
Explorative Datenanalyse in Python: Was Sie wissen müssen
Veröffentlicht: 2021-03-12Explorative Datenanalyse (EDA) ist eine sehr verbreitete und wichtige Praxis, die von allen Datenwissenschaftlern befolgt wird. Es ist der Prozess, Tabellen und Datentabellen aus verschiedenen Blickwinkeln zu betrachten, um sie vollständig zu verstehen. Ein gutes Verständnis der Daten hilft uns, sie zu bereinigen und zusammenzufassen, was dann die sonst unklaren Erkenntnisse und Trends hervorbringt.
EDA hat kein hartes Regelwerk, das befolgt werden muss, wie beispielsweise in der „Datenanalyse“. Menschen, die neu auf dem Gebiet sind, neigen immer dazu, zwischen den beiden Begriffen zu verwechseln, die meist ähnlich, aber unterschiedlich in ihrem Zweck sind. Im Gegensatz zu EDA tendiert die Datenanalyse eher zur Implementierung von Wahrscheinlichkeiten und statistischen Methoden, um Fakten und Beziehungen zwischen verschiedenen Varianten aufzudecken.
Zurückkommend, es gibt keinen richtigen oder falschen Weg, um EDA durchzuführen. Es ist von Person zu Person unterschiedlich, es gibt jedoch einige wichtige Richtlinien, die allgemein befolgt werden und die unten aufgeführt sind.
- Umgang mit fehlenden Werten: Nullwerte können angezeigt werden, wenn möglicherweise nicht alle Daten verfügbar waren oder während der Erfassung aufgezeichnet wurden.
- Entfernen doppelter Daten: Es ist wichtig, eine Überanpassung oder Verzerrung zu verhindern, die während des Trainings des maschinellen Lernalgorithmus mit wiederholten Datensätzen entsteht
- Umgang mit Ausreißern: Ausreißer sind Datensätze, die sich drastisch von den restlichen Daten unterscheiden und nicht dem Trend folgen. Dies kann aufgrund bestimmter Ausnahmen oder Ungenauigkeiten während der Datenerfassung auftreten
- Skalierung und Normalisierung: Dies wird nur für numerische Datenvariablen durchgeführt. Meistens unterscheiden sich die Variablen stark in ihrer Reichweite und Skala, was es schwierig macht, sie zu vergleichen und Korrelationen zu finden.
- Univariate und bivariate Analyse: Die univariate Analyse wird normalerweise durchgeführt, indem man sieht, wie eine Variable die Zielvariable beeinflusst. Die bivariate Analyse wird zwischen 2 beliebigen Variablen durchgeführt, sie kann entweder numerisch oder kategorial oder beides sein.
Wir werden uns ansehen, wie einige davon implementiert werden, indem wir einen sehr berühmten „Home Credit Default Risk“-Datensatz verwenden , der hier auf Kaggle verfügbar ist . Die Daten enthalten Informationen über den Kreditbewerber zum Zeitpunkt der Kreditbeantragung. Es enthält zwei Arten von Szenarien:
- Der Kunde mit Zahlungsschwierigkeiten : er/sie hatte mehr als X Tage Zahlungsverzug
auf mindestens eine der ersten Y-Raten des Darlehens in unserer Stichprobe,
- Alle anderen Fälle : Alle anderen Fälle, in denen die Zahlung fristgerecht erfolgt.
Wir werden für diesen Artikel nur an den Anwendungsdatendateien arbeiten.
Verwandte: Ideen und Themen für Python-Projekte für Anfänger
Inhaltsverzeichnis
Blick auf die Daten
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
Nachdem wir die Anwendungsdaten gelesen haben, verwenden wir die Funktion info(), um uns einen kurzen Überblick über die Daten zu verschaffen, mit denen wir es zu tun haben. Die folgende Ausgabe informiert uns darüber, dass wir etwa 300000 Kreditdatensätze mit 122 Variablen haben. Davon gibt es 16 kategoriale Variablen und der Rest ist numerisch.
<Klasse 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 Einträge, 0 bis 307510
Spalten: 122 Einträge, SK_ID_CURR bis AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: Float64(65), int64(41), Objekt(16)
Speicherverbrauch: 286,2+ MB
Es ist immer eine gute Praxis, numerische und kategoriale Daten separat zu behandeln und zu analysieren.
