
Datenvorverarbeitung beim maschinellen Lernen: 7 einfache Schritte zum Befolgen
Veröffentlicht: 2021-07-15Die Datenvorverarbeitung beim maschinellen Lernen ist ein entscheidender Schritt, der dazu beiträgt, die Datenqualität zu verbessern, um die Extraktion sinnvoller Erkenntnisse aus den Daten zu fördern. Die Datenvorverarbeitung beim maschinellen Lernen bezieht sich auf die Technik der Vorbereitung (Bereinigung und Organisation) der Rohdaten, um sie für das Erstellen und Trainieren von Modellen für maschinelles Lernen geeignet zu machen. Einfach ausgedrückt ist die Datenvorverarbeitung beim maschinellen Lernen eine Data-Mining-Technik, die Rohdaten in ein verständliches und lesbares Format umwandelt.
Inhaltsverzeichnis
Warum Datenvorverarbeitung beim maschinellen Lernen?
Bei der Erstellung eines Modells für maschinelles Lernen ist die Datenvorverarbeitung der erste Schritt, der den Beginn des Prozesses markiert. In der Regel sind reale Daten unvollständig, inkonsistent, ungenau (enthalten Fehler oder Ausreißer) und es fehlen häufig spezifische Attributwerte/Trends. Hier kommt die Datenvorverarbeitung ins Spiel – sie hilft dabei, die Rohdaten zu bereinigen, zu formatieren und zu organisieren und sie so für Modelle des maschinellen Lernens einsatzbereit zu machen. Lassen Sie uns verschiedene Schritte der Datenvorverarbeitung beim maschinellen Lernen untersuchen.
Nehmen Sie online am Kurs für künstliche Intelligenz von den besten Universitäten der Welt teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Schritte in der Datenvorverarbeitung beim maschinellen Lernen
Es gibt sieben wesentliche Schritte bei der Datenvorverarbeitung beim maschinellen Lernen:
1. Erfassen Sie den Datensatz
Das Erfassen des Datensatzes ist der erste Schritt in der Datenvorverarbeitung beim maschinellen Lernen. Um Modelle für maschinelles Lernen zu erstellen und zu entwickeln, müssen Sie zunächst das entsprechende Dataset erwerben. Dieser Datensatz besteht aus Daten, die aus mehreren und unterschiedlichen Quellen gesammelt wurden, die dann in einem geeigneten Format kombiniert werden, um einen Datensatz zu bilden. Datensatzformate unterscheiden sich je nach Anwendungsfall. Beispielsweise unterscheidet sich ein Geschäftsdatensatz völlig von einem medizinischen Datensatz. Während ein Geschäftsdatensatz relevante Branchen- und Geschäftsdaten enthält, enthält ein medizinischer Datensatz gesundheitsbezogene Daten.
Es gibt mehrere Online-Quellen, von denen Sie Datensätze herunterladen können, wie https://www.kaggle.com/uciml/datasets und https://archive.ics.uci.edu/ml/index.php . Sie können auch ein Dataset erstellen, indem Sie Daten über verschiedene Python-APIs sammeln. Sobald das Dataset fertig ist, müssen Sie es im CSV-, HTML- oder XLSX-Dateiformat speichern.

2. Importieren Sie alle wichtigen Bibliotheken
Da Python die am weitesten verbreitete und auch von Data Scientists weltweit am meisten bevorzugte Bibliothek ist, zeigen wir Ihnen, wie Sie Python-Bibliotheken für die Datenvorverarbeitung in Machine Learning importieren. Lesen Sie hier mehr über Python-Bibliotheken für Data Science. Die vordefinierten Python-Bibliotheken können bestimmte Datenvorverarbeitungsaufgaben ausführen. Der Import aller wichtigen Bibliotheken ist der zweite Schritt der Datenvorverarbeitung beim maschinellen Lernen. Die drei wichtigsten Python-Bibliotheken, die für diese Datenvorverarbeitung beim maschinellen Lernen verwendet werden, sind:
- NumPy – NumPy ist das grundlegende Paket für wissenschaftliche Berechnungen in Python. Daher wird es zum Einfügen beliebiger mathematischer Operationen in den Code verwendet. Mit NumPy können Sie Ihrem Code auch große mehrdimensionale Arrays und Matrizen hinzufügen.
