
CNN vs. RNN: Unterschied zwischen CNN und RNN
Veröffentlicht: 2021-02-25Inhaltsverzeichnis
Einführung
Auf dem Gebiet der künstlichen Intelligenz werden neuronale Netze, die vom menschlichen Gehirn inspiriert sind, häufig zum Extrahieren und Verarbeiten komplexer Informationen aus verschiedenen Daten und zur Verwendung sowohl von Convolutional Neural Networks (CNN) als auch von Recurrent Neural Networks (RNN) in solchen Anwendungen eingesetzt erweisen sich als nützlich.
In diesem Artikel werden wir die Konzepte hinter den Convolutional Neural Networks und den Recurrent Neural Networks verstehen, ihre Anwendungen sehen und die Unterschiede zwischen den beiden gängigen Typen von Neural Networks unterscheiden.
Lernen Sie maschinelles Lernen von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.
Neuronale Netze und Deep Learning
Bevor wir uns mit den Konzepten von Convolutional Neural Networks und Recurrent Neural Networks befassen, lassen Sie uns die Konzepte hinter Neural Networks verstehen und wie sie mit Deep Learning verknüpft sind.
In letzter Zeit ist Deep Learning ein Konzept, das in vielen Bereichen weit verbreitet ist und daher heutzutage ein heißes Thema ist. Aber was ist der Grund dafür, dass so viel darüber gesprochen wird? Um diese Frage zu beantworten, lernen wir das Konzept der neuronalen Netze kennen.
Kurz gesagt, neuronale Netze sind das Rückgrat von Deep Learning. Sie sind eine festgelegte Anzahl von Schichten, die aus stark miteinander verbundenen Elementen bestehen, die als Neuronen bekannt sind und eine Reihe von Transformationen an den Daten durchführen, wodurch ein eigenes Verständnis dieser Daten entsteht, das wir als Merkmale bezeichnen.

Was sind neuronale Netze?
Das erste Konzept, mit dem wir fertig werden müssen, ist das der neuronalen Netze. Wir wissen, dass das menschliche Gehirn eine der komplexen Strukturen ist, die je untersucht wurden. Aufgrund seiner Komplexität war es eine große Schwierigkeit, sein Innenleben zu entschlüsseln, aber in der Gegenwart werden verschiedene Arten von Forschungen unternommen, um seine Geheimnisse zu enthüllen. Dieses menschliche Gehirn dient als Inspiration hinter den neuronalen Netzwerkmodellen.
Per Definition sind neuronale Netze die Funktionseinheiten von Deep Learning, die diese neuronalen Netze nutzen, um die Gehirnaktivität nachzuahmen und komplexe Probleme zu lösen. Wenn Eingabedaten in das neuronale Netzwerk eingespeist werden, werden sie durch die Schichten des Perzeptrons verarbeitet und ergeben schließlich die Ausgabe.
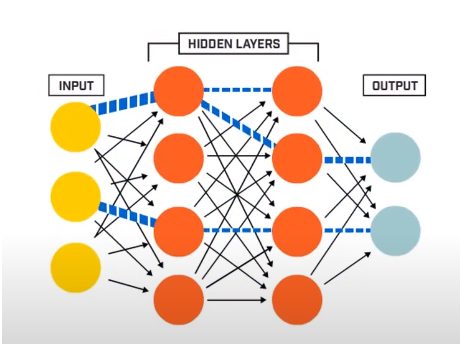
Ein neuronales Netzwerk besteht im Wesentlichen aus 3 Schichten –
- Eingabeschicht
- Versteckte Schichten
- Ausgabeschicht
Die Eingabeschicht liest die Eingabedaten, die in das neuronale Netzwerksystem eingespeist werden, um von den nachfolgenden Schichten künstlicher Neuronen weiter vorverarbeitet zu werden. Alle Schichten, die zwischen der Eingabeschicht und der Ausgabeschicht existieren, werden als verborgene Schichten bezeichnet.
