
Verstehen von clientseitigem GraphQl mit Apollo-Client in React-Apps
Veröffentlicht: 2022-03-10Laut State of JavaScript 2019 würden 38,7 % der Entwickler gerne GraphQL verwenden, während 50,8 % der Entwickler GraphQL lernen möchten.
Als Abfragesprache vereinfacht GraphQL den Arbeitsablauf beim Erstellen einer Client-Anwendung. Es beseitigt die Komplexität der Verwaltung von API-Endpunkten in clientseitigen Anwendungen, da es einen einzigen HTTP-Endpunkt zum Abrufen der erforderlichen Daten verfügbar macht. Daher wird das Überholen und Unterholen von Daten wie im Fall von REST eliminiert.
Aber GraphQL ist nur eine Abfragesprache. Um es einfach zu verwenden, brauchen wir eine Plattform, die die schwere Arbeit für uns erledigt. Eine solche Plattform ist Apollo.
Die Apollo-Plattform ist eine Implementierung von GraphQL, die Daten zwischen der Cloud (dem Server) an die Benutzeroberfläche Ihrer App überträgt. Wenn Sie Apollo Client verwenden, wird die gesamte Logik zum Abrufen von Daten, Verfolgen, Laden und Aktualisieren der Benutzeroberfläche durch den useQuery Hook gekapselt (wie im Fall von React). Daher ist das Abrufen von Daten deklarativ. Es hat auch Zero-Configuration-Caching. Durch einfaches Einrichten des Apollo-Clients in Ihrer App erhalten Sie sofort einen intelligenten Cache, ohne dass eine zusätzliche Konfiguration erforderlich ist.
Apollo Client ist auch mit anderen Frameworks wie Angular, Vue.js und React kompatibel.
Hinweis : Von diesem Tutorial profitieren diejenigen, die in der Vergangenheit mit RESTful oder anderen Formen von APIs auf Client-Seite gearbeitet haben und sehen möchten, ob GraphQL einen Versuch wert ist. Das bedeutet, dass Sie zuvor mit einer API gearbeitet haben sollten; Nur dann können Sie verstehen, wie nützlich GraphQL für Sie sein könnte. Während wir einige Grundlagen von GraphQL und Apollo Client behandeln werden, sind gute Kenntnisse von JavaScript und React Hooks von Vorteil.
GraphQL-Grundlagen
Dieser Artikel ist keine vollständige Einführung in GraphQL, aber wir werden einige Konventionen definieren, bevor wir fortfahren.
Was ist GraphQL?
GraphQL ist eine Spezifikation, die eine deklarative Abfragesprache beschreibt, die Ihre Kunden verwenden können, um eine API nach genau den gewünschten Daten zu fragen. Dies wird durch die Erstellung eines starken Typschemas für Ihre API mit ultimativer Flexibilität erreicht. Es stellt auch sicher, dass die API Daten auflöst und dass Clientabfragen anhand eines Schemas validiert werden. Diese Definition bedeutet, dass GraphQL einige Spezifikationen enthält, die es zu einer deklarativen Abfragesprache machen, mit einer API, die statisch typisiert ist (um Typescript herum aufgebaut) und es dem Client ermöglicht, diese Typsysteme zu nutzen, um die API nach den genauen Daten zu fragen, die er will .
Wenn wir also einige Typen mit einigen Feldern darin erstellt haben, könnten wir von der Client-Seite sagen: „Geben Sie uns diese Daten mit genau diesen Feldern“. Dann antwortet die API mit genau dieser Form, als ob wir ein Typsystem in einer stark typisierten Sprache verwenden würden. Weitere Informationen finden Sie in meinem Typescript-Artikel.
Schauen wir uns einige Konventionen von GraphQl an, die uns beim Fortfahren helfen werden.
Die Grundlagen
- Operationen
In GraphQL wird jede ausgeführte Aktion als Operation bezeichnet. Es gibt einige Operationen, nämlich:- Anfrage
Diese Operation befasst sich mit dem Abrufen von Daten vom Server. Man könnte es auch einen schreibgeschützten Abruf nennen. - Mutation
Dieser Vorgang umfasst das Erstellen, Aktualisieren und Löschen von Daten auf einem Server. Es wird allgemein als CUD-Vorgang (Create, Update, Delete) bezeichnet. - Abonnements
Diese Operation in GraphQL beinhaltet das Senden von Daten von einem Server an seine Clients, wenn bestimmte Ereignisse stattfinden. Sie werden normalerweise mit WebSockets implementiert.
- Anfrage
In diesem Artikel werden wir uns nur mit Abfrage- und Mutationsoperationen befassen.
- Operationsnamen _
Es gibt eindeutige Namen für Ihre clientseitigen Abfrage- und Mutationsvorgänge. - Variablen und Argumente
Operationen können Argumente definieren, ähnlich wie eine Funktion in den meisten Programmiersprachen. Diese Variablen können dann als Argumente an Abfrage- oder Mutationsaufrufe innerhalb der Operation übergeben werden. Es wird erwartet, dass Variablen zur Laufzeit während der Ausführung einer Operation von Ihrem Client angegeben werden. - Aliasing
Dies ist eine Konvention in clientseitigem GraphQL, bei der ausführliche oder vage Feldnamen in einfache und lesbare Feldnamen für die Benutzeroberfläche umbenannt werden. Aliasing ist in Anwendungsfällen erforderlich, in denen Sie keine widersprüchlichen Feldnamen haben möchten.
