
ما هو التعلم الآلي باستخدام Java؟ كيف يتم تنفيذه؟
نشرت: 2021-03-10جدول المحتويات
ما هو التعلم الآلي؟
التعلم الآلي هو قسم من الذكاء الاصطناعي يتعلم من البيانات والأمثلة والخبرات المتاحة لتقليد السلوك البشري والذكاء. يمكن لأي برنامج تم إنشاؤه باستخدام التعلم الآلي بناء المنطق من تلقاء نفسه دون أن يضطر الإنسان إلى كتابة الكود يدويًا.
بدأ كل شيء مع اختبار تورينج في أوائل الخمسينيات من القرن الماضي عندما خلص آلان تورنج إلى أنه لكي يتمتع الكمبيوتر بذكاء حقيقي ، فإنه يحتاج إلى التلاعب أو إقناع الإنسان بأنه إنسان أيضًا. يعد التعلم الآلي مفهومًا قديمًا نسبيًا ، لكن هذا المجال الناشئ هو فقط اليوم خاضع للإدراك لأن أجهزة الكمبيوتر الآن يمكنها معالجة الخوارزميات المعقدة. تطورت خوارزميات التعلم الآلي على مدار العقد الماضي لتشمل المهارات الحسابية المعقدة والتي أدت بدورها إلى تعزيز قدرات المحاكاة الخاصة بها.
كما زادت تطبيقات التعلم الآلي بمعدل ينذر بالخطر. من الرعاية الصحية والتمويل والتحليلات والتعليم إلى التصنيع والتسويق والعمليات الحكومية ، شهدت كل صناعة زيادة كبيرة في الجودة والكفاءة بعد تطبيق تقنيات التعلم الآلي. كانت هناك تحسينات نوعية واسعة النطاق في جميع أنحاء العالم ، مما أدى إلى زيادة الطلب على المتخصصين في التعلم الآلي.
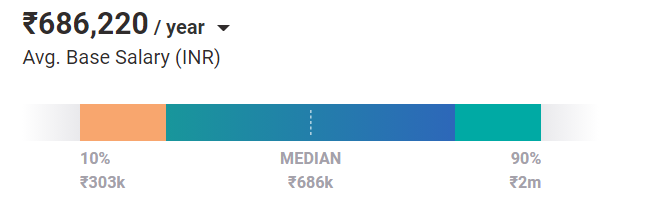
في المتوسط ، يستحق مهندسو التعلم الآلي راتبًا قدره 686،220 دولارًا في السنة اليوم. وهذا هو الحال بالنسبة لوظيفة مستوى الدخول. من خلال الخبرة والمهارات ، يمكنهم كسب ما يصل إلى 2 مليون دولار في السنة في الهند.
أنواع خوارزميات التعلم الآلي
تتكون خوارزميات التعلم الآلي من ثلاثة أنواع:
1. التعلم الخاضع للإشراف : في هذا النوع من التعلم ، توجه مجموعات بيانات التدريب خوارزمية لعمل تنبؤات دقيقة أو قرارات تحليلية. يستخدم التعلم من مجموعات بيانات التدريب السابقة لمعالجة البيانات الجديدة. فيما يلي بعض الأمثلة على نماذج التعلم الآلي للتعلم الخاضع للإشراف:

- الانحدارالخطي
- الانحدار اللوجستي
- شجرة القرار
2. التعلم غير الخاضع للإشراف : في هذا النوع من التعلم ، يتعلم نموذج التعلم الآلي من المعلومات غير المصنفة. يستخدم تجميع البيانات عن طريق تجميع الكائنات أو فهم العلاقة بينها ، أو استغلال خصائصها الإحصائية لإجراء التحليل. أمثلة على خوارزميات التعلم غير الخاضعة للرقابة هي:
- K- يعني التجميع
- المجموعات الهرمية
3. التعلم المعزز : تعتمد هذه العملية على الضرب والمحاكمة. إنه التعلم من خلال التفاعل مع الفضاء أو البيئة. تتعلم خوارزمية RL من تجاربها السابقة من خلال التفاعل مع البيئة وتحديد أفضل مسار للعمل.
كيف يتم تنفيذ التعلم الآلي باستخدام Java؟
تعد Java من بين أفضل لغات البرمجة المستخدمة لتنفيذ خوارزميات التعلم الآلي. معظم مكتباتها مفتوحة المصدر ، وتوفر دعمًا موسعًا للتوثيق ، وسهولة الصيانة ، وقابلية التسويق ، وسهولة القراءة.
