
6 bahnbrechende Funktionen von Apache Spark im Jahr 2022 [Wie sollten Sie verwenden]
Veröffentlicht: 2021-01-07Seit Big Data die Technologie- und Geschäftswelt im Sturm erobert hat, gab es einen enormen Aufschwung von Big Data-Tools und -Plattformen, insbesondere von Apache Hadoop und Apache Spark. Heute werden wir uns ausschließlich auf Apache Spark konzentrieren und ausführlich über seine geschäftlichen Vorteile und Anwendungen sprechen.
Apache Spark trat 2009 ins Rampenlicht und hat sich seitdem nach und nach eine Nische in der Branche geschaffen. Laut Apache org. ist Spark eine „blitzschnelle einheitliche Analyse-Engine“, die für die Verarbeitung kolossaler Mengen von Big Data entwickelt wurde. Dank einer aktiven Community ist Spark heute eine der größten Open-Source-Big-Data-Plattformen der Welt.
Inhaltsverzeichnis
Was ist Apache Spark?
Ursprünglich im AMPLab der University of California (Berkeley) entwickelt, wurde Spark als robuste Verarbeitungs-Engine für Hadoop-Daten konzipiert, mit besonderem Fokus auf Geschwindigkeit und Benutzerfreundlichkeit. Es ist eine Open-Source-Alternative zu MapReduce von Hadoop. Im Wesentlichen ist Spark ein paralleles Datenverarbeitungs-Framework, das mit Apache Hadoop zusammenarbeiten kann, um die reibungslose und schnelle Entwicklung anspruchsvoller Big-Data-Anwendungen auf Hadoop zu erleichtern.
Spark ist vollgepackt mit einer breiten Palette von Bibliotheken für Machine Learning (ML)-Algorithmen und Graphalgorithmen. Darüber hinaus unterstützt es auch Echtzeit-Streaming und SQL-Apps über Spark Streaming bzw. Shark. Das Beste an der Verwendung von Spark ist, dass Sie Spark-Apps in Java, Scala oder sogar Python schreiben können, und diese Apps laufen fast zehnmal schneller (auf der Festplatte) und 100-mal schneller (im Arbeitsspeicher) als MapReduce-Apps.
Apache Spark ist sehr vielseitig, da es auf viele Arten bereitgestellt werden kann, und es bietet auch native Bindungen für die Programmiersprachen Java, Scala, Python und R. Es unterstützt SQL, Graphverarbeitung, Datenstreaming und maschinelles Lernen. Aus diesem Grund wird Spark in verschiedenen Branchen eingesetzt, darunter Banken, Telekommunikationsunternehmen, Spieleentwicklungsfirmen, Regierungsbehörden und natürlich in allen Top-Unternehmen der Technologiewelt – Apple, Facebook, IBM und Microsoft.
Die 6 besten Funktionen von Apache Spark
Die Funktionen, die Spark zu einer der am häufigsten verwendeten Big-Data-Plattformen machen, sind:

1. Blitzschnelle Verarbeitungsgeschwindigkeit
Bei der Verarbeitung von Big Data geht es darum, große Mengen komplexer Daten zu verarbeiten. Wenn es um die Verarbeitung von Big Data geht, wünschen sich Organisationen und Unternehmen daher solche Frameworks, die riesige Datenmengen mit hoher Geschwindigkeit verarbeiten können. Wie bereits erwähnt, können Spark-Apps im Arbeitsspeicher bis zu 100-mal schneller und auf der Festplatte in Hadoop-Clustern bis zu 10-mal schneller ausgeführt werden.
Es basiert auf Resilient Distributed Dataset (RDD), das es Spark ermöglicht, Daten transparent im Speicher zu speichern und sie nur bei Bedarf auf die Disc zu lesen/schreiben. Dies trägt dazu bei, den größten Teil der Disc-Lese- und Schreibzeit während der Datenverarbeitung zu reduzieren.
2. Benutzerfreundlichkeit
Mit Spark können Sie skalierbare Anwendungen in Java, Scala, Python und R schreiben. Entwickler erhalten also den Spielraum, um Spark-Anwendungen in ihren bevorzugten Programmiersprachen zu erstellen und auszuführen. Darüber hinaus ist Spark mit einem integrierten Satz von über 80 hochrangigen Operatoren ausgestattet. Sie können Spark interaktiv verwenden, um Daten aus Scala-, Python-, R- und SQL-Shells abzufragen.