kategorial = app_data.select_dtypes(include = object).columns
app_data[categorical].apply(pd.Series.nunique, Achse = 0)
Wenn wir uns nur die kategorialen Merkmale unten ansehen, sehen wir, dass die meisten von ihnen nur wenige Kategorien haben, was die Analyse mit einfachen Diagrammen erleichtert.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
BERUF_TYP 18
WEEKDAY_APPR_PROCESS_START 7
ORGANISATIONSTYP 58
FONDKAPREMONT_MODE 4
HAUSTYP_MODUS 3
WANDMATERIAL_MODUS 7
NOTZUSTAND_MODUS 2
dtyp: int64
Nun zu den numerischen Merkmalen: Die Methode describe() gibt uns die Statistik unserer Daten:
numer= app_data.describe()
Numerisch= Zahl.Spalten
Zahl
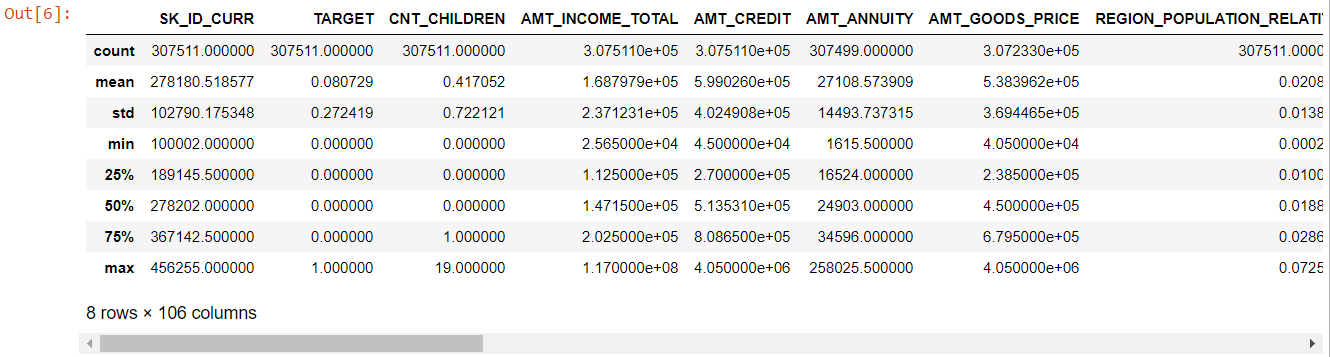
Wenn man sich die gesamte Tabelle ansieht, wird deutlich:
- days_birth ist negativ: Alter des Antragstellers (in Tagen) relativ zum Tag der Antragstellung
- tage_beschäftigt hat Ausreißer (Maximalwert liegt bei etwa 100 Jahren) (635243)
- amt_annuity- bedeuten viel kleiner als der maximale Wert
Jetzt wissen wir also, welche Merkmale weiter analysiert werden müssen.
Fehlende Daten
Wir können ein Punktdiagramm aller Merkmale mit fehlenden Werten erstellen, indem wir den Prozentsatz der fehlenden Daten entlang der Y-Achse zeichnen.
fehlt = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = missing)

plt.xticks (Rotation = 90, Schriftgröße = 7)
plt.title("Prozentsatz fehlender Werte")
plt.ylabel("PERCENTAGE")
plt.show()
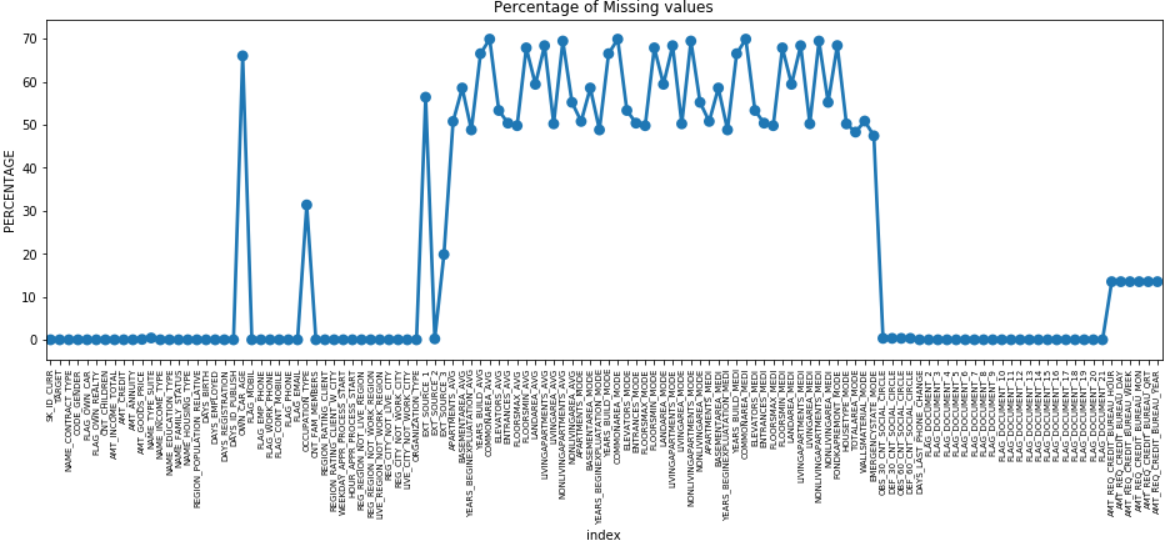
Viele Spalten haben viele fehlende Daten (30-70 %), einige haben wenige fehlende Daten (13-19 %) und viele Spalten haben auch überhaupt keine fehlenden Daten. Es ist nicht wirklich notwendig, den Datensatz zu ändern, wenn Sie nur EDA durchführen müssen. Wenn wir jedoch mit der Datenvorverarbeitung fortfahren, sollten wir wissen, wie wir mit fehlenden Werten umgehen.
