
Hinzufügen von Code-Splitting-Funktionen zu einer WordPress-Website über PoP
Veröffentlicht: 2022-03-10Geschwindigkeit gehört heutzutage zu den obersten Prioritäten für jede Website. Eine Möglichkeit, das Laden einer Website zu beschleunigen, ist das Code-Splitting: Aufteilen einer Anwendung in Teile, die bei Bedarf geladen werden können – Laden nur des erforderlichen JavaScripts, das benötigt wird, und sonst nichts. Websites, die auf JavaScript-Frameworks basieren, können Code-Splitting sofort über Webpack, den beliebten JavaScript-Bundler, implementieren. Für WordPress-Websites ist es jedoch nicht so einfach. Erstens wurde Webpack nicht absichtlich für die Arbeit mit WordPress entwickelt, daher erfordert die Einrichtung eine ziemliche Problemumgehung. Zweitens scheinen keine Tools verfügbar zu sein, die native On-Demand-Funktionen zum Laden von Assets für WordPress bieten.
Angesichts dieses Mangels an einer geeigneten Lösung für WordPress entschied ich mich, meine eigene Version von Code-Splitting für PoP zu implementieren, ein von mir erstelltes Open-Source-Framework zum Erstellen von WordPress-Websites. Eine WordPress-Website mit installiertem PoP verfügt nativ über Code-Splitting-Funktionen, sodass sie nicht von Webpack oder einem anderen Bundler abhängig sein muss. In diesem Artikel zeige ich Ihnen, wie es gemacht wird, und erkläre, welche Entscheidungen basierend auf Aspekten der Architektur des Frameworks getroffen wurden. Am Ende werde ich die Leistung einer Website mit und ohne Code-Splitting analysieren und die Vor- und Nachteile der Verwendung einer benutzerdefinierten Implementierung gegenüber einem externen Bundler analysieren. Ich hoffe, Sie genießen die Fahrt!
Definieren der Strategie
Code-Splitting kann grob in diese zwei Schritte unterteilt werden:
- Berechnung, welche Assets für jede Route geladen werden müssen,
- Dynamisches Laden dieser Assets bei Bedarf.
Um den ersten Schritt anzugehen, müssen wir eine Asset-Abhängigkeitskarte erstellen, die alle Assets in unserer Anwendung enthält. Assets müssen dieser Map rekursiv hinzugefügt werden – Abhängigkeiten von Abhängigkeiten müssen ebenfalls hinzugefügt werden, bis kein weiteres Asset mehr benötigt wird. Wir können dann alle Abhängigkeiten berechnen, die für eine bestimmte Route erforderlich sind, indem wir die Asset-Abhängigkeitskarte durchlaufen, beginnend am Einstiegspunkt der Route (dh der Datei oder dem Codeabschnitt, von dem aus sie ausgeführt wird) bis hinunter zur letzten Ebene.
Um den zweiten Schritt anzugehen, könnten wir berechnen, welche Assets für die angeforderte URL auf der Serverseite benötigt werden, und dann entweder die Liste der benötigten Assets in der Antwort senden, woraufhin die Anwendung sie laden müsste, oder direkt HTTP/ 2 Schieben Sie die Ressourcen neben die Antwort.
Diese Lösungen sind jedoch nicht optimal. Im ersten Fall muss die Anwendung alle Assets anfordern, nachdem die Antwort zurückgegeben wurde, sodass es eine zusätzliche Reihe von Roundtrip-Anforderungen zum Abrufen der Assets geben würde und die Ansicht nicht generiert werden könnte, bevor alle geladen wurden der Benutzer muss warten (dieses Problem wird dadurch gemildert, dass alle Assets von Servicemitarbeitern vorab zwischengespeichert werden, sodass die Wartezeit verkürzt wird, aber wir können das Analysieren der Assets nicht vermeiden, das erst nach der Antwort erfolgt). Im zweiten Fall könnten wir dieselben Assets wiederholt pushen (es sei denn, wir fügen zusätzliche Logik hinzu, um anzuzeigen, welche Ressourcen wir bereits durch Cookies geladen haben, aber dies fügt tatsächlich unerwünschte Komplexität hinzu und verhindert, dass die Antwort zwischengespeichert wird), und wir kann die Assets nicht von einem CDN bereitstellen.
Aus diesem Grund habe ich mich entschieden, diese Logik auf der Client-Seite handhaben zu lassen. Eine Liste, welche Assets für jede Route benötigt werden, wird der Anwendung auf dem Client zur Verfügung gestellt, sodass sie bereits weiß, welche Assets für die angeforderte URL benötigt werden. Damit werden die oben genannten Probleme behoben:
- Assets können sofort geladen werden, ohne auf die Antwort des Servers warten zu müssen. (Wenn wir das mit Servicemitarbeitern koppeln, können wir ziemlich sicher sein, dass alle Ressourcen geladen und geparst sind, wenn die Antwort zurückkommt, sodass es keine zusätzliche Wartezeit gibt.)
