
تصنيف الصور في CNN: كل ما تحتاج إلى معرفته
نشرت: 2021-02-25جدول المحتويات
مقدمة
أثناء تصفح موجز Facebook ، هل تساءلت يومًا كيف يتم تصنيف الأشخاص في صورة جماعية تلقائيًا بواسطة برنامج Facebook؟ خلف كل واجهة مستخدم تفاعلية على Facebook ، توجد خوارزمية معقدة وقوية تُستخدم للتعرف على كل صورة يتم تحميلها من قبلنا على منصة التواصل الاجتماعي وتسميتها. مع كل صورة لنا ، نساعد فقط في تحسين كفاءة الخوارزمية. نعم ، يعد تصنيف الصور أحد الخوارزميات الأكثر استخدامًا حيث نرى تطبيق الذكاء الاصطناعي.
في الآونة الأخيرة ، أصبحت الشبكات العصبية التلافيفية (CNN) واحدة من أقوى مؤيدي التعلم العميق. أحد التطبيقات الشائعة لهذه الشبكات التلافيفية هو تصنيف الصور. في هذا البرنامج التعليمي ، سنتعرف على أساسيات الشبكات العصبية التلافيفية ، ونرى الطبقات المختلفة المشاركة في بناء نموذج CNN وأخيراً نتخيل مثالاً على مهمة تصنيف الصور.
تصنيف الصور
قبل الدخول في تفاصيل التعلم العميق والشبكات العصبية التلافيفية ، دعونا نفهم أساسيات تصنيف الصور. بشكل عام ، يتم تعريف تصنيف الصور على أنه المهمة التي نعطي فيها صورة كمدخلات لنموذج مبني باستخدام خوارزمية محددة تُخرج الفئة أو احتمالية الفئة التي تنتمي إليها الصورة. هذه العملية التي نقوم فيها بتسمية صورة لفصل معين تسمى التعلم الخاضع للإشراف.
هناك فرق كبير بين كيف نرى الصورة وكيف يرى الجهاز (الكمبيوتر) نفس الصورة. بالنسبة لنا ، نحن قادرون على تصور الصورة وتمييزها بناءً على اللون والحجم. من ناحية أخرى ، بالنسبة للجهاز ، كل ما يمكنه رؤيته هو الأرقام. تسمى الأرقام التي يتم رؤيتها بالبكسل.
كل بكسل له قيمة بين 0 و 255. وبالتالي ، مع هذه البيانات الرقمية ، تتطلب الآلة بعض خطوات المعالجة المسبقة من أجل اشتقاق بعض الأنماط أو الميزات المحددة التي تميز صورة عن الأخرى. تساعدنا الشبكات العصبية التلافيفية في بناء خوارزميات قادرة على اشتقاق النمط المحدد من الصور.
ما نراه مقابل ما يراه الكمبيوتر
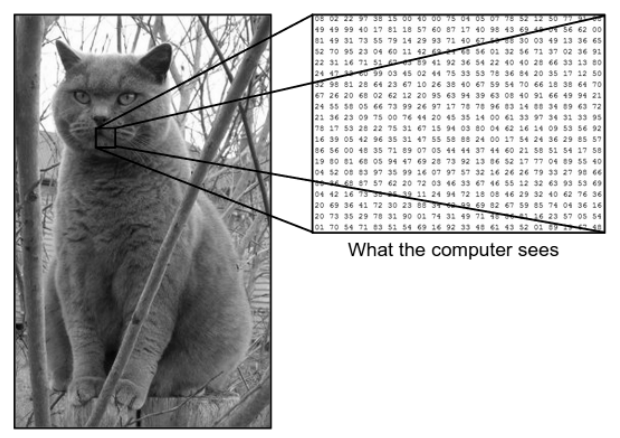 المصدر - الفرق بين الكمبيوتر والعين البشرية
المصدر - الفرق بين الكمبيوتر والعين البشرية

التعلم العميق لتصنيف الصور
الآن بعد أن فهمنا ما هو تصنيف الصور ، دعونا نرى الآن كيف يمكننا تنفيذه باستخدام الذكاء الاصطناعي. لهذا ، نستخدم طرق التعلم العميق الشائعة. التعلم العميق هو مجموعة فرعية من الذكاء الاصطناعي الذي يستخدم مجموعات بيانات الصور الكبيرة للتعرف على الأنماط واستخلاصها من الصور المختلفة للتمييز بين الفئات المختلفة الموجودة في مجموعة بيانات الصورة.
