
So erstellen Sie einen Amazon Product Scraper mit Node.js
Veröffentlicht: 2022-03-10Waren Sie jemals in einer Position, in der Sie den Markt für ein bestimmtes Produkt genau kennen mussten? Vielleicht bringen Sie eine Software auf den Markt und müssen wissen, wie Sie den Preis festlegen. Oder vielleicht haben Sie bereits Ihr eigenes Produkt auf dem Markt und möchten sehen, welche Funktionen Sie für einen Wettbewerbsvorteil hinzufügen können. Oder vielleicht möchten Sie einfach nur etwas für sich selbst kaufen und sicherstellen, dass Sie das Beste für Ihr Geld bekommen.
All diese Situationen haben eines gemeinsam: Sie benötigen genaue Daten, um die richtige Entscheidung zu treffen . Eigentlich haben sie noch etwas gemeinsam. Alle Szenarien können vom Einsatz eines Web Scrapers profitieren.
Web Scraping ist die Praxis, große Mengen von Webdaten durch die Verwendung von Software zu extrahieren. Im Wesentlichen ist es also eine Möglichkeit, den mühsamen Prozess zu automatisieren, 200 Mal auf „Kopieren“ und dann „Einfügen“ zu klicken. Natürlich kann ein Bot das in der Zeit erledigen, die Sie zum Lesen dieses Satzes benötigt haben, also ist es nicht nur weniger langweilig, sondern auch viel schneller.
Aber die brennende Frage ist: Warum sollte jemand Amazon-Seiten schaben wollen?
Du wirst es gleich herausfinden! Aber zunächst einmal möchte ich etwas klarstellen – während das Scraping öffentlich zugänglicher Daten legal ist, hat Amazon auf seinen Seiten einige Maßnahmen, um dies zu verhindern. Daher fordere ich Sie auf, beim Scrapen immer auf die Website zu achten, darauf zu achten, sie nicht zu beschädigen, und ethische Richtlinien zu befolgen.
Leseempfehlung : „The Guide To Ethical Scraping of Dynamic Websites With Node.js And Puppeteer“ von Andreas Altheimer
Warum Sie Amazon-Produktdaten extrahieren sollten
Als größter Online-Händler der Welt kann man mit Sicherheit sagen, dass Sie, wenn Sie etwas kaufen möchten, es wahrscheinlich bei Amazon bekommen können. Es versteht sich also von selbst, wie groß der Datenschatz der Website ist.
Wenn Sie das Internet durchsuchen, sollte Ihre primäre Frage sein, was Sie mit all diesen Daten tun sollen. Obwohl es viele individuelle Gründe gibt, läuft es auf zwei herausragende Anwendungsfälle hinaus: die Optimierung Ihrer Produkte und die Suche nach den besten Angeboten.
„
Beginnen wir mit dem ersten Szenario. Sofern Sie kein wirklich innovatives neues Produkt entwickelt haben, stehen die Chancen gut, dass Sie bei Amazon bereits etwas Ähnliches finden. Das Scrapen dieser Produktseiten kann Ihnen unschätzbare Daten einbringen, wie zum Beispiel:
- Die Preisstrategie der Wettbewerber
Damit Sie Ihre Preise anpassen können, um wettbewerbsfähig zu sein, und verstehen können, wie andere Werbeangebote handhaben; - Kundenmeinungen
Um zu sehen, was Ihrem zukünftigen Kundenstamm am wichtigsten ist und wie Sie seine Erfahrung verbessern können; - Die häufigsten Merkmale
Um zu sehen, was Ihre Konkurrenz anbietet, um zu wissen, welche Funktionalitäten entscheidend sind und welche später aufgehoben werden können.
Im Wesentlichen bietet Amazon alles, was Sie für eine tiefgreifende Markt- und Produktanalyse benötigen. Mit diesen Daten sind Sie besser darauf vorbereitet, Ihre Produktpalette zu entwerfen, auf den Markt zu bringen und zu erweitern.
