
Der ultimative Data Science Spickzettel, den jeder Data Scientist haben sollte
Veröffentlicht: 2021-01-29Für alle angehenden Fachleute und Neulinge, die in die boomende Welt der Datenwissenschaft eintauchen möchten, haben wir einen kurzen Spickzettel zusammengestellt, um Sie mit den Grundlagen und Methoden aufzufrischen, die diesen Bereich unterstreichen.
Inhaltsverzeichnis
Data Science-Die Grundlagen
Die Daten, die in unserer Welt generiert werden, liegen in Rohform vor, dh Zahlen, Codes, Wörter, Sätze usw. Data Science verwendet diese sehr rohen Daten, um sie mit wissenschaftlichen Methoden zu verarbeiten, um sie in aussagekräftige Formen umzuwandeln, um Wissen und Erkenntnisse zu gewinnen .
Daten
Bevor wir in die Grundsätze der Datenwissenschaft eintauchen, lassen Sie uns ein wenig über Daten, ihre Typen und die Datenverarbeitung sprechen.
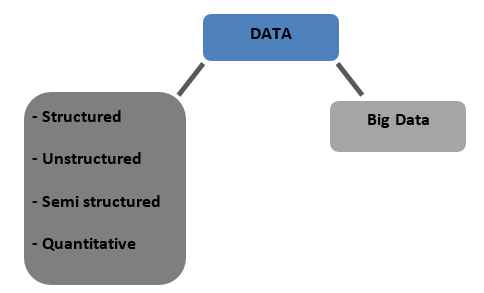
Arten von Daten
Strukturiert – Daten, die in tabellarischer Form in Datenbanken gespeichert sind. Es kann entweder numerisch oder Text sein
Unstrukturiert – Daten, die nicht mit einer nennenswerten endgültigen Struktur tabelliert werden können, werden als unstrukturierte Daten bezeichnet
Halbstrukturiert – Gemischte Daten mit Merkmalen sowohl strukturierter als auch unstrukturierter Daten
Quantitativ – Daten mit eindeutigen numerischen Werten, die quantifiziert werden können
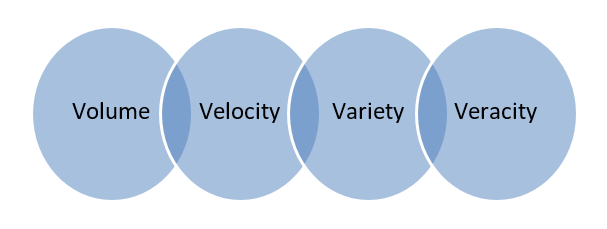
Big Data – Daten, die in riesigen Datenbanken gespeichert sind, die sich über mehrere Computer oder Serverfarmen erstrecken, werden als Big Data bezeichnet. Als Big Data gelten biometrische Daten, Social-Media-Daten etc. Big Data ist durch 4 V gekennzeichnet
Datenvorverarbeitung
Datenklassifizierung – Es ist der Prozess der Kategorisierung oder Kennzeichnung von Daten in Klassen wie numerisch, Text oder Bild, Text, Video usw.
Datenbereinigung – Es besteht aus dem Aussortieren fehlender/inkonsistenter/inkompatibler Daten oder dem Ersetzen von Daten mit einer der folgenden Methoden.
- Interpolation
- Heuristik
- Zufallsauswahl
- Nächster Nachbar
Datenmaskierung – Ausblenden oder Maskieren vertraulicher Daten, um die Vertraulichkeit sensibler Informationen zu wahren und sie dennoch verarbeiten zu können.