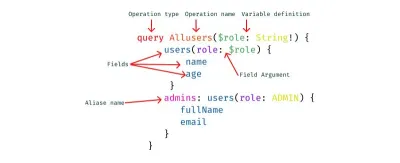
Was ist clientseitiges GraphQL?
Wenn ein Front-End-Ingenieur UI-Komponenten mit einem beliebigen Framework wie Vue.js oder (in unserem Fall) React erstellt, werden diese Komponenten nach einem bestimmten Muster auf dem Client modelliert und entworfen, um den Daten zu entsprechen, die vom Server abgerufen werden.
Eines der häufigsten Probleme mit RESTful-APIs ist Overfetching und Underfetching. Dies geschieht, weil die einzige Möglichkeit für einen Client, Daten herunterzuladen, darin besteht, Endpunkte zu treffen, die feste Datenstrukturen zurückgeben. Overfetching bedeutet in diesem Zusammenhang, dass ein Client mehr Informationen herunterlädt, als von der App benötigt werden.
In GraphQL hingegen senden Sie einfach eine einzelne Abfrage an den GraphQL-Server, die die erforderlichen Daten enthält. Der Server würde dann mit einem JSON-Objekt mit genau den von Ihnen angeforderten Daten antworten – daher kein Überholen. Sebastian Eschweiler erklärt die Unterschiede zwischen RESTful APIs und GraphQL.
Clientseitiges GraphQL ist eine clientseitige Infrastruktur, die mit Daten von einem GraphQL-Server verbunden ist, um die folgenden Funktionen auszuführen:
- Es verwaltet Daten, indem es Abfragen sendet und Daten verändert, ohne dass Sie selbst HTTP-Anforderungen erstellen müssen. Sie verbringen weniger Zeit mit der Datenanalyse und mehr Zeit mit dem Erstellen der eigentlichen Anwendung.
- Es verwaltet die Komplexität eines Caches für Sie. So können Sie die vom Server abgerufenen Daten ohne Eingriffe Dritter speichern und abrufen und ganz einfach das erneute Abrufen doppelter Ressourcen vermeiden. Somit erkennt es, wenn zwei Ressourcen gleich sind, was für eine komplexe App großartig ist.
- Es hält Ihre Benutzeroberfläche konsistent mit der optimistischen Benutzeroberfläche, einer Konvention, die die Ergebnisse einer Mutation (dh die erstellten Daten) simuliert und die Benutzeroberfläche aktualisiert, noch bevor Sie eine Antwort vom Server erhalten. Sobald die Antwort vom Server empfangen wird, wird das optimistische Ergebnis verworfen und durch das tatsächliche Ergebnis ersetzt.
Für weitere Informationen über clientseitiges GraphQL nehmen Sie sich eine Stunde Zeit mit dem Mitschöpfer von GraphQL und anderen coolen Leuten auf GraphQL Radio.
Was ist Apollo-Client?
Apollo Client ist ein interoperabler, ultraflexibler, Community-gesteuerter GraphQL-Client für JavaScript und native Plattformen. Zu den beeindruckenden Funktionen gehören ein robustes Zustandsverwaltungstool (Apollo Link), ein konfigurationsfreies Caching-System, ein deklarativer Ansatz zum Abrufen von Daten, eine einfach zu implementierende Paginierung und die optimistische Benutzeroberfläche für Ihre clientseitige Anwendung.
Apollo Client speichert nicht nur den Status der vom Server abgerufenen Daten, sondern auch den Status, den er lokal auf Ihrem Client erstellt hat. Daher verwaltet es den Status sowohl für API-Daten als auch für lokale Daten.
Es ist auch wichtig zu beachten, dass Sie Apollo Client ohne Konflikte zusammen mit anderen State-Management-Tools wie Redux verwenden können. Außerdem ist es möglich, Ihre Zustandsverwaltung beispielsweise von Redux auf Apollo Client zu migrieren (was den Rahmen dieses Artikels sprengen würde). Letztendlich besteht der Hauptzweck von Apollo Client darin, Ingenieuren die nahtlose Abfrage von Daten in einer API zu ermöglichen.
Funktionen des Apollo-Clients
Apollo Client hat so viele Ingenieure und Unternehmen aufgrund seiner äußerst hilfreichen Funktionen überzeugt, die das Erstellen moderner robuster Anwendungen zum Kinderspiel machen. Die folgenden Funktionen sind integriert:
- Caching
Apollo Client unterstützt Caching on the fly. - Optimistische Benutzeroberfläche
Apollo Client bietet coole Unterstützung für die optimistische Benutzeroberfläche. Dabei wird der Endzustand einer Operation (Mutation) während der Operation vorübergehend angezeigt. Sobald die Operation abgeschlossen ist, ersetzen die realen Daten die optimistischen Daten. - Seitennummerierung
Apollo Client verfügt über eine integrierte Funktionalität, die es ganz einfach macht, Paginierung in Ihrer Anwendung zu implementieren. Es kümmert sich um die meisten technischen Probleme beim Abrufen einer Liste von Daten, entweder in Patches oder auf einmal, mit derfetchMoreFunktion, die mit demuseQueryHook geliefert wird.
