
أهم 15 سؤالاً وأجوبة لمقابلة Hadoop في عام 2022
نشرت: 2021-01-09مع اكتساب تحليلات البيانات زخمًا ، كان هناك ارتفاع في طلب الأشخاص الجيدين في التعامل مع البيانات الضخمة. من محللي البيانات إلى علماء البيانات ، تقوم البيانات الضخمة بإنشاء مجموعة من ملفات تعريف الوظائف اليوم. أول وأهم شيء تتوقع أن تتعلمه هو Hadoop.
بغض النظر عن الوظيفة / الملف الشخصي ، فمن المحتمل أنك ستعمل على Hadoop بطريقة أو بأخرى. لذلك ، يمكنك دائمًا أن تتوقع من المحاورين أن يطلقوا بعض أسئلة Hadoop على طريقتك.
لذلك وأكثر ، دعنا نلقي نظرة على أفضل 15 سؤالاً من أسئلة مقابلة Hadoop التي يمكن توقعها في أي مقابلة تجلس من أجلها.
ما هو Hadoop؟ ما هي المكونات الأساسية Hadoop؟
Hadoop هي بنية تحتية مجهزة بالأدوات والخدمات ذات الصلة المطلوبة لمعالجة البيانات الكبيرة وتخزينها. على وجه الدقة ، Hadoop هو "الحل" لجميع تحديات البيانات الضخمة. علاوة على ذلك ، يساعد إطار عمل Hadoop أيضًا المؤسسات على تحليل البيانات الضخمة واتخاذ قرارات أعمال أفضل.
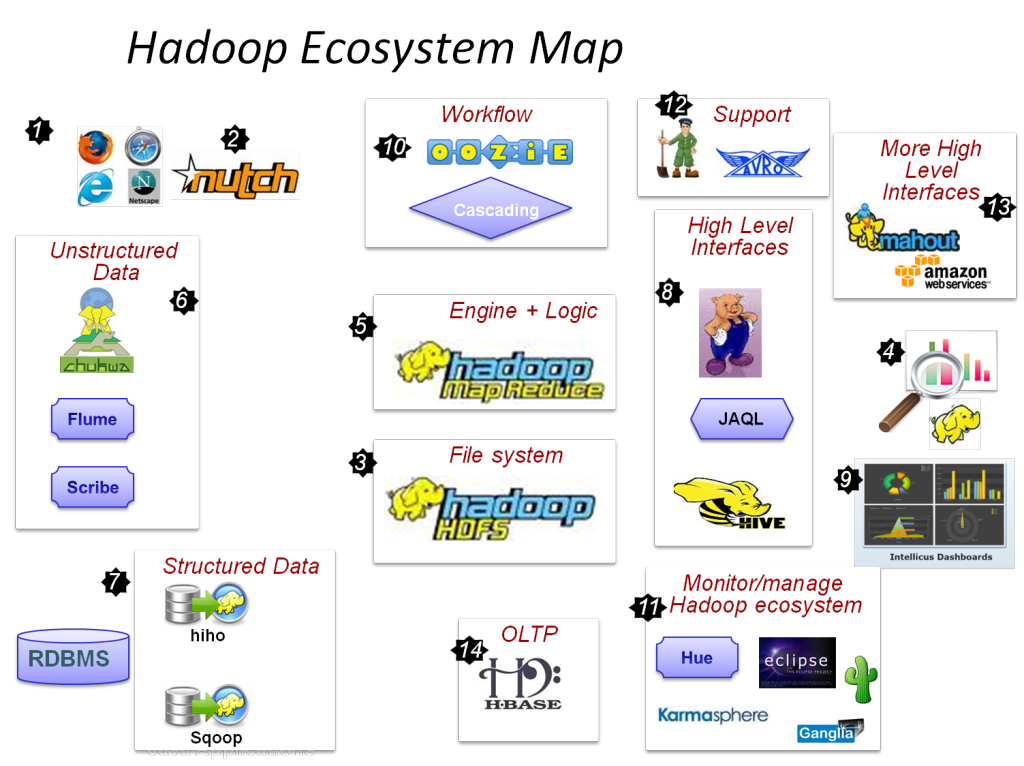
المكونات الأساسية لـ Hadoop هي:
- HDFS
- Hadoop MapReduce
- Hadoop المشتركة
- غزل
- PIG و HIVE - مكونات الوصول إلى البيانات.