3. Es bietet Unterstützung für anspruchsvolle Analysen
Spark unterstützt nicht nur einfache „Map“- und „Reduce“-Operationen, sondern unterstützt auch SQL-Abfragen, Streaming-Daten und erweiterte Analysen, einschließlich ML- und Graphalgorithmen. Es wird mit einem leistungsstarken Stapel von Bibliotheken wie SQL & DataFrames und MLlib (für ML), GraphX und Spark Streaming geliefert. Das Faszinierende ist, dass Sie mit Spark die Funktionen all dieser Bibliotheken in einem einzigen Workflow/einer einzigen Anwendung kombinieren können.
4. Echtzeit-Stream-Verarbeitung
Spark wurde entwickelt, um Datenstreaming in Echtzeit zu verarbeiten. Während MapReduce darauf ausgelegt ist, die bereits in Hadoop-Clustern gespeicherten Daten zu handhaben und zu verarbeiten, kann Spark beides tun und Daten auch in Echtzeit über Spark Streaming manipulieren.
Im Gegensatz zu anderen Streaming-Lösungen kann Spark Streaming die verlorene Arbeit wiederherstellen und die exakte Semantik sofort bereitstellen, ohne dass zusätzlicher Code oder Konfiguration erforderlich sind. Außerdem können Sie denselben Code für die Batch- und Stream-Verarbeitung und sogar für das Zusammenführen von Streaming-Daten mit historischen Daten wiederverwenden.
5. Es ist flexibel
Spark kann unabhängig im Clustermodus ausgeführt werden und kann auch auf Hadoop YARN, Apache Mesos, Kubernetes und sogar in der Cloud ausgeführt werden. Darüber hinaus kann es auf diverse Datenquellen zugreifen. Beispielsweise kann Spark auf dem YARN-Cluster-Manager ausgeführt werden und alle vorhandenen Hadoop-Daten lesen. Es kann aus beliebigen Hadoop-Datenquellen wie HBase, HDFS, Hive und Cassandra lesen. Dieser Aspekt von Spark macht es zu einem idealen Tool für die Migration reiner Hadoop-Anwendungen, vorausgesetzt, der Anwendungsfall der Apps ist Spark-freundlich.
6. Aktive und expandierende Community
Entwickler aus über 300 Unternehmen haben zum Design und Aufbau von Apache Spark beigetragen. Seit 2009 haben mehr als 1200 Entwickler aktiv dazu beigetragen, Spark zu dem zu machen, was es heute ist! Natürlich wird Spark von einer aktiven Community von Entwicklern unterstützt, die daran arbeiten, seine Funktionen und Leistung kontinuierlich zu verbessern. Um die Spark-Community zu erreichen, können Sie Mailinglisten für alle Fragen nutzen und auch an Spark-Meetup-Gruppen und -Konferenzen teilnehmen.
Die Anatomie von Spark-Anwendungen
Jede Spark-Anwendung besteht aus zwei Kernprozessen – einem primären Treiberprozess und einer Sammlung von Executor - Prozessen.
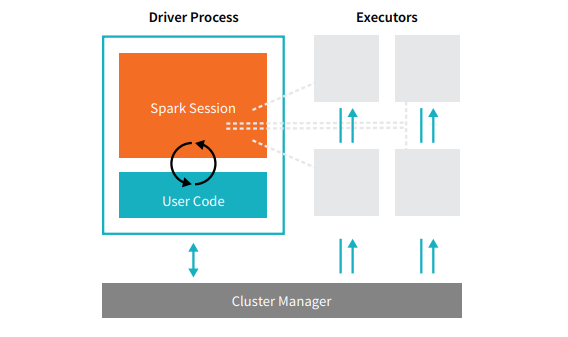
Quelle
Der Treiberprozess, der sich auf einem Knoten im Cluster befindet, ist für die Ausführung der main()-Funktion verantwortlich. Es übernimmt auch drei weitere Aufgaben – das Verwalten von Informationen über die Spark-Anwendung, das Reagieren auf den Code oder die Eingabe eines Benutzers und das Analysieren, Verteilen und Planen der Arbeit über die Ausführenden hinweg. Der Treiberprozess bildet das Herzstück einer Spark-Anwendung – er enthält und verwaltet alle kritischen Informationen, die die Lebensdauer der Spark-Anwendung abdecken.

