
تحويل الصورة إلى نص باستخدام React و Tesseract.js (OCR)
نشرت: 2022-03-10البيانات هي العمود الفقري لكل تطبيق برمجي لأن الغرض الرئيسي من التطبيق هو حل المشكلات البشرية. لحل مشاكل الإنسان ، من الضروري الحصول على بعض المعلومات عنها.
يتم تمثيل هذه المعلومات على أنها بيانات ، وخاصة من خلال الحساب. على الويب ، يتم جمع البيانات في الغالب في شكل نصوص وصور ومقاطع فيديو وغير ذلك الكثير. في بعض الأحيان ، تحتوي الصور على نصوص أساسية من المفترض أن تتم معالجتها لتحقيق غرض معين. تمت معالجة هذه الصور يدويًا في الغالب لأنه لا توجد طريقة لمعالجتها برمجيًا.
كان عدم القدرة على استخراج النص من الصور أحد قيود معالجة البيانات التي واجهتها بشكل مباشر في شركتي الأخيرة. كنا بحاجة إلى معالجة بطاقات الهدايا الممسوحة ضوئيًا وكان علينا القيام بذلك يدويًا لأننا لم نتمكن من استخراج النص من الصور.
كان هناك قسم يسمى "العمليات" داخل الشركة كان مسؤولاً عن تأكيد بطاقات الهدايا يدويًا وإيداع حسابات المستخدمين. على الرغم من أن لدينا موقع ويب يتواصل من خلاله المستخدمون معنا ، إلا أن معالجة بطاقات الهدايا تتم يدويًا خلف الكواليس.
في ذلك الوقت ، تم إنشاء موقعنا الإلكتروني بشكل أساسي باستخدام PHP (Laravel) للواجهة الخلفية و JavaScript (jQuery و Vue) للواجهة الأمامية. كانت مجموعتنا الفنية جيدة بما يكفي للعمل مع Tesseract.js بشرط أن تكون المشكلة مهمة من قبل الإدارة.
كنت على استعداد لحل المشكلة ولكن لم يكن من الضروري حل المشكلة من وجهة نظر الشركة أو وجهة نظر الإدارة. بعد ترك الشركة قررت إجراء بعض الأبحاث ومحاولة إيجاد الحلول الممكنة. في النهاية ، اكتشفت التعرف الضوئي على الحروف.
ما هو التعرف الضوئي على الحروف؟
يرمز OCR إلى "التعرف البصري على الأحرف" أو "قارئ الأحرف البصري". يتم استخدامه لاستخراج النصوص من الصور.
يمكن تتبع تطور OCR إلى العديد من الاختراعات ، لكن Optophone و "Gismo" و CCD المسطح الماسح الضوئي و Newton MesssagePad و Tesseract هي الاختراعات الرئيسية التي تنقل التعرف على الأحرف إلى مستوى آخر من الفائدة.
إذن ، لماذا تستخدم OCR؟ حسنًا ، يحل التعرف البصري على الأحرف الكثير من المشكلات ، والتي دفعتني إحداها لكتابة هذا المقال. أدركت أن القدرة على استخراج نصوص من صورة تضمن الكثير من الاحتمالات مثل:
- اللائحة
تحتاج كل منظمة إلى تنظيم أنشطة المستخدمين لبعض الأسباب. يمكن استخدام اللائحة لحماية حقوق المستخدمين وتأمينها من التهديدات أو عمليات الاحتيال.
يُمكِّن استخراج النصوص من صورة المؤسسة من معالجة المعلومات النصية على الصورة من أجل التنظيم ، خاصةً عندما يتم توفير الصور من قبل بعض المستخدمين.
