
أدوات البيانات الكمية لمصممي UX
نشرت: 2022-03-10يخشى العديد من مصممي UX من البيانات ، معتقدين أنها تتطلب معرفة عميقة بالإحصاءات والرياضيات. على الرغم من أن هذا قد يكون صحيحًا بالنسبة لعلوم البيانات المتقدمة ، إلا أنه لا ينطبق على تحليل بيانات البحث الأساسي الذي يتطلبه معظم مصممي تجربة المستخدم. نظرًا لأننا نعيش في عالم يعتمد على البيانات بشكل متزايد ، فإن معرفة البيانات الأساسية مفيدة لأي محترف تقريبًا - وليس فقط مصممي تجربة المستخدم.
يجادل آرون جتلين ، مصمم التفاعل في Google ، بأن العديد من المصممين لم يعتمدوا بعد على البيانات:
"بينما تروج العديد من الشركات لأنفسها على أنها تعتمد على البيانات ، فإن معظم المصممين مدفوعون بالفطرة والتعاون وأساليب البحث النوعي."
- آرون جتلين ، "أن تصبح مصممًا مدركًا للبيانات"
من خلال هذه المقالة ، أود أن أمنح مصممي تجربة المستخدم المعرفة والأدوات اللازمة لدمج البيانات في إجراءاتهم اليومية.
لكن أولاً ، بعض مفاهيم البيانات
في هذه المقالة سأتحدث عن البيانات المنظمة ، أي البيانات التي يمكن تمثيلها في جدول ، مع صفوف وأعمدة. البيانات غير المهيكلة ، كونها موضوعًا في حد ذاتها ، يصعب تحليلها ، كما أشار ديفين بيكيل (متخصص تسويق المحتوى في G2 Crowd ، يكتب عن البيانات والتحليلات) في مقالته "البيانات المهيكلة مقابل البيانات غير المهيكلة - ما الفرق؟" إذا كان من الممكن تمثيل البيانات المنظمة في نموذج جدول ، فإن المفاهيم الرئيسية هي:
مجموعة البيانات
المجموعة الكاملة من البيانات التي نعتزم تحليلها. يمكن أن يكون هذا ، على سبيل المثال ، جدول Excel. تنسيق شائع آخر لتخزين مجموعات البيانات هو ملف القيم المفصولة بفواصل (CSV). ملفات CSV هي ملفات نصية بسيطة تستخدم لتخزين معلومات تشبه الجدول. يتوافق كل صف CSV مع صف في الجدول ، ويحتوي كل صف CSV على قيم مفصولة (بشكل طبيعي) بفاصلات ، والتي تتوافق مع خلايا الجدول.
نقطة البيانات
صف واحد من جدول مجموعة البيانات هو نقطة بيانات. بهذه الطريقة ، تكون مجموعة البيانات عبارة عن مجموعة من نقاط البيانات.
متغير البيانات
تمثل القيمة المفردة من صف نقطة البيانات متغير بيانات - ببساطة ، خلية جدول. يمكن أن يكون لدينا نوعان من متغيرات البيانات: المتغيرات النوعية والمتغيرات الكمية. المتغيرات النوعية (المعروفة أيضًا باسم المتغيرات الفئوية) لها مجموعة منفصلة من القيم ، مثل color = red/green/blue . المتغيرات الكمية لها قيم عددية ، مثل height = 167 . يمكن للمتغير الكمي ، على عكس المتغير النوعي ، أن يأخذ أي قيمة.
إنشاء مشروع البيانات لدينا
الآن نحن نعرف الأساسيات ، حان الوقت لتسخير أيدينا وإنشاء مشروع بياناتنا الأول. يتمثل نطاق المشروع في تحليل مجموعة البيانات من خلال المرور عبر تدفق البيانات بالكامل لاستيراد البيانات ومعالجتها ورسمها. أولاً ، سنختار مجموعة البيانات الخاصة بنا ، ثم سنقوم بتنزيل وتثبيت الأدوات لتحليل البيانات.
مجموعة بيانات السيارات
لغرض هذا المقال ، اخترت مجموعة بيانات السيارات ، لأنها بسيطة وبديهية. سيؤكد تحليل البيانات ببساطة ما نعرفه بالفعل عن السيارات - وهو أمر جيد ، لأن تركيزنا ينصب على تدفق البيانات والأدوات.
