
Auswahl einer neuen serverlosen Datenbanktechnologie in einer Agentur (Fallstudie)
Veröffentlicht: 2022-03-10Dieser Artikel wurde freundlicherweise von unseren lieben Freunden bei Fauna unterstützt, die die Arbeit mit Betriebsdaten für jedes Softwareentwicklungsteam produktiv, skalierbar und sicher machen. Danke!

Die Einführung einer neuen Technologie ist eine der schwierigsten Entscheidungen für einen Technologen in einer Führungsrolle. Dies ist oft ein großer und unbequemer Risikobereich, unabhängig davon, ob Sie Software für eine andere Organisation oder innerhalb Ihrer eigenen erstellen.
In den letzten zwölf Jahren als Software-Ingenieur war ich immer häufiger in der Lage, eine neue Technologie zu evaluieren . Dies kann das nächste Frontend-Framework, eine neue Sprache oder sogar völlig neue Architekturen wie Serverless sein.
Die Experimentierphase ist oft lustig und spannend. Hier sind Softwareentwickler am meisten zu Hause, um die Neuheit und Euphorie von „Aha“-Momenten zu umarmen, während sie neue Konzepte grokken. Als Ingenieure denken und basteln wir gerne, aber mit genügend Erfahrung lernt jeder Ingenieur, dass selbst die unglaublichste Technologie ihre Schönheitsfehler hat. Du hast sie nur noch nicht gefunden.
Als Mitbegründer einer Kreativagentur sind mein Team und ich oft in der einzigartigen Position, neue Technologien einzusetzen. Wir sehen viele Greenfield-Projekte, die zur perfekten Gelegenheit werden, etwas Neues einzuführen. Diese Projekte sehen auch ein gewisses Maß an technischer Isolation von der größeren Organisation und sind oft weniger durch frühere Entscheidungen belastet.
Abgesehen davon wird ein guter Agenturleiter damit betraut, sich um die große Idee eines anderen zu kümmern und sie der Welt zu präsentieren. Wir müssen damit noch sorgsamer umgehen als mit unseren eigenen Projekten. Immer wenn ich kurz davor bin, eine neue Technologie endgültig einzusetzen, denke ich oft über diese Weisheit des Mitbegründers von Stack Overflow Joel Spolski nach:
„Du musst ein oder zwei Jahre mit dem Ding schwitzen und bluten, bevor du wirklich weißt, dass es gut genug ist, oder erkennen, dass du es nicht kannst, egal wie sehr du es versuchst …“
Dies ist die Angst, dies ist der Ort, an dem sich kein technischer Leiter wiederfinden möchte. Die Auswahl einer neuen Technologie für ein reales Projekt ist schwer genug, aber als Agentur müssen Sie diese Entscheidungen mit dem Projekt eines anderen treffen, mit jemandem der Traum eines anderen, das Geld eines anderen. In einer Agentur ist das Letzte, was Sie wollen, einen dieser Schönheitsfehler kurz vor Ablauf der Frist für ein Projekt zu finden. Enge Zeitpläne und Budgets machen es fast unmöglich, den Kurs umzukehren, nachdem eine bestimmte Schwelle überschritten wurde. Daher kann es katastrophal sein, zu spät in einem Projekt herauszufinden, dass eine Technologie etwas Kritisches nicht leisten kann oder unzuverlässig ist.
Während meiner gesamten Karriere als Softwareentwickler habe ich bei SaaS-Unternehmen und Kreativagenturen gearbeitet. Wenn es darum geht, eine neue Technologie für ein Projekt einzusetzen, haben diese beiden Umgebungen sehr unterschiedliche Kriterien. Es gibt Überschneidungen bei den Kriterien, aber im Großen und Ganzen muss die Agenturumgebung mit starren Budgets und strengen Zeitvorgaben arbeiten . Obwohl wir möchten, dass die von uns gebauten Produkte im Laufe der Zeit gut altern, ist es oft schwieriger, in etwas weniger Bewährtes zu investieren oder Technologien mit steileren Lernkurven und Ecken und Kanten zu übernehmen.
Abgesehen davon haben Agenturen auch einige einzigartige Einschränkungen, die eine einzelne Organisation möglicherweise nicht hat. Wir müssen uns auf Effizienz und Stabilität konzentrieren. Die abrechenbare Stunde ist oft die letzte Maßeinheit, wenn ein Projekt abgeschlossen ist. Ich war bei SaaS-Unternehmen, wo es keine große Sache ist, ein oder zwei Tage mit der Einrichtung oder einer Build-Pipeline zu verbringen.
In einer Agentur belasten diese Art von Zeitkosten die Beziehungen, da die Finanzteams sehen, dass sich die Gewinnspannen für wenig sichtbare Ergebnisse verringern. Wir müssen auch die langfristige Wartung eines Projekts berücksichtigen und umgekehrt, was passiert, wenn ein Projekt an den Kunden zurückgegeben werden muss. Wir müssen daher bei der von uns gewählten Technologie auf Effizienz, Lernkurve und Stabilität setzen.