- Die Anwendung weiß, welche Assets bereits geladen wurden; Daher werden nicht alle für diese Route erforderlichen Assets angefordert, sondern nur die Assets, die noch nicht geladen wurden.
Der negative Aspekt bei der Bereitstellung dieser Liste an das Frontend ist, dass sie je nach Größe der Website (z. B. wie viele Routen sie zur Verfügung stellt) sehr umfangreich werden kann. Wir müssen einen Weg finden, es zu laden, ohne die wahrgenommene Ladezeit der Anwendung zu verlängern. Dazu später mehr.
Nachdem wir diese Entscheidungen getroffen haben, können wir mit dem Design fortfahren und dann Code-Splitting in der Anwendung implementieren. Zum leichteren Verständnis wurde der Prozess in die folgenden Schritte unterteilt:
- Verständnis der Architektur der Anwendung,
- Asset-Abhängigkeiten abbilden,
- Auflistung aller Anwendungswege,
- Generieren einer Liste, die definiert, welche Assets für jede Route erforderlich sind,
- Assets dynamisch laden,
- Anwenden von Optimierungen.
Lassen Sie uns direkt darauf eingehen!
0. Die Architektur der Anwendung verstehen
Wir müssen die Beziehung aller Assets zueinander abbilden. Lassen Sie uns die Besonderheiten der PoP-Architektur durchgehen, um die am besten geeignete Lösung zum Erreichen dieses Ziels zu entwerfen.
PoP ist eine Schicht, die WordPress umschließt und es uns ermöglicht, WordPress als das CMS zu verwenden, das die Anwendung antreibt, und dennoch ein benutzerdefiniertes JavaScript-Framework bereitstellt, um Inhalte auf der Client-Seite zu rendern, um dynamische Websites zu erstellen. Es definiert die Bauelemente der Webseite neu: Während WordPress derzeit auf dem Konzept hierarchischer Templates basiert, die HTML erzeugen (wie single.php , home.php und archive.php ), basiert PoP auf dem Konzept von „Modulen, “, die entweder eine atomare Funktionalität oder eine Zusammensetzung anderer Module sind. Das Erstellen einer PoP-Anwendung ähnelt dem Spielen mit LEGO – das Stapeln von Modulen übereinander oder das Verpacken von einander, wodurch letztendlich eine komplexere Struktur entsteht. Man könnte es sich auch als Implementierung von Brad Frosts Atomdesign vorstellen, und es sieht so aus:
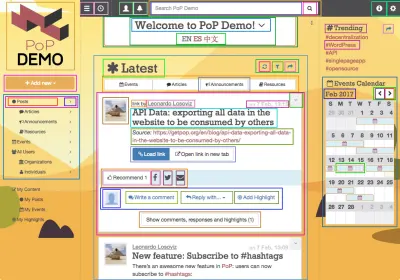
Module können in Einheiten höherer Ordnung gruppiert werden, nämlich: Blöcke, BlockGruppen, Seitenabschnitte und TopLevels. Diese Entitäten sind ebenfalls Module, nur mit zusätzlichen Eigenschaften und Verantwortlichkeiten, und sie enthalten sich gegenseitig, indem sie einer strikten Top-Down-Architektur folgen, in der jedes Modul die Eigenschaften aller seiner inneren Module sehen und ändern kann. Die Beziehung zwischen den Modulen ist wie folgt:
- 1 oberste Ebene enthält N Seitenabschnitte,
- 1 Seitenabschnitt enthält N Blöcke oder Blockgruppen,
- 1 blockGroup enthält N Blöcke oder blockGroups,
- 1 Block enthält N Module,
- 1 Modul enthält N Module, ad infinitum.
Ausführen von JavaScript-Code in PoP
PoP erstellt dynamisch HTML, indem es beginnend auf der pageSection-Ebene durch alle Module der Reihe nach iteriert, jedes von ihnen durch die vordefinierte Handlebars-Vorlage des Moduls rendert und schließlich die entsprechenden neu erstellten Elemente des Moduls in das DOM einfügt. Sobald dies geschehen ist, führt es JavaScript-Funktionen auf ihnen aus, die modulweise vordefiniert sind.
PoP unterscheidet sich von JavaScript-Frameworks (wie React und AngularJS) darin, dass der Ablauf der Anwendung nicht vom Client ausgeht, sondern immer noch im Backend innerhalb der Modulkonfiguration (die in einem PHP-Objekt codiert ist) konfiguriert wird. Beeinflusst von WordPress-Action-Hooks implementiert PoP ein Publish-Subscribe-Muster:
- Jedes Modul definiert, welche JavaScript-Funktionen auf seinen entsprechenden neu erstellten DOM-Elementen ausgeführt werden müssen, ohne unbedingt im Voraus zu wissen, was diesen Code ausführt oder woher er kommt.
- JavaScript-Objekte müssen registrieren, welche JavaScript-Funktionen sie implementieren.
- Schließlich berechnet PoP zur Laufzeit, welche JavaScript-Objekte welche JavaScript-Funktionen ausführen müssen, und ruft sie entsprechend auf.