يمكننا تنزيل مجموعة بيانات السيارات المستعملة من Kaggle ، أحد أكبر مصادر مجموعات البيانات المجانية. ستحتاج إلى التسجيل أولاً.
بعد تنزيل الملف ، افتحه وألق نظرة عليه. إنه ملف CSV كبير حقًا ، لكن يجب أن تفهم الجوهر. سيبدو سطر في هذا الملف كما يلي:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3كما ترى ، تحتوي نقطة البيانات هذه على عدة متغيرات مفصولة بفواصل. نظرًا لأن لدينا الآن مجموعة البيانات ، فلنتحدث قليلاً عن الأدوات.
أدوات التجارة
سنستخدم لغة R و RStudio لتحليل مجموعة البيانات. لغة R هي لغة شائعة جدًا وسهلة التعلم ، ولا يستخدمها علماء البيانات فحسب ، بل يستخدمها أيضًا الأشخاص في الأسواق المالية والطب والعديد من المجالات الأخرى. RStudio هي البيئة التي يتم فيها تطوير مشاريع R ، وهناك إصدار مجاني ، وهو أكثر من كافٍ لاحتياجاتنا كمصممي UX.
من المحتمل أن يستخدم بعض مصممي UX برنامج Excel لسير عمل البيانات الخاصة بهم. إذا كان هذا يعني أنك ، فجرّب R - هناك فرصة جيدة لأنك ستحبها ، لأنها سهلة التعلم ، وأكثر مرونة وقوة من Excel. ستحدث إضافة R إلى مجموعة الأدوات الخاصة بك فرقًا.
تثبيت الأدوات
أولاً ، نحتاج إلى تنزيل R و RStudio وتثبيتهما. يجب عليك تثبيت R أولاً ، ثم RStudio. عمليات التثبيت لكل من R و RStudio بسيطة ومباشرة.
إعداد مشروع
بمجرد اكتمال التثبيت ، قم بإنشاء مجلد مشروع - قمت بتسميته used-cars-prj . في هذا المجلد ، أنشئ مجلدًا فرعيًا يسمى البيانات ، ثم انسخ ملف مجموعة البيانات (الذي تم تنزيله من Kaggle) إلى هذا المجلد وأعد تسميته إلى used-cars.csv . عد الآن إلى مجلد مشروعنا ( used-cars-prj ) وأنشئ ملفًا نصيًا عاديًا يسمى used-cars.r . يجب أن ينتهي بك الأمر بنفس البنية كما في لقطة الشاشة أدناه.
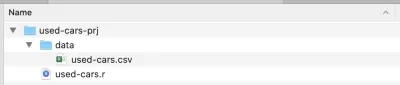
الآن لدينا بنية المجلد في مكانها الصحيح ، يمكننا فتح RStudio وإنشاء مشروع R جديد. اختر مشروع جديد ... من قائمة " ملف " وحدد الخيار الثاني " الدليل الحالي ". ثم حدد دليل المشروع ( used-cars-prj ). أخيرًا ، اضغط على زر إنشاء مشروع وبذلك تكون قد انتهيت. بمجرد إنشاء المشروع ، افتح used-cars.r في RStudio - هذا هو الملف حيث سنضيف كل كود R الخاص بنا.
استيراد البيانات
سنضيف السطر الأول في used-cars.r ، لقراءة البيانات من ملف used-cars.csv . تذكر أن ملفات CSV هي مجرد ملفات نصية عادية تُستخدم لتخزين البيانات. سيبدو السطر الأول من كود R كما يلي:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") قد يبدو الأمر مخيفًا بعض الشيء ، لكنه في الحقيقة ليس كذلك - بالمناسبة ، هذا هو السطر الأكثر تعقيدًا في المقالة بأكملها. ما لدينا هنا هو دالة read.csv ، والتي تأخذ ثلاثة معاملات.
