
13 spannende Data-Science-Projektideen und -themen für Anfänger [2022]
Veröffentlicht: 2021-06-22Inhaltsverzeichnis
Ein Ausdruck zu Data-Science-Projektideen
Data Science entwickelt sich kontinuierlich zu einer großartigen Karriereoption für diese Generation. Es gehört zu den vielversprechendsten und interessantesten Entscheidungen überhaupt. Der Markt wächst mit steigender Nachfrage nach Data Scientists. Kürzlich wurde berichtet, dass die Nachfrage in den kommenden Jahren um ein Vielfaches zunehmen wird. Wenn Sie also ein Data-Science-Anfänger sind, ist das Beste, was Sie tun können, an einigen Echtzeit- Data-Science-Projektideen zu arbeiten.
Wenn Sie also ein aufstrebender Datenwissenschaftler sind, wird dringend empfohlen, Fähigkeiten zu üben, um ein effizienter Fachmann für diesen Bereich zu werden. Nachdem Sie sich einige sehr gute theoretische Kenntnisse über Data Science angeeignet haben, ist es jetzt an der Zeit, einige praktische Projekte durchzuführen, wenn Sie wirklich nach vorne schauen, um herauszufinden, wie es scheint, ein Profi zu sein.
Sie müssen einige der technischen und Echtzeit- Data-Science-Projekte durchführen , damit Sie Ihr Karrierewachstum vorantreiben können. Je mehr Sie mit Data-Science-Projekten üben , desto mehr können Sie mithalten, um ein solider Data-Science-Profi zu werden.
Wenn Sie also einige Live -Data-Science-Projekte durchführen , wird dies Ihr Wissen, Ihre technischen Fähigkeiten und Ihr allgemeines Selbstvertrauen verbessern. Aber am wichtigsten ist, dass es für Sie viel einfacher ist, einen guten Job zu bekommen, wenn Sie auch nur ein paar Data-Science-Projekte in Ihrem Lebenslauf präsentieren. Warum so? Denn dann weiß der Interviewer, dass Sie eine Data-Science-Karriere wirklich ernst meinen.
Ihre Echtzeit-Erfahrung bei Live- Data-Science-Projekten gibt Ihnen einen starken Überblick über Data-Science-Trends und -Technologien. Legen Sie also Ihre Hände auf Echtzeit- Data-Science-Projekte und Sie werden wissen, wie vorteilhaft dies für Ihr schnelles Karrierewachstum sein wird. Nach all diesen Diskussionen wissen wir, dass Sie die Suche nach der perfekten Data-Science-Projektidee für Ihr Data-Science-Projekt noch mehr beschäftigt als die tatsächliche Umsetzung.
In diesem Data-Science-Blog haben wir die Namen einiger Data-Science-Projektideen aufgelistet . Und um Ihre Frage zu beantworten – „Welche Art von Data-Science-Projekt ist gut, um damit anzufangen?“, haben wir ein paar gute Ideen für Data-Science-Projekte zusammengestellt, aus denen Sie auswählen können.
Keine Programmiererfahrung erforderlich. 360° Karriereunterstützung. PG-Diplom in maschinellem Lernen und KI von IIIT-B und upGrad.
Hier sind 50 Data-Science-Projektideen für Sie, und im nächsten Blog besprechen wir einige dieser Projekte im Detail. Fangen wir also an!
- Chatbot
- Analyse der Auswirkungen des Klimawandels auf die globale Nahrungsmittelversorgung
- Wettervorhersage
- Keyword-Generierung für Google-Anzeigen
- Verkehrszeichenerkennung
- Analyse der Weinqualität
- Börsenprognose
- Erkennung gefälschter Nachrichten
- Videoklassifizierung
- Erkennung menschlicher Handlungen
- Erstellung medizinischer Berichte mit CT-Scans
- E-Mail-Klassifizierung
- Uber-Datenanalyse
- Klangklassifizierung
- Erkennung von Kreditkartenbetrug
- Gebärdenspracherkennung
- Klasse der Blumenvorhersage
- Farberkennung
- Kreditprognose
- Vorhersage des Straßenverkehrs
- Einkommensklassifizierung
- Sprache Emotionserkennung
- Promi-Stimmenvorhersage
- Verkaufsvorhersage speichern
- Parkinson-Krankheit erkennen
- Vorhersage der Luftverschmutzung
- Alters- und Geschlechtserkennung
- Optimierung des Produktpreises
- IMDB-Vorhersagen
- Handschriftliche Ziffernerkennung
- Quora Unaufrichtige Fragen-Klassifizierung
- Fahrermüdigkeitserkennung
- Vorhersage von Web-Traffic-Zeitreihen
- Überlebensvorhersage auf der Titanic
- Zeitreihenmodellierung
- Bildunterschrift-Generator
- Vorhersage des Versicherungskaufs
- Kriminalanalyse
- Kundensegmentierung
- Vorhersage der Taxifahrtzeit
- Job-Empfehlungssystem
- Vorhersagen für Bostoner Immobilien
- Stimmungsanalyse
- Zinsniveau in Mietobjekten
- Keyword-Generierung für Google Ads
- Brustkrebs-Klassifikation
- Anforderungen an den Computerzugriff der Mitarbeiter
- Tweets-Klassifizierung
- Filmempfehlungssystem
- Produktpreisvorschläge
Neueste Ideen für Data Science-Projekte
Wir haben alle Data Science-Projektideen nach dem Niveau des Lernenden segmentiert. Daher erhalten Sie eine Liste mit einigen erstaunlichen Projektbeschreibungen für Anfänger, Fortgeschrittene und fortgeschrittene Data Science-Projektideen .
