
Eine Anleitung zur linearen Regression mit Scikit [mit Beispielen]
Veröffentlicht: 2021-06-18Es gibt im Allgemeinen zwei Arten von überwachten Lernalgorithmen: Regression und Klassifizierung mit der Vorhersage von kontinuierlichen und diskreten Ausgaben.
Der folgende Artikel behandelt die lineare Regression und ihre Implementierung unter Verwendung einer der beliebtesten Python-Bibliotheken für maschinelles Lernen, der Scikit-learn-Bibliothek. Tools für maschinelles Lernen und statistische Modelle sind in der Python-Bibliothek für Klassifizierung, Regression, Clustering und Dimensionsreduktion verfügbar. Die Bibliothek wurde in der Programmiersprache Python geschrieben und basiert auf den Python-Bibliotheken NumPy, SciPy und Matplotlib.
Inhaltsverzeichnis
Lineare Regression
Die lineare Regression führt die Aufgabe der Regression unter dem überwachten Lernverfahren durch. Basierend auf unabhängigen Variablen wird ein Zielwert vorhergesagt. Die Methode wird hauptsächlich zur Vorhersage und Identifizierung einer Beziehung zwischen den Variablen verwendet.
In der Algebra bedeutet der Begriff Linearität eine lineare Beziehung zwischen Variablen. Zwischen den Variablen wird in einem zweidimensionalen Raum eine Gerade abgeleitet.
Wenn eine Linie ein Diagramm zwischen den unabhängigen Variablen auf der X-Achse und den abhängigen Variablen auf der Y-Achse ist, wird durch lineare Regression eine gerade Linie erreicht, die am besten zu den Datenpunkten passt.
Die Geradengleichung hat die Form

Y = mx + b
Wobei b = abfangen
m= Steigung der Geraden
Daher durch lineare Regression
- Die optimalen Werte für den Achsenabschnitt und die Steigung werden in zwei Dimensionen bestimmt.
- Es gibt keine Änderung in den x- und y-Variablen, da sie die Datenmerkmale sind und daher gleich bleiben.
- Nur der Achsenabschnitt und die Steigungswerte können gesteuert werden.
- Es können mehrere gerade Linien basierend auf den Werten von Steigung und Schnittpunkt existieren, aber durch den Algorithmus der linearen Regression werden mehrere Linien an die Datenpunkte angepasst und die Linie mit dem geringsten Fehler wird zurückgegeben.
Lineare Regression mit Python
Für die Implementierung der linearen Regression in Python müssen die richtigen Pakete zusammen mit ihren Funktionen und Klassen angewendet werden. Das Paket NumPy in Python ist Open Source und erlaubt mehrere Operationen über die Arrays, sowohl ein- als auch mehrdimensionale Arrays.
Eine weitere weit verbreitete Bibliothek in Python ist Scikit-learn, die für Probleme mit maschinellem Lernen verwendet wird.
Scikit-learN
Die Scikit-learn-Bibliothek bietet den Entwicklern Algorithmen, die sowohl auf überwachtem als auch auf unüberwachtem Lernen basieren. Die Open-Source-Bibliothek von Python ist für Aufgaben des maschinellen Lernens konzipiert.
Die Datenwissenschaftler können die Daten importieren, vorverarbeiten, grafisch darstellen und mithilfe von scikit-learn Daten vorhersagen.
David Cournapeau entwickelte scikit-learn erstmals im Jahr 2007, und die Bibliothek ist seit Jahrzehnten gewachsen.
Von scikit-learn bereitgestellte Tools sind:
- Regression: Umfasst die logistische Regression und die lineare Regression
- Klassifizierung: Beinhaltet die Methode von K-Nearest Neighbors
- Auswahl eines Modells
- Clustering: Umfasst sowohl K-Means++ als auch K-Means
- Vorverarbeitung
Vorteile der Bibliothek sind:
- Das Erlernen und die Implementierung der Bibliothek sind einfach.
- Es ist eine Open-Source-Bibliothek und daher kostenlos.
- Aspekte des maschinellen Lernens können verdeckt werden, einschließlich Deep Learning.
- Es ist ein leistungsstarkes und vielseitiges Paket.
- Die Bibliothek verfügt über eine ausführliche Dokumentation.
- Eines der am häufigsten verwendeten Toolkits für maschinelles Lernen.
Importieren von scikit-learn
Das scikit-learn muss zuerst über pip oder über conda installiert werden.
