
كيف يتم تطبيق التصنيف في التعلم الآلي؟
نشرت: 2021-03-12لقد زاد تطبيق التعلم الآلي في مختلف المجالات بسرعة فائقة في السنوات القليلة الماضية ، وهو مستمر في القيام بذلك. تتمثل إحدى المهام الأكثر شيوعًا في نموذج التعلم الآلي في التعرف على الكائنات وفصلها في الفئات المخصصة لها.
هذه هي طريقة التصنيف التي تعد واحدة من أكثر تطبيقات التعلم الآلي شيوعًا. يُستخدم التصنيف لفصل كمية هائلة من البيانات إلى مجموعة من القيم المنفصلة التي قد تكون ثنائية مثل 0/1 أو نعم / لا أو متعددة الفئات مثل الحيوانات والسيارات والطيور وما إلى ذلك.
في المقالة التالية ، يجب أن نفهم مفهوم التصنيف في التعلم الآلي ، وأنواع البيانات المتضمنة ، ونرى بعض خوارزميات التصنيف الأكثر شيوعًا المستخدمة في التعلم الآلي لتصنيف العديد من البيانات.
جدول المحتويات
ما هو التعلم الخاضع للإشراف؟
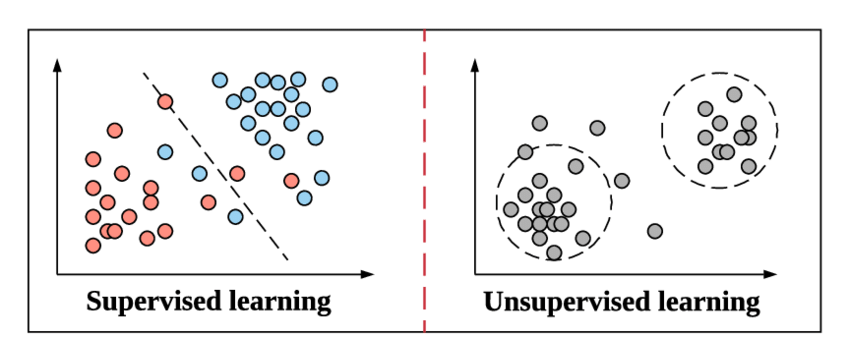
نظرًا لأننا نستعد للتعمق في مفهوم التصنيف وأنواعه ، فلنتحدث سريعًا عن المقصود بالتعلم الخاضع للإشراف وكيف يختلف عن الطريقة الأخرى للتعلم غير الخاضع للإشراف في التعلم الآلي.
دعونا نفهم هذا من خلال أخذ مثال بسيط من فصل الفيزياء في المدرسة الثانوية. افترض أن هناك مشكلة بسيطة تنطوي على طريقة جديدة. إذا تم تقديم سؤال يتعين علينا حله باستخدام نفس الطريقة ، فلن نشير جميعًا إلى مثال لمشكلة بنفس الطريقة ونحاول حلها. بمجرد أن نثق بهذه الطريقة ، لا نحتاج إلى الرجوع إليها مرة أخرى ومواصلة حلها.
مصدر

هذه هي نفس الطريقة التي يعمل بها التعلم الخاضع للإشراف في التعلم الآلي. يتعلم بالقدوة. لإبقاء الأمر أكثر بساطة ، في التعلم الخاضع للإشراف ، يتم تغذية البيانات بأكملها بالتسميات المقابلة لها ، وبالتالي أثناء عملية التدريب ، فإن نموذج التعلم الآلي يقارن مخرجاته لبيانات معينة مع الناتج الحقيقي لتلك البيانات نفسها ويحاول ذلك تقليل الخطأ بين قيمة التسمية المتوقعة والحقيقية.
تتبع خوارزميات التصنيف التي سنتناولها في هذه المقالة طريقة التعلم الخاضع للإشراف - على سبيل المثال ، اكتشاف البريد العشوائي والتعرف على الكائنات.
يعد التعلم غير الخاضع للإشراف خطوة أعلاه حيث لا يتم تغذية البيانات بملصقاتها. يعود الأمر إلى مسؤولية وكفاءة نموذج التعلم الآلي في اشتقاق الأنماط من البيانات وإعطاء المخرجات. تتبع خوارزميات التجميع طريقة التعلم غير الخاضعة للرقابة.
