
Datenrahmen in Python: Ausführliches Python-Tutorial 2022
Veröffentlicht: 2021-01-09Wenn Sie ein Entwickler oder Programmierer sind, der in der Programmiersprache Python arbeitet, müssen Sie mit einer der erstaunlichsten Datenverwaltungsbibliotheken da draußen vertraut sein – Pandas, eine der besten Python-Bibliotheken da draußen. Im Laufe der Jahre hat sich Pandas zu einem Standardtool für die Datenanalyse und -verwaltung mit Python entwickelt. Lesen Sie mehr über andere wichtige Python-Tools.
Pandas ist zweifellos das vielseitigste Python-Paket für die Datenwissenschaft, und das zu Recht. Es bietet leistungsstarke, ausdrucksstarke und flexible Datenstrukturen für eine einfache Datenbearbeitung und -analyse, und Data Frames in Python ist eine dieser Strukturen.
Genau das sind unsere Diskussionsthemen in diesem Beitrag – wir stellen Ihnen das grundlegende Datenformat für Pandas vor, nämlich den Pandas Data Frame.
Inhaltsverzeichnis
Was ist ein Datenrahmen?
Laut der Pandas-Bibliotheksdokumentation ist ein Datenrahmen eine „zweidimensionale, größenveränderliche, potenziell heterogene tabellarische Datenstruktur mit beschrifteten Achsen (Zeilen und Spalten)“. Mit einfachen Worten, ein Datenrahmen ist eine Datenstruktur, in der Daten tabellarisch angeordnet sind, d. h. in Zeilen und Spalten.
Ein Datenrahmen hat normalerweise die folgenden Eigenschaften:
- Es kann mehrere Zeilen und Spalten haben.
- Während jede Zeile eine Datenstichprobe darstellt, umfasst jede Spalte eine andere Variable, die die Stichproben (Zeilen) beschreibt.
- Die Daten in jeder Spalte sind normalerweise die gleichen Datentypen (z. B. Zahlen, Zeichenfolgen, Datumsangaben usw.).
- Im Gegensatz zu Excel-Datensätzen werden fehlende Werte vermieden, sodass es keine Lücken oder leeren Werte zwischen Zeilen oder Spalten gibt.
In einem Pandas-Datenrahmen können Sie auch den Index und die Spaltennamen für Ihren Datenrahmen angeben. Während der Index den Unterschied in Zeilen anzeigt, zeigen die Spaltennamen den Unterschied in Spalten.
So erstellen Sie einen Datenrahmen in Python (mit Pandas)
Das Erstellen eines Datenrahmens ist der erste Schritt für das Datenmunging in Python. Sie können einen Pandas-Datenrahmen mit Eingaben wie den folgenden erstellen:
- Dikt
- Listen
- Serie
- Numpy „ndarray“
- Ein weiterer Datenrahmen
- Externe Dateien wie CS
- Erstellen eines leeren Datenrahmens
Es ist ganz einfach, einen einfachen Datenrahmen, auch bekannt als leerer Datenrahmen, zu erstellen. Hier ist ein Beispiel:
Eingang –

Ausgabe -

- Erstellen eines Datenrahmens aus Listen
Sie können einen Datenrahmen entweder mit einer einzelnen Liste oder mehreren Listen erstellen.
Eingang –

Ausgabe -

- Erstellen eines Datenrahmens aus Dict von „ndarrays“ oder Listen
Um einen Datenrahmen aus einem Diktat von ndarrays zu erstellen, müssen alle ndarrays dieselbe Länge haben. Wenn es indiziert ist, sollte die Länge des Index auch gleich der Länge der Arrays sein. Wenn es jedoch nicht indiziert ist, ist der Index standardmäßig range(n), wobei 'n' die Array-Länge bezeichnet.
Eingang –

Ausgabe -

Hier sind die Werte 0,1,2,3 der Standardindex, der jeder Zeile mit der Funktion range(n) zugewiesen wird.
Was sind die grundlegenden Datenrahmenoperationen?
