
15 أسئلة وأجوبة مقابلة التعلم الآلي لعام 2022
نشرت: 2021-01-08هل أنت شخص يرغب في تحقيق مستقبل مهني ناجح في التعلم الآلي؟ إذا كان الأمر كذلك ، فهذا عظيم لك!
لكن أولاً ، يجب أن تعد نفسك لكسر الجمود - مقابلة ML.
نظرًا لأن عملية التحضير للمقابلة قد تكون مربكة ، فقد قررنا التدخل - إليك قائمة منسقة تضم 15 سؤالًا الأكثر شيوعًا في مقابلات التعلم الآلي!
- ما الفرق بين التعلم العميق والتعلم الآلي؟
بينما يتضمن التعلم الآلي تطبيق واستخدام الخوارزميات المتقدمة لتحليل البيانات ، واكتشاف الأنماط المخفية داخل البيانات والتعلم منها ، وأخيراً تطبيق الرؤى المكتسبة لاتخاذ قرارات عمل مستنيرة. أما بالنسبة للتعلم العميق ، فهو مجموعة فرعية من التعلم الآلي الذي يتضمن استخدام الشبكات العصبية الاصطناعية التي تستمد الإلهام من البنية الشبكية العصبية للدماغ البشري. يستخدم التعلم العميق على نطاق واسع في اكتشاف الميزات.
- تعريف - الدقة والاستدعاء.
مقاييس الدقة أو القيمة التنبؤية الإيجابية أو بشكل أكثر دقة تتنبأ بعدد الإيجابيات الحقيقية التي يطالب بها النموذج مقارنة بعدد الإيجابيات التي يدعيها بالفعل.
يشير الاسترجاع أو المعدل الإيجابي الحقيقي إلى عدد الإيجابيات التي يطالب بها النموذج مقارنة بالعدد الفعلي للإيجابيات الموجودة في جميع البيانات.

انضم إلى دورة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
- اشرح المصطلحين "التحيز" و "التباين". "
أثناء عملية التدريب ، يتم تصنيف الخطأ المتوقع لخوارزمية التعلم بشكل عام أو تحللها إلى جزأين - التحيز والتباين. في حين أن "التحيز" هو حالة خطأ ناتجة عن استخدام افتراضات بسيطة في خوارزمية التعلم ، فإن "التباين" يشير إلى خطأ ناتج بسبب تعقيد خوارزمية التعلم هذه في تحليل البيانات. يقيس التحيز قرب المصنف المتوسط الذي أنشأته خوارزمية التعلم من الوظيفة المستهدفة ، ويقيس التباين بمدى اختلاف تنبؤات خوارزمية التعلم لمجموعات بيانات التدريب المختلفة.
- كيف يعمل منحنى ROC؟
منحنى ROC أو منحنى خاصية تشغيل جهاز الاستقبال هو تمثيل رسومي للتباين بين المعدلات الإيجابية الحقيقية والمعدلات الإيجابية الخاطئة عند عتبات متفاوتة. إنها أداة أساسية لتقييم الاختبار التشخيصي وغالبًا ما تستخدم كتمثيل للمفاضلة بين حساسية النموذج (الإيجابيات الحقيقية) مقابل احتمال إطلاق إنذارات كاذبة (إيجابيات كاذبة).
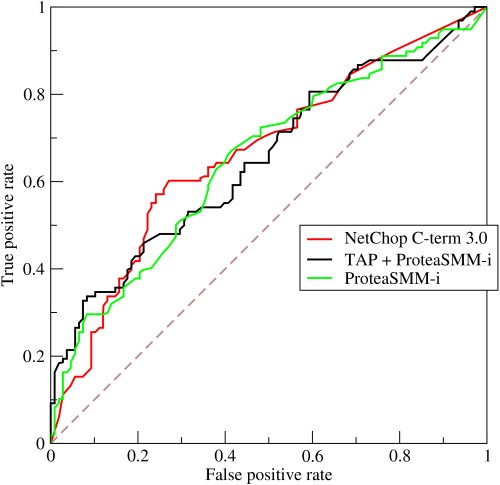
مصدر
- يصور المنحنى المفاضلة بين الحساسية والنوعية - إذا زادت الحساسية ، ستنخفض الخصوصية.
- إذا كانت حدود المنحنى أكثر باتجاه المحور الأيسر وأعلى مساحة ROC ، فعادةً ما يكون الاختبار أكثر دقة. ومع ذلك ، إذا اقترب المنحنى من القطر 45 درجة لمساحة ROC ، فإن الاختبار يكون أقل دقة أو موثوقية.
- يشير منحدر خط المماس عند نقطة القطع إلى نسبة الاحتمالية (LR) لتلك القيمة المعينة للاختبار.
- تقيس المنطقة الواقعة أسفل المنحنى دقة الاختبار.
