
Entwicklung für das semantische Web
Veröffentlicht: 2022-03-10Im Juli kündigte die Wikimedia Foundation Abstract Wikipedia an, einen Versuch, sprachunabhängiges Wissen zu markieren. In vielerlei Hinsicht ist dies der Höhepunkt eines jahrzehntelangen Aufbaus, in dem der Traum vom Semantic Web nie ganz aufgegangen ist, aber auch nie ganz verschwunden ist.
Tatsächlich wächst das semantische Web, und da es seine Mission erneuert, können wir alle davon profitieren, wenn wir semantische Auszeichnungen in unsere Websites integrieren, seien es persönliche Blogs oder Social-Media-Giganten. Egal, ob Sie sich für ausgefeilte Web-Erlebnisse, SEO oder die Abwehr der Tyrannei von Web-Monopolen interessieren, das Semantic Web verdient unsere Aufmerksamkeit.
Die Vorteile der Entwicklung für das semantische Web sind nicht immer unmittelbar oder sichtbar, aber jede Website, die dies tut, stärkt die Grundlagen eines offenen, transparenten und dezentralisierten Internets.
Das semantische Web
Was genau ist das Semantische Web? Es ist ein maschinenlesbares Web, das durch Metadaten „ein gemeinsames Framework bereitstellt, das es ermöglicht, Daten über Anwendungs-, Unternehmens- und Community-Grenzen hinweg gemeinsam zu nutzen und wiederzuverwenden“.
Die Idee ist so alt wie das World Wide Web selbst. Älter sogar. Es war ein Schwerpunkt von Tim Berners-Lees Vorschlag von 1989. Wie er skizzierte, sollten nicht nur Dokumente Webs bilden, sondern auch die darin enthaltenen Daten:
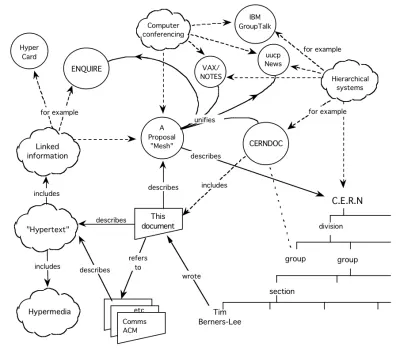
Das Semantic Web hat in den Jahrzehnten seitdem einen steinigen Weg beschritten. Seit der Jahrtausendwende hat es sich in mehrere Konzepte verwandelt – offene Daten, Wissensgraphen – die alle dasselbe bedeuten: Datennetze.
Wie das W3C zusammenfasst, ist es „eine Erweiterung des aktuellen Webs, in der Informationen eine klar definierte Bedeutung erhalten, wodurch Computer und Menschen besser zusammenarbeiten können“.

Die Idee hat einen fairen Anteil an Befürwortern. Der Internet-Hacktivist Aaron Swartz hat ein Buchmanuskript über das Semantic Web mit dem Titel A Programmable Web geschrieben. Darin schrieb er:
„Dokumente können nicht wirklich zusammengeführt und integriert und abgefragt werden; Sie dienen meist als isolierte Fälle, die betrachtet und überprüft werden müssen. Aber Daten sind veränderlich und können sich in jede Form verwandeln, die Ihren Anforderungen am besten entspricht.“
Aus verschiedenen Gründen hat sich das Semantic Web nicht so entwickelt wie das Web, obwohl es aufholt. Im Laufe der Jahre haben mehrere Markups versucht, den Mantel zu erobern – RDFa, OWL und Schema, um nur einige zu nennen – obwohl keines so zum Standard geworden ist, wie es beispielsweise HTML oder CSS getan haben. Die Eintrittsbarriere war zu hoch.
Der Traum vom semantischen Web hat jedoch Bestand, und da immer mehr Websites es in ihre Designs integrieren, gibt es umso mehr Gründe, sich der Party anzuschließen. Je mehr Seiten an Bord kommen, desto stärker wird das Semantic Web.
Weiterführende Lektüre
- Datenintelligenz
- The Semantic Web, ein Artikel aus dem Jahr 2001 von Tim Berners-Lee, James Hensley und Ora Lassila
- Glaubwürdige Web-Community-Gruppe beim W3C
Wissen ohne Grenzen
Bevor wir uns mit dem Design für das semantische Web befassen, lohnt es sich, ein wenig tiefer in das Warum einzudringen . Was spielt es für eine Rolle, ob Daten verbunden sind? Sind verbundene Dokumente nicht genug?