Nachdem wir nun drei Möglichkeiten zum Erstellen von Datenrahmen in Python gesehen haben, ist es an der Zeit, sich mit den verschiedenen Vorgängen innerhalb eines Datenrahmens vertraut zu machen.
- Auswählen eines Index oder einer Spalte aus einem Pandas-Datenrahmen
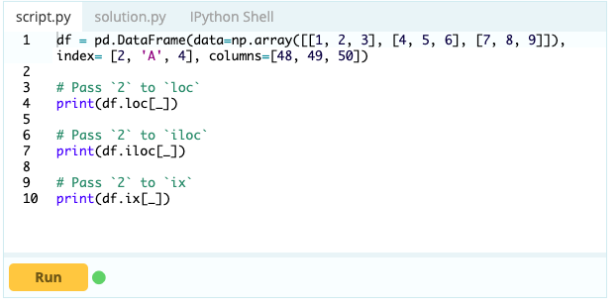
Es ist wichtig zu wissen, wie man einen Index oder eine Spalte auswählt, bevor man mit dem Hinzufügen, Löschen und Umbenennen der Komponenten in einem DataFrame beginnen kann. Angenommen, dies ist Ihr Datenrahmen:

Sie möchten auf den Wert unter Index 0 in Spalte „A“ zugreifen – der Wert ist 1. Es gibt viele Möglichkeiten, auf diesen Wert zuzugreifen, aber zwei der wichtigsten sind – .loc[] und .iloc[].
Eingang –
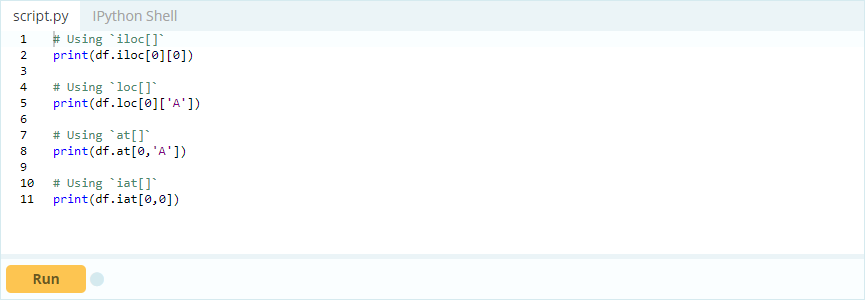
Ausgabe -
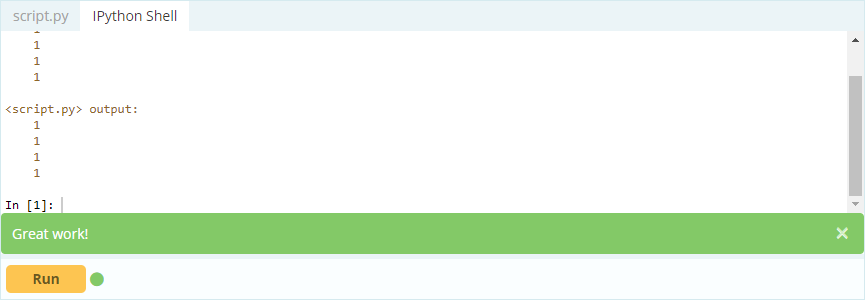
Wie Sie also sehen, können Sie auf Werte zugreifen, indem Sie sie entweder über ihre Bezeichnung aufrufen oder ihre Position im Index oder in der Spalte angeben. Während hier ein Wert aus einem Datenrahmen ausgewählt wurde, wie können Sie Zeilen und Spalten aus demselben auswählen?