- HBase - لتخزين البيانات
- Ambari و Oozie و ZooKeeper - مكون إدارة البيانات والمراقبة
- مكونات Thrift and Avro - Data Serialization
- Apache Flume و Sqoop و Chukwa - مكونات تكامل البيانات
- Apache Mahout and Drill - مكونات استخبارات البيانات
ما هي المفاهيم الأساسية لإطار Hadoop؟
يعتمد Hadoop بشكل أساسي على مفهومين أساسيين. هم انهم:
- HDFS: HDFS أو Hadoop Distributed File System هو نظام ملفات موثوق به يعتمد على Java ويستخدم لتخزين مجموعات البيانات الضخمة في تنسيق الكتلة. العمارة السيد والعبد تدعمها.
- MapReduce: MapReduce هي بنية برمجة تساعد في معالجة مجموعات البيانات الكبيرة. يتم تقسيم هذه الوظيفة بشكل أكبر إلى جزأين - بينما تفصل "الخريطة" مجموعات البيانات إلى مجموعات ، يستخدم "تقليل" مجموعات الخريطة وينشئ مجموعة من مجموعات أصغر من المجموعات.
هل تريد تسمية أكثر تنسيقات الإدخال شيوعًا في Hadoop؟
هناك ثلاثة تنسيقات إدخال شائعة في Hadoop:
- تنسيق إدخال النص: هذا هو تنسيق الإدخال الافتراضي في Hadoop.
- تنسيق إدخال ملف التسلسل: يستخدم تنسيق الإدخال هذا لقراءة الملفات بالتسلسل.
- تنسيق إدخال قيمة المفتاح: يستخدم هذا الخيار لقراءة ملفات النص العادي.
ما هو الغزل؟
YARN هو اختصار لعبارة "مفاوض موارد آخر". إن إطار معالجة البيانات في Hadoop هو الذي يدير موارد البيانات ويخلق بيئة للمعالجة الناجحة. 
ما هو "رف الوعي"؟
"الوعي بالأرفف" هو خوارزمية يستخدمها NameNode لتحديد النمط الذي يتم فيه تخزين كتل البيانات ونسخها المتماثلة داخل مجموعة Hadoop. يتم تحقيق ذلك بمساعدة تعريفات الحامل التي تقلل الازدحام بين عقد البيانات الموجودة في نفس الرف.

ما هي عُقد الاسم النشطة والخاملة؟
عادةً ما يحتوي نظام Hadoop عالي التوفر على اثنين من NameNode - Active NameNode و Passive NameNode.
يسمى NameNode الذي يقوم بتشغيل كتلة Hadoop بـ Active NameNode و NameNode في وضع الاستعداد الذي يخزن بيانات Active NameNode هو Passive NameNode.
الغرض من وجود اثنين من NameNodes هو أنه في حالة تعطل Active NameNode ، يمكن أن تتولى Passive NameNode القيادة. وبالتالي ، فإن NameNode تعمل دائمًا في الكتلة ، ولا يفشل النظام أبدًا.
ما هي برامج الجدولة المختلفة في إطار عمل Hadoop؟
هناك ثلاثة برامج جدولة مختلفة في إطار عمل Hadoop:
- COSHH - يساعد COSHH في جدولة القرارات من خلال مراجعة المجموعة وعبء العمل جنبًا إلى جنب مع عدم التجانس.
- مجدول FIFO - يصطف FIFO الوظائف في قائمة انتظار بناءً على وقت وصولهم ، دون استخدام عدم التجانس.
- المشاركة العادلة - تُنشئ المشاركة العادلة مجموعة للمستخدمين الفرديين تحتوي على خرائط متعددة وتقليل الفتحات الموجودة على أحد الموارد التي يمكنهم استخدامها لتنفيذ مهام محددة.
ما هو التنفيذ التخميني؟
غالبًا في إطار Hadoop ، قد تعمل بعض العقد بشكل أبطأ من البقية. هذا يميل إلى تقييد البرنامج بأكمله. للتغلب على هذا ، يكتشف Hadoop أولاً أو "يتكهن" عندما تعمل المهمة بشكل أبطأ من المعتاد ، ثم يقوم بتشغيل نسخة احتياطية مكافئة لتلك المهمة. لذلك ، في هذه العملية ، تنفذ العقدة الرئيسية كلا من المهام في وقت واحد ويتم قبول أيهما تم الانتهاء منه أولاً بينما يتم قتل الآخر. تُعرف ميزة النسخ الاحتياطي لبرنامج Hadoop باسم التنفيذ التخميني.

هل تريد تسمية المكونات الرئيسية لـ Apache HBase؟
يتكون Apache HBase من ثلاثة مكونات:
- خادم المنطقة: بعد تقسيم الجدول إلى مناطق متعددة ، يتم إعادة توجيه مجموعات هذه المناطق إلى العملاء عبر خادم المنطقة.
- HMaster: هذه أداة تساعد في إدارة وتنسيق خادم المنطقة.
