
Apache Kafka: Architektur, Konzepte, Funktionen und Anwendungen
Veröffentlicht: 2021-03-09Kafka wurde 2011 gegründet, alles dank LinkedIn. Seitdem hat es ein unglaubliches Wachstum erlebt, bis zu dem Punkt, dass die meisten Unternehmen, die in Fortune 500 gelistet sind, es jetzt verwenden. Es ist ein hochskalierbares, langlebiges Produkt mit hohem Durchsatz, das große Mengen an Streaming-Daten verarbeiten kann. Aber ist das der einzige Grund für seine enorme Popularität? Nun, nein. Wir haben noch nicht einmal mit seinen Funktionen, der Qualität, die es erzeugt, und der Benutzerfreundlichkeit begonnen, die es den Benutzern bietet.
Wir werden später darauf eingehen. Lassen Sie uns zuerst verstehen, was Kafka ist und wo es verwendet wird.
Inhaltsverzeichnis
Was ist Apache Kafka?
Apache Kafka ist eine Open-Source-Stream-Verarbeitungssoftware, die darauf abzielt, einen hohen Durchsatz und eine geringe Latenz zu liefern und gleichzeitig Echtzeitdaten zu verwalten. Kafka wurde in Java und Scala geschrieben, bietet Haltbarkeit über In-Memory-Microservices und spielt eine wesentliche Rolle bei der Aufrechterhaltung von Versorgungsereignissen für Complex Event Streaming Services, auch bekannt als CEP oder Automatisierungssysteme.
Es ist ein außergewöhnlich vielseitiges, fehlersicheres verteiltes System, das es Unternehmen wie Uber ermöglicht, die Abstimmung von Fahrgästen und Fahrern zu verwalten. Es bietet auch Echtzeitdaten und proaktive Wartung für die Smart-Home-Produkte von British Gas, abgesehen davon, dass es LinkedIn dabei hilft, mehrere Echtzeitdienste zu verfolgen.
Kafka wird häufig in Echtzeit-Streaming-Datenarchitekturen eingesetzt, um Echtzeitanalysen bereitzustellen, und ist ein schnelles, robustes, skalierbares und Publish-Subscribe-Messaging-System. Apache Kafka kann aufgrund seiner hervorragenden Kompatibilität und flexiblen Architektur, die es ihm ermöglicht, Serviceaufrufe oder IoT-Sensordaten zu verfolgen, als Ersatz für herkömmliches MOM verwendet werden.
Kafka funktioniert hervorragend mit Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink und Apache Spark für die Aufnahme, Recherche, Analyse und Verarbeitung von Streaming-Daten in Echtzeit. Kafka-Intermediäre erleichtern auch Follow-up-Berichte mit geringer Latenz in Hadoop oder Spark. Kafka hat auch ein untergeordnetes Projekt namens Kafka Stream, das als effektives Tool für Echtzeitanalysen fungiert.

Kafka-Architektur und -Komponenten
Kafka wird zum Streamen von Echtzeitdaten an mehrere Empfängersysteme verwendet. Kafka fungiert als zentrale Schicht zur Entkopplung von Echtzeit-Datenpipelines. Es findet nicht viel Verwendung in direkten Berechnungen. Es ist am besten mit Fast-Lane-Zuführsystemen kompatibel, die in Echtzeit oder auf Betriebsdaten basieren, um eine erhebliche Datenmenge für die Chargendatenanalyse zu streamen.
Storm-, Flink-, Spark- und CEP-Frameworks sind einige Datensysteme, mit denen Kafka arbeitet, um Echtzeitanalysen durchzuführen, Backups, Audits und mehr zu erstellen. Es kann auch in Big-Data-Plattformen oder Datenbanksysteme wie RDBMS und Cassandra, Spark usw. für Data Science Crunch, Reporting usw. integriert werden.