- Anforderungen: 64-Bit-Version von Python 3 mit installierten Bibliotheken NumPy und Scipy. Auch für die Visualisierung von Datendiagrammen ist matplotlib erforderlich.
Installationsbefehl: pip install -U scikit-learn
Überprüfen Sie dann, ob die Installation abgeschlossen ist
Installation von Numpy, Scipy und matplotlib
Die Installation kann bestätigt werden durch:
Quelle
Lineare Regression durch Scikit-learn
Die Implementierung der linearen Regression durch das Paket scikit-learn umfasst die folgenden Schritte.
- Die Pakete und die benötigten Klassen sollen importiert werden.
- Daten werden benötigt, um mit den entsprechenden Transformationen zu arbeiten und diese auch durchzuführen.
- Es soll ein Regressionsmodell erstellt und mit den vorhandenen Daten angepasst werden.
- Die Modellanpassungsdaten müssen überprüft werden, um zu analysieren, ob das erstellte Modell zufriedenstellend ist.
- Vorhersagen sollen durch die Anwendung des Modells getroffen werden.
Das Paket NumPy und die Klasse LinearRegression sind aus dem sklearn.linear_model zu importieren.

Quelle
Die für die lineare Sklearn-Regression erforderlichen Funktionalitäten sind alle vorhanden, um die lineare Regression schließlich zu implementieren. Die Klasse sklearn.linear_model.LinearRegression wird zur Durchführung von Regressionsanalysen (sowohl linear als auch polynomial) und zur Durchführung von Vorhersagen verwendet.
Für alle maschinellen Lernalgorithmen und die lineare Regression von Scikit Learn muss der Datensatz zuerst importiert werden. Drei Optionen sind in Scikit-learn verfügbar, um die Daten zu erhalten:
- Datensätze wie die Iris-Klassifizierung oder der Regressionssatz für die Immobilienpreise von Boston.
- Datensätze der realen Welt können direkt über die vordefinierten Funktionen von Scikit-learn aus dem Internet heruntergeladen werden.
- Über den Scikit-Learn-Datengenerator kann ein Datensatz zufällig generiert werden, um ihn mit einem bestimmten Muster abzugleichen.
Unabhängig von der gewählten Option müssen die Moduldatensätze importiert werden.

Importieren Sie sklearn.datasets als Datensätze
1. Der Klassifikationssatz der Iris
iris = datasets.load_iris()
Die Datensatz-Iris wird als 2D-Array -Datenfeld von n_samples * n_features gespeichert. Der Import erfolgt als Objekt eines Wörterbuchs. Es enthält alle notwendigen Daten zusammen mit den Metadaten.
Die Funktionen DESCR, shape und _names können verwendet werden, um Beschreibungen und Formatierungen der Daten zu erhalten. Beim Drucken der Funktionsergebnisse werden die Informationen des Datensatzes angezeigt, die bei der Arbeit am Iris-Datensatz benötigt werden könnten.
Der folgende Code lädt die Informationen des Iris-Datensatzes.
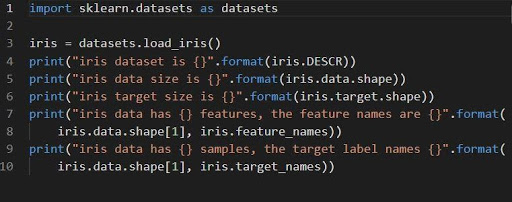
Quelle
2. Generierung von Regressionsdaten
Wenn keine eingebauten Daten benötigt werden, können die Daten über eine wählbare Verteilung generiert werden.
Generieren von Regressionsdaten mit einem Satz von 1 informativen Merkmal und 1 Merkmal.
X , Y = datasets.make_regression(n_features=1, n_informative=1)
Die generierten Daten werden in einem 2D-Datensatz mit den Objekten x, und y gespeichert. Die Eigenschaften der generierten Daten können durch Ändern von Parametern der Funktion make_regression verändert werden.
In diesem Beispiel werden die Parameter der informativen Merkmale und Merkmale von einem Standardwert von 10 auf 1 geändert.
Andere berücksichtigte Parameter sind die Proben und Ziele , wobei die Anzahl der verfolgten Ziel- und Probenvariablen gesteuert wird.
- Die Merkmale, die den Algorithmen von ML nützliche Informationen liefern, werden als informative Merkmale bezeichnet, während diejenigen, die nicht hilfreich sind, als nicht-informative Merkmale bezeichnet werden.
3. Plotten von Daten
Die Daten werden mit der matplotlib-Bibliothek geplottet. Zuerst muss die matplotlib importiert werden.
