
Erstellen eines Workflows für kontinuierliche Integrationstests mithilfe von GitHub-Aktionen
Veröffentlicht: 2022-03-10Wenn Sie zu Projekten auf Versionskontrollplattformen wie GitHub und Bitbucket beitragen, besteht die Konvention darin, dass es den Hauptzweig gibt, der die funktionale Codebasis enthält. Dann gibt es andere Zweige, in denen mehrere Entwickler an Kopien des Hauptprogramms arbeiten können, um entweder ein neues Feature hinzuzufügen, einen Fehler zu beheben und so weiter. Dies ist sehr sinnvoll, da es einfacher wird, die Auswirkungen der eingehenden Änderungen auf den vorhandenen Code zu überwachen. Wenn ein Fehler auftritt, kann er leicht zurückverfolgt und behoben werden, bevor die Änderungen in den Hauptzweig integriert werden. Es kann zeitaufwändig sein, jede einzelne Codezeile manuell nach Fehlern oder Bugs zu durchsuchen – selbst bei einem kleinen Projekt. Hier kommt die kontinuierliche Integration ins Spiel.
Was ist kontinuierliche Integration (CI)?
„Kontinuierliche Integration (CI) ist die Praxis, die Integration von Codeänderungen von mehreren Mitwirkenden in ein einziges Softwareprojekt zu automatisieren.“
– Atlassian.com
Die allgemeine Idee hinter Continuous Integration (CI) besteht darin, sicherzustellen, dass am Projekt vorgenommene Änderungen nicht „den Build zerstören“, d. h. die vorhandene Codebasis ruinieren. Durch die Implementierung von Continuous Integration in Ihrem Projekt würde, je nachdem, wie Sie Ihren Workflow einrichten, ein Build erstellt werden, wenn jemand Änderungen am Repository vornimmt.
Also, was ist ein Build?
Ein Build – in diesem Zusammenhang – ist die Kompilierung von Quellcode in ein ausführbares Format. Wenn es erfolgreich ist, bedeutet dies, dass die eingehenden Änderungen die Codebasis nicht negativ beeinflussen, und sie können loslegen. Wenn der Build jedoch fehlschlägt, müssen die Änderungen neu bewertet werden. Aus diesem Grund ist es ratsam, Änderungen an einem Projekt vorzunehmen, indem Sie an einer Kopie des Projekts in einem anderen Zweig arbeiten, bevor Sie es in die Hauptcodebasis integrieren. Auf diese Weise wäre es einfacher, herauszufinden, woher der Fehler kommt, wenn der Build abbricht, und er wirkt sich auch nicht auf Ihren Hauptquellcode aus.
„Je früher man Mängel entdeckt, desto günstiger sind sie zu beheben.“
— David Farley, Continuous Delivery: Zuverlässige Software-Releases durch Build-, Test- und Bereitstellungsautomatisierung
Es stehen mehrere Tools zur Verfügung, die Ihnen bei der Erstellung einer kontinuierlichen Integration für Ihr Projekt helfen. Dazu gehören Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions usw. Für dieses Tutorial werde ich GitHub Actions verwenden.
GitHub-Aktionen für kontinuierliche Integration
CI-Aktionen sind eine ziemlich neue Funktion auf GitHub und ermöglichen die Erstellung von Workflows, die automatisch den Build und die Tests Ihres Projekts ausführen. Ein Workflow enthält einen oder mehrere Jobs, die aktiviert werden können, wenn ein Ereignis eintritt. Dieses Ereignis kann ein Push an einen der Branches im Repo oder die Erstellung einer Pull-Anforderung sein. Ich werde diese Begriffe im weiteren Verlauf ausführlich erläutern.
Lass uns anfangen!
Voraussetzungen
Dies ist ein Tutorial für Anfänger, daher werde ich hauptsächlich oberflächlich über GitHub Actions CI sprechen. Die Leser sollten bereits mit dem Erstellen einer Node JS-REST-API unter Verwendung der PostgreSQL-Datenbank, Sequelize ORM und dem Schreiben von Tests mit Mocha und Chai vertraut sein.
Außerdem sollte Folgendes auf Ihrem Computer installiert sein:
- NodeJS,
- PostgreSQL,
- NEM,
- VSCode (oder einen beliebigen Editor und Terminal Ihrer Wahl).
Ich werde eine von mir bereits erstellte REST-API namens countries-info-api verwenden. Es ist eine einfache API ohne rollenbasierte Autorisierungen (zum Zeitpunkt der Erstellung dieses Tutorials). Das bedeutet, dass jeder die Details eines Landes hinzufügen, löschen und/oder aktualisieren kann. Jedes Land hat eine ID (automatisch generierte UUID), einen Namen, eine Hauptstadt und eine Bevölkerung. Um dies zu erreichen, habe ich Node js, express js framework und Postgresql für die Datenbank verwendet.