بناءً على الشعبية ، إليك أفضل 10 مكتبات للتعلم الآلي تُستخدم لتنفيذ التعلم الآلي في Java.
1. آدمز
يهتم نظام التنقيب عن البيانات المتقدم والتعلم الآلي أو ADAMS ببناء أنظمة سير عمل جديدة ومرنة وإدارة العمليات المعقدة في العالم الحقيقي. تستخدم ADAMS بنية تشبه الشجرة لإدارة تدفق البيانات بدلاً من إجراء اتصالات الإدخال والإخراج اليدوية.
إنه يلغي أي حاجة لتوصيلات صريحة. وهو يقوم على مبدأ "الأقل هو الأكثر" ويؤدي عمليات الاسترجاع والتصور والتصورات القائمة على البيانات. ADAMS بارع في معالجة البيانات وتدفق البيانات وإدارة قواعد البيانات والبرمجة النصية والتوثيق.
2. JavaML
تقدم JavaML مجموعة متنوعة من خوارزميات ML واستخراج البيانات التي تمت كتابتها لجافا لدعم مهندسي البرمجيات والمبرمجين وعلماء البيانات والباحثين. كل خوارزمية لها واجهة مشتركة سهلة الاستخدام ولديها دعم توثيق شامل على الرغم من عدم وجود واجهة المستخدم الرسومية.
إنه بسيط ومباشر إلى حد ما للتنفيذ بالمقارنة مع خوارزميات التجميع الأخرى. تشمل ميزاته الأساسية معالجة البيانات والتوثيق وإدارة قواعد البيانات وتصنيف البيانات والتجميع واختيار الميزات وما إلى ذلك.
انضم إلى دورة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
3. WEKA
Weka هي أيضًا مكتبة تعلم آلي مفتوحة المصدر مكتوبة لجافا تدعم التعلم العميق. يوفر مجموعة من خوارزميات التعلم الآلي ويجد استخدامًا مكثفًا في استخراج البيانات ، وإعداد البيانات ، وتجميع البيانات ، وتصور البيانات ، والانحدار ، من بين عمليات البيانات الأخرى.
مثال: سوف نوضح ذلك باستخدام مجموعة بيانات صغيرة لمرض السكري.
الخطوة 1 : قم بتحميل البيانات باستخدام Weka
| استيراد weka.core.Instances ؛ استيراد weka.core.converters.ConverterUtils.DataSource ؛ فئة عامة رئيسية { يطرح (String [] args) public static void main استثناء { // تحديد مصدر البيانات DataSource dataSource = new DataSource (“data.arff”) ؛ // تحميل مجموعة البيانات مثيلات dataInstances = dataSource.getDataSet () ؛ // عرض عدد الحالات log.info ("عدد المثيلات المحملة هو:" + dataInstances.numInstances ())؛ log.info ("data:" + dataInstances.toString ()) ؛ } } |
الخطوة 2: تحتوي مجموعة البيانات على 768 مثيلاً. نحتاج إلى الوصول إلى عدد السمات ، أي 9.
| log.info ("عدد السمات (الميزات) في مجموعة البيانات:" + dataInstances.numAttributes ()) ؛ |
الخطوة 3 : نحتاج إلى تحديد العمود الهدف قبل إنشاء نموذج والعثور على عدد الفئات.
| // تحديد فهرس الملصق dataInstances.setClassIndex (dataInstances.numAttributes () - 1) ؛ // الحصول على عدد log.info ("عدد الفئات:" + dataInstances.numClasses ())؛ |
الخطوة 4 : سنقوم الآن ببناء النموذج باستخدام مصنف شجرة بسيط ، J48.
| // إنشاء مصنف شجرة قرار J48 treeClassifier = جديد J48 () ؛ treeClassifier.setOptions (سلسلة جديدة [] {"-U"}) ؛ treeClassifier.buildClassifier (dataInstances) ؛ |
يسلط الرمز أعلاه الضوء على كيفية إنشاء شجرة غير مضبوطة تتكون من مثيلات البيانات المطلوبة لتدريب النموذج. بمجرد طباعة هيكل الشجرة بعد تدريب النموذج ، يمكننا تحديد كيفية بناء القواعد داخليًا.