In diesem Artikel werden wir uns eine Auswahl dieser Funktionen ansehen.
Genug der Theorie. Schnallen Sie sich fest und holen Sie sich eine Tasse Kaffee zu Ihren Pfannkuchen, während wir uns die Hände schmutzig machen.
Aufbau unserer Web-App
Dieses Projekt ist von Scott Moss inspiriert.
Wir werden eine einfache Web-App für eine Zoohandlung erstellen, deren Funktionen Folgendes umfassen:
- Abrufen unserer Haustiere von der Serverseite;
- Erstellen eines Haustiers (was das Erstellen des Namens, der Art des Haustiers und des Bildes beinhaltet);
- Verwenden der optimistischen Benutzeroberfläche;
- Paginierung verwenden, um unsere Daten zu segmentieren.
Klonen Sie zunächst das Repository und stellen Sie sicher, dass der starter Zweig das ist, was Sie geklont haben.
Einstieg
- Installieren Sie die Apollo Client Developer Tools-Erweiterung für Chrome.
- Navigieren Sie mithilfe der Befehlszeilenschnittstelle (CLI) zum Verzeichnis des geklonten Repositorys und führen Sie den Befehl aus, um alle Abhängigkeiten abzurufen:
npm install. - Führen Sie den Befehl
npm run appaus, um die App zu starten. - Führen Sie, während Sie sich noch im Stammordner befinden, den Befehl
npm run server. Dadurch wird unser Back-End-Server für uns gestartet, den wir im weiteren Verlauf verwenden werden.
Die App sollte in einem konfigurierten Port geöffnet werden. Meine ist https://localhost:1234/ ; bei dir ist es wohl was anderes.
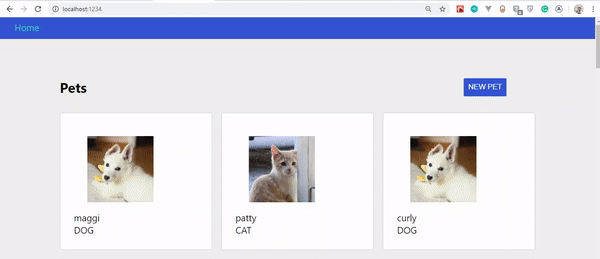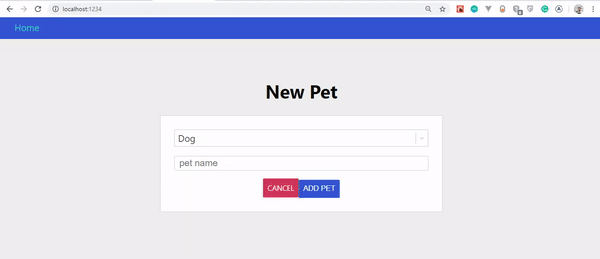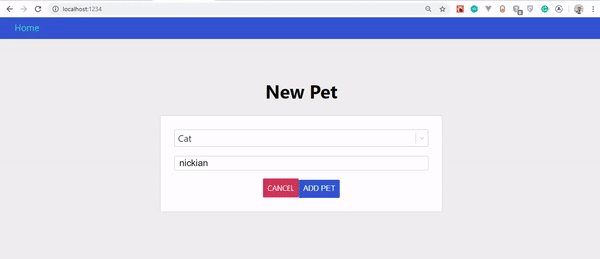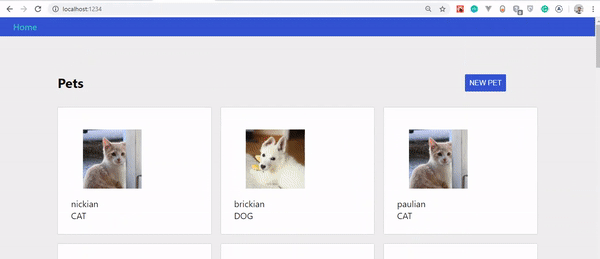
Wenn alles gut funktioniert hat, sollte Ihre App so aussehen:
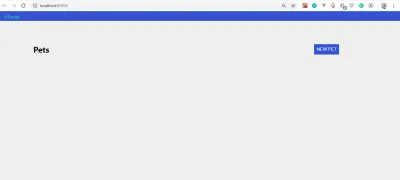
Sie werden feststellen, dass wir keine Haustiere zum Ausstellen haben. Das liegt daran, dass wir eine solche Funktionalität noch nicht erstellt haben.
Wenn Sie die Apollo-Client-Entwicklertools korrekt installiert haben, öffnen Sie die Entwicklertools und klicken Sie auf das Taskleistensymbol. Sie sehen „Apollo“ und so etwas:
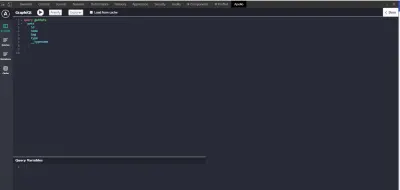
Wie die Redux- und React-Entwicklertools werden wir die Apollo-Client-Entwicklertools verwenden, um unsere Abfragen und Mutationen zu schreiben und zu testen. Die Erweiterung wird mit dem GraphQL Playground geliefert.