Es gibt mehrere Gründe, warum das Semantic Web weiterhin von denjenigen vorangetrieben wird, denen ein freies und offenes Internet am Herzen liegt. Das Verständnis dieser Gründe ist für den Implementierungsprozess von entscheidender Bedeutung. Es sollte nicht heißen „Essen Sie Ihr Gemüse, verwenden Sie semantische Auszeichnungen“. Das Semantic Web ist etwas, an das man glauben und ein Teil davon sein sollte.
Zu den Vorteilen des Semantic Web gehören:
- Reichhaltigere, anspruchsvollere Web-Erlebnisse
- Inhaltssilos und Internetmonopole umgehen
- Verbesserte Lesbarkeit und Rankings in Suchmaschinen
- Demokratisierung von Informationen
Die meisten davon lassen sich auf einen Kerngedanken des Semantic Web zurückführen: eine universelle Sprache für Daten. Obwohl das Internet bereits Wunder für die internationale Kommunikation bewirkt hat, lässt sich die Tatsache nicht leugnen, dass einige Länder es viel besser haben als andere. Nehmen Sie zum Beispiel Sprachen, die im Internet verwendet werden, im Vergleich zu Sprachen, die in der realen Welt verwendet werden. Die Adleraugen unter Ihnen können vielleicht ein leichtes Ungleichgewicht in den folgenden Daten erkennen …
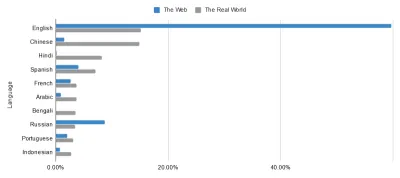
Die grenzenlose Utopie des Internets ist nicht so nah, wie es uns in der englischsprachigen Blase erscheinen mag. Ist das etwas, wofür man jemanden bestrafen sollte? Nicht unbedingt, aber es ist etwas, dem man sich stellen muss. Dies unterstreicht die Bedeutung von Markup, das diese Lücken schließt. Indem wir die Daten des Webs anreichern, entlasten wir seine Sprachen.
Dies ist der Kernpunkt der kürzlich angekündigten abstrakten Wikipedia, die versuchen wird, Artikel von der Sprache zu entkoppeln, in der sie zufällig geschrieben wurden. Katherine Maher, Executive Director von Wikimedia, schreibt: „Mithilfe von Code werden Freiwillige in der Lage sein, diese abstrakten ‚Artikel' in sie zu übersetzen ihre eigenen Sprachen. Wenn dies erfolgreich ist, könnte dies letztendlich jedem ermöglichen, über jedes Thema in Wikidata in seiner eigenen Sprache zu lesen.“
Zusammenfassung Wikipedia-Schöpfer Denny Vrandecic ist seit Jahren ein Verfechter des Semantic Web und hat dessen Potenzial erkannt, ungenutztes Potenzial online zu erschließen. Der Abbau nationaler Barrieren ist für diesen Prozess von wesentlicher Bedeutung.
„Egal in welcher Sprache Sie Ihre Inhalte veröffentlichen, Sie werden es verpassen, die große Mehrheit der Menschen auf der Welt einzubeziehen. Das Web gab uns diese wunderbare Gelegenheit, globale Reichweite zu haben – aber indem wir uns auf eine einzige Sprache oder eine kleine Gruppe von Sprachen verlassen, vergeuden wir diese Gelegenheit. Während das wichtigste Ziel darin besteht, überhaupt gute Inhalte zu erstellen, laden Sie mehr Menschen ein, sich an der Entwicklung besserer Inhalte zu beteiligen, indem Sie sprachunabhängig sind. Es hilft Ihnen, die Barrieren für Beiträge und Konsum zu senken, und es ermöglicht viel mehr Menschen, von diesen Bemühungen zu profitieren.“
— Denny Vrandecic, Autor von Abstract Wikipedia
Ein aktuelles Beispiel dafür war die Datenvisualisierung während der COVID-19-Pandemie. Der Virus hat weltweit unsägliches Chaos angerichtet, aber er war auch ein glänzender Moment für offene Datennetzwerke, der es ermöglichte, hervorragende Web-Apps, Berichte und mehr im gesamten Web zu verbreiten.
