Anfängerleitfaden für Convolutional Neural Network (CNN)
Veröffentlicht: 2021-07-05Das letzte Jahrzehnt hat ein enormes Wachstum bei künstlicher Intelligenz und intelligenteren Maschinen erlebt. Das Feld hat viele Unterdisziplinen hervorgebracht, die sich auf bestimmte Aspekte der menschlichen Intelligenz spezialisiert haben. Beispielsweise versucht die Verarbeitung natürlicher Sprache, menschliche Sprache zu verstehen und zu modellieren, während Computer Vision darauf abzielt, Maschinen ein menschenähnliches Sehen zu ermöglichen.
Da wir über Convolutional Neural Networks sprechen werden, wird unser Fokus hauptsächlich auf Computer Vision liegen. Ziel von Computer Vision ist es, Maschinen in die Lage zu versetzen, die Welt so zu sehen, wie wir es tun, und Probleme im Zusammenhang mit Bilderkennung, Bildklassifizierung und vielem mehr zu lösen. Convolutional Neural Networks werden verwendet, um verschiedene Aufgaben des Computer Vision zu erfüllen. Sie sind auch als CNN oder ConvNet bekannt und folgen einer Architektur, die den Mustern und Verbindungen von Neuronen im menschlichen Gehirn ähnelt, und sind von verschiedenen biologischen Prozessen inspiriert, die im Gehirn ablaufen, um die Kommunikation zu ermöglichen.
Inhaltsverzeichnis
Die biologische Bedeutung eines Convoluted Neural Network
CNNs sind von unserem visuellen Kortex inspiriert. Es ist der Bereich der Großhirnrinde, der an der visuellen Verarbeitung in unserem Gehirn beteiligt ist. Der visuelle Kortex hat verschiedene kleine zelluläre Regionen, die für visuelle Reize empfindlich sind.
Diese Idee wurde 1962 von Hubel und Wiesel in einem Experiment erweitert, bei dem festgestellt wurde, dass verschiedene unterschiedliche neuronale Zellen auf das Vorhandensein unterschiedlicher Kanten mit einer bestimmten Ausrichtung reagieren (gefeuert werden). Beispielsweise würden einige Neuronen beim Erkennen horizontaler Kanten feuern, andere beim Erkennen diagonaler Kanten und wieder andere würden feuern, wenn sie vertikale Kanten erkennen. Durch dieses Experiment. Hubel und Wiesel fanden heraus, dass die Neuronen modular aufgebaut sind und alle Module zusammen benötigt werden, um die visuelle Wahrnehmung hervorzurufen.
Dieser modulare Ansatz – die Idee, dass spezialisierte Komponenten innerhalb eines Systems spezifische Aufgaben haben – bildet die Grundlage der CNNs.
Lassen Sie uns damit fortfahren, wie CNNs lernen, visuelle Eingaben wahrzunehmen.

Convolutional Neural Network Learning
Bilder bestehen aus einzelnen Pixeln, was eine Darstellung zwischen den Zahlen 0 und 255 ist. Jedes Bild, das Sie sehen, kann also mithilfe dieser Zahlen in eine richtige digitale Darstellung umgewandelt werden – und so arbeiten auch Computer mit Bildern.
Hier sind einige wichtige Vorgänge, die dazu beitragen, dass ein CNN für die Bilderkennung oder -klassifizierung lernt. Dadurch erhalten Sie eine Vorstellung davon, wie Lernen in CNNs stattfindet.
1. Faltung
Faltung kann mathematisch als kombinierte Integration zweier verschiedener Funktionen verstanden werden, um herauszufinden, wie sich die verschiedenen Funktionen beeinflussen oder gegenseitig modifizieren. So kann es mathematisch definiert werden:
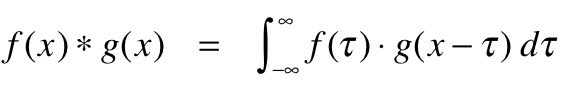
Der Zweck der Faltung besteht darin, verschiedene visuelle Merkmale in den Bildern zu erkennen, wie Linien, Kanten, Farben, Schatten und mehr. Dies ist eine sehr nützliche Eigenschaft, denn sobald Ihr CNN die Eigenschaften eines bestimmten Merkmals im Bild gelernt hat, kann es dieses Merkmal später in jedem anderen Teil des Bilds erkennen.
CNNs verwenden Kernel oder Filter, um die verschiedenen Merkmale zu erkennen, die in jedem Bild vorhanden sind. Kernel sind nur eine Matrix aus unterschiedlichen Werten (in der Welt der künstlichen neuronalen Netze als Gewichte bekannt), die darauf trainiert sind, bestimmte Merkmale zu erkennen. Der Filter bewegt sich über das gesamte Bild, um zu prüfen, ob ein Merkmal erkannt wird oder nicht. Der Filter führt die Faltungsoperation durch, um einen endgültigen Wert bereitzustellen, der darstellt, wie sicher es ist, dass ein bestimmtes Merkmal vorhanden ist.