| البلاس <= 127 | الكتلة <= 26.4 | | preg <= 7: اختبار سلبي (117.0 / 1.0) | | preg> 7 | | | الكتلة <= 0: تم اختباره_إيجابية (2.0) | | | الكتلة> 0: سلبية مختبرة (13.0) | الكتلة> 26.4 | | العمر <= 28: اختبار سلبي (180.0 / 22.0) | | العمر> 28 | | | plas <= 99: اختبار سلبي (55.0 / 10.0) | | | plas> 99 | | | | بيدي <= 0.56: اختبار سلبي (84.0 / 34.0) | | | | بيدي> 0.56 | | | | | preg <= 6 | | | | | | العمر <= 30: اختبار إيجابي (4.0) | | | | | | العمر> 30 | | | | | | | العمر <= 34: اختبار سلبي (7.0 / 1.0) | | | | | | | العمر> 34 | | | | | | | | الكتلة <= 33.1: اختبارها إيجابي (6.0) | | | | | | | | الكتلة> 33.1: اختبار سلبي (4.0 / 1.0) | | | | | preg> 6: تم اختباره_إيجابي (13.0) البلاس> 127 | الكتلة <= 29.9 | | plas <= 145: اختبار سلبي (41.0 / 6.0) | | البلاس> 145 | | | العمر <= 25: اختبار سلبي (4.0) | | | العمر> 25 | | | | العمر <= 61 | | | | | الكتلة <= 27.1: مختبرة إيجابية (12.0 / 1.0) | | | | | الكتلة> 27.1 | | | | | | بريس <= 82 | | | | | | | بيدي <= 0.396: اختبار_إيجابي (8.0 / 1.0)  | | | | | | | بيدي> 0.396: اختبار سلبي (3.0) | | | | | | عرض> 82: اختبار سلبي (4.0) | | | | العمر> 61: اختبار سلبي (4.0) | الكتلة> 29.9 | | البلاس <= 157 | | | عرض <= 61: تم اختباره_إيجابي (15.0 / 1.0) | | | بريس> 61 | | | | العمر <= 30: اختبار سلبي (40.0 / 13.0) | | | | العمر> 30: تم اختباره - إيجابي (60.0 / 17.0) | | plas> 157: تم اختباره_إيجابي (92.0 / 12.0) عدد الأوراق: 22 حجم الشجرة: 43 |
4. أباتشي ماهاوت
Mahaut عبارة عن مجموعة من الخوارزميات للمساعدة في تنفيذ التعلم الآلي باستخدام Java. إنه إطار عمل للجبر الخطي قابل للتطوير يمكن للمطورين من خلاله تنفيذ الرياضيات وتحليلات الإحصائيين. يتم استخدامه عادةً من قبل علماء البيانات ومهندسي الأبحاث ومحترفي التحليلات لإنشاء تطبيقات جاهزة للمؤسسات. تسمح قابليته للتوسع والمرونة للمستخدمين بتنفيذ تجميع البيانات وأنظمة التوصية وإنشاء تطبيقات تعلم الآلة عالية الأداء بسرعة وسهولة.
5. Deeplearning4j
Deeplearning4j هي مكتبة برمجة مكتوبة بلغة Java وتقدم دعمًا مكثفًا للتعلم العميق. إنه إطار مفتوح المصدر يجمع بين الشبكات العصبية العميقة والتعلم المعزز العميق لخدمة العمليات التجارية. وهو متوافق مع Scala و Kotlin و Apache Spark و Hadoop ولغات JVM الأخرى وأطر حوسبة البيانات الضخمة.
يتم استخدامه عادةً لاكتشاف الأنماط والعواطف في الصوت والكلام والنص المكتوب. إنه بمثابة أداة DIY يمكنها اكتشاف التناقضات في المعاملات ، والتعامل مع مهام متعددة. إنها مكتبة موزعة من الدرجة التجارية تحتوي على وثائق مفصلة لواجهة برمجة التطبيقات نظرًا لطبيعتها مفتوحة المصدر.
فيما يلي مثال لكيفية تنفيذ التعلم الآلي باستخدام Deeplearning4j.
مثال : باستخدام Deeplearning4j ، سنقوم ببناء نموذج Convolution Neural Network (CNN) لتصنيف الأرقام المكتوبة بخط اليد بمساعدة مكتبة MNIST.
الخطوة 1 : قم بتحميل مجموعة البيانات لعرض حجمها.
| DataSetIterator MNISTTrain = new MnistDataSetIterator (batchSize، true، seed)؛ DataSetIterator MNISTTest = new MnistDataSetIterator (batchSize، false، seed) ؛ |
الخطوة 2 : تأكد من أن مجموعة البيانات تعطينا عشرة تسميات فريدة.
| log.info ("عدد الملصقات الإجمالية الموجودة في مجموعة بيانات التدريب" + MNISTTrain.totalOutcomes ()) ؛ log.info ("عدد الملصقات الإجمالية الموجودة في مجموعة بيانات الاختبار" + MNISTTest.totalOutcomes ()) ؛ |
الخطوة 3 : الآن ، سنقوم بتكوين بنية النموذج باستخدام طبقتين التفاف مع طبقة مسطحة لعرض المخرجات.