المعلمة الأولى هي الملف المراد قراءته ، في حالتنا used-cars.csv ، الموجود في مجلد البيانات . المعلمة الثانية ، stringsAsFactors=FALSE تم تعيينها للتأكد من عدم تحويل سلاسل مثل "BMW" أو "Audi" إلى عوامل (لغة R للبيانات الفئوية) - كما تتذكر ، يمكن أن تحتوي المتغيرات النوعية أو الفئوية على قيم منفصلة فقط مثل red/green/blue . أخيرًا ، يحدد المعامل الثالث sep="," نوع الفاصل المستخدم لفصل القيم في ملف CSV: فاصلة.
بعد قراءة ملف CSV ، يتم تخزين البيانات في كائن إطار بيانات cars . إطار البيانات عبارة عن هيكل بيانات ثنائي الأبعاد (مثل جدول Excel) ، وهو مفيد جدًا في R لمعالجة البيانات. بعد إدخال الخط وتشغيله ، سيتم إنشاء إطار بيانات cars لك. إذا نظرت في الربع العلوي الأيمن في RStudio ، ستلاحظ إطار بيانات cars ، في قسم البيانات ضمن علامة التبويب البيئة . إذا نقرت نقرًا مزدوجًا فوق سيارات ، فسيتم فتح علامة تبويب جديدة في الربع العلوي الأيسر من RStudio ، وستعرض إطار بيانات cars . كما قد تتوقع ، يبدو وكأنه جدول Excel.
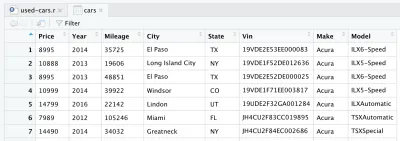
هذه في الواقع هي البيانات الأولية التي قمنا بتنزيلها من Kaggle. ولكن نظرًا لأننا نريد إجراء تحليل البيانات ، فنحن بحاجة إلى معالجة مجموعة البيانات الخاصة بنا أولاً.
معالجة البيانات
نعني بالمعالجة إزالة المعلومات أو تحويلها أو إضافتها إلى مجموعة البيانات الخاصة بنا ، من أجل التحضير لنوع التحليل الذي نريد إجراؤه. لدينا البيانات في كائن إطار البيانات ، لذلك نحتاج الآن إلى تثبيت مكتبة dplyr ، وهي مكتبة قوية لمعالجة البيانات. لتثبيت المكتبة في بيئة R الخاصة بنا ، نحتاج إلى كتابة السطر التالي أعلى ملف R الخاص بنا.
install.packages("dplyr")بعد ذلك ، لإضافة المكتبة إلى مشروعنا الحالي ، سنستخدم السطر التالي:
library(dplyr) بمجرد إضافة مكتبة dplyr إلى مشروعنا ، يمكننا البدء في معالجة البيانات. لدينا مجموعة بيانات كبيرة حقًا ، ونحتاج فقط إلى البيانات التي تمثل نفس صانع السيارة وطرازها ، لربط ذلك بالسعر. سنستخدم رمز R التالي للاحتفاظ فقط بالبيانات المتعلقة بسيارة BMW 3 Series ، وإزالة الباقي. بالطبع ، يمكنك اختيار أي مصنع وطراز آخر من مجموعة البيانات ، وتتوقع الحصول على نفس خصائص البيانات.
cars <- cars %>% filter(Make == "BMW", Model == "3")الآن لدينا مجموعة بيانات أكثر قابلية للإدارة ، على الرغم من أنها لا تزال تحتوي على أكثر من 11000 نقطة بيانات ، والتي تتناسب مع غرضنا المقصود: تحليل أسعار السيارات ، وتوزيعات العمر والأميال ، وكذلك العلاقات المتبادلة بينهما. لذلك ، نحتاج إلى الاحتفاظ فقط بأعمدة "السعر" و "السنة" و "المسافة المقطوعة" وإزالة الباقي - ويتم ذلك بالسطر التالي.