Bei der Bewertung einer neuen Technologie betrachte ich drei übergreifende Bereiche:
- Die Technologie
- Die Entwicklererfahrung
- Das Geschäft
Jeder dieser Bereiche hat eine Reihe von Kriterien, die ich erfüllen möchte, bevor ich wirklich in den Code eintauche und experimentiere. In diesem Artikel werfen wir einen Blick auf diese Kriterien und verwenden das Beispiel der Erwägung einer neuen Datenbank für ein Projekt und überprüfen sie auf hoher Ebene unter jeder Lupe. Eine konkrete Entscheidung wie diese zu treffen, hilft zu zeigen, wie wir diesen Rahmen in der realen Welt anwenden können.
Die Technologie
Das allererste, worauf Sie bei der Bewertung einer neuen Technologie achten sollten, ist, ob diese Lösung die Probleme lösen kann, die sie zu lösen vorgibt. Bevor wir uns damit befassen, wie eine Technologie unsere Prozesse und Geschäftsabläufe unterstützen kann, ist es wichtig, zunächst festzustellen, ob sie unsere funktionalen Anforderungen erfüllt . Hier schaue ich mir auch gerne an, welche bestehenden Lösungen wir verwenden und wie sich diese neue gegen sie schlägt.
Ich werde mir Fragen stellen wie:
- Löst es zumindest das Problem meiner bestehenden Lösung?
- Inwiefern ist diese Lösung besser?
- Inwiefern ist es schlimmer?
- In Bereichen, in denen es noch schlimmer ist, was ist nötig, um diese Mängel zu überwinden?
- Wird es mehrere Tools ersetzen?
- Wie stabil ist die Technik?
Unser Warum?
An dieser Stelle möchte ich auch darauf eingehen, warum wir nach einer anderen Lösung suchen. Eine einfache Antwort ist, dass wir auf ein Problem stoßen, das bestehende Lösungen nicht lösen . Dies ist jedoch oft selten der Fall. Wir haben im Laufe der Jahre viele Softwareprobleme mit all der Technologie gelöst, die wir heute haben. Was normalerweise passiert, ist, dass wir auf eine neue Technologie umgestellt werden, die etwas, das wir gerade tun, einfacher, stabiler, schneller oder billiger macht.
Nehmen wir React als Beispiel. Warum haben wir uns für React entschieden, wenn jQuery oder Vanilla JavaScript die Arbeit erledigten? In diesem Fall zeigte die Verwendung des Frameworks, dass dies ein viel besserer Weg war, um zustandsbehaftete Frontends zu handhaben. Es wurde schneller für uns, Dinge wie Filter- und Sortierfunktionen zu erstellen, indem wir mit Datenstrukturen statt direkter DOM-Manipulation arbeiteten. Dies war eine Zeitersparnis und erhöhte Stabilität unserer Lösungen.
Typoskript ist ein weiteres Beispiel, bei dem wir uns entschieden haben, es zu übernehmen, weil wir Verbesserungen in der Stabilität unseres Codes und der Wartbarkeit festgestellt haben. Bei der Einführung neuer Technologien gibt es oft kein klares Problem, das wir lösen möchten, sondern einfach nur versuchen, auf dem Laufenden zu bleiben und dann effizientere und stabilere Lösungen zu entdecken, als wir derzeit verwenden.
Im Falle einer Datenbank erwogen wir speziell den Wechsel zu einer serverlosen Option . Wir hatten viel Erfolg mit serverlosen Anwendungen und Bereitstellungen, die unseren Overhead als Unternehmen reduzierten. Ein Bereich, in dem wir das Gefühl hatten, dass dies fehlte, war unsere Datenschicht. Wir sahen Dienste wie Amazon Aurora, Fauna, Cosmos und Firebase, die serverlose Prinzipien auf Datenbanken anwendeten, und wollten sehen, ob es an der Zeit wäre, selbst den Sprung zu wagen. In diesem Fall wollten wir unsere Betriebskosten senken und unsere Entwicklungsgeschwindigkeit und -effizienz erhöhen.
Auf dieser Ebene ist es wichtig, Ihr Warum zu verstehen, bevor Sie in neue Angebote eintauchen. Dies kann daran liegen, dass Sie ein neuartiges Problem lösen, aber viel häufiger möchten Sie Ihre Fähigkeit verbessern, eine Art von Problem zu lösen, die Sie bereits lösen. In diesem Fall müssen Sie eine Bestandsaufnahme machen , wo Sie waren, um herauszufinden, was eine sinnvolle Verbesserung Ihres Arbeitsablaufs bewirken würde. Aufbauend auf unserem Beispiel der Betrachtung serverloser Datenbanken müssen wir einen Blick darauf werfen, wie wir derzeit Probleme lösen und wo diese Lösungen zu kurz kommen.
