
Binomialverteilung in Python mit Beispielen aus der realen Welt [2022]
Veröffentlicht: 2021-01-09Der Wert von Wahrscheinlichkeit und Statistik im Bereich der Datenwissenschaft ist immens, wobei künstliche Intelligenz und maschinelles Lernen stark auf sie angewiesen sind. Wir verwenden Prozessmodelle der Normalverteilung jedes Mal, wenn wir A/B-Tests und Investitionsmodellierung durchführen.
Die Binomialverteilung in Python wird jedoch auf mehrere Arten angewendet, um mehrere Prozesse auszuführen. Bevor Sie jedoch mit der Binomialverteilung in Python beginnen , müssen Sie sich mit der Binomialverteilung im Allgemeinen und ihrer Verwendung im Alltag auskennen. Wenn Sie Anfänger sind und mehr über Data Science erfahren möchten, sehen Sie sich unsere Data Science-Schulungen von Top-Universitäten an.
Inhaltsverzeichnis
Was ist die Binomialverteilung ?
Haben Sie schon einmal eine Münze geworfen? Wenn ja, dann müssen Sie wissen, dass die Wahrscheinlichkeit, Kopf oder Zahl zu bekommen, gleich ist. Aber wie sieht es mit der Wahrscheinlichkeit aus, bei insgesamt zehn Würfen einer Münze sieben Schwänze zu bekommen? Hier kann die Binomialverteilung helfen, die Ergebnisse jedes Wurfs zu berechnen und so die Wahrscheinlichkeit herauszufinden, sieben Schwänze für zehn Würfe einer Münze zu erhalten.
Der Kern der Wahrscheinlichkeitsverteilung ergibt sich aus der Varianz jedes Ereignisses. Für jeden Satz von zehn Münzwürfen kann die Wahrscheinlichkeit, Kopf und Zahl zu bekommen, irgendwo zwischen ein- und zehnmal liegen, gleich und wahrscheinlich. Die Unsicherheit im Ergebnis (auch bekannt als Varianz) hilft bei der Generierung der Verteilung der erzeugten Ergebnisse.
Mit anderen Worten, die Binomialverteilung ist ein Prozess, bei dem es nur zwei mögliche Ergebnisse gibt: wahr oder falsch. Daher hat es eine gleiche Wahrscheinlichkeit für beide Ergebnisse über alle Ereignisse hinweg, da jedes Mal dieselben Aktionen ausgeführt werden. Es gibt nur eine Bedingung … Die Schritte müssen völlig unabhängig voneinander sein, und die Ergebnisse können gleich wahrscheinlich sein oder nicht.
Daher ist die Wahrscheinlichkeitsfunktion einer Binomialverteilung:
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
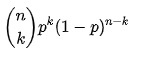
Quelle
Woher,
![]() = n n! k k !( n n!- k k!)
= n n! k k !( n n!- k k!)
Hier ist n = Gesamtzahl der Versuche
p = Erfolgswahrscheinlichkeit
k = Zielanzahl der Erfolge
Binomialverteilung in Python
Für die Binomialverteilung über Python können Sie die eindeutige Zufallsvariable aus der Funktion binom.rvs () erzeugen, wobei „n“ als Gesamthäufigkeit der Versuche definiert ist und „p“ gleich der Erfolgswahrscheinlichkeit ist.
Sie können die Verteilung auch mit der loc-Funktion verschieben, und die Größe definiert die Häufigkeit einer Aktion, die in der Serie wiederholt wird. Das Hinzufügen eines random_state kann dabei helfen, die Reproduzierbarkeit aufrechtzuerhalten.
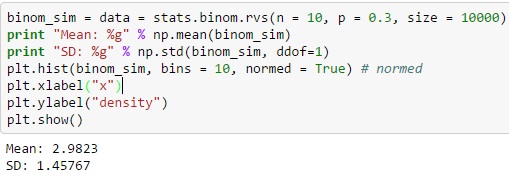
Quelle
Beispiele aus der Praxis für die Binomialverteilung in Python
Es gibt viel mehr Ereignisse (größer als Münzwürfe), die durch die Binomialverteilung in Python angegangen werden können. Einige der Anwendungsfälle können dabei helfen, den ROI (Return on Investment) für große und kleine Unternehmen zu verfolgen und zu verbessern. Hier ist wie:

- Stellen Sie sich ein Callcenter vor, in dem jedem Mitarbeiter durchschnittlich 50 Anrufe pro Tag zugewiesen werden.
- Die Conversion-Wahrscheinlichkeit bei jedem Anruf beträgt 4 %.