In diesen verborgenen Schichten verwenden die darin vorhandenen Neuronen gewichtete Eingaben und Verzerrungen und erzeugen eine Ausgabe unter Verwendung der Aktivierungsfunktionen. Die Ausgabeschicht ist die letzte Schicht von Neuronen, die uns die Ausgabe für das gegebene Programm liefert.
Quelle
Wie funktionieren neuronale Netze?
Nachdem wir nun eine Vorstellung von der Grundstruktur neuronaler Netze haben, werden wir weitermachen und verstehen, wie sie funktionieren. Um seine Funktionsweise zu verstehen, müssen wir zunächst etwas über eine der Grundstrukturen neuronaler Netze lernen, die als Perzeptron bekannt ist.
Perceptron ist eine Art von neuronalem Netzwerk, das in seiner Form am grundlegendsten ist. Es ist ein einfaches künstliches neuronales Feed-Forward-Netzwerk mit nur einer verborgenen Schicht. Im Perceptron-Netzwerk ist jedes Neuron mit jedem anderen Neuron in Vorwärtsrichtung verbunden.
Die Verbindungen zwischen diesen Neuronen sind gewichtet, wodurch die zwischen den beiden Neuronen übertragenen Informationen durch diese Gewichtungen verstärkt oder abgeschwächt werden. Im Trainingsprozess der neuronalen Netze werden diese Gewichte angepasst, um den richtigen Wert zu erhalten.
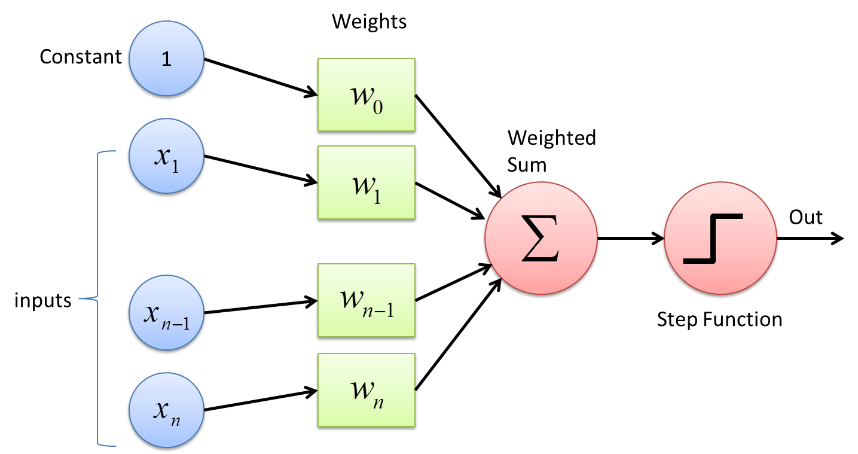
Das Perzeptron verwendet eine binäre Klassifizierungsfunktion, bei der ein Vektor von Variablen, die binärer Natur sind, auf eine einzelne binäre Ausgabe abgebildet wird. Dies kann auch beim überwachten Lernen verwendet werden. Die Schritte im Perzeptron-Lernalgorithmus sind –
- Multiplizieren Sie alle Eingaben mit ihren Gewichten w, wobei w reelle Zahlen sind, die anfänglich fest oder randomisiert sein können.
- Addieren Sie das Produkt, um die gewichtete Summe ∑ wj xj zu erhalten
- Sobald die gewichtete Summe der Eingaben erhalten ist, wird die Aktivierungsfunktion angewendet, um zu bestimmen, ob die gewichtete Summe größer als ein bestimmter Schwellenwert ist oder nicht, abhängig von der angewendeten Aktivierungsfunktion. Der Ausgang wird abhängig von der Schwellenbedingung als 1 oder 0 zugewiesen. Hier bezieht sich der Wert „-threshold“ auch auf den Begriff Bias, b.