ما هو التصنيف؟
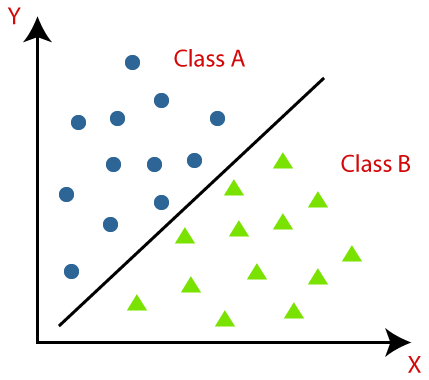
يُعرّف التصنيف بأنه التعرف على الكائنات أو البيانات وفهمها وتجميعها في فئات محددة مسبقًا. من خلال تصنيف البيانات قبل عملية تدريب نموذج التعلم الآلي ، يمكننا استخدام خوارزميات تصنيف مختلفة لتصنيف البيانات إلى عدة فئات. على عكس الانحدار ، تحدث مشكلة التصنيف عندما يكون متغير المخرجات فئة ، مثل "نعم" أو "لا" أو "مرض" أو "لا مرض".
في معظم مشكلات التعلم الآلي ، بمجرد تحميل مجموعة البيانات إلى البرنامج ، قبل التدريب ، قم بتقسيم مجموعة البيانات إلى مجموعة تدريب ومجموعة الاختبار بنسبة ثابتة (عادةً ما تكون مجموعة تدريب 70٪ ومجموعة اختبار 30٪). تسمح عملية التقسيم هذه للنموذج بأداء backpropagation الذي يحاول فيه تصحيح خطأ القيمة المتوقعة مقابل القيمة الحقيقية من خلال عدة تقديرات رياضية.
وبالمثل ، قبل أن نبدأ التصنيف ، يتم إنشاء مجموعة بيانات التدريب. تخضع خوارزمية التصنيف للتدريب عليها أثناء الاختبار على مجموعة بيانات الاختبار مع كل تكرار ، والمعروف باسم الحقبة.
مصدر
أحد أكثر تطبيقات خوارزميات التصنيف شيوعًا هو تصفية رسائل البريد الإلكتروني لمعرفة ما إذا كانت "بريدًا عشوائيًا" أو "ليست بريدًا عشوائيًا". باختصار ، يمكننا تعريف التصنيف في التعلم الآلي كشكل من أشكال "التعرف على الأنماط" حيث يتم استخدام هذه الخوارزميات التي يتم تطبيقها على بيانات التدريب لاستخراج عدة أنماط من البيانات (مثل الكلمات المتشابهة أو التسلسل الرقمي ، والمشاعر ، إلخ. .).
التصنيف هو عملية تصنيف مجموعة معينة من البيانات إلى فئات ؛ يمكن إجراؤها على كل من البيانات المهيكلة أو غير المهيكلة. يبدأ بالتنبؤ بفئة نقاط البيانات المحددة. يشار إلى هذه الفئات أيضًا باسم متغيرات الإخراج ، والعلامات المستهدفة وما إلى ذلك. تحتوي العديد من الخوارزميات على وظائف رياضية تحمل في ثناياه عوامل لتقريب وظيفة التعيين من متغيرات نقطة بيانات الإدخال إلى فئة هدف الإخراج. الهدف الأساسي للتصنيف هو تحديد الفئة / الفئة التي ستندرج فيها البيانات الجديدة.
أنواع خوارزميات التصنيف في التعلم الآلي
اعتمادًا على نوع البيانات التي يتم تطبيق خوارزميات التصنيف عليها ، هناك فئتان عريضتان من الخوارزميات ، النموذجين الخطي وغير الخطي.
النماذج الخطية
- الانحدار اللوجستي
- دعم آلات المتجهات (SVM)
النماذج غير الخطية
- تصنيف K- أقرب الجيران (KNN)
- نواة SVM
- تصنيف بايز ساذج
- تصنيف شجرة القرار
- تصنيف الغابات العشوائية
في هذه المقالة ، سنتناول بإيجاز المفهوم الكامن وراء كل من الخوارزميات المذكورة أعلاه.
