
Was ist explorative Datenanalyse in Python? Von Grund auf lernen
Veröffentlicht: 2021-03-04Exploratory Data Analysis oder kurz EDA macht fast 70 % des Data-Science-Projekts aus. EDA ist der Prozess der Untersuchung der Daten mithilfe verschiedener Analysetools, um die Schlussfolgerungsstatistiken aus den Daten zu erhalten. Diese Erkundungen werden entweder durch das Betrachten einfacher Zahlen oder durch das Zeichnen von Diagrammen und Diagrammen verschiedener Typen durchgeführt.
Jede Grafik oder jedes Diagramm zeigt eine andere Geschichte und einen Blickwinkel auf dieselben Daten. Für den größten Teil der Datenanalyse und -bereinigung ist Pandas das am häufigsten verwendete Tool. Für die Visualisierungen und das Plotten von Grafiken/Charts werden Plotbibliotheken wie Matplotlib, Seaborn und Plotly verwendet.
EDA ist unbedingt erforderlich, da es Ihnen die Daten bekannt gibt. Ein Data Scientist, der eine sehr gute EDA macht, weiß viel über die Daten und daher wird das Modell, das er erstellt, automatisch besser sein als der Data Scientist, der keine gute EDA macht.
Am Ende dieses Tutorials werden Sie Folgendes wissen:
- Überprüfung der Grundübersicht der Daten
- Überprüfung der deskriptiven Statistik der Daten
- Bearbeiten von Spaltennamen und Datentypen
- Umgang mit fehlenden Werten und doppelten Zeilen
- Bivariate Analyse
Inhaltsverzeichnis
Grundlegende Übersicht der Daten
Für dieses Tutorial verwenden wir den Cars -Datensatz, der von Kaggle heruntergeladen werden kann. Der erste Schritt für fast jeden Datensatz besteht darin, ihn zu importieren und seine grundlegende Übersicht zu überprüfen – seine Form, Spalten, Spaltentypen, obersten 5 Zeilen usw. Dieser Schritt gibt Ihnen einen schnellen Überblick über die Daten, mit denen Sie arbeiten werden. Mal sehen, wie man das in Python macht.
| # Importieren der erforderlichen Bibliotheken pandas als pd importieren importiere numpy als np Seaborn als sns #Visualisierung importieren importiere matplotlib.pyplot als plt #visualisierung %matplotlib inline sns.set (Farbcodes = True ) |
Daten Head & Tail
| Daten = pd.read_csv( „Pfad/Datensatz.csv“ ) # Überprüfen Sie die obersten 5 Zeilen des Datenrahmens data.head() |
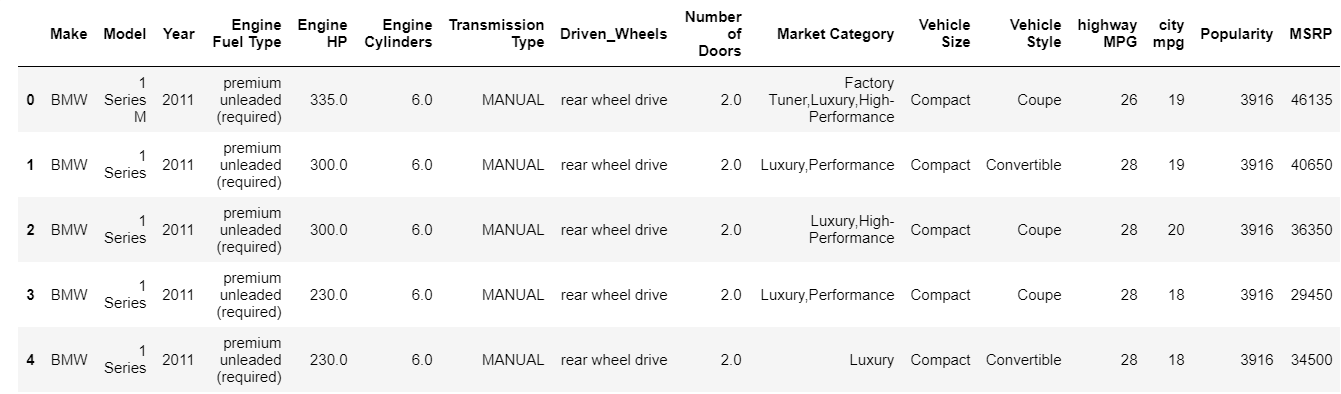
Die Head-Funktion druckt standardmäßig die obersten 5 Indizes des Datenrahmens. Sie können auch angeben, wie viele Top-Indizes Sie sehen müssen, indem Sie diesen Wert an den Kopf übergeben. Das Drucken des Kopfes gibt uns sofort einen schnellen Überblick darüber, welche Art von Daten wir haben, welche Art von Merkmalen vorhanden sind und welche Werte sie enthalten. Natürlich erzählt dies nicht die ganze Geschichte über die Daten, aber es gibt Ihnen einen kurzen Einblick in die Daten. Sie können auf ähnliche Weise den unteren Teil des Datenrahmens drucken, indem Sie die Tail-Funktion verwenden.