- Pandas – Pandas ist eine hervorragende Open-Source-Python-Bibliothek zur Datenmanipulation und -analyse. Es wird ausgiebig zum Importieren und Verwalten der Datensätze verwendet. Es enthält leistungsstarke, einfach zu verwendende Datenstrukturen und Datenanalysetools für Python.
- Matplotlib – Matplotlib ist eine Python-2D-Plotbibliothek, die verwendet wird, um jede Art von Diagrammen in Python zu plotten. Es kann Zahlen in Veröffentlichungsqualität in zahlreichen Papierformaten und interaktiven Umgebungen plattformübergreifend (IPython-Shells, Jupyter-Notebook, Webanwendungsserver usw.) liefern.
Lesen Sie : Projektideen für maschinelles Lernen für Anfänger
3. Importieren Sie den Datensatz
In diesem Schritt müssen Sie die Datensätze importieren, die Sie für das vorliegende ML-Projekt gesammelt haben. Das Importieren des Datensatzes ist einer der wichtigen Schritte in der Datenvorverarbeitung beim maschinellen Lernen. Bevor Sie jedoch die Datensätze importieren können, müssen Sie das aktuelle Verzeichnis als Arbeitsverzeichnis festlegen. Sie können das Arbeitsverzeichnis in Spyder IDE in drei einfachen Schritten festlegen:
- Speichern Sie Ihre Python-Datei in dem Verzeichnis, das das Dataset enthält.
- Gehen Sie in der Spyder IDE zur Option Datei-Explorer und wählen Sie das gewünschte Verzeichnis aus.
- Klicken Sie nun auf die Schaltfläche F5 oder die Option Ausführen, um die Datei auszuführen.
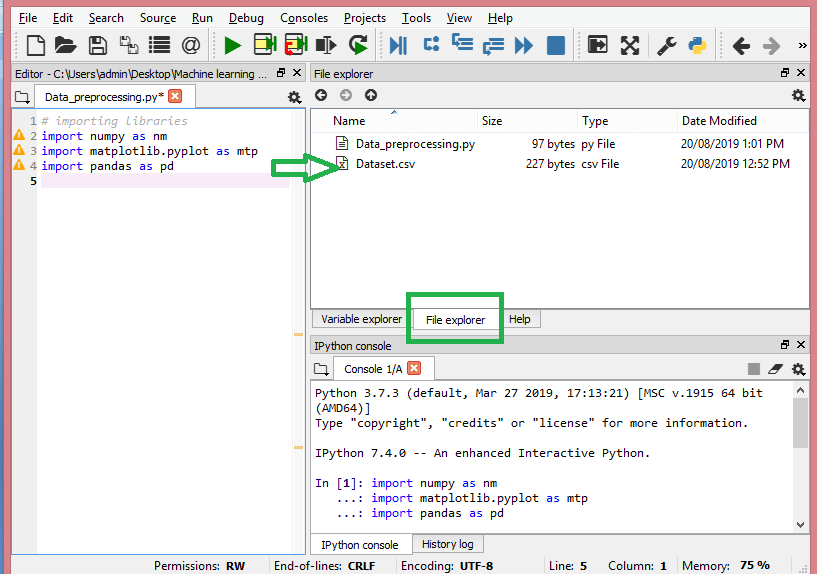
Quelle
So sollte das Arbeitsverzeichnis aussehen.
Nachdem Sie das Arbeitsverzeichnis mit dem entsprechenden Datensatz festgelegt haben, können Sie den Datensatz mit der Funktion „read_csv()“ der Pandas-Bibliothek importieren. Diese Funktion kann eine CSV-Datei lesen (entweder lokal oder über eine URL) und auch verschiedene Operationen daran ausführen. Die read_csv() wird geschrieben als:
data_set= pd.read_csv('Datensatz.csv')
In dieser Codezeile bezeichnet „data_set“ den Namen der Variablen, in der Sie den Datensatz gespeichert haben. Die Funktion enthält auch den Namen des Datensatzes. Sobald Sie diesen Code ausführen, wird das Dataset erfolgreich importiert.
Während des Dataset-Importprozesses gibt es eine weitere wichtige Sache, die Sie tun müssen – das Extrahieren abhängiger und unabhängiger Variablen. Für jedes Modell des maschinellen Lernens ist es notwendig, die unabhängigen Variablen (Matrix der Merkmale) und die abhängigen Variablen in einem Datensatz zu trennen.