على سبيل المثال ، يمكن تحقيق التنظيم الشبيه بالفيسبوك لعدد النصوص على الصور المستخدمة للإعلانات باستخدام التعرف الضوئي على الحروف. أيضًا ، أصبح إخفاء المحتوى الحساس على Twitter ممكنًا أيضًا عن طريق التعرف الضوئي على الحروف. - إمكانية البحث
يعد البحث من أكثر الأنشطة شيوعًا ، خاصة على الإنترنت. تعتمد خوارزميات البحث في الغالب على معالجة النصوص. من خلال التعرف الضوئي على الأحرف ، من الممكن التعرف على الأحرف الموجودة في الصور واستخدامها لتقديم نتائج الصور ذات الصلة للمستخدمين. باختصار ، يمكن الآن البحث في الصور ومقاطع الفيديو بمساعدة التعرف الضوئي على الحروف. - إمكانية الوصول
لطالما كان وجود نصوص على الصور تحديًا لإمكانية الوصول ومن القاعدة الأساسية أن يكون لديك عدد قليل من النصوص على الصورة. باستخدام OCR ، يمكن لقارئات الشاشة الوصول إلى النصوص الموجودة على الصور لتوفير بعض الخبرة اللازمة لمستخدميها. - أتمتة معالجة البيانات تتم معالجة البيانات في الغالب بشكل آلي لقياس الحجم. يعد وجود نصوص على الصور قيدًا على معالجة البيانات لأنه لا يمكن معالجة النصوص إلا يدويًا. يتيح التعرف الضوئي على الأحرف (OCR) استخراج النصوص من الصور برمجيًا ، مما يضمن أتمتة معالجة البيانات خاصة عندما يتعلق الأمر بمعالجة النصوص الموجودة على الصور.
- رقمنة المطبوعات
كل شيء أصبح رقميًا ولا يزال هناك الكثير من المستندات التي يتعين رقمنتها. يمكن الآن رقمنة الشيكات والشهادات والمستندات المادية الأخرى باستخدام التعرف الضوئي على الأحرف.
أدى اكتشاف جميع الاستخدامات المذكورة أعلاه إلى تعميق اهتماماتي ، لذلك قررت المضي قدمًا بطرح سؤال:
"كيف يمكنني استخدام OCR على الويب ، خاصة في تطبيق React؟"
قادني هذا السؤال إلى Tesseract.js.
ما هو Tesseract.js؟
Tesseract.js هي مكتبة JavaScript تقوم بتجميع Tesseract الأصلي من C إلى JavaScript WebAssembly مما يجعل التعرف الضوئي على الحروف متاحًا في المتصفح. تمت كتابة محرك Tesseract.js في الأصل بتنسيق ASM.js وتم نقله لاحقًا إلى WebAssembly ولكن لا يزال ASM.js يعمل كنسخة احتياطية في بعض الحالات عندما لا يكون WebAssembly غير مدعوم.
كما هو مذكور على موقع Tesseract.js ، فهو يدعم أكثر من 100 لغة ، والتوجيه التلقائي للنص واكتشاف النص ، وواجهة بسيطة لقراءة الفقرات والكلمات ومربعات إحاطة الأحرف.
Tesseract هو محرك التعرف الضوئي على الحروف لأنظمة التشغيل المختلفة. إنه برنامج مجاني ، تم إصداره بموجب ترخيص Apache. قامت شركة Hewlett-Packard بتطوير Tesseract كبرنامج احتكاري في الثمانينيات. تم إصداره كمصدر مفتوح في عام 2005 وتم تطويره برعاية Google منذ عام 2006.
تم إصدار أحدث إصدار ، الإصدار 4 ، من Tesseract في أكتوبر 2018 ويحتوي على محرك OCR جديد يستخدم نظام شبكة عصبية يعتمد على الذاكرة طويلة المدى (LSTM) ويهدف إلى الحصول على نتائج أكثر دقة.
فهم واجهات برمجة تطبيقات Tesseract
لفهم كيفية عمل Tesseract حقًا ، نحتاج إلى تفكيك بعض واجهات برمجة التطبيقات ومكوناتها. وفقًا لوثائق Tesseract.js ، هناك طريقتان للتعامل مع استخدامه. فيما يلي النهج الأول:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } تأخذ طريقة recognize الصورة على أنها الوسيطة الأولى ، واللغة (التي يمكن أن تكون متعددة) كوسيطة ثانية لها و { logger: m => console.log(me) } كوسيطة أخيرة لها. تنسيق الصورة الذي تدعمه Tesseract هو jpg و png و bmp و pbm والتي لا يمكن توفيرها إلا كعناصر (img أو فيديو أو لوحة قماشية) أو كائن ملف ( <input> ) أو كائن blob أو مسار أو عنوان URL لصورة وصورة مشفرة base64 . (اقرأ هنا لمزيد من المعلومات حول جميع تنسيقات الصور التي يمكن لـ Tesseract التعامل معها.)
يتم توفير اللغة كسلسلة مثل eng . يمكن استخدام علامة + لسلسلة عدة لغات كما هو الحال في eng+chi_tra . يتم استخدام حجة اللغة لتحديد بيانات اللغة المدربة لاستخدامها في معالجة الصور.
ملاحظة : ستجد كل اللغات المتاحة ورموزها هنا.