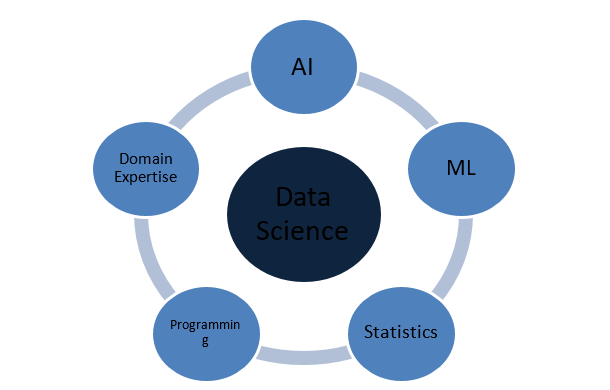
Woraus besteht Data Science?
Konzepte der Statistik
Rückfall
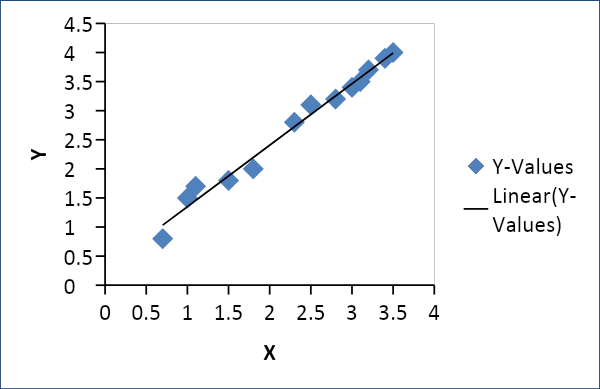
Lineare Regression
Die lineare Regression wird verwendet, um eine Beziehung zwischen zwei Variablen wie Angebot und Nachfrage, Preis und Verbrauch usw. herzustellen. Sie bezieht sich wie folgt auf eine Variable x als lineare Funktion einer anderen Variablen y
Y = f(x) oder Y = mx + c, wobei m = Koeffizient
Logistische Regression
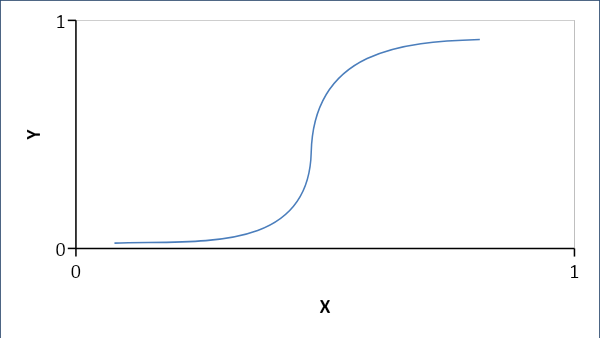
Die logistische Regression stellt eher eine probabilistische als eine lineare Beziehung zwischen Variablen her. Die resultierende Antwort ist entweder 0 oder 1 und wir suchen nach Wahrscheinlichkeiten und die Kurve ist S-förmig.
Wenn p < 0,5, dann ist es 0, sonst 1
Formel:
Y = e^ (b0 + b1x) / (1 + e^ (b0 + b1x))
wobei b0 = Bias und b1 = Koeffizient
Wahrscheinlichkeit
Die Wahrscheinlichkeit hilft, die Wahrscheinlichkeit des Eintretens eines Ereignisses vorherzusagen. Einige Terminologien:
Stichprobe: Der Satz wahrscheinlicher Ergebnisse
Ereignis: Es ist eine Teilmenge des Abtastraums
Zufallsvariable: Zufallsvariablen helfen dabei, wahrscheinliche Ergebnisse auf Zahlen oder eine Linie in einem Stichprobenraum abzubilden oder zu quantifizieren
Wahrscheinlichkeitsverteilungen
Diskrete Verteilungen: Gibt die Wahrscheinlichkeit als eine Menge diskreter Werte an (ganzzahlig)
P[X=x] = p(x)
 Bildquelle
Bildquelle
Kontinuierliche Verteilungen: Gibt die Wahrscheinlichkeit über eine Reihe von kontinuierlichen Punkten oder Intervallen anstelle von diskreten Werten an. Formel:
P[a ≤ x ≤ b] = a∫bf(x) dx, wobei a, b die Punkte sind
Bildquelle
Korrelation und Kovarianz
Standardabweichung: Die Variation oder Abweichung eines bestimmten Datensatzes von seinem Mittelwert
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
Kovarianz
Sie definiert das Ausmaß der Abweichung der Zufallsvariablen X und Y vom Mittelwert des Datensatzes.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Korrelation
Die Korrelation definiert das Ausmaß einer linearen Beziehung zwischen Variablen zusammen mit ihrer Richtung, +ve oder -ve
ρXY= σ2XY/ σX * *σY
Künstliche Intelligenz
Die Fähigkeit von Maschinen, sich Wissen anzueignen und auf der Grundlage von Eingaben Entscheidungen zu treffen, wird als künstliche Intelligenz oder einfach KI bezeichnet.
