
تقديم واجهة برمجة التطبيقات (API) القائمة على المكون
نشرت: 2022-03-10تم تحديث هذه المقالة في 31 يناير 2019 للرد على ملاحظات القراء. أضاف المؤلف إمكانات الاستعلام المخصصة إلى واجهة برمجة التطبيقات القائمة على المكون ووصف كيفية عملها .
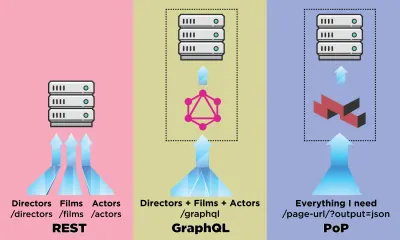
API هي قناة الاتصال لتطبيق ما لتحميل البيانات من الخادم. في عالم واجهات برمجة التطبيقات ، كانت REST هي المنهجية الأكثر رسوخًا ، لكن GraphQL طغت عليها مؤخرًا ، والتي تقدم مزايا مهمة مقارنة بـ REST. في حين أن REST يتطلب طلبات HTTP متعددة لجلب مجموعة من البيانات لعرض أحد المكونات ، يمكن لـ GraphQL الاستعلام عن هذه البيانات واستردادها في طلب واحد ، وستكون الاستجابة هي بالضبط ما هو مطلوب ، دون زيادة أو نقص البيانات كما يحدث عادةً في راحة.
في هذه المقالة ، سأصف طريقة أخرى لجلب البيانات التي صممتها وأطلق عليها اسم "PoP" (ومفتوحة المصدر هنا) ، والتي تتوسع في فكرة جلب البيانات للعديد من الكيانات في طلب واحد مقدم من GraphQL وتأخذها خطوة أبعد ، على سبيل المثال ، بينما يقوم REST بجلب البيانات لمورد واحد ، وتقوم GraphQL بجلب البيانات لجميع الموارد في مكون واحد ، يمكن لواجهة برمجة التطبيقات القائمة على المكون جلب البيانات لجميع الموارد من جميع المكونات في صفحة واحدة.
يكون استخدام واجهة برمجة التطبيقات القائمة على المكونات أكثر منطقية عندما يتم إنشاء موقع الويب باستخدام مكونات ، أي عندما تتكون صفحة الويب بشكل متكرر من مكونات تغلف مكونات أخرى حتى نحصل في الجزء العلوي على مكون واحد يمثل الصفحة. على سبيل المثال ، تم إنشاء صفحة الويب الموضحة في الصورة أدناه بمكونات تم تحديدها بمربعات:
يمكن لواجهة برمجة التطبيقات القائمة على المكون تقديم طلب واحد للخادم عن طريق طلب البيانات لجميع الموارد في كل مكون (بالإضافة إلى جميع المكونات الموجودة في الصفحة) والتي يتم إنجازها عن طريق الحفاظ على العلاقات بين المكونات في هيكل API نفسه.
من بين أمور أخرى ، يقدم هذا الهيكل الفوائد العديدة التالية:
- الصفحة التي تحتوي على العديد من المكونات ستطلق طلبًا واحدًا فقط بدلاً من العديد ؛
- يمكن جلب البيانات المشتركة عبر المكونات مرة واحدة فقط من قاعدة البيانات وطباعتها مرة واحدة فقط في الاستجابة ؛
- يمكن أن يقلل بشكل كبير - حتى يزيل تمامًا - الحاجة إلى مخزن البيانات.
سنستكشف هذه التفاصيل بالتفصيل في جميع أنحاء المقالة ، ولكن أولاً ، دعنا نستكشف المكونات الموجودة بالفعل وكيف يمكننا إنشاء موقع بناءً على هذه المكونات ، وأخيراً ، استكشاف كيفية عمل واجهة برمجة التطبيقات القائمة على المكون.
يوصى بقراءة : كتاب تمهيدي لـ GraphQL: لماذا نحتاج إلى نوع جديد من واجهة برمجة التطبيقات
بناء موقع من خلال المكونات
المكون هو ببساطة مجموعة من أجزاء من كود HTML و JavaScript و CSS يتم تجميعها معًا لإنشاء كيان مستقل. يمكن أن يؤدي هذا بعد ذلك إلى التفاف المكونات الأخرى لإنشاء هياكل أكثر تعقيدًا ، وأن يتم لفها بمكونات أخرى أيضًا. للمكون غرض ، والذي يمكن أن يتراوح من شيء أساسي للغاية (مثل رابط أو زر) إلى شيء معقد للغاية (مثل الرف الدائري أو أداة تحميل الصور بالسحب والإفلات). تكون المكوّنات مفيدة للغاية عندما تكون عامة وتمكّن التخصيص من خلال الخصائص المحقونة (أو "الدعائم") ، بحيث يمكن أن تخدم مجموعة واسعة من حالات الاستخدام. في الحالة القصوى ، يصبح الموقع نفسه مكونًا.
غالبًا ما يستخدم مصطلح "مكون" للإشارة إلى كل من الوظيفة والتصميم. على سبيل المثال ، فيما يتعلق بالوظائف ، تسمح أطر عمل JavaScript مثل React أو Vue بإنشاء مكونات من جانب العميل ، والتي تكون قادرة على العرض الذاتي (على سبيل المثال ، بعد أن تجلب واجهة برمجة التطبيقات البيانات المطلوبة) ، وتستخدم الخاصيات لتعيين قيم التكوين على مكونات ملفوفة ، مما يتيح إمكانية إعادة استخدام الكود. فيما يتعلق بالتصميم ، قام Bootstrap بتوحيد شكل وشعور مواقع الويب من خلال مكتبة مكونات الواجهة الأمامية ، وأصبح اتجاهًا صحيًا للفرق لإنشاء أنظمة تصميم للحفاظ على مواقع الويب الخاصة بهم ، مما يسمح لأعضاء الفريق المختلفين (المصممين والمطورين ، ولكن أيضًا المسوقين والباعة) للتحدث بلغة موحدة والتعبير عن هوية متسقة.
يعد تكوين موقع ما طريقة معقولة للغاية لجعل موقع الويب أكثر قابلية للصيانة. المواقع التي تستخدم أطر عمل JavaScript مثل React و Vue هي بالفعل قائمة على المكونات (على الأقل من جانب العميل). لا يؤدي استخدام مكتبة مكونة مثل Bootstrap بالضرورة إلى جعل الموقع قائمًا على المكونات (يمكن أن يكون كتلة كبيرة من HTML) ، ومع ذلك ، فإنه يدمج مفهوم العناصر القابلة لإعادة الاستخدام لواجهة المستخدم.