Beispielsweise zeigt ein Kalendermodul über sein entsprechendes PHP-Objekt an, dass die calendar für seine DOM-Elemente wie folgt ausgeführt werden muss:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Dann gibt ein JavaScript-Objekt – in diesem Fall popFullCalendar – bekannt, dass es die calendar implementiert hat. Dies geschieht durch Aufrufen von popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Schließlich führt popJSLibraryManager den Abgleich durch, was welchen Code ausführt. Es ermöglicht JavaScript-Objekten, zu registrieren, welche Funktionen sie implementieren, und stellt eine Methode bereit, um eine bestimmte Funktion von allen abonnierten JavaScript-Objekten auszuführen:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Nachdem dem DOM ein neues Kalenderelement mit der ID „ calendar-293 “ hinzugefügt wurde, führt PoP einfach die folgende Funktion aus:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Einstiegspunkt
Für PoP ist der Einstiegspunkt zum Ausführen von JavaScript-Code diese Zeile am Ende der HTML-Ausgabe:
<script type="text/javascript">popManager.init();</script> popManager.init() initialisiert zuerst das Front-End-Framework und führt dann die JavaScript-Funktionen aus, die von allen gerenderten Modulen definiert werden, wie oben erläutert. Unten ist eine sehr vereinfachte Form dieser Funktion (der Originalcode ist auf GitHub). Durch Aufrufen von popJSLibraryManager.execute('pageSectionInitialized', pageSection) und popJSLibraryManager.execute('documentInitialized') alle JavaScript-Objekte, die diese Funktionen implementieren ( pageSectionInitialized und documentInitialized ), diese aus.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); Die Funktion runJSMethods führt die JavaScript-Methoden aus, die für jedes einzelne Modul definiert sind, beginnend mit pageSection, dem obersten Modul, und dann die ganze Reihe für alle seine inneren Blöcke und deren innere Module:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);Zusammenfassend lässt sich sagen, dass die JavaScript-Ausführung in PoP lose gekoppelt ist: Anstatt hart fixierte Abhängigkeiten zu haben, führen wir JavaScript-Funktionen über Hooks aus, die jedes JavaScript-Objekt abonnieren kann.
Webseiten und APIs
Eine PoP-Website ist eine selbst verbrauchte API. In PoP gibt es keinen Unterschied zwischen einer Webseite und einer API: Jede URL gibt standardmäßig die Webseite zurück, und durch einfaches Hinzufügen des Parameters output=json wird stattdessen ihre API zurückgegeben (z. B. getpop.org/en/ ist eine Webseite und getpop.org/en/?output=json ist ihre API). Die API wird zum dynamischen Rendern von Inhalten in PoP verwendet; Wenn Sie also auf einen Link zu einer anderen Seite klicken, wird die API angefordert, da bis dahin der Frame der Website geladen ist (z. B. die obere und seitliche Navigation) – dann werden die für den API-Modus erforderlichen Ressourcen bereitgestellt eine Teilmenge davon von der Webseite sein. Dies müssen wir bei der Berechnung der Abhängigkeiten für eine Route berücksichtigen: Das Laden der Route beim ersten Laden der Website oder das dynamische Laden durch Klicken auf einen Link führt zu unterschiedlichen Sätzen erforderlicher Assets.
Dies sind die wichtigsten Aspekte von PoP, die das Design und die Implementierung von Code-Splitting definieren werden. Fahren wir mit dem nächsten Schritt fort.
1. Zuordnung von Asset-Abhängigkeiten
Wir könnten für jede JavaScript-Datei eine Konfigurationsdatei hinzufügen, in der ihre expliziten Abhängigkeiten aufgeführt sind. Dies würde jedoch Code duplizieren und wäre schwierig konsistent zu halten. Eine sauberere Lösung wäre, die JavaScript-Dateien als einzige Quelle der Wahrheit zu behalten, den Code aus ihnen zu extrahieren und diesen Code dann zu analysieren, um die Abhängigkeiten neu zu erstellen.
Die Metadaten, nach denen wir in den JavaScript-Quelldateien suchen, um das Mapping neu erstellen zu können, sind die folgenden:
- interne Methodenaufrufe wie
this.runJSMethods(...); - externe Methodenaufrufe wie
popJSRuntimeManager.getDOMElements(...); - alle Vorkommen von
popJSLibraryManager.execute(...), die eine JavaScript-Funktion in allen Objekten ausführt, die sie implementieren; - alle Vorkommen von
popJSLibraryManager.register(...), um zu ermitteln, welche JavaScript-Objekte welche JavaScript-Methoden implementieren.