Typen
- Reaktive Maschinen: Reaktive Maschinen-KI funktioniert, indem sie lernt, auf vordefinierte Szenarien zu reagieren, indem sie sich auf die schnellsten und besten Optionen beschränkt. Sie haben wenig Speicher und eignen sich am besten für Aufgaben mit einem definierten Satz von Parametern. Sehr zuverlässig und konsistent.
- Begrenzter Speicher: Diese KI wird mit einigen realen Beobachtungs- und Legacy-Daten versorgt. Es kann anhand der gegebenen Daten lernen und Entscheidungen treffen, aber keine neuen Erfahrungen sammeln.
- Theory of Mind: Es ist eine interaktive KI, die Entscheidungen basierend auf dem Verhalten der umgebenden Entitäten treffen kann.
- Selbstbewusstsein: Diese KI ist sich ihrer Existenz und Funktionsweise unabhängig von der Umgebung bewusst. Es kann kognitive Fähigkeiten entwickeln und die Auswirkungen des eigenen Handelns auf die Umgebung verstehen und bewerten.
KI-Begriffe
Neuronale Netze
Neuronale Netze sind ein Bündel oder Netzwerk miteinander verbundener Knoten, die Daten und Informationen in einem System weiterleiten. NNs sind so modelliert, dass sie Neuronen in unserem Gehirn nachahmen und Entscheidungen durch Lernen und Vorhersagen treffen können.
Heuristik
Heuristik ist die Fähigkeit, basierend auf Annäherungen und Schätzungen schnell Vorhersagen zu treffen, indem frühere Erfahrungen in Situationen verwendet werden, in denen die verfügbaren Informationen lückenhaft sind. Es ist schnell, aber nicht genau oder präzise.
Fallbasiertes Schließen
Die Fähigkeit, aus früheren Problemlösungsfällen zu lernen und sie in aktuellen Situationen anzuwenden, um zu einer akzeptablen Lösung zu gelangen
Verarbeitung natürlicher Sprache
Es ist einfach die Fähigkeit einer Maschine, menschliche Sprache oder Text zu verstehen und direkt damit zu interagieren. Zum Beispiel Sprachbefehle in einem Auto
Maschinelles Lernen
Maschinelles Lernen ist einfach eine Anwendung von KI, die verschiedene Modelle und Algorithmen verwendet, um Probleme vorherzusagen und zu lösen.

Typen
Beaufsichtigt
Dieses Verfahren beruht auf Eingabedaten, die mit den Ausgabedaten assoziativ sind. Der Maschine wird ein Satz von Zielvariablen Y zur Verfügung gestellt, und sie muss unter der Aufsicht eines Optimierungsalgorithmus durch einen Satz von Eingangsvariablen X zu der Zielvariablen gelangen. Beispiele für überwachtes Lernen sind Neuronale Netze, Random Forest, Deep Learning, Support Vector Machines usw.
Unbeaufsichtigt
Bei dieser Methode haben Eingabevariablen keine Kennzeichnung oder Assoziation, und Algorithmen arbeiten daran, Muster und Cluster zu finden, die zu neuem Wissen und Erkenntnissen führen.