| # Drucken Sie die letzten 10 Zeilen des Datenrahmens data.tail( 10 ) |
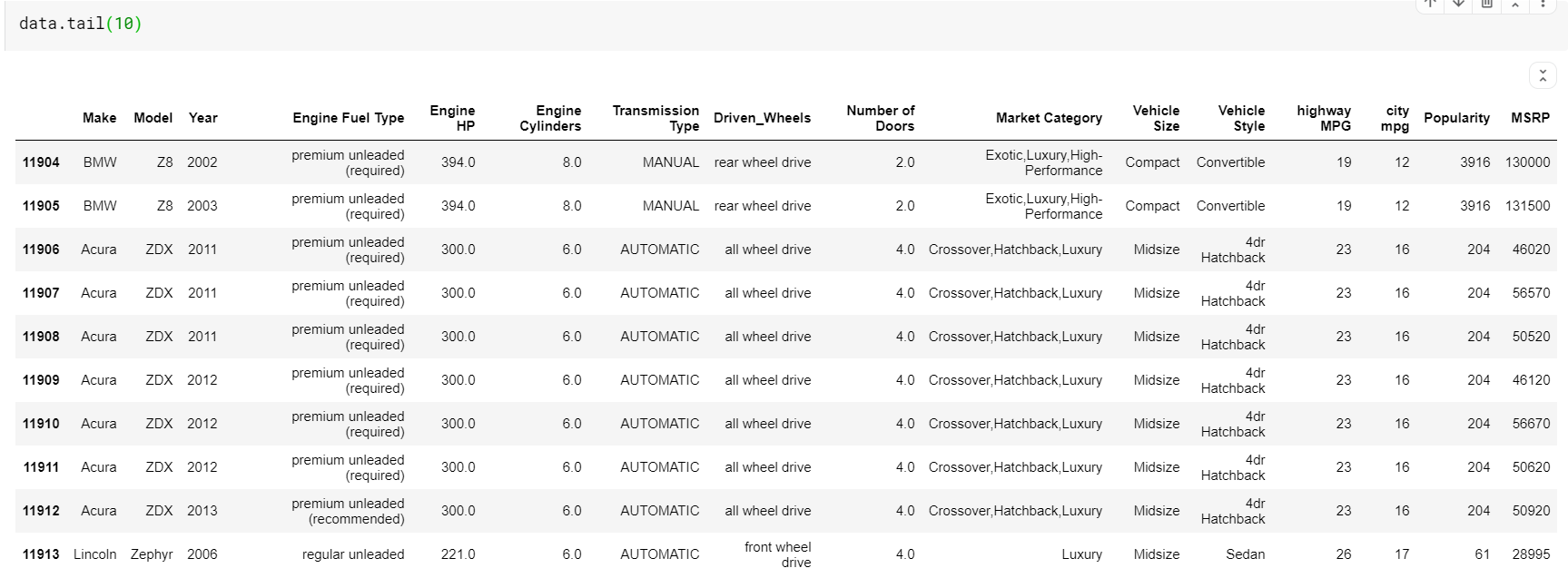
Eine Sache, die hier zu beachten ist, ist, dass sowohl die Funktionen head als auch tail uns die oberen oder unteren Indizes liefern. Aber die oberen oder unteren Zeilen sind nicht immer eine gute Vorschau auf die Daten. Sie können also auch eine beliebige Anzahl von zufällig aus dem Datensatz gezogenen Zeilen mit der Funktion sample() drucken.