Wir werden jParser und jTokenizer verwenden, um unsere JavaScript-Quelldateien in PHP zu tokenisieren und die Metadaten wie folgt zu extrahieren:
- Interne Methodenaufrufe (z. B.
this.runJSMethods) werden abgeleitet, wenn die folgende Sequenz gefunden wird: entweder tokenthisoderthat+.+ ein anderes Token, das der Name für die interne Methode ist (runJSMethods). - Externe Methodenaufrufe (wie
popJSRuntimeManager.getDOMElements) werden abgeleitet, wenn die folgende Sequenz gefunden wird: ein Token, das in der Liste aller JavaScript-Objekte in unserer Anwendung enthalten ist (wir benötigen diese Liste im Voraus; in diesem Fall enthält sie das ObjektpopJSRuntimeManager) +.+ ein anderes Token, das der Name für die externe Methode ist (getDOMElements). - Immer wenn wir
popJSLibraryManager.execute("someFunctionName")finden, leiten wir die Javascript-Methode alssomeFunctionName. - Immer wenn wir
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])finden, leiten wir das Javascript-ObjektsomeJSObject, um die MethodensomeFunctionName1,someFunctionName2zu implementieren.
Ich habe das Skript implementiert, werde es hier aber nicht beschreiben. (Es ist zu lang, bringt nicht viel Wert, kann aber im Repository von PoP gefunden werden). Das Skript, das beim Anfordern einer internen Seite auf dem Entwicklungsserver der Website ausgeführt wird (über die Methodik habe ich in einem früheren Artikel über Servicemitarbeiter geschrieben), generiert die Zuordnungsdatei und speichert sie auf dem Server. Ich habe ein Beispiel für die generierte Zuordnungsdatei vorbereitet. Es ist eine einfache JSON-Datei, die die folgenden Attribute enthält:
-
internalMethodCalls
Listen Sie für jedes JavaScript-Objekt die Abhängigkeiten von internen Funktionen untereinander auf. -
externalMethodCalls
Listen Sie für jedes JavaScript-Objekt die Abhängigkeiten von internen Funktionen zu Funktionen von anderen JavaScript-Objekten auf. -
publicMethods
Listen Sie alle registrierten Methoden auf und für jede Methode, welche JavaScript-Objekte sie implementieren. -
methodExecutions
Listen Sie für jedes JavaScript-Objekt und jede interne Funktion alle Methoden auf, die durchpopJSLibraryManager.execute('someMethodName')ausgeführt werden.
Bitte beachten Sie, dass das Ergebnis noch keine Asset-Abhängigkeitskarte ist, sondern eine JavaScript-Objektabhängigkeitskarte. Aus dieser Karte können wir feststellen, wann immer eine Funktion von einem Objekt ausgeführt wird, welche anderen Objekte ebenfalls benötigt werden. Wir müssen noch für alle Assets konfigurieren, welche JavaScript-Objekte in jedem Asset enthalten sind (im jTokenizer-Skript sind JavaScript-Objekte die Token, nach denen wir suchen, um die externen Methodenaufrufe zu identifizieren, daher sind diese Informationen eine Eingabe für das Skript und können nicht aus den Quelldateien selbst bezogen werden). Dies geschieht über ResourceLoaderProcessor -PHP-Objekte wie resourceloader-processor.php.
Durch die Kombination der Karte und der Konfiguration können wir schließlich alle erforderlichen Assets für jede Route in der Anwendung berechnen.
2. Auflisten aller Anwendungsrouten
Wir müssen alle in unserer Anwendung verfügbaren Routen identifizieren. Bei einer WordPress-Website beginnt diese Liste mit der URL aus jeder der Vorlagenhierarchien. Die für PoP implementierten sind diese:
- Homepage: https://getpop.org/en/
- Autor: https://getpop.org/en/u/leo/
- einzeln: https://getpop.org/en/blog/new-feature-code-splitting/
- Tag: https://getpop.org/en/tags/internet/
- Seite: https://getpop.org/en/philosophy/
- Kategorie: https://getpop.org/en/blog/ (die Kategorie ist eigentlich als Seite implementiert, um
category/aus dem URL-Pfad zu entfernen) - 404: https://getpop.org/en/this-page-does-not-exist/
Für jede dieser Hierarchien müssen wir alle Routen erhalten, die eine eindeutige Konfiguration erzeugen (dh die einen eindeutigen Satz von Assets erfordern). Im Fall von PoP haben wir Folgendes:
- Homepage und 404 sind einzigartig.
- Tag-Seiten haben immer die gleiche Konfiguration für alle Tags. Somit reicht eine einzelne URL für ein beliebiges Tag aus.
- Einzelner Beitrag hängt von der Kombination des Beitragstyps (z. B. „Veranstaltung“ oder „Beitrag“) und der Hauptkategorie des Beitrags (z. B. „Blog“ oder „Artikel“) ab. Dann brauchen wir für jede dieser Kombinationen eine URL.
- Die Konfiguration einer Kategorieseite hängt von der Kategorie ab. Wir brauchen also die URL jeder Post-Kategorie.
- Eine Autorenseite hängt von der Rolle des Autors ab („Individuum“, „Organisation“ oder „Gemeinschaft“). Wir benötigen also URLs für drei Autoren, von denen jeder eine dieser Rollen hat.
- Jede Seite kann ihre eigene Konfiguration haben („Anmelden“, „Kontaktieren Sie uns“, „unsere Mission“ usw.). Daher müssen alle Seiten-URLs zur Liste hinzugefügt werden.
