
Erstellen Sie eine Bookmarking-Anwendung mit FaunaDB, Netlify und 11ty
Veröffentlicht: 2022-03-10Die JAMstack-Revolution (JavaScript, APIs und Markup) ist in vollem Gange. Statische Websites sind sicher, schnell, zuverlässig und es macht Spaß, daran zu arbeiten. Das Herzstück des JAMstack sind Static Site Generators (SSGs), die Ihre Daten als Flatfiles speichern: Markdown, YAML, JSON, HTML und so weiter. Manchmal kann die Verwaltung von Daten auf diese Weise zu kompliziert sein. Manchmal brauchen wir noch eine Datenbank.
Vor diesem Hintergrund arbeiteten Netlify – ein statischer Site-Host und FaunaDB – eine serverlose Cloud-Datenbank – zusammen, um die Kombination beider Systeme zu vereinfachen.
Warum eine Bookmarking-Site?
Der JAMstack eignet sich hervorragend für viele professionelle Anwendungen, aber einer meiner Lieblingsaspekte dieser Technologie ist die niedrige Eintrittsbarriere für persönliche Tools und Projekte.
Es gibt viele gute Produkte auf dem Markt für die meisten Anwendungen, die mir einfallen könnten, aber keines wäre genau für mich geeignet. Keiner würde mir die volle Kontrolle über meine Inhalte geben. Keiner würde ohne Kosten kommen (monetär oder informativ).
Vor diesem Hintergrund können wir mithilfe von JAMstack-Methoden unsere eigenen Minidienste erstellen. In diesem Fall erstellen wir eine Website zum Speichern und Veröffentlichen aller interessanten Artikel, auf die ich bei meiner täglichen Technologielektüre stoße.
Ich verbringe viel Zeit damit, Artikel zu lesen, die auf Twitter geteilt wurden. Wenn mir eins gefällt, drücke ich auf das „Herz“-Symbol. Dann, innerhalb weniger Tage, ist es fast unmöglich, mit dem Zustrom neuer Favoriten zu finden. Ich möchte etwas bauen, das der Leichtigkeit des „Herzens“ so nahe kommt, das ich aber besitze und kontrolliere.
Wie machen wir das? Ich bin froh, dass du gefragt hast.
Sind Sie daran interessiert, den Code zu erhalten? Sie können es auf Github abrufen oder direkt von diesem Repository aus auf Netlify bereitstellen! Sehen Sie sich hier das fertige Produkt an.
Unsere Technologien
Hosting und serverlose Funktionen: Netlify
Für Hosting- und serverlose Funktionen verwenden wir Netlify. Als zusätzlichen Bonus verbindet sich Netlifys CLI – „Netlify Dev“ – mit der oben erwähnten neuen Zusammenarbeit automatisch mit FaunaDB und speichert unsere API-Schlüssel als Umgebungsvariablen.
Datenbank: FaunaDB
FaunaDB ist eine „serverlose“ NoSQL-Datenbank. Wir werden es verwenden, um unsere Lesezeichendaten zu speichern.
Statischer Site-Generator: 11ty
Ich bin ein großer Anhänger von HTML. Aus diesem Grund verwendet das Tutorial kein Front-End-JavaScript, um unsere Lesezeichen zu rendern. Stattdessen verwenden wir 11ty als statischen Site-Generator. 11ty verfügt über eine integrierte Datenfunktion, die das Abrufen von Daten aus einer API so einfach macht wie das Schreiben einiger kurzer JavaScript-Funktionen.
iOS-Verknüpfungen
Wir brauchen eine einfache Möglichkeit, Daten in unsere Datenbank zu posten. In diesem Fall verwenden wir die Shortcuts-App von iOS. Dies könnte auch in ein Android- oder Desktop-JavaScript-Lesezeichen umgewandelt werden.