Ich werde kurz erklären, wie ich den Server und die Datenbank einrichte, bevor ich mit dem Schreiben der Tests für die Testabdeckung und der Workflow-Datei für die kontinuierliche Integration beginne.
Sie können das countries-info-api Repo klonen, um es zu verfolgen, oder Ihre eigene API erstellen.
Verwendete Technologie : Node Js, NPM (ein Paketmanager für Javascript), Postgresql-Datenbank, Sequelize ORM, Babel.
Einrichten des Servers
Vor dem Einrichten des Servers habe ich einige Abhängigkeiten von npm installiert.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonIch verwende das Express-Framework und schreibe im ES6-Format, daher brauche ich Babeljs, um meinen Code zu kompilieren. Sie können die offizielle Dokumentation lesen, um mehr darüber zu erfahren, wie es funktioniert und wie Sie es für Ihr Projekt konfigurieren. Nodemon erkennt alle Änderungen am Code und startet den Server automatisch neu.
Hinweis : Npm-Pakete, die mit dem --save-dev installiert wurden, sind nur während der Entwicklungsphasen erforderlich und werden unter devDependencies in der Datei „package.json“ package.json .
Ich habe meiner index.js -Datei Folgendes hinzugefügt:
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Dadurch wird unsere API so eingerichtet, dass sie auf dem ausgeführt wird, was der PORT -Variablen in der .env -Datei zugewiesen ist. Hier werden wir auch Variablen deklarieren, auf die andere keinen einfachen Zugriff haben sollen. Das dotenv npm-Paket lädt unsere Umgebungsvariablen aus .env .
Wenn ich jetzt npm run start in meinem Terminal ausführe, bekomme ich Folgendes:
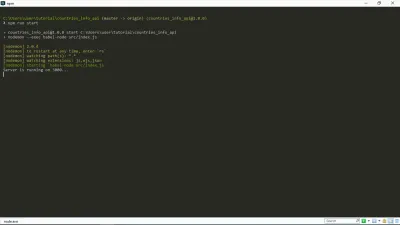
Wie Sie sehen können, ist unser Server in Betrieb. Yay!
Dieser Link https://127.0.0.1:your_port_number/ in Ihrem Webbrowser sollte die Willkommensnachricht zurückgeben. Das heißt, solange der Server läuft.
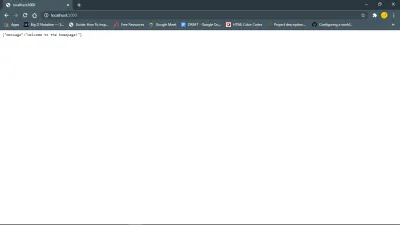
Als nächstes Datenbank und Modelle.
Ich habe das Ländermodell mit Sequelize erstellt und mich mit meiner Postgres-Datenbank verbunden. Sequelize ist ein ORM für Nodejs. Ein großer Vorteil ist, dass wir die Zeit für das Schreiben von rohen SQL-Abfragen sparen.
Da wir Postgresql verwenden, kann die Datenbank über die psql-Befehlszeile mit dem Befehl CREATE DATABASE database_name erstellt werden. Dies kann auch auf Ihrem Terminal erfolgen, aber ich bevorzuge PSQL Shell.
In der env-Datei richten wir die Verbindungszeichenfolge unserer Datenbank gemäß dem folgenden Format ein.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Für mein Modell habe ich dieses Sequelize-Tutorial befolgt. Es ist leicht verständlich und erklärt alles über die Einrichtung von Sequelize.
Als nächstes werde ich Tests für das Modell schreiben, das ich gerade erstellt habe, und die Abdeckung auf Coverall einrichten.
Schreiben von Tests und Berichterstattung über die Berichterstattung
Warum Tests schreiben? Ich persönlich glaube, dass das Schreiben von Tests Ihnen als Entwickler hilft, besser zu verstehen, wie Ihre Software in den Händen Ihrer Benutzer funktionieren soll, da es sich um einen Brainstorming-Prozess handelt. Es hilft Ihnen auch, Fehler rechtzeitig zu entdecken.
Tests:
Es gibt jedoch verschiedene Methoden zum Testen von Software. Für dieses Tutorial habe ich Unit- und End-to-End-Tests verwendet.