- اشرح الفرق بين أخطاء النوع 1 والنوع 2؟
الخطأ من النوع الأول هو خطأ إيجابي خاطئ "يدعي" وقوع حادث بينما ، في الواقع ، لم يحدث شيء. أفضل مثال على الخطأ الإيجابي الكاذب هو إنذار حريق كاذب - يبدأ الإنذار في الرنين عندما لا يكون هناك حريق. على عكس ذلك ، فإن الخطأ من النوع 2 هو خطأ سلبي كاذب "يدعي" أنه لم يحدث شيء عندما حدث شيء ما بالتأكيد. سيكون خطأ من النوع 2 أن تخبر سيدة حامل بأنها لا تحمل طفلاً.
- لماذا يشار إلى Bayes باسم "Naive Bayes؟"
يشار إلى Naive Bayes باسم "ساذج" لأنه على الرغم من أنه يحتوي على العديد من التطبيقات العملية ، إلا أنه يعتمد على الافتراض الذي يستحيل العثور عليه في بيانات الحياة الواقعية - جميع الميزات في مجموعة البيانات حاسمة ومستقلة ومتساوية. في نهج Naive Bayes ، يتم حساب الاحتمال الشرطي على أنه المنتج النقي لاحتمالات المكونات الفردية ، مما يعني ضمناً الاستقلال التام للميزات. لسوء الحظ ، لا يمكن تحقيق هذا الافتراض في سيناريو العالم الحقيقي.
- ما هو المقصود بمصطلح "Overfitting"؟ هل يمكنك تجنبه؟ إذا كان الأمر كذلك ، فكيف؟
عادة ، أثناء عملية التدريب ، يتم تغذية النموذج بكميات كبيرة من البيانات. في سياق العملية ، تبدأ البيانات في التعلم حتى من المعلومات غير الدقيقة والضوضاء الموجودة في مجموعة البيانات النموذجية. هذا يخلق تأثيرًا سلبيًا على أداء النموذج على البيانات الجديدة ، أي أن النموذج لا يمكنه تصنيف الحالات / البيانات الجديدة بدقة بصرف النظر عن تلك الخاصة بمجموعة التدريب. هذا هو المعروف باسم Overfitting.
نعم ، من الممكن تجنب فرط التجهيز. إليك الطريقة:
- اجمع المزيد من البيانات (من مصادر مختلفة) لتدريب النموذج بعينات مختلفة.
- تطبيق طرق التجميع (على سبيل المثال ، Random Forest) التي تستخدم نهج التعبئة لتقليل التباين في التنبؤات عن طريق مقارنة نتائج أشجار القرار المتعددة على وحدات مختلفة من مجموعة البيانات.
- تأكد من استخدام تقنيات التحقق المتبادل.
- قم بتسمية الطريقتين المستخدمتين للمعايرة في التعلم الخاضع للإشراف.
طريقتا المعايرة في التعلم الخاضع للإشراف هما - معايرة بلات والانحدار متساوي التوتر. تم تصميم كلتا الطريقتين خصيصًا للتصنيف الثنائي.

- لماذا تقليم شجرة القرار؟
يجب تقليم أشجار القرار للتخلص من الفروع ذات القدرات التنبؤية الضعيفة. يساعد هذا في تقليل حاصل تعقيد نموذج شجرة القرار وتحسين دقته التنبؤية. يمكن إجراء التقليم إما من أعلى إلى أسفل أو من أسفل إلى أعلى. يعد التقليم المنخفض للخطأ ، وتقليم التكلفة المعقدة ، وتقليم الأخطاء المعقدة ، وتقليم الخطأ الأدنى من أكثر طرق تقليم شجرة القرار استخدامًا.
- ما المقصود بنتيجة F1؟
بعبارات بسيطة ، تعتبر درجة F1 مقياسًا لأداء النموذج - متوسط الدقة والاسترجاع لنموذج ، مع النتائج التي تقترب من 1 هي الأفضل وتلك التي تقترب من الصفر هي الأسوأ. يمكن استخدام درجة F1 في اختبارات التصنيف التي لا تركز على السلبيات الحقيقية.
- التفريق بين الخوارزمية التوليدية والتمييزية.
بينما تتعلم الخوارزمية التوليدية فئات البيانات ، تتعلم الخوارزمية التمييزية التمييز بين فئات البيانات المختلفة. عندما يتعلق الأمر بمهام التصنيف ، عادة ما تفوق النماذج التمييزية النماذج التوليدية.
- ما هو التعلم الجماعي؟
تستخدم Ensemble Learning مجموعة من خوارزميات التعلم لتحسين الأداء التنبئي للنماذج. في هذه الطريقة ، يتم إنشاء نماذج متعددة مثل المصنفات أو الخبراء بشكل استراتيجي ودمجها لمنع فرط التخصيص في النماذج. يتم استخدامه في الغالب لتحسين التنبؤ والتصنيف وتقريب الوظيفة والأداء وما إلى ذلك ، لنموذج ما.
- حدد "Kernel Trick".