إذا كان الموقع عبارة عن كتلة كبيرة من HTML ، بالنسبة لنا لتقسيمه إلى مكونات ، يجب علينا تقسيم التنسيق إلى سلسلة من الأنماط المتكررة ، والتي يجب علينا تحديد أقسام الصفحة وفهرستها بناءً على تشابه وظائفها وأنماطها ، وكسر هذه أقسام إلى طبقات ، دقيقة قدر الإمكان ، في محاولة لجعل كل طبقة تركز على هدف أو إجراء واحد ، ومحاولة أيضًا مطابقة الطبقات المشتركة عبر أقسام مختلفة.
ملاحظة : يعد "التصميم الذري" لبراد فروست منهجية رائعة لتحديد هذه الأنماط الشائعة وبناء نظام تصميم قابل لإعادة الاستخدام.
ومن ثم ، فإن بناء موقع من خلال المكونات يشبه اللعب بـ LEGO. كل مكون هو إما وظيفة ذرية ، أو تكوين مكونات أخرى ، أو مزيج من الاثنين.
كما هو موضح أدناه ، يتكون المكون الأساسي (الصورة الرمزية) بشكل متكرر من مكونات أخرى حتى الحصول على صفحة الويب في الأعلى:

مواصفات API المستندة إلى المكون
بالنسبة لواجهة برمجة التطبيقات (API) القائمة على المكونات التي قمت بتصميمها ، يُطلق على المكون اسم "وحدة نمطية" ، لذلك من الآن فصاعدًا يتم استخدام المصطلحين "مكون" و "وحدة" بالتبادل.
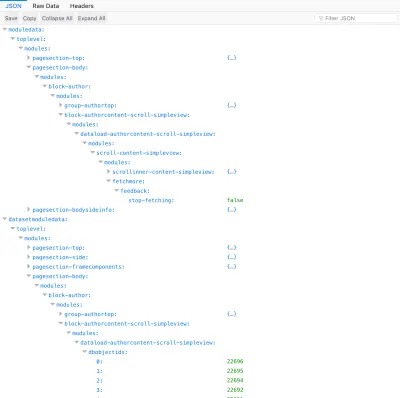
تسمى العلاقة بين جميع الوحدات التي تلتف مع بعضها البعض ، بدءًا من الوحدة النمطية العلوية وصولاً إلى المستوى الأخير ، "التسلسل الهرمي للمكونات". يمكن التعبير عن هذه العلاقة من خلال مصفوفة ترابطية (مصفوفة مفتاح => خاصية) على جانب الخادم ، حيث تحدد كل وحدة اسمها على أنها السمة الرئيسية والوحدات النمطية الداخلية لها ضمن modules الخصائص. ثم تقوم واجهة برمجة التطبيقات (API) ببساطة بترميز هذه المصفوفة ككائن JSON للاستهلاك:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }يتم تحديد العلاقة بين الوحدات بأسلوب تنازلي صارم: تقوم الوحدة النمطية بتغليف الوحدات الأخرى وتعرف من تكون ، ولكنها لا تعرف - ولا تهتم - الوحدات التي تغلفها.
على سبيل المثال ، في كود JSON أعلاه ، يعرف مستوى الوحدة module-level1 أنه يلتف للوحدات module-level11 module-level12 ، ويعرف أيضًا أنه يلتف module-level121 ؛ لكن الوحدة module-level11 ، وبالتالي فهي غير مدركة لمستوى module-level1 .
بوجود الهيكل القائم على المكون ، يمكننا الآن إضافة المعلومات الفعلية المطلوبة من قبل كل وحدة ، والتي يتم تصنيفها في أي من الإعدادات (مثل قيم التكوين والخصائص الأخرى) والبيانات (مثل معرفات كائنات قاعدة البيانات التي تم الاستعلام عنها وخصائص أخرى) ، ويتم وضعها وفقًا لذلك ضمن وحدات وحدات الإدخالات modulesettings moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } بعد ذلك ، ستضيف واجهة برمجة التطبيقات بيانات كائن قاعدة البيانات. لا يتم وضع هذه المعلومات تحت كل وحدة ، ولكن ضمن قسم مشترك يسمى databases ، لتجنب تكرار المعلومات عندما تقوم وحدتان مختلفتان أو أكثر بجلب نفس الكائنات من قاعدة البيانات.
بالإضافة إلى ذلك ، تمثل واجهة برمجة التطبيقات بيانات كائن قاعدة البيانات بطريقة علائقية ، لتجنب تكرار المعلومات عندما يرتبط اثنان أو أكثر من كائنات قاعدة البيانات المختلفة بكائن مشترك (مثل عمليتين لهما نفس المؤلف). بمعنى آخر ، يتم تطبيع بيانات كائن قاعدة البيانات.
يوصى بالقراءة : إنشاء نموذج اتصال بدون خادم لموقعك الثابت
الهيكل عبارة عن قاموس ، منظم تحت كل نوع كائن أولاً ومعرف الكائن ثانيًا ، والذي يمكننا من خلاله الحصول على خصائص الكائن:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }كائن JSON هذا هو بالفعل استجابة من واجهة برمجة التطبيقات القائمة على المكون. تنسيقه عبارة عن مواصفات في حد ذاته: طالما أن الخادم يُرجع استجابة JSON بالتنسيق المطلوب ، يمكن للعميل أن يستهلك واجهة برمجة التطبيقات بشكل مستقل عن كيفية تنفيذها. ومن ثم ، يمكن تنفيذ واجهة برمجة التطبيقات على أي لغة (وهي واحدة من ميزات GraphQL: كونها مواصفات وليست تطبيقًا فعليًا قد مكنها من أن تصبح متاحة بعدد لا يحصى من اللغات).
ملاحظة : في مقال قادم ، سأصف تطبيقي لواجهة برمجة التطبيقات القائمة على المكونات في PHP (وهو المتاح في الريبو).
مثال على استجابة API
على سبيل المثال ، تحتوي استجابة واجهة برمجة التطبيقات أدناه على تسلسل هرمي للمكونات مع وحدتين ، page => post-feed ، حيث تجلب وحدة post-feed منشورات المدونة. يرجى ملاحظة ما يلي:
- تعرف كل وحدة نمطية العناصر التي تم الاستعلام عنها من الخاصية
dbobjectids(المعرفان4و9لمنشورات المدونة) - تعرف كل وحدة نمط الكائن الخاص بالكائنات التي تم الاستعلام عنها من
dbkeysللخاصية (توجد بيانات كل منشور ضمنposts، وبيانات مؤلف المنشور ، المقابلة للمؤلف مع المعرّف الوارد ضمنauthorخاصية المنشور ، توجد ضمنusers) - نظرًا لأن بيانات كائن قاعدة البيانات علائقية ، فإن
authorالخاصية يحتوي على معرف كائن المؤلف بدلاً من طباعة بيانات المؤلف مباشرةً.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }الاختلافات في جلب البيانات من واجهات برمجة التطبيقات المستندة إلى الموارد والقائمة على المخطط والمكونات
دعونا نرى كيف تقارن واجهة برمجة التطبيقات القائمة على المكونات مثل PoP ، عند جلب البيانات ، بواجهة برمجة التطبيقات القائمة على الموارد مثل REST ، وواجهة برمجة التطبيقات القائمة على المخطط مثل GraphQL.