Einrichten von FaunaDB über Netlify Dev
Unabhängig davon, ob Sie sich bereits für FaunaDB angemeldet haben oder ein neues Konto erstellen müssen, der einfachste Weg, eine Verbindung zwischen FaunaDB und Netlify herzustellen, ist über die CLI von Netlify: Netlify Dev. Die vollständigen Anweisungen von FaunaDB finden Sie hier oder folgen Sie unten.
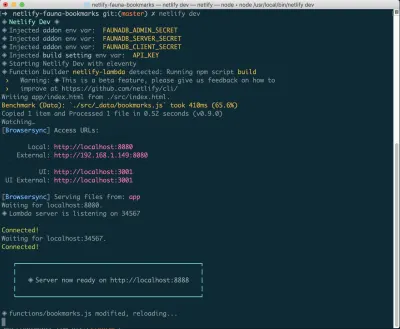
Wenn Sie dies noch nicht installiert haben, können Sie den folgenden Befehl im Terminal ausführen:
npm install netlify-cli -gFühren Sie in Ihrem Projektverzeichnis die folgenden Befehle aus:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Sobald dies alles verbunden ist, können Sie netlify dev in Ihrem Projekt ausführen. Dadurch werden alle von uns eingerichteten Build-Skripte ausgeführt, aber auch eine Verbindung zu den Netlify- und FaunaDB-Diensten hergestellt und alle erforderlichen Umgebungsvariablen abgerufen. Praktisch!
Erstellen unserer ersten Daten
Von hier aus melden wir uns bei FaunaDB an und erstellen unseren ersten Datensatz. Wir beginnen mit der Erstellung einer neuen Datenbank namens „Lesezeichen“. Innerhalb einer Datenbank haben wir Sammlungen, Dokumente und Indizes.
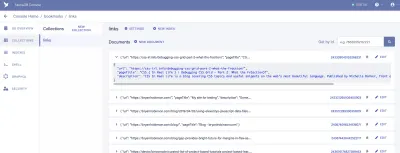
Eine Sammlung ist eine kategorisierte Gruppe von Daten. Jedes Datenelement hat die Form eines Dokuments. Laut Faunas Dokumentation ist ein Dokument ein „einzelner, veränderbarer Datensatz in einer FaunaDB-Datenbank“. Sie können sich Sammlungen als herkömmliche Datenbanktabelle und ein Dokument als Zeile vorstellen.
Für unsere Anwendung benötigen wir eine Sammlung, die wir „Links“ nennen. Jedes Dokument innerhalb der „Links“-Sammlung ist ein einfaches JSON-Objekt mit drei Eigenschaften. Zunächst fügen wir ein neues Dokument hinzu, mit dem wir unseren ersten Datenabruf erstellen.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Dies schafft die Grundlage für die Informationen, die wir aus unseren Lesezeichen ziehen müssen, und liefert uns unseren ersten Datensatz, den wir in unsere Vorlage ziehen können.
Wenn Sie wie ich sind, möchten Sie sofort die Früchte Ihrer Arbeit sehen. Lasst uns etwas auf die Seite bringen!
11ty installieren und Daten in eine Vorlage ziehen
Da wir möchten, dass die Lesezeichen in HTML gerendert und nicht vom Browser abgerufen werden, benötigen wir etwas zum Rendern. Es gibt viele großartige Möglichkeiten, dies zu tun, aber aus Gründen der Einfachheit und Leistungsfähigkeit verwende ich gerne den statischen Site-Generator von 11ty.
Da 11ty ein statischer JavaScript-Site-Generator ist, können wir ihn über NPM installieren.
npm install --save @11ty/eleventy Von dieser Installation aus können wir eleventy oder eleventy --serve in unserem Projekt ausführen, um es zum Laufen zu bringen.
