
7 خوارزميات تعلم الآلة الأكثر استخدامًا في Python يجب أن تعرفها
نشرت: 2021-03-04التعلم الآلي هو فرع من فروع الذكاء الاصطناعي (AI) الذي يتعامل مع خوارزميات الكمبيوتر المستخدمة في أي بيانات. إنه يركز على التعلم التلقائي من البيانات التي يتم إدخالها فيه ويمنحنا نتائج من خلال تحسين التنبؤات السابقة في كل مرة.
جدول المحتويات
أهم خوارزميات التعلم الآلي المستخدمة في بايثون
فيما يلي بعض من أفضل خوارزميات التعلم الآلي المستخدمة في Python ، جنبًا إلى جنب مع مقتطفات التعليمات البرمجية التي توضح تنفيذها وتصورات حدود التصنيف.
1. الانحدار الخطي
يعد الانحدار الخطي أحد أكثر تقنيات التعلم الآلي الخاضعة للإشراف استخدامًا. كما يوحي اسمه ، يحاول هذا الانحدار نمذجة العلاقة بين متغيرين باستخدام معادلة خطية وملاءمة هذا الخط للبيانات المرصودة. تُستخدم هذه التقنية لتقدير القيم الحقيقية المستمرة مثل إجمالي المبيعات أو تكلفة المنازل.
يسمى الخط الأنسب أيضًا خط الانحدار. تعطى بالمعادلة التالية:
ص = أ * س + ب
حيث Y هو المتغير التابع ، a هو المنحدر ، X هو المتغير المستقل و b هي قيمة التقاطع. يتم اشتقاق المعاملين أ و ب عن طريق تقليل مربع فرق تلك المسافة بين نقاط البيانات المختلفة ومعادلة خط الانحدار.

# مجموعة بيانات تركيبية لانحدار بسيط
من sklearn.datasets استيراد make_regression
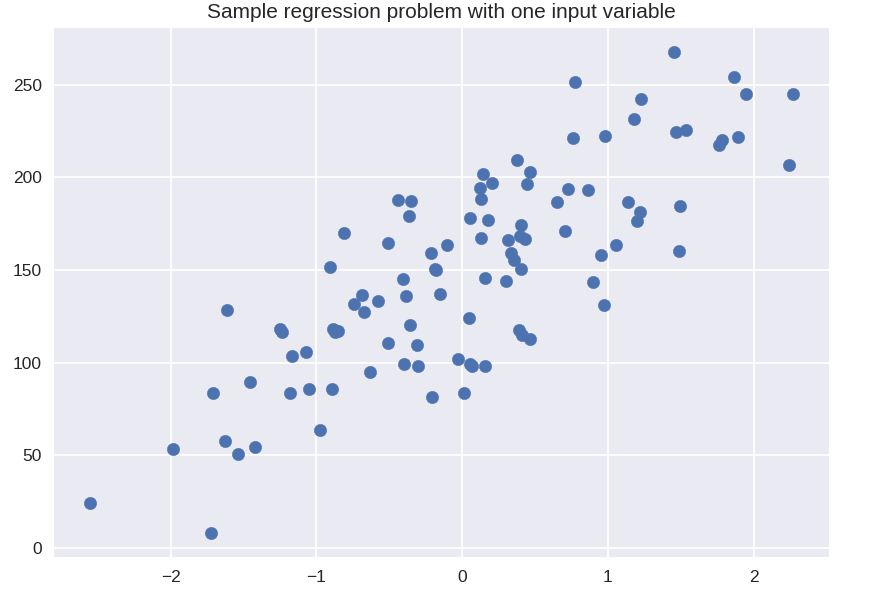
plt. الشكل ()
plt.title ("نموذج مشكلة الانحدار بمتغير إدخال واحد")
X_R1، y_R1 = make_regression (n_samples = 100، n_features = 1، n_informative = 1، bias = 150.0، الضوضاء = 30، random_state = 0)
مبعثر plt (X_R1، y_R1، علامة = 'o'، s = 50)
plt.show ()
من sklearn.linear_model استيراد LinearRegression
X_train ، X_test ، y_train ، y_test = train_test_split (X_R1 ، y_R1 ،
عشوائية = 0)
linreg = LinearRegression (). fit (X_train، y_train)
طباعة ("معامل النموذج الخطي (w): {}" تنسيق (linreg.coef_))
طباعة ('تقاطع النموذج الخطي (ب): {: .3f}' تنسيق z (linreg.intercept_))
print ('R-squared Score (training): {: .3f}'. format (linreg.score (X_train، y_train)))