لنفترض أن موقع IMDB يحتوي على صفحة بها مكونان يحتاجان إلى جلب البيانات: "مخرج متميز" (يعرض وصفًا لجورج لوكاس وقائمة بأفلامه) و "أفلام موصى بها لك" (تعرض أفلامًا مثل Star Wars: Episode I - تهديد الشبح والمنهي ). يمكن أن يبدو كالتالي:
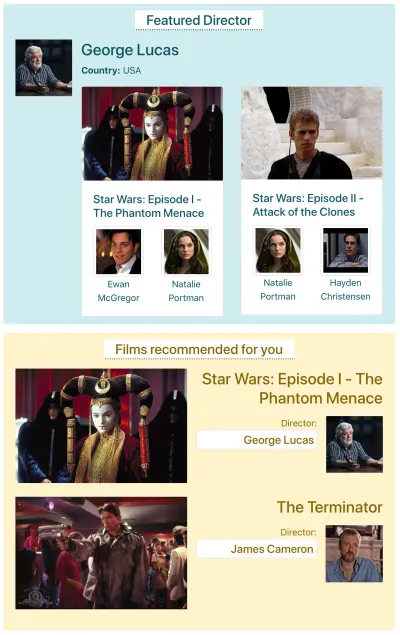
دعونا نرى عدد الطلبات اللازمة لجلب البيانات من خلال كل طريقة من طرق API. في هذا المثال ، يأتي مكوِّن "المخرج المميز" بنتيجة واحدة ("جورج لوكاس") ، يسترد منها فيلمين ( حرب النجوم: الحلقة الأولى - تهديد الشبح وحرب النجوم: الحلقة الثانية - هجوم المستنسخين ) ، و لكل فيلم ممثلان ("إيوان ماكجريجور" و "ناتالي بورتمان" للفيلم الأول ، و "ناتالي بورتمان" و "هايدن كريستنسن" للفيلم الثاني). يأتي المكون "أفلام موصى بها لك" بنتيجتين ( حرب النجوم: الحلقة الأولى - تهديد الشبح و The Terminator ) ، ثم يجلب مخرجيهما ("جورج لوكاس" و "جيمس كاميرون" على التوالي).
باستخدام REST لتقديم المكون featured-director ، قد نحتاج إلى الطلبات السبعة التالية (يمكن أن يختلف هذا الرقم اعتمادًا على مقدار البيانات التي يتم توفيرها بواسطة كل نقطة نهاية ، أي مقدار الجلب الزائد الذي تم تنفيذه):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen تسمح GraphQL ، من خلال المخططات المكتوبة بقوة ، بجلب جميع البيانات المطلوبة في طلب واحد لكل مكون. يبدو الاستعلام الخاص بجلب البيانات من خلال GraphQL للمكون featuredDirector الدليل هكذا (بعد أن قمنا بتنفيذ المخطط المقابل):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }وتنتج الاستجابة التالية:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }والاستعلام عن المكون "أفلام موصى بها لك" ينتج عنه الاستجابة التالية:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } سيصدر PoP طلبًا واحدًا فقط لجلب جميع البيانات لجميع المكونات في الصفحة ، وتطبيع النتائج. نقطة النهاية المراد استدعاؤها هي ببساطة نفس عنوان URL الذي نحتاج إليه للحصول على البيانات ، فقط إضافة معلمة إضافية output=json للإشارة إلى إحضار البيانات بتنسيق JSON بدلاً من طباعتها بتنسيق HTML:
GET - /url-of-the-page/?output=json بافتراض أن هيكل الوحدة يحتوي على وحدة نمطية عليا مسماة page تحتوي على وحدات featured-director films-recommended-for-you ، ولديها أيضًا وحدات فرعية ، مثل هذا:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"ستبدو استجابة JSON المفردة كما يلي:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }دعونا نحلل كيفية مقارنة هذه الطرق الثلاث مع بعضها البعض ، من حيث السرعة وكمية البيانات المستردة.
سرعة
من خلال REST ، فإن الاضطرار إلى جلب 7 طلبات فقط لتقديم مكون واحد يمكن أن يكون بطيئًا للغاية ، في الغالب على اتصالات البيانات المتنقلة والهشة. ومن ثم ، فإن الانتقال من REST إلى GraphQL يمثل قدرًا كبيرًا من السرعة ، لأننا قادرون على تقديم مكون بطلب واحد فقط.
PoP ، لأنه يمكن أن يجلب جميع البيانات للعديد من المكونات في طلب واحد ، سيكون أسرع لتقديم العديد من المكونات في وقت واحد ؛ ومع ذلك ، على الأرجح ليست هناك حاجة لذلك. يعد تقديم المكونات بالترتيب (كما تظهر في الصفحة) ممارسة جيدة بالفعل ، وبالنسبة للمكونات التي تظهر تحت الجزء المرئي من الصفحة ، فلا داعي للتسرع في عرضها بالتأكيد. ومن ثم ، فإن واجهات برمجة التطبيقات (API) القائمة على المخطط والمكونات هي بالفعل جيدة جدًا ومتفوقة بشكل واضح على واجهة برمجة التطبيقات القائمة على الموارد.
كمية البيانات
في كل طلب ، يمكن تكرار البيانات في استجابة GraphQL: تم جلب الممثلة "ناتالي بورتمان" مرتين في الاستجابة من المكون الأول ، وعند النظر في الإخراج المشترك للمكونين ، يمكننا أيضًا العثور على بيانات مشتركة ، مثل الفيلم حرب النجوم: الحلقة الأولى - تهديد الشبح .
من ناحية أخرى ، يقوم PoP بتطبيع بيانات قاعدة البيانات ويطبعها مرة واحدة فقط ، ومع ذلك ، فإنه يحمل عبء طباعة هيكل الوحدة. ومن ثم ، بناءً على الطلب المعين الذي يحتوي على بيانات مكررة أم لا ، فإن واجهة API المستندة إلى المخطط أو واجهة برمجة التطبيقات القائمة على المكون سيكون لها حجم أصغر.
في الختام ، تعد واجهة برمجة التطبيقات القائمة على المخطط مثل GraphQL وواجهة برمجة التطبيقات القائمة على المكونات مثل PoP جيدة أيضًا فيما يتعلق بالأداء وتتفوق على واجهة برمجة التطبيقات القائمة على الموارد مثل REST.
يوصى بالقراءة : فهم واستخدام REST APIs
الخصائص الخاصة لواجهة برمجة التطبيقات القائمة على المكون
إذا لم تكن واجهة برمجة التطبيقات (API) القائمة على المكون أفضل بالضرورة من حيث الأداء من واجهة برمجة التطبيقات القائمة على المخطط ، فقد تتساءل ، فما الذي أحاول تحقيقه من خلال هذه المقالة؟
في هذا القسم ، سأحاول إقناعك بأن واجهة برمجة التطبيقات هذه تتمتع بإمكانيات مذهلة ، حيث توفر العديد من الميزات المرغوبة للغاية ، مما يجعلها منافسًا جادًا في عالم واجهات برمجة التطبيقات. أصف وأعرض كل من ميزاته الرائعة الفريدة أدناه.