Netlify Dev erkennt oft 11ty als Anforderung und führt den Befehl für uns aus. Um diese Arbeit zu erledigen und sicherzustellen, dass wir für die Bereitstellung bereit sind, können wir auch „serve“- und „build“-Befehle in unserer package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11tys Datendateien
Die meisten statischen Site-Generatoren haben die Idee einer eingebauten „Datendatei“. Normalerweise handelt es sich bei diesen Dateien um JSON- oder YAML-Dateien, mit denen Sie Ihrer Website zusätzliche Informationen hinzufügen können.
In 11ty können Sie JSON-Datendateien oder JavaScript-Datendateien verwenden. Durch die Verwendung einer JavaScript-Datei können wir unsere API-Aufrufe tatsächlich durchführen und die Daten direkt in eine Vorlage zurückgeben.
Standardmäßig möchte 11ty, dass Datendateien in einem _data Verzeichnis gespeichert werden. Sie können dann auf die Daten zugreifen, indem Sie den Dateinamen als Variable in Ihren Vorlagen verwenden. In unserem Fall erstellen wir eine Datei unter _data/bookmarks.js und greifen über den Variablennamen {{ bookmarks }} darauf zu.
Wenn Sie sich eingehender mit der Konfiguration von Datendateien befassen möchten, können Sie sich Beispiele in der 11ty-Dokumentation durchlesen oder sich dieses Tutorial zur Verwendung von 11ty-Datendateien mit der Meetup-API ansehen.
Die Datei wird ein JavaScript-Modul sein. Damit also irgendetwas funktioniert, müssen wir entweder unsere Daten oder eine Funktion exportieren. In unserem Fall exportieren wir eine Funktion.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Lassen Sie uns das aufschlüsseln. Wir haben zwei Funktionen, die hier unsere Hauptarbeit leisten: mapBookmarks() und getBookmarks() .
Die Funktion getBookmarks() holt unsere Daten aus unserer FaunaDB-Datenbank und mapBookmarks() nimmt ein Array von Lesezeichen und strukturiert es um, damit es besser für unsere Vorlage funktioniert.
Lassen Sie uns tiefer in getBookmarks() .
getBookmarks()
Zuerst müssen wir eine Instanz des FaunaDB-JavaScript-Treibers installieren und initialisieren.
npm install --save faunadbJetzt, da wir es installiert haben, fügen wir es am Anfang unserer Datendatei hinzu. Dieser Code stammt direkt aus Faunas Dokumenten.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Danach können wir unsere Funktion erstellen. Wir beginnen damit, unsere erste Abfrage mit integrierten Methoden des Treibers zu erstellen. Dieses erste Bit des Codes gibt die Datenbankreferenzen zurück, die wir verwenden können, um vollständige Daten für alle unsere mit Lesezeichen versehenen Links zu erhalten. Wir verwenden die Paginate Methode als Hilfsmittel zur Verwaltung des Cursorstatus, falls wir uns entscheiden, die Daten zu paginieren, bevor wir sie an 11ty übergeben. In unserem Fall geben wir einfach alle Referenzen zurück.
In diesem Beispiel gehe ich davon aus, dass Sie FaunaDB über die Netlify Dev CLI installiert und verbunden haben. Mit diesem Prozess erhalten Sie lokale Umgebungsvariablen der FaunaDB-Geheimnisse. Wenn Sie es nicht auf diese Weise installiert haben oder netlify dev nicht in Ihrem Projekt ausführen, benötigen Sie ein Paket wie dotenv , um die Umgebungsvariablen zu erstellen. Sie müssen auch Ihre Umgebungsvariablen zu Ihrer Netlify-Site-Konfiguration hinzufügen, damit Bereitstellungen später funktionieren.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Dieser Code gibt ein Array aller unserer Links in Referenzform zurück. Wir können jetzt eine Abfrageliste erstellen, die an unsere Datenbank gesendet wird.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) Von hier aus müssen wir nur noch die zurückgegebenen Daten bereinigen. Hier kommt mapBookmarks() ins Spiel!
mapBookmarks()
In dieser Funktion behandeln wir zwei Aspekte der Daten.