Betrachten Sie diesen Datensatz:
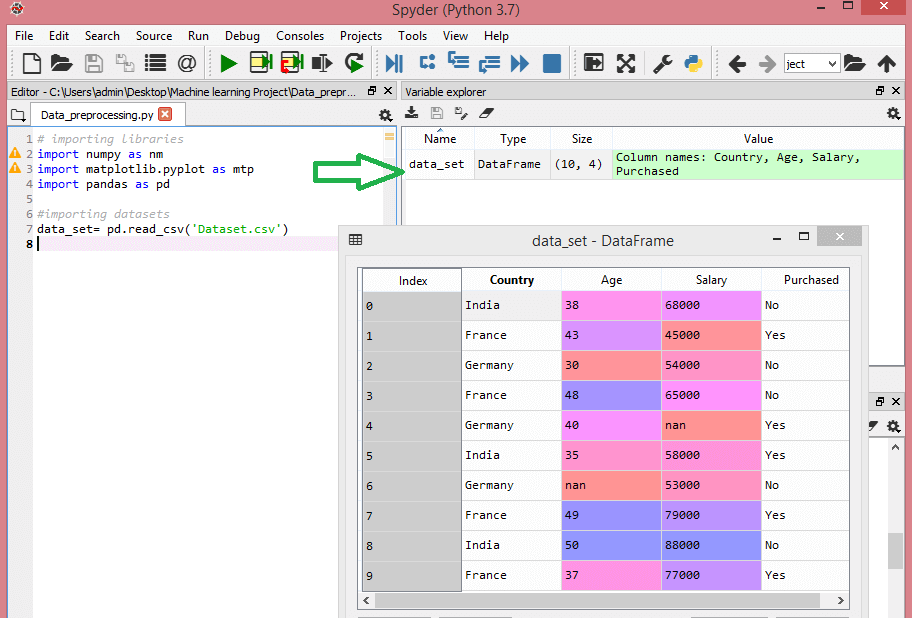
Quelle
Dieser Datensatz enthält drei unabhängige Variablen – Land, Alter und Gehalt – und eine abhängige Variable – gekauft.
Wie extrahiert man die unabhängigen Variablen?
Um die unabhängigen Variablen zu extrahieren, können Sie die Funktion „iloc[ ]“ der Pandas-Bibliothek verwenden. Diese Funktion kann ausgewählte Zeilen und Spalten aus dem Datensatz extrahieren.
x= data_set.iloc[:,:-1].values
In der obigen Codezeile berücksichtigt der erste Doppelpunkt (:) alle Zeilen und der zweite Doppelpunkt (:) alle Spalten. Der Code enthält „:-1“, da Sie die letzte Spalte mit der abhängigen Variable weglassen müssen. Wenn Sie diesen Code ausführen, erhalten Sie die Funktionsmatrix wie folgt:
[['Indien' 38.0 68000.0]
['Frankreich' 43.0 45000.0]
['Deutschland' 30.0 54000.0]
['Frankreich' 48.0 65000.0]
['Deutschland' 40,0 nan]
['Indien' 35.0 58000.0]
['Deutschland' nan 53000.0]
['Frankreich' 49.0 79000.0]
['Indien' 50.0 88000.0]
['Frankreich' 37.0 77000.0]]
Wie extrahiert man die abhängige Variable?
Sie können auch die Funktion „iloc[ ]“ verwenden, um die abhängige Variable zu extrahieren. So schreibst du es:
y= data_set.iloc[:,3].values
Diese Codezeile berücksichtigt nur alle Zeilen mit der letzten Spalte. Wenn Sie den obigen Code ausführen, erhalten Sie das Array der abhängigen Variablen wie folgt:
array(['Nein', 'Ja', 'Nein', 'Nein', 'Ja', 'Ja', 'Nein', 'Ja', 'Nein', 'Ja'],
dtype=Objekt)
4. Identifizieren und Umgang mit den fehlenden Werten
In der Datenvorverarbeitung ist es entscheidend, die fehlenden Werte zu identifizieren und richtig zu handhaben, da Sie andernfalls möglicherweise ungenaue und fehlerhafte Rückschlüsse und Rückschlüsse aus den Daten ziehen. Unnötig zu erwähnen, dass dies Ihr ML-Projekt behindern wird.