يمكن استنتاج البيانات المراد استردادها من قاعدة البيانات من التسلسل الهرمي للمكونات
عندما تعرض وحدة نمطية خاصية من كائن قاعدة بيانات ، قد لا تعرف الوحدة النمطية ، أو تهتم ، ما هو الكائن ؛ كل ما يهم هو تحديد الخصائص المطلوبة من الكائن المحمل.
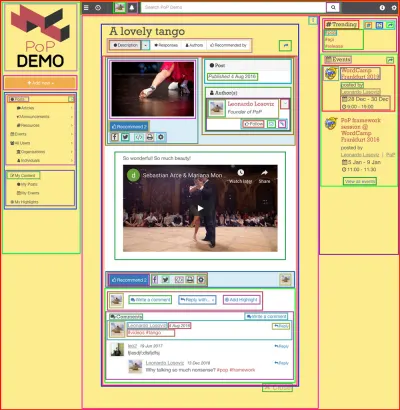
على سبيل المثال ، انظر إلى الصورة أدناه. تقوم الوحدة بتحميل عنصر من قاعدة البيانات (في هذه الحالة ، منشور واحد) ، ثم ستعرض الوحدات التابعة لها خصائص معينة من الكائن ، مثل title content :
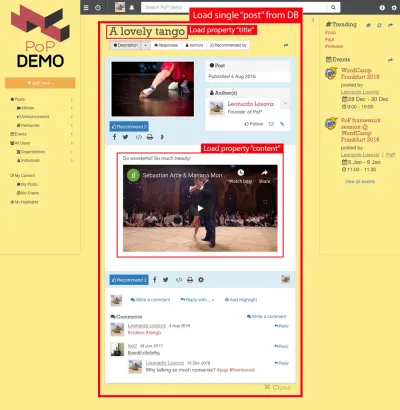
ومن ثم ، على طول التسلسل الهرمي للمكونات ، ستكون وحدات "تحميل البيانات" مسؤولة عن تحميل الكائنات المطلوبة (الوحدة النمطية التي تقوم بتحميل المنشور الفردي ، في هذه الحالة) ، وستحدد الوحدات التابعة لها الخصائص المطلوبة من كائن قاعدة البيانات ( title content ، في هذه الحالة).
يمكن إحضار جميع الخصائص المطلوبة لكائن قاعدة البيانات تلقائيًا عن طريق اجتياز التسلسل الهرمي للمكونات: بدءًا من وحدة تحميل البيانات ، نقوم بتكرار جميع الوحدات النمطية التابعة لها على طول الطريق حتى الوصول إلى وحدة تحميل بيانات جديدة ، أو حتى نهاية الشجرة ؛ في كل مستوى نحصل على جميع الخصائص المطلوبة ، ثم نقوم بدمج جميع الخصائص معًا والاستعلام عنها من قاعدة البيانات ، وكلها مرة واحدة فقط.
في الهيكل أدناه ، تقوم الوحدة النمطية single-post بإحضار النتائج من قاعدة البيانات (المنشور ذي المعرف 37) ، وتحدد الوحدات الفرعية post-title post-content الخصائص التي سيتم تحميلها لكائن قاعدة البيانات الذي تم الاستعلام عنه ( title content على التوالي) ؛ لا تتطلب الوحدات الفرعية post-layout و fetch-next-post-button أي حقول بيانات.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"يتم حساب الاستعلام المراد تنفيذه تلقائيًا من التسلسل الهرمي للمكونات وحقول البيانات المطلوبة ، والتي تحتوي على جميع الخصائص التي تحتاجها جميع الوحدات النمطية ووحداتها الفرعية:
SELECT title, content FROM posts WHERE id = 37 من خلال جلب الخصائص للاسترداد مباشرة من الوحدات النمطية ، سيتم تحديث الاستعلام تلقائيًا كلما تغير التسلسل الهرمي للمكونات. إذا قمنا ، على سبيل المثال ، بإضافة post-thumbnail للوحدة الفرعية ، والتي تتطلب thumbnail لحقل البيانات:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"ثم يتم تحديث الاستعلام تلقائيًا لجلب الخاصية الإضافية:
SELECT title, content, thumbnail FROM posts WHERE id = 37نظرًا لأننا أنشأنا بيانات كائن قاعدة البيانات ليتم استردادها بطريقة علائقية ، يمكننا أيضًا تطبيق هذه الاستراتيجية بين العلاقات بين كائنات قاعدة البيانات نفسها.
ضع في اعتبارك الصورة أدناه: بدءًا من post نوع الكائن والانتقال إلى أسفل التسلسل الهرمي للمكونات ، سنحتاج إلى تحويل نوع كائن قاعدة البيانات إلى user comment ، بما يتوافق مع مؤلف المنشور وكل تعليق من تعليقات المنشور على التوالي ، ثم لكل منها التعليق ، يجب تغيير نوع الكائن مرة أخرى إلى user المقابل لمؤلف التعليق.
الانتقال من كائن قاعدة بيانات إلى كائن علائقي (ربما تغيير نوع الكائن ، كما في post => انتقال author من post إلى user ، أو لا ، كما في author => المتابعون الذين ينتقلون من user إلى user ) هو ما أسميه "تبديل المجالات ".
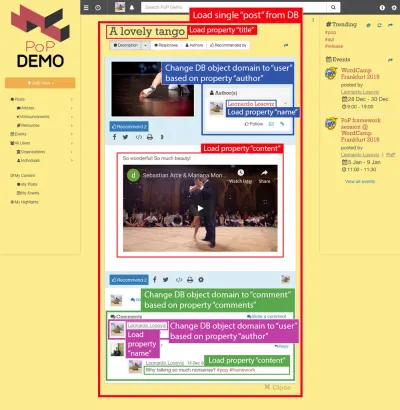
بعد التبديل إلى مجال جديد ، من هذا المستوى في التسلسل الهرمي للمكونات إلى أسفل ، ستخضع جميع الخصائص المطلوبة للمجال الجديد:
- تم جلب
nameمن كائنuser(يمثل مؤلف المنشور) ، - يتم جلب
contentمن كائنcomment(يمثل كل تعليق من تعليقات المنشور) ، - تم جلب
nameمن كائنuser(يمثل مؤلف كل تعليق).
من خلال اجتياز التسلسل الهرمي للمكونات ، تعرف واجهة برمجة التطبيقات (API) متى يتم التبديل إلى مجال جديد وتقوم ، بشكل مناسب ، بتحديث الاستعلام لجلب الكائن العلائقي.