Zuerst bekommen wir eine kostenlose dateTime in FaunaDB. Für alle erstellten Daten gibt es eine Eigenschaft timestamp ( ts ). Es ist nicht so formatiert, dass der Standard-Datumsfilter von Liquid zufrieden ist, also lassen Sie uns das beheben.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Damit können wir ein neues Objekt für unsere Daten erstellen. In diesem Fall hat es eine time , und wir verwenden den Spread-Operator, um unser data zu destrukturieren, damit sie alle auf einer Ebene leben.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Hier sind unsere Daten vor unserer Funktion:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Hier sind unsere Daten nach unserer Funktion:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Jetzt haben wir gut formatierte Daten, die für unsere Vorlage bereit sind!
Lassen Sie uns eine einfache Vorlage schreiben. Wir werden unsere Lesezeichen durchlaufen und validieren, dass jedes einen pageTitle und eine url hat, damit wir nicht albern aussehen.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Wir nehmen jetzt Daten von FaunaDB auf und zeigen sie an. Nehmen wir uns einen Moment Zeit und denken wir darüber nach, wie schön es ist, dass dies reines HTML ausgibt und keine Notwendigkeit besteht, Daten auf der Client-Seite abzurufen!
Aber das ist nicht wirklich genug, um dies zu einer nützlichen App für uns zu machen. Lassen Sie uns einen besseren Weg finden, als ein Lesezeichen in der FaunaDB-Konsole hinzuzufügen.
Geben Sie Netlify-Funktionen ein
Das Functions-Add-on von Netlify ist eine der einfacheren Möglichkeiten, AWS-Lambda-Funktionen bereitzustellen. Da es keinen Konfigurationsschritt gibt, ist es perfekt für DIY-Projekte, bei denen Sie nur den Code schreiben möchten.
Diese Funktion befindet sich unter einer URL in Ihrem Projekt, die so aussieht: https://myproject.com/.netlify/functions/bookmarks , vorausgesetzt, die Datei, die wir in unserem Funktionsordner erstellen, ist bookmarks.js .
Grundfluss
- Übergeben Sie eine URL als Abfrageparameter an unsere Funktions-URL.
- Verwenden Sie die Funktion, um die URL zu laden und den Titel und die Beschreibung der Seite zu entfernen, falls verfügbar.
- Formatieren Sie die Details für FaunaDB.
- Schieben Sie die Details in unsere FaunaDB-Sammlung.
- Erstellen Sie die Website neu.
Anforderungen
Wir haben ein paar Pakete, die wir brauchen werden, wenn wir das bauen. Wir verwenden die netlify-lambda-CLI, um unsere Funktionen lokal zu erstellen. request-promise ist das Paket, das wir für Anfragen verwenden. Cheerio.js ist das Paket, das wir verwenden, um bestimmte Elemente von unserer angeforderten Seite zu entfernen (denken Sie an jQuery für Node). Und schließlich brauchen wir FaunaDb (das bereits installiert sein sollte.
npm install --save netlify-lambda request-promise cheerioSobald dies installiert ist, konfigurieren wir unser Projekt so, dass die Funktionen lokal erstellt und bereitgestellt werden.
Wir ändern unsere „build“- und „serve“-Skripte in unserer package.json so, dass sie wie folgt aussehen:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Warnung: Es gibt einen Fehler mit dem NodeJS-Treiber von Fauna beim Kompilieren mit Webpack, das von den Funktionen von Netlify zum Erstellen verwendet wird. Um dies zu umgehen, müssen wir eine Konfigurationsdatei für Webpack definieren. Sie können den folgenden Code in einer neuen – oder vorhandenen – webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Sobald diese Datei vorhanden ist und wir den Befehl netlify-lambda verwenden, müssen wir ihr mitteilen, dass sie von dieser Konfiguration aus ausgeführt werden soll. Aus diesem Grund verwenden unsere „serve“- und „build“ --config den Wert „--config“ für diesen Befehl.