Wo wir waren…
Als Agentur haben wir zuvor eine breite Palette von Datenbanken verwendet, einschließlich, aber nicht beschränkt auf MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery und Firebase Cloud Storage. Die überwiegende Mehrheit unserer Arbeit konzentrierte sich jedoch auf drei Kerndatenbanken: PostgreSQL, MongoDB und Firebase Realtime Database. Jedes dieser Angebote hat tatsächlich semi-serverlose Angebote, aber einige Schlüsselmerkmale neuerer Angebote veranlassten uns, unsere früheren Annahmen neu zu bewerten. Werfen wir zunächst einen Blick auf unsere historische Erfahrung mit jedem dieser Faktoren und warum wir überhaupt Alternativen in Betracht ziehen.
Normalerweise wählen wir PostgreSQL für größere, langfristige Projekte, da dies der kampferprobte Goldstandard für fast alles ist. Es unterstützt klassische Transaktionen, normalisierte Daten und ist ACID-konform. Es gibt eine Fülle von Tools und ORMs, die in fast jeder Sprache verfügbar sind, und es kann sogar als Ad-hoc-NoSQL-Datenbank mit seiner JSON-Spaltenunterstützung verwendet werden. Es lässt sich gut in viele bestehende Frameworks, Bibliotheken und Programmiersprachen integrieren, was es zu einem echten Allround-Arbeitstier macht. Es ist auch Open Source und macht uns daher nicht an einen Anbieter gebunden. Wie sie sagen, wurde noch nie jemand gefeuert, weil er sich für Postgres entschieden hat.
Davon abgesehen haben wir uns allmählich dabei befunden, PostgreSQL immer weniger zu verwenden, da wir mehr zu einem Node-orientierten Shop wurden. Wir haben festgestellt, dass die ORMs für Node glanzlos sind und mehr benutzerdefinierte Abfragen erfordern (obwohl dies jetzt weniger problematisch geworden ist), und NoSQL schien eine natürlichere Lösung zu sein, wenn Sie in einer JavaScript- oder TypeScript-Laufzeitumgebung arbeiten. Allerdings hatten wir oft Projekte, die mit klassischer relationaler Modellierung wie E-Commerce-Workflows recht schnell erledigt werden konnten. Der Umgang mit der lokalen Einrichtung der Datenbank, die Vereinheitlichung des Testablaufs über Teams hinweg und der Umgang mit lokalen Migrationen waren jedoch Dinge, die wir nicht mochten und die wir gerne hinter uns ließen, als Cloud-basierte NoSQL-Datenbanken immer beliebter wurden.
MongoDB war zunehmend unsere bevorzugte Datenbank, da wir Node.js als unser bevorzugtes Backend übernommen haben. Die Arbeit mit MongoDB Atlas machte es einfach, schnelle Entwicklungs- und Testdatenbanken zu haben, die unser Team nutzen konnte. Eine Zeit lang war MongoDB nicht ACID-konform, unterstützte keine Transaktionen und entmutigte zu viele innere Join-ähnliche Operationen, daher verwendeten wir für E-Commerce-Anwendungen immer noch am häufigsten Postgres. Abgesehen davon gibt es eine Fülle von Bibliotheken, die dazu passen, und die Abfragesprache von Mongo und die erstklassige JSON-Unterstützung gaben uns Geschwindigkeit und Effizienz, die wir mit relationalen Datenbanken nicht erlebt hatten. MongoDB hat kürzlich Unterstützung für ACID-Transaktionen hinzugefügt, aber lange Zeit war dies der Hauptgrund, warum wir uns stattdessen für Postgres entschieden haben.
MongoDB führte uns auch zu einem neuen Maß an Flexibilität. Mitten in einem Agenturprojekt ändern sich zwangsläufig die Anforderungen. Egal wie hart Sie sich dagegen wehren, es gibt immer eine Datenanforderung in letzter Minute . Bei NoSQL-Datenbanken machte die Flexibilität der Datenstruktur diese Art von Änderungen im Allgemeinen weniger hart. Wir hatten am Ende keinen Ordner voller Migrationsdateien, um hinzugefügte und entfernte und wieder hinzugefügte Spalten zu verwalten, bevor ein Projekt überhaupt das Licht der Welt erblickte.
Als Service war Mongo Atlas auch ziemlich nah an dem, was wir uns von einem Datenbank-Cloud-Service erhofft hatten. Ich stelle mir Atlas gerne als halb -serverloses Angebot vor, da Sie immer noch einen gewissen Betriebsaufwand für die Verwaltung haben. Sie müssen eine Datenbank mit einer bestimmten Größe bereitstellen und im Voraus eine Menge an Arbeitsspeicher auswählen. Diese Dinge werden nicht automatisch für Sie skaliert, sodass Sie sie überwachen müssen, wenn es an der Zeit ist, mehr Speicherplatz oder Arbeitsspeicher bereitzustellen. In einer wirklich serverlosen Datenbank würde dies alles automatisch und nach Bedarf geschehen.