Haustiere holen
Lassen Sie uns die Funktionalität hinzufügen, die Haustiere abruft. Wechseln Sie zu client/src/client.js . Wir schreiben Apollo Client, verknüpfen ihn mit einer API, exportieren ihn als Standardclient und schreiben eine neue Abfrage.
Kopieren Sie den folgenden Code und fügen Sie ihn in client.js :
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http' const link = new HttpLink({ uri: 'https://localhost:4000/' }) const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default clientHier ist eine Erklärung, was oben passiert:
-
ApolloClient
Dies ist die Funktion, die unsere App umschließt und somit eine Schnittstelle mit dem HTTP herstellt, die Daten zwischenspeichert und die Benutzeroberfläche aktualisiert. -
InMemoryCache
Dies ist der normalisierte Datenspeicher in Apollo Client, der bei der Bearbeitung des Caches in unserer Anwendung hilft. -
HttpLink
Dies ist eine Standard-Netzwerkschnittstelle zum Ändern des Kontrollflusses von GraphQL-Anforderungen und zum Abrufen von GraphQL-Ergebnissen. Es fungiert als Middleware und ruft jedes Mal, wenn der Link ausgelöst wird, Ergebnisse vom GraphQL-Server ab. Außerdem ist es ein guter Ersatz für andere Optionen wieAxiosundwindow.fetch. - Wir deklarieren eine Link-Variable, die einer Instanz von
HttpLink. Es übernimmt eineuri-Eigenschaft und einen Wert für unseren Server,https://localhost:4000/. - Als nächstes kommt eine Cache-Variable, die die neue Instanz von
InMemoryCache. - Die Client-Variable übernimmt auch eine Instanz von
ApolloClientund umschließtlinkundcache. - Zuletzt exportieren wir den
client, damit wir ihn in der gesamten Anwendung verwenden können.
Bevor wir dies in Aktion sehen, müssen wir sicherstellen, dass unsere gesamte App Apollo ausgesetzt ist und dass unsere App vom Server abgerufene Daten empfangen und diese Daten mutieren kann.
Um dies zu erreichen, gehen wir zu client/src/index.js :
import React from 'react' import ReactDOM from 'react-dom' import { BrowserRouter } from 'react-router-dom' import { ApolloProvider } from '@apollo/react-hooks' import App from './components/App' import client from './client' import './index.css' const Root = () => ( <BrowserRouter><ApolloProvider client={client}> <App /> </ApolloProvider></BrowserRouter> ); ReactDOM.render(<Root />, document.getElementById('app')) if (module.hot) { module.hot.accept() }
Wie Sie im hervorgehobenen Code sehen werden, haben wir die App -Komponente in ApolloProvider und den Client als Prop an den client übergeben. ApolloProvider ähnelt dem Context.Provider von React. Es umschließt Ihre React-App und stellt den Client in einen Kontext, sodass Sie von überall in Ihrem Komponentenbaum darauf zugreifen können.
Um unsere Haustiere vom Server zu holen, müssen wir Abfragen schreiben, die genau die Felder anfordern, die wir wollen. Gehen Sie zu client/src/pages/Pets.js , kopieren Sie den folgenden Code und fügen Sie ihn ein:
import React, {useState} from 'react' import gql from 'graphql-tag' import { useQuery, useMutation } from '@apollo/react-hooks' import PetsList from '../components/PetsList' import NewPetModal from '../components/NewPetModal' import Loader from '../components/Loader'const GET_PETS = gql` query getPets { pets { id name type img } } `;export default function Pets () { const [modal, setModal] = useState(false)const { loading, error, data } = useQuery(GET_PETS); if (loading) return <Loader />; if (error) return <p>An error occured!</p>;const onSubmit = input => { setModal(false) } if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section><PetsList pets={data.pets}/></section> </div> ) }
Mit ein paar Bits Code können wir die Haustiere vom Server holen.

Was ist gql?
Es ist wichtig zu beachten, dass Operationen in GraphQL im Allgemeinen JSON-Objekte sind, die mit graphql-tag und Backticks geschrieben sind.
gql Tags sind JavaScript-Template-Literal-Tags, die GraphQL-Abfragezeichenfolgen in den GraphQL-AST (abstrakten Syntaxbaum) parsen.
- Abfrageoperationen
Um unsere Haustiere vom Server abzurufen, müssen wir eine Abfrage durchführen.- Da wir eine
querydurchführen, mussten wir dietypeder Operation angeben, bevor wir sie benennen konnten. - Der Name unserer Abfrage ist
GET_PETS. Es ist eine Namenskonvention von GraphQL, camelCase für Feldnamen zu verwenden. - Der Name unserer Felder ist
pets. Daher geben wir genau die Felder an, die wir vom Server benötigen(id, name, type, img). -
useQueryist ein React-Hook, der die Grundlage für die Ausführung von Abfragen in einer Apollo-Anwendung bildet. Um eine Abfrageoperation in unserer React-Komponente durchzuführen, rufen wir den HookuseQuery, der ursprünglich aus@apollo/react-hooksimportiert wurde. Als nächstes übergeben wir ihm eine GraphQL-GET_PETS, in unserem Fall GET_PETS.