Funktion Hauswirtschaft
Um unsere Hauptfunktionsdatei so sauber wie möglich zu halten, erstellen wir unsere Funktionen in einem separaten bookmarks und importieren sie in unsere Hauptfunktionsdatei.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
Die Funktion getDetails() übernimmt eine URL, die von unserem exportierten Handler übergeben wird. Von dort aus erreichen wir die Website unter dieser URL und greifen relevante Teile der Seite auf, um sie als Daten für unser Lesezeichen zu speichern.
Wir beginnen mit der Anforderung der NPM-Pakete, die wir benötigen:
const rp = require('request-promise'); const cheerio = require('cheerio'); Dann verwenden wir das request-promise Modul, um einen HTML-String für die angeforderte Seite zurückzugeben, und übergeben diesen an cheerio , um uns eine sehr jQuery-ähnliche Schnittstelle zu geben.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Von hier aus müssen wir den Seitentitel und eine Meta-Beschreibung erhalten. Dazu verwenden wir Selektoren, wie Sie es in jQuery tun würden.
Hinweis: In diesem Code verwenden wir 'head > title' als Selektor, um den Titel der Seite zu erhalten. Wenn Sie dies nicht angeben, erhalten Sie möglicherweise <title> -Tags in allen SVGs auf der Seite, was alles andere als ideal ist.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Mit den Daten in der Hand ist es an der Zeit, unser Lesezeichen an unsere Sammlung in FaunaDB zu senden!
saveBookmark(details)
Für unsere Speicherfunktion möchten wir die von getDetails Details sowie die URL als einzelnes Objekt übergeben. Der Spread-Operator schlägt wieder zu!
const savedResponse = await saveBookmark({url, ...details}); In unserer create.js -Datei müssen wir auch unseren FaunaDB-Treiber benötigen und einrichten. Dies sollte Ihnen aus unserer 11ty-Datendatei sehr bekannt vorkommen.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Sobald wir das aus dem Weg geräumt haben, können wir codieren.
Zuerst müssen wir unsere Details in eine Datenstruktur formatieren, die Fauna für unsere Abfrage erwartet. Fauna erwartet ein Objekt mit einer Dateneigenschaft, die die Daten enthält, die wir speichern möchten.
const saveBookmark = async function(details) { const data = { data: details }; ... }Dann öffnen wir eine neue Abfrage, um sie unserer Sammlung hinzuzufügen. In diesem Fall verwenden wir unseren Abfragehelfer und die Create-Methode. Create() nimmt zwei Argumente entgegen. Erstens die Sammlung, in der wir unsere Daten speichern möchten, und zweitens die Daten selbst.
Nachdem wir gespeichert haben, geben wir entweder Erfolg oder Misserfolg an unseren Handler zurück.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Werfen wir einen Blick auf die vollständige Funktionsdatei.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
Das scharfsinnige Auge wird bemerken, dass wir eine weitere Funktion in unseren Handler importiert haben: rebuildSite() . Diese Funktion verwendet die Deploy Hook-Funktion von Netlify, um unsere Website jedes Mal aus den neuen Daten neu zu erstellen, wenn wir ein neues – erfolgreiches – Lesezeichen speichern.
In den Einstellungen Ihrer Website in Netlify können Sie auf Ihre Build & Deploy-Einstellungen zugreifen und einen neuen „Build Hook“ erstellen. Hooks haben einen Namen, der im Deploy-Abschnitt erscheint, und eine Option für einen Non-Master-Branch, der bereitgestellt werden kann, wenn Sie dies wünschen. In unserem Fall nennen wir ihn „new_link“ und stellen unseren Master-Branch bereit.
