
Der Leitfaden zum ethischen Scraping dynamischer Websites mit Node.js und Puppeteer
Veröffentlicht: 2022-03-10Beginnen wir mit einem kleinen Abschnitt darüber, was Web Scraping eigentlich bedeutet. Wir alle verwenden Web Scraping in unserem täglichen Leben. Es beschreibt lediglich den Vorgang des Extrahierens von Informationen von einer Website. Wenn Sie also ein Rezept Ihres Lieblingsnudelgerichts aus dem Internet kopieren und in Ihr persönliches Notizbuch einfügen, betreiben Sie Web Scraping .
Wenn wir diesen Begriff in der Softwarebranche verwenden, beziehen wir uns normalerweise auf die Automatisierung dieser manuellen Aufgabe durch den Einsatz einer Software. Um bei unserem vorherigen Beispiel „Nudelgericht“ zu bleiben, umfasst dieser Prozess normalerweise zwei Schritte:
- Abrufen der Seite
Wir müssen zuerst die Seite als Ganzes herunterladen. Dieser Schritt ist wie das Öffnen der Seite in Ihrem Webbrowser beim manuellen Scrapen. - Analysieren der Daten
Nun müssen wir das Rezept im HTML der Website extrahieren und in ein maschinenlesbares Format wie JSON oder XML konvertieren.
In der Vergangenheit habe ich für viele Unternehmen als Datenberater gearbeitet. Ich war erstaunt zu sehen, wie viele Datenextraktions-, Aggregations- und Anreicherungsaufgaben immer noch manuell durchgeführt werden, obwohl sie mit nur wenigen Codezeilen leicht automatisiert werden könnten. Genau darum geht es mir beim Web Scraping: wertvolle Informationen aus einer Website zu extrahieren und zu normalisieren , um einen anderen wertsteigernden Geschäftsprozess zu fördern.
Während dieser Zeit habe ich gesehen, wie Unternehmen Web Scraping für alle möglichen Anwendungsfälle eingesetzt haben. Investmentfirmen konzentrierten sich in erster Linie auf das Sammeln alternativer Daten wie Produktbewertungen , Preisinformationen oder Social-Media-Beiträge, um ihre Finanzinvestitionen zu untermauern.
Hier ist ein Beispiel. Ein Kunde wandte sich an mich, um Produktbewertungsdaten für eine umfangreiche Liste von Produkten von mehreren E-Commerce-Websites zu kratzen, einschließlich der Bewertung, des Standorts des Bewerters und des Bewertungstexts für jede eingereichte Bewertung. Die Ergebnisdaten ermöglichten es dem Kunden , Trends zur Popularität des Produkts in verschiedenen Märkten zu erkennen . Dies ist ein hervorragendes Beispiel dafür, wie eine scheinbar „nutzlose“ Einzelinformation im Vergleich zu einer größeren Menge wertvoll werden kann.
Andere Unternehmen beschleunigen ihren Verkaufsprozess, indem sie Web-Scraping zur Lead-Generierung einsetzen. Dieser Prozess beinhaltet normalerweise das Extrahieren von Kontaktinformationen wie Telefonnummer, E-Mail-Adresse und Kontaktname für eine bestimmte Liste von Websites. Durch die Automatisierung dieser Aufgabe haben Vertriebsteams mehr Zeit, sich an potenzielle Kunden zu wenden. Dadurch steigt die Effizienz des Verkaufsprozesses.
Halten Sie sich an die Regeln
Im Allgemeinen ist das Web-Scraping öffentlich zugänglicher Daten legal, wie die Rechtsprechung im Fall Linkedin vs. HiQ bestätigt. Allerdings habe ich mir ein ethisches Regelwerk gesetzt, an das ich mich gerne halte, wenn ich ein neues Web-Scraping-Projekt starte. Das beinhaltet:
- Überprüfung der robots.txt-Datei.
Es enthält normalerweise klare Informationen darüber, auf welche Teile der Website der Seitenbesitzer von Robots & Scrapern zugreifen darf, und hebt die Abschnitte hervor, auf die nicht zugegriffen werden sollte. - Lesen der AGB.
Im Vergleich zur robots.txt ist diese Information nicht seltener vorhanden, gibt aber meist an, wie sie mit Data Scrapern umgehen. - Schaben mit mäßiger Geschwindigkeit.