| # 5 zufällige Zeilen drucken data.sample( 5 ) |
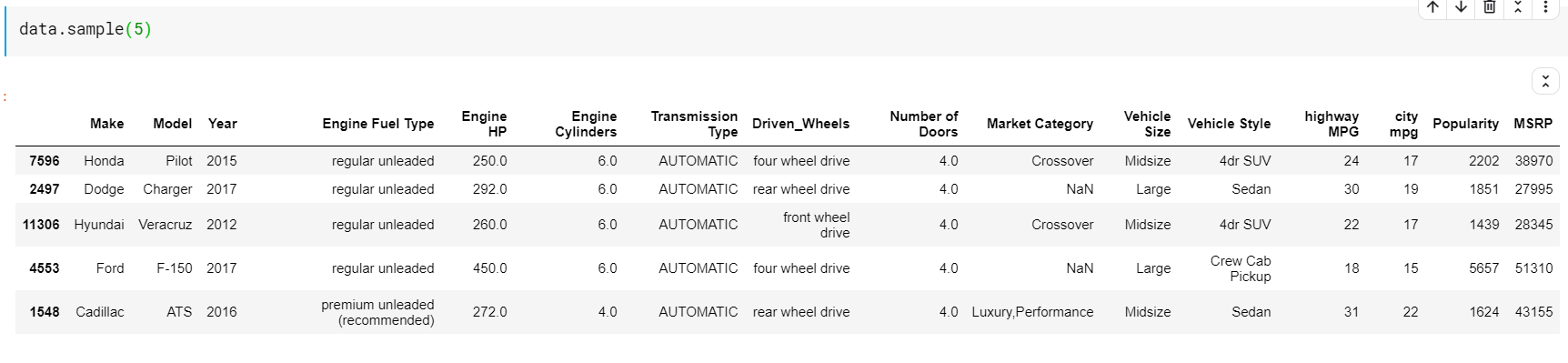
Beschreibende Statistik
Sehen wir uns als Nächstes die deskriptiven Statistiken des Datensatzes an. Beschreibende Statistiken bestehen aus allem, was den Datensatz „beschreibt“. Wir prüfen die Form des Datenrahmens, welche Spalten vorhanden sind, welche numerischen und kategorialen Merkmale vorhanden sind. Wir werden auch sehen, wie man all dies in einfachen Funktionen macht.
Form
| # Überprüfen der Form des Datenrahmens (mxn) # m=Anzahl der Zeilen # n=Anzahl der Spalten data.shape |

Wie wir sehen, enthält dieser Datenrahmen 11914 Zeilen und 16 Spalten.