Wir haben auch Firebase Realtime Database für einige Projekte verwendet. Dies war in der Tat ein serverloses Angebot, bei dem die Datenbank nach Bedarf hoch- und herunterskaliert wird, und mit nutzungsbasierten Preisen war es sinnvoll für Anwendungen, bei denen die Skalierung im Voraus nicht bekannt und das Budget begrenzt war. Wir haben dies anstelle von MongoDB für kurzlebige Projekte mit einfachen Datenanforderungen verwendet.
Eine Sache, die uns an Firebase nicht gefallen hat, war, dass es weiter von dem typischen relationalen Modell entfernt war, das auf normalisierten Daten basiert, an das wir gewöhnt waren. Da wir die Datenstrukturen flach hielten, hatten wir oft mehr Duplizierung, was mit zunehmendem Projektwachstum ein wenig hässlich werden konnte. Am Ende müssen Sie dieselben Daten an mehreren Stellen aktualisieren oder versuchen, verschiedene Referenzen zusammenzuführen, was zu mehreren Abfragen führt, die im Code schwer zu erklären sind. Obwohl wir Firebase mochten, haben wir uns nie wirklich in die Abfragesprache verliebt und fanden die Dokumentation manchmal glanzlos.
Im Allgemeinen hatten sowohl MongoDB als auch Firebase einen ähnlichen Fokus auf denormalisierte Daten , und ohne Zugriff auf effiziente Transaktionen fanden wir oft viele der Workflows, die in relationalen Datenbanken einfach zu modellieren waren, was zu komplexerem Code auf der Anwendungsebene führte NoSQL-Pendants. Wenn wir die Flexibilität und Benutzerfreundlichkeit dieser NoSQL-Angebote mit der Robustheit und relationalen Modellierung einer traditionellen SQL-Datenbank kombinieren könnten, hätten wir wirklich eine großartige Übereinstimmung gefunden. Wir waren der Meinung, dass MongoDB die bessere API und die besseren Funktionen hatte, aber Firebase hatte das wirklich serverlose Modell im Betrieb.
Unser Ideal
An diesem Punkt können wir anfangen zu prüfen, welche neuen Optionen wir in Betracht ziehen werden. Wir haben unsere bisherigen Lösungen klar definiert und die Dinge identifiziert, die für uns mindestens in unserer neuen Lösung wichtig sind. Wir haben nicht nur eine Grundlinie oder Mindestanforderungen, sondern auch eine Reihe von Problemen, die wir mit der neuen Lösung für uns lösen möchten. Hier sind die technischen Voraussetzungen , die wir haben:
- Betrieblich serverlos mit On-Demand-Skalierung
- Flexible Modellierung (schemalos)
- Keine Abhängigkeit von Migrationen oder ORMs
- ACID-konforme Transaktionen
- Unterstützt Beziehungen und normalisierte Daten
- Funktioniert sowohl mit serverlosen als auch mit traditionellen Backends
Jetzt, wo wir eine Liste mit Must-Haves haben, können wir tatsächlich einige Optionen bewerten. Es ist vielleicht nicht wichtig, dass die neue Lösung hier jedes Ziel trifft. Es kann einfach sein, dass es die richtige Kombination von Funktionen trifft, wo sich bestehende Lösungen nicht überschneiden. Wenn Sie beispielsweise schemalose Flexibilität wollten, mussten Sie ACID-Transaktionen aufgeben. (Bei Datenbanken war dies lange Zeit der Fall.)
Ein Beispiel aus einer anderen Domäne ist, dass Sie TSX und React verwenden müssen, wenn Sie Typskript-Validierung in Ihrem Vorlagen-Rendering haben möchten. Wenn Sie sich für Optionen wie Svelte oder Vue entscheiden, können Sie dies – teilweise, aber nicht vollständig – über das Vorlagen-Rendering erreichen . Eine Lösung, die Ihnen den geringen Platzbedarf und die Geschwindigkeit von Svelte mit der Typprüfung auf Vorlagenebene von React und TypeScript bietet, könnte also für die Übernahme ausreichen, selbst wenn ihr eine andere Funktion fehlt. Das Gleichgewicht zwischen Wünschen und Bedürfnissen ändert sich von Projekt zu Projekt. Es liegt an Ihnen, herauszufinden, wo der Wert liegen wird, und zu entscheiden, wie Sie die wichtigsten Punkte in Ihrer Analyse ankreuzen.