Das ist wie:
Eingang –
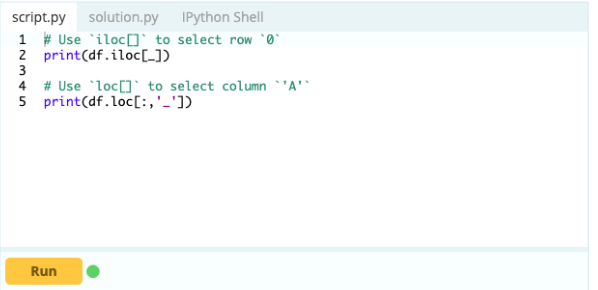
Ausgabe-
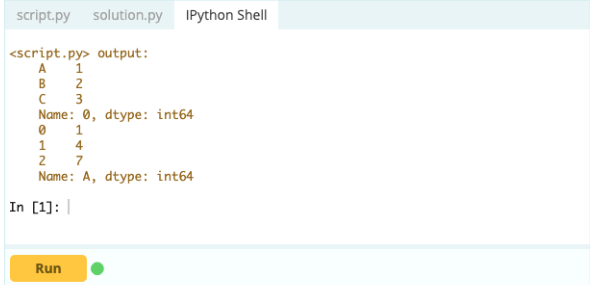
- So fügen Sie einem Pandas DataFrame einen Index, eine Zeile oder eine Spalte hinzu
Sobald Sie gelernt haben, wie man auf Werte zugreift und Spalten aus einem Datenrahmen auswählt, können Sie lernen, Index, Zeile oder Spalte in einem Pandas-Datenrahmen hinzuzufügen.
Index hinzufügen:
Beim Erstellen eines Datenrahmens können Sie dem „Index“-Argument eine Eingabe hinzufügen. Dadurch wird sichergestellt, dass Sie problemlos auf den gewünschten Index zugreifen können. Wenn Sie den Index nicht angeben, wird ihm standardmäßig ein numerisch bewerteter Index hinzugefügt, der mit 0 beginnt und bis zur letzten Zeile des DataFrame fortgesetzt wird. Auch nachdem der Index standardmäßig angegeben wurde, können Sie eine Spalte verwenden und sie in einen Index konvertieren, indem Sie die Funktion set_index() im Datenrahmen aufrufen.

Zeile hinzufügen:
Mit der Append-Funktion können Sie Zeilen zu einem DataFrame hinzufügen.
Eingang –

Ausgabe -

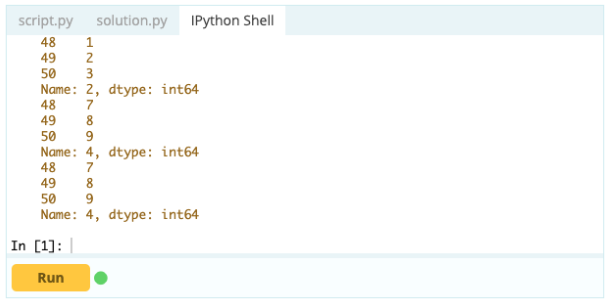
Sie können .loc auch verwenden, um Zeilen wie folgt in Ihren DataFrame einzufügen:
Eingang –
Ausgabe -
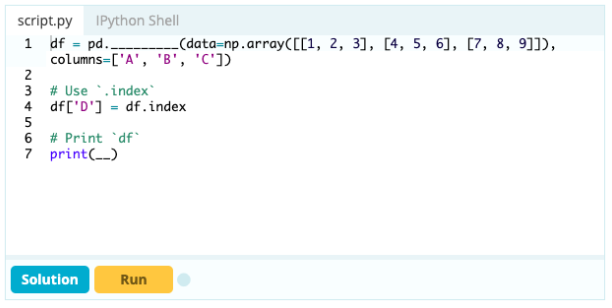
Spalte hinzufügen