Wenn ein Merkmal im Bild vorhanden ist, ist das Ergebnis der Faltungsoperation eine positive Zahl mit einem hohen Wert. Fehlt das Merkmal, ergibt die Faltungsoperation entweder 0 oder eine sehr niedrigwertige Zahl.
Lassen Sie uns dies anhand eines Beispiels besser verstehen. In der Abbildung unten wurde ein Filter zum Erkennen eines Pluszeichens trainiert. Dann wird der Filter über das Originalbild geleitet. Da ein Teil des Originalbilds dieselben Merkmale enthält, für die der Filter trainiert wurde, sind die Werte in jeder Zelle, in der das Merkmal vorhanden ist, eine positive Zahl. Ebenso wird das Ergebnis einer Faltungsoperation ebenfalls zu einer großen Zahl führen.
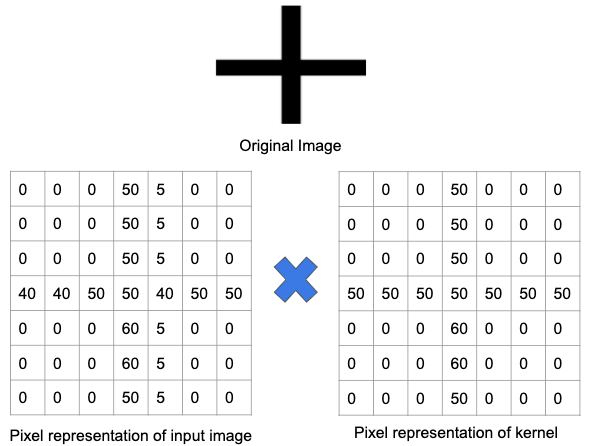
Wenn derselbe Filter jedoch über ein Bild mit unterschiedlichen Merkmalen und Kanten geleitet wird, ist die Ausgabe einer Faltungsoperation geringer – was bedeutet, dass im Bild kein starkes Pluszeichen vorhanden war.
Bei komplexen Bildern mit verschiedenen Merkmalen wie Kurven, Kanten, Farben usw. benötigen wir also eine Anzahl N solcher Merkmalsdetektoren.
Wenn dieser Filter durch das Bild geleitet wird, wird eine Merkmalskarte erzeugt, die im Grunde die Ausgabematrix ist, die die Faltungen dieses Filters über verschiedene Teile des Bildes speichert. Bei vielen Filtern erhalten wir am Ende eine 3D-Ausgabe. Dieser Filter sollte die gleiche Anzahl von Kanälen wie das Eingabebild haben, damit die Faltungsoperation stattfinden kann.
Außerdem kann ein Filter in unterschiedlichen Intervallen über das Eingabebild geschoben werden, wobei ein Schrittwert verwendet wird. Der Stride-Wert gibt an, wie weit sich der Filter bei jedem Schritt bewegen soll.
Die Anzahl der Ausgabeschichten eines bestimmten Faltungsblocks kann daher mit der folgenden Formel bestimmt werden:

2. Polsterung
Ein Problem bei der Arbeit mit Faltungsebenen besteht darin, dass einige Pixel am Umfang des Originalbilds verloren gehen. Da die verwendeten Filter im Allgemeinen klein sind, können pro Filter nur wenige Pixel verloren gehen, aber dies summiert sich, wenn wir verschiedene Faltungsebenen anwenden, was zu vielen verlorenen Pixeln führt.
Beim Padding-Konzept geht es darum, dem Bild zusätzliche Pixel hinzuzufügen, während ein Filter eines CNN es verarbeitet. Dies ist eine Lösung, um den Filter bei der Bildverarbeitung zu unterstützen – indem das Bild mit Nullen aufgefüllt wird, damit der Kernel mehr Platz hat, um das gesamte Bild abzudecken. Durch das Hinzufügen von Null-Paddings zu den Filtern ist die Bildverarbeitung von CNN viel genauer und genauer.
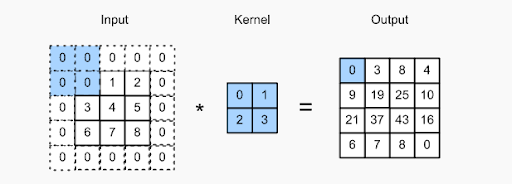
Überprüfen Sie das Bild oben – das Auffüllen wurde durch Hinzufügen zusätzlicher Nullen an der Grenze des Eingabebilds durchgeführt. Dies ermöglicht die Erfassung aller markanten Merkmale ohne Pixelverlust.