التحدي الرئيسي الذي يواجه التعلم العميق هو أنه بالنسبة لقاعدة البيانات الضخمة ، فإنها تستغرق وقتًا طويلاً جدًا ولها تكلفة حسابية عالية. ومع ذلك ، فإن الشبكات العصبية التلافيفية ، وهي نوع من خوارزمية التعلم العميق ، تعالج هذه المشكلة جيدًا.
الشبكات العصبية التلافيفية
في التعلم العميق ، الشبكات العصبية التلافيفية هي فئة من الشبكات العصبية العميقة التي تستخدم في الغالب في الصور المرئية. إنها بنية خاصة للشبكات العصبية الاصطناعية (ANN) التي اقترحها Yann LeCunn في عام 1998. تتكون الشبكات العصبية التلافيفية من جزأين.
يتكون الجزء الأول من الطبقات التلافيفية وطبقات التجمع التي تحدث فيها عملية استخراج الميزة الرئيسية. في الجزء الثاني ، تقوم الطبقات المتصلة بالكامل والطبقات الكثيفة بإجراء العديد من التحويلات غير الخطية على الميزات المستخرجة وتعمل بمثابة جزء المصنف. تعلم CNN لتصنيف الصور.
ضع في اعتبارك الصورة الموضحة أعلاه لما يراه الإنسان والآلة. كما نرى ، يرى الكمبيوتر مجموعة من البكسل. على سبيل المثال ، إذا كان حجم الصورة 500 × 500 ، فسيكون حجم المصفوفة 500 × 500 × 3. هنا ، يرمز 500 لكل ارتفاع وعرض ، 3 يرمز إلى قناة RGB حيث يتم تمثيل كل قناة لونية بمصفوفة منفصلة. تختلف شدة البكسل من 0 إلى 255.
الآن بالنسبة لتصنيف الصور ، سيبحث الكمبيوتر عن الميزات الموجودة في المستوى الأساسي. وفقًا لنا كبشر ، فإن هذه السمات الأساسية للقط هي آذانها وأنفها وشعيراتها. بينما بالنسبة للكمبيوتر ، فإن ميزات المستوى الأساسي هذه هي الانحناءات والحدود. بهذه الطريقة باستخدام عدة طبقات مختلفة مثل الطبقات التلافيفية وطبقات التجمع ، يستخرج الكمبيوتر ميزات المستوى الأساسي من الصور.
في نموذج الشبكة العصبية التلافيفية ، هناك عدة أنواع من الطبقات مثل -
- طبقة الإدخال
- طبقة تلافيفية
- طبقة التجميع
- طبقة متصلة بالكامل
- طبقة الإخراج
- وظائف التنشيط
دعنا ننتقل إلى كل طبقة باختصار قبل أن ندخل في تطبيقها في تصنيف الصور.
طبقة الإدخال
من الاسم ، نفهم أن هذه هي الطبقة التي سيتم فيها إدخال صورة الإدخال في نموذج CNN. اعتمادًا على متطلباتنا ، يمكننا إعادة تشكيل الصورة بأحجام مختلفة مثل (28 ، 28 ، 3)
طبقة تلافيفية
ثم تأتي أهم طبقة تتكون من مرشح (يُعرف أيضًا باسم النواة) بحجم ثابت. يتم تنفيذ العملية الحسابية للالتفاف بين صورة الإدخال والمرشح. هذه هي المرحلة التي يتم فيها استخراج معظم الميزات الأساسية مثل الحواف الحادة والمنحنيات من الصورة ، ومن ثم تُعرف هذه الطبقة أيضًا باسم طبقة مستخرج المعالم.