1. Anfängerstufe | Ideen für Data Science-Projekte
Diese Liste mit Data-Science-Projektideen für Studenten eignet sich für Anfänger und diejenigen, die gerade erst mit Python oder Data Science im Allgemeinen beginnen. Diese Data-Science-Projektideen bringen Sie mit allen praktischen Aspekten in Schwung, die Sie für eine erfolgreiche Karriere als Data-Science-Entwickler benötigen.
Wenn Sie außerdem nach Data-Science-Projektideen für das Abschlussjahr suchen, sollte Sie diese Liste in Schwung bringen. Lassen Sie uns also ohne weiteres auf einige datenwissenschaftliche Projektideen eingehen , die Ihre Basis stärken und es Ihnen ermöglichen, die Leiter nach oben zu klettern.
1.1 Auswirkungen des Klimawandels auf die globale Nahrungsmittelversorgung
Häufig Klimawandel und Unregelmäßigkeiten sind große herausfordernde Umweltprobleme. Diese Unregelmäßigkeiten in den Klimazonen wirken sich drastisch auf das Leben der Menschen auf der Erde aus. Dieses Data-Science-Projekt konzentriert sich darauf, wie die Auswirkungen des Klimawandels die globale Nahrungsmittelproduktion weltweit stark beeinflussen werden und wie stark die Quantifizierung den Klimawandel beeinflussen wird.
Das Hauptziel der Entwicklung für dieses Projekt ist die Berechnung der Potenziale für die Produktion von Grundnahrungsmitteln aufgrund des Klimawandels. Durch dieses Projekt ändern sich alle Auswirkungen in Bezug auf Temperaturen und Niederschlag. Es wird dann berücksichtigt, wie viel Kohlendioxid das Pflanzenwachstum beeinflusst und welche Unsicherheiten bei der klimatischen Konditionierung auftreten. Daher wird sich dieses Projekt hauptsächlich mit Datenvisualisierungen befassen. Es wird auch die Produktion in verschiedenen Regionen in verschiedenen Zeitzonen verglichen.
1.2 Erkennung gefälschter Nachrichten
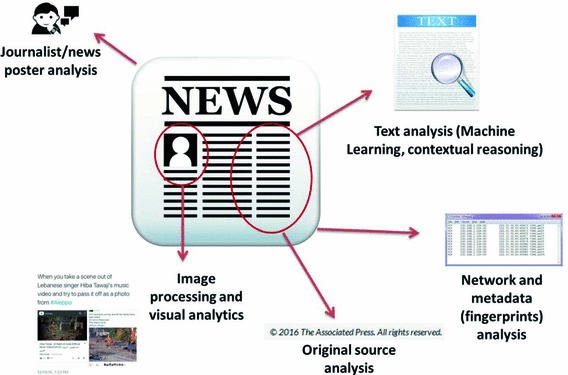
Quelle
Sie können Ihre Data-Science-Karriere mit dieser erstaunlichen Data-Science-Projektidee für Anfänger vorantreiben – Erkennung gefälschter Nachrichten mithilfe der Python-Sprache. Der Akt von falschem oder irreführendem Journalismus auf einer digitalen Plattform oder Fake News kann durch dieses Projekt erkannt werden. Fälschungen verbreiten sich über Social-Media-Plattformen und Online-Kanäle und digitale Medien, um jede politische Agenda zu erreichen.
Mit dieser datenwissenschaftlichen Projektidee können Sie die Python-Sprache verwenden, um ein spezifisches Modell zu entwickeln, das genau erkennen kann, ob es sich bei den Nachrichten um echten Journalismus oder um falsche Informationen handelt. Dazu müssen Sie einen „TfidfVectorizer“-Klassifikator erstellen und dann einen „PassiveAggressiveClassifier“ verwenden ', um die Nachrichten entweder in "echte" und "falsche" Segmente zu klassifizieren. Es wird einen Datensatz mit der Form von 7796 × 4-Abmessungen geben und alle diese im 'JupyterLab' ausführen.
Die Hauptidee dieses Data-Science-Projekts besteht darin, ein maschinelles Lernmodell in Echtzeit zu entwickeln, das die Authentizität von Social-Media-Nachrichten korrekt erkennen kann. 'TF', allgemein bekannt als 'Term Frequency', ist die Gesamthäufigkeit, mit der ein Wort in einem einzelnen Dokument vorkommt. Während „IDF“ oder „Inverse Document Frequency“ ein rechnerisches Maß für den Wert eines Wortes ist und auf der Reputationshäufigkeit seines Vorkommens in den verschiedenen Dokumenten basiert.
Die Theorie basiert auf den „gebräuchlichen Wörtern“, wenn diese gebräuchlichen Wörter zufällig in mehreren Dokumenten mit hoher Häufigkeit vorkommen, werden sie als weniger wichtige Wörter betrachtet. Was also „TFIDFVectorizer“ tut, ist die Sammlung dieser Dokumente zu analysieren und dann entsprechend eine „TF-IDF“-Matrix dafür zu erstellen.
Außerdem bleibt ein „Passiv-Aggressiv“-Klassifikator „passiv“, falls das „Klassifizierungsergebnis“ korrekt ist; aber andererseits wird es sich aggressiv ändern, wenn das „Klassifizierungsergebnis“ falsch ist. Sie können also mit dieser Idee des Data Science-Projekts ein Modell für maschinelles Lernen erstellen, um Social-Media-Nachrichten als echte oder gefälschte Nachrichten zu erkennen.