{ logger: m => console.log(m) } مفيد جدًا للحصول على معلومات حول تقدم الصورة التي تتم معالجتها. تأخذ خاصية المسجل وظيفة سيتم استدعاؤها عدة مرات أثناء معالجة Tesseract للصورة. يجب أن تكون المعلمة الخاصة بوظيفة المسجل كائنًا به workerId و jobId status progress كخصائصها:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress هو رقم بين 0 و 1 ، وهو النسبة المئوية لإظهار التقدم المحرز في عملية التعرف على الصور.
تقوم Tesseract تلقائيًا بإنشاء الكائن كمعامل لوظيفة المسجل ولكن يمكن أيضًا توفيره يدويًا. أثناء إجراء عملية التعرف ، يتم تحديث خصائص كائن logger في كل مرة يتم استدعاء الوظيفة . لذلك ، يمكن استخدامه لإظهار شريط تقدم التحويل ، أو تغيير جزء من التطبيق ، أو استخدامه لتحقيق أي نتيجة مرغوبة.
result في الكود أعلاه هي نتيجة عملية التعرف على الصور. كل خاصية من خصائص result لها خاصية bbox مثل إحداثيات x / y لمربعها المحيط.
فيما يلي خصائص الكائن result ومعانيها واستخداماتها:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: كل النص الذي تم التعرف عليه كسلسلة. -
lines: مصفوفة من كل سطر بسطر نص معترف به. -
words: مجموعة من كل كلمة معترف بها. -
symbols: مصفوفة من كل حرف تم التعرف عليه. -
paragraphs: مصفوفة من كل فقرة معترف بها. سنناقش "الثقة" لاحقًا في هذه الكتابة.
يمكن أيضًا استخدام Tesseract بشكل أكثر إلحاحًا كما في:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();يرتبط هذا النهج بالنهج الأول ولكن مع تطبيقات مختلفة.
createWorker(options) عامل ويب أو عملية عقدة فرعية تنشئ عامل Tesseract. يساعد العامل في إعداد محرك Tesseract OCR. تقوم طريقة load() بتحميل البرامج النصية الأساسية Tesseract ، loadLanguage() أي لغة تم توفيرها لها كسلسلة ، وتتأكد initialize() من أن Tesseract جاهزة تمامًا للاستخدام ثم يتم استخدام طريقة التعرف لمعالجة الصورة المقدمة. طريقة إنهاء () توقف العامل وتنظف كل شيء.
ملاحظة : يرجى مراجعة وثائق Tesseract APIs لمزيد من المعلومات.
الآن ، علينا بناء شيء ما لنرى حقًا مدى فعالية Tesseract.js.
ما الذي سنقوم ببنائه؟
سنقوم ببناء مستخرج PIN لبطاقة الهدايا لأن استخراج رقم التعريف الشخصي من بطاقة الهدايا كان هو المشكلة التي أدت إلى مغامرة الكتابة هذه في المقام الأول.
سننشئ تطبيقًا بسيطًا يستخرج رمز PIN من بطاقة هدايا ممسوحة ضوئيًا . عندما شرعت في بناء مستخرج بسيط لبطاقة الهدايا ، سوف أطلعك على بعض التحديات التي واجهتها على طول الخط ، والحلول التي قدمتها ، واستنتاجي بناءً على تجربتي.
- انتقل إلى التعليمات البرمجية المصدر →
فيما يلي الصورة التي سنستخدمها للاختبار لأنها تحتوي على بعض الخصائص الواقعية الممكنة في العالم الحقيقي.

سنقوم باستخراج AQUX-QWMB6L-R6JAU من البطاقة. لذلك دعونا نبدأ.
تركيب React و Tesseract
هناك سؤال يجب الإجابة عليه قبل تثبيت React و Tesseract.js والسؤال هو ، لماذا استخدام React مع Tesseract؟ عمليًا ، يمكننا استخدام Tesseract مع Vanilla JavaScript وأي مكتبات أو أطر عمل JavaScript مثل React و Vue و Angular.
استخدام React في هذه الحالة هو تفضيل شخصي. في البداية ، أردت استخدام Vue لكنني قررت استخدام React لأنني أكثر دراية بـ React من Vue.
الآن ، دعنا نواصل التركيبات.
لتثبيت React باستخدام create-react-app ، عليك تشغيل الكود أدناه:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsأو
npm install tesseract.jsقررت استخدام الغزل لتثبيت Tesseract.js لأنني لم أتمكن من تثبيت Tesseract باستخدام npm ولكن الغزل أنجز المهمة دون إجهاد. يمكنك استخدام npm ولكني أوصي بتثبيت Tesseract مع الغزل انطلاقا من تجربتي.