Säulen
| # Drucken Sie die Spaltennamen Daten.Spalten |
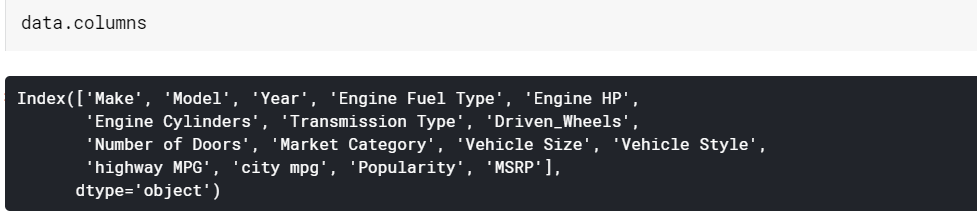
Dataframe-Informationen
| # Gibt die Spaltendatentypen und die Anzahl der nicht fehlenden Werte aus data.info() |
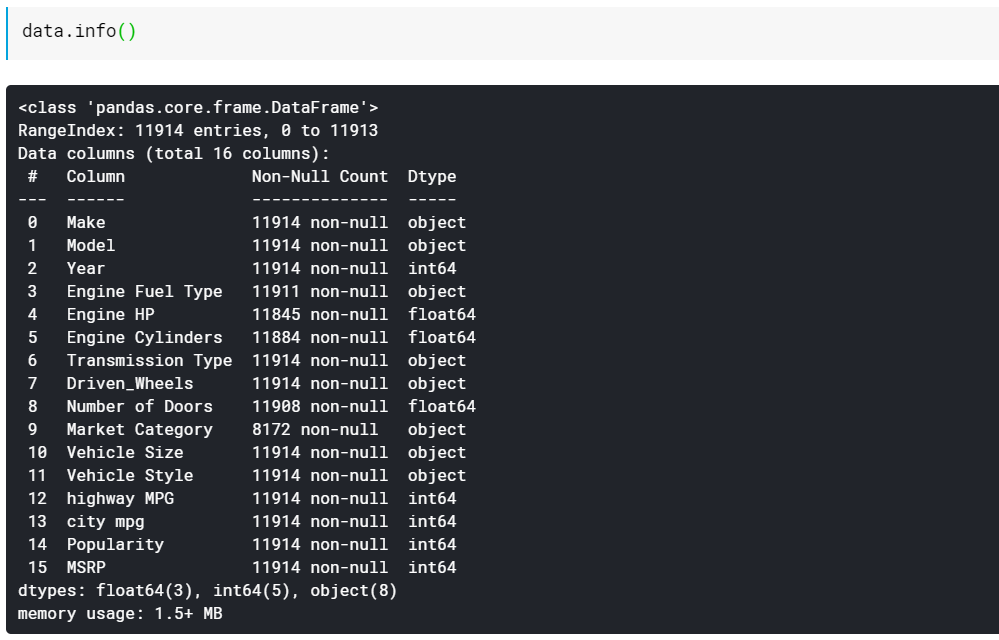
Wie Sie sehen, gibt uns die info()-Funktion alle Spalten, wie viele Nicht-Null- oder nicht fehlende Werte in diesen Spalten vorhanden sind, und schließlich den Datentyp dieser Spalten. Auf diese Weise können Sie schnell sehen, welche Funktionen numerisch und welche kategorisch/textbasiert sind. Außerdem haben wir jetzt Informationen darüber, in welchen Spalten Werte fehlen. Wir werden uns später ansehen, wie man mit fehlenden Werten arbeitet.
Bearbeiten von Spaltennamen und Datentypen
Das sorgfältige Überprüfen und Manipulieren jeder Spalte ist bei EDA äußerst wichtig. Wir müssen sehen, welche Arten von Inhalten eine Spalte / Funktion enthält und was Pandas ihren Datentyp gelesen hat. Die numerischen Datentypen sind meist int64 oder float64. Den textbasierten oder kategorialen Merkmalen wird der Datentyp „Objekt“ zugeordnet.
Die auf Datum und Uhrzeit basierenden Funktionen werden zugewiesen. Es gibt Zeiten, in denen Pandas den Datentyp einer Funktion nicht versteht. In solchen Fällen weist es ihm nur faul den Datentyp „Objekt“ zu. Wir können die Spaltendatentypen explizit angeben, während wir die Daten mit read_csv lesen.
Kategorische und numerische Spalten auswählen
| # Fügen Sie alle kategorialen und numerischen Spalten zu separaten Listen hinzu kategorial = data.select_dtypes( 'object' ).columns Numerisch = data.select_dtypes( 'number' ).columns |


Hier wählt der Typ, den wir als „Zahl“ übergeben haben, alle Spalten mit Datentypen aus, die irgendeine Art von Zahl haben – sei es int64 oder float64.