على سبيل المثال ، إذا احتجنا إلى إظهار البيانات من مؤلف المنشور ، فسيؤدي تكديس المؤلف post-author للوحدة الفرعية إلى تغيير المجال في هذا المستوى من post إلى user المقابل ، ومن هذا المستوى إلى أسفل ، يكون كائن قاعدة البيانات الذي تم تحميله في السياق الذي تم تمريره إلى الوحدة النمطية هو المستخدم. بعد ذلك ، سيتم تحميل الوحدات الفرعية user-name و user-avatar ضمن post-author name الخصائص avatar ضمن كائن user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"الناتج عن الاستعلام التالي:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idباختصار ، من خلال تكوين كل وحدة نمطية بشكل مناسب ، ليست هناك حاجة لكتابة الاستعلام لجلب البيانات لواجهة برمجة التطبيقات القائمة على المكون. يتم إنشاء الاستعلام تلقائيًا من هيكل التسلسل الهرمي للمكونات نفسه ، والحصول على الكائنات التي يجب تحميلها بواسطة وحدات تحميل البيانات ، والحقول المراد استردادها لكل كائن محمل محدد في كل وحدة فرعية ، وتبديل المجال المحدد في كل وحدة فرعية.
ستؤدي إضافة أو إزالة أو استبدال أو تغيير أي وحدة إلى تحديث الاستعلام تلقائيًا. بعد تنفيذ الاستعلام ، ستكون البيانات المسترجعة هي المطلوبة بالضبط - لا أكثر أو أقل.
مراقبة البيانات وحساب الخصائص الإضافية
بدءًا من وحدة تحميل البيانات أسفل التسلسل الهرمي للمكونات ، يمكن لأي وحدة مراقبة النتائج التي تم إرجاعها وحساب عناصر البيانات الإضافية بناءً عليها ، أو قيم feedback ، والتي يتم وضعها ضمن moduledata .
على سبيل المثال ، يمكن للوحدة النمطية fetch-next-post-button إضافة خاصية تشير إلى ما إذا كان هناك المزيد من النتائج المطلوب جلبها أم لا (بناءً على قيمة الملاحظات هذه ، إذا لم يكن هناك المزيد من النتائج ، فسيتم تعطيل الزر أو إخفاؤه):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }المعرفة الضمنية بالبيانات المطلوبة تقلل من التعقيد وتجعل مفهوم "نقطة النهاية" قديمًا
كما هو موضح أعلاه ، يمكن لواجهة برمجة التطبيقات القائمة على المكونات جلب البيانات المطلوبة بالضبط ، لأنها تحتوي على نموذج لجميع المكونات على الخادم وما هي حقول البيانات المطلوبة من قبل كل مكون. بعد ذلك ، يمكن أن تجعل المعرفة بحقول البيانات المطلوبة ضمنية.

الميزة هي أن تحديد البيانات المطلوبة من قبل المكون يمكن تحديثه فقط من جانب الخادم ، دون الحاجة إلى إعادة نشر ملفات JavaScript ، ويمكن جعل العميل غبيًا ، فقط يطلب من الخادم تقديم أي بيانات يحتاجها ، وبالتالي تقليل تعقيد التطبيق من جانب العميل.
بالإضافة إلى ذلك ، يمكن تنفيذ استدعاء واجهة برمجة التطبيقات لاسترداد البيانات لجميع مكونات عنوان URL محدد ببساطة عن طريق الاستعلام عن عنوان URL هذا بالإضافة إلى إضافة output=json للإشارة إلى بيانات واجهة برمجة التطبيقات العائدة بدلاً من طباعة الصفحة. ومن ثم ، يصبح عنوان URL نقطة النهاية الخاصة به أو ، إذا تم النظر إليه بطريقة مختلفة ، يصبح مفهوم "نقطة النهاية" عفا عليه الزمن.
استرداد مجموعات فرعية من البيانات: يمكن جلب البيانات لوحدات نمطية معينة ، يمكن العثور عليها في أي مستوى من التسلسل الهرمي للمكونات
ماذا يحدث إذا لم نكن بحاجة إلى جلب البيانات لجميع الوحدات في الصفحة ، ولكن ببساطة البيانات الخاصة بوحدة نمطية معينة تبدأ من أي مستوى من التسلسل الهرمي للمكونات؟ على سبيل المثال ، إذا نفذت الوحدة النمطية التمرير اللانهائي ، فعند التمرير لأسفل ، يجب علينا جلب بيانات جديدة فقط لهذه الوحدة ، وليس للوحدات النمطية الأخرى على الصفحة.
يمكن تحقيق ذلك عن طريق تصفية فروع التسلسل الهرمي للمكونات التي سيتم تضمينها في الاستجابة ، لتشمل الخصائص التي تبدأ فقط من الوحدة النمطية المحددة وتجاهل كل شيء فوق هذا المستوى. في تطبيقي (الذي سأصفه في مقال قادم) ، يتم تمكين التصفية عن طريق إضافة modulefilter=modulepaths إلى عنوان URL ، وتتم الإشارة إلى الوحدة (أو الوحدات النمطية) المحددة من خلال معلمة modulepaths[] ، حيث "مسار الوحدة النمطية "هي قائمة الوحدات التي تبدأ من أعلى وحدة إلى الوحدة المحددة (على سبيل المثال module1 => module2 => module3 بها مسار وحدة نمطية [ module1 ، module2 ، module3 ] ويتم تمريرها كمعامل URL مثل module1.module2.module3 ) .
على سبيل المثال ، في التسلسل الهرمي للمكونات أدناه ، تحتوي كل وحدة نمطية على إدخال dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] ثم طلب عنوان URL لصفحة الويب بإضافة معلمات modulefilter=modulepaths and modulepaths[]=module1.module2.module5 سيؤدي إلى الاستجابة التالية:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] في الأساس ، تبدأ API في تحميل البيانات بدءًا من module1 => module2 => module5 . هذا هو السبب في أن module6 ، التي تأتي ضمن module5 ، تجلب بياناتها أيضًا بينما لا تقوم الوحدة module3 module4 بذلك.
بالإضافة إلى ذلك ، يمكننا إنشاء مرشحات وحدة مخصصة لتضمين مجموعة وحدات مرتبة مسبقًا. على سبيل المثال ، استدعاء صفحة باستخدام module3 modulefilter=userstate يمكنه طباعة تلك الوحدات النمطية التي تتطلب حالة المستخدم لعرضها في العميل ، مثل الوحدات النمطية 3 والوحدة module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] تأتي المعلومات الخاصة بوحدات البداية ضمن قسم requestmeta ، ضمن وحدات filteredmodules الإدخال ، كمصفوفة من مسارات الوحدة:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }تسمح هذه الميزة بتنفيذ تطبيق أحادي الصفحة غير معقد ، حيث يتم تحميل إطار الموقع عند الطلب الأولي:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] ولكن ، من الآن فصاعدًا ، يمكننا إلحاق modulefilter=page بجميع عناوين URL المطلوبة ، مع تصفية الإطار وإحضار محتوى الصفحة فقط:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] على غرار مرشحات الوحدة النمطية userstate page الموضحة أعلاه ، يمكننا تنفيذ أي مرشح وحدة مخصص وإنشاء تجارب مستخدم ثرية.