1.3 Erkennung menschlicher Handlungen
Dies ist ein Data-Science-Projekt zum Modell der menschlichen Aktionserkennung. Es wird sich die kurzen Videos ansehen, die von Menschen gemacht wurden, in denen sie bestimmte Aktionen ausführen. Dieses Modell versucht, eine Klassifizierung vorzunehmen, die auf durchgeführten Aktionen basiert. In diesem Data-Science-Projekt müssen Sie ein komplexes neuronales Netzwerk verwenden. Dieses neuronale Netz wird dann mit einem bestimmten Datensatz trainiert, der diese kurzen Videos enthält. Dann gibt es Beschleunigungsmesserdaten, die dem Datensatz zugeordnet sind. Die Datenumwandlung des Beschleunigungsmessers erfolgt zuerst zusammen mit einer "zeitgeschnittenen" Darstellung. Danach müssen Sie die „ Keras “-Bibliothek verwenden, damit Sie das Netzwerk basierend auf diesen Datensätzen trainieren, validieren und testen können.
1.4 Waldbrandvorhersage
Eine der alarmierenden und häufigen Katastrophen in der heutigen Welt sind Waldbrände. Diese Katastrophen schaden dem Ökosystem in hohem Maße. Um mit einer solchen Katastrophe fertig zu werden, wird viel Geld für Infrastruktur & Steuerung und Abwicklung benötigt. Wir können ein Data-Science-Projekt mit „k-Means-Clustering“ erstellen – es kann alle Hotspots von Waldbränden zusammen mit der Schwere des Feuers an dieser bestimmten Stelle identifizieren.
Es kann alternativ für eine bessere Ressourcenzuweisung mit der schnelleren Antwortzeit verwendet werden. Daher kann die Verwendung meteorologischer Daten wie der Jahreszeiten, in denen diese Art von Brandtragödien wahrscheinlicher sind, und verschiedener Wetterbedingungen, die sie verschlimmern, die Genauigkeit dieser Ergebnisse erhöhen.
1.5 Fahrspurlinienerkennung
Eine weitere Data-Science-Projektidee für Anfänger umfasst ein in Python integriertes Live-Lane-Line-Detection-System. In diesem Projekt erhält ein menschlicher Fahrer durch auf der Straße gezeichnete Linien eine Anleitung zur Fahrspurerkennung.
Darüber hinaus bezieht es sich darauf, in welche Richtung der Fahrer sein Fahrzeug lenken soll. Diese Anwendung des Data Science Project ist für die Entwicklung fahrerloser Autos von entscheidender Bedeutung. Daher können Sie auch eine Anwendung mit der leistungsstarken Fähigkeit entwickeln, eine Spurlinie durch die Eingabebilder oder über einen kontinuierlichen Videorahmen zu identifizieren.
Lesen Sie: Top 4 Datenanalyse-Projektideen: Anfänger- bis Expertenebene
2. Ideen für Data Science-Projekte | Mittelstufe
2.1 Erkennung von Sprachemotionen
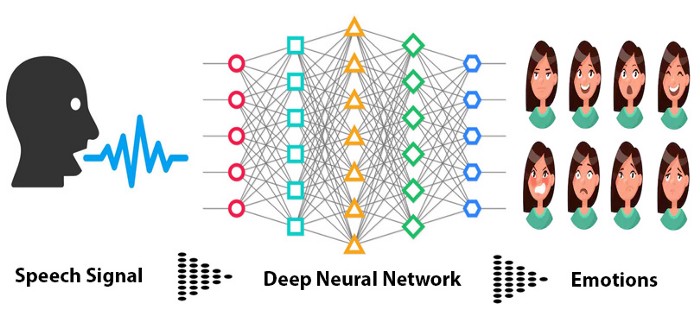
Quelle
Eine der beliebten Data-Science-Projektideen ist die Erkennung von Sprachemotionen. Wenn Sie die Verwendung verschiedener Bibliotheken lernen möchten, ist dieses Projekt perfekt für Sie. Sie müssen viele Editor-Tools gesehen haben, die uns sagen können, wie unsere Sprach-Emotion erscheint. Dieses Programmmodell kann als Data Science-Projekt erstellt werden.
In diesem Data-Science-Projekt werden wir „librosa“ verwenden, das eine „Speech Emotion Recognition“ für uns durchführt. Der SER-Prozess ist ein Versuchsprozess, der menschliche Emotionen erkennen kann. Es kann auch die Sprache aus den affektiven Zuständen erkennen. Da wir eine Kombination aus einem Ton und einer Tonhöhe verwenden, um Emotionen durch unsere Stimme auszudrücken.

Das Speech Emotion Recognition-Modell ist absolut möglich. Es kann jedoch ein herausforderndes Projekt sein, da menschliche Emotionen sehr subjektiv sind. Die Annotation des menschlichen Audios ist ebenfalls eine ziemliche Herausforderung. Hier verwenden Sie also die mfcc-, mel- und die Chroma-Funktionen. Damit verwenden Sie auch den als "RAVDESS" bekannten Datensatz für den Emotionserkennungsprozess. In diesem Data-Science-Projekt lernen Sie auch, wie Sie einen „MLPClassifier“ für dieses Modell entwickeln.
2.2 Geschlechts- und Alterserkennung mit Data Science

Quelle
Eine der beeindruckenden Projektideen zu Data Science ist also die „Geschlechts- und Alterserkennung mit OpenCV“. Mit dieser Art von Echtzeitprojekt können Sie in einem Data-Science-Interview ganz einfach die Aufmerksamkeit Ihres Personalvermittlers auf sich ziehen.