Spalten umbenennen
| # Umbenennen der Spaltennamen data = data.rename(columns={ „Engine HP“ : „HP“ , „Motorzylinder“ : „Zylinder“ , „Übertragungstyp“ : „Übertragung“ , „Driven_Wheels“ : „Fahrmodus “ , „Autobahn MPG“ : „MPG-H“ , „UVP“ : „Preis“ }) data.head( 5 ) |

Die Umbenennungsfunktion übernimmt lediglich ein Wörterbuch mit den umzubenennenden Spaltennamen und ihren neuen Namen.
Umgang mit fehlenden Werten und doppelten Zeilen
Fehlende Werte sind eines der häufigsten Probleme/Diskrepanzen in realen Datensätzen. Der Umgang mit fehlenden Werten ist an sich ein großes Thema, da es mehrere Möglichkeiten gibt, dies zu tun. Einige Methoden sind allgemeiner und einige sind spezifischer für den Datensatz, mit dem man es zu tun haben könnte.
Überprüfung fehlender Werte
| # Überprüfung fehlender Werte data.isnull().sum() |
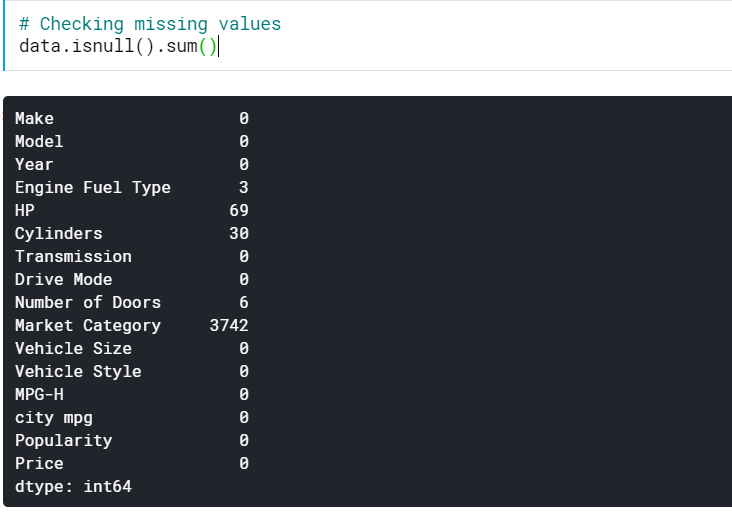
Dies gibt uns die Anzahl der fehlenden Werte in allen Spalten. Wir können auch den Prozentsatz der fehlenden Werte sehen.
| # Prozent der fehlenden Werte data.isnull().mean()* 100 |
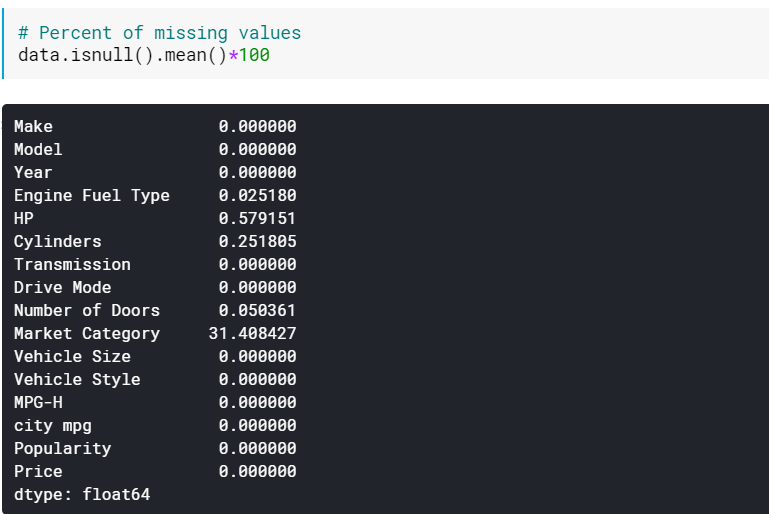
Die Überprüfung der Prozentsätze kann hilfreich sein, wenn viele Spalten fehlende Werte aufweisen. In solchen Fällen können die Spalten mit vielen fehlenden Werten (z. B. >60 % fehlend) einfach weggelassen werden.