print ('R-squared Score (test): {: .3f}'. تنسيق (linreg.score (X_test، y_test)))
انتاج |
معامل النموذج الخطي (ث): [45.71]
اعتراض النموذج الخطي (ب): 148.446
النتيجة التربيعية (التدريب): 0.679
النتيجة التربيعية (اختبار): 0.492
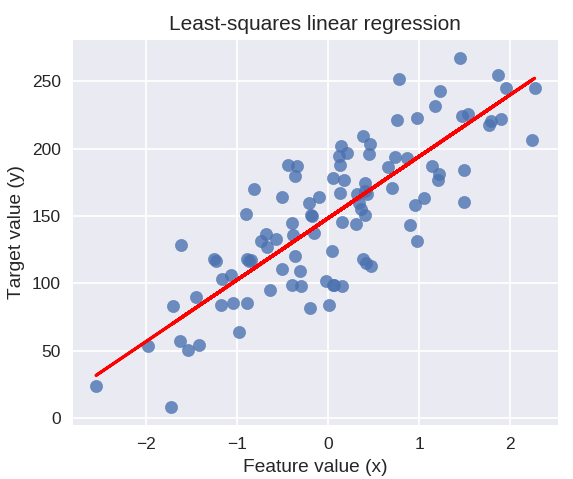
سوف يرسم الكود التالي خط الانحدار المناسب على مخطط نقاط البيانات الخاصة بنا.
شكل plt (حجم الشكل = (5 ، 4))
مبعثر plt (X_R1، y_R1، علامة = 'o'، s = 50، alpha = 0.8)
plt.plot (X_R1، linreg.coef_ * X_R1 + linreg.intercept_، 'r-')
plt.title ("الانحدار الخطي للمربعات الصغرى")
plt.xlabel ("قيمة الميزة (س)")
plt.ylabel ("القيمة المستهدفة (ص)")
plt.show ()
تحضير مجموعة بيانات مشتركة لاستكشاف تقنيات التصنيف
سيتم استخدام البيانات التالية لإظهار خوارزميات التصنيف المختلفة الأكثر استخدامًا في التعلم الآلي في Python.
يتم تخزين مجموعة بيانات UCI Mushroom في mushrooms.csv.
٪ دفتر matplotlib
استيراد الباندا كما pd
استيراد numpy كـ np
استيراد matplotlib.pyplot كـ PLT
من sklearn.decomposition استيراد PCA
من sklearn.model_selection استيراد train_test_split
df = pd.read_csv ('readonly / mushrooms.csv')
df2 = pd.get_dummies (df)
df3 = df2.sample (frac = 0.08)
X = df3.iloc [:، 2:]
y = df3.iloc [:، 1]
pca = PCA (n_components = 2) .fit_transform (X)
X_train ، X_test ، y_train ، y_test = train_test_split (pca ، y ، random_state = 0)
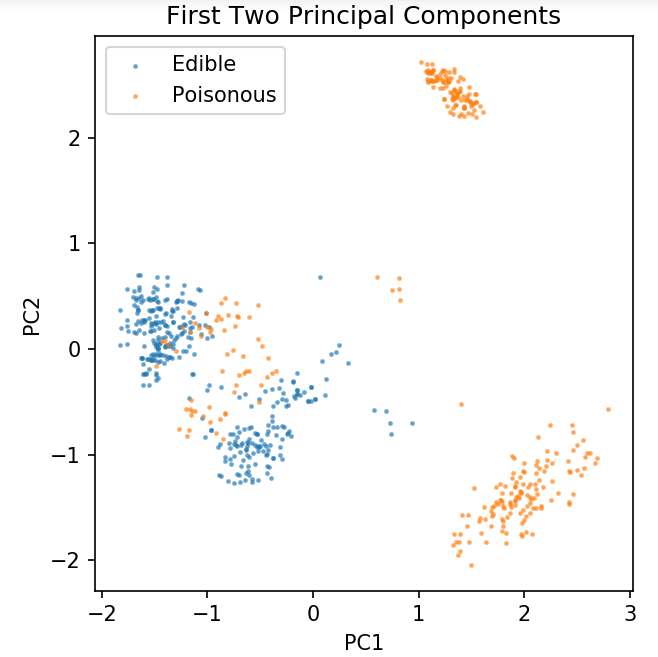
شكل plt (نقطة في البوصة = 120)
plt.scatter (pca [y.values == 0، 0]، pca [y.values == 0، 1]، alpha = 0.5، label = 'Edible'، s = 2)
plt.scatter (pca [y.values == 1، 0]، pca [y.values == 1، 1]، alpha = 0.5، label = "Poisonous"، s = 2)
plt.legend ()
plt.title ("مجموعة بيانات الفطر \ n المكونان الأساسيان الأولان")
plt.xlabel ('PC1')
plt.ylabel ("PC2")
plt.gca (). set_aspect ("يساوي")
سنستخدم الوظيفة المحددة أدناه للحصول على حدود القرار للمصنفات المختلفة التي سنستخدمها في مجموعة بيانات الفطر.