Importieren Sie matplotlib.pyplot als plt
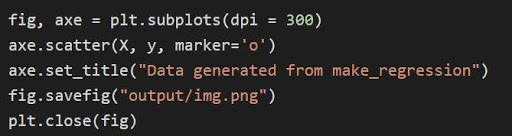
Das obige Diagramm wird durch den Code durch die Matplotlib gezeichnet
Quelle
Im obigen Code:
- Die Tupelvariablen werden entpackt und als separate Variablen in Zeile 1 des Codes gespeichert. Daher können die einzelnen Attribute manipuliert und gespeichert werden.
- Der Datensatz x, y wird verwendet, um ein Streudiagramm bis Zeile 2 zu generieren. Mit der Verfügbarkeit des Markierungsparameters in matplotlib wird die visuelle Darstellung verbessert, indem die Datenpunkte mit einem Punkt (o) markiert werden.
- Der Titel des generierten Diagramms wird in Zeile 3 festgelegt.
- Die Figur kann als .png-Bilddatei gespeichert werden und dann wird die aktuelle Figur geschlossen.
Das durch den obigen Code generierte Regressionsdiagramm ist
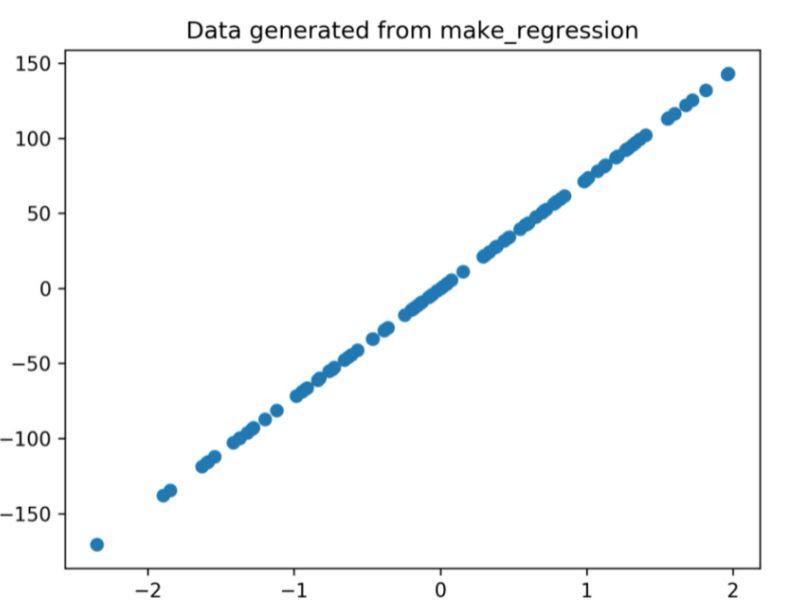
Abbildung 1: Das aus dem obigen Code generierte Regressionsdiagramm.
4. Implementieren des Algorithmus der linearen Regression
Unter Verwendung der Beispieldaten des Preises von Bostoner Wohnungen wird der Algorithmus der linearen Regression von Scikit-learn im folgenden Beispiel implementiert. Wie andere ML-Algorithmen wird der Datensatz importiert und dann mit den vorherigen Daten trainiert.
Die lineare Regressionsmethode wird von Unternehmen verwendet, da es sich um ein Vorhersagemodell handelt, das die Beziehung zwischen einer numerischen Größe und ihren Variablen zum Ausgabewert vorhersagt, wobei die Bedeutung in der Realität einen Wert hat.
Wenn ein Protokoll früherer Daten vorhanden ist, kann das Modell am besten angewendet werden, da es die zukünftigen Ergebnisse dessen vorhersagen kann, was in der Zukunft passieren wird, wenn sich das Muster fortsetzt.
Mathematisch können die Daten angepasst werden, um die Summe aller Residuen zu minimieren, die zwischen den Datenpunkten und dem vorhergesagten Wert vorhanden sind.