Wenn Sie einen Index zum Teil eines Datenrahmens machen möchten, können Sie eine Spalte aus dem Datenrahmen nehmen oder auf eine Spalte verweisen, die noch nicht erstellt wurde, und sie wie folgt der Eigenschaft .index zuweisen:
Eingang –
Ausgabe -
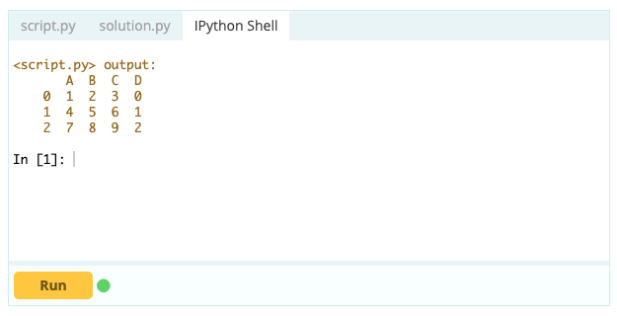
Zum Hinzufügen von Spalten zu einem Datenrahmen können Sie auch den gleichen Ansatz verwenden, den Sie zum Hinzufügen eines Index zum Datenrahmen verwenden würden, d. h. Sie können die Funktion .loc[ ] oder .iloc[ ] verwenden. Zum Beispiel:
Eingang –
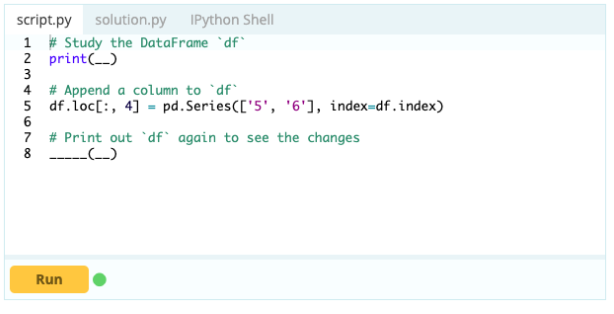
Ausgabe
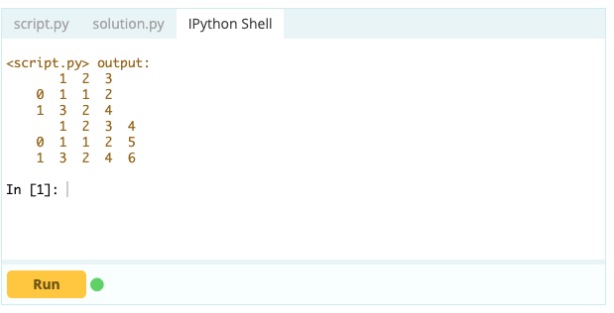
Mit .loc[ ] können Sie einem vorhandenen DataFrame eine Serie hinzufügen. Da ein Serienobjekt einer Spalte eines Datenrahmens ziemlich ähnlich ist, ist es sehr einfach, eine Serie zu einem bestehenden Datenrahmen hinzuzufügen.
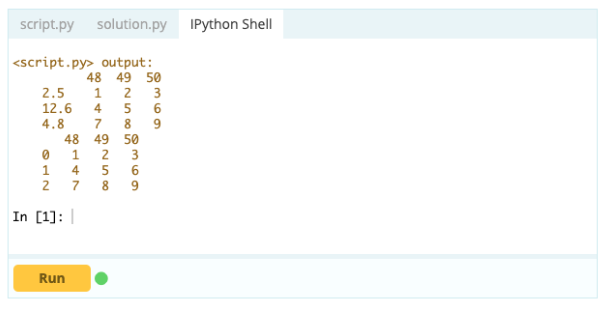
- Wie setzt man den Index eines Datenrahmens zurück?
Sie können den Index eines Datenrahmens zurücksetzen, wenn er nicht wie gewünscht aussieht. Dazu können Sie die Funktion .reset_index() verwenden.
Eingang –
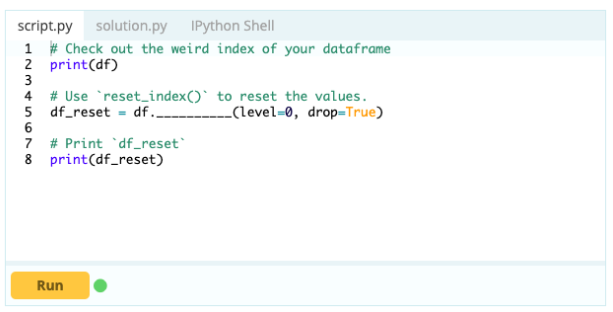
Ausgabe -
- So löschen Sie einen Index, eine Zeile oder eine Spalte in einem Pandas DataFrame
Löschen eines Index
- Zurücksetzen des Index des Datenrahmens.