Apropos Projekt: „Geschlechts- und Alterserkennung“ ist ein maschinelles Lernprojekt, das auf Computer Visioning basiert. Durch dieses Data Science-Projekt können Sie die praktische Anwendung von CNN, dh den Convolutional Neural Networks, erlernen. Später werden Sie auch Modelle verwenden, die von „Tal Hassner“ und „Gil Levi“ für den „Adience“-Datensatz trainiert wurden.
Daneben verwenden Sie auch einige Dateien wie – .pb-, .prototxt-, .pbtxt- und .caffemodel-Dateien. Haben Sie von diesen Begriffen gehört? Lesen Sie mehr über diese Dateien? Modelle auch verstehen? Aber wissen Sie, wie man sie umsetzt? Nun, Sie können es lernen, wenn Sie sich dafür entscheiden, ein Data Science-Projekt darauf zu entwickeln.
Es ist ein sehr praktisches Projekt, da Sie ein Modell erstellen, das das Alter und Geschlecht jedes Menschen durch Analysen der Einzelgesichtserkennung über ein Bild erkennen kann. So kann mit dieser Geschlechtseinteilung in einen Mann oder eine Frau eingeordnet werden. Auch das Alter kann in die Bereiche 0-2/ 4-6/ 8-2/ 15-20/ 25-32/ 38-43/ 48-53/ 60-100 eingeteilt werden.
Aber aufgrund verschiedener Faktoren wie Make-up, hellerer Beleuchtung oder einem ungewöhnlichen Gesichtsausdruck kann die Erkennung des Geschlechts und des Alters aus einer einzigen Quelle schwierig werden. Daher verwenden Sie in diesem Data-Science-Projekt ein Klassifizierungsmodell anstelle eines Regressionsmodells. Sie können viel praktisches und technisches Lernen lernen, um Ihre technischen Fähigkeiten mit dieser Art von Projekten zu verbessern. Nehmen Sie also die Herausforderung an und arbeiten Sie hart daran, einen beeindruckenden Data Science-Lebenslauf zu erstellen.
2.3 Fahrermüdigkeitserkennung in Python
Eine hervorragende Data-Science-Projektidee für Fortgeschrittene ist das „Keras & OpenCV Drowsiness Detection System“. Nachts zu fahren ist nicht nur anstrengend, sondern auch riskant. Wir haben von vielen Fällen gehört, in denen Unfälle passieren, weil der Fahrer während der Fahrt eingeschlafen ist.
Somit kann dieses Projekt dazu beitragen, zahlreiche Verkehrsunfälle zu verhindern, die auf solche Fälle zurückzuführen sind. Das Hauptziel dieses Projekts ist es, zu erkennen, wann der Fahrer während der Fahrt schläfrig werden und einschlafen könnte. Dieses Projekt verwendet die Python-Sprache, in der Sie ein Modell erstellen können, das das schläfrige Fahrerverhalten rechtzeitig erkennen und durch einen hohen Piepton einen Alarm auslösen kann.
In diesem Projekt können Sie ein „Deep-Learning-Modell“ implementieren und mit seiner Verwendung eine Klassifizierung zwischen Bildern vornehmen, bei denen ein menschliches Auge geöffnet oder geschlossen ist. Nicht nur das, in diesem Modell ist eine weitere Formelzeile, um die Punktzahl zu berechnen.
Diese Punktzahl basiert auf dem Zeitraum, in dem die Augen geschlossen bleiben. Die Punktzahl wird während der gesamten Fahrsitzung beibehalten. Wenn diese Punktzahl steigt und einen bestimmten Schwellenwert überschreitet, löst dieses Modell eine Workflow-Automatisierung aus, durch die der Alarm stark zu summen beginnt.
Mit dieser Art von Data-Science-Projektimplementierungen lernen Sie also alle Grundlagen von Data-Science-Projekten. Sie implementieren es mit 'Keras' und 'OpenCV'. Also, warum werden diese verwendet? Nun, Sie verwenden 'OpenCV', um Gesichts- und Augenbewegungen zu erkennen. Während Sie mit „Keras“ den Zustand des Auges klassifizieren können, ob es offen oder geschlossen ist, indem Sie Techniken des Deep Neural Network verwenden.
Data Science Advanced-Zertifizierung, über 250 Einstellungspartner, über 300 Lernstunden, 0 % EMI
2.4 Chatbots

Quelle
Chatbots werden heutzutage immer beliebter. Für ein Data-Science-Projekt ist dies also eine hohe On-Demand-Anforderung von fast allen Organisationen. Heutzutage ist es ein wesentlicher Teil des Geschäfts. Heutzutage spielen Chatbots eine sehr wichtige Rolle in Unternehmen. Sie helfen den Geschäftsbereichen, eine enorme Zeitersparnis bei ihren Personalressourcen zu erzielen. Es wird verwendet, um gleichzeitig einen verbesserten und personalisierten Geschäftsservice bereitzustellen.
Es gibt viele Unternehmen, die ihren Kunden Dienstleistungen anbieten. Um Kundenservice in großem Umfang bereitzustellen, sind viel Personal, viel Zeit und viele Anstrengungen erforderlich, um jeden Kunden pünktlich zu bearbeiten. Andererseits können diese Chatbots eine Automatisierung für Kundeninteraktionsdienste bereitstellen, indem sie einfach eine Reihe häufig gestellter Fragen beantworten, die von den Kunden häufig gestellt werden.