def plot_mushroom_boundary (X، y، mount_model):
شكل plt (حجم الشكل = (9.8 ، 5) ، نقطة في البوصة = 100)
بالنسبة لـ i ، plot_type في التعداد (["حدود القرار" ، "احتمالات القرار"]):
plt.subplot (1، 2، i + 1)
mesh_step_size = 0.01 # حجم خطوة في الشبكة
x_min، x_max = X [:، 0] .min () - .1، X [:، 0] .max () + .1
y_min، y_max = X [:، 1] .min () - .1، X [:، 1] .max () + .1
xx، yy = np.meshgrid (np.arange (x_min، x_max، mesh_step_size)، np.arange (y_min، y_max، mesh_step_size))
إذا كنت == 0:
Z = fit_model.predict (np.c_ [xx.ravel ()، yy.ravel ()])
آخر:
يحاول:
Z = appropriate_model.predict_proba (np.c_ [xx.ravel ()، yy.ravel ()]) [:، 1]
إلا:
plt.text (0.4، 0.5، "الاحتمالات غير متوفرة"، المحاذاة الأفقية = "المركز"، المحاذاة الرأسية = "المركز"، التحويل = plt.gca (). transAxes، Fontize = 12)
plt.axis ("off")
استراحة
Z = Z.reshape (xx. شكل)
مبعثر plt. (X [y.values == 0، 0]، X [y.values == 0، 1]، alpha = 0.4، label = 'Edible'، s = 5)
مبعثر plt. (X [y.values == 1، 0]، X [y.values == 1، 1]، alpha = 0.4، label = 'Posionous'، s = 5)
plt.imshow (Z، interpolation = 'الأقرب'، cmap = 'RdYlBu_r'، alpha = 0.15، مدى = (x_min، x_max، y_min، y_max)، origin = 'Lower')
plt.title (plot_type + '\ n' + str (mount_model) .split ('(') [0] + 'Test Accuracy:' + str (np.round (mount_model.score (X، y)، 5)) )
plt.gca (). set_aspect ("يساوي") ؛
plt.tight_layout ()
plt.subplots_adjust (أعلى = 0.9 ، أسفل = 0.08 ، مسافة wspace = 0.02)
2. الانحدار اللوجستي
على عكس الانحدار الخطي ، يتعامل الانحدار اللوجستي مع تقدير القيم المنفصلة (0/1 قيم ثنائية ، صواب / خطأ ، نعم / لا). هذه التقنية تسمى أيضًا الانحدار اللوغاريتمي Logit regression. هذا لأنه يتنبأ باحتمالية حدث باستخدام وظيفة تسجيل لتدريب البيانات المقدمة. تقع القيمة دائمًا بين 0 و 1 (نظرًا لأنها تحسب احتمالًا).
يتم إنشاء احتمالات سجل النتائج كمجموعة خطية من متغير التوقع على النحو التالي:
الاحتمالات = ع / (1 - ع) = احتمال وقوع الحدث أو احتمال عدم وقوع الحدث
ln (الاحتمالات) = ln (p / (1 - p))

logit (p) = ln (p / (1 - p)) = b0 + b1X1 + b2X2 + b3X3 + ... + bkXk
حيث p هو احتمال وجود خاصية.