الوحدة هي واجهة برمجة التطبيقات الخاصة بها
كما هو موضح أعلاه ، يمكننا تصفية استجابة API لاسترداد البيانات بدءًا من أي وحدة. نتيجة لذلك ، يمكن لكل وحدة أن تتفاعل مع نفسها من عميل إلى خادم فقط عن طريق إضافة مسار الوحدة الخاصة بها إلى عنوان URL لصفحة الويب التي تم تضمينها فيها.
أتمنى أن تتعذروا على فرط الإثارة ، لكنني حقًا لا أستطيع التأكيد بما فيه الكفاية على مدى روعة هذه الميزة. عند إنشاء مكون ، لا نحتاج إلى إنشاء واجهة برمجة تطبيقات لتتماشى معه لاسترداد البيانات (REST أو GraphQL أو أي شيء على الإطلاق) ، لأن المكون قادر بالفعل على التحدث إلى نفسه في الخادم وتحميله الخاص البيانات - هي مستقلة تمامًا وذاتية الخدمة .
تصدر كل وحدة تحميل بيانات عنوان URL للتفاعل معها ضمن dataloadsource من مجموعة datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }إحضار البيانات مفصول عبر الوحدات وجاف
لتوضيح وجهة نظري التي مفادها أن جلب البيانات في واجهة برمجة التطبيقات القائمة على المكونات مفصول بشكل كبير وجاف ( D on't R epeat Y أنفسنا) ، سأحتاج أولاً إلى توضيح كيف أنه في واجهة برمجة التطبيقات القائمة على المخطط مثل GraphQL يكون أقل فصلًا و غير جاف.
في GraphQL ، يجب أن يشير الاستعلام لجلب البيانات إلى حقول البيانات للمكون ، والتي قد تتضمن مكونات فرعية ، وقد تتضمن أيضًا مكونات فرعية ، وما إلى ذلك. بعد ذلك ، يحتاج المكون الأعلى إلى معرفة البيانات المطلوبة من قبل كل مكون من مكوناته الفرعية أيضًا ، لجلب تلك البيانات.
على سبيل المثال ، قد يتطلب عرض مكون <FeaturedDirector> المكونات الفرعية التالية:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> في هذا السيناريو ، يتم تطبيق استعلام GraphQL على مستوى <FeaturedDirector> . بعد ذلك ، إذا تم تحديث المكون الفرعي <Film> ، وطلب العنوان من خلال الخاصية filmTitle بدلاً من title ، فسيلزم تحديث الاستعلام من مكون <FeaturedDirector> أيضًا ، لتعكس هذه المعلومات الجديدة (لدى GraphQL آلية إصدار يمكنها التعامل مع هذه المشكلة ، ولكن عاجلاً أم آجلاً لا يزال يتعين علينا تحديث المعلومات). ينتج عن ذلك تعقيد في الصيانة ، والذي قد يكون من الصعب التعامل معه عندما تتغير المكونات الداخلية غالبًا أو يتم إنتاجها بواسطة مطورين تابعين لجهات خارجية. ومن ثم ، لا يتم فصل المكونات تمامًا عن بعضها البعض.
وبالمثل ، قد نرغب في عرض مكوِّن <Film> مباشرةً لبعض الأفلام المحددة ، ومن ثم يجب علينا أيضًا تنفيذ استعلام GraphQL على هذا المستوى ، لجلب البيانات الخاصة بالفيلم وممثليه ، مما يضيف رمزًا فائضًا: أجزاء من سيعيش نفس الاستعلام على مستويات مختلفة من بنية المكون. لذا فإن GraphQL ليست جافة .
نظرًا لأن واجهة برمجة التطبيقات القائمة على المكونات تعرف بالفعل كيف تلتف مكوناتها مع بعضها البعض في هيكلها الخاص ، يتم تجنب هذه المشكلات تمامًا. أولاً ، يمكن للعميل ببساطة طلب البيانات المطلوبة التي يحتاجها ، أيًا كانت هذه البيانات ؛ if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
في واجهة برمجة التطبيقات القائمة على المكونات ، يمكننا بسهولة استخدام العلاقات بين الوحدات الموصوفة بالفعل في واجهة برمجة التطبيقات لربط الوحدات معًا. بينما في الأصل سيكون لدينا هذا الرد:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }بعد إضافة Instagram ، سنحصل على الاستجابة التي تمت ترقيتها:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } وفقط من خلال تكرار جميع القيم ضمن modulesettings["share-on-social-media"].modules يمكن ترقية المكون <ShareOnSocialMedia> لإظهار مكون <InstagramShare> دون الحاجة إلى إعادة نشر أي ملف JavaScript. ومن ثم ، فإن API يدعم إضافة وإزالة الوحدات دون المساومة على الكود من الوحدات الأخرى ، وتحقيق درجة أعلى من النمطية.
مخزن بيانات / ذاكرة تخزين مؤقت من جانب العميل
يتم تطبيع بيانات قاعدة البيانات المستردة في بنية قاموس ، وتوحيدها بحيث ، بدءًا من القيمة الموجودة على dbobjectids ، يمكن الوصول إلى أي جزء من البيانات ضمن databases فقط باتباع المسار إليها كما هو موضح من خلال إدخالات dbkeys ، أيًا كانت الطريقة التي تم بها تنظيمها . ومن ثم ، فإن منطق تنظيم البيانات أصلي بالفعل لواجهة برمجة التطبيقات نفسها.
يمكننا الاستفادة من هذا الوضع بعدة طرق. على سبيل المثال ، يمكن إضافة البيانات التي تم إرجاعها لكل طلب إلى ذاكرة تخزين مؤقت من جانب العميل تحتوي على جميع البيانات التي يطلبها المستخدم طوال الجلسة. وبالتالي ، من الممكن تجنب إضافة مخزن بيانات خارجي مثل Redux إلى التطبيق (أعني فيما يتعلق بمعالجة البيانات ، وليس فيما يتعلق بالميزات الأخرى مثل التراجع / الإعادة أو البيئة التعاونية أو تصحيح أخطاء السفر عبر الزمن).
أيضًا ، تعزز البنية القائمة على المكون التخزين المؤقت: لا يعتمد التسلسل الهرمي للمكونات على عنوان URL ، بل على المكونات المطلوبة في عنوان URL هذا. بهذه الطريقة ، سيشترك حدثان ضمن /events/1/ و /events/2/ في نفس التسلسل الهرمي للمكون ، ويمكن إعادة استخدام المعلومات الخاصة بالوحدات النمطية المطلوبة عبرهما. نتيجة لذلك ، يمكن تخزين جميع الخصائص (بخلاف بيانات قاعدة البيانات) مؤقتًا على العميل بعد إحضار الحدث الأول وإعادة استخدامها من ذلك الحين فصاعدًا ، بحيث يجب جلب بيانات قاعدة البيانات فقط لكل حدث لاحق وليس أي شيء آخر.