Das zweite Szenario kann sowohl für Unternehmen als auch für normale Personen gelten. Die Idee ist ziemlich ähnlich zu dem, was ich zuvor erwähnt habe. Sie können die Preise, Funktionen und Bewertungen aller Produkte, die Sie auswählen können, zusammenkratzen und so dasjenige auswählen, das die meisten Vorteile zum niedrigsten Preis bietet. Denn wer mag kein gutes Geschäft?
Nicht alle Produkte verdienen dieses Maß an Liebe zum Detail, aber bei teuren Anschaffungen kann es einen großen Unterschied machen. Obwohl die Vorteile klar sind, gehen leider viele Schwierigkeiten mit dem Scraping von Amazon einher.
Die Herausforderungen beim Scraping von Amazon-Produktdaten
Nicht alle Webseiten sind gleich. Als Faustregel gilt: Je komplexer und verbreiteter eine Website ist, desto schwieriger ist es, sie zu schaben. Erinnern Sie sich, als ich sagte, dass Amazon die prominenteste E-Commerce-Website war? Nun, das macht es sowohl äußerst beliebt als auch einigermaßen komplex.
Zunächst einmal weiß Amazon, wie sich Scraping-Bots verhalten, sodass die Website Gegenmaßnahmen ergriffen hat. Wenn nämlich der Scraper einem vorhersehbaren Muster folgt und Anfragen in festen Intervallen sendet, schneller als ein Mensch es könnte oder mit fast identischen Parametern, wird Amazon die IP bemerken und blockieren. Proxys können dieses Problem lösen, aber ich habe sie nicht benötigt, da wir in dem Beispiel nicht zu viele Seiten schaben werden.
Als nächstes verwendet Amazon bewusst unterschiedliche Seitenstrukturen für seine Produkte. Das heißt, wenn Sie die Seiten auf verschiedene Produkte untersuchen, besteht eine gute Chance, dass Sie erhebliche Unterschiede in ihrer Struktur und ihren Eigenschaften finden. Der Grund dafür ist ganz einfach. Sie müssen den Code Ihres Scrapers für ein bestimmtes System anpassen , und wenn Sie dasselbe Skript auf einer neuen Art von Seite verwenden, müssen Sie Teile davon neu schreiben. Sie lassen Sie also im Wesentlichen mehr für die Daten arbeiten.
Schließlich ist Amazon eine riesige Website. Wenn Sie große Datenmengen sammeln möchten, kann sich herausstellen, dass das Ausführen der Scraping-Software auf Ihrem Computer viel zu viel Zeit für Ihre Anforderungen in Anspruch nimmt. Dieses Problem wird durch die Tatsache weiter gefestigt, dass Ihr Abstreifer blockiert wird, wenn Sie zu schnell fahren. Wenn Sie also schnell eine Menge Daten haben möchten, benötigen Sie einen wirklich leistungsstarken Scraper.
Nun, genug über Probleme geredet, konzentrieren wir uns auf Lösungen!
So bauen Sie einen Web Scraper für Amazon
Um die Dinge einfach zu halten, gehen wir beim Schreiben des Codes Schritt für Schritt vor. Fühlen Sie sich frei, parallel mit dem Leitfaden zu arbeiten.
Suchen Sie nach den Daten, die wir benötigen
Also, hier ist ein Szenario: Ich ziehe in ein paar Monaten an einen neuen Ort und brauche ein paar neue Regale für Bücher und Zeitschriften. Ich möchte alle meine Optionen kennen und ein möglichst gutes Angebot machen. Gehen wir also zum Amazon-Markt, suchen nach „Regalen“ und sehen, was wir bekommen.
Die URL für diese Suche und die Seite, die wir kratzen werden, ist hier.
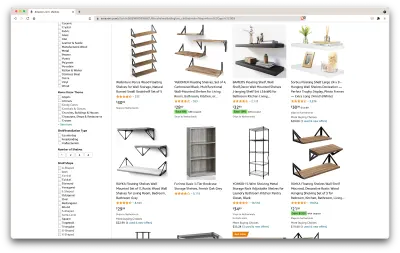
Ok, lasst uns eine Bestandsaufnahme dessen machen, was wir hier haben. Schon durch einen Blick auf die Seite können wir uns ein gutes Bild machen über:
- wie die Regale aussehen;
- was das Paket beinhaltet;
- wie Kunden sie bewerten;
- ihr Preis;
- der Link zum Produkt;
- ein Vorschlag für eine günstigere Alternative für einige der Artikel.
