
Erstellen eines Raummelders für IoT-Geräte unter Mac OS
Veröffentlicht: 2022-03-10Zu wissen, in welchem Raum Sie sich befinden, ermöglicht verschiedene IoT-Anwendungen – vom Einschalten des Lichts bis zum Wechseln der Fernsehkanäle. Wie können wir also erkennen, wann Sie und Ihr Telefon in der Küche, im Schlafzimmer oder im Wohnzimmer sind? Mit der heutigen Standardhardware gibt es unzählige Möglichkeiten:
Eine Lösung besteht darin, jeden Raum mit einem Bluetooth-Gerät auszustatten . Sobald sich Ihr Telefon in Reichweite eines Bluetooth-Geräts befindet, erkennt Ihr Telefon anhand des Bluetooth-Geräts, um welchen Raum es sich handelt. Die Wartung einer Reihe von Bluetooth-Geräten ist jedoch mit einem erheblichen Aufwand verbunden – vom Austausch von Batterien bis zum Austausch defekter Geräte. Außerdem ist die Nähe zum Bluetooth-Gerät nicht immer die Lösung: Wenn Sie sich im Wohnzimmer an der mit der Küche geteilten Wand befinden, sollten Ihre Küchengeräte nicht anfangen, Essen am laufenden Band zu produzieren.
Eine andere, wenn auch unpraktische Lösung ist die Verwendung von GPS . Denken Sie jedoch daran, dass GPS in Innenräumen schlecht funktioniert, wo die Vielzahl von Wänden, anderen Signalen und anderen Hindernissen die Genauigkeit von GPS beeinträchtigen.
Unser Ansatz besteht stattdessen darin, alle WLAN-Netzwerke in Reichweite zu nutzen – auch die, mit denen Ihr Telefon nicht verbunden ist. So geht's: Berücksichtigen Sie die Stärke von WiFi A in der Küche; Sagen wir, es ist 5. Da sich zwischen der Küche und dem Schlafzimmer eine Wand befindet, können wir vernünftigerweise davon ausgehen, dass die Stärke von WiFi A im Schlafzimmer unterschiedlich ist. Sagen wir, es ist 2. Diesen Unterschied können wir ausnutzen, um vorherzusagen, in welchem Raum wir uns befinden. Mehr noch: Das WLAN-Netzwerk B unseres Nachbarn ist nur vom Wohnzimmer aus zu erkennen, von der Küche aus aber quasi unsichtbar. Das macht die Vorhersage noch einfacher. Insgesamt gibt uns die Liste aller WLANs in Reichweite reichlich Informationen.
Diese Methode hat die entscheidenden Vorteile:
- keine weitere Hardware erforderlich;
- sich auf stabilere Signale wie WiFi verlassen;
- funktioniert dort gut, wo andere Techniken wie GPS schwach sind.
Je mehr Wände, desto besser, denn je unterschiedlicher die WLAN-Netzstärken sind, desto besser lassen sich die Räume einordnen. Sie erstellen eine einfache Desktop-App, die Daten sammelt, aus den Daten lernt und vorhersagt, in welchem Raum Sie sich gerade befinden.
Weiterführende Literatur zu SmashingMag:
- Der Aufstieg der intelligenten Conversational UI
- Anwendungen des maschinellen Lernens für Designer
- So erstellen Sie Prototypen für IoT-Erfahrungen: Aufbau der Hardware
- Design für das Internet der emotionalen Dinge
Voraussetzungen
Für dieses Tutorial benötigen Sie einen Mac OSX. Während der Code für jede Plattform gelten kann, stellen wir nur Installationsanweisungen für Abhängigkeiten für Mac bereit.
- Mac OS X
- Homebrew, ein Paketmanager für Mac OSX. Kopieren Sie zum Installieren den Befehl und fügen Sie ihn in brew.sh ein
- Installation von NodeJS 10.8.0+ und npm
- Installation von Python 3.6+ und Pip. Siehe die ersten 3 Abschnitte von „Installieren von virtualenv, Installieren mit pip und Verwalten von Paketen“.