Wie wir sehen können, ist die Liste schon ziemlich lang. Darüber hinaus kann unsere Anwendung der URL Parameter hinzufügen, die die Konfiguration ändern und möglicherweise auch ändern, welche Assets erforderlich sind. PoP bietet beispielsweise an, die folgenden URL-Parameter hinzuzufügen:
- tab (
?tab=…), um eine zugehörige Information anzuzeigen: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), um die Anzeige der Daten zu ändern: https://getpop.org/en/blog/?format=list; - target (
?target=…), um die Seite in einem anderen pageSection zu öffnen: https://getpop.org/en/add-post/?target=addons.
Einige der anfänglichen Routen können einen, zwei oder sogar drei der oben genannten Parameter haben, wodurch eine breite Palette von Kombinationen entsteht:
- Einzelpost: https://getpop.org/en/blog/new-feature-code-splitting/
- Autoren einzelner Beiträge: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- Autoren einzelner Posts als Liste: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- Autoren einzelner Posts als Liste in einem modalen Fenster: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
Zusammenfassend sind für PoP alle möglichen Routen eine Kombination der folgenden Elemente:
- alle Routen der anfänglichen Vorlagenhierarchie;
- all die verschiedenen Werte, für die die Hierarchie eine andere Konfiguration erzeugt;
- alle möglichen Registerkarten für jede Hierarchie (verschiedene Hierarchien können unterschiedliche Registerkartenwerte haben: Ein einzelner Beitrag kann die Registerkarten „Autoren“ und „Antworten“ haben, während ein Autor die Registerkarten „Beiträge“ und „Follower“ haben kann);
- alle möglichen Formate für jede Registerkarte (auf verschiedene Registerkarten können unterschiedliche Formate angewendet werden: die Registerkarte „Autoren“ kann das Format „Karte“ haben, die Registerkarte „Antworten“ jedoch möglicherweise nicht);
- alle möglichen Ziele, die die Seitenabschnitte angeben, in denen jede Route angezeigt werden kann (während ein Beitrag im Hauptabschnitt oder in einem schwebenden Fenster erstellt werden kann, kann die Seite „Mit Ihren Freunden teilen“ so eingestellt werden, dass sie in einem modalen Fenster geöffnet wird).
Daher kann für eine etwas komplexe Anwendung die Erstellung der Liste mit allen Routen nicht manuell durchgeführt werden. Wir müssen dann ein Skript erstellen, um diese Informationen aus der Datenbank zu extrahieren, sie zu manipulieren und sie schließlich im erforderlichen Format auszugeben. Dieses Skript erhält alle Beitragskategorien, aus denen wir die Liste aller verschiedenen Kategorieseiten-URLs erstellen können, und fragt dann für jede Kategorie die Datenbank nach einem beliebigen Beitrag unter derselben ab, wodurch die URL für eine einzelne erzeugt wird Post unter jeder Kategorie, und so weiter. Das vollständige Skript ist verfügbar, beginnend mit der function get_resources() , die Hooks bereitstellt, die von jedem der Hierarchiefälle implementiert werden sollen.
3. Generieren der Liste, die definiert, welche Assets für jede Route erforderlich sind
Inzwischen haben wir die Asset-Dependency-Map und die Liste aller Routen in der Anwendung. Jetzt ist es an der Zeit, diese beiden zu kombinieren und eine Liste zu erstellen, die für jede Route angibt, welche Assets benötigt werden.
Um diese Liste zu erstellen, wenden wir das folgende Verfahren an:
- Erstellen Sie eine Liste mit allen JavaScript-Methoden, die für jede Route ausgeführt werden sollen:
Berechnen Sie die Module der Route, erhalten Sie dann die Konfiguration für jedes Modul, extrahieren Sie dann aus der Konfiguration, welche JavaScript-Funktionen das Modul ausführen muss, und fügen Sie sie alle zusammen. - Durchlaufen Sie als Nächstes die Asset-Abhängigkeitskarte für jede JavaScript-Funktion, stellen Sie die Liste aller erforderlichen Abhängigkeiten zusammen und fügen Sie sie alle zusammen.
- Fügen Sie schließlich die Handlebars-Vorlagen hinzu, die zum Rendern jedes Moduls innerhalb dieser Route erforderlich sind.
Darüber hinaus hat, wie bereits erwähnt, jede URL Webseiten- und API-Modi, daher müssen wir das obige Verfahren zweimal ausführen, einmal für jeden Modus (d. h. einmal den Parameter output=json zur URL hinzufügen, der die Route für den API-Modus darstellt, und einmaliges Beibehalten der URL für den Webseitenmodus). Wir werden dann zwei Listen erstellen, die unterschiedliche Verwendungszwecke haben werden:

- Die Webseitenmodusliste wird beim anfänglichen Laden der Website verwendet, sodass die entsprechenden Skripte für diese Route in der anfänglichen HTML-Antwort enthalten sind. Diese Liste wird auf dem Server gespeichert.
- Die API-Modusliste wird beim dynamischen Laden einer Seite auf der Website verwendet. Diese Liste wird auf dem Client geladen, damit die Anwendung berechnen kann, welche zusätzlichen Assets bei Bedarf geladen werden müssen, wenn auf einen Link geklickt wird.