Grundsätzlich gibt es zwei Möglichkeiten, mit fehlenden Daten umzugehen:
- Löschen einer bestimmten Zeile – Bei dieser Methode entfernen Sie eine bestimmte Zeile mit einem Nullwert für eine Funktion oder eine bestimmte Spalte, in der mehr als 75 % der Werte fehlen. Diese Methode ist jedoch nicht zu 100 % effizient, und es wird empfohlen, sie nur zu verwenden, wenn das Dataset über ausreichende Stichproben verfügt. Sie müssen sicherstellen, dass nach dem Löschen der Daten keine Verzerrungen hinzugefügt werden.
- Berechnen des Mittelwerts – Diese Methode ist nützlich für Merkmale mit numerischen Daten wie Alter, Gehalt, Jahr usw. Hier können Sie den Mittelwert, Median oder Modus eines bestimmten Merkmals oder einer bestimmten Spalte oder Zeile berechnen, die einen fehlenden Wert enthält, und den ersetzen Ergebnis für den fehlenden Wert. Diese Methode kann dem Datensatz Varianz hinzufügen, und jeder Datenverlust kann effizient negiert werden. Daher liefert es im Vergleich zur ersten Methode (Auslassung von Zeilen/Spalten) bessere Ergebnisse. Eine andere Annäherungsmethode ist die Abweichung benachbarter Werte. Dies funktioniert jedoch am besten für lineare Daten.
Lesen Sie: Anwendungen von Anwendungen für maschinelles Lernen mit Cloud
5. Codieren der kategorialen Daten
Kategoriale Daten beziehen sich auf die Informationen, die bestimmte Kategorien innerhalb des Datensatzes haben. In dem oben zitierten Datensatz gibt es zwei kategoriale Variablen – Land und gekauft.
Modelle des maschinellen Lernens basieren hauptsächlich auf mathematischen Gleichungen. Daher können Sie intuitiv verstehen, dass das Beibehalten der kategorialen Daten in der Gleichung bestimmte Probleme verursachen wird, da Sie nur Zahlen in den Gleichungen benötigen würden.
Wie wird die Ländervariable codiert?
Wie in unserem Datensatzbeispiel zu sehen ist, wird die Länderspalte Probleme bereiten, daher müssen Sie sie in numerische Werte umwandeln. Dazu können Sie die Klasse LabelEncoder() aus der Lernbibliothek von sci-kit verwenden. Der Code wird wie folgt sein –
#Katgorische Daten
#für Ländervariable
aus sklearn.preprocessing importieren Sie LabelEncoder
label_encoder_x=LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
Und die Ausgabe wird sein –
Aus[15]:
Array([[2, 38.0, 68000.0],
[0, 43,0, 45000,0],
[1, 30.0, 54000.0],
[0, 48,0, 65000,0],
[1, 40.0, 65222.22222222222],
[2, 35,0, 58000,0],
[1, 41.111111111111114, 53000.0],
[0, 49,0, 79000,0],
[2, 50,0, 88000,0],
[0, 37.0, 77000.0]], dtype=Objekt)
Hier können wir sehen, dass die LabelEncoder-Klasse die Variablen erfolgreich in Ziffern codiert hat. Es gibt jedoch Ländervariablen, die in der oben gezeigten Ausgabe als 0, 1 und 2 codiert sind. Das ML-Modell kann also davon ausgehen, dass eine gewisse Korrelation zwischen den drei Variablen besteht, wodurch eine fehlerhafte Ausgabe erzeugt wird. Um dieses Problem zu beseitigen, verwenden wir jetzt die Dummy-Codierung.
Dummy-Variablen sind solche, die die Werte 0 oder 1 annehmen, um das Fehlen oder Vorhandensein eines bestimmten kategorialen Effekts anzuzeigen, der das Ergebnis verschieben kann. In diesem Fall zeigt der Wert 1 das Vorhandensein dieser Variablen in einer bestimmten Spalte an, während die anderen Variablen den Wert 0 annehmen. Bei der Dummy-Codierung entspricht die Anzahl der Spalten der Anzahl der Kategorien.
Da unser Datensatz drei Kategorien hat, werden drei Spalten mit den Werten 0 und 1 erzeugt. Für die Dummy-Codierung verwenden wir die OneHotEncoder-Klasse der scikit-learn-Bibliothek. Der Eingabecode lautet wie folgt:
#für Ländervariable
aus sklearn.preprocessing importieren Sie LabelEncoder, OneHotEncoder

label_encoder_x=LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Kodierung für Dummy-Variablen
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
Bei Ausführung dieses Codes erhalten Sie die folgende Ausgabe –
array([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
In der oben gezeigten Ausgabe sind alle Variablen in drei Spalten aufgeteilt und in die Werte 0 und 1 kodiert.