Schritt 0: Arbeitsumgebung einrichten
Ihre Desktop-App wird in NodeJS geschrieben. Um jedoch effizientere Rechenbibliotheken wie numpy zu nutzen, wird der Trainings- und Vorhersagecode in Python geschrieben. Zunächst richten wir Ihre Umgebungen ein und installieren Abhängigkeiten. Erstellen Sie ein neues Verzeichnis für Ihr Projekt.
mkdir ~/riotNavigieren Sie in das Verzeichnis.
cd ~/riotVerwenden Sie pip, um den standardmäßigen Virtual Environment Manager von Python zu installieren.
sudo pip install virtualenv Erstellen Sie eine virtuelle Python3.6-Umgebung namens riot .
virtualenv riot --python=python3.6Aktivieren Sie die virtuelle Umgebung.
source riot/bin/activate Vor Ihrer Eingabeaufforderung steht jetzt (riot) . Dies zeigt an, dass wir erfolgreich in die virtuelle Umgebung eingetreten sind. Installieren Sie die folgenden Pakete mit pip :
-
numpy: Eine effiziente, lineare Algebra-Bibliothek -
scipy: Eine wissenschaftliche Rechenbibliothek, die beliebte Modelle für maschinelles Lernen implementiert
pip install numpy==1.14.3 scipy ==1.1.0Bei der Einrichtung des Arbeitsverzeichnisses beginnen wir mit einer Desktop-App, die alle WLAN-Netzwerke in Reichweite aufzeichnet. Diese Aufzeichnungen bilden Trainingsdaten für Ihr maschinelles Lernmodell. Sobald wir Daten zur Hand haben, schreiben Sie einen Kleinste-Quadrate-Klassifikator, der auf den zuvor gesammelten WiFi-Signalen trainiert wird. Schließlich verwenden wir das Modell der kleinsten Quadrate, um den Raum vorherzusagen, in dem Sie sich befinden, basierend auf den WLAN-Netzwerken in Reichweite.
Schritt 1: Erste Desktop-Anwendung
In diesem Schritt erstellen wir eine neue Desktop-Anwendung mit Electron JS. Zu Beginn verwenden wir stattdessen den Node-Paketmanager npm und ein Download-Dienstprogramm wget .
brew install npm wgetZunächst erstellen wir ein neues Node-Projekt.
npm init Dies fordert Sie zur Eingabe des Paketnamens und dann der Versionsnummer auf. Drücken Sie die ENTER , um den Standardnamen riot und die Standardversion 1.0.0 zu akzeptieren.
package name: (riot) version: (1.0.0) Dies fordert Sie zur Eingabe einer Projektbeschreibung auf. Fügen Sie eine beliebige nicht leere Beschreibung hinzu. Unten ist die Beschreibung room detector
description: room detector Dadurch werden Sie aufgefordert, den Einstiegspunkt oder die Hauptdatei anzugeben, von der aus das Projekt ausgeführt werden soll. Geben Sie app.js .
entry point: (index.js) app.js Dies fordert Sie zur Eingabe des test command und des git repository auf. Drücken Sie die ENTER , um diese Felder vorerst zu überspringen.
test command: git repository: Dies fordert Sie zur Eingabe von keywords und author auf. Geben Sie alle gewünschten Werte ein. Unten verwenden wir iot , wifi für Schlüsselwörter und John Doe für den Autor.
keywords: iot,wifi author: John Doe Dies fordert Sie zur Lizenzierung auf. Drücken Sie die ENTER , um den Standardwert von ISC zu akzeptieren.
license: (ISC) An dieser Stelle zeigt Ihnen npm eine Zusammenfassung der bisherigen Informationen an. Ihre Ausgabe sollte der folgenden ähneln.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Drücken Sie zum Akzeptieren die ENTER . npm erzeugt dann eine package.json . Listen Sie alle zu überprüfenden Dateien auf.
lsDadurch wird die einzige Datei in diesem Verzeichnis zusammen mit dem Ordner der virtuellen Umgebung ausgegeben.
package.json riotInstallieren Sie NodeJS-Abhängigkeiten für unser Projekt.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Beginnen Sie mit main.js von Electron Quick Start, indem Sie die Datei herunterladen, indem Sie unten verwenden. Das folgende Argument -O benennt main.js in app.js um.