Wir können uns jetzt eine Lösung ansehen und sehen, wie sie im Vergleich zu unserer gewünschten Lösung abschneidet. Fauna ist eine serverlose Datenbanklösung , die sich durch eine On-Demand-Skalierung mit globaler Verteilung auszeichnet. Es handelt sich um eine schemalose Datenbank, die ACID-konforme Transaktionen bereitstellt und als Feature relationale Abfragen und normalisierte Daten unterstützt. Fauna kann sowohl in serverlosen Anwendungen als auch in traditionelleren Backends verwendet werden und bietet Bibliotheken für die Arbeit mit den gängigsten Sprachen. Fauna bietet zusätzlich Workflows zur Authentifizierung sowie eine einfache und effiziente Mandantenfähigkeit. Dies sind beide solide zusätzliche Merkmale, die zu beachten sind, da sie die schwankenden Faktoren sein könnten, wenn zwei Technologien in unserer Bewertung direkt aufeinander treffen.
Nachdem wir uns nun all diese Stärken angesehen haben, müssen wir die Schwächen bewerten . Eines davon ist Fauna, das nicht Open Source ist. Dies bedeutet jedoch, dass Risiken einer Anbieterbindung oder von Geschäfts- und Preisänderungen bestehen, die außerhalb Ihrer Kontrolle liegen. Open Source kann nett sein, weil Sie die Technologie oft zu einem anderen Anbieter bringen können, wenn Sie möchten, oder möglicherweise zum Projekt beitragen.
In der Welt der Agenturen müssen wir Vendor Lock-in genau beobachten, nicht so sehr wegen des Preises, sondern wegen der Rentabilität des zugrunde liegenden Geschäfts. Datenbanken für ein Projekt, das sich mitten in der Entwicklung befindet oder ein paar Jahre alt ist, ändern zu müssen, ist für eine Agentur katastrophal. Oft muss ein Kunde dafür die Rechnung bezahlen, was kein angenehmes Gespräch ist.
Eine weitere Schwachstelle, mit der wir uns beschäftigt haben, ist der Fokus auf JAMstack . Obwohl wir JAMstack lieben, entwickeln wir immer häufiger eine Vielzahl traditioneller Webanwendungen. Wir möchten sicher sein, dass Fauna diese Anwendungsfälle weiterhin unterstützt. Wir hatten in der Vergangenheit schlechte Erfahrungen mit einem Hosting-Anbieter, der All-in auf JAMstack ging, und mussten am Ende eine ziemlich große Bandbreite von Websites aus dem Dienst migrieren, daher möchten wir zuversichtlich sein, dass alle Anwendungsfälle weiterhin gesehen werden solide Unterstützung. Im Moment scheint dies der Fall zu sein, und die von Fauna bereitgestellten serverlosen Workflows können eine traditionellere Anwendung tatsächlich recht gut ergänzen.

An diesem Punkt haben wir unsere funktionale Recherche durchgeführt und der einzige Weg, um zu wissen, ob diese Lösung realisierbar ist, besteht darin, Code zu schreiben. In einer Agenturumgebung können wir uns nicht einfach Wochen aus dem Zeitplan nehmen, damit die Leute mehrere Lösungen evaluieren. Dies ist die Natur der Arbeit in einer Agentur im Vergleich zu einer SaaS-Umgebung . Im letzteren Fall könnten Sie ein paar Prototypen bauen, um zu versuchen, die richtige Lösung zu finden. In einer Agentur hat man ein paar Tage Zeit zum Experimentieren oder vielleicht die Möglichkeit, ein Nebenprojekt zu machen, aber im Großen und Ganzen müssen wir das jetzt wirklich auf ein oder zwei Technologien eingrenzen und dann die Finger an die Tastatur legen.
Die Entwicklererfahrung
Die Erfahrungsseite einer neuen Technologie zu beurteilen, ist vielleicht der schwierigste der drei Bereiche, da sie von Natur aus subjektiv ist. Es wird auch von Team zu Team Variabilität geben. Wenn Sie beispielsweise einen Ruby-Programmierer, einen Python-Programmierer und einen Rust-Programmierer nach ihrer Meinung zu verschiedenen Sprachfeatures fragen, erhalten Sie eine ganze Reihe von Antworten. Bevor Sie also beginnen, eine Erfahrung zu beurteilen, müssen Sie zunächst entscheiden, welche Eigenschaften für Ihr Team insgesamt am wichtigsten sind.

Für Agenturen gibt es meiner Meinung nach zwei große Engpässe in Bezug auf die Entwicklererfahrung:
- Rüstzeit und Konfiguration
- Erlernbarkeit
Beides wirkt sich auf unterschiedliche Weise auf die langfristige Lebensfähigkeit einer neuen Technologie aus. Es kann Kopfschmerzen bereiten, wechselnde Entwicklerteams in einer Agentur synchron zu halten. Tools mit hohen Einrichtungskosten und Konfigurationen im Voraus sind für Agenturen bekanntermaßen schwierig zu handhaben. Die andere ist die Erlernbarkeit und wie einfach es für Entwickler ist, die neue Technologie zu erweitern. Wir werden näher darauf eingehen und warum sie meine Basis sind, wenn ich mit der Bewertung der Entwicklererfahrung beginne.