Auf diese Weise kann der Perzeptron-Lernalgorithmus verwendet werden, um die Neuronen zu aktivieren (Wert = 1), die in den heute entworfenen und entwickelten neuronalen Netzen vorhanden sind. Eine andere Darstellung des Perzeptron-Lernalgorithmus ist –
f(x) = 1, falls ∑ wj xj + b ≥ 0
0, wenn ∑ wj xj + b < 0
Obwohl die Perceptrons heutzutage nicht weit verbreitet sind, bleiben sie immer noch eines der Kernkonzepte in neuronalen Netzwerken. Bei weiterer Forschung wurde klar, dass kleine Änderungen entweder der Gewichte oder der Verzerrung in nur einem Perzeptron die Ausgabe von 1 auf 0 oder umgekehrt stark verändern können. Dies war ein großer Nachteil des Perceptron. Daher wurden komplexere Aktivierungsfunktionen wie die ReLU-, Sigmoid-Funktionen entwickelt, die nur mäßige Änderungen in den Gewichten und Vorspannungen der künstlichen Neuronen einführen.
Quelle
Faltungsneuronale Netze
Ein Convolutional Neural Network ist ein Deep-Learning-Algorithmus, der ein Bild als Eingabe nimmt und verschiedenen Teilen des Bildes verschiedene Gewichte und Verzerrungen zuweist, sodass sie voneinander unterscheidbar sind. Sobald sie differenzierbar sind, kann das Convolutional Neural Network Model unter Verwendung verschiedener Aktivierungsfunktionen mehrere Aufgaben in der Bildverarbeitungsdomäne ausführen, einschließlich Bilderkennung, Bildklassifizierung, Objekt- und Gesichtserkennung usw.
Die Grundlage eines Convolutional Neural Network-Modells besteht darin, dass es ein Eingangsbild empfängt. Das Eingabebild kann entweder beschriftet (z. B. Katze, Hund, Löwe usw.) oder unbeschriftet sein. Abhängig davon werden die Deep-Learning-Algorithmen in zwei Typen eingeteilt, nämlich die überwachten Algorithmen, bei denen die Bilder beschriftet sind, und die nicht überwachten Algorithmen, bei denen die Bilder keine bestimmte Bezeichnung erhalten.
Für die Computermaschine wird das Eingabebild als ein Array von Pixeln gesehen, häufiger in Form einer Matrix. Bilder haben meistens die Form hxbxd (wobei h = Höhe, w = Breite, d = Abmessung). Beispielsweise bezeichnet ein Bild der Größe 16 x 16 x 3 Matrix-Array ein RGB-Bild (3 steht für die RGB-Werte). Andererseits repräsentiert ein Bild einer 14 x 14 x 1-Matrixanordnung ein Graustufenbild.
Quelle
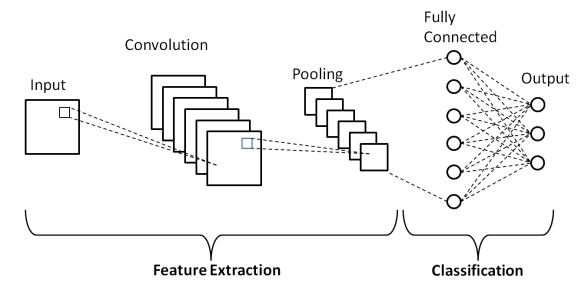
Schichten des Convolutional Neural Network
Wie in der obigen grundlegenden Architektur eines Convolutional Neural Network gezeigt, besteht ein CNN-Modell aus mehreren Schichten, durch die die Eingabebilder einer Vorverarbeitung unterzogen werden, um die Ausgabe zu erhalten. Grundsätzlich werden diese Schichten in zwei Teile unterschieden –

- Die ersten drei Schichten umfassen die Eingabeschicht, die Faltungsschicht und die Pooling-Schicht, die als Werkzeug zur Merkmalsextraktion dient, um die Merkmale auf Basisebene aus den in das Modell eingespeisten Bildern abzuleiten.
- Die endgültige vollständig verbundene Schicht und die Ausgabeschicht verwenden die Ausgabe der Merkmalsextraktionsschichten und sagen eine Klasse für das Bild in Abhängigkeit von den extrahierten Merkmalen voraus.