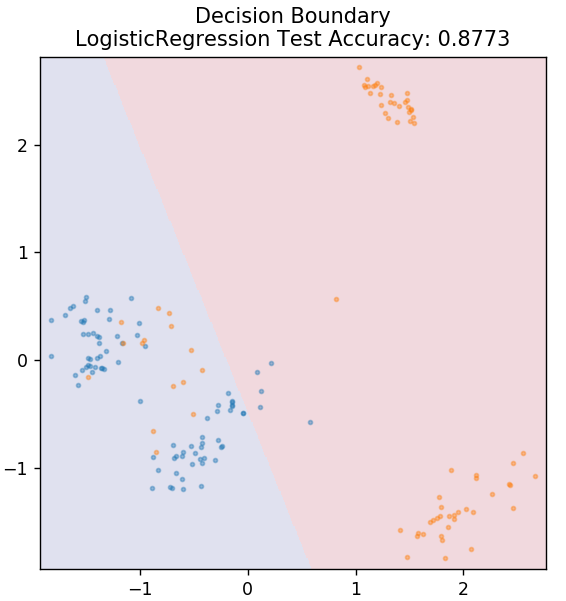
من sklearn.linear_model استيراد LogisticRegression
النموذج = LogisticRegression ()
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
احصل على شهادة الذكاء الاصطناعي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
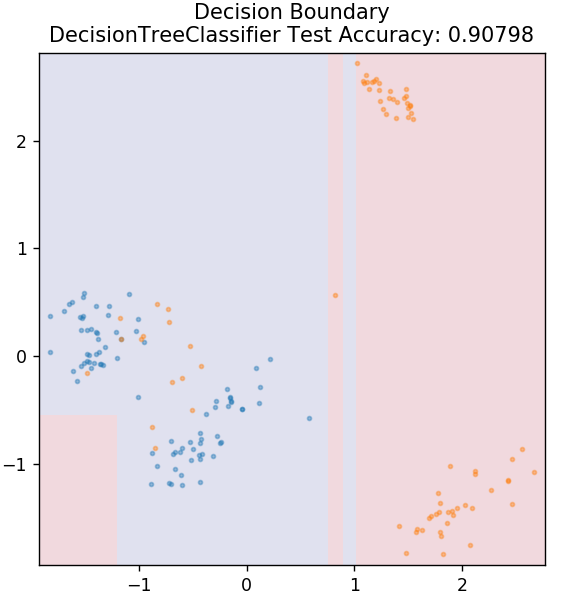
3. شجرة القرار
هذه خوارزمية شائعة جدًا يمكن استخدامها لتصنيف كل من المتغيرات المستمرة والمنفصلة للبيانات. في كل خطوة ، يتم تقسيم البيانات إلى أكثر من مجموعة متجانسة بناءً على بعض سمات / شروط التقسيم.
من sklearn.tree استيراد DecisionTreeClassifier
النموذج = DecisionTreeClassifier (max_depth = 3)
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
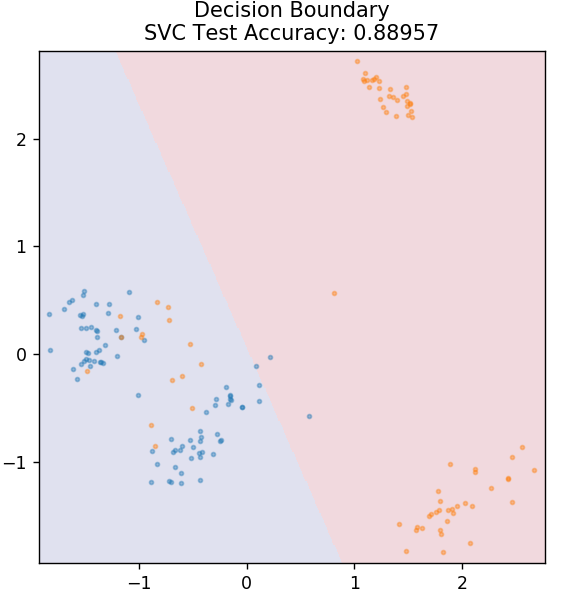
4. SVM
SVM اختصار لـ Support Vector Machines. الفكرة الأساسية هنا هي تصنيف نقاط البيانات باستخدام المخططات الفائقة للفصل. الهدف هو اكتشاف مثل هذا المستوى الفائق الذي يحتوي على أقصى مسافة (أو هامش) بين نقاط البيانات لكل من الفئات أو الفئات.