الآن ، لنبدأ خادم التطوير الخاص بنا عن طريق تشغيل الكود أدناه:
yarn startأو
npm startبعد تشغيل بدء الغزل أو بدء npm ، يجب أن يفتح المتصفح الافتراضي صفحة ويب تبدو كما يلي:

يمكنك أيضًا الانتقال إلى localhost:3000 في المتصفح بشرط عدم تشغيل الصفحة تلقائيًا.
بعد تثبيت React و Tesseract.js ، ماذا بعد؟
إعداد نموذج التحميل
في هذه الحالة ، سنقوم بتعديل الصفحة الرئيسية (App.js) التي شاهدناها للتو في المتصفح لتحتوي على النموذج الذي نحتاجه:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App الجزء من الكود أعلاه الذي يحتاج إلى اهتمامنا في هذه المرحلة هو التابع handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } في الوظيفة ، يأخذ URL.createObjectURL ملفًا محددًا من خلال event.target.files[0] وينشئ عنوان URL مرجعيًا يمكن استخدامه مع علامات HTML مثل img والصوت والفيديو. استخدمنا setImagePath لإضافة عنوان URL إلى الحالة. الآن ، يمكن الآن الوصول إلى عنوان URL باستخدام imagePath .
<img src={imagePath} className="App-logo" alt="image"/> قمنا بتعيين سمة src الخاصة بالصورة على {imagePath} في المتصفح قبل معالجتها.
تحويل الصور المختارة إلى نصوص
نظرًا لأننا أمسكنا المسار إلى الصورة المحددة ، يمكننا تمرير مسار الصورة إلى Tesseract.js لاستخراج النصوص منه.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default Appنضيف الوظيفة "handleClick" إلى "App.js وتحتوي على واجهة برمجة تطبيقات Tesseract.js تأخذ المسار إلى الصورة المحددة. يأخذ Tesseract.js "imagePath" ، "اللغة" ، "كائن الإعداد".
يضاف الزر أدناه إلى النموذج لاستدعاء "handClick" الذي يؤدي إلى تحويل صورة إلى نص كلما تم النقر فوق الزر.
<button onClick={handleClick} style={{height:50}}> convert to text</button>عند نجاح المعالجة ، نصل إلى "الثقة" و "النص" من النتيجة. ثم نضيف "نص" إلى الحالة مع "setText (نص)".
من خلال الإضافة إلى <p> {text} </p> ، نعرض النص المستخرج.
واضح أن "النص" مستخرج من الصورة ولكن ما هي الثقة؟
تظهر الثقة مدى دقة التحويل. يتراوح مستوى الثقة بين 1 و 100. 1 يرمز إلى الأسوأ بينما يمثل 100 الأفضل من حيث الدقة. يمكن استخدامه أيضًا لتحديد ما إذا كان يجب قبول نص مستخرج على أنه دقيق أم لا.
ثم السؤال هو ما هي العوامل التي يمكن أن تؤثر على درجة الثقة أو دقة التحويل بأكمله؟ يتأثر في الغالب بثلاثة عوامل رئيسية - جودة وطبيعة المستند المستخدم وجودة المسح الضوئي الذي تم إنشاؤه من المستند وقدرات المعالجة لمحرك Tesseract.
الآن ، دعنا نضيف الكود أدناه إلى "App.css" لتصميم التطبيق قليلاً.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }ها هي نتيجة اختباري الأول :
النتيجة في Firefox
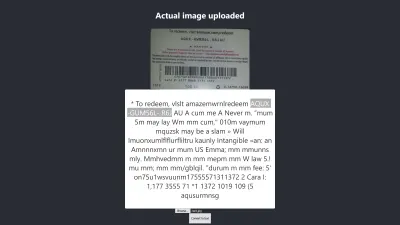
مستوى الثقة للنتيجة أعلاه هو 64. من الجدير بالذكر أن صورة بطاقة الهدايا داكنة اللون وأنها بالتأكيد تؤثر على النتيجة التي نحصل عليها.

إذا ألقيت نظرة فاحصة على الصورة أعلاه ، فسترى أن الدبوس من البطاقة دقيق تقريبًا في النص المستخرج. إنها ليست دقيقة لأن بطاقة الهدايا ليست واضحة حقًا.
