
الدليل النهائي لبناء كاشطات الويب القابلة للتطوير باستخدام Scrapy
نشرت: 2022-03-10يعد تجريف الويب طريقة للحصول على البيانات من مواقع الويب دون الحاجة إلى الوصول إلى واجهات برمجة التطبيقات أو قاعدة بيانات موقع الويب. ما عليك سوى الوصول إلى بيانات الموقع - طالما أن متصفحك يمكنه الوصول إلى البيانات ، فستتمكن من التخلص منها.
من الناحية الواقعية ، يمكنك في معظم الأوقات تصفح موقع الويب يدويًا والحصول على البيانات "يدويًا" باستخدام النسخ واللصق ، ولكن في كثير من الحالات ، قد يستغرق ذلك عدة ساعات من العمل اليدوي ، مما قد يكلفك أكثر بكثير مما تستحقه البيانات ، خاصة إذا كنت قد وظفت شخصًا للقيام بالمهمة نيابة عنك. لماذا تستأجر شخصًا للعمل في دقيقة إلى دقيقتين لكل استعلام بينما يمكنك الحصول على برنامج لإجراء استعلام تلقائيًا كل بضع ثوانٍ؟
على سبيل المثال ، لنفترض أنك ترغب في تجميع قائمة بالفائزين بجائزة الأوسكار لأفضل صورة ، جنبًا إلى جنب مع المخرج والممثلين النجميين وتاريخ الإصدار ووقت التشغيل. باستخدام Google ، يمكنك أن ترى أن هناك العديد من المواقع التي ستدرج هذه الأفلام بالاسم ، وربما بعض المعلومات الإضافية ، ولكن بشكل عام سيتعين عليك المتابعة من خلال الروابط لالتقاط جميع المعلومات التي تريدها.
من الواضح أنه سيكون غير عملي ويستغرق وقتًا طويلاً لتصفح كل رابط من عام 1927 حتى اليوم ومحاولة العثور على المعلومات يدويًا من خلال كل صفحة. باستخدام تجريف الويب ، نحتاج فقط إلى العثور على موقع ويب به صفحات تحتوي على كل هذه المعلومات ، ثم توجيه برنامجنا في الاتجاه الصحيح بالإرشادات الصحيحة.
في هذا البرنامج التعليمي ، سوف نستخدم ويكيبيديا كموقع الويب الخاص بنا لأنه يحتوي على جميع المعلومات التي نحتاجها ثم نستخدم Scrapy على Python كأداة لكشف معلوماتنا.
بعض المحاذير قبل أن نبدأ:
يتضمن تجريف البيانات زيادة تحميل الخادم للموقع الذي تقوم بكشطه ، مما يعني ارتفاع تكلفة الشركات التي تستضيف الموقع وتجربة جودة أقل للمستخدمين الآخرين لهذا الموقع. جودة الخادم الذي يقوم بتشغيل موقع الويب ، وكمية البيانات التي تحاول الحصول عليها ، والمعدل الذي ترسل به الطلبات إلى الخادم ستعمل على تعديل التأثير الذي لديك على الخادم. مع وضع ذلك في الاعتبار ، نحتاج إلى التأكد من أننا نلتزم ببعض القواعد.
تحتوي معظم المواقع أيضًا على ملف يسمى robots.txt في دليلها الرئيسي. يحدد هذا الملف قواعد الدلائل التي لا تريد مواقع الدلائل الوصول إليها. عادةً ما تتيح لك صفحة الشروط والأحكام الخاصة بالموقع الإلكتروني معرفة سياستهم بشأن تجريف البيانات. على سبيل المثال ، تحتوي صفحة شروط IMDB على الجملة التالية:
الروبوتات وكشط الشاشة: لا يجوز لك استخدام التنقيب عن البيانات أو الروبوتات أو كشط الشاشة أو أدوات مماثلة لجمع البيانات واستخراجها على هذا الموقع ، إلا بموافقتنا الكتابية الصريحة كما هو مذكور أدناه.
قبل أن نحاول الحصول على بيانات موقع الويب ، يجب علينا دائمًا التحقق من شروط موقع الويب و robots.txt للتأكد من حصولنا على البيانات القانونية. عند بناء أدوات الكشط ، نحتاج أيضًا إلى التأكد من أننا لا نثقل كاهل الخادم بالطلبات التي لا يمكنه التعامل معها.