Der Großteil der Logik wurde ausgehend von der function add_resources_from_settingsprocessors($fetching_json, ...) implementiert (Sie finden sie im Repository). Der Parameter $fetching_json unterscheidet zwischen Webseiten- ( false ) und API- ( true ) Modus.
Wenn das Skript für den Webseitenmodus ausgeführt wird, gibt es resourceloader-bundle-mapping.json aus, bei dem es sich um ein JSON-Objekt mit den folgenden Eigenschaften handelt:
-
bundle-ids
Dies ist eine Sammlung von bis zu vier Ressourcen (ihre Namen wurden für die Produktionsumgebung entstellt:eq=>handlebars,er=>handlebars-helpersusw.), gruppiert unter einer Bündel-ID. -
bundlegroup-ids
Dies ist eine Sammlung vonbundle-ids. Jede BundleGroup stellt einen eindeutigen Satz von Ressourcen dar. -
key-ids
Dies ist die Zuordnung zwischen Routen (dargestellt durch ihren Hash, der den Satz aller Attribute identifiziert, die eine Route eindeutig machen) und ihrer entsprechenden BundleGroup.
Wie zu beobachten ist, ist die Zuordnung zwischen einer Route und ihren Ressourcen nicht gerade. Anstatt key-ids einer Liste von Ressourcen zuzuordnen, ordnet es sie einer eindeutigen bundleGroup zu, die selbst eine Liste von bundles ist, und nur jedes Bundle ist eine Liste von resources (mit bis zu vier Elementen pro Bundle). Warum wurde das so gemacht? Dies dient zwei Zwecken:
- Es ermöglicht uns, alle Ressourcen unter einer eindeutigen BundleGroup zu identifizieren. Anstatt alle Ressourcen in die HTML-Antwort einzuschließen, können wir also ein eindeutiges JavaScript-Asset einschließen, bei dem es sich stattdessen um die entsprechende BundleGroup-Datei handelt, die alle entsprechenden Ressourcen bündelt. Dies ist nützlich, wenn Geräte bereitgestellt werden, die HTTP/2 immer noch nicht unterstützen, und es verlängert auch die Ladezeit, da das Verpacken einer einzelnen gebündelten Datei mit Gzip effektiver ist, als die einzelnen Dateien zu komprimieren und sie dann zusammenzufügen. Alternativ könnten wir auch eine Reihe von Bundles anstelle einer eindeutigen BundleGroup laden, was einen Kompromiss zwischen Ressourcen und BundleGroups darstellt (das Laden von Bundles ist aufgrund von Gziping langsamer als BundleGroups, aber es ist performanter, wenn es häufig zu Invalidierungen kommt, sodass wir würde nur das aktualisierte Bundle herunterladen und nicht die gesamte BundleGroup). Die Skripte zum Bündeln aller Ressourcen in Bundles und BundleGroups befinden sich in filegenerator-bundles.php und filegenerator-bundlegroups.php.
- Das Aufteilen der Ressourcensätze in Bündel ermöglicht es uns, gemeinsame Muster zu identifizieren (z. B. das Identifizieren von Sätzen von vier Ressourcen, die von vielen Routen gemeinsam genutzt werden), wodurch verschiedene Routen mit demselben Bündel verknüpft werden können. Als Ergebnis hat die generierte Liste eine kleinere Größe. Dies ist möglicherweise nicht von großem Nutzen für die Webseitenliste, die auf dem Server lebt, aber es ist großartig für die API-Liste, die auf dem Client geladen wird, wie wir später sehen werden.
Wenn das Skript für den API-Modus ausgeführt wird, gibt es die Datei „resources.js“ mit den folgenden Eigenschaften aus:
-
bundlesundbundle-groupsdienen demselben Zweck wie für den Webseitenmodus angegeben -
keysdienen auch dem gleichen Zweck wiekey-idsfür den Webseitenmodus. Anstatt jedoch einen Hash als Schlüssel zur Darstellung der Route zu haben, ist es eine Verkettung all jener Attribute, die eine Route einzigartig machen – in unserem Fall format (f), tab (t) und target (r). -
sourcesist die Quelldatei für jede Ressource. -
typesist das CSS oder JavaScript für jede Ressource (obwohl wir der Einfachheit halber in diesem Artikel nicht behandelt haben, dass JavaScript-Ressourcen auch CSS-Ressourcen als Abhängigkeiten festlegen können und Module ihre eigenen CSS-Assets laden können, wodurch die progressive CSS-Ladestrategie implementiert wird ). -
resourceserfasst, welche BundleGroups für jede Hierarchie geladen werden müssen. - „
ordered-load-resources“ enthält, welche Ressourcen der Reihe nach geladen werden müssen, um zu verhindern, dass Skripts vor ihren abhängigen Skripts geladen werden (standardmäßig sind sie asynchron).
Wir werden im nächsten Abschnitt untersuchen, wie Sie diese Datei verwenden.
