
KNN Classifier لتعلم الآلة: كل ما تحتاج إلى معرفته
نشرت: 2021-09-28هل تتذكر الوقت الذي كان فيه الذكاء الاصطناعي (AI) مجرد مفهوم يقتصر على روايات وأفلام الخيال العلمي؟ حسنًا ، بفضل التقدم التكنولوجي ، أصبح الذكاء الاصطناعي شيئًا نعيش معه الآن كل يوم. من وجود Alexa و Siri تحت تصرفنا والاتصال بمنصات OTT "اختيار يدوي" للأفلام التي نرغب في مشاهدتها ، أصبح الذكاء الاصطناعي تقريبًا هو أمر اليوم وهو هنا لنقوله في المستقبل المنظور.
كل هذا ممكن بفضل خوارزميات ML المتقدمة. اليوم ، سنتحدث عن أحد خوارزمية ML المفيدة ، مصنف K-NN.
يستخدم التعلم الآلي ، وهو فرع من فروع الذكاء الاصطناعي وعلوم الكمبيوتر ، البيانات والخوارزميات لتقليد الفهم البشري مع تحسين دقة الخوارزميات تدريجيًا. يتضمن التعلم الآلي خوارزميات التدريب لعمل تنبؤات أو تصنيفات واكتشاف الأفكار الرئيسية التي تدفع عملية اتخاذ القرار الاستراتيجي داخل الشركات والتطبيقات.
تعد خوارزمية KNN (أقرب جوار) خوارزمية تعلم آلي أساسية خاضعة للإشراف تُستخدم لحل عبارات مشكلة الانحدار والتصنيف. لذلك ، دعنا نتعمق لمعرفة المزيد عن مصنف K-NN.
جدول المحتويات
التعلم الآلي الخاضع للإشراف مقابل غير الخاضع للإشراف
يعد التعلم الخاضع للإشراف وغير الخاضع للإشراف نهجين أساسيين لعلوم البيانات ، ومن المناسب معرفة الفرق قبل الخوض في تفاصيل KNN.
التعلم الخاضع للإشراف هو نهج التعلم الآلي الذي يستخدم مجموعات البيانات المصنفة للمساعدة في توقع النتائج. تم تصميم مجموعات البيانات هذه "للإشراف" أو تدريب الخوارزميات على توقع النتائج أو تصنيف البيانات بدقة. ومن ثم ، فإن المدخلات والمخرجات ذات العلامات تمكن النموذج من التعلم بمرور الوقت مع تحسين دقته.

يتضمن التعلم الخاضع للإشراف نوعين من المشاكل - التصنيف والانحدار. في مشاكل التصنيف ، تخصص الخوارزميات بيانات الاختبار في فئات منفصلة ، مثل فصل القطط عن الكلاب.
من الأمثلة الواقعية الهامة تصنيف رسائل البريد العشوائي في مجلد منفصل عن صندوق الوارد الخاص بك. من ناحية أخرى ، فإن طريقة الانحدار للتعلم تحت الإشراف تدرب الخوارزميات لفهم العلاقة بين المتغيرات المستقلة والتابعة. يستخدم نقاط بيانات مختلفة للتنبؤ بالقيم العددية ، مثل توقع إيرادات المبيعات لنشاط تجاري.
على العكس من ذلك ، فإن التعلم غير الخاضع للإشراف يستخدم خوارزميات التعلم الآلي لتحليل مجموعات البيانات غير الموسومة وتجميعها. وبالتالي ، ليست هناك حاجة لتدخل بشري ("غير خاضع للإشراف") للخوارزميات لتحديد الأنماط المخفية في البيانات.
نماذج التعلم غير الخاضعة للإشراف لها ثلاثة تطبيقات رئيسية - الارتباط والتكتل وتقليل الأبعاد. ومع ذلك ، لن نخوض في التفاصيل نظرًا لأنها خارج نطاق مناقشتنا.
K- أقرب الجار (KNN)
خوارزمية K-Nearest Neighbor أو KNN هي خوارزمية تعلم آلي تعتمد على نموذج التعلم الخاضع للإشراف. تعمل خوارزمية K-NN من خلال افتراض وجود أشياء متشابهة بالقرب من بعضها البعض. ومن ثم ، فإن خوارزمية K-NN تستخدم تشابه الميزات بين نقاط البيانات الجديدة والنقاط في مجموعة التدريب (الحالات المتاحة) للتنبؤ بقيم نقاط البيانات الجديدة. في الأساس ، تقوم خوارزمية K-NN بتعيين قيمة لأحدث نقطة بيانات بناءً على مدى تشابهها مع النقاط الموجودة في مجموعة التدريب. تجد خوارزمية K-NN تطبيقًا في كل من مشاكل التصنيف والانحدار ولكنها تستخدم بشكل أساسي لمشاكل التصنيف.
إليك مثال لفهم مصنف K-NN.