Wie codiert man die gekaufte Variable?
Für die zweite kategoriale Variable, also gekauft, können Sie das „labelencoder“-Objekt der LableEncoder-Klasse verwenden. Wir verwenden die OneHotEncoder-Klasse nicht, da die gekaufte Variable nur zwei Kategorien hat, ja oder nein, die beide in 0 und 1 codiert sind.
Der Eingabecode für diese Variable lautet –
labelencoder_y=LabelEncoder()
y= labelencoder_y.fit_transform(y)
Die Ausgabe wird sein –
Aus[17]: Array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Teilen des Datensatzes
Das Aufteilen des Datensatzes ist der nächste Schritt in der Datenvorverarbeitung beim maschinellen Lernen. Jeder Datensatz für Machine-Learning-Modelle muss in zwei getrennte Sätze aufgeteilt werden – Trainingssatz und Testsatz.
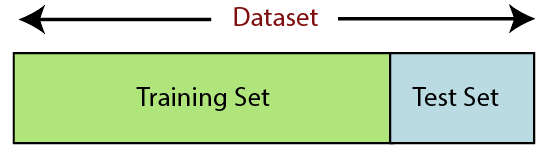
Quelle
Trainingssatz bezeichnet die Teilmenge eines Datensatzes, der zum Trainieren des maschinellen Lernmodells verwendet wird. Hier kennen Sie bereits die Ausgabe. Ein Testsatz hingegen ist die Teilmenge des Datensatzes, der zum Testen des maschinellen Lernmodells verwendet wird. Das ML-Modell verwendet das Testset, um Ergebnisse vorherzusagen.
Normalerweise wird der Datensatz in ein Verhältnis von 70:30 oder 80:20 aufgeteilt. Das bedeutet, dass Sie entweder 70 % oder 80 % der Daten für das Training des Modells verwenden und die restlichen 30 % oder 20 % auslassen. Der Aufteilungsprozess variiert je nach Form und Größe des betreffenden Datensatzes.
Um den Datensatz aufzuteilen, müssen Sie die folgende Codezeile schreiben –
aus sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Hier teilt die erste Zeile die Arrays des Datensatzes in zufällige Zug- und Testteilmengen auf. Die zweite Codezeile enthält vier Variablen:
- x_train – Features für die Trainingsdaten
- x_test – Features für die Testdaten
- y_train – abhängige Variablen für Trainingsdaten
- y_test – unabhängige Variable zum Testen von Daten
Somit enthält die Funktion train_test_split() vier Parameter, von denen die ersten beiden für Arrays von Daten sind. Die Funktion test_size gibt die Größe der Testmenge an. Die test_size kann .5, .3 oder .2 sein – dies gibt das Teilungsverhältnis zwischen Trainings- und Testdatensatz an. Der letzte Parameter „random_state“ setzt den Startwert für einen Zufallsgenerator, sodass die Ausgabe immer gleich ist.
7. Merkmalsskalierung
Die Merkmalsskalierung markiert das Ende der Datenvorverarbeitung beim maschinellen Lernen. Es ist eine Methode, um die unabhängigen Variablen eines Datensatzes innerhalb eines bestimmten Bereichs zu standardisieren. Mit anderen Worten, die Merkmalsskalierung schränkt den Bereich der Variablen ein, sodass Sie sie anhand gemeinsamer Gründe vergleichen können.
Betrachten Sie zum Beispiel diesen Datensatz –
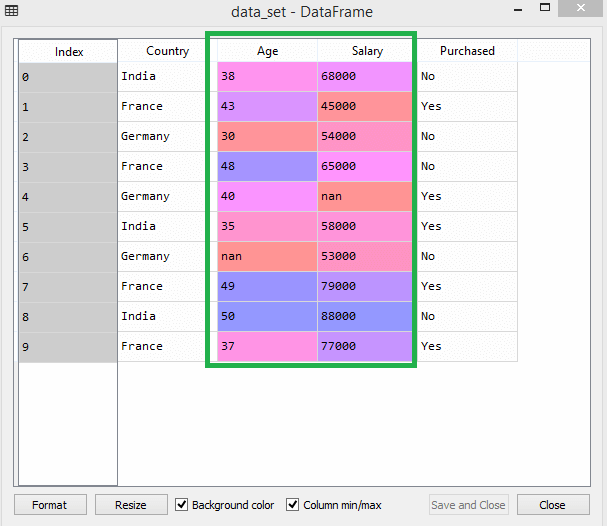
Quelle
Im Datensatz können Sie feststellen, dass die Alters- und Gehaltsspalten nicht denselben Maßstab haben. Wenn Sie in einem solchen Szenario zwei beliebige Werte aus den Spalten Alter und Gehalt berechnen, dominieren die Gehaltswerte die Alterswerte und liefern falsche Ergebnisse. Daher müssen Sie dieses Problem beheben, indem Sie die Funktionsskalierung für maschinelles Lernen durchführen.