تقييم نموذج التصنيف في التعلم الآلي
قبل أن ننتقل إلى مفاهيم هذه الخوارزميات المذكورة أعلاه ، يجب أن نفهم كيف يمكننا تقييم نموذج التعلم الآلي لدينا المبني على رأس هذه الخوارزميات. من الضروري تقييم نموذجنا للتأكد من دقته في كل من مجموعة التدريب ومجموعة الاختبار.
الخسارة عبر الانتروبيا أو فقدان السجل
هذا هو النوع الأول من دالة الخسارة التي سنستخدمها في تقييم أداء المصنف الذي يتراوح ناتجه بين 0 و 1. ويستخدم هذا في الغالب لنماذج التصنيف الثنائي. يتم إعطاء صيغة سجل الخسارة بواسطة ،
سجل الخسارة = - ((1 - ص) * سجل (1 - يهات) + ص * سجل (يهات))
حيث تكون هذه هي القيمة المتوقعة ، و y هي القيمة الحقيقية.
الارتباك مصفوفة
مصفوفة الارتباك هي مصفوفة NXN ، حيث N هو عدد الفئات التي يتم توقعها. توفر لنا مصفوفة الارتباك مصفوفة / جدول كإخراج وتصف أداء النموذج. وهو يتألف من تنبؤات تؤدي إلى شكل مصفوفة يمكننا من خلالها اشتقاق العديد من مقاييس الأداء لتقييم نموذج التصنيف. إنه من الشكل ،
| إيجابي فعلي | سلبي فعلي | |
| توقع إيجابي | صحيح إيجابي | إيجابية كاذبة |
| السلبية المتوقعة | سلبي خطأ | سلبي حقيقي |
فيما يلي بعض مقاييس الأداء التي يمكن اشتقاقها من الجدول أعلاه.
1. الدقة - نسبة العدد الإجمالي للتنبؤات الصحيحة.
2. القيمة التنبؤية الإيجابية أو الدقة - نسبة الحالات الإيجابية التي تم تحديدها بشكل صحيح.
3. القيمة التنبؤية السلبية - نسبة الحالات السلبية التي تم تحديدها بشكل صحيح.
4. الحساسية أو الاستدعاء - نسبة الحالات الإيجابية الفعلية التي تم تحديدها بشكل صحيح.
5. الخصوصية - نسبة الحالات السلبية الفعلية التي تم تحديدها بشكل صحيح.
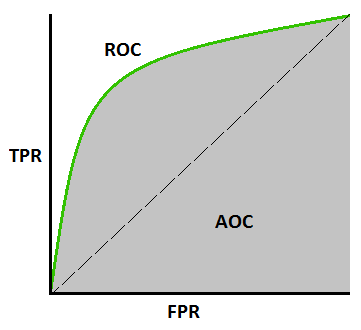
منحنى AUC-ROC -
هذا مقياس منحنى مهم آخر يقوم بتقييم أي نموذج من نماذج التعلم الآلي. يرمز منحنى ROC إلى منحنى خصائص تشغيل جهاز الاستقبال ، بينما يرمز منحنى ROC إلى المنطقة الواقعة تحت المنحنى. يتم رسم منحنى ROC باستخدام TPR و FPR ، حيث TPR (المعدل الإيجابي الحقيقي) على المحور Y و FPR (المعدل الإيجابي الكاذب) على المحور X. يوضح أداء نموذج التصنيف عند عتبات مختلفة.
مصدر
1. الانحدار اللوجستي
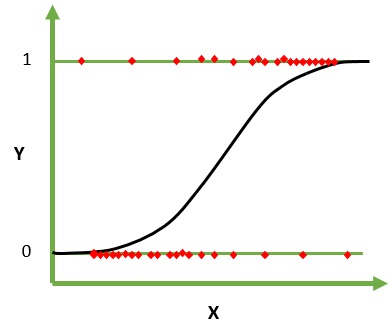
الانحدار اللوجستي هو خوارزمية التعلم الآلي للتصنيف. في هذه الخوارزمية ، يتم نمذجة الاحتمالات التي تصف النتائج المحتملة لتجربة واحدة باستخدام وظيفة لوجستية. يفترض أن متغيرات الإدخال رقمية ولها توزيع غاوسي (منحنى الجرس).