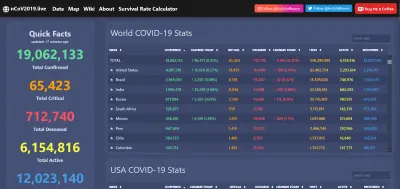
Und wenn die Daten transparent und leicht zugänglich sind, ist es natürlich einfacher, Anomalien zu erkennen … oder schlichte Täuschung. Noch vor 20 Jahren wäre ein weit verbreiteter öffentlicher Zugang zu den oben genannten Informationen undenkbar gewesen. Jetzt erwarten wir es und riechen eine Ratte, wenn es uns verweigert wird. Daten sind mächtig und können, wenn wir wollen, für immer genutzt werden.
In ähnlicher Weise entzieht das Auschecken aus Inhaltssilos – ein Markenzeichen des modernen Weberlebnisses – Webmonopolen wie Google, Facebook und Twitter die Macht. Wir sind so daran gewöhnt, dass Plattformen von Drittanbietern Informationen entschlüsseln und präsentieren, dass wir vergessen, dass dies nicht unbedingt erforderlich ist.
„Wenn wir gemeinsame Formate und Protokolle hätten, könnten wir immer noch damit enden, dass bestimmte Anbieter in bestimmten Märkten eine große Rolle spielen – denken Sie an Gmail für E-Mails – aber es steht jedem frei, zu einem anderen Anbieter zu wechseln, und der Markt bleibt wettbewerbsfähig.“
— Denny Vrandecic, Autor von Abstract Wikipedia
Das Semantic Web ist silolos; es ist frei, offen und abstrakt und ermöglicht die Kommunikation zwischen verschiedenen Sprachen und Plattformen, die sonst viel schwieriger wäre.
Datenauslesende Online-Inhalte
Design für das semantische Web läuft darauf hinaus, Online-Inhalte auszuwerten – sich Ihre Inhalte anzusehen und zu sehen, was abstrahiert werden kann (und sollte). Was bedeutet das in praktischer Hinsicht, abgesehen von der vage Zustimmung, dass es sich lohnt, dies zu tun? Es hängt davon ab, ob:
- Wenn Sie ein Projekt von Grund auf neu beginnen, beziehen Sie Überlegungen zum Semantic Web in Ihre Arbeit ein. Wenn eine Website Gestalt annimmt, weben Sie semantische Auszeichnungen in ihre DNA ein.
- Wenn Sie ein Projekt aktualisieren oder neu erstellen, prüfen Sie, was in das semantische Web eingewoben werden könnte, was derzeit noch nicht der Fall ist, und implementieren Sie es dann.
In beiden Fällen handelt es sich im Grunde um datenschützende Inhalte. In diesem Abschnitt werden wir einige Beispiele für Datenabstraktion durchgehen und zeigen, wie Inhalte besser, intelligenter und breiter verfügbar gemacht werden können.
Informationen abstrahieren
Designen und Entwickeln für das Semantic Web bedeutet, Online-Inhalte mit aufgesetztem Datenhut zu betrachten. Die meisten von uns erleben das Web als eine Reihe miteinander verbundener Dokumente oder Seiten; Was Sie mit dem Semantic Web machen möchten, sind Verbindungsinformationen. Das bedeutet, dass Sie Ihre Inhalte auf Datenpunkte untersuchen und dann das Design basierend auf Ihren Ergebnissen anpassen.
Semantic-Web-Befürworter James Hendler beschreibt diesen Prozess besonders gut mit seinem DIVE-Ethos. ( DIVE in die Daten, eh? Eh?). Es gliedert sich wie folgt:
- Entdecken
Finden Sie Datensätze und/oder Inhalte (auch außerhalb Ihrer eigenen Organisation). - Integrieren
Verknüpfen Sie die Relationen mit aussagekräftigen Labels. - Bestätigen
Bereitstellung von Eingaben für Modellierungs- und Simulationssysteme. - Entdecken
Entwickeln Sie Ansätze, um Daten in verwertbares Wissen umzuwandeln.
Bei der Entwicklung für das semantische Web geht es hauptsächlich darum, die Dinge, die Sie erstellen, aus der Vogelperspektive zu sehen und wie sie möglicherweise zu unendlich reichhaltigeren Web-Erlebnissen beitragen. Wie Hendler sagt, ist verwertbares Wissen das Ziel.
Dies kann wirklich auf fast jede Art von Webinhalten angewendet werden, aber beginnen wir mit einem allgemeinen Beispiel: Rezepte . Nehmen wir an, Sie betreiben einen Kochblog mit neuen Rezepten jeden Donnerstag. Wenn Sie Franzose sind und ein tolles Souffle-Rezept in Klartext auf Ihrem persönlichen Blog veröffentlichen, ist es nur für diejenigen nützlich, die Französisch lesen können.