Die meisten ML-Modelle basieren auf der euklidischen Distanz, die wie folgt dargestellt wird:
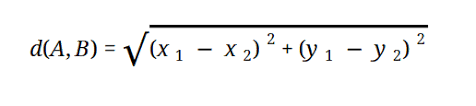
Quelle
Sie können die Feature-Skalierung beim maschinellen Lernen auf zwei Arten durchführen:
Standardisierung
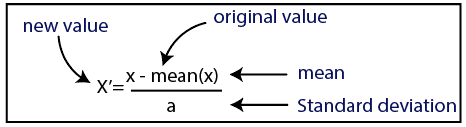
Quelle
Normalisierung
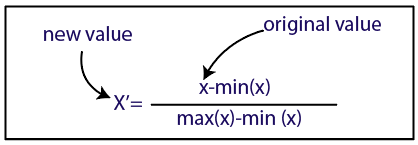
Quelle
Für unseren Datensatz verwenden wir die Standardisierungsmethode. Dazu importieren wir die StandardScaler-Klasse der sci-kit-learn-Bibliothek mit der folgenden Codezeile:
aus sklearn.preprocessing importieren Sie StandardScaler
Der nächste Schritt besteht darin, das Objekt der StandardScaler-Klasse für unabhängige Variablen zu erstellen. Danach können Sie den Trainingsdatensatz mit dem folgenden Code anpassen und transformieren:
st_x=StandardSkalierer()
x_train= st_x.fit_transform(x_train)
Für den Testdatensatz können Sie die Funktion transform() direkt anwenden (Sie müssen die Funktion fit_transform() nicht verwenden, da dies bereits im Trainingssatz erfolgt ist). Der Code wird wie folgt sein –
x_test= st_x.transform(x_test)
Die Ausgabe für den Testdatensatz zeigt die skalierten Werte für x_train und x_test wie folgt:
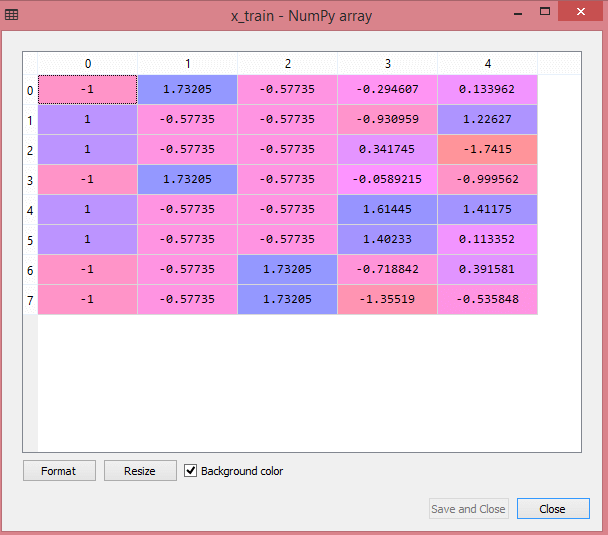
Quelle
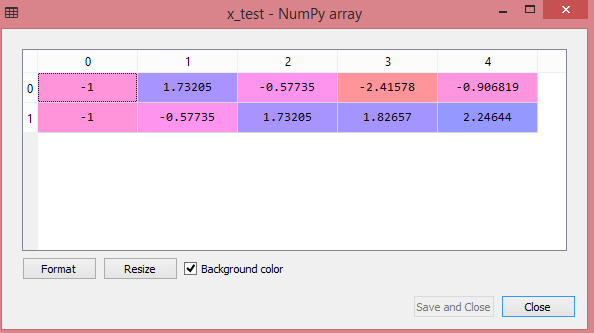
Quelle
Alle Variablen in der Ausgabe werden zwischen den Werten -1 und 1 skaliert.
