
Datenvisualisierung in Python: Grundlegende Diagramme erklärt [mit grafischer Illustration]
Veröffentlicht: 2021-02-08Inhaltsverzeichnis
Grundlegende Gestaltungsprinzipien
Für jeden aufstrebenden oder erfolgreichen Datenwissenschaftler ist es eine sehr wichtige und nützliche Fähigkeit, seine Forschung und Analyse erklären zu können. Hier kommt die Datenvisualisierung ins Spiel. Es ist wichtig, dieses Tool ehrlich zu verwenden, da das Publikum durch schlechte Designentscheidungen sehr leicht falsch informiert oder getäuscht werden kann.
Als Data Scientists haben wir alle bestimmte Verpflichtungen, wenn es darum geht, das zu bewahren, was wahr ist.
Der erste ist, dass wir beim Bereinigen und Zusammenfassen der Daten absolut ehrlich zu uns selbst sein sollten. Die Datenvorverarbeitung ist ein sehr entscheidender Schritt, damit jeder maschinelle Lernalgorithmus funktioniert, und daher führt jede Unehrlichkeit in den Daten zu drastisch unterschiedlichen Ergebnissen.
Eine weitere Verpflichtung besteht gegenüber unserer Zielgruppe. Es gibt verschiedene Techniken in der Datenvisualisierung, die verwendet werden, um bestimmte Datenabschnitte hervorzuheben und einige andere Daten weniger hervorzuheben. Wenn wir also nicht vorsichtig genug sind, kann der Leser die Analyse nicht richtig untersuchen und beurteilen, was zu Zweifeln und mangelndem Vertrauen führen kann.
Sich selbst immer wieder in Frage zu stellen, ist eine gute Eigenschaft für Data Scientists. Und wir sollten immer darüber nachdenken, wie wir auf verständliche und ästhetisch ansprechende Weise zeigen können, was wirklich wichtig ist, und uns gleichzeitig daran erinnern, dass der Kontext wichtig ist.
Genau das versucht Alberto Cairo in seinen Lehren darzustellen. Er erwähnt die fünf Qualitäten großartiger Visualisierungen: schön, aufschlussreich, funktional, aufschlussreich und wahrheitsgemäß , die es wert sind, im Auge behalten zu werden.
Einige grundlegende Diagramme
Nachdem wir nun ein grundlegendes Verständnis der Designprinzipien haben, lassen Sie uns in einige grundlegende Visualisierungstechniken eintauchen, die die Matplotlib- Bibliothek in Python verwenden.
Der gesamte Code unten kann in einem Jupyter-Notebook ausgeführt werden.
%matplotlib-Notizbuch
# Dies stellt eine interaktive Umgebung bereit und legt das Backend fest. ( %matplotlib inline kann auch verwendet werden, ist aber nicht interaktiv. Dies bedeutet, dass alle weiteren Aufrufe von Plotfunktionen unsere ursprüngliche Visualisierung nicht automatisch aktualisieren.)
import matplotlib.pyplot as plt # Importieren des erforderlichen Bibliotheksmoduls
Punktdiagramme
Die einfachste Matplotlib- Funktion zum Zeichnen eines Punkts ist plot() . Die Argumente stellen X- und Y-Koordinaten dar, dann einen Zeichenfolgenwert, der beschreibt, wie die Datenausgabe angezeigt werden soll.
plt.figure()
plt.plot( 5, 6, '+' ) # das + Zeichen dient als Markierung
Streudiagramme
Ein Streudiagramm ist ein zweidimensionales Diagramm. Die scatter()- Funktion nimmt auch den X-Wert als erstes Argument und den Y-Wert als zweites. Das Diagramm unten ist eine diagonale Linie und matplotlib passt die Größe beider Achsen automatisch an. Hier behandelt das Streudiagramm die Elemente nicht als Serie. So können wir für jeden Punkt auch eine Liste mit Wunschfarben angeben.
