
توقع سوق الأسهم باستخدام التعلم الآلي [التنفيذ خطوة بخطوة]
نشرت: 2021-02-26جدول المحتويات
مقدمة
يعد التنبؤ والتحليل لسوق الأوراق المالية من أكثر المهام تعقيدًا التي يجب القيام بها. هناك عدة أسباب لذلك ، مثل تقلب السوق والعديد من العوامل الأخرى المستقلة والمستقلة لتحديد قيمة سهم معين في السوق. هذه العوامل تجعل من الصعب جدًا على أي محلل في سوق الأوراق المالية التنبؤ بالصعود والهبوط بدرجات دقة عالية.
ومع ذلك ، مع ظهور التعلم الآلي وخوارزمياته القوية ، بدأت أحدث تحليلات السوق وتطورات توقعات سوق الأوراق المالية في دمج هذه التقنيات في فهم بيانات سوق الأوراق المالية.
باختصار ، يتم استخدام خوارزميات التعلم الآلي على نطاق واسع من قبل العديد من المؤسسات في تحليل قيم الأسهم والتنبؤ بها. يجب أن تخضع هذه المقالة لعملية تنفيذ بسيطة لتحليل قيم مخزون متجر بيع بالتجزئة عبر الإنترنت شهير عبر الإنترنت والتنبؤ بها باستخدام العديد من خوارزميات التعلم الآلي في Python.
عرض المشكلة
قبل أن ندخل في تنفيذ البرنامج للتنبؤ بقيم سوق الأوراق المالية ، دعونا نتخيل البيانات التي سنعمل عليها. هنا ، سنقوم بتحليل قيمة أسهم شركة Microsoft Corporation (MSFT) من الرابطة الوطنية لعروض الأسعار الآلية لتجار الأوراق المالية (NASDAQ). سيتم تقديم بيانات قيمة المخزون في شكل ملف مفصول بفاصلة (.csv) ، والذي يمكن فتحه وعرضه باستخدام Excel أو جدول بيانات.
تم تسجيل مخزون MSFT في بورصة ناسداك ويتم تحديث قيمها خلال كل يوم عمل في سوق الأوراق المالية. لاحظ أن السوق لا يسمح بالتداول في أيام السبت والأحد ؛ ومن ثم هناك فجوة بين التاريخين. لكل تاريخ ، يتم تدوين القيمة الافتتاحية للمخزون ، القيم الأعلى والأدنى لهذا المخزون في نفس الأيام ، جنبًا إلى جنب مع قيمة الإغلاق في نهاية اليوم.
تُظهر قيمة الإغلاق المعدلة قيمة السهم بعد ترحيل توزيعات الأرباح (تقنية للغاية!). بالإضافة إلى ذلك ، يتم أيضًا تحديد الحجم الإجمالي للأسهم في السوق ، باستخدام هذه البيانات ، الأمر متروك لعمل التعلم الآلي / عالم البيانات لدراسة البيانات وتنفيذ العديد من الخوارزميات التي يمكنها استخراج أنماط من الأسهم التاريخية لشركة Microsoft Corporation بيانات.

ذاكرة طويلة المدى
لتطوير نموذج التعلم الآلي للتنبؤ بأسعار أسهم شركة Microsoft ، سنستخدم تقنية الذاكرة طويلة المدى (LSTM). يتم استخدامها لإجراء تعديلات صغيرة على المعلومات عن طريق الضرب والإضافات. بحكم التعريف ، الذاكرة طويلة المدى (LSTM) هي بنية شبكة عصبية اصطناعية متكررة (RNN) مستخدمة في التعلم العميق.
على عكس الشبكات العصبية القياسية للتغذية الأمامية ، فإن LSTM لديها اتصالات تغذية مرتدة. يمكنه معالجة نقاط البيانات الفردية (مثل الصور) وتسلسلات البيانات بالكامل (مثل الكلام أو الفيديو). لفهم المفهوم الكامن وراء LSTM ، دعنا نأخذ مثالًا بسيطًا لمراجعة العميل عبر الإنترنت للهاتف المحمول.