اه انتظر! كيف سيبدو في Chrome؟
النتيجة في كروم
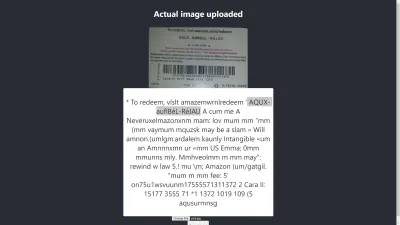
آه! النتيجة أسوأ في Chrome. ولكن لماذا تختلف النتيجة في Chrome عن Mozilla Firefox؟ المتصفحات المختلفة تتعامل مع الصور وملفات تعريف الألوان الخاصة بها بشكل مختلف. هذا يعني أنه يمكن عرض الصورة بشكل مختلف اعتمادًا على المتصفح . من خلال توفير بيانات الصورة التي تم تقديمها مسبقًا إلى image.data ، فمن المحتمل أن تنتج نتيجة مختلفة في متصفحات مختلفة لأن image.data المختلفة يتم توفيرها إلى Tesseract اعتمادًا على المتصفح المستخدم. ستساعد المعالجة المسبقة للصورة ، كما سنرى لاحقًا في هذه المقالة ، في تحقيق نتيجة متسقة.
نحتاج إلى أن نكون أكثر دقة حتى نتأكد من أننا نحصل على المعلومات الصحيحة أو نعطيها. لذلك علينا أن نأخذ الأمر أبعد من ذلك بقليل.
دعونا نحاول المزيد لمعرفة ما إذا كان بإمكاننا تحقيق الهدف في النهاية.
اختبار من أجل الدقة
هناك الكثير من العوامل التي تؤثر على تحويل الصورة إلى نص باستخدام Tesseract.js. تدور معظم هذه العوامل حول طبيعة الصورة التي نريد معالجتها والباقي يعتمد على كيفية تعامل محرك Tesseract مع التحويل.
داخليًا ، تعالج Tesseract الصور قبل التحويل الفعلي لـ OCR ولكنها لا تعطي دائمًا نتائج دقيقة.
كحل ، يمكننا معالجة الصور مسبقًا لتحقيق تحويلات دقيقة. يمكننا تعديل الصورة أو عكسها أو توسيعها أو تعديلها أو إعادة قياسها لمعالجتها مسبقًا من أجل Tesseract.js.
المعالجة المسبقة للصور تتطلب الكثير من العمل أو مجال واسع بمفردها. لحسن الحظ ، قدمت P5.js جميع تقنيات المعالجة المسبقة للصور التي نريد استخدامها. بدلاً من إعادة اختراع العجلة أو استخدام المكتبة بأكملها لمجرد أننا نريد استخدام جزء صغير منها ، قمت بنسخ العناصر التي نحتاجها. يتم تضمين جميع تقنيات المعالجة المسبقة للصور في preprocess.js.
ما هو الثنائي؟
الثنائيات هي تحويل وحدات البكسل في الصورة إلى الأسود أو الأبيض. نريد تحويل بطاقة الهدايا السابقة إلى تنسيق ثنائي للتحقق مما إذا كانت الدقة ستكون أفضل أم لا.
في السابق ، استخرجنا بعض النصوص من بطاقة الهدايا ولكن رقم التعريف الشخصي المستهدف لم يكن دقيقًا كما أردنا. لذلك هناك حاجة لإيجاد طريقة أخرى للحصول على نتيجة دقيقة.
الآن ، نريد تحويل بطاقة الهدايا إلى تنسيق ثنائي ، أي نريد تحويل وحدات البكسل الخاصة بها إلى الأسود والأبيض حتى نتمكن من معرفة ما إذا كان يمكن تحقيق مستوى أفضل من الدقة أم لا.
سيتم استخدام الوظائف أدناه للترجمة الثنائية وسيتم تضمينها في ملف منفصل يسمى preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageماذا الكود أعلاه تفعل؟
نقدم قماشًا للاحتفاظ ببيانات الصورة لتطبيق بعض المرشحات ، لمعالجة الصورة مسبقًا ، قبل تمريرها إلى Tesseract للتحويل.
توجد أول وظيفة preprocessImage في preprocess.js وتجهز اللوحة القماشية للاستخدام من خلال الحصول على وحدات البكسل الخاصة بها. تقوم وظيفة thresholdFilter بترميز الصورة عن طريق تحويل وحدات البكسل الخاصة بها إلى الأسود أو الأبيض .