طبقة التجميع
بعد إجراء عملية الالتواء ، نقوم بإجراء عملية التجميع. يُعرف هذا أيضًا بالاختزال حيث يتم تقليل الحجم المكاني للصورة. على سبيل المثال ، إذا أجرينا عملية تجميع بخطوة 2 على صورة بأبعاد 28 × 28 ، فسيتم تقليل حجم الصورة إلى 14 × 14 ، ويتم تصغيرها إلى نصف حجمها الأصلي.
طبقة متصلة بالكامل
يتم وضع الطبقة المتصلة بالكامل (FC) قبل إخراج التصنيف النهائي لنموذج CNN مباشرةً. تُستخدم هذه الطبقات لتسوية النتائج قبل التصنيف. إنه ينطوي على العديد من التحيزات والأوزان والخلايا العصبية. ينتج عن إرفاق طبقة FC قبل التصنيف متجه N-dimensional حيث N هو عدد من الفئات التي يجب أن يختار النموذج فئة منها.
طبقة الإخراج
أخيرًا ، تتكون طبقة الإخراج من الملصق الذي يتم ترميزه في الغالب باستخدام طريقة التشفير الواحد الساخن.
وظيفة التنشيط
وظائف التنشيط هذه هي جوهر أي نموذج شبكة عصبية تلافيفية. تُستخدم هذه الوظائف لتحديد ناتج الشبكة العصبية. باختصار ، إنه يحدد ما إذا كان يجب تنشيط خلية عصبية معينة ("إطلاق") أم لا. عادة ما تكون هذه وظائف غير خطية يتم تنفيذها على إشارات الإدخال. ثم يتم إرسال هذا الناتج المحول كمدخل إلى الطبقة التالية من الخلايا العصبية. هناك العديد من وظائف التنشيط مثل Sigmoid و ReLU و Leaky ReLU و TanH و Softmax.
هندسة CNN الأساسية
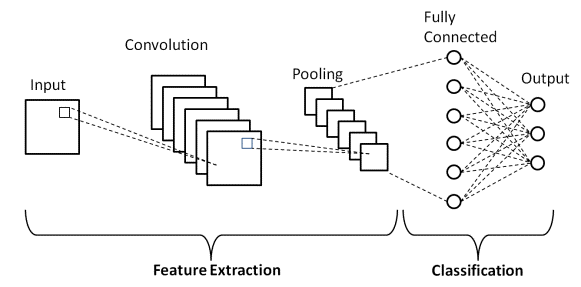
المصدر : Basic CNN Architecture
كما تم تعريفه سابقًا ، فإن الرسم البياني الموضح أعلاه هو البنية الأساسية لنموذج الشبكة العصبية التلافيفية. الآن بعد أن أصبحنا جاهزين بأساسيات تصنيف الصور و CNN ، دعونا الآن نتعمق في تطبيقه بمشكلة في الوقت الفعلي. تعرف على المزيد حول بنية CNN الأساسية.
تنفيذ الشبكات العصبية التلافيفية
الآن بعد أن فهمنا أساسيات تصنيف الصور والشبكات العصبية التلافيفية ، دعونا نتخيل تنفيذها في TensorFlow / Keras مع ترميز Python. في هذا ، سنقوم ببناء نموذج بسيط للشبكة العصبية التلافيفية مع بنية LeNet الأساسية ، وتدريب النموذج على مجموعة تدريب ومجموعة اختبار وأخيراً الحصول على دقة النموذج على بيانات مجموعة الاختبار.
تم ضبط المشكلة
في هذه المقالة لبناء وتدريب نموذج الشبكة العصبية التلافيفية ، سنستخدم مجموعة بيانات Fashion MNIST الشهيرة. MNIST تعني المعهد الوطني المعدل للمعايير والتكنولوجيا. Fashion-MNIST هي مجموعة بيانات لصور مقالات Zalando - وتتألف من مجموعة تدريب من 60.000 مثال ومجموعة اختبار من 10000 مثال. كل مثال عبارة عن صورة ذات تدرج رمادي مقاس 28 × 28 ، مقترنة بملصق من 10 فئات.