Ich habe meine Tests mit dem Mocha-Testframework und der Chai-Assertion-Bibliothek geschrieben. Ich habe auch sequelize-test-helpers installiert, um das mit sequelize.define erstellte Modell zu testen.

Testabdeckung:
Es ist ratsam, Ihre Testabdeckung zu überprüfen, da das Ergebnis zeigt, ob unsere Testfälle den Code tatsächlich abdecken und auch, wie viel Code verwendet wird, wenn wir unsere Testfälle ausführen.
Ich habe Istanbul (ein Testabdeckungstool), nyc (den CLI-Client von Instabul) und Overalls verwendet.
Laut den Dokumenten instrumentiert Istanbul Ihren ES5- und ES2015+-JavaScript-Code mit Zeilenzählern, sodass Sie nachverfolgen können, wie gut Ihre Komponententests Ihre Codebasis ausführen.
In meiner Datei package.json “ führt das Testskript die Tests aus und generiert einen Bericht.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } Dabei wird ein .nyc_output Ordner erstellt, der die rohen Abdeckungsinformationen und einen coverage enthält, der die Abdeckungsberichtsdateien enthält. Beide Dateien sind in meinem Repo nicht erforderlich, daher habe ich sie in der .gitignore -Datei abgelegt.
Nachdem wir nun einen Bericht erstellt haben, müssen wir ihn an Overalls senden. Eine coole Sache an Overalls (und anderen Abdeckungstools, nehme ich an) ist, wie es Ihre Testabdeckung meldet. Die Abdeckung wird auf Dateibasis aufgeschlüsselt, und Sie können die relevante Abdeckung, abgedeckte und verpasste Zeilen und Änderungen in der Build-Abdeckung sehen.
Installieren Sie zunächst das Overalls-npm-Paket. Sie müssen sich auch bei Overalls anmelden und das Repo hinzufügen.
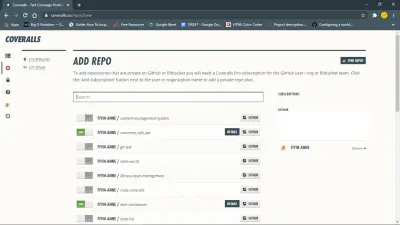
Richten Sie dann Overalls für Ihr Javascript-Projekt ein, indem Sie eine coveralls.yml -Datei in Ihrem Stammverzeichnis erstellen. Diese Datei enthält Ihr repo-token , das Sie aus dem Einstellungsbereich für Ihr Repo auf Overalls erhalten haben.
Ein weiteres Skript, das in der Datei „package.json“ benötigt wird, sind die Coverage-Skripts. Dieses Skript ist praktisch, wenn wir einen Build über Aktionen erstellen.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Grundsätzlich führt es die Tests durch, erhält den Bericht und sendet ihn zur Analyse an Overalls.
Nun zum Hauptpunkt dieses Tutorials.
Node JS-Workflow-Datei erstellen
An diesem Punkt haben wir die erforderlichen Jobs eingerichtet, die wir in unserer GitHub-Aktion ausführen werden. (Sie fragen sich, was „Jobs“ bedeuten? Lesen Sie weiter.)
GitHub hat es einfach gemacht, die Workflow-Datei zu erstellen, indem es eine Startervorlage bereitstellt. Wie auf der Seite „Aktionen“ zu sehen ist, gibt es mehrere Workflow-Vorlagen, die unterschiedlichen Zwecken dienen. Für dieses Tutorial verwenden wir den Node.js-Workflow (den GitHub bereits freundlicherweise vorgeschlagen hat).
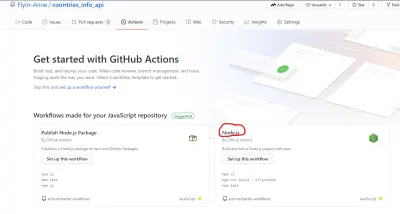
Sie können die Datei direkt auf GitHub bearbeiten, aber ich werde die Datei manuell in meinem lokalen Repo erstellen. Der Ordner .github/workflows mit der Datei node.js.yml befindet sich im Stammverzeichnis.
Diese Datei enthält bereits einige grundlegende Befehle und der erste Kommentar erklärt, was sie tun.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeIch werde einige Änderungen daran vornehmen, damit es zusätzlich zu dem obigen Kommentar auch eine Abdeckung gibt.
Meine .node.js.yml -Datei:
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}Was bedeutet das?
Lass es uns aufschlüsseln.