مصدر
في الصورة أعلاه ، قيمة الإدخال عبارة عن مخلوق له أوجه تشابه بين كل من قطة وكلب. ومع ذلك ، نريد تصنيفها إما إلى قطة أو كلب. لذلك ، يمكننا استخدام خوارزمية K-NN لهذا التصنيف. سيجد نموذج K-NN أوجه تشابه بين مجموعة البيانات الجديدة (الإدخال) لصور القطط والكلاب المتاحة (مجموعة بيانات التدريب). بعد ذلك ، سيضع النموذج نقطة البيانات الجديدة في فئة القط أو الكلب بناءً على الميزات الأكثر تشابهًا.
وبالمثل ، تحتوي الفئة أ (النقاط الخضراء) والفئة ب (النقاط البرتقالية) على المثال الرسومي أعلاه. لدينا أيضًا نقطة بيانات جديدة (نقطة زرقاء) تقع ضمن أي من الفئات. يمكننا حل مشكلة التصنيف هذه باستخدام خوارزمية K-NN وتحديد فئة نقطة البيانات الجديدة.
تحديد خصائص خوارزمية K-NN
تعرف الخاصيتان التاليتان بشكل أفضل خوارزمية K-NN:
- إنها خوارزمية تعليمية كسولة لأنه بدلاً من التعلم من مجموعة التدريب على الفور ، تقوم خوارزمية K-NN بتخزين مجموعة البيانات والقطارات من مجموعة البيانات في وقت التصنيف.
- K-NN هي أيضًا خوارزمية غير معلمية ، مما يعني أنها لا تضع أي افتراضات حول البيانات الأساسية.
عمل خوارزمية K-NN
الآن ، دعنا نلقي نظرة على الخطوات التالية لفهم كيفية عمل خوارزمية K-NN.
الخطوة 1: تحميل بيانات التدريب والاختبار.
الخطوة 2: اختر أقرب نقاط البيانات ، أي قيمة K.
الخطوة 3: احسب مسافة K عدد الجيران (المسافة بين كل صف من بيانات التدريب وبيانات الاختبار). الطريقة الإقليدية هي الأكثر استخدامًا لحساب المسافة.
الخطوة 4: خذ أقرب جيران K بناءً على المسافة الإقليدية المحسوبة.
الخطوة 5: من بين أقرب جيران K ، احسب عدد نقاط البيانات في كل فئة.
الخطوة 6: قم بتخصيص نقاط البيانات الجديدة لتلك الفئة التي يكون عدد الجيران فيها بحد أقصى.
الخطوة 7: النهاية. النموذج جاهز الآن.
انضم إلى دورات الذكاء الاصطناعي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع مسار حياتك المهنية.
اختيار قيمة K.
K هي معلمة مهمة في خوارزمية K-NN. ومن ثم ، علينا أن نضع في اعتبارنا بعض النقاط قبل أن نقرر قيمة K.
يعد استخدام منحنيات الخطأ طريقة شائعة لتحديد قيمة K. تُظهر الصورة أدناه منحنيات الخطأ لقيم K المختلفة لبيانات الاختبار والتدريب.