يتم تخصيص كل تدريب واختبار لإحدى التسميات التالية:
0 - تي شيرت / توب
1 - بنطلون
2 - كنزة صوفية
3 - فستان
4 - معطف
5 - صندل
6 - قميص
7 - حذاء رياضي
8 - حقيبة
9- جزمة الكاحل
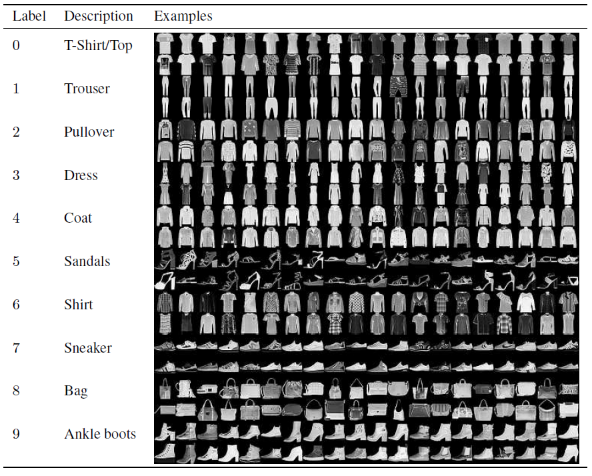

المصدر : صور مجموعة بيانات Fashion MNIST
كود البرنامج
الخطوة 1 - استيراد المكتبات
تتمثل الخطوة الأولى لبناء أي نموذج تعلم عميق في استيراد المكتبات الضرورية للبرنامج. في مثالنا ، نظرًا لأننا نستخدم إطار عمل TensorFlow ، سنقوم باستيراد مكتبة Keras وأيضًا مكتبات مهمة أخرى مثل رقم الحساب و matplotlib لتخطيط المؤامرات.
#TensorFlow - استيراد المكتبات
استيراد numpy كـ np
استيراد matplotlib.pyplot كـ PLT
٪ matplotlib مضمنة
استيراد tensorflow مثل tf
من Keras استيراد Tensorflow
الخطوة 2 - الحصول على مجموعة البيانات وتقسيمها
بمجرد استيراد المكتبات ، فإن الخطوة التالية هي تنزيل مجموعة البيانات وتقسيم مجموعة بيانات Fashion MNIST إلى 60.000 تدريب و 10000 بيانات اختبار. لحسن الحظ ، توفر لنا keras وظيفة محددة مسبقًا لاستيراد مجموعة بيانات Fashion MNIST ويمكننا تقسيمها في السطر التالي باستخدام سطر بسيط من التعليمات البرمجية التي يمكن فهمها ذاتيًا.
#TensorFlow - الحصول على مجموعة البيانات وتقسيمها
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf، train_labels_tf)، (test_images_tf، test_labels_tf) = fashion_mnist.load_data ()
الخطوة 3 - تصور البيانات
نظرًا لتنزيل مجموعة البيانات جنبًا إلى جنب مع الصور والتسميات المقابلة لها ، لتوضيح الأمر بشكل أكبر للمستخدم ، يُنصح دائمًا بعرض البيانات حتى نتمكن من فهم نوع البيانات التي نتعامل معها من خلال بناء التلافيف العصبي نموذج الشبكة وفقًا لذلك. هنا ، مع هذه الكتلة البسيطة من التعليمات البرمجية الموضحة أدناه ، يجب أن نتخيل الصور الثلاث الأولى لمجموعة بيانات التدريب التي يتم خلطها عشوائيًا.