cars <- cars %>% select(Price, Year, Mileage)بعد إزالة الأعمدة الأخرى ، سيبدو إطار البيانات لدينا كما يلي:

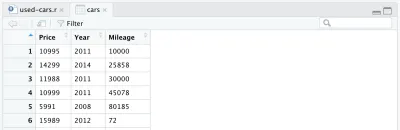
هناك تغيير آخر نريد إجراؤه على مجموعة البيانات لدينا: استبدال سنة التصنيع بعمر السيارة. يمكننا إضافة السطرين التاليين ، الأول لحساب العمر ، والثاني لتغيير اسم العمود.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)أخيرًا ، يبدو إطار البيانات الذي تمت معالجته بالكامل كما يلي:
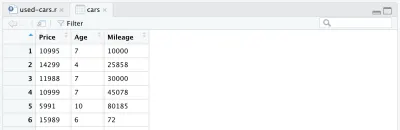
في هذه المرحلة ، سيبدو كود R كما يلي ، وهذا كل شيء لمعالجة البيانات. يمكننا الآن أن نرى مدى سهولة وقوة لغة R. لقد عالجنا مجموعة البيانات الأولية بشكل كبير للغاية باستخدام بضعة أسطر فقط من التعليمات البرمجية.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)تحليل البيانات
بياناتنا الآن في الشكل الصحيح ، لذا يمكننا أن نذهب لعمل بعض المؤامرات. كما ذكرنا سابقًا ، سنركز على جانبين: توزيع المتغيرات الفردية ، والارتباطات بينهما. يساعدنا التوزيع المتغير على فهم ما يعتبر سعرًا متوسطًا أو مرتفعًا لسيارة مستعملة - أو النسبة المئوية للسيارات التي تزيد عن سعر معين. الأمر نفسه ينطبق على عمر السيارات وعدد الأميال المقطوعة. من ناحية أخرى ، تساعد الارتباطات في فهم كيفية ارتباط المتغيرات مثل العمر والأميال ببعضها البعض.
ومع ذلك ، سوف نستخدم نوعين من تصور البيانات: الرسوم البيانية للتوزيع المتغير ، والمخططات المبعثرة للارتباطات.
توزيع الأسعار
يعد رسم الرسم البياني لسعر السيارة بلغة R أمرًا سهلاً مثل هذا:
hist(cars$Price)نصيحة صغيرة: إذا كنت في RStudio يمكنك تشغيل الكود سطرًا بسطر ؛ على سبيل المثال ، في حالتنا ، تحتاج فقط إلى تشغيل السطر أعلاه لعرض الرسم البياني. ليس من الضروري تشغيل كل التعليمات البرمجية مرة أخرى لأنك قمت بتشغيلها مرة واحدة بالفعل. يجب أن يبدو الرسم البياني كما يلي:
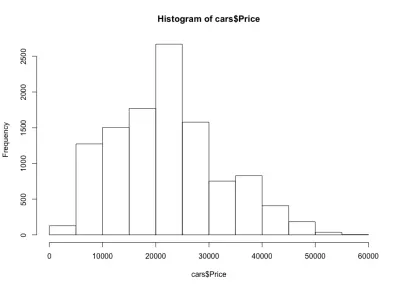
إذا نظرنا إلى الرسم البياني ، نلاحظ توزيعًا يشبه الجرس لأسعار السيارات ، وهو ما توقعناه. تقع معظم السيارات في النطاق المتوسط ، ولدينا عدد أقل وأقل كلما انتقلنا إلى كل جانب. ما يقرب من 80٪ من السيارات تتراوح قيمتها بين 10000 دولار و 30 ألف دولار أمريكي ، ولدينا أكثر من 2500 سيارة بحد أقصى بين 20000 دولار و 25000 دولار أمريكي. على الجانب الأيسر ، لدينا على الأرجح حوالي 150 سيارة أقل من 5000 دولار أمريكي ، وعلى الجانب الأيمن أقل من ذلك. يمكننا أن نرى بسهولة مدى فائدة مثل هذه المؤامرات للحصول على رؤى حول البيانات.
التوزيع العمري
كما هو الحال بالنسبة لأسعار السيارات ، سنستخدم خطًا مشابهًا لرسم الرسم البياني لعمر السيارات.