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Öffnen app.js in nano oder Ihrem bevorzugten Texteditor.
nano app.js Ändern Sie in Zeile 12 index.html in static/index.html , da wir ein Verzeichnis static erstellen werden, das alle HTML-Vorlagen enthält.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Speichern Sie Ihre Änderungen und verlassen Sie den Editor. Ihre Datei sollte mit dem Quellcode der Datei app.js . Erstellen Sie nun ein neues Verzeichnis für unsere HTML-Vorlagen.
mkdir staticLaden Sie ein für dieses Projekt erstelltes Stylesheet herunter.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Öffnen Sie static/index.html in nano oder Ihrem bevorzugten Texteditor. Beginnen Sie mit der Standard-HTML-Struktur.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Verlinken Sie direkt nach dem Titel die von Google Fonts und Stylesheet verlinkte Montserrat-Schriftart.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Fügen Sie zwischen den main Tags einen Platz für den vorhergesagten Raumnamen hinzu.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Ihr Skript sollte jetzt genau mit dem Folgenden übereinstimmen. Verlassen Sie den Editor.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Ändern Sie nun die Paketdatei so, dass sie einen Startbefehl enthält.
nano package.json Fügen Sie direkt nach Zeile 7 einen start hinzu, der auf electron . . Achten Sie darauf, am Ende der vorherigen Zeile ein Komma hinzuzufügen.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Speichern und schließen. Sie können jetzt Ihre Desktop-App in Electron JS starten. Verwenden Sie npm , um Ihre Anwendung zu starten.
npm startIhre Desktop-Anwendung sollte den folgenden entsprechen.

Damit ist Ihre startende Desktop-App abgeschlossen. Navigieren Sie zum Beenden zurück zu Ihrem Terminal und STRG+C. Im nächsten Schritt werden wir WLAN-Netzwerke aufzeichnen und das Aufzeichnungsdienstprogramm über die Benutzeroberfläche der Desktop-Anwendung zugänglich machen.
Schritt 2: WLAN-Netzwerke aufzeichnen
In diesem Schritt schreiben Sie ein NodeJS-Skript, das die Stärke und Frequenz aller WLAN-Netzwerke in Reichweite aufzeichnet. Erstellen Sie ein Verzeichnis für Ihre Skripte.
mkdir scripts Öffnen scripts/observe.js in nano oder Ihrem bevorzugten Texteditor.
nano scripts/observe.jsImportieren Sie ein NodeJS-WLAN-Dienstprogramm und das Dateisystemobjekt.
var wifi = require('node-wifi'); var fs = require('fs'); Definieren Sie eine record , die einen Vervollständigungshandler akzeptiert.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Initialisieren Sie in der neuen Funktion das WLAN-Dienstprogramm. Setzen iface auf null, um eine zufällige WLAN-Schnittstelle zu initialisieren, da dieser Wert derzeit irrelevant ist.
function record(n, completion, hook) { wifi.init({ iface : null }); }Definieren Sie ein Array für Ihre Proben. Beispiele sind Trainingsdaten, die wir für unser Modell verwenden werden. Die Beispiele in diesem speziellen Tutorial sind Listen von WLAN-Netzwerken in Reichweite und den zugehörigen Stärken, Frequenzen, Namen usw.
function record(n, completion, hook) { ... samples = [] } Definieren Sie eine rekursive Funktion startScan , die WLAN-Scans asynchron initiiert. Nach Abschluss ruft der asynchrone WLAN-Scan dann rekursiv startScan auf.
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } Suchen Sie im wifi.scan Callback nach Fehlern oder leeren Listen von Netzwerken und starten Sie den Scan neu, falls dies der Fall ist.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Fügen Sie den Basisfall der rekursiven Funktion hinzu, der den Vervollständigungshandler aufruft.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Geben Sie eine Fortschrittsaktualisierung aus, fügen Sie sie an die Liste der Beispiele an und führen Sie den rekursiven Aufruf durch.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); Rufen Sie am Ende Ihrer Datei die record mit einem Rückruf auf, der Samples in einer Datei auf der Festplatte speichert.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Überprüfen Sie, ob Ihre Datei mit Folgendem übereinstimmt:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Speichern und schließen. Führen Sie das Skript aus.
node scripts/observe.jsIhre Ausgabe wird mit der folgenden übereinstimmen, mit einer variablen Anzahl von Netzwerken.