Einrichtungszeit und Konfiguration
Agenturen haben in der Regel wenig Geduld und Zeit für die Konfiguration. Ich persönlich liebe scharfe Werkzeuge mit ergonomischem Design, die es mir ermöglichen, schnell an einem geschäftlichen Problem zu arbeiten. Vor einigen Jahren habe ich für ein SaaS-Unternehmen gearbeitet, das ein komplexes lokales Setup hatte, das viele Konfigurationen erforderte und oft an zufälligen Punkten im Setup-Prozess fehlschlug. Sobald Sie einmal eingerichtet waren, war es üblich, nichts anzufassen und zu hoffen, dass Sie nicht lange genug im Unternehmen waren, um es auf einem anderen Computer erneut einrichten zu müssen. Ich habe Entwickler getroffen, die es sehr genossen, jeden kleinen Teil ihres Emacs-Setups zu konfigurieren, und sich nichts dabei gedacht haben, ein paar Stunden mit einer kaputten lokalen Umgebung zu verlieren.
Im Allgemeinen habe ich festgestellt, dass Agenturingenieure diese Art von Dingen in ihrer täglichen Arbeit verachten. Zu Hause basteln sie vielleicht an diesen Arten von Tools herum, aber wenn sie eine Deadline haben, gibt es nichts Besseres als Tools, die einfach funktionieren. In Agenturen lernen wir normalerweise lieber ein paar neue Dinge, die gut und beständig funktionieren, als in der Lage zu sein, jedes Stück Technik nach dem persönlichen Geschmack jedes Einzelnen zu konfigurieren.
Das Gute an der Arbeit mit einer Cloud-Plattform, die nicht Open Source ist, ist, dass sie die Einrichtung und Konfiguration vollständig besitzen. Während ein Nachteil davon die Herstellerbindung ist, besteht der Vorteil darin, dass diese Arten von Tools oft das tun, wofür sie eingerichtet wurden. Es gibt kein Herumbasteln an Umgebungen, keine lokalen Setups und keine Deployment-Pipelines. Wir müssen auch weniger Entscheidungen treffen.
Dies ist von Natur aus der Reiz von Serverless . Serverless ist im Allgemeinen stärker auf proprietäre Dienste und Tools angewiesen. Wir tauschen die Flexibilität des Hostings und des Quellcodes aus, um eine größere Stabilität zu erreichen und uns auf die Probleme der Geschäftsdomäne zu konzentrieren, die wir zu lösen versuchen. Ich möchte auch anmerken, dass, wenn ich eine Technologie evaluiere und ich das Gefühl habe, dass eine Migration von einer Plattform erforderlich sein könnte, dies am Anfang oft ein schlechtes Zeichen ist.
Im Fall von Datenbanken ist die Set-it-and-forget-it-Konfiguration ideal, wenn Sie mit Kunden arbeiten, bei denen die Datenbankanforderungen mehrdeutig sein können. Wir hatten Kunden, die sich nicht sicher waren, wie beliebt ein Programm oder eine Anwendung sein würde. Wir hatten Kunden, für deren Unterstützung wir technisch gesehen nicht auf diese Weise beauftragt waren, die uns aber dennoch panisch anriefen, als sie uns zur Skalierung ihrer Datenbank oder Anwendung benötigten.
In der Vergangenheit mussten wir bei der Erstellung unserer SOWs immer Dinge wie Redundanz, Datenreplikation und Sharding berücksichtigen, um sie zu skalieren. Der Versuch, jedes Szenario abzudecken und gleichzeitig darauf vorbereitet zu sein, ein ganzes Geschäftsbuch zu verschieben, falls eine Datenbank nicht skaliert, ist eine unmögliche Situation, auf die man sich vorbereiten kann. Am Ende macht eine serverlose Datenbank diese Dinge einfacher.
Sie verlieren nie Daten , Sie müssen sich keine Gedanken über die Replikation von Daten über ein Netzwerk oder die Bereitstellung einer größeren Datenbank und eines größeren Computers machen, um sie auszuführen – alles funktioniert einfach. Wir konzentrieren uns nur auf das jeweilige Geschäftsproblem, die technische Architektur und Skalierung werden immer verwaltet. Für unser Entwicklungsteam ist dies ein großer Gewinn; Wir haben weniger Brandschutzübungen, Überwachung und Kontextwechsel.
Erlernbarkeit
Es gibt ein klassisches Maß für die Benutzererfahrung, das meines Erachtens auf die Entwicklererfahrung anwendbar ist, nämlich Erlernbarkeit . Beim Entwerfen für eine bestimmte Benutzererfahrung schauen wir nicht nur darauf, ob etwas beim ersten Versuch offensichtlich oder einfach ist. Technologie hat einfach mehr Komplexität als das die meiste Zeit. Wichtig ist, wie einfach ein neuer Benutzer das System erlernen und beherrschen kann.
