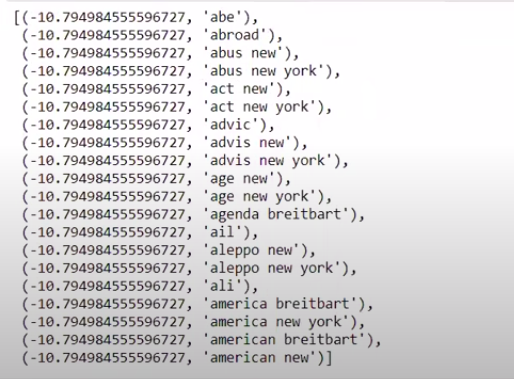
Wenn wir die Werte in nicht umgekehrter Reihenfolge sortieren, erhalten wir Werte mit einem Mindestwert von -10. Diese bezeichnen die Wörter, die am wenigsten echt oder am meisten falsch sind.
| ### Am realsten sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Fazit
In diesem Tutorial haben wir nur ML-Algorithmen verwendet, aber Sie verwenden auch andere neuronale Netzwerkmethoden. Um die Textdaten zu vektorisieren, haben wir außerdem den TF-IDF-Vektorisierer verwendet. Es gibt auch mehr Vektorisierer wie Count Vectorizer, Hashing Vectorizer usw., die die Arbeit besser erledigen können. Probieren und experimentieren Sie mit anderen Algorithmen und Techniken, um zu sehen, ob Sie bessere Ergebnisse erzielen können oder nicht.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das Executive PG-Programm von IIIT-B & upGrad für maschinelles Lernen und KI an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT, bietet -B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Warum müssen Fake News erkannt werden?
In ihrem derzeitigen Zustand sind Social-Media-Plattformen sehr leistungsfähig und wertvoll, da sie es den Benutzern ermöglichen, Ideen zu diskutieren und auszutauschen sowie Themen wie Demokratie, Bildung und Gesundheit zu diskutieren. Bestimmte Unternehmen nutzen solche Plattformen jedoch schlecht, um unter bestimmten Umständen Geld zu verdienen und um bei anderen voreingenommene Standpunkte zu vertreten, Denkweisen zu ändern und Satire oder Lächerlichkeit zu verbreiten. Fake News ist der Fachbegriff für dieses Phänomen. Die Verbreitung von Online-Postings, die nicht der Realität entsprechen, hat zu einer Reihe von Problemen in Politik, Sport, Gesundheit, Wissenschaft und anderen Bereichen geführt.
Welche Unternehmen nutzen die Fake-News-Erkennung hauptsächlich?
Die Erkennung gefälschter Nachrichten wird auf Plattformen wie sozialen Medien und Nachrichtenwebsites verwendet. Social-Media-Giganten wie Facebook, Instagram und Twitter sind anfällig für Fake News, da sich die Mehrheit ihrer Nutzer auf sie als tägliche Nachrichtenquellen verlassen, um die aktuellsten Informationen zu erhalten. Gefälschte Erkennungstechniken werden auch von Medienunternehmen verwendet, um die Authentizität der ihnen vorliegenden Informationen zu bestimmen. E-Mail ist ein weiteres Medium, über das Einzelpersonen Nachrichten erhalten können, was es schwierig macht, ihre Wahrhaftigkeit zu identifizieren und zu überprüfen. Hoaxes, Spam und Junk-Mail sind dafür bekannt, dass sie per E-Mail übertragen werden. Infolgedessen verwenden die meisten E-Mail-Plattformen die Erkennung falscher Nachrichten, um Spam und Junk-Mail zu identifizieren.