Imputieren fehlender Werte
| #Imputieren fehlender Werte numerischer Spalten durch Mittelwert data[numerical] = data[numerical].fillna(data[numerical].mean().iloc[ 0 ]) #Imputieren fehlender Werte von kategorischen Spalten nach Modus data[categorical] = data[categorical].fillna(data[categorical].mode().iloc[ 0 ]) |
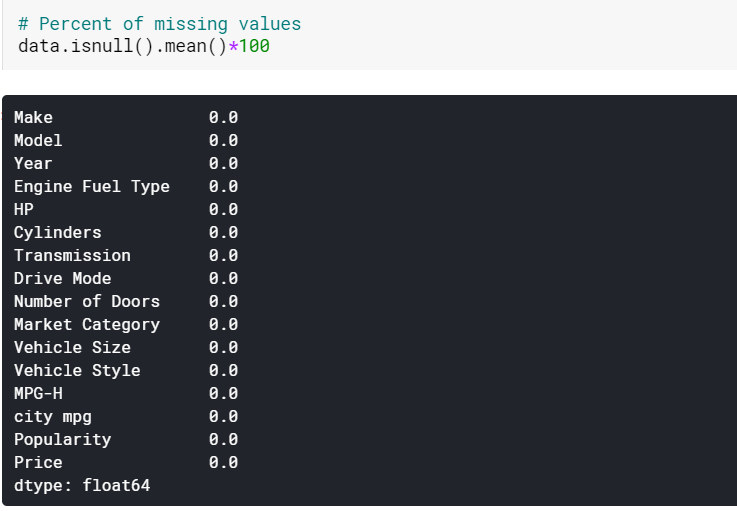
Hier setzen wir einfach die fehlenden Werte in den numerischen Spalten mit ihren jeweiligen Mitteln und die in den kategorialen Spalten mit ihren Modi ein. Und wie wir sehen können, gibt es jetzt keine fehlenden Werte.
Bitte beachten Sie, dass dies die primitivste Methode zur Imputation der Werte ist und in realen Fällen nicht funktioniert, in denen ausgefeiltere Methoden entwickelt werden, z. B. Interpolation, KNN usw.
Umgang mit doppelten Zeilen
| # Doppelte Zeilen löschen data.drop_duplicates(inplace= True ) |
Dadurch werden nur die doppelten Zeilen gelöscht.
Kasse: Ideen und Themen für Python-Projekte
Bivariate Analyse
Sehen wir uns nun an, wie Sie durch eine bivariate Analyse mehr Einblicke erhalten. Bivariat bedeutet eine Analyse, die aus 2 Variablen oder Merkmalen besteht. Es gibt verschiedene Typen von Diagrammen, die für verschiedene Arten von Merkmalen verfügbar sind.
Für Numerisch – Numerisch
- Streudiagramm
- Liniendiagramm
- Heatmap für Korrelationen
Für kategorial-numerisch
- Balkendiagramm
- Violine-Plot
- Schwarm-Plot
Für kategorial-kategorial
- Balkendiagramm
- Punktplot
Heatmap für Korrelationen
| # Überprüfung der Korrelationen zwischen den Variablen. plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= „BrBG“ ,annot= True ) |