Scraping erzeugt Serverlast auf der Infrastruktur der Zielseite. Je nachdem, was Sie scrapen und auf welcher Parallelitätsebene Ihr Scraper arbeitet, kann der Datenverkehr Probleme für die Serverinfrastruktur der Zielseite verursachen. Natürlich spielt die Serverkapazität in dieser Gleichung eine große Rolle. Daher ist die Geschwindigkeit meines Scrapers immer ein Gleichgewicht zwischen der Datenmenge, die ich kratzen möchte, und der Popularität der Zielseite. Dieses Gleichgewicht lässt sich durch die Beantwortung einer einzigen Frage erreichen: „Wird die geplante Geschwindigkeit den organischen Traffic der Website erheblich verändern?“. In Fällen, in denen ich mir über die Menge des natürlichen Traffics einer Website nicht sicher bin, verwende ich Tools wie ahrefs, um eine ungefähre Vorstellung zu bekommen.
Auswahl der richtigen Technologie
Tatsächlich ist das Scraping mit einem Headless-Browser eine der leistungsschwächsten Technologien, die Sie verwenden können, da es Ihre Infrastruktur stark beeinträchtigt. Ein Kern des Prozessors Ihres Computers kann ungefähr eine Chrome-Instanz verarbeiten.
Lassen Sie uns eine kurze Beispielrechnung durchführen , um zu sehen, was dies für ein reales Web-Scraping-Projekt bedeutet.
Szenario
- Sie wollen 20.000 URLs kratzen.
- Die durchschnittliche Antwortzeit von der Zielseite beträgt 6 Sekunden.
- Ihr Server hat 2 CPU-Kerne.
Das Projekt dauert 16 Stunden .
Daher versuche ich immer, die Verwendung eines Browsers zu vermeiden, wenn ich einen Scraping-Machbarkeitstest für eine dynamische Website durchführe.
Hier ist eine kleine Checkliste, die ich immer durchgehe:
- Kann ich den erforderlichen Seitenzustand durch GET-Parameter in der URL erzwingen? Wenn ja, können wir einfach eine HTTP-Anfrage mit den angehängten Parametern ausführen.
- Sind die dynamischen Informationen Teil der Seitenquelle und über ein JavaScript-Objekt irgendwo im DOM verfügbar? Wenn ja, können wir wieder eine normale HTTP-Anfrage verwenden und die Daten aus dem gestringten Objekt parsen.
- Werden die Daten über eine XHR-Anfrage abgerufen? Wenn ja, kann ich mit einem HTTP-Client direkt auf den Endpunkt zugreifen? Wenn ja, können wir direkt eine HTTP-Anfrage an den Endpunkt senden. Oft ist die Antwort sogar in JSON formatiert, was unser Leben viel einfacher macht.
Wenn alle Fragen mit einem klaren „Nein“ beantwortet werden, gehen uns offiziell die praktikablen Möglichkeiten zur Nutzung eines HTTP-Clients aus. Natürlich könnte es weitere seitenspezifische Optimierungen geben, die wir ausprobieren könnten, aber normalerweise ist die erforderliche Zeit, um sie herauszufinden, zu hoch, verglichen mit der langsameren Leistung eines Headless-Browsers. Das Schöne am Scrapen mit einem Browser ist, dass Sie alles schaben können, was der folgenden Grundregel unterliegt:
Wenn Sie mit einem Browser darauf zugreifen können, können Sie es schaben.
Nehmen wir die folgende Seite als Beispiel für unseren Scraper: https://quotes.toscrape.com/search.aspx. Es enthält Zitate aus einer Liste bestimmter Autoren für eine Liste von Themen. Alle Daten werden über XHR abgerufen.
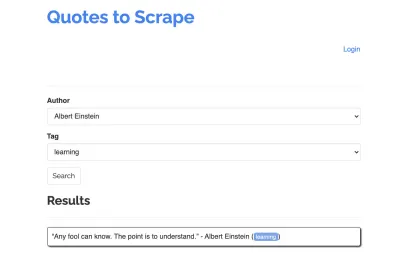
Wer sich die Funktionsweise der Website genau angesehen und die obige Checkliste durchgegangen ist, hat wahrscheinlich festgestellt, dass die Zitate tatsächlich mit einem HTTP-Client gekratzt werden können, da sie durch eine POST-Anfrage direkt am Endpunkt der Zitate abgerufen werden können. Aber da dieses Tutorial behandeln soll, wie man eine Website mit Puppeteer scrapt, werden wir so tun, als wäre dies unmöglich.
Voraussetzungen installieren
Da wir alles mit Node.js erstellen werden, erstellen und öffnen wir zunächst einen neuen Ordner und erstellen darin ein neues Node-Projekt, indem wir den folgenden Befehl ausführen:
mkdir js-webscraper cd js-webscraper npm initBitte stellen Sie sicher, dass Sie npm bereits installiert haben. Das Installationsprogramm stellt uns einige Fragen zu Metainformationen zu diesem Projekt, die wir alle überspringen können, indem wir die Eingabetaste drücken .