3. Aktivierungskarte
Die Feature-Maps müssen durch eine Mapping-Funktion geleitet werden, die nichtlinearer Natur ist. Die Feature-Maps werden mit einem Bias-Term aufgenommen und dann durch die nichtlineare Aktivierungsfunktion (ReLu) geleitet. Diese Funktion zielt darauf ab, ein gewisses Maß an Nichtlinearität in das CNN zu bringen, da die erkannten und untersuchten Bilder ebenfalls nichtlinearer Natur sind und aus verschiedenen Objekten bestehen.
4. Pooling-Phase
Sobald die Aktivierungsphase vorbei ist, fahren wir mit dem Pooling-Schritt fort, bei dem das CNN die gefalteten Merkmale heruntersampelt, was dazu beiträgt, Verarbeitungszeit zu sparen. Dies hilft auch bei der Reduzierung der Gesamtgröße des Bildes, Überanpassung und anderen Problemen, die auftreten würden, wenn die Convoluted Neural Networks mit vielen Informationen gefüttert würden – insbesondere wenn diese Informationen für die Klassifizierung oder Erkennung des Bildes nicht zu relevant sind.
Beim Pooling gibt es grundsätzlich zwei Arten – Max-Pooling und Min-Pooling. Bei der ersteren wird ein Fenster gemäß einem festgelegten Schrittwert über das Bild geführt, und bei jedem Schritt wird der im Fenster enthaltene Maximalwert in der Ausgangsmatrix zusammengefasst. Beim Min-Pooling werden die Minimalwerte in der Ausgangsmatrix zusammengefasst.
Die neue Matrix, die als Ergebnis der Ausgaben gebildet wird, wird als gepoolte Feature-Map bezeichnet.
Neben dem Min- und Max-Pooling besteht ein Vorteil des Max-Pooling darin, dass es dem CNN ermöglicht, sich auf wenige Neuronen mit hohen Werten zu konzentrieren, anstatt sich auf alle Neuronen zu konzentrieren. Ein solcher Ansatz macht es sehr unwahrscheinlich, dass die Trainingsdaten zu stark angepasst werden, und sorgt dafür, dass die Vorhersage und Verallgemeinerung insgesamt gut funktionieren.
5. Abflachung
Nachdem das Pooling abgeschlossen ist, wurde die 3D-Darstellung des Bildes nun in einen Merkmalsvektor umgewandelt. Diese wird dann in ein mehrschichtiges Perzeptron geleitet, um die Ausgabe zu erzeugen. Sehen Sie sich das Bild unten an, um den Vorgang des Reduzierens besser zu verstehen:
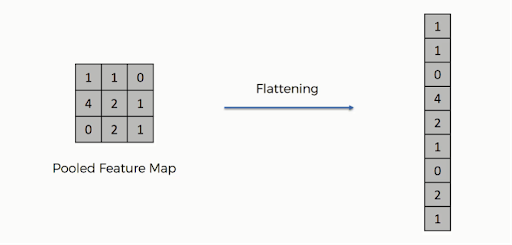
Wie Sie sehen können, werden die Zeilen der Matrix zu einem einzigen Merkmalsvektor verkettet. Wenn mehrere Eingabeschichten vorhanden sind, werden alle Zeilen verbunden, um einen längeren, abgeflachten Merkmalsvektor zu bilden.
6. Vollständig verbundene Schicht (FCL)
In diesem Schritt wird die abgeflachte Karte einem neuronalen Netzwerk zugeführt. Die vollständige Verbindung eines neuronalen Netzes umfasst eine Eingabeschicht, die FCL, und eine abschließende Ausgabeschicht. Die vollständig verbundene Schicht kann als die verborgenen Schichten in künstlichen neuronalen Netzen verstanden werden, außer dass diese Schichten im Gegensatz zu verborgenen Schichten vollständig verbunden sind. Die Informationen durchlaufen das gesamte Netzwerk, und ein Vorhersagefehler wird berechnet. Dieser Fehler wird dann als Feedback (Backpropagation) durch die Systeme gesendet, um Gewichtungen anzupassen und die endgültige Ausgabe zu verbessern, um sie genauer zu machen.