4. Dynamisches Laden der Assets
Wie bereits erwähnt, wird die API-Liste auf dem Client geladen, sodass wir sofort mit dem Laden der erforderlichen Assets für eine Route beginnen können, nachdem der Benutzer auf einen Link geklickt hat.
Laden des Mapping-Skripts
Die generierte JavaScript-Datei mit der Liste der Ressourcen für alle Routen in der Anwendung ist nicht leicht – in diesem Fall kam sie auf 85 KB (was selbst optimiert ist, da die Ressourcennamen verstümmelt und Bündel erstellt wurden, um gemeinsame Muster über Routen hinweg zu identifizieren). . Die Parsing-Zeit sollte kein großer Engpass sein, da das Parsing von JSON zehnmal schneller ist als das Parsing von JavaScript für dieselben Daten. Die Größe ist jedoch ein Problem der Netzwerkübertragung, daher müssen wir dieses Skript so laden, dass die wahrgenommene Ladezeit der Anwendung nicht beeinträchtigt wird oder der Benutzer warten muss.
Die Lösung, die ich implementiert habe, besteht darin, diese Datei mit Service Workern vorab zu cachen, sie mit defer zu laden, damit sie den Haupt-Thread nicht blockiert, während die kritischen JavaScript-Methoden ausgeführt werden, und dann eine Fallback-Benachrichtigung anzuzeigen, wenn der Benutzer auf einen Link klickt bevor das Skript geladen ist: „Die Website wird noch geladen, bitte warten Sie einen Moment, um auf Links zu klicken.“ Dies wird erreicht, indem ein festes div mit einer Klasse von loadingscreen über allem hinzugefügt wird, während die Skripte geladen werden, und dann die Benachrichtigungsnachricht mit einer Klasse von notificationmsg innerhalb des div und diese wenigen CSS-Zeilen hinzugefügt werden:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Eine andere Lösung besteht darin, diese Datei in mehrere aufzuteilen und sie nach Bedarf nach und nach zu laden (eine Strategie, die ich bereits programmiert habe). Darüber hinaus enthält die 85-KB-Datei alle möglichen Routen in der Anwendung, einschließlich solcher Routen wie „die Ankündigungen des Autors, angezeigt in Miniaturansichten, angezeigt im Modals-Fenster“, auf die, wenn überhaupt, nur einmal in Blaumond zugegriffen werden könnte. Die am häufigsten aufgerufenen Routen sind nur wenige (Startseite, Single, Autor, Tag und alle Seiten, alle ohne zusätzliche Attribute), die eine viel kleinere Datei in der Nähe von 30 KB erzeugen sollten.
Abrufen der Route von der angeforderten URL
Wir müssen in der Lage sein, die Route anhand der angeforderten URL zu identifizieren. Zum Beispiel:
-
https://getpop.org/en/u/leo/bildet die Route „Autor“ ab, -
https://getpop.org/en/u/leo/?tab=followersbildet die Route „Autoren-Follower“ ab, -
https://getpop.org/en/tags/internet/bildet die Route „tag“ ab, -
https://getpop.org/en/tags/bildet die Route „Seite/tags/“ ab, - und so weiter.
Dazu müssen wir die URL auswerten und daraus die Elemente ableiten, die eine Route einzigartig machen: die Hierarchie und alle Attribute (Format, Tab und Ziel). Die Identifizierung der Attribute ist kein Problem, da es sich um Parameter in der URL handelt. Die einzige Herausforderung besteht darin, die Hierarchie (Startseite, Autor, Single, Seite oder Tag) aus der URL abzuleiten, indem die URL mit mehreren Mustern abgeglichen wird. Zum Beispiel,
- Alles, was mit
https://getpop.org/en/u/beginnt, ist ein Autor. - Alles, was mit aber nicht genau
https://getpop.org/en/tags/beginnt, ist ein Tag. Wenn es genauhttps://getpop.org/en/tags/ist, dann ist es eine Seite. - Und so weiter.
Die folgende Funktion, implementiert ab Zeile 321 von resourceloader.js, muss mit einer Konfiguration mit den Mustern für alle diese Hierarchien gefüttert werden. Es prüft zunächst, ob die URL keinen Unterpfad enthält – in diesem Fall ist es „home“. Dann prüft es nacheinander, ob die Hierarchien für „Autor“, „Tag“ und „Single“ übereinstimmen. Wenn es mit keinem davon erfolgreich ist, dann ist es der Standardfall, der "Seite" ist:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Da sich alle erforderlichen Daten bereits in der Datenbank befinden (alle Kategorien, alle Seiten-Slugs usw.), führen wir ein Skript aus, um diese Konfigurationsdatei automatisch in einer Entwicklungs- oder Staging-Umgebung zu erstellen. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
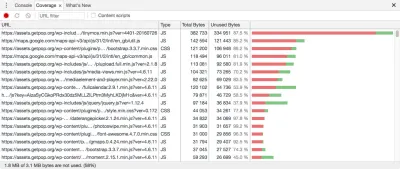
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
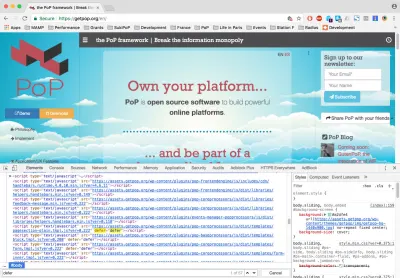
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
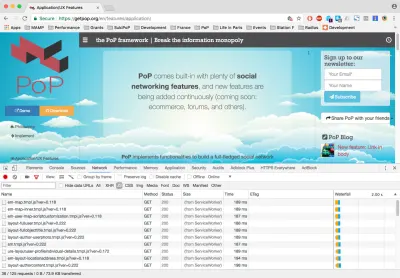
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Nachteile
- Wir müssen es aufrechterhalten.