- Da wir eine
- Wenn unsere Komponente rendert, gibt
useQueryeine Objektantwort von Apollo Client zurück, die Lade-, Fehler- und Dateneigenschaften enthält. Daher werden sie destrukturiert, sodass wir sie zum Rendern der Benutzeroberfläche verwenden können. -
useQueryist genial. Wir müssenasync-awaitnicht einschließen. Im Hintergrund ist es bereits erledigt. Ziemlich cool, oder?-
loading
Diese Eigenschaft hilft uns, den Ladezustand der Anwendung zu handhaben. In unserem Fall geben wir eineLoaderKomponente zurück, während unsere Anwendung geladen wird. Standardmäßig ist das Ladenfalse. -
error
Nur für den Fall, dass wir diese Eigenschaft verwenden, um eventuell auftretende Fehler zu behandeln. -
data
Diese enthält unsere aktuellen Daten vom Server. - Schließlich übergeben wir in unserer
PetsListKomponente diepets-Requisiten mitdata.petsals Objektwert.
-
An diesem Punkt haben wir unseren Server erfolgreich abgefragt.
Um unsere Anwendung zu starten, führen wir den folgenden Befehl aus:
- Starten Sie die Client-App. Führen Sie den Befehl
npm run appin Ihrer CLI aus. - Starten Sie den Server. Führen Sie den Befehl
npm run serverin einer anderen CLI aus.
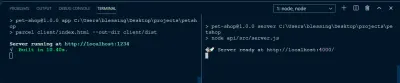
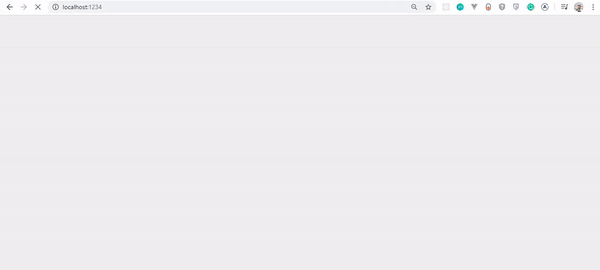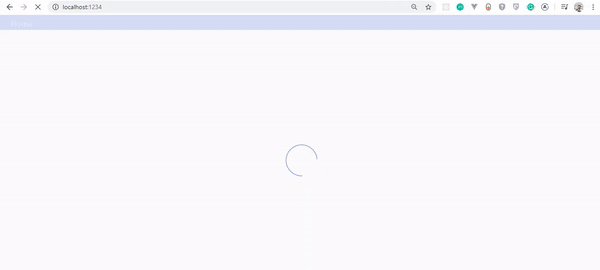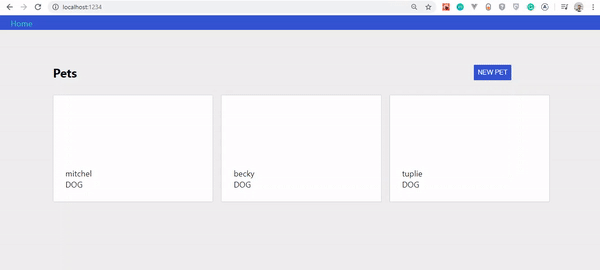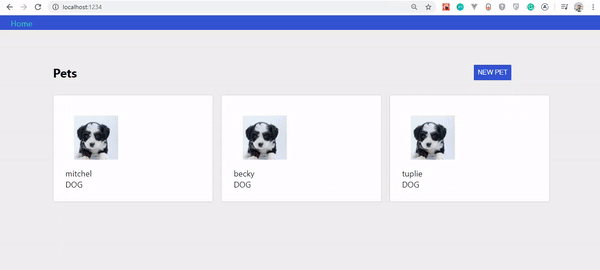
Wenn alles gut gelaufen ist, sollten Sie Folgendes sehen:
Mutierende Daten
Das Mutieren von Daten oder das Erstellen von Daten in Apollo Client ist fast dasselbe wie das Abfragen von Daten, mit sehr geringfügigen Änderungen.
Immer noch in client/src/pages/Pets.js kopieren wir den hervorgehobenen Code und fügen ihn ein:
.... const GET_PETS = gql` query getPets { pets { id name type img } } `;const NEW_PETS = gql` mutation CreateAPet($newPet: NewPetInput!) { addPet(input: $newPet) { id name type img } } `;const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS);const onSubmit = input => { setModal(false)createPet({ variables: { newPet: input } }); } if (loading || newPet.loading) return <Loader />; if (error || newPet.error) return <p>An error occured</p>;if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section> <PetsList pets={data.pets}/> </section> </div> ) } export default Pets
Um eine Mutation zu erstellen, würden wir die folgenden Schritte unternehmen.
1. mutation
Zum Erstellen, Aktualisieren oder Löschen müssen wir die mutation durchführen. Die mutation hat einen CreateAPet Namen mit einem Argument. Dieses Argument hat eine Variable $newPet mit dem Typ NewPetInput . Die ! bedeutet, dass die Operation erforderlich ist; Daher führt GraphQL die Operation nicht aus, es sei denn, wir übergeben eine newPet , deren Typ NewPetInput ist.