Die Executoren oder Executor-Prozesse sind sekundäre Elemente, die die ihnen vom Treiber zugewiesene Aufgabe ausführen müssen. Grundsätzlich führt jeder Executor zwei entscheidende Funktionen aus – führt den ihm vom Treiber zugewiesenen Code aus und meldet den Zustand der Berechnung (auf diesem Executor) an den Treiberknoten. Benutzer können entscheiden und konfigurieren, wie viele Executoren jeder Knoten haben soll.
In einer Spark-Anwendung steuert der Cluster-Manager alle Maschinen und weist der Anwendung Ressourcen zu. Hier kann der Cluster-Manager einer der Core-Cluster-Manager von Spark sein, einschließlich YARN (Sparks eigenständiger Cluster-Manager) oder Mesos. Das bedeutet, dass ein Cluster mehrere Spark-Anwendungen gleichzeitig ausführen kann.
Echte Apache Spark-Anwendungen
Spark ist eine erstklassige und weit verbreitete Big Dara-Plattform in der modernen Industrie. Einige der bekanntesten Beispiele aus der Praxis für Apache Spark-Anwendungen sind:
Spark für maschinelles Lernen
Apache Spark verfügt über eine skalierbare Bibliothek für maschinelles Lernen – MLlib. Diese Bibliothek ist explizit auf Einfachheit, Skalierbarkeit und nahtlose Integration mit anderen Tools ausgelegt. MLlib besitzt nicht nur die Skalierbarkeit, Sprachkompatibilität und Geschwindigkeit von Spark, sondern kann auch eine Vielzahl von erweiterten Analyseaufgaben wie Klassifizierung, Clustering und Dimensionsreduktion ausführen. Dank MLlib kann Spark für prädiktive Analysen, Stimmungsanalysen, Kundensegmentierung und prädiktive Intelligenz verwendet werden.
Ein weiteres beeindruckendes Merkmal von Apache Spark liegt im Bereich der Netzwerksicherheit. Mit Spark Streaming können Benutzer Datenpakete in Echtzeit überwachen, bevor sie in den Speicher verschoben werden. Während dieses Prozesses kann es erfolgreich alle verdächtigen oder böswilligen Aktivitäten identifizieren, die von bekannten Bedrohungsquellen ausgehen. Auch nachdem die Datenpakete an den Speicher gesendet wurden, verwendet Spark MLlib, um die Daten weiter zu analysieren und potenzielle Risiken für das Netzwerk zu identifizieren. Diese Funktion kann auch zur Betrugs- und Ereigniserkennung verwendet werden.
Spark für Fog Computing
Apache Spark ist ein hervorragendes Werkzeug für Fog Computing, insbesondere wenn es um das Internet der Dinge (IoT) geht. Das IoT stützt sich stark auf das Konzept der parallelen Verarbeitung im großen Maßstab. Da das IoT-Netzwerk aus Tausenden und Millionen angeschlossener Geräte besteht, sind die von diesem Netzwerk jede Sekunde generierten Daten unvorstellbar.
Um solch große Datenmengen zu verarbeiten, die von IoT-Geräten erzeugt werden, benötigen Sie natürlich eine skalierbare Plattform, die die parallele Verarbeitung unterstützt. Und was ist besser als die robuste Architektur und die Fog-Computing-Fähigkeiten von Spark, um mit solch riesigen Datenmengen umzugehen!
Fog Computing dezentralisiert die Daten und die Speicherung und führt die Datenverarbeitungsfunktion anstelle der Cloud-Verarbeitung am Rand des Netzwerks aus (hauptsächlich eingebettet in die IoT-Geräte).