لنفترض أننا نريد شراء الهاتف المحمول ، فإننا عادة ما نشير إلى صافي التقييمات من قبل المستخدمين المعتمدين. بناءً على تفكيرهم ومدخلاتهم ، نقرر ما إذا كان الهاتف المحمول جيدًا أم سيئًا ثم نشتريه. بينما نواصل قراءة التعليقات ، نبحث عن كلمات رئيسية مثل "مذهلة" و "كاميرا جيدة" و "أفضل بطارية احتياطية" والعديد من المصطلحات الأخرى المتعلقة بالهاتف المحمول.
نميل إلى تجاهل الكلمات الشائعة في اللغة الإنجليزية مثل "هو" ، "أعطى" ، "هذا" ، إلخ. وهكذا ، عندما نقرر شراء الهاتف المحمول أم لا ، نتذكر فقط الكلمات الرئيسية المحددة أعلاه. على الأرجح ، ننسى الكلمات الأخرى.
هذه هي نفس الطريقة التي تعمل بها خوارزمية الذاكرة طويلة المدى. يتذكر فقط المعلومات ذات الصلة ويستخدمها لعمل تنبؤات تتجاهل البيانات غير ذات الصلة. بهذه الطريقة ، يتعين علينا بناء نموذج LSTM يتعرف بشكل أساسي على البيانات الأساسية فقط حول هذا المخزون ويتجاهل قيمه المتطرفة.
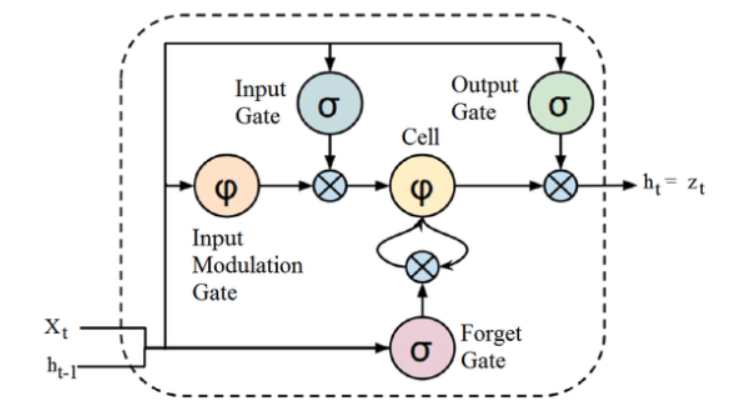
مصدر
على الرغم من أن الهيكل الموضح أعلاه لهندسة LSTM قد يبدو مثيرًا للفضول في البداية ، إلا أنه يكفي أن نتذكر أن LSTM هو نسخة متقدمة من الشبكات العصبية المتكررة التي تحتفظ بالذاكرة لمعالجة تسلسل البيانات. يمكنه إزالة أو إضافة معلومات إلى حالة الخلية ، يتم تنظيمها بعناية بواسطة هياكل تسمى البوابات.
تتكون وحدة LSTM من خلية وبوابة إدخال وبوابة إخراج وبوابة نسيان. تتذكر الخلية القيم على فترات زمنية عشوائية ، وتنظم البوابات الثلاثة تدفق المعلومات داخل الخلية وخارجها.
تنفيذ البرنامج
سننتقل إلى الجزء الذي وضعنا فيه LSTM قيد الاستخدام في التنبؤ بقيمة المخزون باستخدام التعلم الآلي في Python.
الخطوة 1 - استيراد المكتبات
كما نعلم جميعًا ، فإن الخطوة الأولى هي استيراد المكتبات الضرورية للمعالجة المسبقة لبيانات المخزون لشركة Microsoft Corporation والمكتبات الأخرى المطلوبة لبناء وتصور مخرجات نموذج LSTM. لهذا ، سوف نستخدم مكتبة Keras ضمن إطار TensorFlow. يتم استيراد الوحدات المطلوبة من مكتبة Keras بشكل فردي.