تتضمن طريقة Kernel Trick استخدام وظائف kernel التي يمكن أن تعمل في مساحة ميزة ضمنية وذات أبعاد أعلى دون الحاجة إلى حساب إحداثيات النقاط داخل هذا البعد بشكل صريح. تحسب دالات Kernel المنتجات الداخلية بين صور جميع أزواج البيانات الموجودة في مساحة الميزة. هذا الإجراء أرخص من الناحية الحسابية مقارنة بالحساب الصريح للإحداثيات ويعرف باسم Kernel Trick.
- كيف يجب أن تتعامل مع البيانات المفقودة أو التالفة في مجموعة البيانات؟
للعثور على البيانات المفقودة / التالفة في مجموعة البيانات ، يجب عليك إما إسقاط الصفوف والأعمدة أو استبدالها بقيم أخرى. مكتبة Pandas لديها طريقتان رائعتان للعثور على البيانات المفقودة / التالفة - isnull () و dropna (). تم تصميم هاتين الوظيفتين خصيصًا لمساعدتك في العثور على صفوف / أعمدة البيانات ذات البيانات المفقودة / التالفة وإسقاط هذه القيم.
- ما هو Hash Table؟
جدول التجزئة هو هيكل بيانات يقوم بإنشاء مصفوفة ترابطية ، حيث يتم تعيين مفتاح لقيم محددة باستخدام دالة تجزئة. تستخدم جداول التجزئة في الغالب في فهرسة قاعدة البيانات.
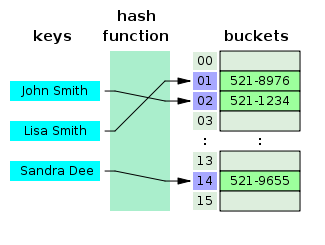
مصدر
تهدف قائمة الأسئلة هذه فقط إلى تعريفك بأساسيات التعلم الآلي ، وبصراحة ، هذه الأسئلة العشرين هي مجرد قطرة في بحر. يتقدم التعلم الآلي بينما نتحدث ، وبالتالي ، مع مرور الوقت ، ستظهر مفاهيم جديدة. وبالتالي ، فإن المفتاح لإبراز مقابلات ML الخاصة بك يكمن في إيواء الرغبة المستمرة في التعلم والارتقاء بالمهارات. لذا ، ابدأ وابدأ في اجتياح الإنترنت ، واقرأ المجلات ، وانضم إلى المجتمعات عبر الإنترنت ، واحضر مؤتمرات وندوات ML - هناك العديد من الطرق للتعلم.
للدخول في مؤسسة كبيرة ، من الضروري الحصول على شهادة من مؤسسة مرموقة. تحقق من IIIT-B's Executive PG Program in Machine Learning & AI واحصل على مساعدة وظيفية من أفضل شركات التعلم الآلي والذكاء الاصطناعي.
ما هي حدود التعلم الجماعي؟
يمكن أن تساعد مناهج المجموعات في تقليل التباين وتطوير نماذج أكثر قوة. ومع ذلك ، هناك عيوب معينة لاستخدام تقنيات المجموعات ، مثل الافتقار إلى القابلية للتفسير والأداء. علاوة على ذلك ، ضع في اعتبارك أن فعالية المجموعات تنبع من قدرتها على تجميع نماذج متعددة تركز على جوانب مختلفة من المشكلة. ومع ذلك ، فإن لديهم فترة توقع أطول لأنك قد تحتاج إلى تنبؤات من مئات النماذج. حتى لو كانت لديهم توقعات أفضل ، فقد لا يكون اكتساب الدقة أمرًا يستحق كل هذا العناء.
ما هو الوقت اللازم لتعلم التعلم الآلي؟
عندما يتعلق الأمر بالتعلم الآلي ، فإن التقنيات المعقدة المستخدمة لنفسه قد تخيف الناس بسهولة. ومع ذلك ، فإن فهمها شيئًا فشيئًا ليس بالأمر الصعب. ستساعدك الخبرة السابقة في الإحصاء والرياضيات المتقدمة وما إلى ذلك بلا شك في استيعاب جميع المفاهيم بسرعة. ومع ذلك ، نظرًا لأن الخلفية التعليمية والمهارات تتراوح من شخص لآخر ، فقد يتعلم فرد واحد ML في ثلاثة أسابيع بينما قد يحتاج الآخر إلى عام.
كيف يتم استخدام التعلم الآلي في حياتنا اليومية؟
يصنف Gmail رسائل البريد الإلكتروني على أنها ضرورية من خلال تصنيفها على أنها أساسية ، ورسائل ترويجية ، واجتماعية ، وتحديث باستخدام التعلم الآلي. تستخدم الشركات الشبكات العصبية لاكتشاف المعاملات الاحتيالية بناءً على بيانات مثل أحدث تواتر للمعاملات ومبلغ المعاملة ونوع التاجر. تستفيد أجهزة كشف السرقة الأدبية أيضًا من التعلم الآلي. عندما يتعلق الأمر بهندسة ML ، فإن الأمر يستغرق حوالي ستة أشهر حتى ينتهي.