مصدر
في المثال الرسومي أعلاه ، خطأ القطار هو صفر عند K = 1 في بيانات التدريب لأن أقرب جار للنقطة هو تلك النقطة نفسها. ومع ذلك ، فإن خطأ الاختبار مرتفع حتى عند القيم المنخفضة لـ K. وهذا ما يسمى التباين العالي أو فرط تجهيز البيانات. يقل خطأ الاختبار مع زيادة قيمة K. ، ولكن بعد قيمة معينة لـ K ، نرى أن خطأ الاختبار يزداد مرة أخرى ، ويسمى التحيز أو التقليل من الملاءمة. وبالتالي ، يكون خطأ بيانات الاختبار مرتفعًا في البداية بسبب التباين ، وبالتالي ينخفض ويستقر ، ومع زيادة أخرى في قيمة K ، يرتفع خطأ الاختبار مرة أخرى بسبب التحيز.

لذلك ، فإن قيمة K التي يستقر عندها خطأ الاختبار وتكون منخفضة تؤخذ على أنها القيمة المثلى لـ K. بالنظر إلى منحنى الخطأ أعلاه ، K = 8 هي القيمة المثلى.
مثال لفهم عمل خوارزمية K-NN
ضع في اعتبارك مجموعة البيانات التي تم رسمها على النحو التالي:

مصدر
لنفترض أن هناك نقطة بيانات جديدة (نقطة سوداء) عند (60،60) والتي يتعين علينا تصنيفها إما إلى فئة أرجوانية أو حمراء. سنستخدم K = 3 ، مما يعني أن نقطة البيانات الجديدة ستعثر على أقرب ثلاث نقاط بيانات ، اثنتان في الفئة الحمراء وواحدة في الفئة الأرجواني.
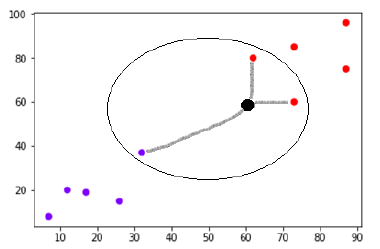
مصدر
يتم تحديد أقرب الجيران عن طريق حساب المسافة الإقليدية بين نقطتين. فيما يلي توضيح لإظهار كيفية إجراء الحساب.

مصدر
الآن ، نظرًا لأن اثنين (من الثلاثة) من أقرب جيران لنقطة البيانات الجديدة (النقطة السوداء) يقعان في الفئة الحمراء ، فسيتم أيضًا تخصيص نقطة البيانات الجديدة للفئة الحمراء.
انضم إلى دورة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
K-NN كمصنف (التنفيذ في Python)
الآن بعد أن حصلنا على شرح مبسط لخوارزمية K-NN ، دعنا ننتقل إلى تنفيذ خوارزمية K-NN في Python. سنركز فقط على مصنف K-NN.
الخطوة 1: استيراد حزم Python الضرورية.

مصدر
الخطوة 2: قم بتنزيل مجموعة بيانات iris من مستودع التعلم الآلي لـ UCI. رابط الويب الخاص به هو "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
الخطوة 3: قم بتعيين أسماء الأعمدة لمجموعة البيانات.

مصدر
الخطوة 4: اقرأ مجموعة البيانات إلى Pandas DataFrame.

مصدر
الخطوة 5: تتم المعالجة المسبقة للبيانات باستخدام سطور البرنامج النصي التالية.

مصدر
الخطوة 6: قسّم مجموعة البيانات إلى قسم اختبار وتدريب. سيقوم الكود أدناه بتقسيم مجموعة البيانات إلى 40٪ بيانات اختبار و 60٪ بيانات تدريب.

مصدر
الخطوة 7: قياس البيانات يتم على النحو التالي:

مصدر
الخطوة 8: تدريب النموذج باستخدام فئة KNeighboursClassifier من sklearn.

مصدر
الخطوة 9: قم بعمل توقع باستخدام البرنامج النصي التالي:

مصدر
الخطوة 10: اطبع النتائج.