Die erste Ebene ist die Eingabeebene , in der das Bild in Form eines Matrix-Arrays, dh 32 x 32 x 3, in das Convolutional Neural Network Model eingespeist wird, wobei 3 angibt, dass das Bild ein RGB-Bild mit gleicher Höhe und Breite ist von 32 Pixeln. Dann passieren diese Eingabebilder die Faltungsschicht , wo die mathematische Operation der Faltung durchgeführt wird.
Das Eingabebild wird mit einer anderen quadratischen Matrix gefaltet, die als Kernel oder Filter bekannt ist. Indem wir den Kernel einzeln über die Pixel des Eingabebildes schieben, erhalten wir das Ausgabebild, das als Merkmalskarte bekannt ist und Informationen über die Basismerkmale des Bildes wie Kanten und Linien bereitstellt.
Auf die Faltungsschicht folgt die Pooling-Schicht, deren Ziel es ist, die Größe der Feature-Map zu reduzieren, um die Rechenkosten zu reduzieren. Dies geschieht durch verschiedene Arten von Pooling wie Max Pooling, Average Pooling und Sum Pooling.
Die Fully Connected (FC)-Schicht ist die vorletzte Schicht des Convolutional Neural Network Model, in der die Schichten abgeflacht und der FC-Schicht zugeführt werden. Hier findet durch Verwendung von Aktivierungsfunktionen wie den Sigmoid-, ReLU- und tanH-Funktionen die Label-Vorhersage statt und wird in der endgültigen Ausgabeschicht ausgegeben .
Wo die CNNs zu kurz kommen
Bei so vielen nützlichen Anwendungen des Convolutional Neural Network in visuellen Bilddaten haben die CNNs einen kleinen Nachteil, da sie mit einer Bildfolge (Videos) nicht gut funktionieren und die zeitlichen Informationen und Textblöcke nicht interpretieren können.
Um mit zeitlichen oder sequentiellen Daten wie den Sätzen umgehen zu können, benötigen wir Algorithmen, die aus den vergangenen Daten und auch den zukünftigen Daten in der Sequenz lernen. Glücklicherweise tun die Recurrent Neural Networks genau das.
Wiederkehrende neuronale Netze
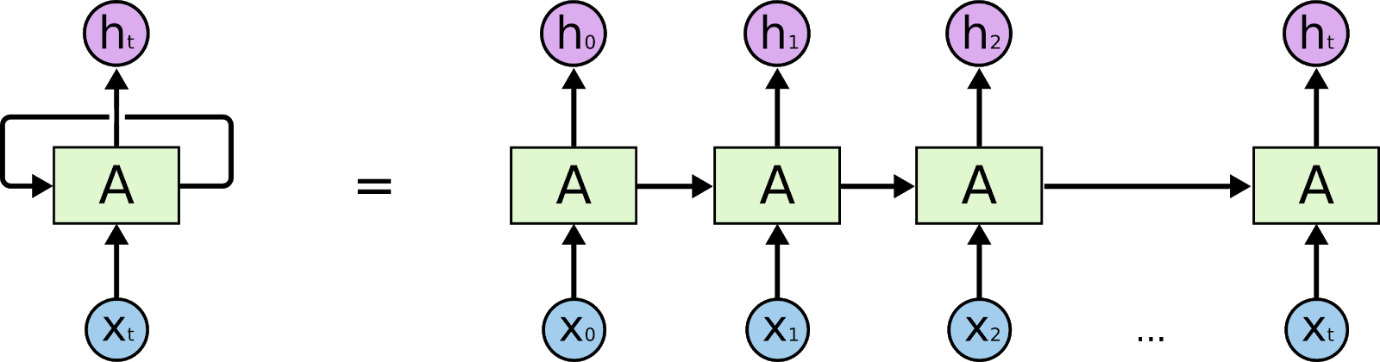
Wiederkehrende neuronale Netze sind Netze, die dafür ausgelegt sind, zeitliche oder sequentielle Informationen zu interpretieren. RNNs verwenden andere Datenpunkte in einer Sequenz, um bessere Vorhersagen zu treffen. Sie tun dies, indem sie Eingaben aufnehmen und die Aktivierungen vorheriger Knoten oder späterer Knoten in der Sequenz wiederverwenden, um die Ausgabe zu beeinflussen.