Das folgende Diagramm veranschaulicht das Kafka-Ökosystem:
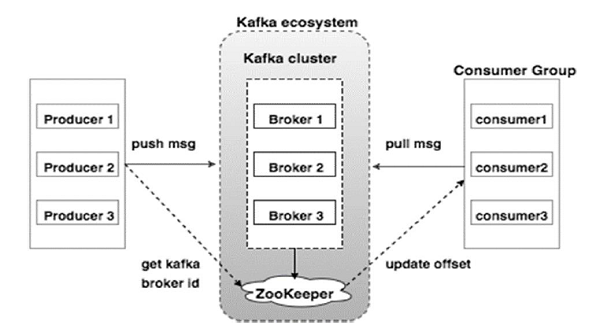
Quelle
Hier sind die verschiedenen Komponenten des Kafka-Ökosystems, wie im Kafka-Architekturdiagramm dargestellt:
1. Kafka-Broker
Kafka emuliert einen Cluster, der mehrere Server umfasst, die jeweils als „Broker“ bezeichnet werden. Jegliche Kommunikation zwischen Clients und Servern folgt einem Hochleistungs-TCP-Protokoll. Es umfasst mehr als einen zustandslosen Broker, um eine hohe Belastung zu bewältigen. Ein einzelner Kafka-Broker ist in der Lage, mehrere lacs von Lese- und Schreibvorgängen pro Sekunde zu verwalten, ohne die Leistung zu beeinträchtigen. Sie verwenden ZooKeeper, um Cluster zu verwalten und den Broker-Leader zu wählen.
2. Kafka Tierpfleger
Wie oben erwähnt, ist ZooKeeper für die Verwaltung von Kafka-Brokern zuständig. Jede Neuaufnahme oder jeder Ausfall eines Brokers im Kafka-Ökosystem wird einem Hersteller oder Verbraucher über ZooKeeper mitgeteilt.
3. Kafka-Produzenten
Sie sind dafür verantwortlich, Daten an Broker zu senden. Hersteller verlassen sich nicht auf Makler, um den Empfang einer Nachricht zu bestätigen. Stattdessen bestimmen sie, wie viel ein Broker verarbeiten kann, und senden entsprechend Nachrichten.
4. Kafka-Konsumenten
Es liegt in der Verantwortung der Kafka-Konsumenten, die Anzahl der vom Partitionsoffset verbrauchten Nachrichten aufzuzeichnen. Das Bestätigen einer Nachricht zeigt an, dass die gesendeten Nachrichten verarbeitet wurden, bevor sie verarbeitet wurden. Um sicherzustellen, dass der Broker über einen Byte-Puffer verfügt, der zum Senden an den Verbraucher bereit ist, initiiert der Verbraucher eine asynchrone Pull-Anforderung. Der ZooKeeper spielt eine Rolle beim Aufrechterhalten des Offsetwerts beim Überspringen oder Zurückspulen einer Nachricht.

Der Mechanismus von Kafka beinhaltet das Senden von Nachrichten zwischen Anwendungen in verteilten Systemen. Kafka verwendet ein Commit-Protokoll, das, wenn es abonniert wird, die vorhandenen Daten für eine Vielzahl von Streaming-Anwendungen veröffentlicht. Der Absender sendet Nachrichten an Kafka, während der Empfänger Nachrichten aus dem von Kafka verteilten Stream empfängt.
Botschaften werden zu Themen zusammengesetzt – eine wirkungsvolle Überlegung Kafkas. Ein bestimmtes Thema stellt einen organisierten Strom von Daten basierend auf einem bestimmten Typ oder einer bestimmten Klassifizierung dar. Der Produzent schreibt Nachrichten, die Verbraucher lesen können und die auf einem Thema basieren.
Jedes Thema erhält einen eindeutigen Namen. Jede Nachricht aus einem bestimmten Thema, die von einem Absender gesendet wird, wird von allen Benutzern empfangen, die sich auf dieses Thema einstellen. Nach der Veröffentlichung können die Daten in einem Thema nicht mehr aktualisiert oder geändert werden.