لحسن الحظ ، تدرك العديد من مواقع الويب حاجة المستخدمين إلى الحصول على البيانات ، وتوفر البيانات من خلال واجهات برمجة التطبيقات. إذا كانت هذه متوفرة ، فعادة ما يكون الحصول على البيانات من خلال واجهة برمجة التطبيقات أسهل بكثير من الحصول عليها من خلال الكشط.
تسمح Wikipedia بكشط البيانات ، طالما أن الروبوتات لا تسير "بسرعة كبيرة جدًا" ، كما هو محدد في robots.txt الخاص بهم. كما أنها توفر مجموعات بيانات قابلة للتنزيل حتى يتمكن الأشخاص من معالجة البيانات على أجهزتهم الخاصة. إذا ذهبنا بسرعة كبيرة ، فستقوم الخوادم تلقائيًا بحظر عنوان IP الخاص بنا ، لذلك سنقوم بتطبيق أجهزة ضبط الوقت من أجل الالتزام بقواعدها.
الشروع في العمل ، تثبيت المكتبات ذات الصلة باستخدام Pip
بادئ ذي بدء ، دعنا نثبت Scrapy.
شبابيك
قم بتثبيت أحدث إصدار من Python من https://www.python.org/downloads/windows/
ملاحظة: سيحتاج مستخدمو Windows أيضًا إلى Microsoft Visual C ++ 14.0 ، والذي يمكنك الحصول عليه من "Microsoft Visual C ++ Build Tools" هنا.
ستحتاج أيضًا إلى التأكد من أن لديك أحدث إصدار من النقطة.
في cmd.exe ، اكتب:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyسيؤدي هذا إلى تثبيت Scrapy وجميع التبعيات تلقائيًا.
لينكس
أولاً ، سترغب في تثبيت جميع التبعيات:
في Terminal ، أدخل:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devبمجرد تثبيت كل شيء ، فقط اكتب:
pip install --upgrade pipللتأكد من تحديث النقطة ، ثم:
pip install scrapyوقد تم كل شيء.
ماك
ستحتاج أولاً إلى التأكد من أن لديك مترجم c على نظامك. في Terminal ، أدخل:
xcode-select --installبعد ذلك ، قم بتثبيت homebrew من https://brew.sh/.
قم بتحديث متغير PATH بحيث يتم استخدام حزم البيرة المنزلية قبل حزم النظام:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcتثبيت Python:
brew install pythonثم تأكد من تحديث كل شيء:
brew update; brew upgrade pythonبعد الانتهاء من ذلك ، ما عليك سوى تثبيت Scrapy باستخدام النقطة:
pip install Scrapy > ## نظرة عامة على Scrapy ، كيف تتناسب القطع معًا ، المحللون ، العناكب ، إلخستكتب نصًا يسمى "العنكبوت" لتشغيل Scrapy ، لكن لا تقلق ، فالعناكب Scrapy ليست مخيفة على الإطلاق على الرغم من اسمها. التشابه الوحيد بين العناكب Scrapy والعناكب الحقيقية هو أنها تحب الزحف على الويب.
يوجد داخل العنكبوت class تحددها تخبر Scrapy بما يجب القيام به. على سبيل المثال ، من أين تبدأ الزحف ، وأنواع الطلبات التي يقدمها ، وكيفية متابعة الروابط على الصفحات ، وكيف يتم تحليل البيانات. يمكنك أيضًا إضافة وظائف مخصصة لمعالجة البيانات أيضًا ، قبل إعادة إخراجها إلى ملف.
لبدء أول عنكبوت لدينا ، نحتاج أولاً إلى إنشاء مشروع Scrapy. للقيام بذلك ، أدخل هذا في سطر الأوامر الخاص بك:
scrapy startproject oscarsسيؤدي ذلك إلى إنشاء مجلد بمشروعك.