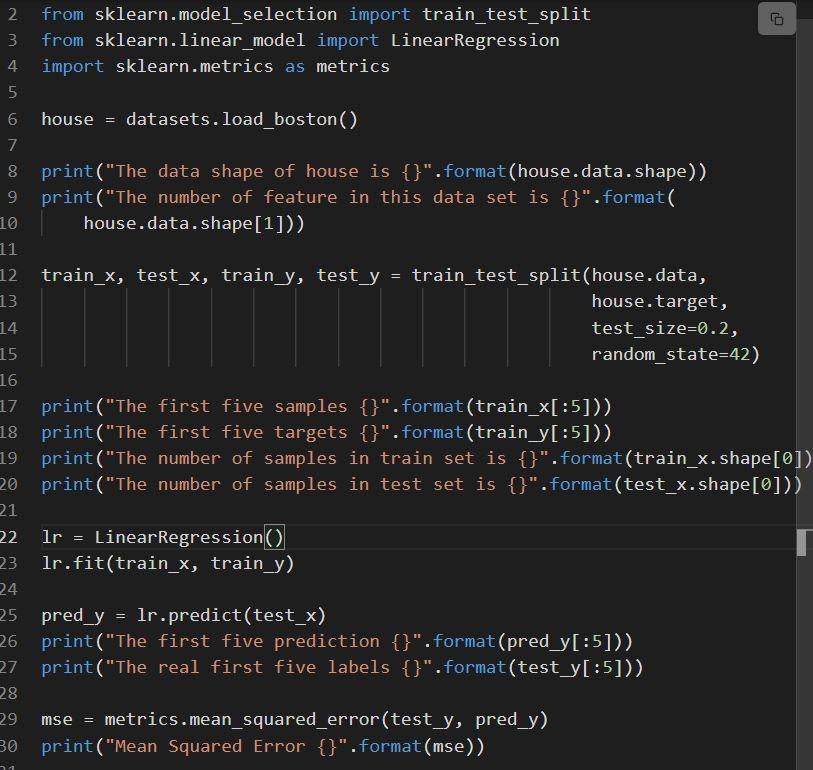
Das folgende Snippet zeigt die Implementierung der linearen Regression von Sklearn.
Quelle
Der Code wird wie folgt erklärt:
- Zeile 6 lädt den Datensatz namens load_boston.
- Der Datensatz wird in Zeile 12 aufgeteilt, dh der Trainingssatz mit 80 % Daten und der Testsatz mit 20 % Daten.
- Erstellung eines Modells der linearen Regression in Zeile 23 und anschließendes Training bei.
- Die Leistung des Modells wird in Zeile 29 durch Aufrufen von mean_squared_error bewertet.
Das lineare Regressionsdiagramm von Sklearn ist unten dargestellt:
Lineares Regressionsmodell der Stichprobendaten der Immobilienpreise in Boston
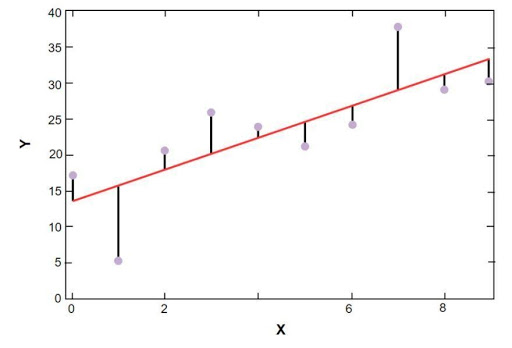
Quelle
In der obigen Abbildung stellt die rote Linie das lineare Modell dar, das für die Beispieldaten des Immobilienpreises in Boston gelöst wurde. Blaue Punkte stellen die ursprünglichen Daten dar und der Abstand zwischen der roten Linie und den blauen Punkten stellt die Summe der Residuen dar. Das Ziel des linearen Regressionsmodells von scikit-learn ist es, die Summe der Residuen zu reduzieren.
Fazit
Der Artikel diskutierte die lineare Regression und ihre Implementierung durch die Verwendung eines Open-Source-Python-Pakets namens scikit-learn. Inzwischen können Sie sich mit diesem Paket ein Konzept für die Implementierung der linearen Regression aneignen. Es lohnt sich zu lernen, wie Sie die Bibliothek für Ihre Datenanalyse verwenden.
Wenn Sie daran interessiert sind, das Thema weiter zu vertiefen, wie z. B. die Implementierung von Python-Paketen in maschinelles Lernen und KI-bezogene Probleme, können Sie den von upGrad angebotenen Kurs Master of Science in Machine Learning & AI besuchen. Der Kurs richtet sich an Berufseinsteiger im Alter von 21 bis 45 Jahren und zielt darauf ab, die Studenten in maschinellem Lernen durch mehr als 650 Stunden Online-Schulung, mehr als 25 Fallstudien und Aufgaben zu schulen. Der von der LJMU zertifizierte Kurs bietet die perfekte Beratung und Unterstützung bei der Jobvermittlung. Bei Fragen oder Anregungen hinterlassen Sie uns eine Nachricht, wir melden uns gerne bei Ihnen.