Heutzutage sind zwei Arten von Chatbots verfügbar: Domain-spezifischer Chatbot und Open-Domain-Chatbot. Der domänenspezifische Chatbot wird am häufigsten für eine bestimmte Problemlösung eingesetzt. Diese werden auf sehr strategische und intelligente Weise angepasst, sodass sie in Bezug auf Domänenspezifikationen strategisch und effektiv arbeiten. Der zweite, „Open-Domain“-Chatbots, benötigt viele Schulungsmaterialien, die zu kontinuierlich sind, da er, wie der Name schon sagt, entwickelt wurde, um jede Art von Frage zu beantworten.
Technisch gesehen werden die Chatbots mit den „Deep Learning“-Techniken trainiert. Sie brauchen einen Datensatz mit Vokabellisten, Listen bestehend aus einem gemeinsamen Satz, einer dahinter stehenden Absicht und dann den passenden Antworten. Dies ist eine der Trendideen für Data-Science-Projekte.
Die 'Recurring Neural Networks' (The RNN's) sind die gängigen Methoden zum Trainieren von Chatbots. Diese Bots enthalten Encoder, die die Zustände gemäß den Eingabesätzen neben der Absicht aktualisieren können. Anschließend übergibt es den angegebenen Zustand an den Chatbot.
Danach verwendet der Chatbot den Decoder, um eine passende und nachfolgende Antwort gemäß den eingegebenen Wörtern und auch neben der Absicht zu suchen. Mit diesem Data Science-Projekt können Sie die Implementierung der Python-Sprache leicht erlernen, da das gesamte Projekt selbst in Python erstellt wird. Sie können Ihre technischen Python-Fähigkeiten bis zu einem gewissen Grad verbessern.
Lernen: Wie man Schritt für Schritt einen Chatbot in Python erstellt
2.5 Projekt zur handschriftlichen Ziffern- und Zeichenerkennung
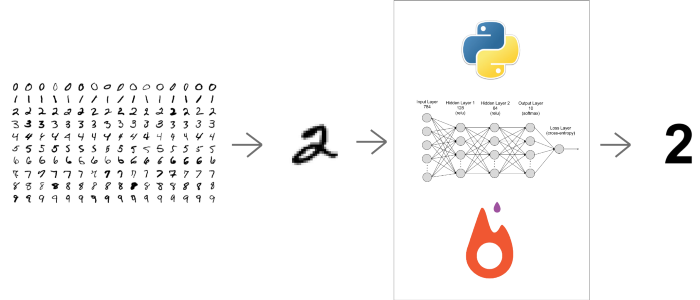
Quelle
Mit dieser Data-Science-Projektidee zum Thema „Handschriftliche Ziffern- und Zeichenerkennung mit Hilfe von CNN“ lernen Sie Deep-Learning-Konzepte praktisch kennen. Wenn Sie also ein angehender Data Scientist oder ein Enthusiast des maschinellen Lernens sind, dann ist dies die perfekte Data Science-Projektidee für Sie. Für diese Projektentwicklung verwenden Sie den „MNIST-Datensatz“ handgeschriebener Ziffern. Dies ist ein großartiges Projekt, um praktische Erfahrungen mit Data Science zu sammeln, da Sie erstaunliche Möglichkeiten kennenlernen werden, die am Prozess der Projekterstellung beteiligt sind.
Wie bereits erwähnt, wird dieses Projekt durch die „Convolutional Neural Networks“ implementiert. Danach erstellen Sie für eine Echtzeitvorhersage eine kreative, grafikbasierte Benutzeroberfläche zum Zeichnen von Ziffern auf der Leinwand, und danach erstellen Sie ein Modell, das für die Vorhersage der Ziffern verwendet wird.
Der Fokus des Projekts liegt auf der Entwicklung der Fähigkeiten des Computers und der Stärkung des Computersystems, damit es Zeichen in handgeschriebenen Formaten von Menschen erkennen kann. Es wird es dann weiter auswerten, um es mit angemessener Genauigkeit zu verstehen. Mit dieser Projektdurchführung können Sie die praktische Umsetzung der 'Keras'- und auch 'Tkinter'-Bibliotheken erlernen.