دعونا نطلق على preprocessImage لمعرفة ما إذا كان النص المستخرج من بطاقة الهدايا السابقة يمكن أن يكون أكثر دقة.
بحلول الوقت الذي نقوم فيه بتحديث App.js ، يجب أن يبدو الآن مثل الكود التالي:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default Appأولاً ، علينا استيراد "preprocessImage" من "preprocess.js" بالرمز أدناه:
import preprocessImage from './preprocess'; ثم نضيف علامة قماشية إلى النموذج. قمنا بتعيين السمة ref لكل من اللوحة القماشية وعلامات img على { canvasRef } و { imageRef } على التوالي. تستخدم المراجع للوصول إلى اللوحة القماشية والصورة من مكون التطبيق. نحصل على كل من اللوحة القماشية والصورة باستخدام "useRef" كما في:
const canvasRef = useRef(null); const imageRef = useRef(null);في هذا الجزء من الكود ، ندمج الصورة في اللوحة القماشية حيث يمكننا فقط معالجة لوحة الرسم في JavaScript. ثم نقوم بتحويله إلى عنوان URL للبيانات مع تنسيق "jpeg" لصورته.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");يتم تمرير "dataUrl" إلى Tesseract كصورة لتتم معالجتها.
الآن ، دعنا نتحقق مما إذا كان النص المستخرج سيكون أكثر دقة.
اختبار رقم 2

توضح الصورة أعلاه النتيجة في Firefox. من الواضح أن الجزء المظلم من الصورة قد تم تغييره إلى اللون الأبيض ولكن المعالجة المسبقة للصورة لا تؤدي إلى نتيجة أكثر دقة. بل هو أسوأ.
التحويل الأول يحتوي فقط على حرفين غير صحيحين ولكن هذا واحد يحتوي على أربعة أحرف غير صحيحة. حتى أنني حاولت تغيير مستوى العتبة ولكن دون جدوى. لا نحصل على نتيجة أفضل ليس لأن الترميز الثنائي سيئ ولكن لأن ثنائيات الصورة لا يصلح طبيعة الصورة بطريقة مناسبة لمحرك Tesseract.
دعنا نتحقق من الشكل الذي يبدو عليه أيضًا في Chrome:

نحصل على نفس النتيجة.
بعد الحصول على نتيجة أسوأ من خلال ثنائيات الصورة ، هناك حاجة للتحقق من تقنيات المعالجة المسبقة للصور لمعرفة ما إذا كان بإمكاننا حل المشكلة أم لا. لذا ، سنحاول التوسيع ، والانعكاس ، والتشويش بعد ذلك.
دعنا فقط نحصل على الكود لكل تقنية من P5.js كما هو مستخدم في هذه المقالة. سنضيف تقنيات معالجة الصور إلى preprocess.js ونستخدمها واحدة تلو الأخرى. من الضروري فهم كل تقنية من تقنيات المعالجة المسبقة للصور التي نريد استخدامها قبل استخدامها ، لذلك سنناقشها أولاً.
ما هو التوسيع؟
التوسيع هو إضافة وحدات بكسل إلى حدود الكائنات في صورة ما لجعلها أعرض أو أكبر أو أكثر انفتاحًا. تُستخدم تقنية "التوسيع" في المعالجة المسبقة لصورنا لزيادة سطوع الكائنات الموجودة على الصور. نحتاج إلى وظيفة لتوسيع الصور باستخدام JavaScript ، لذلك تتم إضافة مقتطف الشفرة لتوسيع الصورة إلى preprocess.js.
ما هو طمس؟
التمويه هو تنعيم ألوان الصورة عن طريق تقليل حدتها. في بعض الأحيان ، تحتوي الصور على نقاط / بقع صغيرة. لإزالة تلك التصحيحات ، يمكننا تشويه الصور. يتم تضمين مقتطف الشفرة لطمس الصورة في preprocess.js.
ما هو الانقلاب؟
الانعكاس هو تغيير مساحات الضوء في الصورة إلى لون داكن والمساحات الداكنة إلى لون فاتح. على سبيل المثال ، إذا كانت الصورة ذات خلفية سوداء ومقدمة بيضاء ، فيمكننا قلبها بحيث تكون خلفيتها بيضاء ومقدمة الصورة سوداء. لقد أضفنا أيضًا مقتطف الشفرة لعكس صورة إلى preprocess.js.