# استيراد المكتبات
استيراد الباندا كـ PD
استيراد NumPy كـ np
٪ matplotlib مضمنة
استيراد matplotlib. pyplot مثل plt
استيراد matplotlib
من sklearn. معالجة الاستيراد المسبق MinMaxScaler
من كراس. طبقات استيراد LSTM ، كثيفة ، تسرب
من sklearn.model_selection استيراد TimeSeriesSplit
من sklearn.metrics import mean_squared_error، r2_score
استيراد matplotlib. التواريخ كولايات
من sklearn. معالجة الاستيراد المسبق MinMaxScaler
من sklearn استيراد linear_model
من كراس. نماذج استيراد متسلسلة
من كراس. طبقات استيراد كثيفة
استيراد كراس. الخلفية مثل K.
من كراس. استيراد عمليات الاسترجاعات EarlyStopping
من كراس. محسنون استيراد آدم
من كراس. نماذج استيراد load_model
من كراس. طبقات استيراد LSTM
من كراس. useds.vis_utils استيراد plot_model
الخطوة 2 - الحصول على تصور للبيانات
باستخدام مكتبة قارئ بيانات Pandas ، سنقوم بتحميل بيانات مخزون النظام المحلي كملف قيم مفصولة بفاصلة (.csv) وتخزينها في pandas DataFrame. أخيرًا ، سنقوم أيضًا بعرض البيانات.
# احصل على مجموعة البيانات
df = pd.read_csv (“MicrosoftStockData.csv”، na_values = ['null']، index_col = 'Date'، parse_dates = True، infer_datetime_format = True)
df.head ()
احصل على شهادة AI عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادة المتقدم في ML & AI لتسريع حياتك المهنية.
الخطوة 3 - اطبع شكل DataFrame وتحقق من القيم الخالية.
في هذه الخطوة الحاسمة الأخرى ، نطبع أولاً شكل مجموعة البيانات. للتأكد من عدم وجود قيم فارغة في إطار البيانات ، نتحقق منها. يميل وجود القيم الفارغة في مجموعة البيانات إلى التسبب في مشاكل أثناء التدريب لأنها تعمل كقيم متطرفة تسبب تباينًا كبيرًا في عملية التدريب.
# اطبع شكل إطار البيانات وتحقق من القيم الخالية
طباعة ("شكل إطار البيانات:" ، شكل df)
print (“Null Value Present:”، df.IsNull (). values.any ())
>> شكل إطار البيانات: (7334، 6)
>> قيمة خالية: خطأ
| تاريخ | افتح | متوسط | قليل | يغلق | أضف إغلاق | الصوت |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
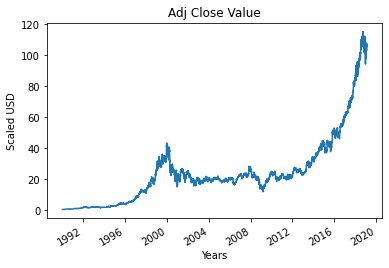
الخطوة 4 - رسم القيمة القريبة الحقيقية المعدلة
قيمة الإخراج النهائية التي سيتم توقعها باستخدام نموذج التعلم الآلي هي قيمة الإغلاق المعدلة. تمثل هذه القيمة القيمة الختامية للسهم في ذلك اليوم المحدد لتداول سوق الأوراق المالية.