Dazu benötigt Fog Computing drei Fähigkeiten, nämlich geringe Latenz, parallele Verarbeitung von ML und komplexe Graphanalysealgorithmen – die alle in Spark vorhanden sind. Darüber hinaus verbessert das Vorhandensein von Spark Streaming, Shark (ein interaktives Abfragetool, das in Echtzeit funktionieren kann), MLlib und GraphX (eine Grafikanalyse-Engine) die Fog-Computing-Fähigkeit von Spark weiter.
Spark für die interaktive Analyse
Im Gegensatz zu MapReduce, Hive oder Pig, die eine relativ niedrige Verarbeitungsgeschwindigkeit haben, kann Spark mit interaktiven Hochgeschwindigkeitsanalysen aufwarten. Es ist in der Lage, explorative Abfragen zu verarbeiten, ohne dass eine Stichprobe der Daten erforderlich ist. Außerdem ist Spark mit fast allen gängigen Entwicklungssprachen kompatibel, einschließlich R, Python, SQL, Java und Scala.
Die neueste Version von Spark – Spark 2.0 – bietet eine neue Funktion, die als strukturiertes Streaming bekannt ist. Mit dieser Funktion können Benutzer strukturierte und interaktive Abfragen von Streaming-Daten in Echtzeit ausführen.
Benutzer von Spark
Nachdem Sie nun die Funktionen und Fähigkeiten von Spark gut kennen, lassen Sie uns über die vier prominenten Benutzer von Spark sprechen!
1. Yahoo
Yahoo verwendet Spark für zwei seiner Projekte, eines zur Personalisierung von Nachrichtenseiten für Besucher und das andere zur Ausführung von Analysen für Werbung. Um Nachrichtenseiten anzupassen, verwendet Yahoo fortschrittliche ML-Algorithmen, die auf Spark ausgeführt werden, um die Interessen, Vorlieben und Bedürfnisse einzelner Benutzer zu verstehen und die Geschichten entsprechend zu kategorisieren.
Für den zweiten Anwendungsfall nutzt Yahoo die interaktiven Funktionen von Hive on Spark (zur Integration mit jedem Tool, das sich in Hive einfügt), um die auf Hadoop gesammelten Werbeanalysedaten von Yahoo anzuzeigen und abzufragen.
2. Über
Uber verwendet Spark Streaming in Kombination mit Kafka und HDFS zum ETL (Extrahieren, Transformieren und Laden) großer Mengen von Echtzeitdaten diskreter Ereignisse in strukturierte und nutzbare Daten für die weitere Analyse. Diese Daten helfen Uber, verbesserte Lösungen für die Kunden zu entwickeln.

3. Konviva
Als Video-Streaming-Unternehmen erhält Conviva jeden Monat durchschnittlich über 4 Millionen Video-Feeds, was zu einer massiven Kundenabwanderung führt. Diese Herausforderung wird durch das Problem der Verwaltung des Live-Videoverkehrs weiter verschärft. Um diesen Herausforderungen effektiv zu begegnen, nutzt Conviva Spark Streaming, um die Netzwerkbedingungen in Echtzeit zu lernen und den Videoverkehr entsprechend zu optimieren. Dadurch kann Conviva den Benutzern ein konsistentes und qualitativ hochwertiges Seherlebnis bieten.
4. Pinterest
Auf Pinterest können Nutzer ihre Lieblingsthemen nach Belieben pinnen, während sie im Web und in den sozialen Medien surfen. Um ein personalisiertes und verbessertes Kundenerlebnis zu bieten, nutzt Pinterest die ETL-Funktionen von Spark, um die einzigartigen Bedürfnisse und Interessen einzelner Nutzer zu ermitteln und ihnen auf Pinterest relevante Empfehlungen zu geben.
Fazit
Zusammenfassend lässt sich sagen, dass Spark eine äußerst vielseitige Big-Data-Plattform mit beeindruckenden Funktionen ist. Da es sich um ein Open-Source-Framework handelt, wird es kontinuierlich verbessert und weiterentwickelt, wobei neue Features und Funktionen hinzugefügt werden. Je vielfältiger und umfangreicher die Anwendungen von Big Data werden, desto vielfältiger werden auch die Anwendungsfälle von Apache Spark.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Sehen Sie sich unsere anderen Softwareentwicklungskurse bei upGrad an.