
Apache Kafka-Architektur: Umfassender Leitfaden für Anfänger [2022]
Veröffentlicht: 2021-12-23Bevor wir uns mit den Details der Apache-Kafka-Architektur befassen, ist es angebracht, etwas Licht ins Dunkel zu bringen, warum Kafka überhaupt Schlagzeilen macht. Zunächst findet Apache Kafka hauptsächlich Verwendung in Echtzeit-Streaming-Datenarchitekturen zur Bereitstellung von Echtzeitanalysen. Das Publish-Subscribe-Messaging-System von Kafka ist langlebig, schnell, skalierbar und fehlertolerant und bietet Anwendungsfälle für Dinge wie das Verfolgen von IoT-Sensordaten oder das Verfolgen von Serviceanrufen.
Unternehmen wie LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal und viele andere verwenden Apache Kafka zur Verarbeitung von Echtzeit-Streaming-Daten. Beispielsweise verwendet LinkedIn, wo Kafka seinen Ursprung hat, es, um Betriebsmetriken und Aktivitätsdaten zu verfolgen. Ebenso ist Apache Kafka für Netflix der De-facto-Standard für seine Messaging-, Eventing- und Stream-Verarbeitungsanforderungen.
Lernen Sie Online-Schulungen zur Softwareentwicklung von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Die Nützlichkeit von Apache Kafka lässt sich besser einschätzen, wenn man die Architektur von Apache Kafka und die zugrunde liegenden Komponenten versteht. Lassen Sie uns also die Details von Kafkas Architektur untersuchen.
Inhaltsverzeichnis
Grundlegende Konzepte der Kafka-Architektur
Die folgenden Konzepte sind grundlegend für das Verständnis der Apache Kafka-Architektur:
1. Themen
Kafka-Themen definieren die Kanäle, über die Daten gestreamt werden. Somit veröffentlichen Produzenten Nachrichten zu den Themen, und Verbraucher lesen Nachrichten von den Themen, die sie abonnieren. Die Anzahl der innerhalb eines Kafka-Clusters erstellten Themen ist unbegrenzt, und jedes Thema wird durch einen eindeutigen Namen identifiziert.

2. Makler
Broker sind Server in einem Kafka-Cluster, die als Container fungieren und mehrere Themen mit unterschiedlichen Partitionen enthalten. Eine eindeutige ganzzahlige ID identifiziert Broker in einem Kafka-Cluster, und eine Verbindung mit einem dieser Broker bedeutet eine Verbindung mit dem gesamten Cluster.
3. Partitionen
Kafka-Themen sind in viele Teile unterteilt, die als Partitionen bekannt sind. Partitionen werden der Reihe nach getrennt und ermöglichen es mehreren Verbrauchern, Daten aus einem bestimmten Thema parallel zu lesen. Die Partitionen eines Themas sind auf mehrere Server im Kafka-Cluster verteilt, und jeder Server verwaltet die Daten und Anfragen für seine vielen Partitionen. Nachrichten erreichen den Broker und einen Schlüssel, und der Schlüssel bestimmt die Partition, an die die bestimmte Nachricht gehen wird. Daher gehen Nachrichten mit demselben Schlüssel an dieselbe Partition. Falls der Schlüssel nicht angegeben ist, wird die Partition nach einem Round-Robin-Ansatz entschieden.
4. Repliken
In Kafka sind Replikate wie Partitionssicherungen, um sicherzustellen, dass im Falle eines geplanten Herunterfahrens oder Ausfalls kein Datenverlust auftritt. Mit anderen Worten, Replikate sind Kopien von Partitionen.
5. Partitions-Offsets
Da Nachrichten oder Datensätze in Kafka Partitionen zugeordnet sind, wird jeder Datensatz mit einem Offset versehen, um seine Position innerhalb der Partition anzugeben. Somit hilft der einem Datensatz zugeordnete Offset-Wert bei seiner einfachen Identifizierung innerhalb der Partition. Ein Partitions-Offset hat nur innerhalb dieser bestimmten Partition Bedeutung, und da Datensätze an Partitionsenden hinzugefügt werden, haben ältere Datensätze niedrigere Offset-Werte.
6. Produzenten
Kafka-Produzenten veröffentlichen Nachrichten zu einem oder mehreren Themen und senden Daten an das Kafka-Cluster. Sobald ein Producer eine Nachricht zu einem Kafka-Topic veröffentlicht, empfängt der Broker die Nachricht und fügt sie einer bestimmten Partition hinzu. Dann können Produzenten die Partition auswählen, auf der sie ihre Nachricht veröffentlichen möchten.
7. Verbraucher und Verbrauchergruppen
Verbraucher lesen Nachrichten aus dem Kafka-Cluster. Wenn ein Verbraucher bereit ist, die Nachricht zu empfangen, werden die Daten vom Broker abgerufen. Verbraucher gehören zu einer Verbrauchergruppe, und jeder Verbraucher innerhalb einer bestimmten Gruppe ist dafür verantwortlich, eine Teilmenge der Partitionen jedes Themas zu lesen, das er abonniert hat.