Durch die Implementierung von semantischem Markup kann der Blog jedoch in einen maschinenlesbaren Rezeptdatensatz umgewandelt werden. Es existiert eine Syntax für zu abstrahierende Kochbegriffe. Schema, zum Beispiel, das neben Microdata, RDFa oder JSON-LD arbeiten kann, hat folgendes Markup:

- Vorbereitungszeit
- Kochzeit
- RezeptErtrag
- RezeptZutat
- geschätzte Kosten
- Ernährung, Aufschlüsselung in Kalorien und Fettgehalt
- geeignetFürDiät.
Ich könnte weitermachen. Die gesamte Palette der Optionen mit Beispielen kann auf Schema.org nachgelesen werden. Wenn Sie sie zum Post-Format hinzufügen, muss sich das Format des Rezepts überhaupt nicht ändern – Sie geben die Informationen einfach in Begriffen aus, die Computer verstehen können.
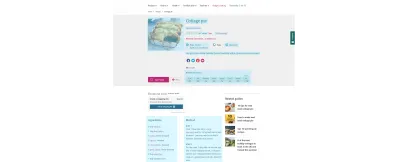
Zum Beispiel wurde alles, was im obigen BBC-Rezept blau hervorgehoben ist, auch mit semantischem Markup versehen – von der Kochzeit bis zum Nährwert. Sie können sehen, was unter der Haube vor sich geht, indem Sie die Rezept-URL in Googles Rich Results Test eingeben. Beachten Sie die Funktion „Zur Einkaufsliste hinzufügen“, ein Beispiel für eine Verbindung, die durch die Implementierung von Semantic Web ermöglicht wird. Aus guten Inhalten werden nutzbare Daten.
Die meisten von uns haben diese Art von Raffinesse über Suchergebnisse gekreuzt, aber die Anwendungen sind viel breiter als das. Die semantische Auszeichnung von Rezepten erleichtert das Auffinden und Verwenden von Websites durch Haushaltsassistenten. Die aufgeführten Zutaten können im örtlichen Supermarkt bestellt werden. Rezepte können auf alle möglichen Arten gefiltert werden – nach Diäten, Allergien, Religion, Kosten usw. Oder nehmen wir an, Sie hatten eine begrenzte Anzahl an Zutaten im Haus. Mit einer Datenbank könnten Sie diese Zutaten eingeben und sehen, welche Rezepte die Rechnung erfüllen.
Die Bandbreite der Möglichkeiten grenzt wirklich an Grenzen. Wie Swartz sagte, sind Daten vielschichtig. Sobald Sie es haben, können Sie es auf alle möglichen seltsamen und wunderbaren Arten verwenden. In diesem Stück geht es weniger um diese seltsamen und wunderbaren Wege, als vielmehr darum, sie möglich zu machen. Das Entwerfen für das semantische Web macht das nachfolgende Design unendlich reichhaltiger.
Hier ist ein persönlicheres Beispiel, um zu zeigen, was ich meine. Ein paar Freunde und ich betreiben als Hobby ein kleines Musik-Webzine. Obwohl wir den einen oder anderen Artikel oder ein Interview veröffentlichen, ist das „Hauptereignis“ unsere wöchentlichen Albumbesprechungen, in denen wir drei jeweils eine Punktzahl vergeben, Lieblingstitel auswählen und Zusammenfassungen schreiben. Wir sind seit mehr als fünf Jahren dabei, was bedeutet, dass wir fast 250 Bewertungen haben, was eine Menge potenzieller Daten bedeutet. Wir wussten nicht, wie viel, bis wir mit der Neugestaltung der Website begannen.
Ich habe dies in einem Artikel über das Backen strukturierter Daten in den Designprozess angesprochen. Beim Analysieren unserer Rezensionen stellten wir fest, dass sie randvoll mit Informationen waren, die mit semantischem Markup versehen werden könnten. Künstler, Albumnamen, Artwork, Veröffentlichungsdatum, Einzelpunktzahl, Gesamtpunktzahl, Veröffentlichungstyp und mehr. Außerdem – und hier wird es richtig spannend – haben wir festgestellt, dass wir eine Verbindung zu einer bestehenden Datenbank herstellen können: MusicBrainz.