نختار الطائرة بهذه الطريقة لرعاية تصنيف النقاط المجهولة في المستقبل بأعلى مستوى من الثقة. يُشتهر استخدام أجهزة SVM لأنها تعطي دقة عالية مع استهلاك طاقة حسابية أقل. يمكن أيضًا استخدام SVMs في مشاكل الانحدار.
من sklearn.svm استيراد SVC
النموذج = SVC (النواة = "خطي")
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
الخروج: مشاريع Python على GitHub
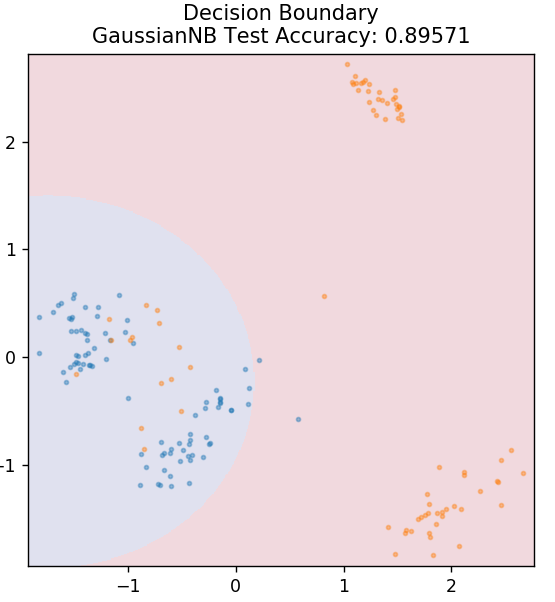
5. ساذج بايز
كما يوحي الاسم ، فإن خوارزمية Naive Bayes هي خوارزمية تعلم خاضعة للإشراف تعتمد على نظرية بايز . تستخدم نظرية بايز الاحتمالات الشرطية لتعطيك احتمالية وقوع حدث بناءً على بعض المعرفة المعطاة.
أين، 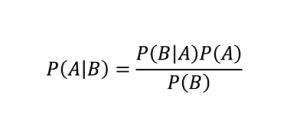
P (A | B): الاحتمال الشرطي لحدوث الحدث A ، بالنظر إلى أن الحدث B قد وقع بالفعل. (يسمى أيضًا الاحتمال اللاحق)
P (A): احتمالية الحدث A.
P (B): احتمالية الحدث B.
P (B | A): الاحتمال الشرطي لحدوث الحدث B ، بالنظر إلى أن الحدث A قد وقع بالفعل.
أنت تسأل لماذا تسمى هذه الخوارزمية ساذجة؟ هذا لأنه يفترض أن جميع تكرارات الأحداث مستقلة عن بعضها البعض. لذلك تحدد كل ميزة على حدة الفئة التي تنتمي إليها نقطة البيانات ، دون وجود أي تبعيات فيما بينها. Naive Bayes هو الخيار الأفضل لتصنيفات النص. ستعمل بشكل جيد بما فيه الكفاية حتى مع كميات صغيرة من بيانات التدريب.
من sklearn.naive_bayes استيراد GaussianNB
النموذج = GaussianNB ()
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
5. KNN
KNN تعني K-Nearest Neighbours. إنها خوارزمية تعلم خاضعة للإشراف تستخدم على نطاق واسع وتصنف بيانات الاختبار وفقًا لأوجه تشابهها مع بيانات التدريب المصنفة مسبقًا. لا تصنف KNN جميع نقاط البيانات أثناء التدريب. بدلاً من ذلك ، يقوم فقط بتخزين مجموعة البيانات وعندما يحصل على أي بيانات جديدة ، فإنه يصنف نقاط البيانات هذه بناءً على أوجه التشابه بينها. يقوم بذلك عن طريق حساب المسافة الإقليدية لعدد K لأقرب الجيران (هنا ، n_ الجيران ) لنقطة البيانات تلك.