- ZooKeeper: ZooKeeper هو منسق داخل بيئة HBase الموزعة. يساعد في الحفاظ على حالة الخادم داخل الكتلة من خلال الاتصال في الجلسات.
ما هو "التفتيش"؟ وما فائدته؟
يشير Checkpointing إلى الإجراء الذي يتم من خلاله دمج FsImage وسجل التحرير لتشكيل FsImage جديد. وبالتالي ، بدلاً من إعادة تشغيل سجل التحرير ، يمكن لـ NameNode تحميل الحالة النهائية للذاكرة مباشرةً من FsImage. تعتبر NameNode الثانوية مسؤولة عن هذه العملية.
الميزة التي يقدمها Checkpointing هي أنه يقلل من وقت بدء تشغيل NameNode ، مما يجعل العملية بأكملها أكثر كفاءة.
تطبيقات البيانات الضخمة في الثقافة الشعبية
كيفية تصحيح كود Hadoop؟
لتصحيح أخطاء كود Hadoop ، أولاً ، تحتاج إلى التحقق من قائمة مهام MapReduce التي تعمل حاليًا. ثم تحتاج إلى التحقق مما إذا كانت أي مهام معزولة تعمل في وقت واحد أم لا. إذا كان الأمر كذلك ، فأنت بحاجة إلى العثور على موقع سجلات إدارة الموارد باتباع الخطوات البسيطة التالية:
قم بتشغيل “ps –ef | grep –I ResourceManager "وفي النتيجة المعروضة ، حاول معرفة ما إذا كان هناك خطأ متعلق بمعرف وظيفة معين.
الآن ، حدد العقدة العاملة التي تم استخدامها لتنفيذ المهمة. قم بتسجيل الدخول إلى العقدة وتشغيل “ps –ef | grep –iNodeManager. "
أخيرًا ، قم بفحص سجل Node Manager. يتم إنشاء معظم الأخطاء من السجلات على مستوى المستخدم لكل مهمة تقليل الخريطة.
ما هو الغرض من RecordReader في Hadoop؟
يقوم Hadoop بتقسيم البيانات إلى تنسيقات حظر. يساعد RecordReader في دمج كتل البيانات هذه في سجل واحد يمكن قراءته. على سبيل المثال ، إذا تم تقسيم بيانات الإدخال إلى كتلتين -
الصف 1 - مرحبًا بك في
الصف 2 - UpGrad
سيقرأ RecordReader هذا كـ "مرحبًا بك في UpG rad."
ما هي الأوضاع التي يمكن لـ Hadoop تشغيلها؟
الأوضاع التي يمكن لـ Hadoop تشغيلها هي:
- وضع Standalone - هذا هو الوضع الافتراضي لـ Hadoop الذي يتم استخدامه لغرض التصحيح. لا يدعم HDFS.
- الوضع الموزع الزائف - يتطلب هذا الوضع تكوين ملفات mapred-site.xml و core-site.xml و hdfs-site.xml. كل من Master و Slave Node متماثلان هنا.
- الوضع الموزع بالكامل - الوضع الموزع بالكامل هو مرحلة إنتاج Hadoop حيث يتم توزيع البيانات عبر العقد المختلفة على مجموعة Hadoop. هنا ، يتم تخصيص العقد الرئيسية والعقد التابعة بشكل منفصل.
قم بتسمية بعض التطبيقات العملية لبرنامج Hadoop.
فيما يلي بعض الأمثلة الواقعية التي يحدث فيها Hadoop فرقًا:
- إدارة حركة المرور في الشوارع
- كشف الاحتيال والوقاية منه
- تحليل بيانات العملاء في الوقت الفعلي لتحسين خدمة العملاء
- الوصول إلى البيانات الطبية غير المنظمة من الأطباء ومقدمي الرعاية الصحية وغيرهم لتحسين خدمات الرعاية الصحية.
ما هي أدوات Hadoop الحيوية التي يمكنها تحسين أداء البيانات الضخمة؟
أدوات Hadoop التي تعزز أداء البيانات الضخمة بشكل كبير هي

• خلية نحل
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• سحاب
• أفرو
• فلوم
• حارس حديقة الحيوان
مهندسو البيانات الضخمة: الخرافات مقابل الحقائق
خاتمة
يجب أن تكون أسئلة مقابلة Hadoop هذه مفيدة للغاية لك في مقابلتك القادمة. في حين أنه في بعض الأحيان يميل المحاورون إلى تحريف بعض أسئلة مقابلة Hadoop ، فلا ينبغي أن تكون مشكلة بالنسبة لك إذا كان لديك فرز أساسياتك.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.