Dieser wechselseitige Ansatz ist der Kern des Semantic Web. Wenn unsere Musik-Website neu gestartet wird, wird sie eine eigene offene Datenquelle mit Tausenden von einzigartigen Datenpunkten sein. Durch die Verbindung mit einer bestehenden Musikdatenbank erhalten unsere eigenen Daten mehr Kontext – und Potenzial. Tausende von Datenpunkten werden zu Zehntausenden von Datenpunkten, vielleicht mehr.
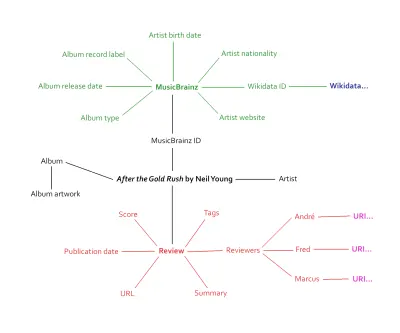
Die obige Grafik kratzt nur an der Oberfläche, wie viele Informationen mit Bewertungsseiten verbunden werden. Der Inhalt ist derselbe wie zuvor, nur dass er jetzt in ein Metadaten-Ökosystem eingebunden ist – den Giant Global Graph, wie Berners-Lee ihn einmal nannte.
Für das Semantic Web zu entwickeln bedeutet, Ihre eigenen Daten zu identifizieren, sie zu markieren und dann herauszufinden, wie sie mit anderen Daten verbunden sind. Denn das tut es. Das tut es immer. Und dieser Prozess ist, wie das…
… mit der Zeit wird das …
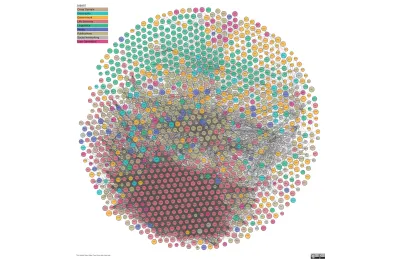
Das zweite Bild ist The Linked Open Data Cloud, eine ständig aktualisierte Visualisierung der verbundenen Daten des Webs. Dieser rote Schwarm von Verbindungen sind die Wissenschaften; der Rest hat noch einiges vor sich. Da kommen wir ins Spiel.
Nützliche Semantic-Web-Ressourcen
- RDF auf w3schools.com
- Der RDF-Validator des W3C
- „Das semantische Web leicht gemacht“ von W3C
- „Was ist mit dem Semantic Web passiert?“ von Two-Bit History
- JSON-LD-Generator
- Markup-Hilfe für strukturierte Daten von Google
Einstecken
Das Ideal des Semantic Web ist die Verbindung. Daten machen, Daten teilen, Daten verlangen. Werden Sie Teil eines Informationsökosystems. Wenn Sie Originaldaten erstellen, großartig. Teilt es. Wenn bereits Daten vorhanden sind und Sie diese verwenden möchten, ziehen Sie sie herein.
Hier sind nur einige der verfügbaren Datenquellen:
- DPpedia
- MusicBrainz
- WorldCat
- ISBNdb
Wo Datenbanken wie diese existieren, würde ich sogar so weit gehen zu sagen, dass es das Richtige wäre, sie dort zu aktualisieren, wo ihnen Informationen fehlen. Warum es für sich behalten? Werden Sie Mitwirkender, ein Verfechter des Semantic Web.
Implementierung
Was den Einbau von Semantic Webness in Ihre Sites angeht, befürworte ich sicherlich kein manuelles, Dokument-für-Dokument-Markup. Wer hat dafür Zeit? Meistens besteht die Lösung darin, ein Format zu standardisieren und dafür Vorlagen zu erstellen.
Templating ist hier die große Chance. Wie viele Leute haben wirklich Zeit, all diese Informationen manuell zu markieren? Wenn Sie jedoch über benutzerdefinierte Eingaben verfügen, erhalten Sie das Beste aus beiden Welten. Inhalte können mit benutzerfreundlichen Informationen gefüllt werden, und die Informationen existieren als Daten, die bereit sind, jedem beliebigen Zweck zu dienen.
Nehmen Sie zum Beispiel einen Static-Site-Generator wie Eleventy, der in letzter Zeit ein wenig Anklang bei der Entwickler-Community gefunden hat. Sie schreiben einen Beitrag, lassen ihn durch eine Vorlage laufen und Sie sind goldrichtig. Warum also nicht semantisches Markup in die Vorlage selbst integrieren?