Wenn es um technische Tools geht, insbesondere um leistungsstarke, wäre es viel verlangt, dass es keine Lernkurve gibt . Normalerweise suchen wir nach einer großartigen Dokumentation für die häufigsten Anwendungsfälle und darauf, dass dieses Wissen in einem Projekt einfach und schnell aufgebaut werden kann. Es ist in Ordnung, beim ersten Projekt mit einer Technologie ein wenig Zeit für das Lernen zu verlieren. Danach sollte sich die Effizienz mit jedem aufeinanderfolgenden Projekt verbessern.
Was ich hier speziell suche, ist, wie wir Wissen und Muster, die wir bereits kennen, nutzen können, um die Lernkurve zu verkürzen. Beispielsweise wird es bei serverlosen Datenbanken praktisch keine Lernkurve geben, um sie in der Cloud einzurichten und bereitzustellen. Wenn es um die Verwendung der Datenbank geht, gefällt mir unter anderem, dass wir immer noch all die Jahre der Beherrschung relationaler Datenbanken nutzen und diese Erkenntnisse auf unser neues Setup anwenden können. In diesem Fall lernen wir den Umgang mit einem neuen Tool, aber es zwingt uns nicht, unsere Datenmodellierung von Grund auf zu überdenken.

Als Beispiel hierfür haben wir festgestellt, dass bei der Verwendung von Firebase, MongoDB und DynamoDB denormalisierte Daten gefördert wurden, anstatt zu versuchen, verschiedene Dokumente zusammenzuführen. Dies führte zu einer Menge kognitiver Reibung bei der Modellierung unserer Daten, da wir eher in Bezug auf Zugriffsmuster als auf Geschäftseinheiten denken mussten. Auf der anderen Seite ermöglichte uns diese Fauna, unser jahrelanges relationales Wissen sowie unsere Vorliebe für normalisierte Daten bei der Modellierung von Daten zu nutzen.
Der Teil, an den wir uns gewöhnen mussten, war die Verwendung von Indizes und einer neuen Abfragesprache, um diese Teile zusammenzubringen. Im Allgemeinen habe ich festgestellt, dass die Beibehaltung von Konzepten, die Teil größerer Softwaredesign-Paradigmen sind, es dem Entwicklungsteam in Bezug auf Erlernbarkeit und Akzeptanz erleichtert.
Woher wissen wir, dass ein Team eine neue Technologie annimmt und liebt? Ich denke, das beste Zeichen ist, wenn wir uns fragen, ob sich dieses Tool in die besagte neue Technologie integrieren lässt? Wenn eine neue Technologie so wünschenswert und angenehm ist, dass das Team nach Möglichkeiten sucht, sie in weitere Projekte zu integrieren, ist das ein gutes Zeichen dafür, dass Sie einen Gewinner haben.
Das Geschäft
In diesem Abschnitt müssen wir uns ansehen, wie eine neue Technologie unsere Geschäftsanforderungen erfüllt . Dazu gehören Fragen wie:
- Wie einfach kann es bepreist und in unsere Supportpläne integriert werden?
- Können wir es einfach auf Kunden übertragen?
- Können Kunden bei Bedarf in dieses Tool aufgenommen werden?
- Wie viel Zeit spart dieses Tool tatsächlich, wenn überhaupt?
Der Aufstieg von Serverless als Paradigma passt gut zu Agenturen. Wenn wir über Datenbanken und DevOps sprechen, ist der Bedarf an Spezialisten in diesen Bereichen in Agenturen begrenzt. Oft geben wir ein abgeschlossenes Projekt ab oder unterstützen es in begrenztem Umfang langfristig. Wir neigen dazu, Full-Stack-Ingenieure zu bevorzugen, da diese Anforderungen die DevOps-Anforderungen bei weitem übersteigen. Wenn wir einen DevOps-Ingenieur einstellen würden, würde er wahrscheinlich ein paar Stunden damit verbringen, ein Projekt bereitzustellen, und viele weitere Stunden damit verbringen, auf ein Feuer zu warten.
In dieser Hinsicht haben wir immer einige DevOps-Kontraktoren bereit, besetzen diese Positionen jedoch nicht in Vollzeit. Das bedeutet, dass wir uns nicht darauf verlassen können, dass ein DevOps-Ingenieur bereit ist, auf ein unerwartetes Problem zu springen. Wir wissen, dass wir bessere Preise für das Hosting erzielen können, indem wir direkt zu AWS gehen, aber wir wissen auch, dass wir uns bei der Verwendung von Heroku auf unsere vorhandenen Mitarbeiter verlassen können, um die meisten Probleme zu beheben. Sofern wir keinen Kunden haben, den wir langfristig mit spezifischen Backend-Anforderungen unterstützen müssen, greifen wir gerne standardmäßig auf verwaltete Plattformen als Service zurück.