2. addPet
Die addPet Funktion, die sich innerhalb der mutation befindet, nimmt ein input und wird auf unsere $newPet Variable gesetzt. Die in unserer addPet Funktion angegebenen Feldsätze müssen den Feldsätzen in unserer Abfrage entsprechen. Die Feldsätze in unserem Betrieb sind:
-
id -
name -
type -
img
3. useMutation
Der Hook useMutation React ist die primäre API zum Ausführen von Mutationen in einer Apollo-Anwendung. Wenn wir Daten mutieren müssen, rufen wir useMutation in einer React-Komponente auf und übergeben ihr einen GraphQL-String (in unserem Fall NEW_PETS ).
Wenn unsere Komponente useMutation rendert, gibt sie ein Tupel (d. h. eine geordnete Menge von Daten, die einen Datensatz bilden) in einem Array zurück, das Folgendes enthält:
- eine
mutate-Funktion, die wir jederzeit aufrufen können, um die Mutation auszuführen; - ein Objekt mit Feldern, die den aktuellen Status der Ausführung der Mutation darstellen.
Dem useMutation Hook wird eine GraphQL-Mutationszeichenfolge übergeben (in unserem Fall NEW_PETS ). Wir haben das Tupel destrukturiert, bei dem es sich um die Funktion ( createPet ) handelt, die die Daten und das Objektfeld ( newPets ) mutiert.
4. createPet
In unserer Funktion onSubmit haben wir kurz nach dem Zustand setModal unser createPet definiert. Diese Funktion nimmt eine variable mit einer Objekteigenschaft eines Wertes, der auf { newPet: input } gesetzt ist. Die input repräsentiert die verschiedenen Eingabefelder in unserem Formular (wie Name, Typ usw.).
Damit sollte das Ergebnis so aussehen:
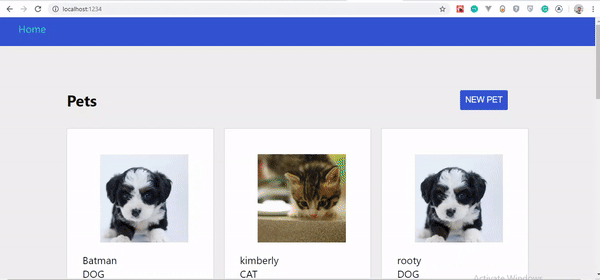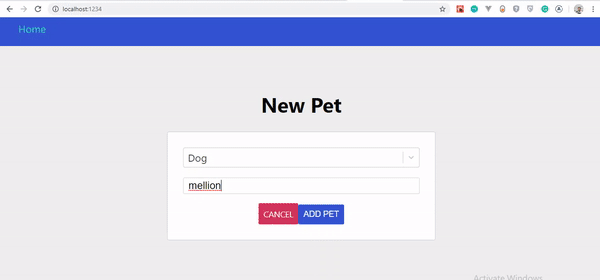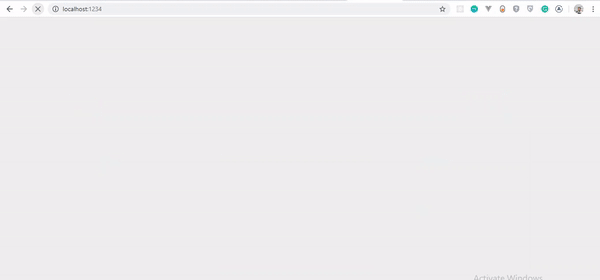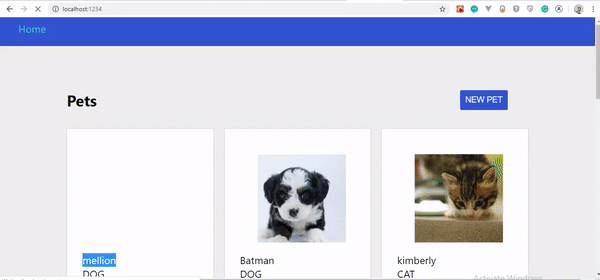
Wenn Sie das GIF genau beobachten, werden Sie feststellen, dass unser erstelltes Haustier nicht sofort angezeigt wird, sondern erst, wenn die Seite aktualisiert wird. Es wurde jedoch auf dem Server aktualisiert.
Die große Frage ist, warum aktualisiert sich unser Haustier nicht sofort? Finden wir es im nächsten Abschnitt heraus.
Caching im Apollo-Client
Der Grund, warum unsere App nicht automatisch aktualisiert wird, ist, dass unsere neu erstellten Daten nicht mit den Cache-Daten in Apollo Client übereinstimmen. Es besteht also ein Konflikt darüber, was genau aus dem Cache aktualisiert werden muss.
Einfach ausgedrückt, wenn wir eine Mutation durchführen, die mehrere Einträge (einen Knoten) aktualisiert oder löscht, dann sind wir dafür verantwortlich, alle Abfragen zu aktualisieren, die auf diesen Knoten verweisen, sodass unsere zwischengespeicherten Daten modifiziert werden, um mit den Änderungen übereinzustimmen, die eine Mutation an unserem Rücken vornimmt. Daten beenden .