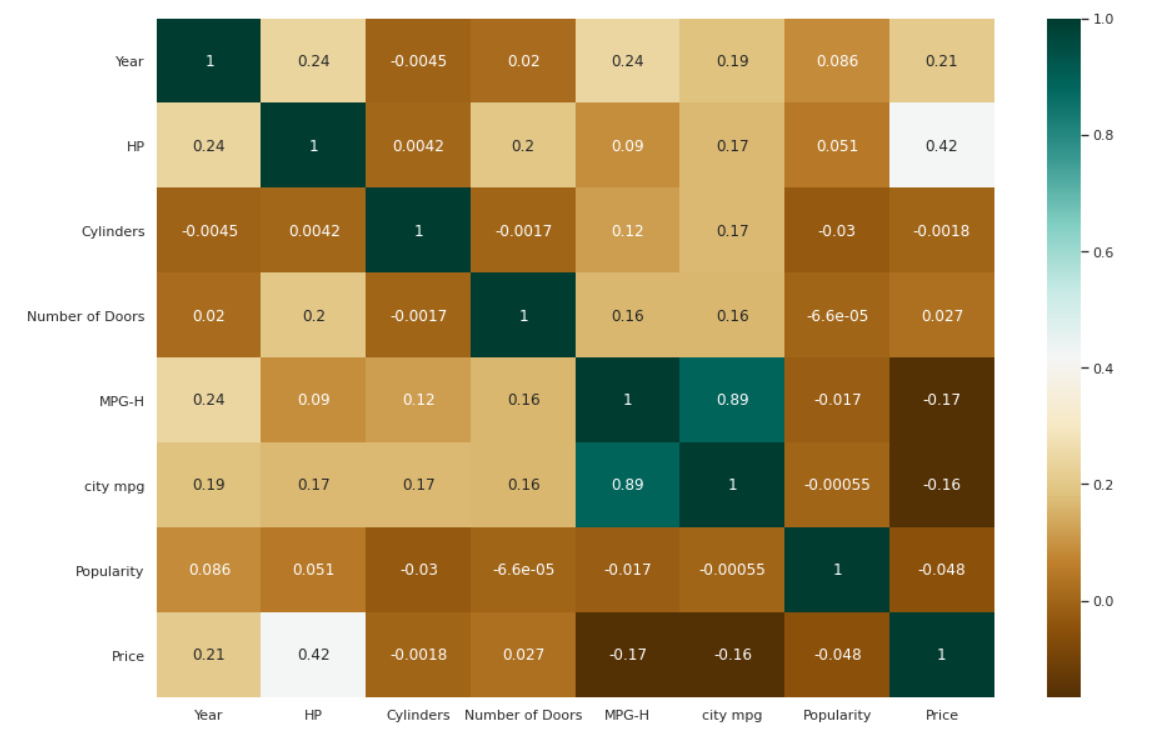
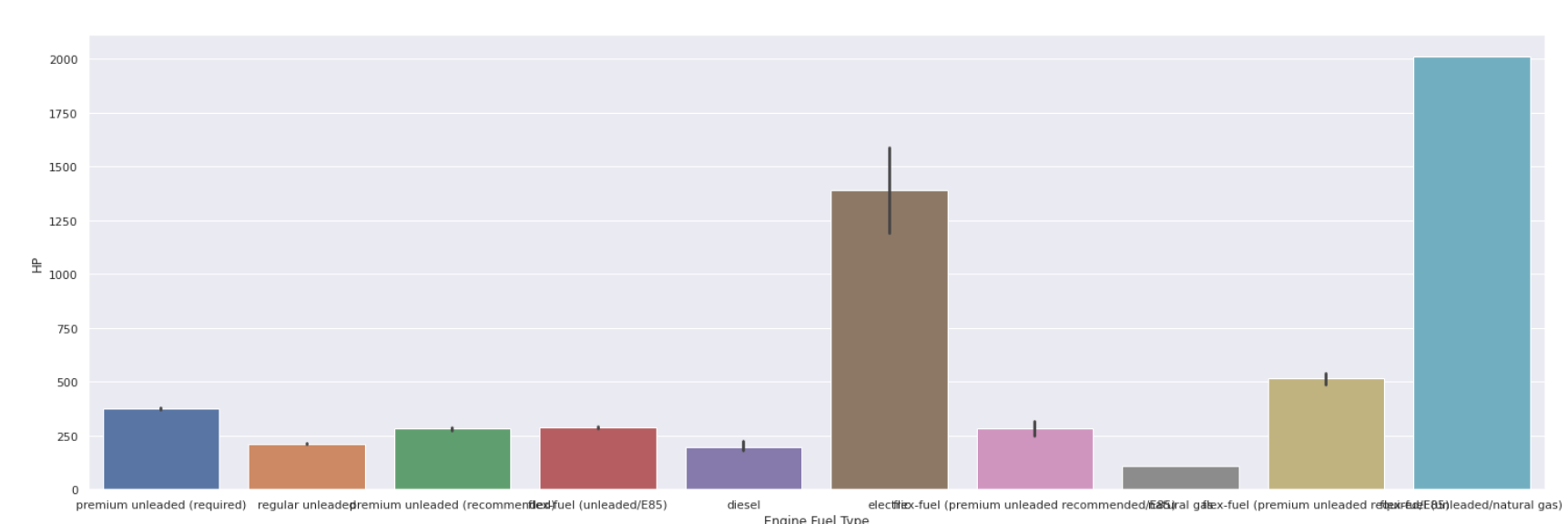
Balkendiagramm
| sns.barplot (data[ 'Engine Fuel Type' ], data[ 'HP' ]) |
Holen Sie sich eine Data-Science-Zertifizierung von den besten Universitäten der Welt. Lernen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Fazit
Wie wir gesehen haben, müssen beim Erkunden eines Datensatzes viele Schritte durchlaufen werden. Wir haben in diesem Tutorial nur eine Handvoll Aspekte behandelt, aber dies wird Ihnen mehr als nur Grundkenntnisse eines guten EDA vermitteln.
Wenn Sie neugierig sind, mehr über Python und alles über Data Science zu erfahren, schauen Sie sich das PG Diploma in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische praktische Workshops und Mentoring mit der Industrie bietet Experten, 1-on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was sind die Schritte in der explorativen Datenanalyse?
Die wichtigsten Schritte, die Sie ausführen müssen, um eine explorative Datenanalyse durchzuführen, sind:
Variablen und Datentypen müssen identifiziert werden.
Analyse der grundlegenden Kennzahlen
Univariate nichtgrafische Analyse
Univariate grafische Analyse
Analyse bivariater Daten
Transformationen, die variabel sind
Behandlung für fehlenden Wert
Behandlung von Ausreißern
Analyse der Korrelation
Reduktion der Dimensionalität
Was ist der Zweck der explorativen Datenanalyse?