Verstärkt
Reinforced Learning konzentriert sich auf Improvisationstechniken, um das Lernverhalten zu schärfen oder zu polieren. Es ist eine belohnungsbasierte Methode, bei der die Maschine ihre Techniken schrittweise verbessert, um eine Zielbelohnung zu gewinnen.
Modellierungsmethoden
Rückfall
Regressionsmodelle liefern immer Zahlen als Ausgabe durch Interpolation oder Extrapolation kontinuierlicher Daten.
Einstufung
Klassifikationsmodelle liefern Ergebnisse als Klasse oder Label und sind besser in der Lage, diskrete Ergebnisse wie „welche Art“ vorherzusagen.
Sowohl Regression als auch Klassifikation sind überwachte Modelle.
Clustering
Clustering ist ein unüberwachtes Modell, das Cluster anhand von Merkmalen, Attributen, Merkmalen usw. identifiziert.
ML-Algorithmen
Entscheidungsbäume
Entscheidungsbäume verwenden einen binären Ansatz, um zu einer Lösung zu gelangen, die auf aufeinanderfolgenden Fragen in jeder Phase basiert, sodass das Ergebnis eines der beiden möglichen wie „Ja“ oder „Nein“ ist. Entscheidungsbäume sind einfach zu implementieren und zu interpretieren.
Random Forest oder Bagging
Random Forest ist ein fortschrittlicher Algorithmus von Entscheidungsbäumen. Es verwendet eine große Anzahl von Entscheidungsbäumen, was die Struktur dicht und komplex wie einen Wald macht. Es generiert mehrere Ergebnisse und führt somit zu genaueren Ergebnissen und Leistungen.
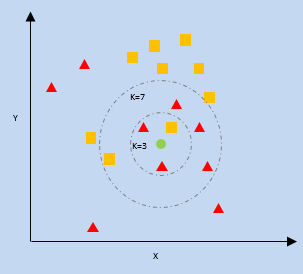
K- Nächster Nachbar (KNN)
kNN nutzt die Nähe der nächsten Datenpunkte auf einem Diagramm relativ zu einem neuen Datenpunkt, um vorherzusagen, in welche Kategorie er fällt. Der neue Datenpunkt wird der Kategorie mit einer höheren Anzahl von Nachbarn zugeordnet.
k = Anzahl der nächsten Nachbarn
Naive Bayes
Naive Bayes arbeitet auf zwei Säulen, erstens, dass jedes Merkmal von Datenpunkten unabhängig, nicht miteinander verbunden, dh einzigartig ist, und zweitens auf dem Bayes-Theorem, das Ergebnisse basierend auf einer Bedingung oder Hypothese vorhersagt.
Satz von Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Wobei P(X|Y) = Bedingte Wahrscheinlichkeit von X bei Auftreten von Y
P(Y|X) = Bedingte Wahrscheinlichkeit von Y bei Auftreten von X
P(X), P(Y) = Wahrscheinlichkeit von X und Y einzeln
Support-Vektor-Maschinen
Dieser Algorithmus versucht, Daten im Raum basierend auf Grenzen zu trennen, die entweder eine Linie oder eine Ebene sein können. Diese Grenze wird als „Hyperebene“ bezeichnet und wird durch die nächstgelegenen Datenpunkte jeder Klasse definiert, die wiederum als „Unterstützungsvektoren“ bezeichnet werden. Der maximale Abstand zwischen Stützvektoren auf beiden Seiten wird als Rand bezeichnet.
Neuronale Netze
Perzeptron
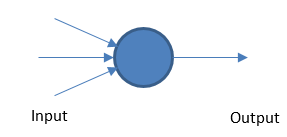
Das grundlegende neuronale Netzwerk arbeitet, indem es gewichtete Eingaben und Ausgaben auf der Grundlage eines Schwellenwerts nimmt.