Das ist mehr, als wir verlangen könnten!
Holen Sie sich die erforderlichen Werkzeuge
Stellen Sie sicher, dass alle folgenden Tools installiert und konfiguriert sind, bevor Sie mit dem nächsten Schritt fortfahren.
- Chrom
Wir können es hier herunterladen. - VSCode
Befolgen Sie die Anweisungen auf dieser Seite, um es auf Ihrem spezifischen Gerät zu installieren. - Node.js
Bevor wir Axios oder Cheerio verwenden, müssen wir Node.js und den Node Package Manager installieren. Der einfachste Weg, Node.js und NPM zu installieren, besteht darin, eines der Installationsprogramme aus der offiziellen Quelle von Node.Js zu beziehen und es auszuführen.
Lassen Sie uns nun ein neues NPM-Projekt erstellen. Erstellen Sie einen neuen Ordner für das Projekt und führen Sie den folgenden Befehl aus:
npm init -yUm den Web Scraper zu erstellen, müssen wir einige Abhängigkeiten in unserem Projekt installieren:
- Tschüss
Eine Open-Source-Bibliothek, die uns hilft, nützliche Informationen zu extrahieren, indem sie Markup analysiert und eine API zur Bearbeitung der resultierenden Daten bereitstellt. Cheerio ermöglicht es uns, Tags eines HTML-Dokuments auszuwählen, indem wir Selektoren verwenden:$("div"). Dieser spezielle Selektor hilft uns, alle<div>-Elemente auf einer Seite auszuwählen. Um Cheerio zu installieren, führen Sie bitte den folgenden Befehl im Projektordner aus:
npm install cheerio- Axios
Eine JavaScript-Bibliothek, die verwendet wird, um HTTP-Anforderungen von Node.js zu stellen.
npm install axiosÜberprüfen Sie die Seitenquelle
In den folgenden Schritten erfahren wir mehr darüber, wie die Informationen auf der Seite organisiert sind. Die Idee ist, ein besseres Verständnis dafür zu bekommen, was wir aus unserer Quelle schöpfen können.
Die Entwicklertools helfen uns dabei, das Document Object Model (DOM) der Website interaktiv zu erkunden. Wir verwenden die Entwicklertools in Chrome, aber Sie können jeden beliebigen Webbrowser verwenden, mit dem Sie vertraut sind.
Lassen Sie uns es öffnen, indem Sie mit der rechten Maustaste auf eine beliebige Stelle auf der Seite klicken und die Option „Inspizieren“ auswählen:
Dadurch wird ein neues Fenster geöffnet, das den Quellcode der Seite enthält. Wie wir bereits gesagt haben, versuchen wir, die Informationen jedes Regals zu kratzen.
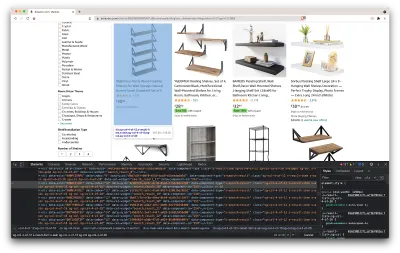
Wie wir auf dem obigen Screenshot sehen können, haben die Container, die alle Daten enthalten, die folgenden Klassen:

sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20Im nächsten Schritt wählen wir mit Cheerio alle Elemente aus, die die benötigten Daten enthalten.
Holen Sie sich die Daten
Nachdem wir alle oben aufgeführten Abhängigkeiten installiert haben, erstellen wir eine neue index.js -Datei und geben die folgenden Codezeilen ein:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Wie wir sehen können, importieren wir die benötigten Abhängigkeiten in den ersten beiden Zeilen und erstellen dann eine fetchShelves() Funktion, die mithilfe von Cheerio alle Elemente mit den Informationen zu unseren Produkten von der Seite abruft.