Für Merkmale mit weniger fehlenden Werten können wir je nach Merkmal die Regression verwenden, um die fehlenden Werte vorherzusagen oder mit dem Mittelwert der vorhandenen Werte zu füllen. Und für Merkmale mit einer sehr hohen Anzahl fehlender Werte ist es besser, diese Spalten zu löschen, da sie sehr wenig Einblick in die Analyse geben.
Datenungleichgewicht
In diesem Datensatz werden Kreditausfälle anhand der binären Variable „TARGET“ identifiziert.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Name: ZIEL, dtype: float64
Wir sehen, dass die Daten mit einem Verhältnis von 92:8 stark unausgeglichen sind. Die meisten Kredite wurden pünktlich zurückgezahlt (Soll = 0). Wann immer also ein so großes Ungleichgewicht besteht, ist es besser, Merkmale zu nehmen und sie mit der Zielvariablen zu vergleichen (gezielte Analyse), um festzustellen, welche Kategorien in diesen Merkmalen dazu neigen, die Kredite häufiger als andere auszufallen.
Unten sind nur einige Beispiele für Diagramme, die mit der Seaborn -Bibliothek von Python und einfachen benutzerdefinierten Funktionen erstellt werden können.
Geschlecht
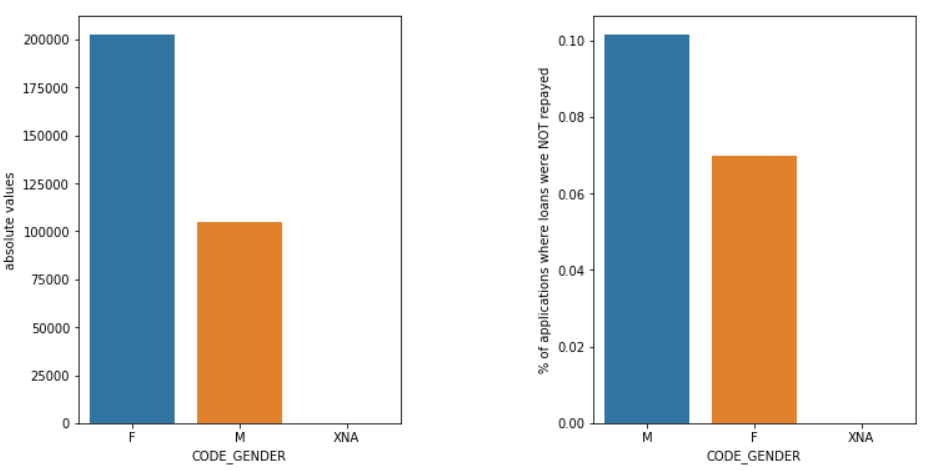
Männer (M) haben im Vergleich zu Frauen (F) ein höheres Ausfallrisiko, obwohl die Zahl der weiblichen Bewerber fast doppelt so hoch ist. Frauen sind also zuverlässiger als Männer, wenn es darum geht, ihre Kredite zurückzuzahlen.
Bildungstyp
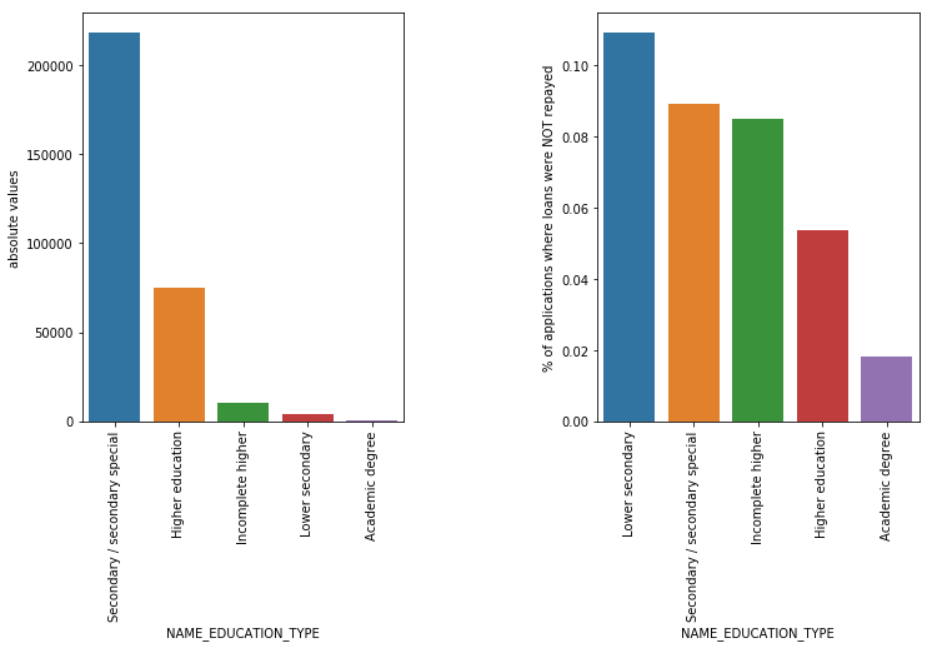
Obwohl die meisten Studentendarlehen für die Sekundar- oder Hochschulbildung bestimmt sind, sind es die Darlehen für die Sekundarstufe I, die für das Unternehmen am riskantesten sind, gefolgt von der Sekundarstufe.