#TensorFlow - تصور البيانات
def imshowTensorFlow (img):
plt.imshow (img، cmap = "رمادي")
print (“Label:”، img [0])
imshowTensorFlow (train_images_tf [0])
التسمية: 9 التسمية: 0 التسمية: 3
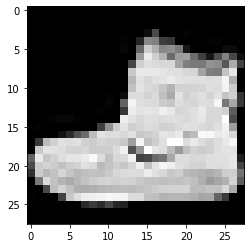


يمكن التحقق من الصورة الواردة أعلاه والتسميات الخاصة بها من خلال الملصقات الواردة في تفاصيل مجموعة بيانات Fashion MNIST أعلاه. من هذا ، نستنتج أن صورة البيانات لدينا عبارة عن صورة ذات تدرج رمادي بارتفاع 28 بكسل وعرض 28 بكسل.
وبالتالي ، يمكن بناء النموذج بحجم إدخال (28،28،1) ، حيث يرمز 1 إلى الصورة ذات التدرج الرمادي.
الخطوة 4 - بناء النموذج
كما ذكرنا أعلاه ، سنقوم في هذه المقالة ببناء شبكة عصبية تلافيفية بسيطة ببنية LeNet. LeNet عبارة عن بنية شبكة عصبية تلافيفية اقترحها Yann LeCun et al. في عام 1989. بشكل عام ، تشير LeNet إلى LeNet-5 وهي عبارة عن شبكة عصبية تلافيفية بسيطة.
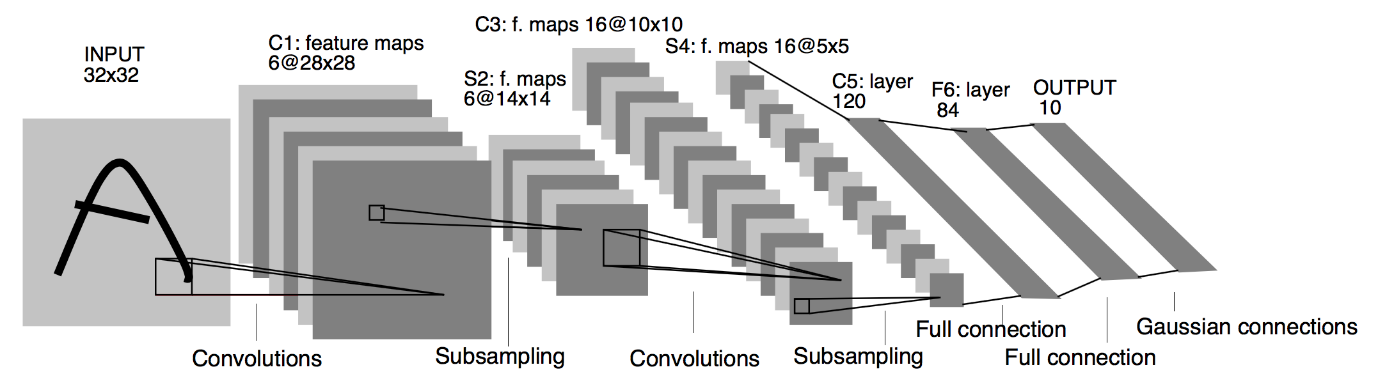
المصدر : The LeNet Architecture
من الرسم التخطيطي للهندسة المعمارية الموضح أعلاه لنموذج LeNet CNN ، نرى أن هناك 5 + 2 طبقات. الطبقتان الأولى والثانية عبارة عن طبقة تلافيفية تليها طبقة تجمع. مرة أخرى ، تتكون الطبقتان الثالثة والرابعة من طبقة تلافيفية وطبقة تجمع. نتيجة لهذه العمليات ، يتم تقليل حجم الصورة المدخلة من 28 × 28 إلى 7 × 7.
الطبقة الخامسة من نموذج LeNet هي الطبقة المتصلة بالكامل والتي تعمل على تسطيح إخراج الطبقة السابقة. متبوعة بطبقتين كثيفتين ، تتكون طبقة الإخراج النهائية لنموذج CNN من وظيفة تنشيط Softmax مع 10 وحدات. تتنبأ دالة Softmax باحتمالية فئة لكل فئة من الفئات العشر لمجموعة بيانات Fashion MNIST.