Wenn wir nur Webpack verwenden würden, könnten wir uns auf seine Community verlassen, um die Software auf dem neuesten Stand zu halten, und könnten von seinem Plugin-Ökosystem profitieren. - Die Ausführung der Skripte dauert einige Zeit.
Die PoP-Website Agenda Urbana hat 304 verschiedene Routen, aus denen sie 422 Sätze einzigartiger Ressourcen produziert. Für diese Website dauert das Ausführen des Skripts, das die Asset-Abhängigkeitskarte generiert, mit einem MacBook Pro von 2012 etwa 8 Minuten, und das Ausführen des Skripts, das die Listen mit allen Ressourcen generiert und die Bundle- und BundleGroup-Dateien erstellt, dauert 15 Minuten . Das ist mehr als genug Zeit für einen Kaffee! - Es erfordert eine Staging-Umgebung.
Wenn wir etwa 25 Minuten warten müssen, um die Skripts auszuführen, können wir sie nicht in der Produktion ausführen. Wir brauchen eine Staging-Umgebung mit genau der gleichen Konfiguration wie das Produktionssystem. - Der Website wird ein zusätzlicher Code hinzugefügt, nur für die Verwaltung.
Der 85-KB-Code ist an sich nicht funktionsfähig, sondern einfach Code zum Verwalten von anderem Code. - Komplexität kommt hinzu.
Dies ist ohnehin unvermeidlich, wenn wir unser Vermögen in kleinere Einheiten aufteilen wollen. Webpack würde die Anwendung auch komplexer machen.
Vorteile
- Es funktioniert mit WordPress.
Webpack funktioniert nicht standardmäßig mit WordPress, und um es zum Laufen zu bringen, bedarf es einiger Workarounds. Diese Lösung funktioniert für WordPress sofort (solange PoP installiert ist). - Es ist skalierbar und erweiterbar.
Die Größe und Komplexität der Anwendung kann unbegrenzt wachsen, da die JavaScript-Dateien bei Bedarf geladen werden. - Es unterstützt Gutenberg (auch bekannt als das WordPress von morgen).
Da es uns ermöglicht, JavaScript-Frameworks nach Bedarf zu laden, unterstützt es Gutenberg-Blöcke (genannt Gutenblocks), die voraussichtlich in dem vom Entwickler gewählten Framework codiert werden, mit dem möglichen Ergebnis, dass für dieselbe Anwendung verschiedene Frameworks benötigt werden. - Es ist bequem.
Das Build-Tool kümmert sich um die Generierung der Konfigurationsdateien. Abgesehen vom Warten ist kein zusätzlicher Aufwand von uns erforderlich. - Es macht die Optimierung einfach.
Wenn ein WordPress-Plugin derzeit JavaScript-Assets selektiv laden möchte, verwendet es viele Bedingungen, um zu prüfen, ob die Seiten-ID die richtige ist. Mit diesem Tool ist das nicht nötig; der Prozess ist automatisch. - Die Anwendung wird schneller geladen.
Das war der ganze Grund, warum wir dieses Tool programmiert haben. - Es erfordert eine Staging-Umgebung.
Ein positiver Nebeneffekt ist die erhöhte Zuverlässigkeit: Wir werden die Skripte nicht in der Produktion ausführen, also werden wir dort nichts kaputt machen; der Bereitstellungsprozess wird nicht durch unerwartetes Verhalten fehlschlagen; und der Entwickler ist gezwungen, die Anwendung mit derselben Konfiguration wie in der Produktion zu testen. - Es ist an unsere Anwendung angepasst.
Es gibt keinen Overhead oder Problemumgehungen. Was wir bekommen, ist genau das, was wir brauchen, basierend auf der Architektur, mit der wir arbeiten.
Fazit: Ja, es lohnt sich, denn jetzt sind wir in der Lage, Load Assets on Demand auf unserer WordPress-Website anzuwenden und sie schneller zu laden.
Weitere Ressourcen
- Webpack, einschließlich „“Code Splitting“-Leitfaden
- „Better Webpack Builds“ (Video), K. Adam White
Integration von Webpack mit WordPress - „Gutenberg und das WordPress von morgen“, Morten Rand-Hendriksen, WP Tavern
- „WordPress untersucht einen JavaScript-Framework-unabhängigen Ansatz zum Erstellen von Gutenberg-Blöcken“, Sarah Gooding, WP Tavern