هناك خيارات في Deeplearning4j تسمح لك بتهيئة مخطط الوزن.
| // بناء نموذج سي إن إن MultiLayerConfiguration conf = جديد NeuralNetConfiguration.Builder () .seed (seed) // بذور عشوائية .l2 (0.0005) // تسوية .weightInit (WeightInit.XAVIER) // تهيئة مخطط الوزن .updater (New Adam (1e-3)) // إعداد خوارزمية التحسين .قائمة() .layer (new ConvolutionLayer.Builder (5، 5) // ضبط الخطوة وحجم النواة ووظيفة التنشيط. .nIn (nChannels) .stride (1،1) .nOut (20) .activation (Activation.IDENTITY) .يبني()) .layer (new SubsamplingLayer.Builder (PoolingType.MAX) // اختزال الالتواء . kernel الحجم (2،2) .stride (2،2) .يبني()) .layer (new ConvolutionLayer.Builder (5، 5) // ضبط الخطوة وحجم النواة ووظيفة التنشيط. .stride (1،1) .nOut (50) .activation (Activation.IDENTITY) .يبني()) .layer (new SubsamplingLayer.Builder (PoolingType.MAX) // اختزال الالتواء . kernel الحجم (2،2) .stride (2،2) .يبني()) .layer (new DenseLayer.Builder (). التنشيط (Activation.RELU) .nOut (500) .build ()) .layer (جديد OutputLayer.Builder (LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut (outputNum) .activation (Activation.SOFTMAX) .يبني()) // الطبقة النهائية هي 28 × 28 بعمق 1. .setInputType (InputType.convolutionalFlat (28،28،1)) .يبني()؛ |
الخطوة 4 : بعد تكوين البنية ، سنقوم بتهيئة الوضع ومجموعة بيانات التدريب ، ونبدأ تدريب النموذج.
| نموذج MultiLayerNetwork = MultiLayerNetwork جديد (conf) ؛ // تهيئة أوزان النموذج. model.init () ؛ log.info ("الخطوة 2: ابدأ تدريب النموذج") ؛ // إعداد مستمع كل 10 تكرارات وتقييم مجموعة الاختبار في كل فترة model.setListeners (جديد ScoreIterationListener (10) ، جديد EvaluativeListener (MNISTTest ، 1 ، InvocationType.EPOCH_END)) ؛ // تدريب النموذج model.fit (MNISTTrain ، nEpochs) ؛ |
مع بدء تدريب النموذج ، سيكون لديك مصفوفة الارتباك الخاصة بدقة التصنيف.
ها هي دقة النموذج بعد عشر فترات تدريب:
| ========================= مصفوفة الارتباك ======================= == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0879 1 0 1 1 | 5 = 5 4 2 0 0 1 1949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2962 2 | 8 = 8 0 2 0 2 11 2 0 3 2987 | 9 = 9 |
6. الكي
بيئة تطوير تطبيقات KDD المدعومة ببنية الفهرس أو ELKI عبارة عن مجموعة من الخوارزميات والبرامج المدمجة المستخدمة في استخراج البيانات. تمت كتابتها بلغة Java ، وهي مكتبة مفتوحة المصدر تشتمل على معلمات قابلة للتكوين بدرجة عالية في الخوارزميات. يتم استخدامه عادةً من قبل علماء البحث والطلاب لاكتساب نظرة ثاقبة لمجموعات البيانات. كما يوحي الاسم ، فإنه يوفر بيئة لتطوير برامج وقواعد بيانات معقدة للتنقيب عن البيانات باستخدام بنية فهرس.
7. JSAT
أداة التحليل الإحصائي Java أو JSAT هي مكتبة GPL3 تستخدم إطار عمل موجه للكائنات لمساعدة المستخدمين على تنفيذ التعلم الآلي باستخدام Java. يتم استخدامه عادةً لأغراض التعليم الذاتي من قبل الطلاب والمطورين. بالمقارنة مع مكتبات تنفيذ الذكاء الاصطناعي الأخرى ، فإن JSAT لديه أكبر عدد من خوارزميات ML وهو الأسرع بين جميع الأطر. مع عدم وجود تبعيات خارجية ، فهي مرنة وفعالة للغاية وتوفر أداءً عاليًا.