التمدد وإعادة الهدف
يمكن توسيع قسم databases في API ، مما يتيح تصنيف المعلومات إلى أقسام فرعية مخصصة. بشكل افتراضي ، يتم وضع جميع بيانات كائن قاعدة البيانات ضمن الإدخال primary ، ومع ذلك ، يمكننا أيضًا إنشاء إدخالات مخصصة حيث يتم وضع خصائص كائن قاعدة بيانات محددة.
على سبيل المثال ، إذا كان المكون "أفلام موصى بها لك" الموصوف سابقًا يعرض قائمة بأصدقاء المستخدم الذي سجّل الدخول والذين شاهدوا هذا الفيلم ضمن خاصية friendsWhoWatchedFilm في كائن DB film ، لأن هذه القيمة ستتغير بناءً على تسجيل الدخول المستخدم ثم userstate هذه الخاصية تحت إدخال حالة المستخدم بدلاً من ذلك ، لذلك عندما يقوم المستخدم بتسجيل الخروج ، نحذف هذا الفرع فقط من قاعدة البيانات المخزنة مؤقتًا على العميل ، ولكن تظل جميع البيانات primary كما يلي:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }بالإضافة إلى ذلك ، حتى نقطة معينة ، يمكن إعادة تصميم بنية استجابة API. على وجه الخصوص ، يمكن طباعة نتائج قاعدة البيانات في بنية بيانات مختلفة ، مثل مصفوفة بدلاً من القاموس الافتراضي.
على سبيل المثال ، إذا كان نوع الكائن واحدًا فقط (مثل films ) ، فيمكن تنسيقه كمصفوفة يتم إدخالها مباشرة في مكون رأس الطباعة:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]دعم البرمجة الموجهة نحو الجانب
بالإضافة إلى جلب البيانات ، يمكن لواجهة برمجة التطبيقات القائمة على المكون أيضًا نشر البيانات ، مثل إنشاء منشور أو إضافة تعليق ، وتنفيذ أي نوع من العمليات ، مثل تسجيل دخول المستخدم أو الخروج منه ، وإرسال رسائل البريد الإلكتروني ، والتسجيل ، والتحليلات ، وما إلى ذلك وهلم جرا. لا توجد قيود: يمكن استدعاء أي وظيفة يوفرها نظام إدارة المحتوى الأساسي من خلال وحدة نمطية - على أي مستوى.
على طول التسلسل الهرمي للمكونات ، يمكننا إضافة أي عدد من الوحدات ، ويمكن لكل وحدة تنفيذ العملية الخاصة بها. ومن ثم ، لا يجب بالضرورة أن تكون جميع العمليات مرتبطة بالإجراء المتوقع للطلب ، كما هو الحال عند إجراء عملية POST أو PUT أو DELETE في REST أو إرسال طفرة في GraphQL ، ولكن يمكن إضافتها لتوفير وظائف إضافية ، مثل إرسال بريد إلكتروني إلى المسؤول عندما ينشئ المستخدم منشورًا جديدًا.
لذلك ، من خلال تحديد التسلسل الهرمي للمكونات من خلال إدخال التبعية أو ملفات التكوين ، يمكن القول أن واجهة برمجة التطبيقات تدعم البرمجة الموجهة نحو الجانب ، "نموذج برمجة يهدف إلى زيادة النمطية من خلال السماح بفصل الاهتمامات المشتركة."
يوصى بقراءة : حماية موقعك باستخدام سياسة الميزات
تعزيز الأمن
لا يتم بالضرورة إصلاح أسماء الوحدات عند طباعتها في الإخراج ، ولكن يمكن اختصارها أو تشويهها أو تغييرها عشوائيًا أو (باختصار) تغييرها بأي طريقة مقصودة. أثناء التفكير في الأصل في تقصير ناتج API (بحيث يمكن تقصير أسماء الوحدات النمطية carousel-featured-posts أو drag-and-drop-user-images إلى تدوين أساسي 64 ، مثل a1 و a2 وما إلى ذلك ، لبيئة الإنتاج ) ، تسمح هذه الميزة بتغيير أسماء الوحدات بشكل متكرر في الاستجابة من واجهة برمجة التطبيقات لأسباب أمنية.
على سبيل المثال ، يتم تسمية أسماء المدخلات افتراضيًا كوحدة نمطية مقابلة لها ؛ ثم ، تسمى الوحدات النمطية اسم username password ، والتي سيتم تقديمها في العميل على أنها <input type="text" name="{input_name}"> و <input type="password" name="{input_name}"> على التوالي ، يمكن تعيين قيم عشوائية متغيرة لأسماء المدخلات الخاصة بهم (مثل zwH8DSeG و QBG7m6EF اليوم و c3oMLBjo و c46oVgN6 غدًا) مما يجعل من الصعب على مرسلي البريد العشوائي والروبوتات استهداف الموقع.
براعة من خلال النماذج البديلة
يسمح تداخل الوحدات النمطية بالتفرع إلى وحدة نمطية أخرى لإضافة التوافق لوسيلة أو تقنية معينة ، أو تغيير بعض التصميم أو الوظائف ، ثم العودة إلى الفرع الأصلي.
على سبيل المثال ، لنفترض أن صفحة الويب تحتوي على البنية التالية:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" في هذه الحالة ، نود أن نجعل موقع الويب يعمل أيضًا مع AMP ، ومع ذلك ، فإن الوحدات النمطية module2 و module4 و module5 ليست متوافقة مع AMP. يمكننا تقسيم هذه الوحدات إلى وحدات نمطية متشابهة ومتوافقة مع AMP module2AMP و module4AMP و module5AMP ، وبعد ذلك نستمر في تحميل التسلسل الهرمي للمكونات الأصلية ، لذلك يتم استبدال هذه الوحدات الثلاث فقط (ولا شيء غير ذلك):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"هذا يجعل من السهل إلى حد ما إنشاء مخرجات مختلفة من قاعدة شفرة واحدة ، وإضافة مفترقات هنا وهناك فقط حسب الحاجة ، ودائمًا ما يتم تحديد نطاقها وتقييدها على الوحدات الفردية.
وقت المظاهرة
الكود الذي يطبق API كما هو موضح في هذه المقالة متاح في هذا المستودع مفتوح المصدر.
لقد قمت بنشر PoP API ضمن https://nextapi.getpop.org لأغراض العرض التوضيحي. يعمل موقع الويب على WordPress ، لذا فإن الروابط الثابتة لعناوين URL هي تلك الموجودة في WordPress. كما أشرنا سابقًا ، من خلال إضافة معلمة output=json إليهم ، تصبح عناوين URL هذه نقاط نهاية API الخاصة بهم.