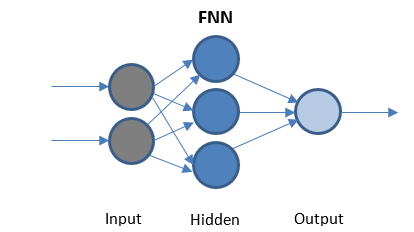
Neuronales Netzwerk weiterleiten
FFN ist das einfachste Netzwerk, das Daten nur in eine Richtung überträgt. Kann verborgene Schichten haben oder nicht.
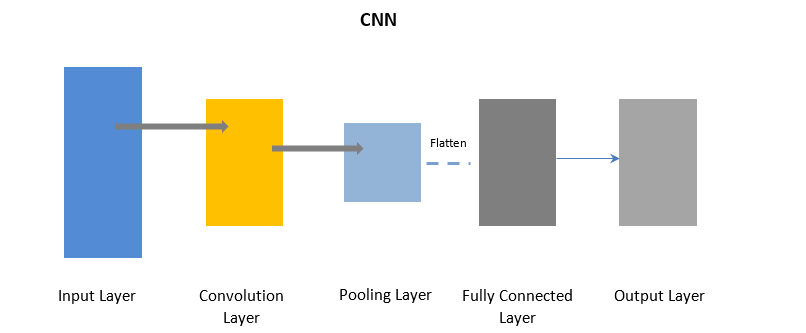
Faltungsneuronale Netze
CNN verwendet eine Faltungsschicht, um bestimmte Teile der Eingabedaten in Stapeln zu verarbeiten, gefolgt von einer Pooling-Schicht, um die Ausgabe zu vervollständigen.
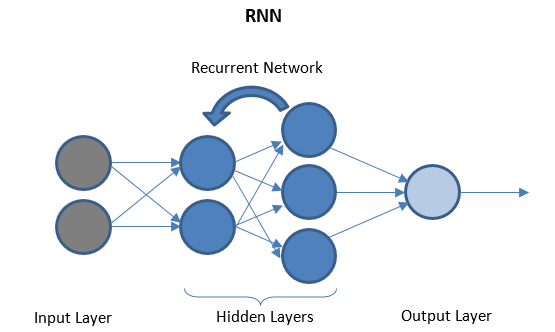
Wiederkehrende neuronale Netze
RNN besteht aus einigen wiederkehrenden Schichten zwischen E/A-Schichten, die „historische“ Daten speichern können. Der Datenfluss ist bidirektional und wird zur Verbesserung der Vorhersagen in die wiederkehrenden Schichten eingespeist.
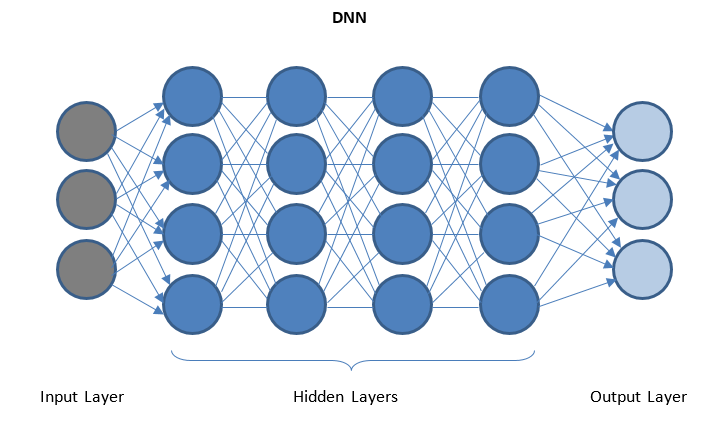
Deep Neural Networks und Deep Learning
DNN ist ein Netzwerk mit mehreren verborgenen Schichten zwischen E/A-Schichten. Die verborgenen Schichten wenden sukzessive Transformationen auf die Daten an, bevor sie an die Ausgabeschicht gesendet werden.