- Entfernen Sie den Indexnamen (sofern vorhanden) mithilfe der Funktion del df.index.name.
- Entfernen Sie einen Index zusammen mit einer Zeile.
- Entfernen Sie alle doppelten Indexwerte, indem Sie den Index zurücksetzen, die Duplikate der Indexspalte löschen, die dem Datenrahmen hinzugefügt wurde, und die neue Spalte (ohne doppelten Index) erneut als Index einsetzen.
Löschen einer Spalte
Um Spalten aus einem Datenrahmen zu entfernen, können Sie die Funktion drop() verwenden.
Eingang –
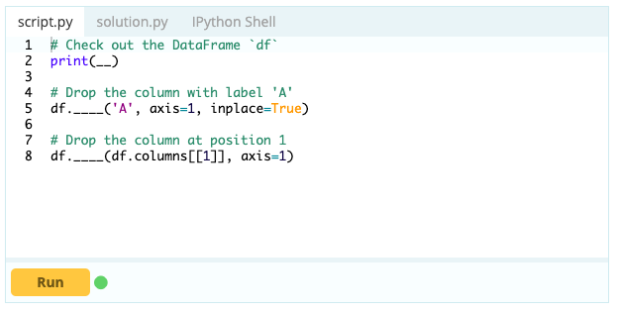
Ausgabe -
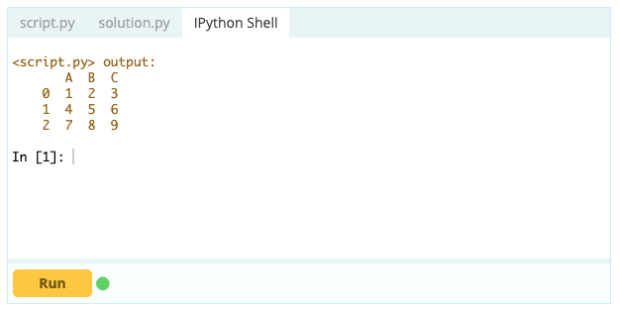
Zeile löschen
Um eine Zeile aus einem Datenrahmen zu löschen, können Sie die drop()-Funktion verwenden, indem Sie die Eigenschaft index verwenden, um den Index der Zeilen anzugeben, die Sie aus dem Datenrahmen löschen möchten.
Eingang –
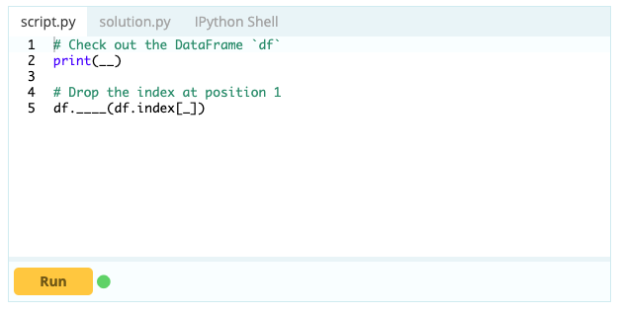
Ausgabe -
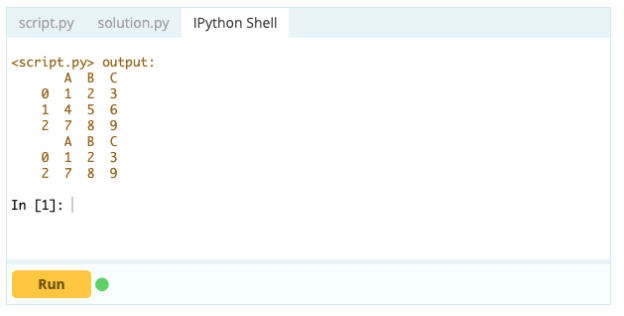
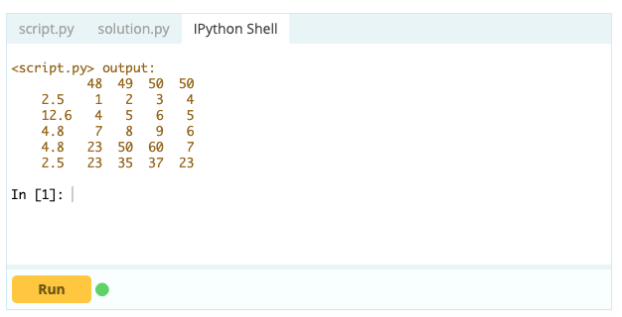
Um jedoch doppelte Zeilen zu löschen, können Sie die Funktion df.drop_duplicates() verwenden.