الموقع مدعوم بقاعدة البيانات نفسها من موقع PoP Demo ، لذلك يمكن عمل تصور للتسلسل الهرمي للمكونات والبيانات المسترجعة بالاستعلام عن نفس عنوان URL في هذا الموقع الآخر (على سبيل المثال ، زيارة https://demo.getpop.org/u/leo/ يشرح البيانات من https://nextapi.getpop.org/u/leo/?output=json ).
توضح الروابط أدناه واجهة برمجة التطبيقات للحالات الموضحة سابقًا في:
- الصفحة الرئيسية ، منشور واحد ، مؤلف ، قائمة منشورات وقائمة مستخدمين.
- حدث ، تصفية من وحدة معينة.
- علامة ووحدات تصفية تتطلب حالة المستخدم وفلترًا لإحضار صفحة فقط من تطبيق أحادي الصفحة.
- مجموعة من المواقع ، لتغذية الكتابة.
- نماذج بديلة لصفحة "من نحن": عادي ، قابل للطباعة ، قابل للتضمين.
- تغيير أسماء الوحدات: أصلي مقابل مشوه.
- معلومات التصفية: إعدادات الوحدة فقط وبيانات الوحدة بالإضافة إلى بيانات قاعدة البيانات.
خاتمة
تعد واجهة برمجة التطبيقات الجيدة بمثابة نقطة انطلاق لإنشاء تطبيقات موثوقة وسهلة الصيانة وقوية. في هذه المقالة ، وصفت المفاهيم التي تدعم واجهة برمجة التطبيقات القائمة على المكونات والتي أعتقد أنها واجهة برمجة تطبيقات جيدة جدًا ، وآمل أن أكون قد أقنعتك أيضًا.
حتى الآن ، اشتمل تصميم وتنفيذ واجهة برمجة التطبيقات على العديد من التكرارات واستغرق الأمر أكثر من خمس سنوات - وهي ليست جاهزة تمامًا بعد. ومع ذلك ، فهو في حالة جيدة جدًا ، وليس جاهزًا للإنتاج ولكن كألفا مستقرة. في هذه الأيام ، ما زلت أعمل عليها. العمل على تحديد المواصفات المفتوحة وتنفيذ الطبقات الإضافية (مثل التقديم) وكتابة التوثيق.
في مقال قادم ، سأصف كيفية عمل تطبيق API الخاص بي. حتى ذلك الحين ، إذا كانت لديك أي أفكار حول هذا الموضوع - بغض النظر عما إذا كانت إيجابية أو سلبية - فأنا أرغب في قراءة تعليقاتك أدناه.
التحديث (31 يناير): قدرات الاستعلام المخصص
علق Alain Schlesser على أن واجهة برمجة التطبيقات التي لا يمكن الاستعلام عنها حسب الطلب من العميل لا قيمة لها ، مما يعيدنا إلى SOAP ، وبالتالي لا يمكنها التنافس مع REST أو GraphQL. بعد الإدلاء بتعليقه بعد أيام قليلة من التفكير ، كان علي أن أعترف بأنه على حق. ومع ذلك ، بدلاً من رفض واجهة برمجة التطبيقات (API) القائمة على المكونات باعتبارها مسعى حسن النية - ولكن ليس تمامًا - حتى الآن ، فقد فعلت شيئًا أفضل بكثير: لقد قمت بتنفيذ إمكانية الاستعلام المخصص لها. وتعمل مثل السحر!
في الروابط التالية ، يتم جلب البيانات الخاصة بمورد أو مجموعة من الموارد كما هو الحال عادةً من خلال REST. ومع ذلك ، من خلال fields المعلمات ، يمكننا أيضًا تحديد البيانات المحددة التي يجب استردادها لكل مورد ، وتجنب الإفراط في جلب البيانات أو نقصها:
- منشور واحد ومجموعة من المنشورات التي تضيف
fields=title,content,datetime - يضيف مستخدم ومجموعة من المستخدمين
fields=name,username,description
توضح الروابط أعلاه جلب البيانات للموارد التي تم الاستعلام عنها فقط. ماذا عن علاقاتهم؟ على سبيل المثال ، لنفترض أننا نريد استرداد قائمة بالمشاركات ذات الحقلين "title" و "content" ، وتعليقات كل منشور مع حقلي "content" و "date" ، ومؤلف كل تعليق مع الحقلين "name" و "url" . لتحقيق ذلك في GraphQL ، سنقوم بتنفيذ الاستعلام التالي:
query { post { title content comments { content date author { name url } } } } لتنفيذ واجهة برمجة التطبيقات القائمة على المكون ، قمت بترجمة الاستعلام إلى تعبير "بناء الجملة النقطي" المقابل ، والذي يمكن توفيره بعد ذلك من خلال fields المعلمات. عند الاستعلام عن مورد "منشور" ، هذه القيمة هي:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url أو يمكن تبسيطها باستخدام | لتجميع كافة الحقول المطبقة على نفس المورد:
fields=title|content,comments.content|date,comments.author.name|urlعند تنفيذ هذا الاستعلام على منشور واحد ، نحصل بالضبط على البيانات المطلوبة لجميع الموارد المعنية:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } ومن ثم يمكننا الاستعلام عن الموارد بطريقة REST ، وتحديد الاستعلامات القائمة على المخطط بطريقة GraphQL ، وسوف نحصل على ما هو مطلوب بالضبط ، دون زيادة أو نقص في جلب البيانات ، وتطبيع البيانات في قاعدة البيانات بحيث لا يتم تكرار أي بيانات. بشكل مفضل ، يمكن أن يتضمن الاستعلام أي عدد من العلاقات ، متداخلة في العمق ، ويتم حلها مع وقت التعقيد الخطي: أسوأ حالة لـ O (n + m) ، حيث n هو عدد العقد التي تقوم بتبديل المجال (في هذه الحالة 2: comments and comments.author ) و m هو عدد النتائج المسترجعة (في هذه الحالة 5: 1 مشاركة + 2 تعليق + 2 مستخدمين) ، ومتوسط حالة O (n). (هذا أكثر كفاءة من GraphQL ، التي لها وقت تعقيد متعدد الحدود O (n ^ c) وتعاني من زيادة وقت التنفيذ مع زيادة عمق المستوى).
أخيرًا ، يمكن لواجهة برمجة التطبيقات هذه أيضًا تطبيق المُعدِّلات عند الاستعلام عن البيانات ، على سبيل المثال لتصفية الموارد التي يتم استردادها ، مثل ما يمكن القيام به من خلال GraphQL. لتحقيق ذلك ، توجد واجهة برمجة التطبيقات ببساطة أعلى التطبيق ويمكنها استخدام وظائفها بسهولة ، لذلك ليست هناك حاجة لإعادة اختراع العجلة. على سبيل المثال ، ستؤدي إضافة معاملات filter=posts&searchfor=internet إلى تصفية جميع المشاركات التي تحتوي على "internet" من مجموعة من المنشورات.
سيتم وصف تنفيذ هذه الميزة الجديدة في مقال قادم.