* [INFO] Collected sample 1 with 39 networks Untersuchen Sie die Proben, die gerade gesammelt wurden. Pipe to json_pp , um den JSON-Code hübsch auszudrucken, und pipe to head, um die ersten 16 Zeilen anzuzeigen.
cat samples.json | json_pp | head -16Unten sehen Sie eine Beispielausgabe für ein 2,4-GHz-Netzwerk.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Damit ist Ihr NodeJS-WLAN-Scan-Skript abgeschlossen. Dadurch können wir alle WLAN-Netzwerke in Reichweite anzeigen. Im nächsten Schritt machen Sie dieses Skript über die Desktop-App zugänglich.
Schritt 3: Verbinden Sie das Scan-Skript mit der Desktop-App
In diesem Schritt fügen Sie der Desktop-App zunächst eine Schaltfläche hinzu, mit der das Skript ausgelöst wird. Anschließend aktualisieren Sie die Benutzeroberfläche der Desktop-App mit dem Fortschritt des Skripts.
Öffnen static/index.html .
nano static/index.htmlFügen Sie die Schaltfläche „Hinzufügen“ ein, wie unten gezeigt.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Speichern und schließen. Öffnen static/add.html .
nano static/add.htmlFügen Sie den folgenden Inhalt ein.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Speichern und schließen. Öffnen Sie scripts/observe.js .
nano scripts/observe.js Definieren Sie unter der cli Funktion eine neue ui Funktion.
function cli() { ... } // start new code function ui() { } // end new code cli();Aktualisieren Sie den Status der Desktop-App, um anzuzeigen, dass die Funktion gestartet wurde.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Partitionieren Sie die Daten in Trainings- und Validierungsdatensätze.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Schreiben Sie beide Datasets noch innerhalb des completion -Callbacks auf die Festplatte.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Rufen Sie record mit den entsprechenden Callbacks auf, um 20 Samples aufzuzeichnen und die Samples auf der Festplatte zu speichern.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Rufen Sie schließlich gegebenenfalls die cli und ui -Funktionen auf. Beginnen Sie mit dem Löschen des cli(); Aufruf am Ende der Datei.
function ui() { ... } cli(); // remove me Überprüfen Sie, ob das Dokumentobjekt global zugänglich ist. Wenn nicht, wird das Skript über die Befehlszeile ausgeführt. Rufen Sie in diesem Fall die cli Funktion auf. Wenn dies der Fall ist, wird das Skript aus der Desktop-App geladen. Binden Sie in diesem Fall den Click-Listener an die ui Funktion.
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Speichern und schließen. Erstellen Sie ein Verzeichnis für unsere Daten.
mkdir dataStarten Sie die Desktop-App.
npm startSie sehen die folgende Homepage. Klicken Sie auf „Raum hinzufügen“.
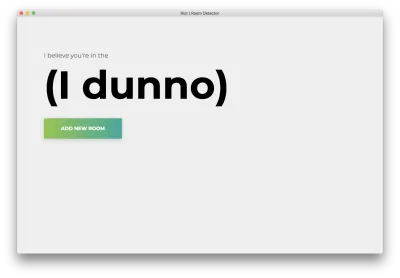
Sie sehen das folgende Formular. Geben Sie einen Namen für den Raum ein. Merken Sie sich diesen Namen, da wir ihn später verwenden werden. Unser Beispiel wird bedroom sein.
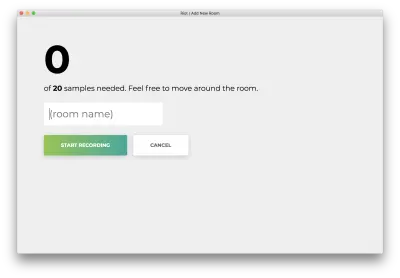
Klicken Sie auf „Aufzeichnung starten“ und Sie sehen den folgenden Status „Listening for wifi…“.

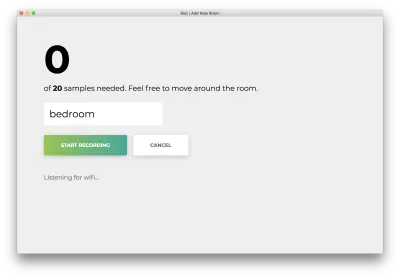
Sobald alle 20 Samples aufgezeichnet sind, stimmt Ihre App mit Folgendem überein. Der Status lautet „Fertig“.