8. Führer und Anhänger
Jede Kafka-Partition hat einen Server, der die Rolle des Leaders spielt. Der Leader führt alle Lese- und Schreibaufgaben für diese bestimmte Partition aus. Auf der anderen Seite besteht die Aufgabe des Followers darin, die Daten des Leaders zu replizieren. Wenn ein Leader in einer bestimmten Partition ausfällt, übernimmt einer der Follower-Knoten die Rolle des Leaders. Eine Partition kann keine oder viele Follower haben.
Das folgende Diagramm ist eine vereinfachte Darstellung der Beziehungen zwischen den oben diskutierten Architekturkomponenten von Apache Kafka.
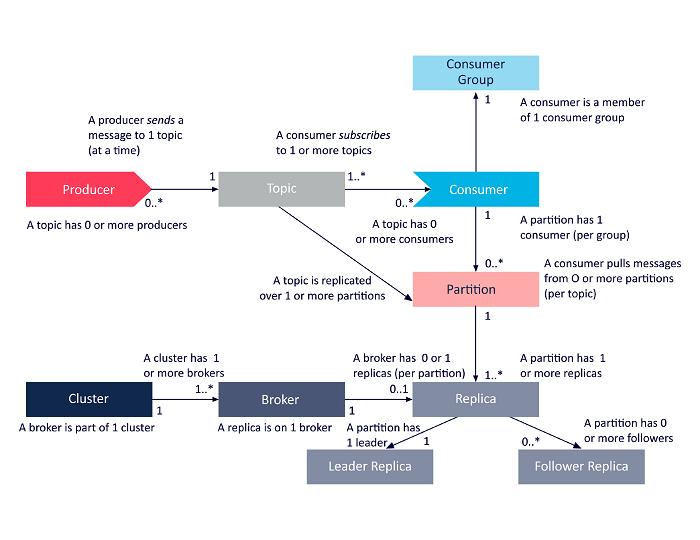
Quelle
Apache Kafka-Cluster-Architektur
Hier ist ein detaillierter Blick auf die wichtigsten architektonischen Komponenten von Kafka:

1. Kafka-Makler
Kafka-Cluster enthalten normalerweise mehrere Knoten, die als Broker bezeichnet werden. Die Broker halten den Lastausgleich aufrecht. Jeder Kafka-Broker kann Hunderte und Tausende von Lese- und Schreibvorgängen pro Sekunde verarbeiten. Ein Broker dient als Leader für eine bestimmte Partition. Der Leader hat einen oder mehrere Follower, wobei die Daten des Leaders über die Follower dieser bestimmten Partition repliziert werden.
Follower müssen mit den Daten des Leaders auf dem Laufenden bleiben. Der Leader wiederum verfolgt die Follower, die mit ihm synchron sind. Wenn ein Follower den Leader nicht einholt oder nicht mehr am Leben ist, wird er aus der mit dem bestimmten Leader verknüpften In-Sync-Replica-Liste entfernt. Ein neuer Anführer wird nach dem Tod des Anführers unter den Anhängern gewählt, und der ZooKeeper überwacht die Wahl. Da die Broker zustandslos sind, behält der ZooKeeper seinen Cluster-Zustand bei. Die Knoten in einem Cluster senden Heartbeat-Nachrichten an den ZooKeeper, um diesen zu informieren, dass sie am Leben sind.
2. Kafka-Produzenten
Kafka-Produzenten senden Daten direkt an die Broker, die die Rolle eines Leaders für eine bestimmte Partition spielen. Die Broker oder Knoten der Kafka-Cluster helfen den Produzenten, direkte Nachrichten zu senden. Sie tun dies, indem sie Anfragen nach Metadaten beantworten, auf denen Server aktiv sind, und den Live-Status der Partitionsleiter eines Themas, sodass der Produzent seine Anfragen entsprechend richten kann. Der Producer entscheidet, auf welcher Partition er Nachrichten veröffentlichen möchte. Nachrichten in Kafka werden in Stapeln gesendet, die als Datensatzstapel bezeichnet werden. Erzeuger sammeln Nachrichten im Speicher und senden sie in Stapeln, entweder nachdem eine festgelegte Zeitspanne verstrichen ist oder nachdem sich eine bestimmte Anzahl von Nachrichten angesammelt hat.
3. Kafka-Konsumenten
Kafka-Konsumenten geben Anfragen an Broker aus, die die Partitionen angeben, die sie verwenden möchten. Der Consumer gibt den Partitions-Offset in seiner Anfrage an und erhält vom Broker ein Protokollstück (beginnend mit der Offset-Position). Ein Protokoll enthält die Datensätze für einen konfigurierbaren Zeitraum, der als Aufbewahrungszeitraum bezeichnet wird.