#TensorFlow - بناء النموذج
النموذج = keras.Sequential ([
keras.layers.Conv2D (input_shape = (28،28،1)، المرشحات = 6، kernel_size = 5، strides = 1، padding = "same"، activation = tf.nn.relu) ،
keras.layers.AveragePooling2D (pool_size = 2 ، خطوات = 2) ،
keras.layers.Conv2D (16، kernel_size = 5، strides = 1، padding = "same"، activation = tf.nn.relu) ،
keras.layers.AveragePooling2D (pool_size = 2 ، خطوات = 2) ،
keras.layers.Flatten () ،
keras.layers.Dense (120 ، تنشيط = tf.nn.relu) ،
keras.layers.Dense (84 ، تنشيط = tf.nn.relu) ،
keras.layers.Dense (10 ، تنشيط = tf.nn.softmax)
])
الخطوة 5 - ملخص النموذج
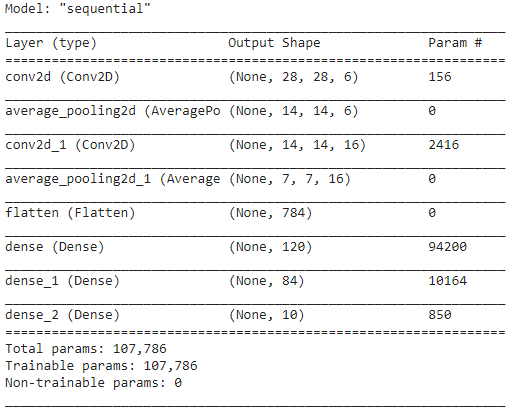
بمجرد الانتهاء من طبقات نموذج LeNet ، يمكننا المضي قدمًا في تجميع النموذج وعرض نسخة مختصرة من نموذج CNN المصمم.
#TensorFlow - ملخص النموذج
model.compile (الخسارة = keras.losses.categorical_crossentropy ،
محسن = 'adam'،
المقاييس = ['acc'])
ملخص نموذج()
في هذا ، نظرًا لأن الناتج النهائي يحتوي على أكثر من صنفين (10 فئات) ، فإننا نستخدم التقاطع الفئوي كوظيفة الخسارة ومحسِّن آدم لنموذجنا المبني. ويرد ملخص النموذج أدناه.
الخطوة 6 - تدريب النموذج
أخيرًا ، نأتي إلى الجزء الذي نبدأ فيه عملية التدريب على نموذج LeNet CNN. أولاً ، نقوم بإعادة تشكيل مجموعة بيانات التدريب وتطبيعها إلى قيم أصغر من خلال القسمة على 255.0 لتقليل التكلفة الحسابية. ثم يتم تحويل تسميات التدريب من متجه فئة عدد صحيح إلى مصفوفة فئة ثنائية. على سبيل المثال ، يتم تحويل التسمية 3 إلى [0 ، 0 ، 0 ، 1 ، 0 ، 0 ، 0 ، 0 ، 0]
#TensorFlow - تدريب النموذج
train_images_tensorflow = (train_images_tf / 255.0) .reshape (train_images_tf.shape [0] ، 28 ، 28 ، 1)
test_images_tensorflow = (test_images_tf / 255.0) .reshape (test_images_tf.shape [0] ، 28 ، 28 ، 1)
train_labels_tensorflow = keras.utils.to_categorical (train_labels_tf)
test_labels_tensorflow = keras.utils.to_categorical (test_labels_tf)
H = model.fit (train_images_tensorflow، train_labels_tensorflow ، عهود = 30 ، حجم_دفعة = 32)
في نهاية التدريب بعد 30 حقبة نحصل على دقة التدريب النهائية والخسارة حيث ،
عصر 30/30
1875/1875 [===============================] - 4 ثوانٍ 2 مللي ثانية / خطوة - خسارة: 0.0421 - acc: 0.9850
دقة التدريب: 98.294997215271٪
خسارة التدريب: 0.04584110900759697
الخطوة 7 - توقع النتائج
أخيرًا ، بمجرد الانتهاء من عملية التدريب الخاصة بنا لنموذج CNN ، سنلائم نفس النموذج في مجموعة بيانات الاختبار ونتوقع دقة 10000 صورة اختبار.