„Deep Learning“ wird durch DNN erleichtert und kann riesige Mengen komplexer Daten verarbeiten und aufgrund mehrerer verborgener Schichten eine hohe Genauigkeit erreichen
Holen Sie sich eine Data-Science-Zertifizierung von den besten Universitäten der Welt. Lernen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Fazit
Data Science ist ein weites Feld, das verschiedene Strömungen durchläuft, aber für uns als Revolution und Offenbarung empfunden wird. Data Science boomt und wird die Funktionsweise und das Verhalten unserer Systeme in Zukunft verändern.
Wenn Sie neugierig sind, mehr über Data Science zu erfahren, schauen Sie sich das PG Diploma in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1- on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Welche Programmiersprache eignet sich am besten für Data Science und warum?
Es gibt Dutzende von Programmiersprachen für Data Science, aber die Mehrheit der Data Science-Community glaubt, dass Python die richtige Wahl ist, wenn Sie sich in Data Science auszeichnen möchten. Im Folgenden sind einige der Gründe aufgeführt, die diese Überzeugung stützen:
1. Python hat eine große Auswahl an Modulen und Bibliotheken wie TensorFlow und PyTorch, die es einfach machen, mit Data-Science-Konzepten umzugehen.
2. Eine riesige Python-Entwickler-Community hilft Neulingen ständig, die nächste Phase ihrer Data-Science-Reise zu erreichen.
3. Diese Sprache ist bei weitem eine der bequemsten und am einfachsten zu schreibenden Sprachen mit einer sauberen Syntax, die ihre Lesbarkeit verbessert.
Welche Konzepte machen Data Science vollständig?
Data Science ist ein riesiger Bereich, der als Dach für verschiedene andere wichtige Bereiche fungiert. Die folgenden sind die bekanntesten Konzepte, die Data Science ausmachen:
Statistiken
Statistik ist ein wichtiges Konzept, in dem Sie sich auszeichnen müssen, um in der Datenwissenschaft voranzukommen. Es hat außerdem einige Unterthemen:
1. Lineare Regression
2. Wahrscheinlichkeit
3. Wahrscheinlichkeitsverteilung
Künstliche Intelligenz
Die Wissenschaft, Maschinen ein Gehirn zu geben und sie ihre eigenen Entscheidungen basierend auf den Eingaben treffen zu lassen, wird als künstliche Intelligenz bezeichnet. Reaktive Maschinen, begrenztes Gedächtnis, Theory of Mind und Selbstbewusstsein sind einige der Arten von künstlicher Intelligenz.
Maschinelles Lernen
Maschinelles Lernen ist eine weitere entscheidende Komponente der Datenwissenschaft, die sich damit befasst, Maschinen beizubringen, zukünftige Ergebnisse auf der Grundlage der bereitgestellten Daten vorherzusagen. Maschinelles Lernen hat drei herausragende Modellierungsmethoden: Clustering, Regression und Klassifizierung.
Beschreiben Sie die Arten des maschinellen Lernens?
Maschinelles Lernen oder einfaches ML hat drei Haupttypen, basierend auf ihren Arbeitsmethoden. Diese Typen sind wie folgt:
1. Überwachtes Lernen
Dies ist die primitivste Art von ML, bei der die Eingabedaten gekennzeichnet sind. Die Maschine wird mit einem kleineren Datensatz versorgt, der der Maschine einen Einblick in das Problem gibt, und darauf trainiert.
2. Unbeaufsichtigtes Lernen
Der größte Vorteil dieser Art ist, dass die Daten hier unbeschriftet sind und der menschliche Arbeitsaufwand nahezu vernachlässigbar ist. Dies öffnet das Tor für viel größere Datensätze, die in das Modell eingeführt werden können.
3. Verstärktes Lernen Dies ist die fortschrittlichste Art von ML, die vom Leben der Menschen inspiriert wird. Gewünschte Ergebnisse werden verstärkt, während die nutzlosen Ergebnisse entmutigt werden.