- Die durchschnittliche Umsatzgenerierung für das Unternehmen auf der Grundlage jeder solchen Konvertierung beträgt 20 USD.
- Wenn Sie 100 solcher Mitarbeiter analysieren, die jeden Tag 200 USD bezahlt bekommen, dann
n = 50
p = 4 %
Der Code kann eine Ausgabe wie folgt generieren:
- Durchschnittliche Konversionsrate pro Mitarbeiter = 2,13
- Die Standardabweichung der Konversionen für jedes Call-Center-Personal = 1,48
- Bruttoumwandlung = 213
- Generierung von Bruttoeinnahmen = 21.300 USD
- Bruttoausgaben = 20.000 USD
- Bruttogewinn = 1.300 USD
Binomialverteilungsmodelle und andere Wahrscheinlichkeitsverteilungen können nur eine Annäherung vorhersagen, die in Bezug auf die Aktionsparameter „n“ und „p“ der realen Welt nahe kommen kann. Es hilft uns, unsere Schwerpunktbereiche zu verstehen und zu identifizieren und die allgemeinen Chancen auf eine bessere Leistung und Effektivität zu verbessern.
Lesen Sie auch: 13 interessante Ideen und Themen für Datenstrukturprojekte für Anfänger
Was als nächstes?
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1 -on-1 mit Branchenmentoren, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Was ist der Unterschied zwischen diskreter Wahrscheinlichkeitsverteilung und kontinuierlicher Wahrscheinlichkeitsverteilung?
Die diskrete Wahrscheinlichkeitsverteilung oder einfach diskrete Verteilung berechnet die Wahrscheinlichkeiten einer Zufallsvariablen, die diskret sein kann. Wenn wir zum Beispiel eine Münze zweimal werfen, sind die wahrscheinlichen Werte einer Zufallsvariablen X, die die Gesamtzahl der Köpfe angibt, {0, 1, 2} und kein zufälliger Wert. Bernoulli, Binomial, Hypergeometric sind einige Beispiele für die diskrete Wahrscheinlichkeitsverteilung. Andererseits liefert die kontinuierliche Wahrscheinlichkeitsverteilung die Wahrscheinlichkeiten eines Zufallswerts, der eine beliebige Zufallszahl sein kann. Beispielsweise könnte der Wert einer Zufallsvariablen X, die die Größe der Bürger einer Stadt angibt, eine beliebige Zahl wie 161,2, 150,9 usw. sein. Normal, Student's T, Chi-Quadrat sind einige Beispiele für kontinuierliche Verteilung.
Welche Bedeutung hat die Wahrscheinlichkeit in der Datenwissenschaft?
Da es in der Datenwissenschaft ausschließlich um das Studium von Daten geht, spielt die Wahrscheinlichkeit hier eine Schlüsselrolle. Die folgenden Gründe beschreiben, warum die Wahrscheinlichkeit ein unverzichtbarer Bestandteil der Datenwissenschaft ist: Sie hilft Analysten und Forschern, Vorhersagen aus Datensätzen zu treffen. Solche geschätzten Ergebnisse bilden die Grundlage für die weitere Analyse der Daten. Die Wahrscheinlichkeit wird auch bei der Entwicklung von Algorithmen verwendet, die in maschinellen Lernmodellen verwendet werden. Es hilft bei der Analyse der Datensätze, die zum Trainieren der Modelle verwendet werden. Es ermöglicht Ihnen, Daten zu quantifizieren und Ergebnisse wie Ableitungen, Mittelwert und Verteilung abzuleiten. Alle unter Verwendung der Wahrscheinlichkeit erzielten Ergebnisse fassen schließlich die Daten zusammen. Diese Zusammenfassung hilft auch bei der Identifizierung vorhandener Ausreißer in den Datensätzen.
Erklären Sie die hypergeometrische Verteilung. In welchem Fall handelt es sich tendenziell um eine Binomialverteilung?
Erfolge über die Anzahl der Versuche ohne Ersatz. Nehmen wir an, wir haben eine Tasche voller roter und grüner Bälle und müssen die Wahrscheinlichkeit ermitteln, mit 5 Versuchen eine grüne Kugel zu ziehen, aber jedes Mal, wenn wir eine Kugel ziehen, legen wir sie nicht zurück in die Tasche. Dies ist ein treffendes Beispiel für die hypergeometrische Verteilung.
Für größere N ist es sehr schwierig, die hypergeometrische Verteilung zu berechnen, aber wenn N klein ist, tendiert es in diesem Fall zur Binomialverteilung.