importiere numpy als np
x = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figure()
plt.scatter( x, y )
Liniendiagramme
Ein Liniendiagramm wird mit der Funktion plot() erstellt und zeichnet eine Reihe verschiedener Datenpunktserien wie ein Streudiagramm, verbindet jedoch jede Punktserie mit einer Linie.
importiere numpy als np
linear_data = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
quadrierte_daten = lineare_daten**2
plt.figure()
plt.plot (linear_data, '-o', squared_data, '-o')
Um das Diagramm besser lesbar zu machen, können wir auch eine Legende hinzufügen, die uns sagt, was jede Linie darstellt. Wichtig ist ein passender Titel für die Grafik und beide Achsen. Außerdem kann jeder Abschnitt des Diagramms mit der Funktion fill_between() schattiert werden , um relevante Bereiche hervorzuheben.
plt.xlabel('X-Werte')
plt.ylabel('Y-Werte')
plt.title('Liniendiagramme')

plt.legend( ['linear', 'squared'] )
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
So sieht das modifizierte Diagramm aus
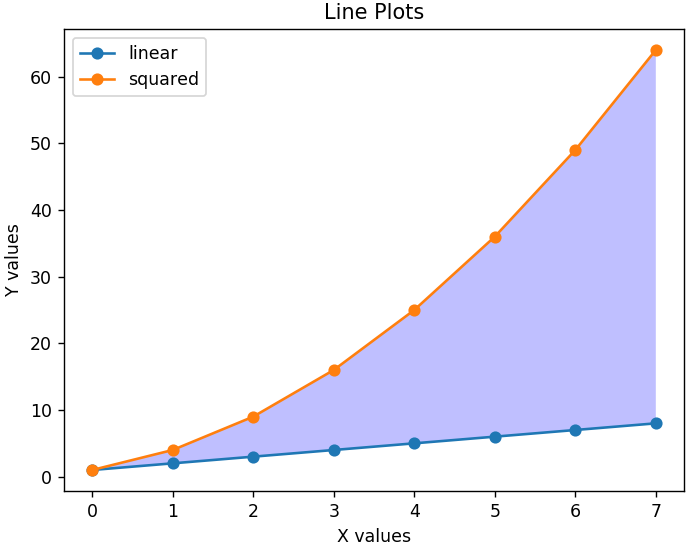
Balkendiagramme
Wir können ein Balkendiagramm zeichnen, indem wir Argumente für die X-Werte und die Höhe jedes Balkens an die Funktion bar() senden . Unten ist ein Balkendiagramm des gleichen linearen Datenarrays, das wir oben verwendet haben.
plt.figure()
x = Bereich ( len ( linear_data ))
plt.bar( x, linear_data )
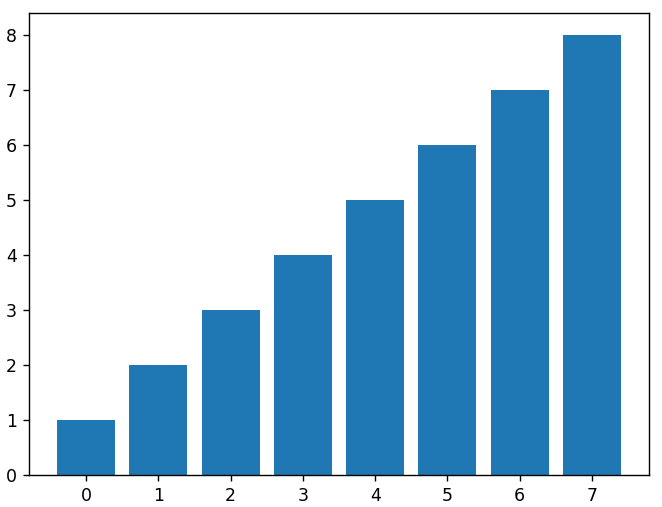