#Plot the True Adj Close Value
df ['Adj Close']. plot ()
الخطوة 5 - تحديد متغير الهدف واختيار الميزات
في الخطوة التالية ، نقوم بتعيين عمود الإخراج إلى المتغير الهدف. في هذه الحالة ، تكون هي القيمة النسبية المعدلة لأسهم Microsoft. بالإضافة إلى ذلك ، نختار أيضًا الميزات التي تعمل كمتغير مستقل للمتغير المستهدف (المتغير التابع). لحساب الغرض التدريبي ، نختار أربع خصائص ، وهي:
- افتح
- متوسط
- قليل
- الصوت
# تعيين متغير الهدف
output_var = PD.DataFrame (df ['Adj Close'])
# اختيار الميزات

الميزات = ['فتح' ، 'مرتفع' ، 'منخفض' ، 'الحجم']
الخطوة 6 - التحجيم
لتقليل التكلفة الحسابية للبيانات في الجدول ، سنقوم بتخفيض قيم المخزون إلى قيم بين 0 و 1. وبهذه الطريقة ، يتم تقليل جميع البيانات بأعداد كبيرة ، وبالتالي تقليل استخدام الذاكرة. أيضًا ، يمكننا الحصول على مزيد من الدقة من خلال تقليص حجم البيانات حيث لا يتم نشر البيانات بقيم هائلة. يتم تنفيذ ذلك بواسطة فئة MinMaxScaler في مكتبة sci-kit-Learn.
# تحجيم
قشارة = MinMaxScaler ()
feature_transform = scaler.fit_transform (df [الميزات])
feature_transform = pd.DataFrame (الأعمدة = الميزات ، البيانات = feature_transform ، الفهرس = df.index)
feature_transform.head ()
| تاريخ | افتح | متوسط | قليل | الصوت |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
كما ذكرنا أعلاه ، نرى أن قيم متغيرات الميزة يتم تصغيرها إلى قيم أصغر مقارنة بالقيم الحقيقية المذكورة أعلاه.
الخطوة 7 - الانقسام إلى مجموعة تدريب ومجموعة اختبار.
قبل إدخال البيانات في نموذج التدريب ، نحتاج إلى تقسيم مجموعة البيانات بأكملها إلى مجموعة تدريب واختبار. سيتم تدريب نموذج التعلم الآلي LSTM على البيانات الموجودة في مجموعة التدريب واختباره على مجموعة الاختبار من أجل الدقة والانتشار العكسي.
لهذا ، سنستخدم فئة TimeSeriesSplit في مكتبة sci-kit-Learn. قمنا بتعيين عدد الانقسامات على 10 ، مما يدل على أنه سيتم استخدام 10٪ من البيانات كمجموعة اختبار ، وسيتم استخدام 90٪ من البيانات لتدريب نموذج LSTM. تتمثل ميزة استخدام تقسيم السلاسل الزمنية هذا في ملاحظة عينات بيانات السلاسل الزمنية المنقسمة على فترات زمنية محددة.
# الانقسام إلى مجموعة التدريب ومجموعة الاختبار
Timesplit = TimeSeriesSplit (n_splits = 10)
بالنسبة لـ train_index ، test_index في Timesplit.split (feature_transform):
X_train، X_test = feature_transform [: len (train_index)]، feature_transform [len (train_index): (len (train_index) + len (test_index))]
y_train، y_test = output_var [: len (train_index)]. القيم.
الخطوة 8 - معالجة البيانات لـ LSTM
بمجرد أن تصبح مجموعات التدريب والاختبار جاهزة ، يمكننا إدخال البيانات في نموذج LSTM بمجرد إنشائه. قبل ذلك ، نحتاج إلى تحويل بيانات مجموعة التدريب والاختبار إلى نوع بيانات يقبله نموذج LSTM. نقوم أولاً بتحويل بيانات التدريب وبيانات الاختبار إلى مصفوفات NumPy ثم نعيد تشكيلها بالتنسيق (عدد العينات ، 1 ، عدد الميزات) حيث يتطلب LSTM تغذية البيانات في شكل ثلاثي الأبعاد. كما نعلم فإن عدد العينات في مجموعة التدريب 90٪ من 7334 أي 6667 ، وعدد الميزات 4 ، تم إعادة تشكيل مجموعة التدريب إلى (6667 ، 1 ، 4). وبالمثل ، تم أيضًا إعادة تشكيل مجموعة الاختبار.