Cache synchron halten
Es gibt einige Möglichkeiten, unseren Cache bei jeder Mutationsoperation synchron zu halten.
Die erste besteht darin, übereinstimmende Abfragen nach einer Mutation erneut abzurufen, indem die refetchQueries wird (der einfachste Weg).
Hinweis: Wenn wir diese Methode verwenden würden, würde sie eine Objekteigenschaft in unserer createPet Funktion namens refetchQueries und ein Array von Objekten mit einem Wert der Abfrage enthalten: refetchQueries: [{ query: GET_PETS }] .
Da unser Fokus in diesem Abschnitt nicht nur darauf liegt, unsere erstellten Haustiere in der Benutzeroberfläche zu aktualisieren, sondern den Cache zu manipulieren, werden wir diese Methode nicht verwenden.
Der zweite Ansatz ist die Verwendung der update Funktion. In Apollo Client gibt es eine update -Hilfsfunktion, die dabei hilft, die Cache-Daten zu ändern, sodass sie mit den Änderungen synchronisiert werden, die eine Mutation an unseren Back-End-Daten vornimmt. Mit dieser Funktion können wir im Cache lesen und schreiben.
Aktualisieren des Caches
Kopieren Sie den folgenden hervorgehobenen Code und fügen Sie ihn in client/src/pages/Pets.js :
...... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } );.....
Die update Funktion erhält zwei Argumente:
- Das erste Argument ist der Cache von Apollo Client.
- Die zweite ist die genaue Mutationsantwort vom Server. Wir destrukturieren die Eigenschaft
dataund setzen sie auf unsere Mutation (addPet).
Um die Funktion zu aktualisieren, müssen wir als nächstes prüfen, welche Abfrage aktualisiert werden muss (in unserem Fall die GET_PETS Abfrage) und den Cache lesen.
Zweitens müssen wir in die gelesene query schreiben, damit sie weiß, dass wir sie aktualisieren werden. Dazu übergeben wir ein Objekt, das eine query enthält, deren Wert auf unsere query ( GET_PETS ) gesetzt ist, und eine data , deren Wert ein pet ist und die ein Array der addPet Mutation und eine Kopie von enthält Haustierdaten.
Wenn Sie diese Schritte sorgfältig befolgt haben, sollten Ihre Haustiere beim Erstellen automatisch aktualisiert werden. Werfen wir einen Blick auf die Änderungen:
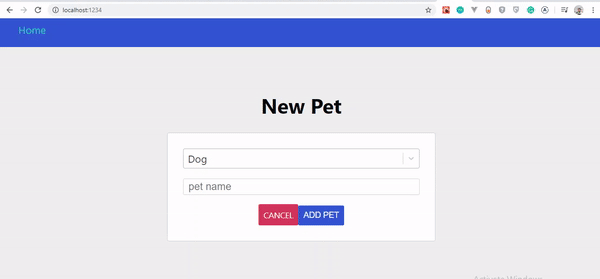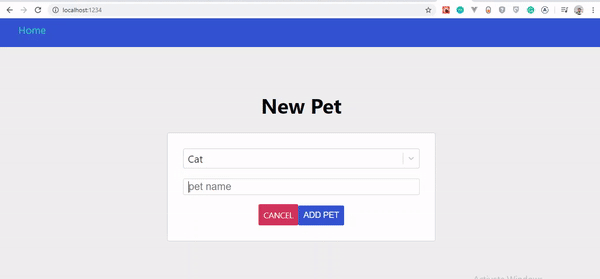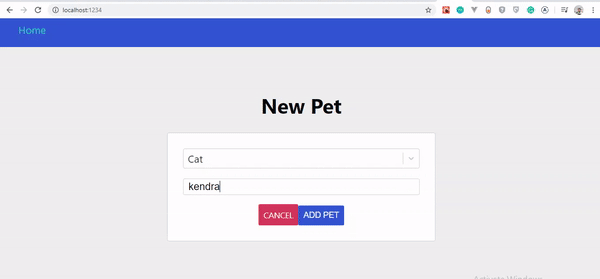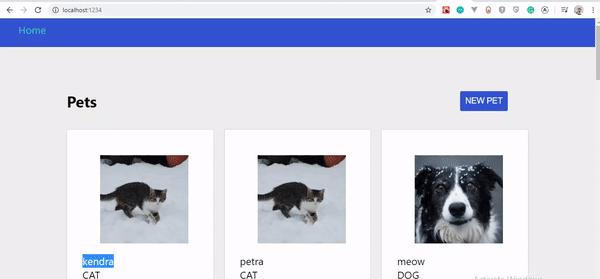
Optimistische Benutzeroberfläche
Viele Leute sind große Fans von Ladern und Spinnern. Es ist nichts falsch daran, einen Lader zu verwenden; Es gibt perfekte Anwendungsfälle, in denen ein Loader die beste Option ist. Ich habe über Loader versus Spinner und ihre besten Anwendungsfälle geschrieben.
Loader und Spinner spielen in der Tat eine wichtige Rolle im UI- und UX-Design, aber die Ankunft von Optimistic UI hat das Rampenlicht gestohlen.
Was ist eine optimistische Benutzeroberfläche?