# Um die quadrierten Daten als einen weiteren Balkensatz in demselben Diagramm darzustellen, müssen wir die neuen x-Werte anpassen, um den ersten Balkensatz auszugleichen
neu_x = []
für Daten in x:
new_x.append(data+0.3)
plt.bar(new_x, squared_data, width = 0.3, color = 'green')
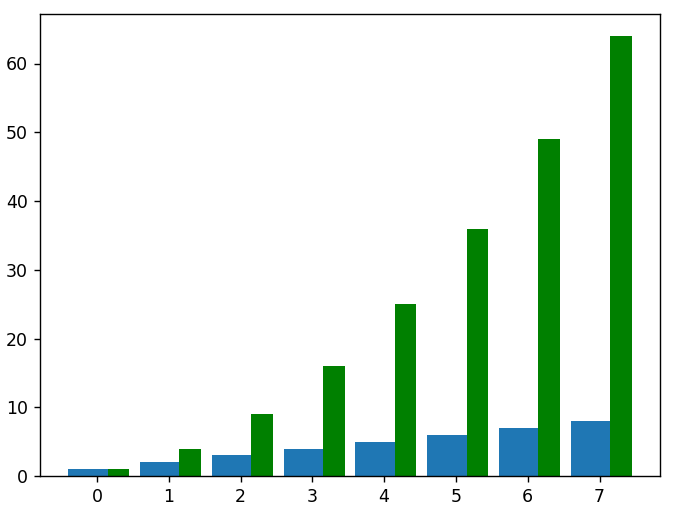
# Für Graphen mit horizontaler Ausrichtung verwenden wir die Funktion barh()
plt.figure()
x = Bereich ( len ( lineare_Daten ))
plt.barh( x, linear_data, Höhe = 0,3, Farbe = 'b')
plt.barh( x, squared_data, height = 0.3, left = linear_data, color = 'g')
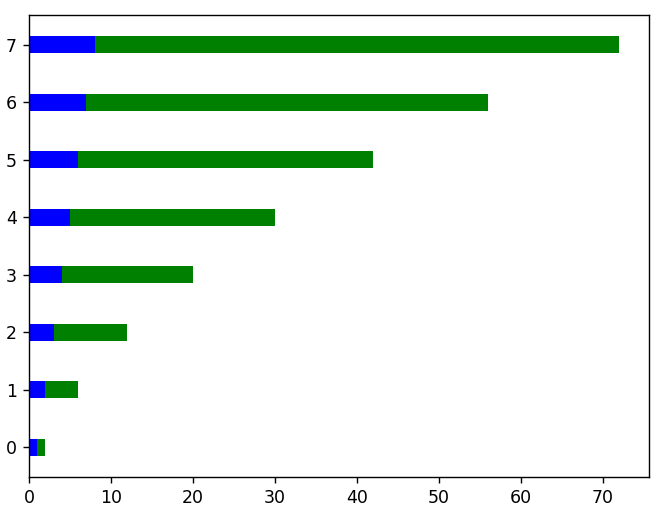
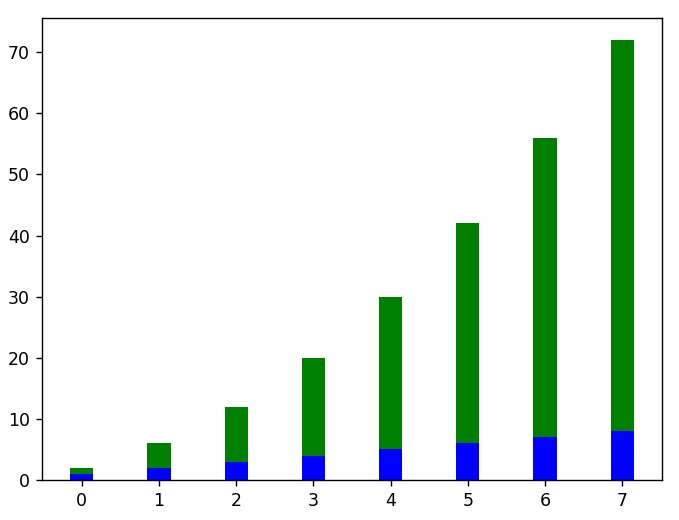
#hier ist ein Beispiel für das vertikale Stapeln von Balkendiagrammen
plt.figure()
x = Bereich ( len ( lineare_Daten ))
plt.bar (x, linear_data, Breite = 0,3, Farbe = 'b')
plt.bar( x, squared_data, width = 0.3, bottom = linear_data, color = 'g')
Lernen Sie Datenwissenschaftskurse von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Fazit
Die Visualisierungstypen enden hier nicht. Python hat auch eine großartige Bibliothek namens Seaborn , die es definitiv wert ist, erkundet zu werden. Die richtige Informationsvisualisierung trägt erheblich dazu bei, den Wert unserer Daten zu steigern. Die Datenvisualisierung wird immer die bessere Option sein, um Einblicke zu gewinnen und verschiedene Trends und Muster zu identifizieren, anstatt langweilige Tabellen mit Millionen von Datensätzen zu durchsuchen.