سنبدأ مع عنكبوت أساسي. يجب إدخال الكود التالي في برنامج نصي من Python. افتح برنامجًا نصيًا جديدًا للبيثون في /oscars/spiders وقم oscars_spider.py
سنقوم باستيراد سكرابي.
import scrapyثم نبدأ في تحديد فئة العنكبوت لدينا. أولاً ، قمنا بتعيين الاسم ثم المجالات التي يُسمح للعنكبوت بكشطها. أخيرًا ، نخبر العنكبوت من أين يبدأ الكشط.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']بعد ذلك ، نحتاج إلى وظيفة تلتقط المعلومات التي نريدها. في الوقت الحالي ، سنحصل فقط على عنوان الصفحة. نستخدم CSS للعثور على العلامة التي تحمل نص العنوان ، ثم نستخرجها. أخيرًا ، نعيد المعلومات مرة أخرى إلى Scrapy ليتم تسجيلها أو كتابتها في ملف.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data الآن احفظ الكود في /oscars/spiders/oscars_spider.py
لتشغيل هذا العنكبوت ، انتقل ببساطة إلى سطر الأوامر واكتب:
scrapy crawl oscarsيجب أن ترى ناتجًا مثل هذا:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
تهانينا ، لقد قمت ببناء أول مكشطة Scrapy أساسية!

الكود الكامل:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataمن الواضح أننا نريده أن يفعل أكثر قليلاً ، لذلك دعونا ننظر في كيفية استخدام Scrapy لتحليل البيانات.
أولاً ، دعنا نتعرف على صدفة Scrapy. يمكن أن يساعدك Scrapy shell في اختبار التعليمات البرمجية الخاصة بك للتأكد من أن Scrapy يستحوذ على البيانات التي تريدها.
للوصول إلى shell ، أدخل هذا في سطر الأوامر:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”سيؤدي هذا بشكل أساسي إلى فتح الصفحة التي وجهتها إليها وسيتيح لك تشغيل أسطر واحدة من التعليمات البرمجية. على سبيل المثال ، يمكنك عرض HTML الخام للصفحة عن طريق كتابة:
print(response.text)أو افتح الصفحة في متصفحك الافتراضي عن طريق كتابة:
view(response)هدفنا هنا هو العثور على الكود الذي يحتوي على المعلومات التي نريدها. في الوقت الحالي ، دعنا نحاول الحصول على أسماء عناوين الفيلم فقط.
أسهل طريقة للعثور على الكود الذي نحتاجه هي فتح الصفحة في متصفحنا وفحص الكود. في هذا المثال ، أستخدم Chrome DevTools. فقط انقر بزر الماوس الأيمن على عنوان أي فيلم وحدد "فحص":
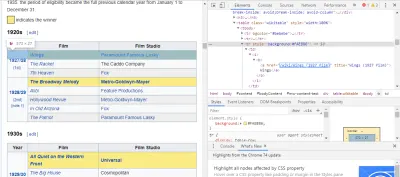
كما ترون ، يمتلك الفائزون بالأوسكار خلفية صفراء بينما يتمتع المرشحون بخلفية بسيطة. يوجد أيضًا رابط للمقال حول عنوان الفيلم ، وتنتهي روابط الأفلام film) . الآن بعد أن عرفنا ذلك ، يمكننا استخدام محدد CSS للحصول على البيانات. في غلاف Scrapy ، اكتب:
response.css(r"tr[] a[href*='film)']").extract()كما ترى ، لديك الآن قائمة بجميع الفائزين بجائزة الأوسكار!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']بالعودة إلى هدفنا الرئيسي ، نريد قائمة بالفائزين بجائزة الأوسكار لأفضل صورة ، جنبًا إلى جنب مع مخرجهم ، والممثلين ، وتاريخ الإصدار ، ووقت التشغيل. للقيام بذلك ، نحتاج إلى Scrapy للحصول على البيانات من كل صفحة من صفحات الأفلام هذه.
سيتعين علينا إعادة كتابة بعض الأشياء وإضافة وظيفة جديدة ، ولكن لا تقلق ، فالأمر بسيط جدًا.