مصدر
انتاج:

مصدر
ماذا بعد؟ الاشتراك في برنامج الشهادة المتقدمة في التعلم الآلي من IIT Madras و upGrad
لنفترض أنك تطمح لأن تصبح عالم بيانات ماهرًا أو محترفًا في التعلم الآلي. في هذه الحالة ، فإن دورة الشهادة المتقدمة في التعلم الآلي والسحابة من IIT Madras و upGrad مخصصة لك فقط!
تم تصميم البرنامج عبر الإنترنت لمدة 12 شهرًا خصيصًا للمهنيين العاملين الذين يتطلعون إلى إتقان المفاهيم في التعلم الآلي ومعالجة البيانات الضخمة وإدارة البيانات وتخزين البيانات والسحابة ونشر نماذج التعلم الآلي.
فيما يلي بعض النقاط البارزة في الدورة التدريبية لإعطائك فكرة أفضل عما يقدمه البرنامج:
- شهادة مرموقة مقبولة عالميًا من IIT Madras
- أكثر من 500 ساعة من التعلم ، وأكثر من 20 دراسة حالة ومشروعًا ، وأكثر من 25 جلسة إرشاد في المجال ، وأكثر من 8 مهام تشفير
- تغطية شاملة لـ 7 لغات وأدوات برمجة
- 4 أسابيع من مشروع تتويجا للصناعة
- ورش عمل عملية
- شبكات نظير إلى نظير دون اتصال بالإنترنت
اشترك اليوم لمعرفة المزيد عن البرنامج!
خاتمة
مع مرور الوقت ، تستمر البيانات الضخمة في النمو ، ويصبح الذكاء الاصطناعي متشابكًا بشكل متزايد مع حياتنا. نتيجة لذلك ، هناك ارتفاع حاد في الطلب على متخصصي علوم البيانات الذين يمكنهم الاستفادة من قوة نماذج التعلم الآلي لجمع رؤى البيانات وتحسين العمليات التجارية الهامة ، وبشكل عام ، عالمنا. لا شك أن مجال الذكاء الاصطناعي والتعلم الآلي يبدو واعدًا حقًا. مع upGrad ، يمكنك أن تطمئن إلى أن حياتك المهنية في التعلم الآلي والسحابة مجزية!
لماذا K-NN مصنف جيد؟
الميزة الأساسية لـ K-NN على خوارزميات التعلم الآلي الأخرى هي أنه يمكننا استخدام K-NN بسهولة لتصنيف متعدد الطبقات. وبالتالي ، فإن K-NN هي أفضل خوارزمية إذا احتجنا إلى تصنيف البيانات إلى أكثر من فئتين أو إذا كانت البيانات تشتمل على أكثر من تسميتين. إلى جانب ذلك ، فهو مثالي للبيانات غير الخطية ولديه دقة عالية نسبيًا.
ما حدود خوارزمية K-NN؟
تعمل خوارزمية K-NN عن طريق حساب المسافة بين نقاط البيانات. ومن ثم ، فمن الواضح أنها خوارزمية تستغرق وقتًا أطول نسبيًا وستستغرق وقتًا أطول لتصنيفها في بعض الحالات. لذلك ، من الأفضل عدم استخدام عدد كبير جدًا من نقاط البيانات أثناء استخدام K-NN للتصنيف متعدد الفئات. تشمل القيود الأخرى التخزين العالي للذاكرة والحساسية للميزات غير ذات الصلة.
ما هي تطبيقات العالم الحقيقي لـ K-NN؟
لدى K-NN العديد من حالات الاستخدام الواقعية في التعلم الآلي ، مثل اكتشاف خط اليد والتعرف على الكلام والتعرف على الفيديو والتعرف على الصور. في البنوك ، يتم استخدام K-NN للتنبؤ بما إذا كان الفرد مؤهلاً للحصول على قرض بناءً على ما إذا كان لديه خصائص مماثلة للمتعثرين. في السياسة ، يمكن استخدام K-NN لتصنيف الناخبين المحتملين إلى فئات مختلفة مثل "سوف يصوتون للحزب X" أو "سوف يصوتون للحزب Y ،" إلخ.