# معالجة بيانات LSTM
trainX = np.array (X_train)
testX = np.array (X_test)
X_train = trainX.reshape (X_train.shape [0]، 1، X_train.shape [1])
X_test = testX.reshape (X_test.shape [0]، 1، X_test.shape [1])
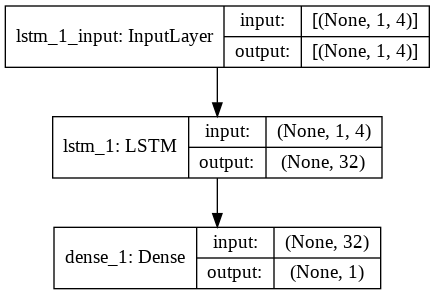
الخطوة 9 - بناء نموذج LSTM
أخيرًا ، وصلنا إلى المرحلة حيث نبني نموذج LSTM. هنا ، نقوم بإنشاء نموذج تسلسلي Keras بطبقة LSTM واحدة. تتكون طبقة LSTM من 32 وحدة ، ويتبعها طبقة كثيفة من خلية عصبية واحدة.
نستخدم Adam Optimizer و Mean Squared Error كوظيفة خسارة لتجميع النموذج. هذان هما التركيبة المفضلة لنموذج LSTM. بالإضافة إلى ذلك ، يتم رسم النموذج أيضًا ويتم عرضه أدناه.
# بناء نموذج LSTM
lstm = تسلسلي ()
lstm.add (LSTM (32، input_shape = (1، trainX.shape [1])، activation = 'relu'، return_sequences = False))
lstm.add (كثيف (1))
lstm.compile (الخسارة = 'mean_squared_error' ، المحسن = 'adam')
plot_model (lstm ، show_shapes = صحيح ، show_layer_names = صحيح)
الخطوة 10 - تدريب النموذج
أخيرًا ، نقوم بتدريب نموذج LSTM المصمم أعلاه على بيانات التدريب لـ 100 عصر بحجم دفعة 8 باستخدام وظيفة الملاءمة.
# تدريب النموذج
history = lstm.fit (X_train ، y_train ، عهود = 100 ، حجم الدفعة = 8 ، مطول = 1 ، خلط ورق اللعب = خطأ)
حقبة 1/100
834/834 [===============================] - 3 ثوانٍ 2 مللي ثانية / خطوة - خسارة: 67.1211
الحقبة 2/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - خسارة: 70.4911
حقبة 3/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 48.8155
حقبة 4/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - خسارة: 21.5447
حقبة 5/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 6.1709
حقبة 6/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 1.8726
حقبة 7/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - خسارة: 0.9380
حقبة 8/100
834/834 [===============================] - 2 ثانية 2 مللي ثانية / الخطوة - الخسارة: 0.6566
حقبة 9/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.5369
عصر 10/100
834/834 [===============================] - 2 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4761
.
.
.
.
حقبة 95/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4542
حقبة 96/100
834/834 [===============================] - 2 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4553
حقبة 97/100
834/834 [================================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4565
حقبة 98/100
834/834 [================================] - 1 ثانية 2 مللي ثانية / خطوة - خسارة: 0.4576
عصر 99/100
834/834 [================================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4588
حقبة 100/100
834/834 [===============================] - 1 ثانية 2 مللي ثانية / خطوة - الخسارة: 0.4599
أخيرًا ، نرى أن قيمة الخسارة قد انخفضت بشكل كبير بمرور الوقت أثناء عملية التدريب التي استمرت 100 حقبة ووصلت إلى قيمة 0.4599
الخطوة 11 - توقع LSTM
مع استعداد نموذجنا ، فقد حان الوقت لاستخدام النموذج الذي تم تدريبه باستخدام شبكة LSTM في مجموعة الاختبار والتنبؤ بالقيمة القريبة المجاورة لمخزون Microsoft. يتم تنفيذ ذلك باستخدام وظيفة التنبؤ البسيطة في نموذج lstm المبني.