hist(cars$Age)وهنا الرسم البياني:
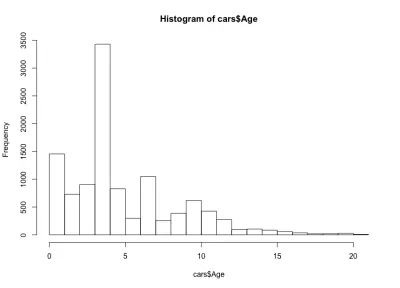
هذه المرة يبدو الرسم البياني غير بديهي - فبدلاً من شكل الجرس البسيط ، لدينا هنا أربعة أجراس. في الأساس ، يحتوي التوزيع على ثلاثة حد أقصى محلي وواحد عالمي ، وهو أمر غير متوقع. سيكون من المثير للاهتمام معرفة ما إذا كان هذا التوزيع الغريب لأعمار السيارات يظل صحيحًا بالنسبة إلى صانع سيارات وطراز آخر. لغرض هذه المقالة ، سنبقى مع مجموعة بيانات BMW الفئة الثالثة ، ولكن يمكنك التعمق في البيانات إذا كنت مهتمًا. فيما يتعلق بتوزيع عمر السيارة لدينا ، نلاحظ أن أكثر من 90٪ من السيارات أقل من 10 سنوات ، وأكثر من 80٪ أقل من 7 سنوات. كما نلاحظ أن غالبية السيارات أقل من 5 سنوات.
توزيع الأميال
الآن ، ماذا يمكننا أن نقول عن الأميال؟ بالطبع ، نتوقع أن يكون لدينا نفس شكل الجرس الذي كان لدينا بالنسبة للسعر. هذا هو رمز R والرسم البياني:
hist(cars$Mileage) 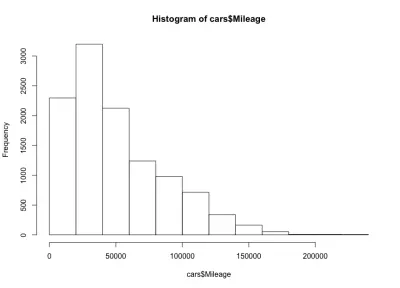
لدينا هنا شكل جرس منحرف لليسار ، مما يعني أن هناك المزيد من السيارات ذات الأميال القليلة في السوق. نلاحظ أيضًا أن غالبية السيارات لديها أقل من 60 ألف ميل ، ولدينا حد أقصى يتراوح بين 20 ألف إلى 40 ألف ميل.
العلاقة بين العمر والسعر
فيما يتعلق بالارتباطات ، دعنا نلقي نظرة فاحصة على الارتباط بين عمر السيارات والسعر. قد نتوقع أن يكون السعر مرتبطًا بشكل سلبي بالعمر - فكلما زاد عمر السيارة ، سينخفض سعرها. سنستخدم وظيفة R plot لعرض الارتباط بين السعر والعمر على النحو التالي:
plot(cars$Age, cars$Price)والحبكة تبدو كالتالي:
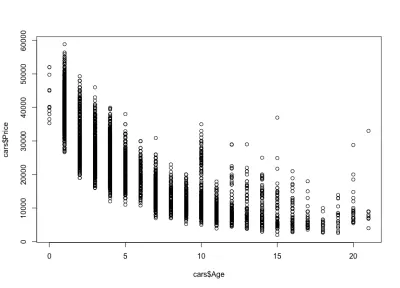
نلاحظ كيف تنخفض أسعار السيارات مع تقدم العمر: هناك سيارات جديدة باهظة الثمن ، وسيارات قديمة أرخص. يمكننا أيضًا رؤية الفاصل الزمني لتغير السعر لأي عمر محدد ، وهو اختلاف يتناقص مع عمر السيارة. هذا الاختلاف مدفوع إلى حد كبير بالأميال والتكوين والحالة العامة للسيارة. على سبيل المثال ، في حالة سيارة عمرها 4 سنوات ، يتراوح السعر بين 10000 دولار و 40 ألف دولار أمريكي.
المسافة بين الأميال والعمر
بالنظر إلى العلاقة بين الأميال والعمر ، نتوقع زيادة الأميال مع تقدم العمر ، مما يعني وجود ارتباط إيجابي. ها هو الكود:
plot(cars$Mileage, cars$Age)وهنا الحبكة:
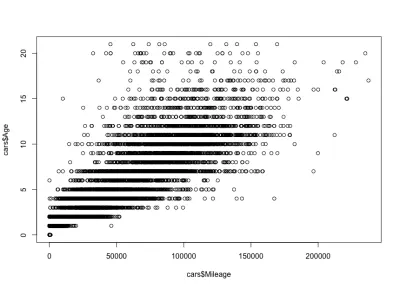
كما ترى ، يرتبط عمر السيارة وعدد الكيلومترات المقطوعة ارتباطًا إيجابيًا ، على عكس سعر السيارة وعمرها ، اللذين يرتبطان ارتباطًا سلبيًا. لدينا أيضًا اختلاف في الأميال متوقع لعمر معين ؛ أي السيارات من نفس العمر لها أميال متفاوتة. على سبيل المثال ، معظم السيارات التي يبلغ عمرها 4 سنوات لها أميال بين 10000 و 80.000 ميل. ولكن هناك أيضًا قيم متطرفة ، مع عدد أميال أكبر.