Quelle
Aufgrund ihres internen Gedächtnisses können sich rekurrente neuronale Netze wichtige Details merken, wie zum Beispiel die Eingaben, die sie erhalten haben, wodurch sie sehr präzise vorhersagen können, was als Nächstes kommt. Daher sind sie der bevorzugte Algorithmus für sequentielle Daten wie Zeitreihen, Sprache, Text, Audio, Video und viele mehr. Rekurrente neuronale Netze können im Vergleich zu anderen Algorithmen ein viel tieferes Verständnis einer Sequenz und ihres Kontexts vermitteln.
Wie funktionieren wiederkehrende neuronale Netze?
Die Grundlagen für das Verständnis der Arbeit an rekurrenten neuronalen Netzen sind die gleichen wie bei den Convolutional Neural Networks, den einfachen Feed-Forward Neural Networks, auch bekannt als Perceptron. Darüber hinaus wird in rekurrenten neuronalen Netzwerken die Ausgabe des vorherigen Schritts als Eingabe in den aktuellen Schritt eingespeist. In den meisten neuronalen Netzwerken ist die Ausgabe normalerweise unabhängig von den Eingaben und umgekehrt, dies ist der grundlegende Unterschied zwischen dem RNN und anderen neuronalen Netzwerken.
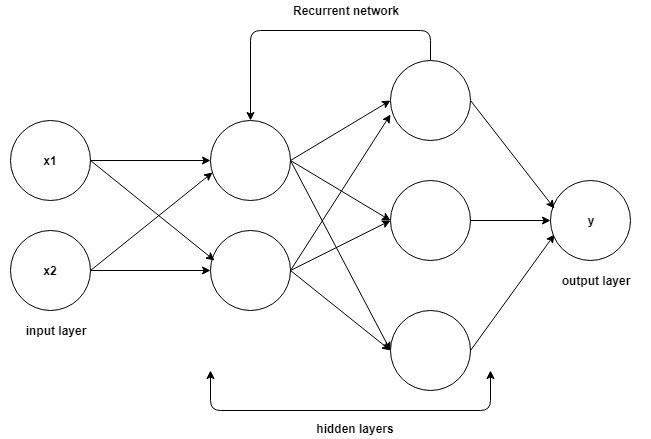
Quelle
Daher hat ein RNN zwei Eingaben: die Gegenwart und die jüngste Vergangenheit. Dies ist wichtig, da die Datenfolge entscheidende Informationen darüber enthält, was als nächstes kommt, weshalb ein RNN Dinge tun kann, die andere Algorithmen nicht können. Das wichtigste und wichtigste Merkmal von Recurrent Neural Networks ist der Hidden-Zustand, der sich an einige Informationen über eine Sequenz erinnert.
Die rekurrenten neuronalen Netze haben einen Speicher, der alle Informationen darüber speichert, was berechnet wurde. Indem die gleichen Parameter für jede Eingabe verwendet werden und die gleiche Aufgabe an allen Eingaben oder versteckten Schichten durchgeführt wird, wird die Komplexität der Parameter reduziert.