Wie Eleventy verwendet die neue Version unserer Musik-Webzine-Site Markdown für ihre Posts. Während wir die gleichen alten Textbeiträge wie immer haben, enthält jede Bewertung jetzt auch die folgenden Metadateneingaben, die dann in die Vorlage gezogen werden:
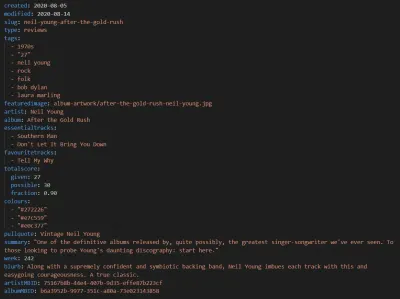
Zusammen mit Autorendetails im Hauptteil des Beitrags und einigen allgemeinen Website-Informationen ergibt dies dann das folgende semantische Markup:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Wo früher nur Text war, gibt es jetzt auf jeder einzelnen Bewertungsseite auch maschinenlesbare Versionen dessen, was die Leser sehen, wenn sie die Seite besuchen. Die Wörter sind alle noch da, der Inhalt hat sich kaum verändert – er wurde nur datengeprüft. Von reichhaltigen Suchergebnissen bis hin zu interaktiven Bewertungsstatistikseiten erweitert dies die Möglichkeiten massiv. Der Weg vor uns ist breit und offen. Es gibt uns auch einen Anteil an der Zukunft von MusicBrainz. Indem wir ihre Daten mit unseren eigenen Daten verbinden, wollen wir wiederum, dass es gut läuft, und werden unseren Teil dazu beitragen, dass dies der Fall ist.
Das geeignete semantische Markup hängt von der Art einer Website ab, aber die Chancen stehen gut, dass es existiert. Beginnen Sie mit den offensichtlichen Eingaben (Datum, Autor, Inhaltstyp usw.) und arbeiten Sie sich in das Unkraut der Inhalte vor. Der erste Schritt könnte so einfach sein wie eine hCard (eine Art digitaler Personalausweis) für Ihre persönliche Website. Drucken Sie Screenshots von Seiten aus und beginnen Sie mit dem Kommentieren. Sie werden erstaunt sein, wie viele Inhalte datengeprüft werden können.
Unvorstellbar
Das Entwerfen und Entwickeln für das semantische Web ist eine Praxis, die auf die Gründungsideale des Internets zurückgeht. Egal, ob Sie eine schöne, informative Datenvisualisierung schätzen, ausgefeiltere Suchergebnisse wünschen, den Netzmonopolen die Macht entziehen möchten oder einfach an freie und offene Informationen glauben, das Semantic Web ist Ihr Verbündeter.
Aaron Swartz schloss sein Manuskript mit einem Aufruf zur Hoffnung:
„Das semantische Web basiert auf Wetten, einer Wette, dass die Bereitstellung von Werkzeugen für die einfache Zusammenarbeit und Kommunikation der Welt zu Möglichkeiten führen wird, die so wunderbar sind, dass wir sie uns derzeit kaum vorstellen können.“
Abstract Wikipedia Denny Vrandecic wiederholt diese Gefühle heute und sagt:
„Es besteht Bedarf an einer Webinfrastruktur, die die Interoperabilität zwischen Diensten erleichtert, was einen gemeinsamen Satz von Standards für die Darstellung von Daten und gemeinsame Protokolle über alle Anbieter hinweg erfordert.“
Das semantische Web hat sich lange genug dahingeschleppt, um klar zu machen, dass eine Wundermittelsprache wahrscheinlich nicht erscheinen wird, aber es gibt jetzt genug friedliche Koexistenz, damit Berners-Lees Gründungstraum für den größten Teil des Webs Wirklichkeit werden kann. Jeder von uns kann Fürsprecher in seiner eigenen Nachbarschaft sein.
Besser sein, besser fordern
Wie Tim Berners-Lee sagte, ist das Semantic Web sowohl eine Kultur als auch eine technische Hürde. In einem TED Talk von 2009 fasste er es schön zusammen: Linked Data machen, Linked Data fordern . Das gilt jetzt mehr denn je. Das World Wide Web ist nur so offen und vernetzt und gut, wie wir es erzwingen. Wann immer Sie etwas online machen, fragen Sie sich: „Wie kann das in das semantische Web integriert werden?“ Die Antworten werden den Dingen, die wir erschaffen, neue Dimensionen hinzufügen und unvorstellbar wunderbare neue Möglichkeiten für die kommenden Jahre schaffen.