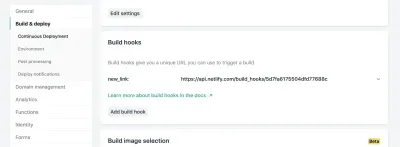
Von dort aus müssen wir nur eine POST-Anforderung an die angegebene URL senden.
Wir brauchen eine Möglichkeit, Anfragen zu stellen, und da wir request-promise bereits installiert haben, werden wir dieses Paket weiterhin verwenden, indem wir es am Anfang unserer Datei anfordern.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Einrichten einer iOS-Verknüpfung
Wir haben also eine Datenbank, eine Möglichkeit zum Anzeigen von Daten und eine Funktion zum Hinzufügen von Daten, aber wir sind immer noch nicht sehr benutzerfreundlich.
Netlify stellt URLs für unsere Lambda-Funktionen bereit, aber es macht keinen Spaß, sie in ein mobiles Gerät einzugeben. Wir müssten auch eine URL als Abfrageparameter übergeben. Das ist eine Menge Aufwand. Wie können wir dies so wenig Aufwand wie möglich machen?
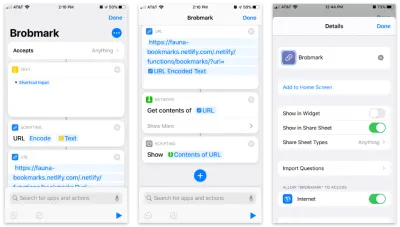
Mit der Shortcuts-App von Apple können Sie benutzerdefinierte Elemente erstellen, die in Ihr Aktienblatt aufgenommen werden können. Innerhalb dieser Shortcuts können wir verschiedene Arten von Datenanfragen senden, die im Freigabeprozess erfasst wurden.
Hier ist die Schritt-für-Schritt-Verknüpfung:
- Akzeptieren Sie alle Artikel und speichern Sie diese Artikel in einem „Text“-Block.
- Übergeben Sie diesen Text in einen „Scripting“-Block zur URL-Codierung (nur für den Fall).
- Übergeben Sie diese Zeichenfolge in einen URL-Block mit der URL unserer Netlify-Funktion und einem Abfrageparameter von
url. - Verwenden Sie von „Netzwerk“ aus einen „Inhalte abrufen“-Block, um POST an JSON an unsere URL zu senden.
- Optional: Unter „Scripting“ „zeigen“ Sie den Inhalt des letzten Schritts (um die von uns gesendeten Daten zu bestätigen).
Um über das Freigabemenü darauf zuzugreifen, öffnen wir die Einstellungen für diese Verknüpfung und schalten die Option „In Share Sheet anzeigen“ ein.
Ab iOS13 können diese Share „Actions“ favorisiert und im Dialog an eine hohe Position verschoben werden.
Wir haben jetzt eine funktionierende „App“ zum Teilen von Lesezeichen auf mehreren Plattformen!
Gehen Sie die Extrameile!
Wenn Sie inspiriert sind, dies selbst auszuprobieren, gibt es viele andere Möglichkeiten, Funktionen hinzuzufügen. Das Schöne am DIY-Web ist, dass Sie diese Art von Anwendungen für sich arbeiten lassen können. Hier sind ein paar Ideen:
- Verwenden Sie einen falschen „API-Schlüssel“ zur schnellen Authentifizierung, damit andere Benutzer nicht auf Ihrer Website posten (meiner verwendet einen API-Schlüssel, also versuchen Sie nicht, darauf zu posten!).
- Fügen Sie Tag-Funktionen hinzu, um Lesezeichen zu organisieren.
- Fügen Sie einen RSS-Feed für Ihre Website hinzu, damit andere ihn abonnieren können.
- Senden Sie programmgesteuert eine wöchentliche Zusammenfassungs-E-Mail für Links, die Sie hinzugefügt haben.
Wirklich, der Himmel ist die Grenze, also fangen Sie an zu experimentieren!