بعد إضافة dilate ، و invertColors ، و blurARGB إلى "preprocess.js" ، يمكننا الآن استخدامها لمعالجة الصور. لاستخدامها ، نحتاج إلى تحديث وظيفة "preprocessImage" الأولية في preprocess.js:
preprocessImage(...) تبدو الآن كما يلي:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } في الصورة أعلاه ، نطبق أربع تقنيات معالجة مسبقة للصورة: preprocessImage blurARGB() لإزالة النقاط على الصورة ، وتوسيع ( dilate() لزيادة سطوع الصورة ، و invertColors() لتبديل لون المقدمة والخلفية للصورة thresholdFilter() التصفية thresholdFilter() لتحويل الصورة إلى أبيض وأسود وهو أكثر ملاءمة لتحويل Tesseract.
يأخذ thresholdFilter() image.data level كمعلماته. يستخدم level لتعيين كيف يجب أن تكون الصورة بيضاء أو سوداء. لقد حددنا مستوى thresholdFilter الفلتر ونصف قطر blurRGB عن طريق التجربة والخطأ لأننا لسنا متأكدين من مدى بياض الصورة أو تعتيمها أو تجانسها حتى تتمكن Tesseract من تحقيق نتيجة رائعة.
اختبار # 3
ها هي النتيجة الجديدة بعد تطبيق أربع تقنيات:

تمثل الصورة أعلاه النتيجة التي نحصل عليها في كل من Chrome و Firefox.
وجه الفتاة! النتيجة رهيبة.
بدلاً من استخدام الأساليب الأربعة ، لماذا لا نستخدم اثنين منهم في المرة الواحدة؟
نعم! يمكننا ببساطة استخدام تقنيات invertColors و thresholdFilter لتحويل الصورة إلى أبيض وأسود ، وتبديل المقدمة وخلفية الصورة. ولكن كيف نعرف ما هي التقنيات التي يجب دمجها؟ نحن نعرف ما يجب دمجه بناءً على طبيعة الصورة التي نريد معالجتها مسبقًا.
على سبيل المثال ، يجب تحويل الصورة الرقمية إلى أبيض وأسود ، ويجب تشويش الصورة ذات التصحيحات لإزالة النقاط / البقع. ما يهم حقًا هو فهم الغرض من استخدام كل تقنية.
لاستخدام invertColors و thresholdFilter ، نحتاج إلى التعليق على كل من blurARGB dilate preprocessImage
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }اختبار رقم 4
الآن ، ها هي النتيجة الجديدة:

لا تزال النتيجة أسوأ من تلك التي لم تتم معالجتها مسبقًا. بعد تعديل كل تقنية من تقنيات هذه الصورة المعينة وبعض الصور الأخرى ، توصلت إلى استنتاج مفاده أن الصور ذات الطبيعة المختلفة تتطلب تقنيات معالجة مسبقة مختلفة.
باختصار ، أدى استخدام Tesseract.js دون المعالجة المسبقة للصور إلى الحصول على أفضل نتيجة لبطاقة الهدايا أعلاه. أسفرت جميع التجارب الأخرى مع المعالجة المسبقة للصور عن نتائج أقل دقة.
مشكلة
في البداية ، كنت أرغب في استخراج رقم التعريف الشخصي من أي بطاقة هدايا من أمازون ، لكنني لم أستطع تحقيق ذلك لأنه لا جدوى من مطابقة رقم التعريف الشخصي غير المتسق للحصول على نتيجة متسقة. على الرغم من أنه من الممكن معالجة صورة للحصول على رقم تعريف شخصي دقيق ، إلا أن هذه المعالجة المسبقة ستكون غير متسقة بحلول الوقت الذي يتم فيه استخدام صورة أخرى ذات طبيعة مختلفة.
أفضل نتيجة تم إنتاجها
توضح الصورة أدناه أفضل نتيجة أنتجتها التجارب.
اختبار رقم 5

النصوص الموجودة على الصورة والنصوص المستخرجة هي نفسها تمامًا. التحويل بدقة 100٪. حاولت إعادة إنتاج النتيجة ولكني لم أتمكن من إعادة إنتاجها إلا عند استخدام صور ذات طبيعة مماثلة.
الملاحظة والدروس
- قد تعطي بعض الصور التي لم تتم معالجتها مسبقًا نتائج مختلفة في متصفحات مختلفة . هذا الادعاء واضح في الاختبار الأول. تختلف النتيجة في Firefox عن تلك الموجودة في Chrome. ومع ذلك ، تساعد المعالجة المسبقة للصور في تحقيق نتيجة متسقة في الاختبارات الأخرى.