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das PG Diploma in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1- on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was sind einige nützliche Python-Pakete für die Datenvisualisierung?
Python hat einige erstaunliche und nützliche Pakete für die Datenvisualisierung. Einige dieser Pakete sind unten aufgeführt:
1. Matplotlib – Matplotlib ist eine beliebte Python-Bibliothek, die für die Datenvisualisierung in verschiedenen Formen wie Streudiagrammen, Balkendiagrammen, Tortendiagrammen und Liniendiagrammen verwendet wird. Es verwendet Numpy für seine mathematischen Operationen.
2. Seaborn – Die Seaborn-Bibliothek wird für statistische Darstellungen in Python verwendet. Es wurde auf der Basis von Matplotlib entwickelt und ist in Pandas Datenstrukturen integriert.
3. Altair – Altair ist eine weitere beliebte Python-Bibliothek für die Datenvisualisierung. Es ist eine deklarative statistische Bibliothek, die es Ihnen ermöglicht, Visuals mit minimal möglicher Codierung zu erstellen.
4. Plotly - Plotly ist eine interaktive und Open-Source-Datenvisualisierungsbibliothek von Python. Die von dieser browserbasierten Bibliothek erstellten visuellen Elemente werden von vielen Plattformen wie Jupyter Notebook und eigenständigen HTML-Dateien unterstützt.
Was wissen Sie über Punktdiagramme und Streudiagramme?
Die Punktdiagramme sind die grundlegendsten und einfachsten Diagramme für die Datenvisualisierung. Ein Punktdiagramm zeigt die Daten in Form von Punkten auf einer kartesischen Ebene an. Das „+“ zeigt den Anstieg des Wertes, während „-“ den Abfall des Wertes im Laufe der Zeit anzeigt.
Ein Streudiagramm hingegen ist ein optimiertes Diagramm, bei dem die Daten auf einer 2-D-Ebene visualisiert werden. Es wird mit der Funktion scatter() definiert, die den x-Achsenwert als ersten Parameter und den y-Achsenwert als zweiten Parameter verwendet.
Was sind die Vorteile der Datenvisualisierung?
Die folgenden Vorteile zeigen, wie Datenvisualisierungen zum wahren Helden für das Wachstum einer Organisation werden können:
1. Die Datenvisualisierung erleichtert die Interpretation der Rohdaten und ihr Verständnis für die weitere Analyse.
2. Nach der Recherche und Analyse der Daten können die Ergebnisse anhand aussagekräftiger Visualisierungen dargestellt werden. Dies erleichtert es, mit dem Publikum in Kontakt zu treten und die Ergebnisse zu erklären.
3. Eine der wichtigsten Anwendungen dieser Technik ist die Analyse von Mustern und Trends, um Vorhersagen und potenzielle Wachstumsbereiche abzuleiten.
4. Es ermöglicht Ihnen auch, die Daten nach Kundenpräferenzen zu trennen. Sie können auch die Bereiche identifizieren, die mehr Aufmerksamkeit erfordern.