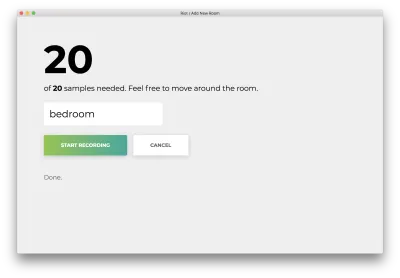
Klicken Sie auf das falsch benannte „Abbrechen“, um zur Startseite zurückzukehren, die der folgenden entspricht.
Wir können jetzt WLAN-Netzwerke von der Desktop-Benutzeroberfläche aus scannen, wodurch alle aufgezeichneten Samples in Dateien auf der Festplatte gespeichert werden. Als Nächstes trainieren wir einen sofort einsatzbereiten Algorithmus für maschinelles Lernen – die kleinsten Quadrate auf den von Ihnen gesammelten Daten.
Schritt 4: Schreiben Sie ein Python-Trainingsskript
In diesem Schritt schreiben wir ein Trainingsskript in Python. Erstellen Sie ein Verzeichnis für Ihre Schulungsprogramme.
mkdir model Öffnen model/train.py
nano model/train.py Importieren Sie oben in Ihrer Datei die numpy Berechnungsbibliothek und scipy für das Modell der kleinsten Quadrate.
import numpy as np from scipy.linalg import lstsq import json import sysDie nächsten drei Dienstprogramme kümmern sich um das Laden und Einrichten von Daten aus den Dateien auf der Festplatte. Beginnen Sie mit dem Hinzufügen einer Hilfsfunktion, die verschachtelte Listen vereinfacht. Sie werden dies verwenden, um eine Liste von Beispielen zu vereinfachen.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Fügen Sie ein zweites Dienstprogramm hinzu, das Beispiele aus den angegebenen Dateien lädt. Diese Methode abstrahiert die Tatsache, dass Samples über mehrere Dateien verteilt sind, und gibt nur einen einzigen Generator für alle Samples zurück. Für jede der Proben ist das Etikett der Index der Datei. Beispiel: Wenn Sie get_all_samples('a.json', 'b.json') , haben alle Samples in a.json das Label 0 und alle Samples in b.json das Label 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelFügen Sie als Nächstes ein Dienstprogramm hinzu, das die Beispiele mit einem Bag-of-Words-ähnlichen Modell codiert. Hier ist ein Beispiel: Angenommen, wir sammeln zwei Proben.
- WLAN-Netzwerk A mit Stärke 10 und WLAN-Netzwerk B mit Stärke 15
- WLAN-Netzwerk B mit Stärke 20 und WLAN-Netzwerk C mit Stärke 25.
Diese Funktion erzeugt eine Liste mit drei Zahlen für jedes der Samples: Der erste Wert ist die Stärke von WLAN-Netzwerk A, der zweite für Netzwerk B und der dritte für C. Tatsächlich ist das Format [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Mit allen drei oben genannten Dienstprogrammen synthetisieren wir eine Sammlung von Samples und ihren Labels. Sammeln Sie alle Proben und Labels mit get_all_samples . Definieren Sie eine konsistente ordering für die One-Hot-Codierung aller Samples und wenden Sie dann die one_hot Codierung auf die Samples an. Konstruieren Sie schließlich die Daten- und Beschriftungsmatrizen X bzw. Y
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingDiese Funktionen vervollständigen die Datenpipeline. Als nächstes abstrahieren wir die Modellvorhersage und -bewertung. Beginnen Sie mit der Definition der Vorhersagemethode. Die erste Funktion normalisiert unsere Modellausgaben, sodass die Summe aller Werte 1 ergibt und alle Werte nicht negativ sind; Dadurch wird sichergestellt, dass die Ausgabe eine gültige Wahrscheinlichkeitsverteilung ist. Die zweite wertet das Modell aus.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Bewerten Sie als Nächstes die Genauigkeit des Modells. Die erste Zeile führt die Vorhersage mithilfe des Modells aus. Die zweite zählt, wie oft sowohl der vorhergesagte als auch der wahre Wert übereinstimmen, und normalisiert dann durch die Gesamtzahl der Abtastwerte.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Damit sind unsere Vorhersage- und Bewertungsprogramme abgeschlossen. Definieren Sie nach diesen Dienstprogrammen eine main , die das Dataset sammelt, trainiert und auswertet. Lesen Sie zunächst die Liste der Argumente von der Befehlszeile aus sys.argv ; Dies sind die Räume, die in die Schulung einbezogen werden sollen. Erstellen Sie dann einen großen Datensatz aus allen angegebenen Räumen.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Wenden Sie One-Hot-Codierung auf die Etiketten an. Eine One-Hot-Kodierung ähnelt dem obigen Bag-of-Words-Modell; Wir verwenden diese Kodierung, um kategoriale Variablen zu behandeln. Angenommen, wir haben 3 mögliche Labels. Anstatt 1, 2 oder 3 zu kennzeichnen, kennzeichnen wir die Daten mit [1, 0, 0], [0, 1, 0] oder [0, 0, 1]. Für dieses Tutorial ersparen wir uns die Erklärung, warum die One-Hot-Codierung wichtig ist. Trainieren Sie das Modell, und evaluieren Sie sowohl den Trainings- als auch den Validierungssatz.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Drucken Sie beide Genauigkeiten aus und speichern Sie das Modell auf der Festplatte.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() Führen Sie am Ende der Datei die main aus.