#TensorFlow - مقارنة النتائج
التنبؤات = model.predict (test_images_tensorflow)
صحيح = 0
بالنسبة إلى i ، قبل التعداد (التنبؤات):
إذا كان np.argmax (pred) == test_labels_tf [i]:
صحيح + = 1
print ('اختبار دقة النموذج على {} صور الاختبار: {}٪ باستخدام TensorFlow'.format (test_images_tf.shape [0]، 100 * true / test_images_tf.shape [0]))
الناتج الذي نحصل عليه هو
اختبار دقة النموذج على 10000 صورة اختبار: 90.67٪ مع TensorFlow
بهذا ، نصل إلى نهاية البرنامج الخاص ببناء نموذج تصنيف الصور باستخدام الشبكات العصبية التلافيفية.
اقرأ أيضًا: أفكار مشروع التعلم الآلي
خاتمة
وبالتالي ، في هذا البرنامج التعليمي حول تنفيذ تصنيف الصور في CNN ، فهمنا المفاهيم الأساسية وراء تصنيف الصور والشبكات العصبية التلافيفية جنبًا إلى جنب مع تنفيذها في لغة برمجة Python مع إطار عمل TensorFlow.
إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad's في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهام ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.
ما هو نموذج CNN الذي يعتبر الأفضل لتصنيف الصور؟
أفضل نموذج CNN لتصنيف الصور هو VGG-16 ، والذي يرمز إلى الشبكات التلافيفية العميقة جدًا للتعرف على الصور على نطاق واسع. يتفوق VGG ، الذي تم تصميمه ليكون بمثابة شبكة CNN عميقة ، على خطوط الأساس في مجموعة واسعة من المهام ومجموعات البيانات خارج ImageNet. السمة المميزة للنموذج هي أنه عندما تم إنشاؤه ، تم إيلاء المزيد من الاهتمام لدمج طبقات التفاف ممتازة بدلاً من التركيز على إضافة عدد كبير من المعلمات الفائقة. تحتوي على إجمالي 16 طبقة ، 5 كتل ، ولكل كتلة أقصى طبقة تجميع ، مما يجعلها شبكة كبيرة جدًا.
ما هي عيوب استخدام نماذج CNN لتصنيف الصور؟
عندما يتعلق الأمر بتصنيف الصور ، فإن نماذج CNN ناجحة للغاية. ومع ذلك ، هناك عدة عيوب لاستخدام شبكات CNN. إذا كانت الصورة المراد تحديدها مائلة أو مستديرة ، فإن نموذج CNN يواجه مشاكل في تحديد الصورة بدقة. عندما تصور CNN الصور ، لا توجد تمثيلات داخلية للمكونات ووصلاتها الجزئية بالكامل. علاوة على ذلك ، إذا اشتمل نموذج CNN المراد استخدامه على طبقات تلافيفية عديدة ، فستستغرق عملية التصنيف وقتًا طويلاً.
لماذا يُفضل استخدام نموذج CNN على ANN لبيانات الصورة كإدخال؟
من خلال الجمع بين المرشحات أو التحويلات ، يمكن لـ CNN التعرف على العديد من طبقات تمثيلات الميزات لكل صورة يتم تقديمها كمدخلات. تم تقليل التخصيص نظرًا لأن عدد المعلمات للشبكة للتعلم في CNN أصغر بكثير من الشبكات العصبية متعددة الطبقات. عند استخدام ANN ، قد تتعلم الشبكات العصبية تمثيل ميزة واحدة للصورة ، ولكن في حالة الصور المعقدة ، ستفشل ANN في توفير تصورات أو تصنيفات محسّنة لأنها لا تستطيع معرفة تبعيات البكسل الموجودة في صور الإدخال.