Das Hauptziel von EDA ist die Unterstützung bei der Analyse von Daten, bevor Annahmen getroffen werden. Es kann bei der Erkennung offensichtlicher Fehler sowie bei einem besseren Verständnis von Datenmustern, der Erkennung von Ausreißern oder ungewöhnlichen Ereignissen und der Entdeckung interessanter Beziehungen zwischen Variablen helfen.
Die explorative Analyse kann von Datenwissenschaftlern verwendet werden, um sicherzustellen, dass die von ihnen erstellten Ergebnisse genau und für alle angestrebten Geschäftsergebnisse und -ziele geeignet sind. Die EDA unterstützt die Interessengruppen auch, indem sie sicherstellt, dass sie sich mit den entsprechenden Fragen befassen. Standardabweichungen, kategoriale Daten und Konfidenzintervalle können alle mit EDA beantwortet werden. Nach dem Abschluss von EDA und der Gewinnung von Erkenntnissen können seine Funktionen für eine fortgeschrittenere Datenanalyse oder Modellierung, einschließlich maschinellem Lernen, angewendet werden.
Welche Arten der explorativen Datenanalyse gibt es?
Es gibt zwei Arten von EDA-Techniken: grafische und quantitative (nicht-grafische). Der quantitative Ansatz hingegen erfordert die Erstellung zusammenfassender Statistiken, während die grafischen Methoden eine diagrammartige oder visuelle Erfassung der Daten beinhalten. Univariate und multivariate Ansätze sind Teilmengen dieser beiden Arten von Methodologien.
Um Beziehungen zu untersuchen, betrachten univariate Ansätze jeweils eine Variable (Datenspalte), während multivariate Methoden zwei oder mehr Variablen gleichzeitig betrachten. Univariate und multivariate grafische und nichtgrafische sind die vier Formen von EDA. Quantitative Verfahren sind objektiver, bildliche Verfahren hingegen subjektiv.