Verbraucher können Daten auch erneut konsumieren, solange das Protokoll die Daten enthält. Kafka-Verbraucher arbeiten mit einem Pull-basierten Ansatz, was bedeutet, dass die Broker Daten nicht sofort an die Verbraucher weitergeben. Stattdessen senden Verbraucher zuerst Anfragen an Broker, die signalisieren, dass sie bereit sind, Daten zu konsumieren. Daher stellt das Pull-basierte System sicher, dass die Verbraucher nicht mit Nachrichten überhäuft werden und aufholen können, wenn sie ins Hintertreffen geraten.
Es folgt ein vereinfachtes Apache Kafka-Architekturdiagramm:
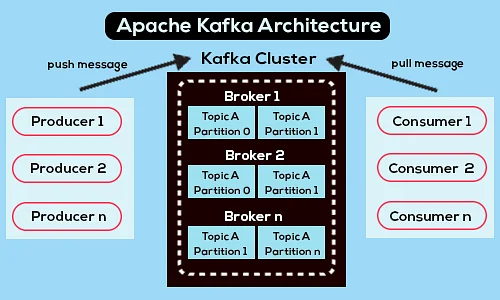
Quelle
Erfahren Sie mehr über Apache Kafka.
Apache Kafka API-Architektur
Apache Kafka verfügt über vier Schlüssel-APIs – die Streams-API, die Connector-API, die Producer-API und die Consumer-API. Sehen wir uns an, welche Rolle jeder bei der Verbesserung der Fähigkeiten von Apache Kafka spielen muss:
1. Streams-API
Die Streams-API von Kafka ermöglicht es einer Anwendung, Daten mithilfe eines Streams-Verarbeitungsalgorithmus zu verarbeiten. Mithilfe der Streams-API können Anwendungen Eingabestreams von einem oder mehreren Themen nutzen, sie mit Stream-Operationen verarbeiten, Ausgabestreams erzeugen und sie schließlich an ein oder mehrere Themen senden. Somit erleichtert die Streams-API die Umwandlung von Eingabeströmen in Ausgabeströme.
2. Connector-API
Die Konnektor-API von Kafka ist hilfreich beim Erstellen, Ausführen und Verwalten wiederverwendbarer Produzenten und Konsumenten, die Kafka-Themen mit vorhandenen Datensystemen oder Anwendungen verbinden. Beispielsweise könnte ein Konnektor zu einer relationalen Datenbank alle Aktualisierungen erfassen und sicherstellen, dass die Änderungen innerhalb eines Kafka-Themas verfügbar sind.

3. Hersteller-API
Die Producer-API von Kafka ermöglicht es Anwendungen, einen Stream von Datensätzen zu Kafka-Themen zu veröffentlichen.
4. Verbraucher-API
Die Consumer-API von Kafka Ermöglicht Anwendungen, Kafka-Themen zu abonnieren. Es ermöglicht Anwendungen auch, Aufzeichnungsströme zu verarbeiten, die zu diesen Kafka-Themen produziert werden.
Weg nach vorn
Die Apache-Kafka-Architektur ist nur ein winziger Teil des riesigen Repertoires an Werkzeugen und Sprachen, mit denen sich Softwareentwickler beschäftigen. Angenommen, Sie sind ein angehender Softwareentwickler mit einer Neigung zu Big Data. Dann können Sie mit upGrads Executive PG Program in Software Development – Specialization in Big Data den ersten Schritt zu Ihren Zielen machen .
Hier ein Überblick über das Programm mit einigen Highlights:
- Executive PGP von IIIT Bangalore mit Zertifizierungen in Data Science und Cloud Infrastructure
- Online-Sitzungen und Live-Vorträge mit über 400 Stunden Inhalt
- 7+ Fallstudien und Projekte
- Über 14 Programmiersprachen und Tools
- 360-Grad-Karriereunterstützung
- Peer- und Branchen-Networking
Melden Sie sich für weitere Details an über den Kurs!
Wofür wird Kafka verwendet?
Apache Kafka wird hauptsächlich zum Erstellen von Echtzeit-Streaming-Datenpipelines und Anwendungen verwendet, die sich an diese Datenströme anpassen. Es ermöglicht sowohl die Speicherung als auch die Analyse von Echtzeit- und Verlaufsdaten durch eine Kombination aus Messaging, Speicherung und Stream-Verarbeitung.
Ist Kafka ein Framework?
Apache Kafka ist eine Open-Source-Software, die ein Framework zum Speichern, Lesen und Analysieren von Streaming-Daten bereitstellt. Da es Open Source ist, kann Kafka kostenlos von vielen Entwicklern und Benutzern verwendet werden, die zu neuen Funktionen, Updates und Unterstützung für neue Benutzer beitragen.
Warum brauchen wir Kafka-Streams?
Kafka Streams ist eine Client-Bibliothek zum Erstellen von Microservices und Streaming-Anwendungen, bei denen die Eingabedaten und Ausgabedaten im Apache Kafka-Cluster gespeichert werden. Einerseits bietet es die Vorteile der serverseitigen Cluster-Technologie von Apache Kafka. Andererseits vereinfacht es das Schreiben und Bereitstellen von Scala- und Java-Standardanwendungen auf der Client-Seite.