- يميل اللون الأسود على خلفية بيضاء إلى إعطاء نتائج يمكن التحكم فيها. الصورة أدناه هي مثال على نتيجة دقيقة دون أي معالجة مسبقة . تمكنت أيضًا من الحصول على نفس المستوى من الدقة من خلال المعالجة المسبقة للصورة ، لكن الأمر تطلب مني الكثير من التعديل الذي كان غير ضروري.
التحويل دقيق 100٪.
- يميل النص ذو حجم الخط الكبير إلى أن يكون أكثر دقة.
- تميل الخطوط ذات الحواف المنحنية إلى إرباك Tesseract. تم تحقيق أفضل نتيجة حصلت عليها عندما استخدمت Arial (الخط).
- لا يعد التعرف الضوئي على الحروف حاليًا جيدًا بما يكفي لأتمتة تحويل الصورة إلى نص ، خاصةً عند الحاجة إلى مستوى دقة يزيد عن 80٪. ومع ذلك ، يمكن استخدامه لجعل المعالجة اليدوية للنصوص على الصور أقل إجهادًا عن طريق استخراج النصوص للتصحيح اليدوي.
- OCR حاليًا ليس جيدًا بما يكفي لتمرير معلومات مفيدة إلى برامج قراءة الشاشة لإمكانية الوصول . قد يؤدي تقديم معلومات غير دقيقة إلى قارئ الشاشة إلى تضليل المستخدمين أو تشتيت انتباههم بسهولة.
- يعد التعرف الضوئي على الحروف واعدًا جدًا حيث تتيح الشبكات العصبية التعلم والتحسين. التعلم العميق سيجعل التعرف الضوئي على الحروف سيغير قواعد اللعبة في المستقبل القريب .
- اتخاذ القرارات بثقة. يمكن استخدام درجة الثقة لاتخاذ القرارات التي يمكن أن تؤثر بشكل كبير على تطبيقاتنا. يمكن استخدام درجة الثقة لتحديد ما إذا كنت تريد قبول أو رفض نتيجة. من تجربتي وتجربتي ، أدركت أن أي درجة ثقة أقل من 90 ليست مفيدة حقًا. إذا كنت بحاجة فقط إلى استخراج بعض الدبابيس من نص ، فسوف أتوقع درجة ثقة بين 75 و 100 ، وسيتم رفض أي شيء أقل من 75 .
في حال كنت أتعامل مع نصوص دون الحاجة إلى استخراج أي جزء منها ، سأقبل بالتأكيد درجة ثقة بين 90 إلى 100 لكنني سأرفض أي درجة أقل من ذلك. على سبيل المثال ، ستكون الدقة 90 وما فوق متوقعة إذا كنت أرغب في رقمنة المستندات مثل الشيكات أو المسودة التاريخية أو كلما كانت هناك حاجة إلى نسخة طبق الأصل. لكن الدرجة التي تتراوح بين 75 و 90 مقبولة عندما لا تكون النسخة الدقيقة مهمة مثل الحصول على رقم التعريف الشخصي من بطاقة الهدايا. باختصار ، تساعد درجة الثقة في اتخاذ القرارات التي تؤثر على طلباتنا.
خاتمة
نظرًا لقيود معالجة البيانات التي تسببها النصوص الموجودة على الصور والعيوب المرتبطة بها ، فإن التعرف الضوئي على الأحرف (OCR) هو تقنية مفيدة يجب احتضانها. على الرغم من أن OCR لها حدودها ، إلا أنها واعدة جدًا بسبب استخدامها للشبكات العصبية.
بمرور الوقت ، سيتغلب OCR على معظم قيوده بمساعدة التعلم العميق ، ولكن قبل ذلك ، يمكن استخدام الأساليب الموضحة في هذه المقالة للتعامل مع استخراج النص من الصور ، على الأقل ، لتقليل المشقة والخسائر المرتبطة بالدليل المعالجة - خاصة من وجهة نظر العمل.
حان دورك الآن لتجربة OCR لاستخراج النصوص من الصور. حظ سعيد!
قراءة متعمقة
- P5.js
- المعالجة المسبقة في التعرف الضوئي على الحروف
- تحسين جودة المخرجات
- استخدام JavaScript في المعالجة المسبقة للصور لـ OCR
- OCR في المتصفح باستخدام Tesseract.js
- تاريخ سريع للتعرف البصري على الحروف
- مستقبل التعرف الضوئي على الحروف هو التعلم العميق
- التسلسل الزمني للتعرف البصري على الأحرف