Optimistische Benutzeroberfläche ist eine Konvention, die die Ergebnisse einer Mutation (erstellte Daten) simuliert und die Benutzeroberfläche aktualisiert, bevor eine Antwort vom Server empfangen wird. Sobald die Antwort vom Server empfangen wird, wird das optimistische Ergebnis verworfen und durch das tatsächliche Ergebnis ersetzt.
Letztendlich ist eine optimistische Benutzeroberfläche nichts anderes als eine Möglichkeit, die wahrgenommene Leistung zu verwalten und Ladezustände zu vermeiden.
Apollo Client hat eine sehr interessante Möglichkeit, die Optimistic UI zu integrieren. Es gibt uns einen einfachen Haken, der es uns ermöglicht, nach der Mutation in den lokalen Cache zu schreiben. Mal sehen, wie es funktioniert!
Schritt 1
Gehen Sie zu client/src/client.js und fügen Sie nur den hervorgehobenen Code hinzu.
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http'import { setContext } from 'apollo-link-context' import { ApolloLink } from 'apollo-link' const http = new HttpLink({ uri: "https://localhost:4000/" }); const delay = setContext( request => new Promise((success, fail) => { setTimeout(() => { success() }, 800) }) ) const link = ApolloLink.from([ delay, http ])const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default client
Der erste Schritt beinhaltet Folgendes:
- Wir importieren
setContextausapollo-link-context. Die FunktionsetContextverwendet eine Callback-Funktion und gibt ein Promise zurück, dessensetTimeoutauf800msms festgelegt ist, um eine Verzögerung zu erzeugen, wenn eine Mutationsoperation ausgeführt wird. - Die
ApolloLink.fromMethode stellt sicher, dass die Netzwerkaktivität, die den Link (unsere API) vonHTTPdarstellt, verzögert wird.
Schritt 2
Der nächste Schritt ist die Verwendung des Optimistic UI-Hooks. Gehen Sie zurück zu client/src/pages/Pets.js und fügen Sie nur den unten hervorgehobenen Code hinzu.
..... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS); const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } ); const onSubmit = input => { setModal(false) createPet({ variables: { newPet: input },optimisticResponse: { __typename: 'Mutation', addPet: { __typename: 'Pet', id: Math.floor(Math.random() * 10000 + ''), name: input.name, type: input.type, img: 'https://via.placeholder.com/200' } }}); } .....
Das optimisticResponse -Objekt wird verwendet, wenn wir möchten, dass die Benutzeroberfläche sofort aktualisiert wird, wenn wir ein Haustier erstellen, anstatt auf die Serverantwort zu warten.
Die obigen Code-Snippets beinhalten Folgendes:
-
__typenamewird von Apollo in die Abfrage eingefügt, um dentypeder abgefragten Entitäten abzurufen. Diese Typen werden vom Apollo-Client verwendet, um die Eigenschaftid(die ein Symbol ist) für Caching-Zwecke inapollo-cachezu erstellen.__typenameist also eine gültige Eigenschaft der Abfrageantwort. - Die Mutation wird als
__typenamevonoptimisticResponsefestgelegt. - Wie zuvor definiert, lautet der Name unserer Mutation
addPetund der__typenamePet. - Als nächstes sind die Felder unserer Mutation, die die optimistische Antwort aktualisieren soll:
-
id
Da wir die ID des Servers nicht kennen, haben wir mitMath.flooreine erstellt. -
name
Dieser Wert wird aufinput.namegesetzt. -
type
Der Wert des Typs istinput.type. -
img
Da unser Server nun Bilder für uns generiert, haben wir einen Platzhalter verwendet, um unser Bild vom Server nachzuahmen.
-
Dies war in der Tat eine lange Fahrt. Wenn Sie am Ende angelangt sind, zögern Sie nicht, eine Pause von Ihrem Stuhl mit einer Tasse Kaffee einzulegen.
Werfen wir einen Blick auf unser Ergebnis. Das unterstützende Repository für dieses Projekt befindet sich auf GitHub. Klonen und damit experimentieren.
Fazit
Die erstaunlichen Funktionen von Apollo Client, wie z. B. die optimistische Benutzeroberfläche und Paginierung, machen das Erstellen clientseitiger Apps zur Realität.
Während Apollo Client sehr gut mit anderen Frameworks wie Vue.js und Angular funktioniert, haben React-Entwickler Apollo Client Hooks und können daher nicht anders, als Spaß daran zu haben, eine großartige App zu erstellen.
In diesem Artikel haben wir nur an der Oberfläche gekratzt. Die Beherrschung von Apollo Client erfordert ständige Übung. Machen Sie also weiter und klonen Sie das Repository, fügen Sie Paginierung hinzu und spielen Sie mit den anderen Funktionen herum, die es bietet.
Bitte teilen Sie Ihr Feedback und Ihre Erfahrungen im Kommentarbereich unten mit. Wir können Ihren Fortschritt auch auf Twitter besprechen. Prost!
Verweise
- „Clientseitiges GraphQL in React“, Scott Moss, Frontend-Master
- „Dokumentation“, Apollo Client
- „Die optimistische Benutzeroberfläche mit React“, Patryk Andrzejewski
- „Wahre Lügen optimistischer Benutzeroberflächen“, Smashing Magazine