من sklearn.neighbours استيراد KNeighboursClassifier
النموذج = KNeighboursClassifier (n_neighbours = 20)
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
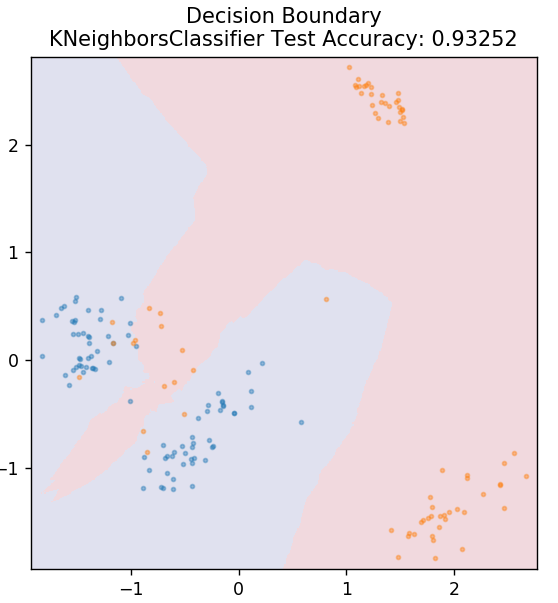
6. الغابة العشوائية
Random Forest هي خوارزمية تعلم آلي بسيطة جدًا ومتنوعة تستخدم تقنية تعلم خاضعة للإشراف. كما يمكنك نوع التخمين من الاسم ، تتكون الغابة العشوائية من عدد كبير من أشجار القرار ، والتي تعمل كمجموعة. ستحدد كل شجرة قرار فئة المخرجات لنقاط البيانات وسيتم اختيار فئة الأغلبية كمخرج نهائي للنموذج. الفكرة هنا هي أن المزيد من الأشجار التي تعمل على نفس البيانات تميل إلى أن تكون أكثر دقة في النتائج من الأشجار الفردية.
من sklearn.ensemble استيراد RandomForestClassifier
النموذج = RandomForestClassifier ()
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
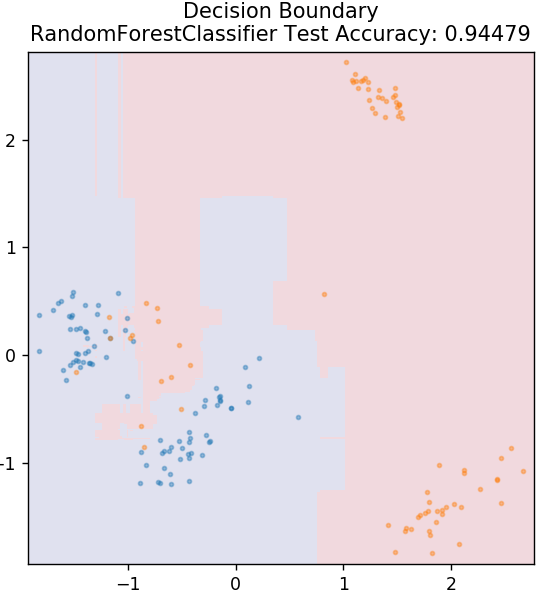
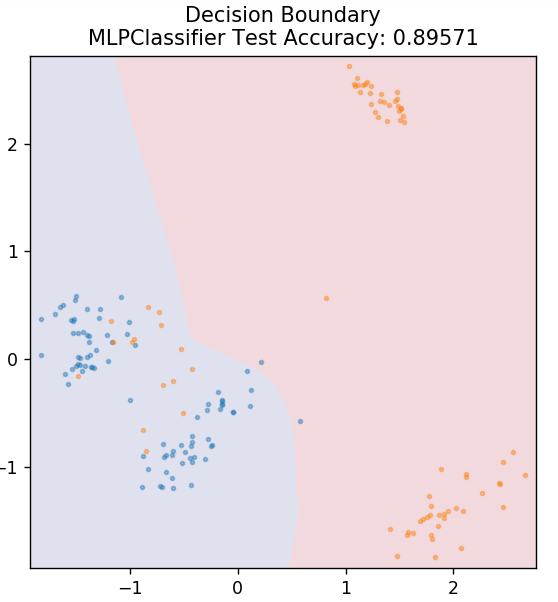
7. متعدد الطبقات Perceptron
تعد Perceptron متعدد الطبقات (أو MLP) خوارزمية رائعة جدًا تندرج تحت فرع التعلم العميق. وبشكل أكثر تحديدًا ، فهو ينتمي إلى فئة الشبكات العصبية الاصطناعية ذات التغذية الأمامية (ANN). يشكل MLP شبكة من الإدراك الحسي المتعدد بثلاث طبقات على الأقل: طبقة إدخال وطبقة إخراج وطبقة (طبقات) مخفية. MLPs قادرة على التمييز بين البيانات التي لا يمكن فصلها خطيًا.