Dies sind einige Ideen für Data Science-Zwischenprojekte, an denen Sie arbeiten können. Wenn Sie trotzdem Ihr Wissen testen und knifflige Projekte übernehmen möchten
3. Ideen für Data Science-Projekte auf fortgeschrittenem Niveau
3.1 Projekt zur Erkennung von Kreditkartenbetrug
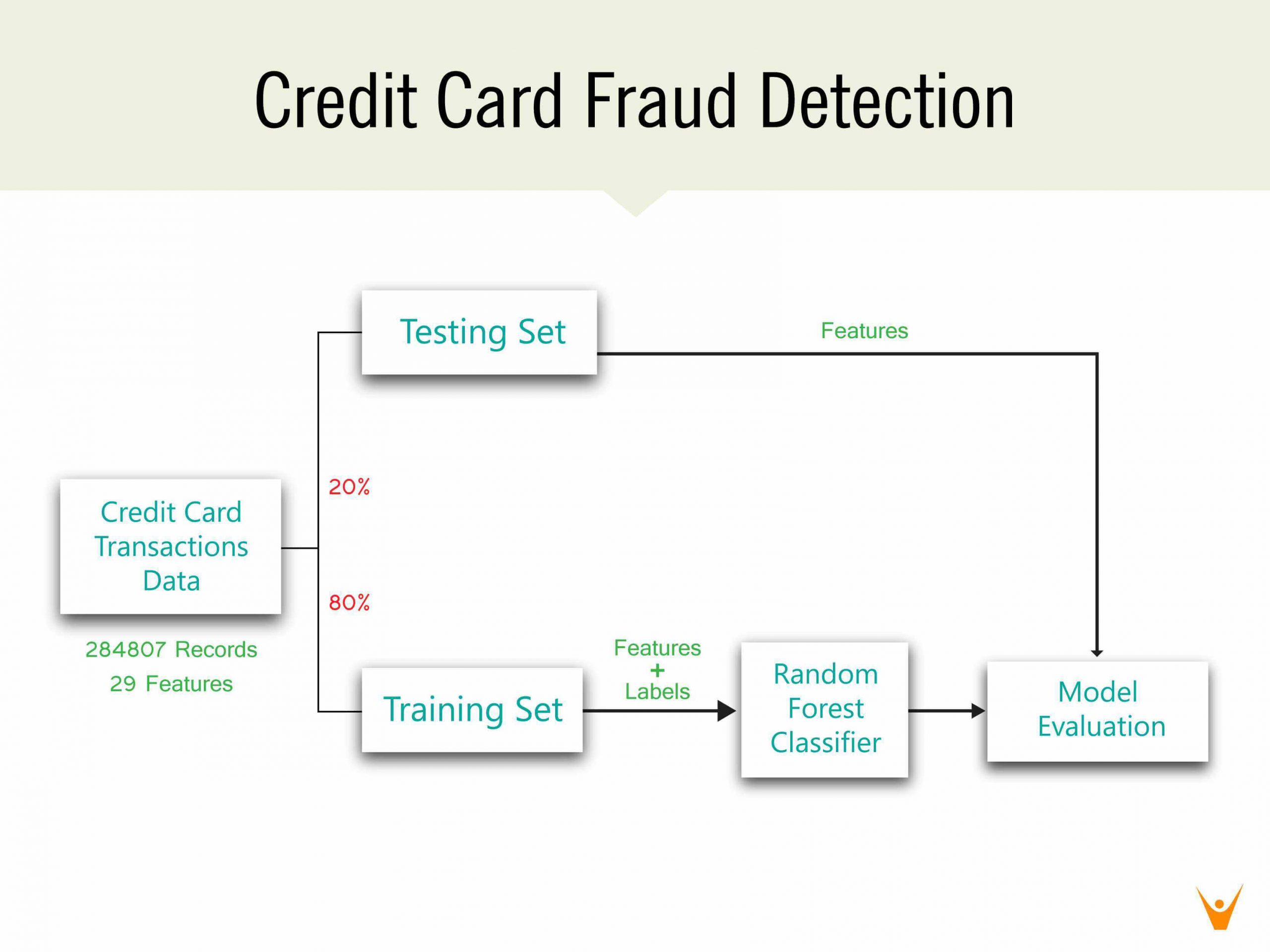
Quelle
Nachdem Sie einfache Projekte implementiert haben, können Sie jetzt zu einigen fortgeschrittenen Data Science-Projektideen übergehen, um mehr Konzepte zu lernen. Eine solche Idee ist die Erkennung von Kreditkartenbetrug. Mit diesem Projekt lernen Sie, wie Sie das R mit verschiedenen Algorithmen wie Decision Tree, Artificial Neural Networks, Logistic Regression und dem Gradient Boosting Classifier verwenden.
Sie können auch lernen, die Datensätze „Kartentransaktionen“ zu verwenden, um die Kreditkartentransaktion als betrügerische Aktivität oder echte Transaktion zu klassifizieren. Sie werden auch lernen, alle verschiedenen Arten von Modellen zusammen mit der Plot-Leistungskurve für alle anzupassen. Dies ist eine der besten Data-Science-Projektideen, die man finden kann.