if __name__ == '__main__': main()Speichern und schließen. Überprüfen Sie, ob Ihre Datei mit Folgendem übereinstimmt:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Speichern und schließen. Erinnern Sie sich an den Raumnamen, der oben verwendet wurde, als Sie die 20 Samples aufgenommen haben. Verwenden Sie diesen Namen anstelle von bedroom unten. Unser Beispiel ist bedroom . Wir verwenden -W ignore um Warnungen von einem LAPACK-Bug zu ignorieren.
python -W ignore model/train.py bedroomDa wir nur Trainingsbeispiele für einen Raum gesammelt haben, sollten Sie Trainings- und Validierungsgenauigkeiten von 100 % sehen.
Train accuracy (100.0%), Validation accuracy (100.0%)Als Nächstes verknüpfen wir dieses Trainingsskript mit der Desktop-App.
Schritt 5: Link-Train-Skript
In diesem Schritt trainieren wir das Modell automatisch neu, wenn der Benutzer eine neue Charge von Proben sammelt. Öffnen scripts/observe.js .
nano scripts/observe.js Importieren Sie direkt nach dem fs -Import den untergeordneten Prozess-Spawner und die Dienstprogramme.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); Fügen Sie in der ui -Funktion den folgenden Aufruf zum retrain am Ende des Vervollständigungshandlers hinzu.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Fügen Sie nach der ui -Funktion die folgende retrain Funktion hinzu. Dies erzeugt einen untergeordneten Prozess, der das Python-Skript ausführt. Nach Abschluss ruft der Prozess einen Abschlusshandler auf. Bei einem Fehler wird die Fehlermeldung protokolliert.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Speichern und schließen. Öffnen scripts/utils.js .
nano scripts/utils.js Fügen Sie das folgende Dienstprogramm zum Abrufen aller Datensätze in data/ hinzu.
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Speichern und schließen. Bewegen Sie sich zum Abschluss dieses Schritts physisch an einen neuen Ort. Idealerweise sollte zwischen Ihrem ursprünglichen Standort und Ihrem neuen Standort eine Wand sein. Je mehr Barrieren vorhanden sind, desto besser funktioniert Ihre Desktop-App.
Führen Sie erneut Ihre Desktop-App aus.
npm startFühren Sie wie zuvor das Trainingsskript aus. Klicken Sie auf „Raum hinzufügen“.
Geben Sie einen Raumnamen ein, der sich von dem Ihres ersten Raums unterscheidet. Wir werden das living room .
Klicken Sie auf „Aufzeichnung starten“ und Sie sehen den folgenden Status „Listening for wifi…“.