تستخدم كل خلية عصبية في الطبقات المخفية وظيفة تنشيط للانتقال إلى الطبقة التالية. هنا ، يتم استخدام خوارزمية backpropagation لضبط المعلمات فعليًا وبالتالي تدريب الشبكة العصبية. يمكن استخدامه في الغالب لمشاكل الانحدار البسيطة.
من sklearn.neural_network استيراد MLPClassifier
النموذج = MLPClassifier ()
model.fit (X_train، y_train)
plot_mushroom_boundary (X_test ، y_test ، نموذج)
اقرأ أيضًا: موضوعات وأفكار مشروع Python
خاتمة
يمكننا أن نستنتج أن خوارزميات التعلم الآلي المختلفة تنتج حدودًا مختلفة للقرار ، وبالتالي تنتج الدقة المختلفة في تصنيف مجموعة البيانات نفسها.
لا توجد طريقة لإعلان أي خوارزمية على أنها أفضل خوارزمية لجميع أنواع البيانات بشكل عام. يتطلب التعلم الآلي تجربة صارمة وأخطاء للعديد من الخوارزميات لتحديد ما هو الأفضل لكل مجموعة بيانات على حدة. من الواضح أن قائمة خوارزميات ML لا تنتهي هنا. هناك بحر واسع من التقنيات الأخرى التي تنتظر استكشافها في مكتبة Scikit-Learn في Python. انطلق وقم بتدريب مجموعات البيانات الخاصة بك باستخدام كل هؤلاء واستمتع!
إذا كنت مهتمًا بمعرفة المزيد حول أشجار القرار ، والتعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة و المهام ، وحالة خريجي IIIT-B ، وأكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع كبرى الشركات.
ما هي الافتراضات الأولية للانحدار الخطي؟
هناك 4 افتراضات أساسية للانحدار الخطي: الخطية ، والمثلية الجنسية ، والاستقلالية ، والحالة الطبيعية. الخطية تعني أن العلاقة بين المتغير المستقل (X) ومتوسط المتغير التابع (Y) تعتبر خطية عندما نستخدم الانحدار الخطي. تعني المثلية الجنسية أن التباين في أخطاء النقاط المتبقية في الرسم البياني يُفترض أنه ثابت. يشير الاستقلال إلى جميع الملاحظات من بيانات الإدخال التي يجب اعتبارها مستقلة عن بعضها البعض. تعني الحالة الطبيعية أن توزيع بيانات الإدخال يمكن أن يكون موحدًا أو غير منتظم ، ولكن من المفترض أن يتم توزيعه بشكل موحد في حالة الانحدار الخطي.
ما هي الاختلافات بين شجرة القرار والغابة العشوائية؟
تنفذ شجرة القرار عملية صنع القرار الخاصة بها ، باستخدام هيكل يشبه الشجرة يمثل النتائج المحتملة لإجراءات محددة. تستخدم Random Forest حزمة من أشجار القرار لتحليل البيانات. من خلال هذه العملية ، سيتم استخدام المزيد من البيانات بواسطة Random Forest ، ولكنها تساعد في منع فرط التجهيز وتعطي نتائج دقيقة. هناك نطاق من التجاوز في خوارزمية شجرة القرار ويمكن أن توفر نتائج أقل دقة. من السهل تفسير شجرة القرار لأنها تتطلب عددًا أقل من العمليات الحسابية ، بينما يصعب تفسير الغابة العشوائية بسبب تحليلاتها المعقدة.
ما هي بعض المكتبات القياسية المستخدمة في خوارزميات التعلم الآلي في Python؟
استبدلت Python جميع اللغات الأخرى تقريبًا في التعلم الآلي نظرًا لتوفر عدد كبير من المكتبات وقواعد بناء الجملة السهلة. هناك العديد من مكتبات Python للتعلم الآلي مثل Numpy و Scipy و Scikit-Learn و Theono و TensorFlow و PyTorch و Matplotlib و Keras و Pandas ، إلخ. إن استخدام الوظائف من هذه المكتبات يوفر الكثير من الوقت في كتابة الخوارزميات لكل مهمة ؛ تستغرق العمليات وقتًا أقل وتوفر نتائج فعالة. تحتوي هذه المكتبات على تطبيقات مثل معالجة المصفوفة ، ومشكلات التحسين ، واستخراج البيانات ، والتحليل الإحصائي ، والحسابات التي تتضمن الموترات ، واكتشاف الكائنات ، والشبكات العصبية ، وغيرها الكثير.