Merkmale von Kafka
- Kafka besteht aus einem dauerhaften Commit-Protokoll, mit dem Sie es abonnieren und anschließend Daten in mehreren Systemen oder Echtzeitanwendungen veröffentlichen können.
- Es gibt Anwendungen die Möglichkeit, diese Daten zu kontrollieren, sobald sie ankommen. Die Streams-API in Apache Kafka ist eine leistungsstarke, schlanke Bibliothek, die die Batch-Datenverarbeitung im laufenden Betrieb erleichtert.
- Es ist eine Java-Anwendung, mit der Sie Ihren Arbeitsablauf regulieren und den Wartungsaufwand erheblich reduzieren können.
- Kafka fungiert als „Speicher der Wahrheit“, der Daten auf mehrere Knoten verteilt, indem die Datenbereitstellung über mehrere Datensysteme ermöglicht wird.
- Das Commit-Protokoll von Kafka macht es zu einem zuverlässigen Speichersystem. Kafka erstellt Replikate/Backups einer Partition, die helfen, Datenverlust zu verhindern (die richtigen Konfigurationen können zu keinem Datenverlust führen). Dies verhindert auch Serverausfälle und erhöht die Haltbarkeit von Kafka.
- Themen in Kafka haben Tausende von Partitionen, wodurch es in der Lage ist, eine beliebige Menge an Daten und hohe Belastungen zu verarbeiten.
- Kafka ist auf den Kernel des Betriebssystems angewiesen, um Daten schnell zu verschieben. Diese Informationscluster sind Ende-zu-Ende verschlüsselt, vom Produzenten über das Dateisystem bis zum Endverbraucher.
- Batching in Kafka macht die Datenkomprimierung effizienter und verringert die I/O-Latenz.
Anwendungen von Kafka
Viele Unternehmen, die täglich mit großen Datenmengen umgehen, nutzen Kafka.

- LinkedIn verwendet Kafka, um Benutzeraktivitäten und Leistungskennzahlen zu verfolgen. Twitter kombiniert es mit Storm, um ein Stream-Verarbeitungs-Framework zu ermöglichen.
- Square verwendet Kafka, um die Übertragung aller Systemereignisse zu anderen Square-Rechenzentren zu erleichtern. Dazu gehören Protokolle, benutzerdefinierte Ereignisse und Metriken.
- Andere beliebte Unternehmen, die die Vorteile von Kafka nutzen, sind Netflix, Spotify, Uber, Tumblr, CloudFlare und PayPal.
Warum sollten Sie Apache Kafka lernen?
Kafka ist eine hervorragende Event-Streaming-Plattform , die Echtzeitdaten effizient verarbeiten, verfolgen und überwachen kann. Seine fehlertolerante und skalierbare Architektur ermöglicht eine Datenintegration mit geringer Latenz, was zu einem hohen Durchsatz von Streaming-Ereignissen führt. Kafka reduziert die „Time-to-Value“ für Daten erheblich.
Es fungiert als grundlegendes System, das Informationen für Organisationen liefert, indem es „Protokolle“ um Daten eliminiert. Dadurch können Data Scientists und Spezialisten jederzeit problemlos auf Informationen zugreifen.
Aus diesen Gründen ist es für viele Top-Unternehmen die bevorzugte Streaming-Plattform und daher sind Kandidaten mit einer Qualifikation in Apache Kafka sehr gefragt.
Wenn Sie daran interessiert sind, mehr über Kafka und Big Data zu erfahren, sollten Sie sich das PG-Diplom von upGrad in Softwareentwicklungsspezialisierung in Big Data ansehen, das mehr als 7 Fallstudien und Projekte sowie Mentoring von erstklassigen Fakultäts- und Branchenexperten bietet. Das 13-monatige Programm umfasst 14 Programmiersprachen und lehrt unter anderem Datenverarbeitung, MapReduce, Data Warehousing, Echtzeitverarbeitung, Big Data-Verarbeitung in der Cloud.
Sehen Sie sich unsere anderen Softwareentwicklungskurse bei upGrad an.