8. إطار عمل تعلم الآلة Encog
تمت كتابة Encog بلغة Java و C # ويتضمن مكتبات تساعد في تنفيذ خوارزميات التعلم الآلي. يتم استخدامه لبناء الخوارزميات الجينية وشبكات Bayesian والنماذج الإحصائية مثل Hidden Markov Model والمزيد.
9. مطرقة
يستخدم التعلم الآلي لمجموعة أدوات اللغة أو ماليت في معالجة اللغة الطبيعية (NLP). مثل معظم أطر تنفيذ ML الأخرى ، يوفر Mallet أيضًا دعمًا لنمذجة البيانات وتجميع البيانات ومعالجة المستندات وتصنيف المستندات وما إلى ذلك.
10. شرارة MLlib
يتم استخدام Spark MLlib من قبل الشركات لتعزيز كفاءة إدارة سير العمل وقابليتها للتوسع. يعالج كميات وفيرة من البيانات ويدعم خوارزميات ML ذات التحميل الثقيل.
الخروج: أفكار مشروع التعلم الآلي
خاتمة
هذا يقودنا إلى نهاية المقال. لمزيد من المعلومات حول مفاهيم التعلم الآلي ، تواصل مع أعضاء هيئة التدريس الأعلى في IIIT Bangalore وجامعة Liverpool John Moores من خلال برنامج upGrad's Master of Science in Machine Learning & AI.
لماذا يجب علينا استخدام Java جنبًا إلى جنب مع التعلم الآلي؟
سيجد محترفو التعلم الآلي أنه من الأسهل التعامل مع مستودعات الأكواد الحالية إذا اختاروا Java كلغة برمجة لمشاريعهم. إنها لغة مفضلة لتعلم الآلة نظرًا لميزات مثل سهولة الاستخدام وخدمات الحزم وتفاعل أفضل للمستخدم وتصحيح الأخطاء السريع والتوضيح الرسومي للبيانات. تسهل Java على مطوري التعلم الآلي توسيع نطاق أنظمتهم ، مما يجعلها خيارًا ممتازًا لإنشاء تطبيقات تعلم الآلة الكبيرة والمعقدة من الألف إلى الياء. تدعم Java Virtual Machine (JVM) عددًا من بيئات التطوير المتكاملة (IDEs) التي تسمح لمتعلمي الآلة بتصميم أدوات جديدة بسرعة.
هل تعلم جافا أمر سهل؟
نظرًا لأن Java لغة عالية المستوى ، فمن السهل فهمها. بصفتك متعلمًا ، لن تضطر إلى الخوض في الكثير من التفاصيل لأنها لغة جيدة التنظيم وموجهة نحو الكائنات وبسيطة بما يكفي للمبتدئين لالتقاطها. نظرًا لوجود العديد من الإجراءات التي تعمل تلقائيًا ، يمكنك إتقانها بسرعة. ليس عليك الخوض في تفاصيل كبيرة حول كيفية عمل الأشياء هناك. Java هي لغة برمجة مستقلة عن النظام الأساسي. يمكّن المبرمج من إنشاء تطبيق جوال يمكن استخدامه على أي جهاز. إنها اللغة المفضلة لإنترنت الأشياء ، فضلاً عن أنها أفضل أداة لتطوير التطبيقات على مستوى المؤسسة.
ما هو ADAMS ، وكيف يكون مفيدًا في التعلم الآلي؟
يعد نظام التنقيب عن البيانات المتقدم والتعلم الآلي (ADAMS) محرك سير عمل مرخص له من قبل GPLv3 لإنشاء وإدارة تدفقات العمل القائمة على البيانات والتفاعلية والتي يمكن دمجها بسهولة في العمليات التجارية. محرك سير العمل ، الذي يتبع مبدأ الأقل هو الأكثر ، يقع في قلب ADAMS. يستخدم ADAMS بنية تشبه الشجرة بدلاً من السماح للمستخدم بترتيب المشغلين (أو الممثلين بلغة ADAMS) على لوحة قماشية ثم ربط المدخلات والمخرجات يدويًا. لا توجد اتصالات صريحة مطلوبة لأن هذا الهيكل والجهات الفاعلة الضابطة تحدد كيفية تدفق البيانات في العملية. ينتج عن تمثيل الكائن الداخلي وتداخل عامل التشغيل الفرعي داخل معالجات المشغل بنية تشبه الشجرة. يوفر ADAMS مجموعة متنوعة من الوكلاء لاسترجاع البيانات ومعالجتها وتعدينها وعرضها.