سنبدأ ببدء الكاشطة بنفس الطريقة السابقة.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] لكن هذه المرة ، سيتغير شيئان. أولاً ، سنقوم باستيراد time جنبًا إلى جنب مع scrapy لأننا نريد إنشاء مؤقت لتقييد سرعة كشط الروبوت. أيضًا ، عندما نقوم بتحليل الصفحات في المرة الأولى ، نريد فقط الحصول على قائمة بالارتباطات لكل عنوان ، حتى نتمكن من الحصول على معلومات من تلك الصفحات بدلاً من ذلك.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req هنا نقوم بعمل حلقة للبحث عن كل رابط في الصفحة التي تنتهي film) مع الخلفية الصفراء فيه ثم نقوم بضم هذه الروابط معًا في قائمة عناوين URL ، والتي سنرسلها إلى الوظيفة parse_titles لتمرير المزيد. كما نقوم أيضًا بإدخال مؤقت حتى يطلب الصفحات كل 5 ثوانٍ فقط. تذكر أنه يمكننا استخدام Scrapy shell لاختبار حقول response.css الخاصة بنا للتأكد من حصولنا على البيانات الصحيحة!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data يتم إنجاز العمل الحقيقي في دالة parse_data بنا ، حيث نقوم بإنشاء قاموس يسمى data ثم نملأ كل مفتاح بالمعلومات التي نريدها. مرة أخرى ، تم العثور على كل هذه المحددات باستخدام Chrome DevTools كما هو موضح سابقًا ثم تم اختبارها باستخدام غلاف Scrapy.
يعرض السطر الأخير قاموس البيانات مرة أخرى إلى Scrapy لتخزينه.
كود كامل:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataفي بعض الأحيان نرغب في استخدام الوكلاء حيث ستحاول مواقع الويب منع محاولاتنا في إلغاء الاشتراك.
للقيام بذلك ، نحتاج فقط إلى تغيير بعض الأشياء. باستخدام مثالنا ، في def parse() ، نحتاج إلى تغييره إلى ما يلي:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqسيؤدي هذا إلى توجيه الطلبات من خلال الخادم الوكيل الخاص بك.
النشر والتسجيل ، اعرض كيفية إدارة العنكبوت بالفعل في الإنتاج
حان الوقت الآن لتشغيل عنكبوتنا. لجعل Scrapy يبدأ في الكشط ثم الإخراج إلى ملف CSV ، أدخل ما يلي في موجه الأوامر:
scrapy crawl oscars -o oscars.csvسترى ناتجًا كبيرًا ، وبعد دقيقتين ، سيكتمل وسيكون لديك ملف CSV موجود في مجلد المشروع الخاص بك.
تجميع النتائج ، وضح كيفية استخدام النتائج المجمعة في الخطوات السابقة
عندما تفتح ملف CSV ، سترى جميع المعلومات التي أردناها (مرتبة حسب الأعمدة ذات العناوين). انها حقا بهذه البساطة.
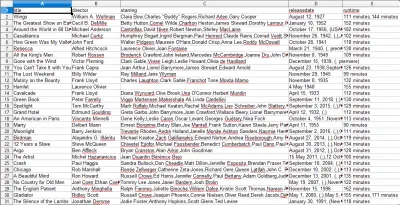
باستخدام تجريف البيانات ، يمكننا الحصول على أي مجموعة بيانات مخصصة نريدها تقريبًا ، طالما أن المعلومات متاحة للجمهور. ما تريد القيام به بهذه البيانات متروك لك. هذه المهارة مفيدة للغاية لإجراء أبحاث السوق ، والحفاظ على تحديث المعلومات على موقع الويب ، وأشياء أخرى كثيرة.
من السهل إلى حد ما إعداد مكشطة الويب الخاصة بك للحصول على مجموعات بيانات مخصصة بنفسك ، ومع ذلك ، تذكر دائمًا أنه قد تكون هناك طرق أخرى للحصول على البيانات التي تحتاجها. تستثمر الشركات كثيرًا في توفير البيانات التي تريدها ، لذلك من العدل أن نحترم شروطها وأحكامها.
موارد إضافية لتعلم المزيد عن Scrapy و Web Scraping بشكل عام
- موقع سكرابى الرسمي
- صفحة Scrapy's GitHub
- "أفضل 10 أدوات لاستخراج البيانات وأدوات تجريف الويب" ، Scraper API
- "5 نصائح لكشط الويب دون أن يتم حظره أو وضعه في القائمة السوداء" ، Scraper API
- Parsel ، مكتبة Python لاستخدام التعبيرات العادية لاستخراج البيانات من HTML.