Eingang –
Ausgabe -
Quellen: Tutorialspoint Datacamp
Fazit
Das ist also Ihr grundlegendes Tutorial für Data Frame in Python mit Pandas.
Wenn Sie daran interessiert sind, Python, Data Science zu lernen, schauen Sie sich das PG Diploma in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische praktische Workshops, Mentoring mit Branchenexperten, 1-on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Warum ist Pandas eine der am meisten bevorzugten Bibliotheken zum Erstellen von Datenrahmen in Python?
Die Pandas-Bibliothek gilt als am besten geeignet zum Erstellen von Datenrahmen, da sie verschiedene Funktionen bietet, die das Erstellen eines Datenrahmens effizient machen. Einige dieser Funktionen sind wie folgt: Pandas stellen uns verschiedene Datenrahmen zur Verfügung, die nicht nur eine effiziente Datendarstellung ermöglichen, sondern uns auch ermöglichen, sie zu manipulieren. Es bietet effiziente Ausrichtungs- und Indizierungsfunktionen, die intelligente Möglichkeiten zur Kennzeichnung und Organisation der Daten bieten. Einige Funktionen von Pandas machen den Code sauberer und erhöhen seine Lesbarkeit, wodurch er effizienter wird. Es kann auch mehrere Dateiformate lesen. JSON, CSV, HDF5 und Excel sind einige der von Pandas unterstützten Dateiformate. Das Zusammenführen mehrerer Datensätze war für viele Programmierer eine echte Herausforderung. Pandas überwinden auch dies und führen mehrere Datensätze sehr effizient zusammen.
Welche anderen Bibliotheken und Tools ergänzen die Pandas-Bibliothek?
Pandas fungiert nicht nur als zentrale Bibliothek zum Erstellen von Datenrahmen, sondern arbeitet auch mit anderen Bibliotheken und Tools von Python zusammen, um effizienter zu sein. Pandas basiert auf dem NumPy-Python-Paket, was darauf hinweist, dass der größte Teil der Pandas-Bibliotheksstruktur aus dem NumPy-Paket repliziert wird. Die statistische Analyse der Daten in der Pandas-Bibliothek wird von SciPy durchgeführt, Plotting-Funktionen auf Matplotlib und maschinelle Lernalgorithmen in Scikit-learn. Jupyter Notebook ist eine webbasierte interaktive Umgebung, die als IDE funktioniert und eine gute Umgebung für Pandas bietet.
Was sind die grundlegenden Datenrahmenoperationen?
Es ist wichtig, einen Index oder eine Spalte auszuwählen, bevor Sie mit einer Operation wie Hinzufügen oder Löschen beginnen. Sobald Sie gelernt haben, wie Sie auf Werte zugreifen und Spalten aus einem Datenrahmen auswählen, können Sie lernen, Index, Zeile oder Spalte in einem Pandas-Datenrahmen hinzuzufügen. Wenn der Index im Datenrahmen nicht wie gewünscht ausfällt, können Sie ihn zurücksetzen. Um den Index zurückzusetzen, können Sie die Funktion „reset_index()“ verwenden.