3.2 Kundensegmentierung
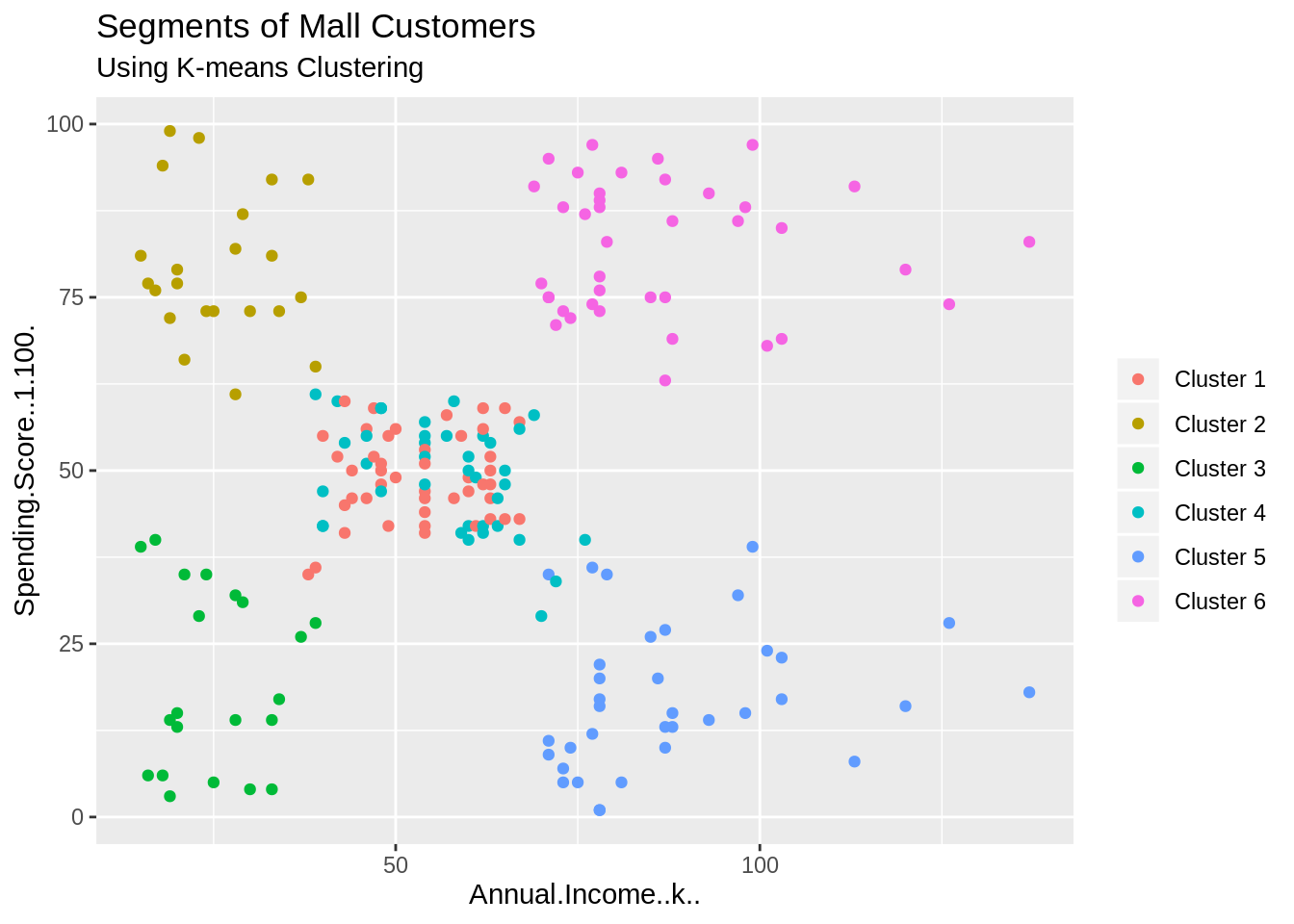
Quelle
Dies ist eines der beliebtesten Data-Science-Projekte im Bereich Data Science. Digitales Marketing ist heutzutage eine fortschrittliche Methode, um ein Publikum für die Unternehmen durch ihre Online-Marketingaktivitäten für Marketingzwecke anzusprechen. Bevor also eine Marketingkampagne durchgeführt wird, erfolgt zunächst eine unterschiedliche Kundensegmentierung.
Die Kundensegmentierung gehört zu den sehr beliebten Anwendungen des tatsächlich unüberwachten Lernens. Hiermit können Unternehmen nun mithilfe von Clustering-Methoden die verschiedenen Segmente der Kunden leicht identifizieren, um die potenzielle Nutzerbasis gezielt anzusprechen. Es werden Einteilungen nach Kunden vorgenommen & Gruppen werden nach gemeinsamen Merkmalen wie Geschlecht, Interessengebieten, Alter und Gewohnheiten gebildet.
Anhand dieser Angaben können sie jede Kundengruppe effektiv vermarkten. Das Projekt verwendet das „K-Means-Clustering“ und Sie lernen, wie Sie Visualisierungen zu Verteilungen wie Geschlecht und Alter durchführen. Auch Jahreseinkommen und durchschnittliche Score-Werte der Kunden können analysiert werden.
3.3 Verkehrszeichenerkennung

Quelle
Dieses Projekt zielt darauf ab, ein Modell zu entwickeln, um eine hohe Genauigkeit in selbstfahrenden Autotechnologien unter Verwendung von CNN-Techniken zu erreichen. Verkehrszeichen und Verkehrsregeln sind für jeden Autofahrer von größter Bedeutung und müssen beachtet werden, um Unfälle zu vermeiden. Um diese Regeln zu befolgen, muss der Benutzer verstehen, wie die Verkehrszeichen zu sein scheinen.
Es ist eine allgemeine Regel, dass eine Person alle Fahrsignale lernen muss, um einen Führerschein zu erhalten. Aber für autonome Fahrzeuge gibt es Programme, die entwickelt wurden, wie die „Verkehrszeichenerkennung“ mit CNN, wo Sie lernen können, wie man ein Modell programmiert, das verschiedene Arten von Verkehrszeichen durch die Eingabe eines Bildes genau identifizieren kann.
Es gibt einen Datensatz namens „Deutscher Verkehrszeichenerkennungs-Benchmark“. Es ist allgemein als GTSRB bekannt, das bei der Entwicklung eines Deep Neural Network verwendet wird, um die Klasse aller Verkehrszeichen zu erkennen, die zu welchem Klassentyp gehören. Sie lernen auch praktisches Wissen zum Erstellen einer GUI für die Anwendungsinteraktion.
Mehr wissen: 10 spannende Python-GUI-Projekte und -Themen für Anfänger
Endeffekt
In diesem Artikel haben wir die besten Data-Science-Projektideen behandelt. Wir haben mit einigen Anfängerprojekten begonnen, die Sie mit Leichtigkeit lösen können. Wenn Sie mit diesen einfachen Data-Science-Projekten fertig sind, schlage ich vor, dass Sie zurückgehen, ein paar weitere Konzepte lernen und dann die Zwischenprojekte ausprobieren.