Lesen Sie auch: Karriere in der Datenwissenschaft
Fazit
Eine solche Art von Analyse, wie oben gezeigt, wird in großem Umfang in der Risikoanalyse im Bank- und Finanzdienstleistungsbereich durchgeführt. Auf diese Weise können Datenarchive verwendet werden, um das Risiko zu minimieren, bei der Kreditvergabe an Kunden Geld zu verlieren. Der Anwendungsbereich von EDA in allen anderen Sektoren ist endlos und sollte umfassend genutzt werden.
Wenn Sie neugierig sind, mehr über Data Science zu erfahren, schauen Sie sich das Executive PG in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1- on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Die explorative Datenanalyse gilt als Anfangsstufe, wenn Sie mit der Modellierung Ihrer Daten beginnen. Dies ist eine ziemlich aufschlussreiche Technik, um die Best Practices für die Modellierung Ihrer Daten zu analysieren. Sie können visuelle Diagramme, Grafiken und Berichte aus den Daten extrahieren, um sie vollständig zu verstehen. Ausreißer beziehen sich auf die Anomalien oder geringfügigen Abweichungen in Ihren Daten. Es kann während der Datenerfassung passieren. Es gibt 4 Möglichkeiten, wie wir einen Ausreißer im Datensatz erkennen können. Diese Methoden sind wie folgt: Im Gegensatz zur Datenanalyse gibt es für EDA keine festen Regeln und Vorschriften, die befolgt werden müssen. Man kann nicht sagen, dass dies die richtige oder die falsche Methode ist, um EDA durchzuführen. Anfänger werden oft missverstanden und zwischen EDA und Datenanalyse verwechselt.Warum wird eine explorative Datenanalyse (EDA) benötigt?
Die EDA umfasst bestimmte Schritte zur vollständigen Analyse der Daten, einschließlich der Ableitung der statistischen Ergebnisse, der Suche nach fehlenden Datenwerten, der Behandlung fehlerhafter Dateneingaben und schließlich der Ableitung verschiedener Diagramme und Grafiken.
Das Hauptziel dieser Analyse besteht darin, sicherzustellen, dass der von Ihnen verwendete Datensatz geeignet ist, um mit der Anwendung von Modellierungsalgorithmen zu beginnen. Aus diesem Grund ist dies der erste Schritt, den Sie mit Ihren Daten durchführen sollten, bevor Sie zur Modellierungsphase übergehen. Was sind Ausreißer und wie geht man damit um?
1. Boxplot – Boxplot ist eine Methode zur Erkennung eines Ausreißers, bei der wir die Daten nach ihren Quartilen trennen.
2. Streudiagramm – Ein Streudiagramm zeigt die Daten von 2 Variablen in Form einer Sammlung von Punkten an, die auf der kartesischen Ebene markiert sind. Der Wert einer Variablen repräsentiert die horizontale Achse (x-Achse) und der Wert der anderen Variablen repräsentiert die vertikale Achse (y-Achse).
3. Z-Score - Bei der Berechnung des Z-Scores suchen wir nach Punkten, die weit vom Zentrum entfernt sind und betrachten sie als Ausreißer.
4. InterQuartile Range (IQR) – Der InterQuartile Range oder IQR ist die Differenz zwischen dem oberen und unteren Quartil oder dem 75. und 25. Quartil, oft als statistische Streuung bezeichnet. Was sind die Richtlinien zur Durchführung von EDA?
Es gibt jedoch einige Richtlinien, die allgemein praktiziert werden:
1. Umgang mit fehlenden Werten
2. Entfernen doppelter Daten
3. Umgang mit Ausreißern
4. Skalierung und Normalisierung
5. Univariate und bivariate Analyse