#LSTM التنبؤ
y_pred = lstm.predict (X_test)
الخطوة 12 - القيمة القريبة الصحيحة مقابل القيمة المتوقعة المتوقعة - LSTM
أخيرًا ، كما توقعنا قيم مجموعة الاختبار ، يمكننا رسم الرسم البياني لمقارنة كل من القيم الحقيقية لـ Adj Close والقيمة المتوقعة لـ Adj Close بواسطة نموذج LSTM Machine Learning.
#True vs Predicted Adj Close Value - LSTM
plt.plot (y_test، label = "القيمة الحقيقية")
plt.plot (y_pred ، التسمية = "قيمة LSTM")
plt.title ("التنبؤ بواسطة LSTM")
plt.xlabel ("مقياس الوقت")
plt.ylabel ("تحجيم بالدولار الأمريكي")
plt.legend ()
plt.show ()
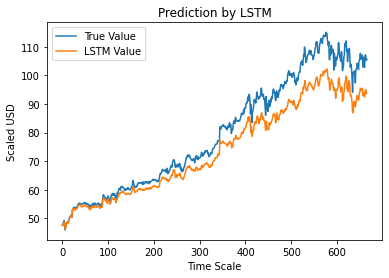
يوضح الرسم البياني أعلاه أنه تم اكتشاف بعض الأنماط بواسطة نموذج شبكة LSTM الفردي الأساسي للغاية المبني أعلاه. من خلال ضبط العديد من المعلمات وإضافة المزيد من طبقات LSTM إلى النموذج ، يمكننا تحقيق تمثيل أكثر دقة لقيمة سهم أي شركة معينة.
خاتمة
إذا كنت مهتمًا بمعرفة المزيد حول أمثلة الذكاء الاصطناعي ، والتعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة والمهام ، وحالة خريجي IIIT-B ، وأكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع كبرى الشركات.
هل يمكنك توقع سوق الأسهم باستخدام التعلم الآلي؟
اليوم ، لدينا عدد من المؤشرات للمساعدة في توقع اتجاهات السوق. ومع ذلك ، لا يتعين علينا أن ننظر إلى أبعد من جهاز كمبيوتر عالي القدرة للعثور على أكثر المؤشرات دقة لسوق الأسهم. سوق الأوراق المالية هو نظام مفتوح ويمكن اعتباره شبكة معقدة. تتكون الشبكة من العلاقات بين الأسهم والشركات والمستثمرين وأحجام التجارة. باستخدام خوارزمية استخراج البيانات مثل آلة متجه الدعم ، يمكنك تطبيق صيغة رياضية لاستخراج العلاقات بين هذه المتغيرات. سوق الأسهم الآن يتجاوز التوقعات البشرية.
ما هي أفضل الخوارزمية لتوقع سوق الأسهم؟
للحصول على أفضل النتائج ، يجب عليك استخدام الانحدار الخطي. الانحدار الخطي هو نهج إحصائي يستخدم لتحديد العلاقة بين متغيرين مختلفين. في هذا المثال ، المتغيرات هي السعر والوقت. في تنبؤات سوق الأوراق المالية ، السعر هو المتغير المستقل ، والوقت هو المتغير التابع. إذا كان من الممكن تحديد علاقة خطية بين هذين المتغيرين ، فمن الممكن التنبؤ بدقة بقيمة السهم في أي وقت في المستقبل.
هل تنبؤات البورصة مشكلة تصنيف أم انحدار؟
قبل أن نجيب ، نحتاج إلى فهم ما تعنيه تنبؤات سوق الأسهم. هل هي مشكلة تصنيف ثنائي أم مشكلة انحدار؟ لنفترض أننا نريد التنبؤ بمستقبل السهم ، حيث يعني المستقبل اليوم أو الأسبوع أو الشهر أو السنة التالية. إذا كان الأداء السابق للسهم في وقت ما هو المدخل والمستقبل هو المخرجات ، فهذه مشكلة انحدار. إذا كان الأداء السابق للسهم ومستقبل السهم مستقلين ، فهذه مشكلة تصنيف.