المسافة بين الأميال والسعر
كما هو متوقع ، سيكون هناك ارتباط سلبي بين المسافة المقطوعة بالسيارة والسعر ، مما يعني أن زيادة الأميال تقلل من السعر.
plot(cars$Mileage, cars$Price)وهنا الحبكة:
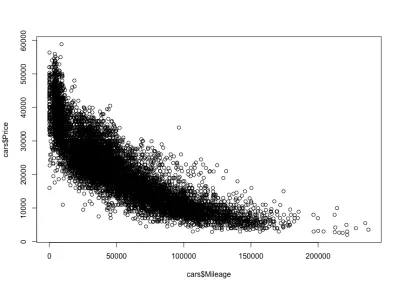
كما توقعنا ، هناك ارتباط سلبي. يمكننا أيضًا أن نلاحظ فاصل السعر الإجمالي بين 3000 دولار و 50000 دولار أمريكي ، والمسافة المقطوعة بين 0 و 150000 دولار. إذا نظرنا عن كثب إلى شكل التوزيع ، نلاحظ أن السعر ينخفض بشكل أسرع للسيارات ذات الأميال الأقل مما هو عليه في السيارات ذات الأميال الأكبر. هناك سيارات بدون أميال تقريبًا ، حيث ينخفض سعرها بشكل كبير. أيضًا ، ما يزيد عن 200000 ميل - لأن الأميال عالية جدًا - يظل السعر ثابتًا.
من الأرقام إلى تصورات البيانات
في هذه المقالة ، استخدمنا نوعين من التصور: الرسوم البيانية لتوزيعات البيانات ، والمخططات المبعثرة لارتباطات البيانات. الرسوم البيانية هي تمثيلات مرئية تأخذ قيم متغير بيانات ( أرقام فعلية) وتوضح كيفية توزيعها عبر نطاق. استخدمنا وظيفة R hist() لرسم مخطط بياني.
من ناحية أخرى ، تأخذ المخططات المبعثرة أزواج من الأرقام وتمثلها على محورين. تستخدم المخططات المبعثرة الدالة plot() وتوفر معلمتين: متغيرا البيانات الأول والثاني للارتباط الذي نريد فحصه. وبالتالي ، فإن وظيفتي R ، hist() plot() تساعدنا في ترجمة مجموعات من الأرقام في تمثيلات بصرية ذات مغزى.
خاتمة
بعد أن أصبحت أيدينا متسخة خلال تدفق البيانات بالكامل لاستيراد البيانات ومعالجتها وتخطيطها ، تبدو الأمور أكثر وضوحًا الآن. يمكنك تطبيق نفس تدفق البيانات على أي مجموعة بيانات جديدة لامعة ستواجهها. في بحث المستخدم ، على سبيل المثال ، يمكنك رسم بياني للوقت في توزيعات المهام أو الأخطاء ، ويمكنك أيضًا رسم وقت على المهمة مقابل ارتباط الخطأ.
لمعرفة المزيد حول لغة R ، يعد Quick-R مكانًا جيدًا للبدء ، ولكن يمكنك أيضًا التفكير في R Bloggers. للحصول على وثائق حول حزم R ، مثل dplyr ، يمكنك زيارة RDocumentation. يمكن أن يكون اللعب بالبيانات ممتعًا ، ولكنه أيضًا مفيد للغاية لأي مصمم UX في عالم يعتمد على البيانات. نظرًا لأنه يتم جمع المزيد من البيانات واستخدامها لإبلاغ قرارات العمل ، فهناك فرصة متزايدة للمصممين للعمل على تصور البيانات أو منتجات البيانات ، حيث يكون فهم طبيعة البيانات أمرًا ضروريًا.