Es iteriert über jeden von ihnen und schiebt es in ein leeres Array, um ein besser formatiertes Ergebnis zu erhalten.
Die Funktion fetchShelves() gibt im Moment nur den Titel des Produkts zurück, also holen wir uns die restlichen Informationen, die wir brauchen. Bitte fügen Sie die folgenden Codezeilen nach der Zeile hinzu, in der wir die Variable title definiert haben.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } Ersetzen shelves.push(title) durch shelves.push(element) .
Wir wählen jetzt alle benötigten Informationen aus und fügen sie einem neuen Objekt namens element hinzu. Jedes Element wird dann in das shelves -Array verschoben, um eine Liste von Objekten zu erhalten, die genau die Daten enthält, nach denen wir suchen.
So sollte ein shelf aussehen, bevor es unserer Liste hinzugefügt wird:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Formatieren Sie die Daten
Nachdem wir die benötigten Daten abgerufen haben, ist es eine gute Idee, sie als .CSV -Datei zu speichern, um die Lesbarkeit zu verbessern. Nachdem wir alle Daten erhalten haben, verwenden wir das von Node.js bereitgestellte fs -Modul und speichern eine neue Datei namens saved-shelves.csv im Ordner des Projekts. Importieren Sie das fs -Modul am Anfang der Datei und kopieren oder schreiben Sie entlang der folgenden Codezeilen:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Wie wir sehen können, formatieren wir in den ersten drei Zeilen die zuvor gesammelten Daten, indem wir alle Werte eines Regalobjekts mit einem Komma verbinden. Dann erstellen wir mit dem fs -Modul eine Datei namens saved-shelves.csv , fügen eine neue Zeile hinzu, die die Spaltenüberschriften enthält, fügen die Daten hinzu, die wir gerade formatiert haben, und erstellen eine Callback-Funktion, die die Fehler behandelt.
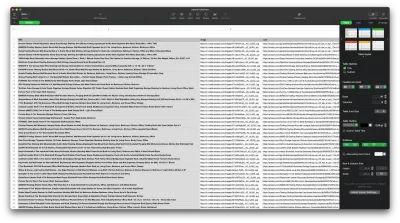
Das Ergebnis sollte in etwa so aussehen:
Bonus-Tipps!
Scraping von Einzelseitenanwendungen
Dynamische Inhalte werden heutzutage zum Standard, da Websites komplexer sind als je zuvor. Um die bestmögliche Benutzererfahrung zu bieten, müssen Entwickler unterschiedliche Lademechanismen für dynamische Inhalte anwenden , was unsere Arbeit etwas komplizierter macht. Wenn Sie nicht wissen, was das bedeutet, stellen Sie sich einen Browser ohne grafische Benutzeroberfläche vor. Glücklicherweise gibt es Puppeteer – die magische Node-Bibliothek, die eine High-Level-API bereitstellt, um eine Chrome-Instanz über das DevTools-Protokoll zu steuern. Dennoch bietet es die gleiche Funktionalität wie ein Browser, aber es muss programmgesteuert gesteuert werden, indem ein paar Zeilen Code eingegeben werden. Mal sehen, wie das funktioniert.
Installieren Sie im zuvor erstellten Projekt die Puppeteer-Bibliothek, indem Sie npm install puppeteer , eine neue puppeteer.js -Datei erstellen und die folgenden Codezeilen kopieren oder schreiben:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() Im obigen Beispiel erstellen wir eine Chrome-Instanz und öffnen eine neue Browserseite, die erforderlich ist, um zu diesem Link zu gelangen. In der folgenden Zeile sagen wir dem Headless Browser, dass er warten soll, bis das Element mit der Klasse rpBJOHq2PR60pnwJlUyP0 auf der Seite erscheint. Außerdem haben wir angegeben, wie lange der Browser auf das Laden der Seite warten soll (2000 Millisekunden).