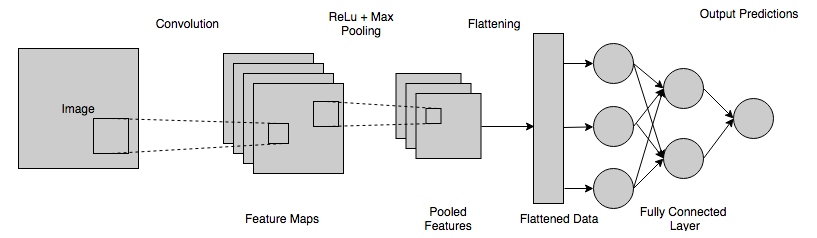
Die endgültige Ausgabe, die von der obigen Schicht des neuronalen Netzwerks erhalten wird, summiert sich im Allgemeinen nicht zu eins. Diese Ausgaben müssen auf Zahlen im Bereich von [0,1] reduziert werden – die dann die Wahrscheinlichkeiten jeder Klasse darstellen. Dazu wird die Softmax-Funktion verwendet.
Die von der dichten Schicht erhaltene Ausgabe wird der Softmax-Aktivierungsfunktion zugeführt. Dadurch werden alle endgültigen Ausgaben auf einen Vektor abgebildet, bei dem die Summe aller Elemente eins ergibt.
Die vollständig verbundene Schicht funktioniert, indem sie sich die Ausgabe der vorherigen Schicht ansieht und dann bestimmt, welches Merkmal am meisten mit einer bestimmten Klasse korreliert. Wenn das Programm also vorhersagt, ob ein Bild eine Katze enthält oder nicht, hat es hohe Werte in den Aktivierungskarten, die Merkmale wie vier Beine, Pfoten, Schwanz usw. darstellen. Ebenso, wenn das Programm etwas anderes vorhersagt, wird es verschiedene Arten von Aktivierungskarten haben. Eine vollständig verbundene Schicht kümmert sich um die verschiedenen Merkmale, die stark mit bestimmten Klassen und Gewichtungen korrelieren, sodass die Berechnung zwischen Gewichtungen und der vorherigen Schicht genau ist und Sie korrekte Wahrscheinlichkeiten für unterschiedliche Ausgabeklassen erhalten.
Eine kurze Zusammenfassung der Funktionsweise von CNNs
Hier ist eine kurze Zusammenfassung des gesamten Prozesses, wie CNN funktioniert und bei Computer Vision hilft:
- Die verschiedenen Pixel aus dem Bild werden der Faltungsschicht zugeführt, wo eine Faltungsoperation durchgeführt wird.
- Der vorherige Schritt führt zu einer gefalteten Karte.
- Diese Abbildung wird durch eine Gleichrichterfunktion geleitet, um eine gleichgerichtete Abbildung zu erzeugen.
- Das Bild wird mit unterschiedlichen Faltungen und Aktivierungsfunktionen verarbeitet, um unterschiedliche Merkmale zu lokalisieren und zu erkennen.
- Pooling-Layer werden verwendet, um bestimmte, unterschiedliche Teile des Bildes zu identifizieren.
- Die gepoolte Schicht wird abgeflacht und als Eingabe für die vollständig verbundene Schicht verwendet.
- Die vollständig verbundene Schicht berechnet die Wahrscheinlichkeiten und gibt eine Ausgabe im Bereich von [0,1] aus.
Abschließend
Die innere Funktionsweise von CNN ist sehr spannend und eröffnet viele Möglichkeiten für Innovation und Kreation. Ebenso sind andere Technologien unter dem Dach der Künstlichen Intelligenz faszinierend und versuchen, zwischen menschlichen Fähigkeiten und maschineller Intelligenz zu arbeiten. Folglich erkennen Menschen aus der ganzen Welt, die verschiedenen Domänen angehören, ihr Interesse an diesem Bereich und unternehmen die ersten Schritte.
Glücklicherweise ist die KI-Branche außerordentlich gastfreundlich und unterscheidet nicht aufgrund Ihres akademischen Hintergrunds. Alles, was Sie brauchen, sind praktische Kenntnisse der Technologien sowie grundlegende Qualifikationen, und Sie sind bereit!
Wenn Sie das Wesentliche von ML und KI beherrschen möchten, wäre die ideale Vorgehensweise, sich für ein professionelles KI/ML-Programm anzumelden. Beispielsweise ist unser Executive Program in Machine Learning and AI der perfekte Kurs für Data-Science-Anwärter. Das Programm umfasst Themen wie Statistik und explorative Datenanalyse, maschinelles Lernen und Verarbeitung natürlicher Sprache. Außerdem umfasst es über 13 Industrieprojekte, mehr als 25 Live-Sitzungen und 6 Abschlussprojekte. Das Beste an diesem Kurs ist, dass Sie mit Kollegen aus der ganzen Welt interagieren können. Es erleichtert den Austausch von Ideen und hilft den Lernenden, dauerhafte Verbindungen zu Menschen mit unterschiedlichem Hintergrund aufzubauen. Unsere 360-Grad-Karriereunterstützung ist genau das, was Sie brauchen, um sich auf Ihrer ML- und KI-Reise zu profilieren!
Führen Sie die KI-gesteuerte technologische Revolution an