Wenn Sie nun alle Schritte kombinieren, die wir bisher durchgeführt haben, erhalten Sie:
# Bibliotheken importieren
importiere numpy als nm
importiere matplotlib.pyplot als mtp
pandas als pd importieren
#Datensätze importieren
data_set= pd.read_csv('Datensatz.csv')
#Extrahieren unabhängiger Variablen
x= data_set.iloc[:, :-1].values
#Extrahieren abhängiger Variable
y= data_set.iloc[:, 3].values
#Behandlung fehlender Daten (Fehlende Daten durch den Mittelwert ersetzen)
aus sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Anpassung des Imputer-Objekts an die unabhängigen Variablen x.
imputerimputer= imputer.fit(x[:, 1:3])
#Fehlende Daten durch den errechneten Mittelwert ersetzen
x[:, 1:3]= imputer.transform(x[:, 1:3])
#für Ländervariable
aus sklearn.preprocessing importieren Sie LabelEncoder, OneHotEncoder
label_encoder_x=LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Kodierung für Dummy-Variablen
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#Kodierung für gekaufte Variable
labelencoder_y=LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Aufteilen des Datensatzes in Trainings- und Testsatz.
aus sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Funktionsskalierung von Datensätzen
aus sklearn.preprocessing importieren Sie StandardScaler
st_x=StandardSkalierer()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Das ist also die Datenverarbeitung im maschinellen Lernen auf den Punkt gebracht!
Sie können das Executive PG-Programm des IIT Delhi in Machine Learning & AI in Verbindung mit upGrad überprüfen . IIT Delhi ist eine der renommiertesten Institutionen in Indien. Mit mehr als 500 internen Fakultätsmitgliedern, die die Besten in den Fachgebieten sind.
Welche Bedeutung hat die Datenvorverarbeitung?
Da Fehler, Redundanzen, fehlende Werte und Inkonsistenzen die Integrität des Datensatzes gefährden, müssen Sie sie alle ansprechen, um ein genaueres Ergebnis zu erhalten. Angenommen, Sie verwenden einen fehlerhaften Datensatz, um ein maschinelles Lernsystem für die Bearbeitung der Einkäufe Ihrer Kunden zu trainieren. Das System erzeugt wahrscheinlich Verzerrungen und Abweichungen, was zu einer schlechten Benutzererfahrung führt. Bevor Sie diese Daten für den beabsichtigten Zweck verwenden, müssen sie daher so organisiert und „sauber“ wie möglich sein. Abhängig von der Art der Schwierigkeit, mit der Sie es zu tun haben, gibt es zahlreiche Optionen.
Was ist Datenbereinigung?
Ihre Datensätze werden mit ziemlicher Sicherheit fehlende und verrauschte Daten enthalten. Da das Datenerfassungsverfahren nicht ideal ist, erhalten Sie viele nutzlose und fehlende Informationen. Datenbereinigung ist der Weg, den Sie anwenden sollten, um mit diesem Problem umzugehen. Dies kann in zwei Kategorien unterteilt werden. Der erste behandelt den Umgang mit fehlenden Daten. Sie können die fehlenden Werte in diesem Abschnitt der Datenerfassung (als Tupel bezeichnet) ignorieren. Die zweite Datenreinigungsmethode ist für verrauschte Daten. Es ist wichtig, nutzlose Daten zu entfernen, die von den Systemen nicht gelesen werden können, wenn Sie möchten, dass der gesamte Prozess reibungslos abläuft.
Was verstehen Sie unter Datentransformation und -reduktion?
Die Datenvorverarbeitung geht nach der Bearbeitung der Bedenken in die Transformationsphase über. Sie verwenden es, um Daten in relevante Konformationen für die Analyse umzuwandeln. Normalisierung, Attributauswahl, Diskretisierung und Konzepthierarchiegenerierung sind einige der Ansätze, die verwendet werden können, um dies zu erreichen. Selbst bei automatisierten Methoden kann das Durchsuchen großer Datensätze lange dauern. Deshalb ist die Phase der Datenreduktion so entscheidend: Sie reduziert die Größe von Datensätzen, indem sie sie auf die wichtigsten Informationen beschränkt, die Speichereffizienz erhöht und gleichzeitig den finanziellen und zeitlichen Aufwand für die Arbeit mit ihnen senkt.