Unterschied zwischen CNN und RNN
| Faltungsneuronale Netze | Wiederkehrende neuronale Netze |
| Beim Deep Learning ist ein Convolutional Neural Network (CNN oder ConvNet) eine Klasse von Deep Neural Networks, die am häufigsten zur Analyse visueller Bilder verwendet werden. | Ein rekurrentes neuronales Netzwerk (RNN) ist eine Klasse künstlicher neuronaler Netzwerke, bei denen Verbindungen zwischen Knoten einen gerichteten Graphen entlang einer zeitlichen Sequenz bilden. |
| Es eignet sich für räumliche Daten wie Bilder. | RNN wird für zeitliche Daten verwendet, die auch als sequentielle Daten bezeichnet werden. |
| CNN ist eine Art künstliches neuronales Feed-Forward-Netzwerk mit Variationen von mehrschichtigen Perzeptrons, die so konzipiert sind, dass minimale Mengen an Vorverarbeitung erforderlich sind. | RNN können im Gegensatz zu neuronalen Feed-Forward-Netzwerken ihren internen Speicher verwenden, um beliebige Sequenzen von Eingaben zu verarbeiten. |
| CNN gilt als mächtiger als RNN. | RNN bietet im Vergleich zu CNN weniger Funktionskompatibilität. |
| Dieses CNN nimmt Eingaben fester Größe und erzeugt Ausgaben fester Größe. | RNN kann beliebige Ein-/Ausgabelängen handhaben. |
| CNNs sind ideal für die Bild- und Videoverarbeitung. | RNNs sind ideal für die Text- und Sprachanalyse. |
| Zu den Anwendungen gehören Bilderkennung, Bildklassifizierung, medizinische Bildanalyse, Gesichtserkennung und Computer Vision. | Zu den Anwendungen gehören Textübersetzung, Verarbeitung natürlicher Sprache, Sprachübersetzung, Stimmungsanalyse und Sprachanalyse. |
Fazit
Daher haben wir in diesem Artikel über die Unterschiede zwischen den beiden beliebtesten Arten von neuronalen Netzwerken, Convolutional Neural Networks und Recurrent Neural Networks, die grundlegende Struktur eines neuronalen Netzwerks zusammen mit den Grundlagen von CNN und RNN kennengelernt und abschließend a zusammengefasst kurzer Vergleich zwischen den beiden mit ihren Anwendungen in der realen Welt.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das Executive PG-Programm von IIIT-B & upGrad für maschinelles Lernen und KI an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT, bietet -B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Warum ist CNN schneller als RNN?
CNNs sind schneller als RNNs, da sie für die Verarbeitung von Bildern ausgelegt sind, während RNNs für die Verarbeitung von Text ausgelegt sind. Während RNNs trainiert werden können, mit Bildern umzugehen, ist es für sie immer noch schwierig, kontrastierende Merkmale zu trennen, die näher beieinander liegen. Wenn Sie beispielsweise ein Bild von einem Gesicht mit Augen, Nase und Mund haben, fällt es RNNs schwer, herauszufinden, welches Merkmal zuerst angezeigt werden soll. CNNs verwenden ein Punkteraster, und mithilfe eines Algorithmus können sie darauf trainiert werden, Formen und Muster zu erkennen. CNNs sind besser als RNNs darin, Bilder zu sortieren; Sie sind schneller als RNNs, weil sie einfach zu berechnen sind und Bilder besser sortieren können.
Wofür wird RNN verwendet?
Rekurrente neuronale Netze (RNNs) sind eine Klasse künstlicher neuronaler Netze, bei denen Verbindungen zwischen Einheiten einen gerichteten Zyklus bilden. Die Ausgabe einer Einheit wird zur Eingabe einer anderen Einheit und so weiter, ähnlich wie die Ausgabe eines Neurons zur Eingabe eines anderen wird. RNNs wurden erfolgreich verwendet, um komplexe Aufgaben wie Spracherkennung und maschinelle Übersetzung durchzuführen, die mit Standardmethoden nur schwer durchzuführen sind.
Was ist RNN und wie unterscheidet es sich von Feedforward Neural Networks?
Recurrent Neural Networks (RNNs) sind eine Art von neuronalen Netzen, die zur Verarbeitung sequentieller Daten verwendet werden. Ein rekurrentes neuronales Netz besteht aus einer Eingabeschicht, einer oder mehreren verborgenen Schichten und einer Ausgabeschicht. Die verborgene(n) Schicht(en) sind dafür ausgelegt, interne Darstellungen der Eingabedaten zu lernen, die dann der Ausgabeschicht als externe Darstellung präsentiert werden. Das RNN wird mit Hilfe von Backpropagation trainiert. RNNs werden oft mit Feedforward Neural Networks (FNNs) verglichen. Während sowohl RNNs als auch FNNs interne Darstellungen von Daten lernen können, sind RNNs in der Lage, langfristige Abhängigkeiten zu lernen, wozu FNNs nicht in der Lage sind.