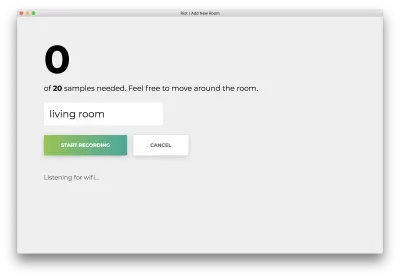
Sobald alle 20 Samples aufgezeichnet sind, stimmt Ihre App mit Folgendem überein. Der Status lautet „Fertig. Umschulungsmodell …“
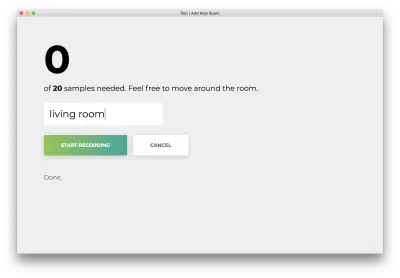
Im nächsten Schritt werden wir dieses neu trainierte Modell verwenden, um den Raum, in dem Sie sich befinden, spontan vorherzusagen.
Schritt 6: Schreiben Sie ein Python-Evaluierungsskript
In diesem Schritt laden wir die vortrainierten Modellparameter, scannen nach WLAN-Netzwerken und prognostizieren den Raum basierend auf dem Scan.
Öffnen model/eval.py .
nano model/eval.pyImportieren Sie Bibliotheken, die in unserem letzten Skript verwendet und definiert wurden.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Definieren Sie ein Dienstprogramm zum Extrahieren der Namen aller Datensätze. Diese Funktion geht davon aus, dass alle Datasets in data/ als <dataset>_train.json und <dataset>_test.json sind.
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Definieren Sie die main und beginnen Sie mit dem Laden von Parametern, die aus dem Trainingsskript gespeichert wurden.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Erstellen Sie das Dataset und prognostizieren Sie es.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Berechnen Sie einen Konfidenzwert basierend auf der Differenz zwischen den beiden höchsten Wahrscheinlichkeiten.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Extrahieren Sie abschließend die Kategorie und drucken Sie das Ergebnis aus. Um das Skript abzuschließen, rufen Sie die main Funktion auf.
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Speichern und schließen. Überprüfen Sie, ob Ihr Code mit dem Folgenden übereinstimmt (Quellcode):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Als Nächstes verbinden wir dieses Bewertungsskript mit der Desktop-App. Die Desktop-App führt kontinuierlich WLAN-Scans durch und aktualisiert die Benutzeroberfläche mit dem vorhergesagten Raum.
Schritt 7: Verbinden Sie die Evaluierung mit der Desktop-App
In diesem Schritt aktualisieren wir die Benutzeroberfläche mit einer „Vertrauens“-Anzeige. Dann führt das zugehörige NodeJS-Skript kontinuierlich Scans und Vorhersagen aus und aktualisiert die Benutzeroberfläche entsprechend.
Öffnen static/index.html .
nano static/index.htmlFügen Sie direkt nach dem Titel und vor den Schaltflächen eine Vertrauenszeile hinzu.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Direkt nach main , aber vor dem Ende des body , fügen Sie ein neues Skript predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Speichern und schließen. Öffnen scripts/predict.js .
nano scripts/predict.jsImportieren Sie die erforderlichen NodeJS-Dienstprogramme für das Dateisystem, die Dienstprogramme und den untergeordneten Prozess-Spawner.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Definieren Sie eine predict , die einen separaten Knotenprozess aufruft, um WLAN-Netzwerke zu erkennen, und einen separaten Python-Prozess, um den Raum vorherzusagen.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Nachdem beide Prozesse erzeugt wurden, fügen Sie Callbacks für Erfolge und Fehler zum Python-Prozess hinzu. Der Erfolgs-Callback protokolliert Informationen, ruft den Abschluss-Callback auf und aktualisiert die UI mit der Vorhersage und dem Vertrauen. Der Fehlerrückruf protokolliert den Fehler.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Definieren Sie eine Hauptfunktion, um die predict für immer rekursiv aufzurufen.
function main() { f = function() { predict(f) } predict(f) } main();Öffnen Sie ein letztes Mal die Desktop-App, um die Live-Vorhersage anzuzeigen.
npm startUngefähr jede Sekunde wird ein Scan durchgeführt und die Benutzeroberfläche wird mit dem neuesten Vertrauen und vorhergesagten Raum aktualisiert. Glückwünsche; Sie haben einen einfachen Raummelder fertiggestellt, der auf allen WLAN-Netzwerken in Reichweite basiert.