-
name
Dies wäre der Name Ihres Workflows (NodeJS CI) oder Jobs (Build) und GitHub zeigt ihn auf der Aktionsseite Ihres Repositorys an. -
on
Dies ist das Ereignis, das den Workflow auslöst. Diese Zeile in meiner Datei weist GitHub im Grunde an, den Workflow auszulösen, wenn ein Push an mein Repo erfolgt. -
jobs
Ein Arbeitsablauf kann mindestens einen oder mehrere Jobs enthalten, und jeder Job wird in einer Umgebung ausgeführt, die durchruns-onangegeben wird. Im obigen Dateibeispiel gibt es nur einen Job, der den Build ausführt und auch Coverage ausführt, und er wird in einer Windows-Umgebung ausgeführt. Ich kann es auch in zwei verschiedene Jobs aufteilen:
Aktualisierte Node.yml-Datei
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Diese enthält die Umgebungsvariablen, die für alle oder bestimmte Jobs und Schritte im Workflow verfügbar sind. Im Coverage-Job können Sie sehen, dass die Umgebungsvariablen „ausgeblendet“ wurden. Sie finden sie auf der Secrets-Seite Ihres Repos unter Einstellungen. -
steps
Dies ist im Grunde eine Liste der Schritte, die beim Ausführen dieses Jobs ausgeführt werden müssen. - Der
build-Job macht eine Reihe von Dingen:- Es verwendet eine Checkout-Aktion (v2 steht für die Version), die Ihr Repository buchstäblich auscheckt, sodass es für Ihren Workflow zugänglich ist;
- Es verwendet eine setup-node-Aktion, die die zu verwendende Node-Umgebung einrichtet;
- Es führt Installations-, Build- und Testskripte aus, die in unserer Datei „package.json“ enthalten sind.
-
coverage
Dabei wird eine coverallsapp-Aktion verwendet, die die LCOV-Abdeckungsdaten Ihrer Testsuite zur Analyse an coveralls.io sendet.
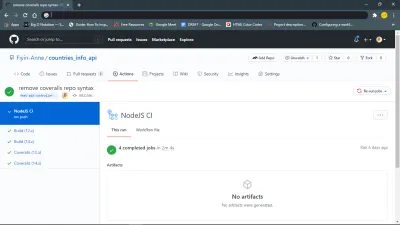
Ich habe zunächst einen Push zu meinem feat-add-controllers-and-route Zweig gemacht und vergessen, das repo_token von Coveralls zu meiner .coveralls.yml -Datei hinzuzufügen, also habe ich den Fehler erhalten, den Sie in Zeile 132 sehen können.
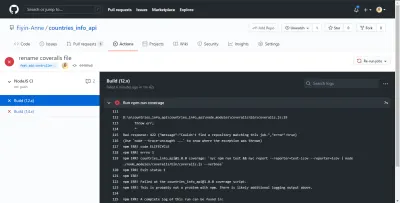
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Nachdem ich das repo_token hinzugefügt hatte, konnte mein Build erfolgreich ausgeführt werden. Ohne dieses Token wären Overalls nicht in der Lage, meine Testabdeckungsanalyse ordnungsgemäß zu melden. Gut, dass unser GitHub Actions CI auf den Fehler hingewiesen hat, bevor er in den Hauptzweig gepusht wurde.
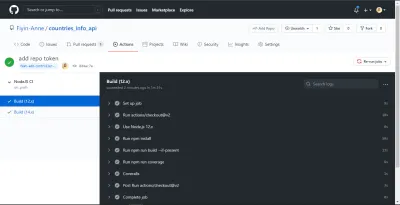
NB: Diese wurden aufgenommen, bevor ich den Job in zwei Jobs aufteilte. Außerdem konnte ich die Coverage-Zusammenfassung – und die Fehlermeldung – auf meinem Terminal sehen, weil ich das Flag --verbose am Ende meines Coverage-Skripts hinzugefügt habe
Fazit
Wir können sehen, wie wir eine kontinuierliche Integration für unsere Projekte einrichten und auch die Testabdeckung mit den von GitHub bereitgestellten Aktionen integrieren. Es gibt so viele andere Möglichkeiten, wie dies an die Anforderungen Ihres Projekts angepasst werden kann. Obwohl das in diesem Tutorial verwendete Beispiel-Repository ein wirklich kleines Projekt ist, können Sie sehen, wie wichtig Continuous Integration sogar in einem größeren Projekt ist. Nachdem meine Jobs nun erfolgreich gelaufen sind, bin ich zuversichtlich, die Filiale mit meiner Hauptfiliale zusammenzuführen. Ich würde trotzdem dazu raten, sich nach jedem Durchlauf auch die Ergebnisse der Schritte durchzulesen, um zu sehen, ob es rundum gelungen ist.