
Aufbau eines zentralen Protokollierungsdienstes im eigenen Haus
Veröffentlicht: 2022-03-10Wir alle wissen, wie wichtig Debugging für die Verbesserung der Anwendungsleistung und -funktionen ist. BrowserStack führt täglich eine Million Sitzungen auf einem stark verteilten Anwendungsstapel aus! Jede beinhaltet mehrere bewegliche Teile, da eine einzelne Sitzung eines Kunden mehrere Komponenten über mehrere geografische Regionen hinweg umfassen kann.
Ohne das richtige Framework und die richtigen Tools kann der Debugging-Prozess ein Alptraum sein. In unserem Fall brauchten wir eine Möglichkeit, Ereignisse zu sammeln, die in verschiedenen Phasen jedes Prozesses stattfanden, um ein tiefes Verständnis von allem zu bekommen, was während einer Sitzung passiert. Mit unserer Infrastruktur wurde die Lösung dieses Problems kompliziert, da jede Komponente möglicherweise mehrere Ereignisse aus ihrem Lebenszyklus der Verarbeitung einer Anfrage hat.
Aus diesem Grund haben wir unser eigenes internes Central Logging Service Tool (CLS) entwickelt, um alle wichtigen Ereignisse aufzuzeichnen, die während einer Sitzung protokolliert werden. Diese Ereignisse helfen unseren Entwicklern, Bedingungen zu identifizieren, bei denen in einer Sitzung etwas schief geht, und helfen dabei, bestimmte wichtige Produktmetriken im Auge zu behalten.
Das Debuggen von Daten reicht von einfachen Dingen wie der API-Antwortlatenz bis hin zur Überwachung des Netzwerkzustands eines Benutzers. In diesem Artikel teilen wir unsere Geschichte des Aufbaus unseres CLS-Tools, das 70 GB relevanter chronologischer Daten pro Tag von über 100 Komponenten zuverlässig, in großem Maßstab und mit zwei M3.large EC2-Instances sammelt.
Die Entscheidung zum Eigenbau
Lassen Sie uns zunächst überlegen, warum wir unser CLS-Tool intern erstellt haben, anstatt eine vorhandene Lösung zu verwenden. Jede unserer Sitzungen sendet durchschnittlich 15 Ereignisse von mehreren Komponenten an den Dienst – was ungefähr 15 Millionen Ereignissen pro Tag entspricht.
Unser Dienst benötigte die Möglichkeit, all diese Daten zu speichern. Wir haben nach einer Komplettlösung gesucht, um das Speichern, Senden und Abfragen von Ereignissen über Ereignisse hinweg zu unterstützen. Da wir Lösungen von Drittanbietern wie Amplitude und Keen in Betracht gezogen haben, umfassten unsere Bewertungsmetriken Kosten, Leistung bei der Verarbeitung vieler paralleler Anfragen und einfache Einführung. Leider konnten wir keine Lösung finden, die alle unsere Anforderungen im Rahmen des Budgets erfüllte – obwohl die Vorteile darin bestanden hätten, Zeit zu sparen und Warnmeldungen zu minimieren. Obwohl dies zusätzlichen Aufwand erfordern würde, haben wir uns entschieden, selbst eine Inhouse-Lösung zu entwickeln.

Technische Details
In Bezug auf die Architektur unserer Komponente haben wir die folgenden grundlegenden Anforderungen skizziert:
- Kundenleistung
Beeinflusst nicht die Leistung des Clients/der Komponente, die die Ereignisse sendet. - Skala
Kann eine große Anzahl von Anfragen parallel bearbeiten. - Serviceleistung
Schnelle Verarbeitung aller an ihn gesendeten Ereignisse. - Einblick in Daten
Jedes protokollierte Ereignis muss über einige Metainformationen verfügen, um die Komponente oder den Benutzer, das Konto oder die Nachricht eindeutig identifizieren zu können und weitere Informationen bereitzustellen, die dem Entwickler helfen, schneller zu debuggen. - Abfragebare Schnittstelle
Entwickler können alle Ereignisse für eine bestimmte Sitzung abfragen und dabei helfen, eine bestimmte Sitzung zu debuggen, Berichte zum Komponentenzustand zu erstellen oder aussagekräftige Leistungsstatistiken unserer Systeme zu generieren. - Schnellere und einfachere Annahme
Einfache Integration mit einer bestehenden oder neuen Komponente, ohne Teams zu belasten und ihre Ressourcen zu beanspruchen. - Geringer Wartungsaufwand
Wir sind ein kleines Ingenieurteam, also haben wir nach einer Lösung gesucht, um Warnungen zu minimieren!
Aufbau unserer CLS-Lösung
Entscheidung 1: Auswählen einer offenzulegenden Schnittstelle
Bei der Entwicklung von CLS wollten wir natürlich keine unserer Daten verlieren, aber wir wollten auch nicht, dass die Komponentenleistung darunter leidet. Ganz zu schweigen von dem zusätzlichen Faktor, der verhindert, dass vorhandene Komponenten komplizierter werden, da dies die allgemeine Einführung und Veröffentlichung verzögern würde. Bei der Bestimmung unserer Schnittstelle haben wir die folgenden Optionen in Betracht gezogen:
- Speichern von Ereignissen in lokalen Redis in jeder Komponente, während ein Hintergrundprozessor sie an CLS weiterleitet. Dies erfordert jedoch eine Änderung aller Komponenten sowie eine Einführung von Redis für Komponenten, die es noch nicht enthielten.
- Ein Publisher-Subscriber-Modell, bei dem Redis näher am CLS liegt. Da jeder Veranstaltungen veröffentlicht, haben wir wieder den Faktor, dass Komponenten auf der ganzen Welt laufen. Während der Zeit mit hohem Verkehrsaufkommen würde dies Komponenten verzögern. Darüber hinaus konnte dieser Schreibvorgang zeitweise bis zu fünf Sekunden springen (allein aufgrund des Internets).
- Senden von Ereignissen über UDP, was sich weniger auf die Anwendungsleistung auswirkt. In diesem Fall würden Daten verschickt und vergessen, der Nachteil hier wäre jedoch Datenverlust.
Interessanterweise betrug unser Datenverlust über UDP weniger als 0,1 Prozent, was für uns ein akzeptabler Wert war, um den Aufbau eines solchen Dienstes in Erwägung zu ziehen. Wir konnten alle Teams davon überzeugen, dass dieser Verlust die Leistung wert war, und setzten eine UDP-Schnittstelle ein, die auf alle gesendeten Ereignisse lauschte.
Während ein Ergebnis eine geringere Auswirkung auf die Leistung einer Anwendung war, hatten wir ein Problem, da UDP-Verkehr nicht von allen Netzwerken zugelassen wurde, hauptsächlich von unseren Benutzern, was dazu führte, dass wir in einigen Fällen überhaupt keine Daten erhielten. Als Problemumgehung haben wir die Protokollierung von Ereignissen mithilfe von HTTP-Anforderungen unterstützt. Alle Ereignisse, die von der Benutzerseite kommen, würden über HTTP gesendet, während alle Ereignisse, die von unseren Komponenten aufgezeichnet werden, über UDP gesendet würden.
Entscheidung 2: Tech Stack (Sprache, Framework & Speicher)
Wir sind ein Ruby-Shop. Wir waren uns jedoch nicht sicher, ob Ruby für unser spezielles Problem die bessere Wahl wäre. Unser Dienst müsste viele eingehende Anfragen verarbeiten und viele Schreibvorgänge verarbeiten. Mit der Global Interpreter-Sperre wäre es in Ruby schwierig, Multithreading oder Parallelität zu erreichen (bitte nehmen Sie es nicht übel – wir lieben Ruby!). Also brauchten wir eine Lösung, die uns dabei helfen würde, diese Art von Parallelität zu erreichen.
Wir wollten auch unbedingt eine neue Sprache in unserem Tech-Stack evaluieren, und dieses Projekt schien perfekt, um mit neuen Dingen zu experimentieren. An diesem Punkt entschieden wir uns, Golang eine Chance zu geben, da es integrierte Unterstützung für Nebenläufigkeit und leichtgewichtige Threads und Go-Routinen bot. Jeder protokollierte Datenpunkt ähnelt einem Schlüssel-Wert-Paar, wobei „Schlüssel“ das Ereignis ist und „Wert“ als zugehöriger Wert dient.
Aber ein einfacher Schlüssel und ein einfacher Wert reichen nicht aus, um sitzungsbezogene Daten abzurufen – es gibt mehr Metadaten dazu. Um dies zu beheben, haben wir entschieden, dass jedes Ereignis, das protokolliert werden muss, eine Sitzungs-ID zusammen mit seinem Schlüssel und Wert haben würde. Wir haben auch zusätzliche Felder wie Zeitstempel, Benutzer-ID und die Komponente, die die Daten protokolliert, hinzugefügt, sodass das Abrufen und Analysieren von Daten einfacher wurde.

Nachdem wir uns nun für unsere Payload-Struktur entschieden hatten, mussten wir unseren Datenspeicher auswählen. Wir haben Elastic Search in Betracht gezogen, wollten aber auch Aktualisierungsanfragen für Schlüssel unterstützen. Dies würde eine Neuindizierung des gesamten Dokuments auslösen, was sich auf die Leistung unserer Schreibvorgänge auswirken könnte. MongoDB war als Datenspeicher sinnvoller, da es einfacher wäre, alle Ereignisse basierend auf einem der hinzugefügten Datenfelder abzufragen. Das war einfach!
Entscheidung 3: DB-Größe ist riesig und Abfragen und Archivierung sind scheiße!
Um den Wartungsaufwand zu reduzieren, müsste unser Service so viele Ereignisse wie möglich bewältigen. Angesichts der Geschwindigkeit, mit der BrowserStack Funktionen und Produkte veröffentlicht, waren wir uns sicher, dass die Anzahl unserer Ereignisse im Laufe der Zeit schneller zunehmen würde, was bedeutet, dass unser Service weiterhin gut funktionieren muss. Mit zunehmendem Speicherplatz nehmen Lese- und Schreibvorgänge mehr Zeit in Anspruch – was sich stark auf die Leistung des Dienstes auswirken könnte.
Die erste Lösung, die wir untersucht haben, war das Verschieben von Protokollen aus einem bestimmten Zeitraum aus der Datenbank (in unserem Fall haben wir uns für 15 Tage entschieden). Dazu haben wir für jeden Tag eine andere Datenbank erstellt, die es uns ermöglicht, Protokolle zu finden, die älter als ein bestimmter Zeitraum sind, ohne alle schriftlichen Dokumente scannen zu müssen. Jetzt entfernen wir kontinuierlich Datenbanken, die älter als 15 Tage sind, aus Mongo und bewahren natürlich Backups für alle Fälle auf.
Übrig blieb lediglich eine Entwicklerschnittstelle zur Abfrage sitzungsbezogener Daten. Ehrlich gesagt war dies das am einfachsten zu lösende Problem. Wir stellen eine HTTP-Schnittstelle bereit, über die Personen nach sitzungsbezogenen Ereignissen in der entsprechenden Datenbank in der MongoDB nach allen Daten mit einer bestimmten Sitzungs-ID fragen können.
Die Architektur
Lassen Sie uns über die internen Komponenten des Dienstes sprechen und dabei die folgenden Punkte berücksichtigen:
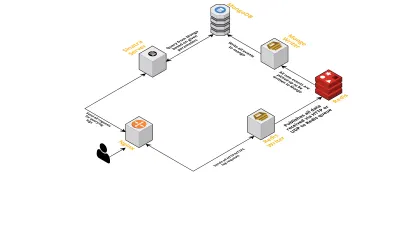
- Wie bereits erwähnt, brauchten wir zwei Schnittstellen – eine, die über UDP lauscht, und eine andere, die über HTTP lauscht. Also haben wir zwei Server gebaut, wiederum einen für jede Schnittstelle, um auf Ereignisse zu lauschen. Sobald ein Ereignis eintrifft, analysieren wir es, um zu prüfen, ob es die erforderlichen Felder enthält – dies sind Sitzungs-ID, Schlüssel und Wert. Wenn dies nicht der Fall ist, werden die Daten gelöscht. Andernfalls werden die Daten über einen Go-Kanal an eine andere Goroutine übergeben, deren einzige Verantwortung darin besteht, in die MongoDB zu schreiben.
- Ein mögliches Anliegen ist hier das Schreiben in die MongoDB. Wenn Schreibvorgänge in die MongoDB langsamer sind als die Rate, mit der Daten empfangen werden, entsteht ein Engpass. Dies wiederum verhungert andere eingehende Ereignisse und bedeutet verlorene Daten. Der Server sollte daher eingehende Protokolle schnell verarbeiten und bereit sein, kommende zu verarbeiten. Um das Problem anzugehen, haben wir den Server in zwei Teile geteilt: Der erste empfängt alle Ereignisse und stellt sie für den zweiten in die Warteschlange, der sie verarbeitet und in die MongoDB schreibt.
- Für die Warteschlange haben wir uns für Redis entschieden. Indem wir die gesamte Komponente in diese beiden Teile aufgeteilt haben, haben wir die Arbeitslast des Servers reduziert und ihm Platz für die Verarbeitung von mehr Protokollen gegeben.
- Wir haben einen kleinen Dienst geschrieben, der den Sinatra-Server verwendet, um die gesamte Arbeit der Abfrage von MongoDB mit den angegebenen Parametern zu erledigen. Es gibt eine HTML/JSON-Antwort an Entwickler zurück, wenn sie Informationen zu einer bestimmten Sitzung benötigen.
Alle diese Prozesse laufen problemlos auf einer einzigen m3.large- Instanz.
Funktionsanfragen
Da unser CLS-Tool im Laufe der Zeit immer häufiger verwendet wurde, benötigte es mehr Funktionen. Im Folgenden besprechen wir diese und wie sie hinzugefügt wurden.
Fehlende Metadaten
Da die Anzahl der Komponenten in BrowserStack allmählich zunimmt, haben wir mehr von CLS verlangt. Beispielsweise benötigten wir die Möglichkeit, Ereignisse von Komponenten ohne Sitzungs-ID zu protokollieren. Andernfalls würde die Beschaffung unserer Infrastruktur unsere Infrastruktur belasten, indem die Anwendungsleistung beeinträchtigt und Datenverkehr auf unseren Hauptservern verursacht wird.
Wir haben dies behoben, indem wir die Ereignisprotokollierung mit anderen Schlüsseln wie Terminal- und Benutzer-IDs aktiviert haben. Jetzt wird CLS immer dann, wenn eine Sitzung erstellt oder aktualisiert wird, mit der Sitzungs-ID sowie den jeweiligen Benutzer- und Endgeräte-IDs informiert. Es speichert eine Karte, die durch Schreiben in MongoDB abgerufen werden kann. Immer wenn ein Ereignis abgerufen wird, das entweder die Benutzer- oder die Terminal-ID enthält, wird die Sitzungs-ID hinzugefügt.
Spamming behandeln (Codeprobleme in anderen Komponenten)
CLS hatte auch mit den üblichen Schwierigkeiten bei der Handhabung von Spam-Ereignissen zu kämpfen. Wir haben häufig Deployments in Komponenten gefunden, die eine große Menge an Anfragen generiert haben, die an CLS gesendet wurden. Andere Protokolle würden darunter leiden, da der Server zu beschäftigt wurde, um diese zu verarbeiten, und wichtige Protokolle verworfen wurden.
Zum größten Teil wurden die meisten Daten über HTTP-Anfragen protokolliert. Um sie zu kontrollieren, aktivieren wir die Ratenbegrenzung auf nginx (mithilfe des Moduls limit_req_zone), das Anfragen von allen IPs blockiert, die wir gefunden haben, die Anfragen mit mehr als einer bestimmten Anzahl in kurzer Zeit treffen. Natürlich nutzen wir Zustandsberichte zu allen blockierten IPs und informieren die zuständigen Teams.
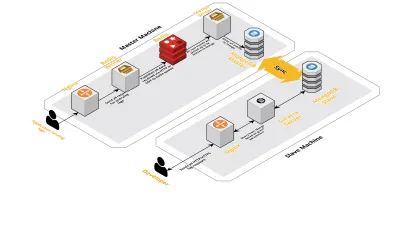
Skala v2
Als unsere Sitzungen pro Tag zunahmen, stiegen auch die Daten, die in CLS protokolliert wurden. Dies wirkte sich auf die Abfragen aus, die unsere Entwickler täglich ausführten, und bald lag der Engpass bei der Maschine selbst. Unser Setup bestand aus zwei Kernmaschinen, auf denen alle oben genannten Komponenten ausgeführt wurden, zusammen mit einer Reihe von Skripten, um Mongo abzufragen und die wichtigsten Metriken für jedes Produkt zu verfolgen. Im Laufe der Zeit waren die Daten auf der Maschine stark angestiegen und Skripte begannen, viel CPU-Zeit zu beanspruchen. Auch nach dem Versuch, Mongo-Abfragen zu optimieren, sind wir immer wieder auf die gleichen Probleme gestoßen.
Um dies zu lösen, haben wir einen weiteren Computer zum Ausführen von Zustandsberichtsskripten und die Schnittstelle zum Abfragen dieser Sitzungen hinzugefügt. Der Prozess umfasste das Booten einer neuen Maschine und das Einrichten eines Slaves des Mongo, der auf der Hauptmaschine läuft. Dies hat dazu beigetragen, die CPU-Spitzen zu reduzieren, die wir jeden Tag durch diese Skripte verursacht sehen.
Fazit
Das Erstellen eines Dienstes für eine so einfache Aufgabe wie die Datenprotokollierung kann mit zunehmender Datenmenge kompliziert werden. In diesem Artikel werden die von uns untersuchten Lösungen sowie die Herausforderungen bei der Lösung dieses Problems erörtert. Wir haben mit Golang experimentiert, um zu sehen, wie gut es in unser Ökosystem passt, und bisher waren wir zufrieden. Unsere Entscheidung, einen internen Service zu schaffen, anstatt für einen externen zu bezahlen, war wunderbar kosteneffizient. Wir mussten unser Setup auch erst viel später auf eine andere Maschine skalieren – als das Volumen unserer Sitzungen zunahm. Natürlich basierten unsere Entscheidungen bei der Entwicklung von CLS vollständig auf unseren Anforderungen und Prioritäten.
Heute verarbeitet CLS täglich bis zu 15 Millionen Ereignisse, die bis zu 70 GB an Daten ausmachen. Diese Daten werden verwendet, um uns bei der Lösung von Problemen zu helfen, mit denen unsere Kunden während einer Sitzung konfrontiert sind. Wir verwenden diese Daten auch für andere Zwecke. Angesichts der Einblicke, die die Daten jeder Sitzung zu verschiedenen Produkten und internen Komponenten bieten, haben wir begonnen, diese Daten zu nutzen, um jedes Produkt im Auge zu behalten. Dies wird erreicht, indem die Schlüsselmetriken für alle wichtigen Komponenten extrahiert werden.
Alles in allem haben wir großen Erfolg beim Aufbau unseres eigenen CLS-Tools gesehen. Wenn es für Sie sinnvoll ist, empfehle ich Ihnen, dasselbe zu tun!