Mit der Methode „ evaluate “ in der page haben wir Puppeteer angewiesen, die Javascript-Schnipsel im Kontext der Seite auszuführen, unmittelbar nachdem das Element endgültig geladen wurde. Dadurch können wir auf den HTML-Inhalt der Seite zugreifen und den Hauptteil der Seite als Ausgabe zurückgeben. Anschließend schließen wir die Chrome-Instanz, indem wir die close -Methode für die chrome Variable aufrufen. Die resultierende Arbeit sollte aus dem gesamten dynamisch generierten HTML-Code bestehen. So kann uns Puppeteer helfen, dynamische HTML-Inhalte zu laden .
Wenn Sie sich mit Puppeteer nicht wohl fühlen, beachten Sie, dass es ein paar Alternativen gibt, wie NightwatchJS, NightmareJS oder CasperJS. Sie sind etwas anders, aber am Ende ist der Prozess ziemlich ähnlich.
user-agent Header setzen
user-agent ist ein Request-Header, der der Website, die Sie besuchen, Informationen über sich selbst mitteilt, nämlich Ihren Browser und Ihr Betriebssystem. Dies wird verwendet, um den Inhalt für Ihr Setup zu optimieren, aber Websites verwenden es auch, um Bots zu identifizieren, die Tonnen von Anfragen senden – selbst wenn es IPS ändert.
So sieht ein user-agent Header aus:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Um nicht entdeckt und blockiert zu werden, sollten Sie diesen Header regelmäßig ändern. Achten Sie besonders darauf, keinen leeren oder veralteten Header zu senden, da dies für einen gewöhnlichen Benutzer niemals passieren sollte, und Sie werden auffallen.
Ratenbegrenzung
Web Scraper können Inhalte extrem schnell sammeln, aber Sie sollten es vermeiden, mit Höchstgeschwindigkeit zu arbeiten. Dafür gibt es zwei Gründe:
- Zu viele Anfragen in kurzer Zeit können den Server der Website verlangsamen oder sogar zum Erliegen bringen, was zu Problemen für den Eigentümer und andere Besucher führen kann. Es kann im Wesentlichen zu einem DoS-Angriff werden.
- Ohne rotierende Proxys ist es vergleichbar mit der lauten Ankündigung, dass Sie einen Bot verwenden, da kein Mensch Hunderte oder Tausende von Anfragen pro Sekunde senden würde.
Die Lösung besteht darin, eine Verzögerung zwischen Ihren Anfragen einzuführen, eine Praxis, die als „Ratenbegrenzung“ bezeichnet wird. ( Es ist auch ziemlich einfach zu implementieren! )
In dem oben bereitgestellten Puppeteer-Beispiel können wir vor dem Erstellen der body -Variablen die von Puppeteer bereitgestellte Methode waitForTimeout verwenden, um einige Sekunden zu warten, bevor wir eine weitere Anfrage stellen:
await page.waitForTimeout(3000); Wobei ms die Anzahl der Sekunden ist, die Sie warten möchten.
Wenn wir dasselbe für das Axios-Beispiel tun möchten, können wir ein Promise erstellen, das die Methode setTimeout() , um uns zu helfen, auf die gewünschte Anzahl von Millisekunden zu warten:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))Auf diese Weise können Sie vermeiden, zu viel Druck auf den Zielserver auszuüben, und auch einen menschlicheren Ansatz für das Web Scraping einführen.
Abschließende Gedanken
Und da haben Sie es, eine Schritt-für-Schritt-Anleitung zum Erstellen Ihres eigenen Web Scrapers für Amazon-Produktdaten! Aber denken Sie daran, dies war nur eine Situation. Wenn Sie eine andere Website scrapen möchten, müssen Sie einige Anpassungen vornehmen, um aussagekräftige Ergebnisse zu erhalten.
Verwandte Lektüre
Wenn Sie dennoch mehr Web Scraping in Aktion sehen möchten, haben wir hier nützliches Lesematerial für Sie:
- „Der ultimative Leitfaden für Web Scraping mit JavaScript und Node.Js“, Robert Sfichi
- „Erweitertes Node.JS Web Scraping mit Puppeteer“, Gabriel Cioci
- „Python Web Scraping: Der ultimative Leitfaden zum Erstellen Ihres Scrapers“, Raluca Penciuc