Puppenspieler installieren
Wir haben bereits über das Scraping mit einem Browser gesprochen. Puppeteer ist eine Node.js-API, die es uns ermöglicht, programmgesteuert mit einer Headless-Chrome-Instanz zu kommunizieren.
Lassen Sie uns es mit npm installieren:
npm install puppeteerAufbau unseres Schabers
Beginnen wir nun mit dem Erstellen unseres Scrapers, indem wir eine neue Datei namens scraper.js erstellen .
Zuerst importieren wir die zuvor installierte Bibliothek Puppeteer:
const puppeteer = require('puppeteer');Als nächsten Schritt weisen wir Puppeteer an, eine neue Browserinstanz innerhalb einer asynchronen und selbstausführenden Funktion zu öffnen:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Hinweis : Standardmäßig ist der Headless-Modus ausgeschaltet, da dies die Leistung erhöht. Wenn ich jedoch einen neuen Scraper baue, schalte ich den Headless-Modus gerne aus. Auf diese Weise können wir den Prozess verfolgen, den der Browser durchläuft, und alle gerenderten Inhalte sehen. Dies wird uns später beim Debuggen unseres Skripts helfen.
Innerhalb unserer geöffneten Browserinstanz öffnen wir nun eine neue Seite und leiten zu unserer Ziel-URL weiter:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Als Teil der asynchronen Funktion verwenden wir die await -Anweisung, um auf die Ausführung des folgenden Befehls zu warten, bevor wir mit der nächsten Codezeile fortfahren.
Nachdem wir nun erfolgreich ein Browserfenster geöffnet und zur Seite navigiert haben, müssen wir den Zustand der Website erstellen , damit die gewünschten Informationen zum Scrapen sichtbar werden.
Die verfügbaren Themen werden dynamisch für einen ausgewählten Autor generiert. Daher wählen wir zunächst „Albert Einstein“ aus und warten auf die generierte Themenliste. Nachdem die Liste vollständig generiert wurde, wählen wir „Lernen“ als Thema und wählen es als zweiten Formularparameter aus. Wir klicken dann auf „Senden“ und extrahieren die abgerufenen Angebote aus dem Container, der die Ergebnisse enthält.

Da wir dies nun in JavaScript-Logik umwandeln, erstellen wir zunächst eine Liste aller Elementselektoren, über die wir im vorherigen Absatz gesprochen haben:
| Autorenauswahlfeld | #author |
| Tag-Auswahlfeld | #tag |
| Senden-Schaltfläche | input[type="submit"] |
| Container zitieren | .quote |
Bevor wir mit der Interaktion mit der Seite beginnen, stellen wir sicher, dass alle Elemente, auf die wir zugreifen werden, sichtbar sind, indem wir unserem Skript die folgenden Zeilen hinzufügen:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Als Nächstes wählen wir Werte für unsere beiden ausgewählten Felder aus:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Wir sind jetzt bereit, unsere Suche durchzuführen, indem wir auf der Seite auf die Schaltfläche „Suchen“ klicken und warten, bis die Zitate erscheinen:
await page.click('.btn'); await page.waitForSelector('.quote'); Da wir jetzt auf die HTML-DOM-Struktur der Seite zugreifen, rufen wir die bereitgestellte Funktion page.evaluate() auf und wählen den Container aus, der die Anführungszeichen enthält (in diesem Fall ist es nur einer). Dann bauen wir ein Objekt und definieren null als Fallback-Wert für jeden object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Wir können alle Ergebnisse in unserer Konsole sichtbar machen, indem wir sie protokollieren:
console.log(quotes);Schließen wir zum Schluss unseren Browser und fügen eine catch-Anweisung hinzu:
await browser.close();Der komplette Schaber sieht wie folgt aus:
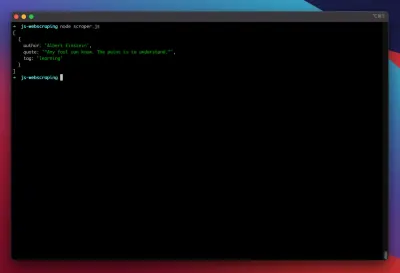
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Versuchen wir, unseren Scraper auszuführen mit:
node scraper.jsUnd los geht's! Der Scraper gibt unser Kursobjekt wie erwartet zurück:
Erweiterte Optimierungen
Unser einfacher Schaber funktioniert jetzt. Lassen Sie uns einige Verbesserungen hinzufügen, um es für einige ernsthaftere Scraping-Aufgaben vorzubereiten.