Datenbanken sind keine Ausnahme. Wir stützen uns gerne auf Dienste wie Mongo Atlas oder Heroku Postgres, um diesen Prozess so einfach wie möglich zu gestalten. Als wir anfingen, immer mehr unserer Stacks in serverlose Tools wie Vercel, Netlify oder AWS Lambda zu integrieren, mussten sich unsere Datenbankanforderungen entsprechend weiterentwickeln. Serverlose Datenbanken wie Firebase, DynamoDB und Fauna sind großartig, weil sie sich gut in serverlose Anwendungen integrieren lassen, aber unser Unternehmen auch vollständig von Bereitstellung und Skalierung befreien.
Diese Lösungen eignen sich auch gut für traditionellere Anwendungen, bei denen wir keine serverlose Anwendung haben, aber dennoch serverlose Effizienzen auf Datenbankebene nutzen können. Als Unternehmen ist es für uns produktiver, eine einzige Datenbank zu lernen, die auf beide Welten angewendet werden kann, als den Kontext zu wechseln. Dies ähnelt unserer Entscheidung, Node und isomorphes JavaScript (und TypeScript) zu übernehmen.
Einer der Nachteile, die wir bei Serverless festgestellt haben, war die Preisgestaltung für Kunden , für die wir diese Dienste verwalten. In einer traditionelleren Architektur machen es Flatrate-Stufen sehr einfach, diese in einen Tarif für Kunden mit vorhersehbaren Umständen für Erhöhungen und Überschreitungen umzuwandeln. Wenn es um Serverless geht, kann dies mehrdeutig sein. Finanzleute mögen es normalerweise nicht, Dinge zu hören, wie wir 1/10 Cent für jeden Lesevorgang über 1 Million verlangen, und so weiter und so weiter.
Dies ist selbst für Ingenieure schwer in eine feste Zahl zu übersetzen, da wir oft Anwendungen erstellen, bei denen wir nicht sicher sind, wie sie verwendet werden . Wir müssen die Ebenen oft selbst erstellen, aber die vielen Variablen, die in die Kostenberechnung eines Lambda einfließen, können schwer zu verstehen sein. Letztendlich sind diese Pay-as-you-go-Preismodelle für ein SaaS-Produkt großartig, aber für Agenturen mögen die Buchhalter konkretere und vorhersehbare Zahlen.
Wenn es um Fauna ging, war dies definitiv mehrdeutiger herauszufinden als beispielsweise eine Standard-MySQL-Datenbank, die ein Flatrate-Hosting für eine festgelegte Menge an Speicherplatz hatte. Der Vorteil war, dass Fauna einen netten Rechner bietet, mit dem wir unsere eigenen Preisschemata zusammenstellen konnten.
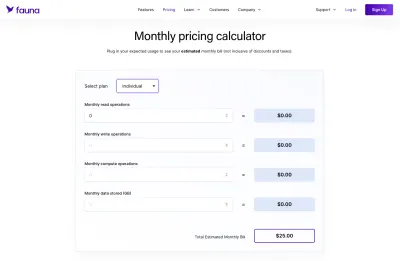
Ein weiterer schwieriger Aspekt von Serverless kann sein, dass viele dieser Anbieter keine einfache Aufschlüsselung jeder gehosteten Anwendung zulassen . Die Heroku-Plattform macht dies beispielsweise ganz einfach, indem sie neue Pipelines und Teams erstellt. Wir können sogar die Kreditkarte eines Kunden für ihn eingeben, falls er unsere Hosting-Angebote nicht nutzen möchte. Dies kann auch alles innerhalb desselben Dashboards erfolgen, sodass wir nicht mehrere Anmeldungen erstellen mussten.
Bei anderen serverlosen Tools war dies viel schwieriger. Bei der Bewertung serverloser Datenbanken unterstützt Firebase die Aufteilung von Zahlungen nach Projekt . Im Fall von Fauna oder DynamoDB ist dies nicht möglich, daher müssen wir einige Arbeiten durchführen, um die Nutzung in ihrem Dashboard zu überwachen, und wenn der Kunde unseren Dienst verlassen möchte, müssten wir die Datenbank auf sein eigenes Konto übertragen.
Letztendlich bieten serverlose Tools großartige Geschäftsmöglichkeiten in Bezug auf Kosteneinsparungen, Verwaltung und Prozesseffizienz. Allerdings erweisen sie sich für Agenturen oft als Herausforderung, wenn es um Preisgestaltung und Kontoverwaltung geht. Dies ist ein Bereich, in dem wir Kostenrechner nutzen mussten, um unsere eigenen vorhersehbaren Preisstaffeln zu erstellen, oder Kunden mit ihren eigenen Konten einrichten mussten, damit sie die Zahlungen direkt vornehmen können.
Fazit
Es kann eine schwierige Aufgabe sein, eine neue Technologie als Agentur einzuführen. Während wir in der einzigartigen Position sind, mit neuen Greenfield-Projekten zu arbeiten, die Möglichkeiten für neue Technologien bieten, müssen wir auch die langfristigen Investitionen in diese berücksichtigen. Wie werden sie abschneiden? Werden unsere Mitarbeiter produktiv sein und sie gerne benutzen? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Weiterführende Lektüre
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience