
Eine alternative Sprachbenutzeroberfläche zu Sprachassistenten
Veröffentlicht: 2022-03-10Die meisten Menschen denken bei Voice User Interfaces zuerst an Sprachassistenten wie Siri, Amazon Alexa oder Google Assistant. Tatsächlich sind Assistenten der einzige Kontext, in dem die meisten Menschen jemals Sprache verwendet haben, um mit einem Computersystem zu interagieren.
Während Sprachassistenten Sprachbenutzerschnittstellen in den Mainstream gebracht haben, ist das Assistentenparadigma nicht die einzige und nicht einmal die beste Möglichkeit, Sprachbenutzerschnittstellen zu verwenden, zu entwerfen und zu erstellen.
In diesem Artikel gehe ich auf die Probleme ein, unter denen Sprachassistenten leiden, und stelle einen neuen Ansatz für Sprachbenutzeroberflächen vor, den ich direkte Sprachinteraktionen nenne.
Sprachassistenten sind sprachbasierte Chatbots
Ein Sprachassistent ist eine Software, die anstelle von Symbolen und Menüs natürliche Sprache als Benutzeroberfläche verwendet. Assistenten beantworten normalerweise Fragen und versuchen oft proaktiv, dem Benutzer zu helfen.
Anstelle von einfachen Transaktionen und Befehlen imitieren Assistenten ein menschliches Gespräch und verwenden natürliche Sprache bidirektional als Interaktionsmodalität, was bedeutet, dass sie sowohl Eingaben vom Benutzer entgegennimmt als auch Antworten an den Benutzer unter Verwendung natürlicher Sprache verwendet.
Die ersten Assistenten waren dialogbasierte Frage-Antwort-Systeme. Ein frühes Beispiel ist Clippy von Microsoft, das versucht hat, Benutzern von Microsoft Office zu helfen, indem es ihnen Anweisungen gab, die darauf basierten, was der Benutzer seiner Meinung nach erreichen wollte. Ein typischer Anwendungsfall für das Assistenten-Paradigma sind heutzutage Chatbots, die häufig für den Kundensupport in einer Chat-Diskussion verwendet werden.
Sprachassistenten hingegen sind Chatbots, die Sprache statt Tippen und Text verwenden . Die Benutzereingabe besteht nicht aus Auswahlen oder Text, sondern aus Sprache, und die Antwort des Systems wird ebenfalls laut ausgesprochen. Diese Assistenten können allgemeine Assistenten wie Google Assistant oder Alexa sein, die eine Vielzahl von Fragen auf vernünftige Weise beantworten können, oder benutzerdefinierte Assistenten, die für einen speziellen Zweck wie Fast-Food-Bestellungen entwickelt wurden.
Obwohl die Eingabe des Benutzers oft nur aus ein oder zwei Wörtern besteht und als Auswahl statt als tatsächlicher Text dargestellt werden kann, werden die Konversationen mit der Weiterentwicklung der Technologie offener und komplexer . Das erste definierende Merkmal von Chatbots und Assistenten ist die Verwendung natürlicher Sprache und eines Konversationsstils anstelle von Symbolen, Menüs und Transaktionsstilen, die eine typische Benutzererfahrung einer mobilen App oder Website definieren.
Empfohlene Lektüre : Erstellen eines einfachen KI-Chatbots mit Web Speech API und Node.js
Das zweite definierende Merkmal, das sich aus den Antworten in natürlicher Sprache ergibt, ist die Illusion einer Persona. Der Ton, die Qualität und die Sprache, die das System verwendet, definieren sowohl die Assistentenerfahrung, die Illusion von Empathie und Servicebereitschaft als auch seine Persönlichkeit. Die Idee einer guten Assistentenerfahrung ist wie die Interaktion mit einer echten Person .
Da die Stimme für uns die natürlichste Art der Kommunikation ist, mag das großartig klingen, aber es gibt zwei große Probleme bei der Verwendung natürlicher Sprachantworten. Eines dieser Probleme, das damit zusammenhängt, wie gut Computer Menschen imitieren können, könnte in Zukunft mit der Entwicklung von Konversations-KI-Technologien behoben werden, aber das Problem, wie menschliche Gehirne mit Informationen umgehen, ist ein menschliches Problem, das in absehbarer Zeit nicht behoben werden kann. Sehen wir uns diese Probleme als nächstes an.
Zwei Probleme mit Antworten in natürlicher Sprache
Sprachbenutzerschnittstellen sind natürlich Benutzerschnittstellen, die Sprache als Modalität verwenden. Aber die Sprachmodalität kann für beide Richtungen verwendet werden: zum Eingeben von Informationen vom Benutzer und zum Ausgeben von Informationen vom System zurück an den Benutzer. Beispielsweise verwenden einige Aufzüge Sprachsynthese zum Bestätigen der Benutzerauswahl, nachdem der Benutzer eine Taste drückt. Wir werden später sprachliche Benutzerschnittstellen diskutieren, die nur Sprache zum Eingeben von Informationen verwenden und traditionelle grafische Benutzerschnittstellen verwenden, um die Informationen dem Benutzer wiederzugeben.
Sprachassistenten hingegen verwenden Sprache sowohl für die Eingabe als auch für die Ausgabe . Dieser Ansatz hat zwei Hauptprobleme:
Problem Nr. 1: Die Nachahmung eines Menschen schlägt fehl
Als Menschen haben wir eine angeborene Neigung, nichtmenschlichen Objekten menschenähnliche Merkmale zuzuschreiben. Wir sehen die Züge eines Mannes in einer vorbeiziehenden Wolke oder schauen auf ein Sandwich und es scheint, als würde es uns angrinsen. Dies nennt man Anthropomorphismus .

Dieses Phänomen gilt auch für Assistenten und wird durch ihre natürlichen Sprachantworten ausgelöst. Während eine grafische Benutzeroberfläche einigermaßen neutral aufgebaut sein kann, kann es unmöglich sein, dass ein Mensch nicht darüber nachdenkt, ob die Stimme einer jungen oder einer alten Person gehört oder ob sie männlich oder weiblich ist. Aus diesem Grund beginnt der Benutzer fast zu glauben, dass der Assistent tatsächlich ein Mensch ist.
Wir Menschen sind jedoch sehr gut darin, Fälschungen zu erkennen . Seltsamerweise beginnen uns die kleinen Abweichungen umso mehr zu stören, je näher etwas einem Menschen ähnelt. Es gibt ein Gefühl der Gruseligkeit gegenüber etwas, das versucht, menschlich zu sein, aber nicht ganz dem entspricht. In der Robotik und Computeranimation wird dies als „Uncanny Valley“ bezeichnet.

Je besser und menschlicher wir versuchen, den Assistenten zu gestalten, desto gruseliger und enttäuschender kann die Benutzererfahrung sein, wenn etwas schief geht. Jeder, der Assistenten ausprobiert hat, ist wahrscheinlich auf das Problem gestoßen, mit etwas zu antworten, das sich idiotisch oder sogar unhöflich anfühlt.
Das Uncanny Valley der Sprachassistenten stellt ein schwer zu überwindendes Qualitätsproblem in der Benutzererfahrung der Assistenten dar. Tatsächlich ist der Turing-Test (benannt nach dem berühmten Mathematiker Alan Turing) bestanden, wenn ein menschlicher Bewerter, der ein Gespräch zwischen zwei Agenten zeigt, nicht unterscheiden kann, welcher von ihnen eine Maschine und welcher ein Mensch ist. Bisher wurde es noch nie bestanden.
Das bedeutet, dass das Assistenten -Paradigma ein Versprechen eines menschenähnlichen Serviceerlebnisses verspricht , das niemals erfüllt werden kann und den Benutzer zwangsläufig enttäuschen wird. Die erfolgreichen Erfahrungen bauen nur die eventuelle Enttäuschung auf, wenn der Benutzer beginnt, seinem menschenähnlichen Assistenten zu vertrauen.
Problem 2: Sequentielle und langsame Interaktionen
Das zweite Problem von Sprachassistenten besteht darin, dass die rundenbasierte Natur von Antworten in natürlicher Sprache die Interaktion verzögert. Das liegt daran, wie unser Gehirn Informationen verarbeitet.
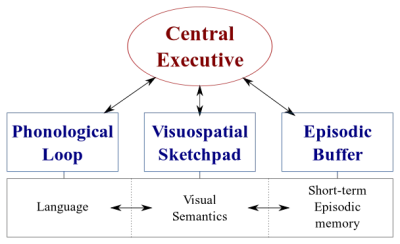
Es gibt zwei Arten von Datenverarbeitungssystemen in unserem Gehirn:
- Ein Sprachsystem , das Sprache verarbeitet;
- Ein visuell-räumliches System , das auf die Verarbeitung visueller und räumlicher Informationen spezialisiert ist.
Diese beiden Systeme können parallel betrieben werden, aber beide Systeme verarbeiten jeweils nur eine Sache . Aus diesem Grund können Sie gleichzeitig sprechen und Auto fahren, aber Sie können nicht schreiben und fahren, da beide Aktivitäten im visuell-räumlichen System stattfinden würden.

Wenn Sie mit dem Sprachassistenten sprechen, muss der Assistent in ähnlicher Weise leise bleiben und umgekehrt. Dadurch entsteht ein rundenbasiertes Gespräch , bei dem der andere Teil immer voll passiv ist.
Denke jedoch über ein schwieriges Thema nach, das du mit deinem Freund besprechen möchtest. Sie würden wahrscheinlich eher von Angesicht zu Angesicht als am Telefon diskutieren, oder? Das liegt daran, dass wir in einem persönlichen Gespräch nonverbale Kommunikation verwenden, um unserem Gesprächspartner in Echtzeit visuelles Feedback zu geben. Dies schafft eine bidirektionale Informationsaustauschschleife und ermöglicht es beiden Parteien, gleichzeitig aktiv am Gespräch teilzunehmen.
Assistenten geben kein visuelles Feedback in Echtzeit. Sie verlassen sich auf eine Technologie namens End-Pointing, um zu entscheiden, wann der Benutzer aufgehört hat zu sprechen und erst danach antwortet. Und wenn sie antworten, nehmen sie gleichzeitig keine Eingaben vom Benutzer entgegen. Die Erfahrung ist vollständig unidirektional und rundenbasiert.
In einem bidirektionalen und Echtzeit-Face-to-Face- Gespräch können beide Parteien sowohl auf visuelle als auch auf sprachliche Signale sofort reagieren. Dies nutzt die verschiedenen Informationsverarbeitungssysteme des menschlichen Gehirns und die Konversation wird reibungsloser und effizienter.
Sprachassistenten stecken im unidirektionalen Modus fest, weil sie natürliche Sprache sowohl als Eingabe- als auch als Ausgabekanal verwenden. Während die Sprache für die Eingabe bis zu viermal schneller ist als das Tippen, ist sie wesentlich langsamer zu verdauen als das Lesen. Da Informationen sequentiell verarbeitet werden müssen, funktioniert dieser Ansatz nur gut für einfache Befehle wie „Licht ausschalten“, die vom Assistenten nicht viel Aufwand erfordern.

Früher habe ich versprochen, Sprachbenutzerschnittstellen zu diskutieren, die Sprache nur zum Eingeben von Daten vom Benutzer verwenden. Diese Art von Sprachbenutzeroberflächen profitiert von den besten Seiten von Sprachbenutzeroberflächen – Natürlichkeit, Geschwindigkeit und Benutzerfreundlichkeit – leidet aber nicht unter den schlechten Seiten – Uncanny Valley und sequentielle Interaktionen
Betrachten wir diese Alternative.
Eine bessere Alternative zum Sprachassistenten
Die Lösung zur Überwindung dieser Probleme bei Sprachassistenten besteht darin, natürliche Sprachantworten loszulassen und sie durch visuelles Echtzeit-Feedback zu ersetzen. Das Umschalten auf visuelles Feedback ermöglicht es dem Benutzer, gleichzeitig Feedback zu geben und zu erhalten. Dadurch kann die Anwendung reagieren, ohne den Benutzer zu unterbrechen, und es wird ein bidirektionaler Informationsfluss ermöglicht. Da der Informationsfluss bidirektional ist, ist sein Durchsatz größer.
Derzeit sind die wichtigsten Anwendungsfälle für Sprachassistenten das Einstellen von Weckern, das Abspielen von Musik, das Überprüfen des Wetters und das Stellen einfacher Fragen. All dies sind Aufgaben mit geringem Einsatz , die den Benutzer nicht zu sehr frustrieren, wenn sie versagen.
Wie David Pierce vom Wall Street Journal einmal schrieb:
„Ich kann mir nicht vorstellen, einen Flug zu buchen oder mein Budget über einen Sprachassistenten zu verwalten oder meine Ernährung zu verfolgen, indem ich meinem Lautsprecher Zutaten zurufe.“
– David Pierce vom Wall Street Journal
Dies sind informationsintensive Aufgaben, die richtig ausgeführt werden müssen.
Irgendwann wird die Sprachbenutzeroberfläche jedoch fehlschlagen. Der Schlüssel ist, dies so schnell wie möglich zu decken. Viele Fehler passieren beim Tippen auf einer Tastatur oder sogar in einem persönlichen Gespräch. Dies ist jedoch überhaupt nicht frustrierend, da der Benutzer einfach auf die Rücktaste klicken und es erneut versuchen oder um Klärung bitten kann.
Diese schnelle Wiederherstellung nach Fehlern ermöglicht es dem Benutzer, effizienter zu sein, und zwingt ihn nicht zu einer seltsamen Unterhaltung mit einem Assistenten.
Direkte Sprachinteraktionen
In den meisten Anwendungen werden Aktionen durch Manipulieren grafischer Elemente auf dem Bildschirm, durch Anstupsen oder Wischen (auf Berührungsbildschirmen), Klicken mit einer Maus und/oder Drücken von Tasten auf einer Tastatur ausgeführt. Spracheingabe kann als zusätzliche Option oder Modalität zum Manipulieren dieser grafischen Elemente hinzugefügt werden. Diese Art der Interaktion kann als direkte Sprachinteraktion bezeichnet werden.
Der Unterschied zwischen direkter Sprachinteraktion und Assistenten besteht darin, dass der Benutzer, anstatt einen Avatar, den Assistenten, um eine Aufgabe zu bitten, die grafische Benutzeroberfläche direkt mit Sprache manipuliert.
„Ist das nicht Semantik?“, werden Sie vielleicht fragen. Wenn Sie mit dem Computer sprechen, spielt es wirklich eine Rolle, ob Sie direkt mit dem Computer oder über eine virtuelle Person sprechen? In beiden Fällen sprechen Sie nur mit einem Computer!
Ja, der Unterschied ist subtil, aber entscheidend. Beim Anklicken eines Buttons oder Menüpunktes in einem GUI ( G raphical U ser Interface) ist es unübersehbar, dass wir eine Maschine bedienen. Es gibt keine Illusion einer Person. Indem wir dieses Klicken durch einen Sprachbefehl ersetzen, verbessern wir die Mensch-Computer-Interaktion. Mit dem Assistenten-Paradigma hingegen schaffen wir eine verschlechterte Version der Mensch-zu-Mensch-Interaktion und reisen damit ins unheimliche Tal.
Das Einfügen von Sprachfunktionen in die grafische Benutzeroberfläche bietet auch das Potenzial, die Leistungsfähigkeit verschiedener Modalitäten zu nutzen. Während der Benutzer die Anwendung mit Sprache bedienen kann, hat er auch die Möglichkeit, die herkömmliche grafische Benutzeroberfläche zu verwenden. Dadurch kann der Benutzer nahtlos zwischen Berührung und Sprache wechseln und die beste Option basierend auf seinem Kontext und seiner Aufgabe auswählen.
Sprache ist beispielsweise eine sehr effiziente Methode zum Eingeben umfangreicher Informationen. Die Auswahl zwischen ein paar gültigen Alternativen, Berühren oder Klicken ist wahrscheinlich besser. Der Benutzer kann dann das Tippen und Blättern ersetzen, indem er etwas sagt wie „Zeige mir Flüge von London nach New York mit Abflug morgen“ und die beste Option aus der Liste durch Berühren auswählen.
Jetzt fragen Sie sich vielleicht: „OK, das sieht toll aus, warum haben wir also noch nie Beispiele für solche Sprachbenutzerschnittstellen gesehen? Warum entwickeln die großen Technologieunternehmen keine Tools für so etwas?“ Nun, dafür gibt es wahrscheinlich viele Gründe. Ein Grund dafür ist, dass das aktuelle Sprachassistenten-Paradigma wahrscheinlich der beste Weg für sie ist, die Daten, die sie von den Endbenutzern erhalten, zu nutzen. Ein weiterer Grund hat mit der Art und Weise zu tun, wie ihre Sprachtechnologie aufgebaut ist.
Eine gut funktionierende Sprachbenutzeroberfläche erfordert zwei verschiedene Teile:
- Spracherkennung , die Sprache in Text umwandelt;
- Komponenten zum Verständnis natürlicher Sprache, die Bedeutung aus diesem Text extrahieren.
Der zweite Teil ist die Magie, die die Äußerungen „Schalte das Licht im Wohnzimmer aus“ und „Bitte schalte das Licht im Wohnzimmer aus“ in dieselbe Aktion umwandelt.
Empfohlene Lektüre : So erstellen Sie mithilfe von API.AI Ihre eigene Aktion für Google Home
Wenn Sie jemals einen Assistenten mit Display (wie Siri oder Google Assistant) verwendet haben, ist Ihnen wahrscheinlich aufgefallen, dass Sie das Transkript nahezu in Echtzeit erhalten, aber nachdem Sie aufgehört haben zu sprechen, dauert es einige Sekunden, bevor das System angezeigt wird tatsächlich die von Ihnen angeforderte Aktion ausführt. Dies liegt daran, dass sowohl die Spracherkennung als auch das Verstehen natürlicher Sprache nacheinander stattfinden.
Mal sehen, wie man das ändern könnte.
Gesprochenes Sprachverständnis in Echtzeit: Die geheime Zutat für effizientere Sprachbefehle
Wie schnell eine Anwendung auf Benutzereingaben reagiert, ist ein wichtiger Faktor für die allgemeine Benutzererfahrung der Anwendung. Die wichtigste Neuerung des ursprünglichen iPhone war der extrem reaktionsschnelle und reaktive Touchscreen. Ebenso wichtig ist die Fähigkeit einer Sprachbenutzeroberfläche , sofort auf Spracheingaben zu reagieren .
Um eine schnelle bidirektionale Informationsaustauschschleife zwischen dem Benutzer und der Benutzeroberfläche einzurichten, sollte die sprachgesteuerte GUI in der Lage sein, sofort zu reagieren – sogar mitten im Satz – wenn der Benutzer etwas Umsetzbares sagt. Dies erfordert eine Technik, die als Streaming-Gesprochenes-Sprache-Verstehen bezeichnet wird.
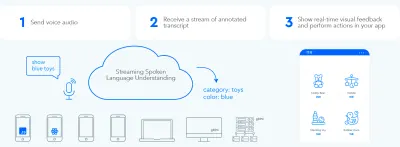
Im Gegensatz zu herkömmlichen rundenbasierten Sprachassistenzsystemen, die darauf warten, dass der Benutzer aufhört zu sprechen, bevor sie die Benutzeranfrage verarbeiten, versuchen Systeme, die das Verstehen von gesprochener Sprache per Streaming verwenden, aktiv, die Benutzerabsicht von dem Moment an zu verstehen, in dem der Benutzer zu sprechen beginnt. Sobald der Benutzer etwas Umsetzbares sagt, reagiert die Benutzeroberfläche sofort darauf.
Die sofortige Antwort bestätigt sofort, dass das System den Benutzer versteht, und ermutigt den Benutzer, fortzufahren. Es ist vergleichbar mit einem Nicken oder einem kurzen „a-ha“ in der Mensch-zu-Mensch-Kommunikation. Dadurch werden längere und komplexere Äußerungen unterstützt. Wenn das System den Benutzer nicht versteht oder der Benutzer sich falsch ausspricht, ermöglicht sofortiges Feedback eine schnelle Wiederherstellung . Der Benutzer kann sofort korrigieren und fortfahren oder sich sogar verbal selbst korrigieren: „Ich möchte dies, nein, ich meinte, ich möchte das.“ Sie können diese Art von Anwendung in unserer Sprachsuche-Demo selbst ausprobieren.
Wie Sie in der Demo sehen können, ermöglicht das visuelle Echtzeit-Feedback dem Benutzer, sich auf natürliche Weise zu korrigieren, und ermutigt ihn, mit dem Spracherlebnis fortzufahren. Da sie von einer virtuellen Persona nicht verwirrt werden, können sie sich auf mögliche Fehler ähnlich wie Tippfehler beziehen – nicht als persönliche Beleidigungen. Das Erlebnis ist schneller und natürlicher, da die dem Benutzer zugeführten Informationen nicht durch die typische Sprechgeschwindigkeit von etwa 150 Wörtern pro Minute begrenzt sind.
Empfohlene Lektüre : Designing Voice Experiences von Lyndon Cerejo
Schlussfolgerungen
Während Sprachassistenten bisher bei weitem die häufigste Verwendung für Sprachbenutzeroberflächen waren, macht die Verwendung von Antworten in natürlicher Sprache sie ineffizient und unnatürlich. Sprache ist eine großartige Modalität für die Eingabe von Informationen, aber einer Maschine zuzuhören, die spricht, ist nicht sehr inspirierend. Das ist das große Problem der Sprachassistenten.
Die Zukunft der Stimme sollte daher nicht in Gesprächen mit einem Computer liegen, sondern darin , mühsame Benutzeraufgaben durch die natürlichste Art der Kommunikation zu ersetzen : Sprache . Direkte Sprachinteraktionen können verwendet werden, um das Ausfüllen von Formularen in Web- oder Mobilanwendungen zu verbessern, bessere Sucherlebnisse zu schaffen und eine effizientere Möglichkeit zum Steuern oder Navigieren in einer Anwendung zu ermöglichen.
Designer und App-Entwickler suchen ständig nach Möglichkeiten, Reibungsverluste in ihren Apps oder Websites zu reduzieren . Die Verbesserung der aktuellen grafischen Benutzeroberfläche mit einer Sprachmodalität würde mehrfach schnellere Benutzerinteraktionen ermöglichen, insbesondere in bestimmten Situationen, z. B. wenn der Endbenutzer mobil und unterwegs ist und das Tippen schwierig ist. Tatsächlich kann die Sprachsuche bis zu fünfmal schneller sein als eine herkömmliche Suchfilter-Benutzeroberfläche, selbst wenn ein Desktop-Computer verwendet wird.
Wenn Sie das nächste Mal darüber nachdenken, wie Sie eine bestimmte Benutzeraufgabe in Ihrer Anwendung benutzerfreundlicher und angenehmer gestalten können, oder wenn Sie daran interessiert sind, die Conversions zu steigern, überlegen Sie, ob diese Benutzeraufgabe in natürlicher Sprache genau beschrieben werden kann. Wenn ja, ergänzen Sie Ihre Benutzeroberfläche mit einer Sprachmodalität, aber zwingen Sie Ihre Benutzer nicht , sich mit einem Computer zu unterhalten.
Ressourcen
- „Voice First im Vergleich zu den multimodalen Benutzeroberflächen der Zukunft“, Joan Palmiter Bajorek, UXmatters
- „Richtlinien zum Erstellen produktiver sprachgesteuerter Apps“, Hannes Heikinheimo, Speechly
- „6 Gründe, warum Ihre Touchscreen-Apps über Sprachfunktionen verfügen sollten“, Ottomatias Peura, UXmatters
- Materielles und immaterielles Mischen: Entwerfen multimodaler Schnittstellen mit Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD kann für Prototyping etwas Ähnliches sein ) - „Effizienz mit Schallgeschwindigkeit: Das Versprechen sprachgestützter Operationen“, Eric Turkington, RAIN
- Eine Demo, die visuelles Echtzeit-Feedback bei der Filterung der E-Commerce-Sprachsuche zeigt (Videoversion)
- Speechly bietet Entwicklertools für diese Art von Benutzeroberflächen
- Open-Source-Alternative: voice2json