Einstellen eines User-Agents
Standardmäßig verwendet Puppeteer einen Benutzeragenten, der die Zeichenfolge HeadlessChrome enthält. Nicht wenige Websites achten auf diese Art von Signatur und blockieren eingehende Anfragen mit einer solchen Signatur. Um zu vermeiden, dass dies ein möglicher Grund für das Scheitern des Scrapers ist, lege ich immer einen benutzerdefinierten Benutzeragenten fest, indem ich unserem Code die folgende Zeile hinzufüge:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Dies könnte noch weiter verbessert werden, indem bei jeder Anfrage ein zufälliger Benutzeragent aus einer Reihe der 5 häufigsten Benutzeragenten ausgewählt wird. Eine Liste der gebräuchlichsten User-Agents finden Sie in einem Beitrag zu Most Common User-Agents.
Implementieren eines Proxys
Puppeteer macht die Verbindung zu einem Proxy sehr einfach, da die Proxy-Adresse beim Start wie folgt an Puppeteer übergeben werden kann:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies bietet eine große Liste kostenloser Proxys, die Sie verwenden können. Alternativ können rotierende Proxy-Dienste verwendet werden. Da Proxys normalerweise von vielen Kunden (oder in diesem Fall kostenlosen Benutzern) gemeinsam genutzt werden, wird die Verbindung viel unzuverlässiger, als sie es unter normalen Umständen bereits ist. Dies ist der perfekte Moment, um über Fehlerbehandlung und Retry-Management zu sprechen.
Fehler- und Retry-Management
Viele Faktoren können dazu führen, dass Ihr Schaber ausfällt. Daher ist es wichtig, mit Fehlern umzugehen und zu entscheiden, was im Falle eines Fehlers geschehen soll. Da wir unseren Scraper mit einem Proxy verbunden haben und erwarten, dass die Verbindung instabil ist (insbesondere weil wir kostenlose Proxys verwenden), wollen wir es viermal wiederholen, bevor wir aufgeben.
Außerdem macht es keinen Sinn, eine Anfrage mit derselben IP-Adresse erneut zu versuchen, wenn sie zuvor fehlgeschlagen ist. Daher werden wir ein kleines Proxy-Rotationssystem aufbauen .
Zunächst erstellen wir zwei neue Variablen:
let retry = 0; let maxRetries = 5; Jedes Mal, wenn wir unsere Funktion scrape() ausführen, erhöhen wir unsere Retry-Variable um 1. Wir umschließen dann unsere vollständige Scraping-Logik mit einer Try-and-Catch-Anweisung, damit wir Fehler behandeln können. Das Retry-Management geschieht innerhalb unserer catch -Funktion:
Die vorherige Browserinstanz wird geschlossen, und wenn unsere Retry-Variable kleiner als unsere maxRetries Variable ist, wird die Scrape-Funktion rekursiv aufgerufen.
Unser Scraper sieht nun so aus:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Lassen Sie uns nun den zuvor erwähnten Proxy-Rotator hinzufügen.
Lassen Sie uns zuerst ein Array erstellen, das eine Liste von Proxys enthält:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Wählen Sie nun einen zufälligen Wert aus dem Array aus:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Wir können jetzt den dynamisch generierten Proxy zusammen mit unserer Puppeteer-Instanz ausführen:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Natürlich könnte dieser Proxy-Rotator weiter optimiert werden, um tote Proxys zu kennzeichnen usw., aber dies würde definitiv den Rahmen dieses Tutorials sprengen.
Dies ist der Code unseres Schabers (einschließlich aller Verbesserungen):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voila! Wenn Sie unseren Scraper in unserem Terminal ausführen, werden die Kurse zurückgegeben.
Dramatiker als Alternative zum Puppenspieler
Puppenspieler wurde von Google entwickelt. Anfang 2020 veröffentlichte Microsoft eine Alternative namens Playwright. Microsoft hat viele Ingenieure aus dem Puppeteer-Team abgeworben. Daher wurde Playwright von vielen Ingenieuren entwickelt, die bereits an Puppeteer gearbeitet haben. Abgesehen davon, dass Playwright das neue Kind im Blog ist, ist das größte Unterscheidungsmerkmal von Playwright die browserübergreifende Unterstützung, da es Chromium, Firefox und WebKit (Safari) unterstützt.
Leistungstests (wie dieser von Checkly durchgeführte) zeigen, dass Puppeteer im Vergleich zu Playwright im Allgemeinen eine um etwa 30 % bessere Leistung bietet, was meiner eigenen Erfahrung entspricht – zumindest zum Zeitpunkt des Schreibens.
Andere Unterschiede, wie die Tatsache, dass Sie mehrere Geräte mit einer Browserinstanz betreiben können, sind für den Kontext von Web Scraping nicht wirklich wertvoll.
Ressourcen und zusätzliche Links
- Puppenspieler-Dokumentation
- Puppenspieler & Dramatiker lernen
- Web Scraping mit Javascript von Zenscrape
- Die gängigsten User-Agents
- Puppenspieler vs. Dramatiker