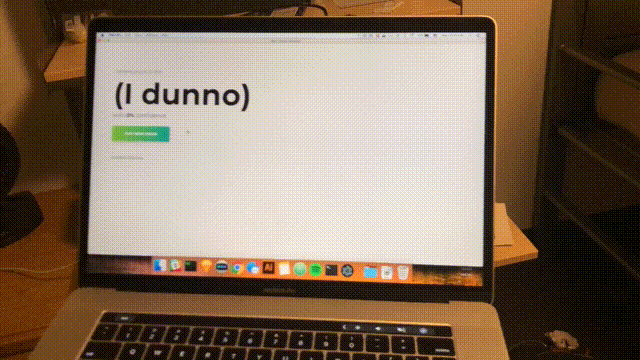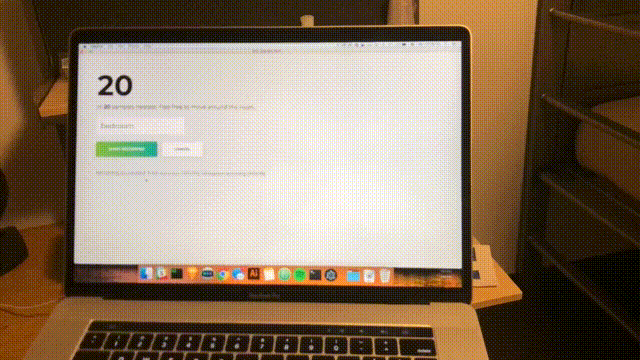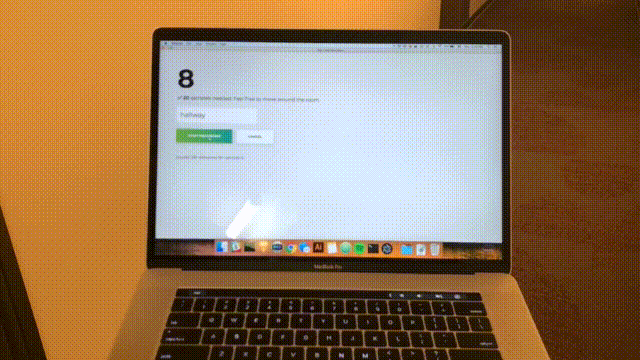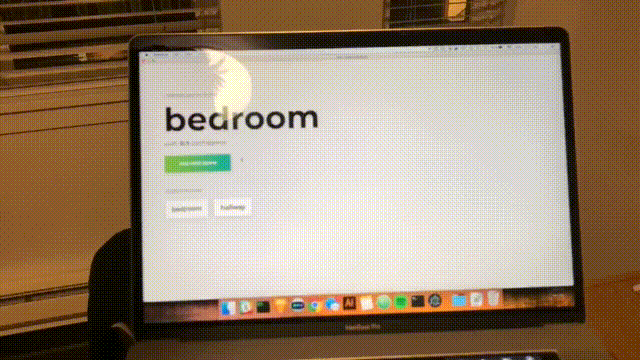
Fazit
In diesem Tutorial haben wir eine Lösung erstellt, die nur Ihren Desktop verwendet, um Ihren Standort innerhalb eines Gebäudes zu erkennen. Wir haben eine einfache Desktop-App mit Electron JS erstellt und eine einfache maschinelle Lernmethode auf alle WLAN-Netzwerke in Reichweite angewendet. Dies ebnet den Weg für Internet-of-Things-Anwendungen ohne die Notwendigkeit von Arrays von Geräten, deren Wartung kostspielig ist (Kosten nicht in Form von Geld, sondern in Bezug auf Zeit und Entwicklung).
Hinweis : Sie können den gesamten Quellcode auf Github einsehen.
Mit der Zeit stellen Sie vielleicht fest, dass diese Methode der kleinsten Quadrate tatsächlich keine spektakuläre Leistung erbringt. Versuchen Sie, zwei Orte in einem einzigen Raum zu finden, oder stellen Sie sich in Türen. Kleinste Quadrate sind groß und können nicht zwischen Randfällen unterscheiden. Können wir es besser machen? Es stellt sich heraus, dass wir dies können, und in zukünftigen Lektionen werden wir andere Techniken und die Grundlagen des maschinellen Lernens nutzen, um eine bessere Leistung zu erzielen. Dieses Tutorial dient als schnelle Testumgebung für kommende Experimente.