Wenn Sie sich sicher fühlen, können Sie die fortgeschrittenen Projekte angehen. Wenn Sie Ihre datenwissenschaftlichen Fähigkeiten verbessern möchten, müssen Sie diese datenwissenschaftlichen Projektideen in die Hände bekommen. Machen Sie jetzt weiter und testen Sie all das Wissen, das Sie in unserem Leitfaden zu Data-Science-Projektideen gesammelt haben, um Ihr ganz eigenes Data-Science-Projekt aufzubauen!
Wir wünschen uns, dass Sie mit den Projektideen, die wir Ihnen hier in diesem Blog vorgestellt haben, alle Fähigkeiten von Data Science drastisch verbessern. Aber falls Sie neu im Bereich Data Science sind und Data Science lernen und ähnliche Modelle für den technologischen Fortschritt erstellen möchten, empfehlen wir Ihnen, sich den Online-Kurs zu den PG-Diploma-Programmen von upGrad & IIIT-B anzusehen, um zu lernen und sich weiterzubilden in der Welt der Datenwissenschaft mit erfahrenen und erfahrenen Fachleuten.
Mit den richtigen Kenntnissen, Anleitungen und Tools können Sie jedes Data-Science-Projekt erlernen. Kein Level ist für Lernende schwierig. Aus diesem Grund sind all diese Live-Projekte ein perfekter Weg, um seine Fähigkeiten zu verbessern und schnelle Fortschritte bei der Erlangung der Meisterschaft zu erzielen. Bei upGrad bieten wir 3 Data Science Online-Zertifizierungen an:
1. Executive PG Program in Data Science (12 Monate)
Von IIIT Bangalore
2. Master of Science in Data Science (18 Monate)
Von der Liverpool John Moores University
3. Advanced Certificate Program in Data Science (7 Monate)
Von IIIT Bangalore
Probieren Sie diese Data-Science-Online-Zertifizierungen von upGrad aus, da wir sicher sind, dass sie Ihnen auf Ihrem Data-Science-Karriereweg helfen werden. Zögern Sie daher nicht! Starten Sie jetzt Ihre Praxis!
Die folgenden Punkte sollten vor Beginn eines Data-Science-Projekts beachtet werden: Die folgenden Komponenten heben die allgemeinste Architektur eines Data-Science-Projekts hervor: Im Folgenden sind die wesentlichen Fähigkeiten und Werkzeuge aufgeführt, die jeder Data Science-Enthusiast beherrschen sollte:Wie macht man ein gutes Data-Science-Projekt?
Wählen Sie die Programmiersprache, mit der Sie vertraut sind. Die gewählte Sprache sollte jedoch eine der gefragtesten Sprachen wie Python, R und Scala sein.
Verwenden Sie Datensätze aus vertrauenswürdigen Quellen. Sie können Kaggle-Datensätze verwenden. Stellen Sie außerdem sicher, dass der von Ihnen verwendete Datensatz keine Fehler enthält.
Finden Sie Fehler oder Ausreißer in Ihrem Datensatz und beheben Sie diese, bevor Sie Ihr Modell trainieren. Sie können Visualisierungstools verwenden, um die Fehler in Ihrem Datensatz zu finden. Beschreiben Sie die Hauptkomponenten, die ein Data-Science-Projekt haben sollte?
Problemstellung : Dies ist die grundlegende Komponente, auf der das gesamte Projekt basiert. Es definiert das Problem, das Ihr Modell lösen soll, und erläutert den Ansatz, dem Ihr Projekt folgen wird.
Datensatz : Dies ist eine sehr wichtige Komponente für Ihr Projekt und sollte sorgfältig ausgewählt werden. Für das Projekt sollten nur ausreichend große Datensätze aus vertrauenswürdigen Quellen verwendet werden.
Algorithmus : Dazu gehört der Algorithmus, den Sie verwenden, um Ihre Daten zu analysieren und die Ergebnisse vorherzusagen. Beliebte algorithmische Techniken umfassen Regressionsalgorithmen, Regressionsbäume, Naive-Bayes-Algorithmen und Vektorquantisierung.
Trainingsmodelle : Dies beinhaltet das Trainieren Ihres Modells anhand verschiedener Eingaben und das Vorhersagen der Ausgabe. Diese Komponente entscheidet über die Genauigkeit Ihres Projekts. Die Verwendung geeigneter Trainingstechniken kann zu besseren Ergebnissen führen. Welche Fähigkeiten braucht man als Data Scientist?
1. Statistische Fähigkeiten einschließlich Wahrscheinlichkeit
2. Analytische Fähigkeiten zum Analysieren und Testen der Daten.
3. Programmiersprachen wie Python, R, Scala und JAVA.
4.Datenvisualisierungstools wie Power BI, Tableau
5. Algorithmen einschließlich Regression, Entscheidungsbäume, Bayes-Algorithmus
6. Analysis und Algebra.
7. Kommunikations- und Präsentationsfähigkeiten
8. Datenbanken wie SQL
9. Cloud Computing zur Verwaltung der Ressourcen
Abgesehen von diesen technischen Fähigkeiten sollte ein professioneller Data Scientist auch über einige Soft Skills verfügen, um dem Unternehmen einen Mehrwert zu bieten und die zwischenmenschlichen Beziehungen zu verbessern. Diese Fähigkeiten umfassen kritisches und neugieriges Denken, Geschäftsorientierung, intelligente Kommunikationsfähigkeiten, Problemlösung, Teammanagement und Kreativität.