تم استخدام الوظيفة اللوجستية ، التي تسمى أيضًا الوظيفة السينية ، في البداية من قبل الإحصائيين لوصف النمو السكاني في البيئة. الدالة السينية هي دالة رياضية تستخدم لتعيين القيم المتوقعة إلى الاحتمالات. يحتوي الانحدار اللوجستي على منحنى على شكل حرف S ويمكن أن يأخذ قيمًا بين 0 و 1 ولكن ليس عند هذه الحدود تمامًا.
مصدر
يستخدم الانحدار اللوجستي بشكل أساسي للتنبؤ بنتيجة ثنائية مثل نعم / لا وتمرير / فشل. يمكن أن تكون المتغيرات المستقلة فئوية أو رقمية ، لكن المتغير التابع يكون دائمًا قاطعًا. يتم إعطاء صيغة الانحدار اللوجستي بواسطة ،
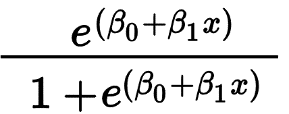
حيث يمثل e المنحنى على شكل حرف S والذي له قيم بين 0 و 1.
2. دعم آلات المتجهات
تستخدم آلة متجه الدعم (SVM) خوارزميات لتدريب البيانات وتصنيفها ضمن درجات القطبية ، مما يجعلها إلى درجة تتجاوز تنبؤات X / Y. في SVM ، يشار إلى الخط المستخدم لفصل الفئات باسم Hyperplane. تسمى نقاط البيانات الموجودة على جانبي الطائرة الفائقة الأقرب للطائرة الفائقة متجهات الدعم المستخدمة لرسم خط الحدود.
تمثل آلة المتجه الداعمة في التصنيف بيانات التدريب كنقاط بيانات في مساحة يتم فيها فصل العديد من الفئات إلى فئات Hyperplane. عندما تدخل نقطة جديدة ، يتم تصنيفها من خلال التنبؤ بالفئة التي تندرج تحتها والتي تنتمي إلى مساحة معينة.
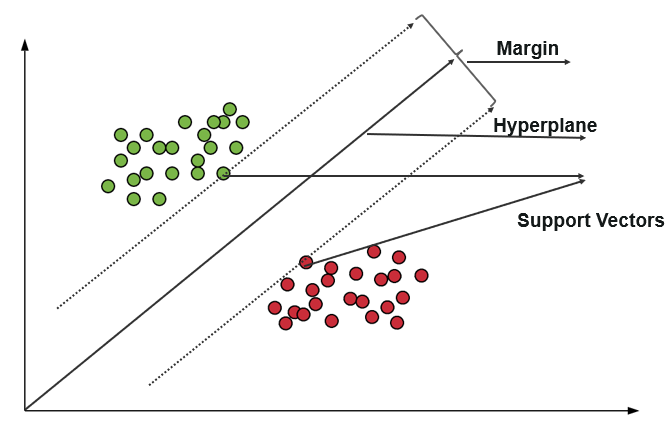
مصدر
الهدف الرئيسي من جهاز Vector Support هو زيادة الهامش بين متجهي الدعم.
انضم إلى دورة ML عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادة المتقدم في ML & AI لتسريع حياتك المهنية.
3. تصنيف K- أقرب الجيران (KNN)
يعد تصنيف KNN أحد أبسط خوارزميات التصنيف ، ومع ذلك يتم استخدامه بشكل كبير بسبب كفاءته العالية وسهولة استخدامه. في هذه الطريقة ، يتم تخزين مجموعة البيانات بأكملها في الجهاز في البداية. ثم يتم اختيار القيمة - k ، والتي تمثل عدد الجيران. بهذه الطريقة ، عند إضافة نقطة بيانات جديدة إلى مجموعة البيانات ، فإنها تأخذ تصويت الأغلبية من تسمية فئة الجيران k الأقرب إلى نقطة البيانات الجديدة تلك. مع هذا التصويت ، تتم إضافة نقطة البيانات الجديدة إلى تلك الفئة المعينة ذات التصويت الأعلى.
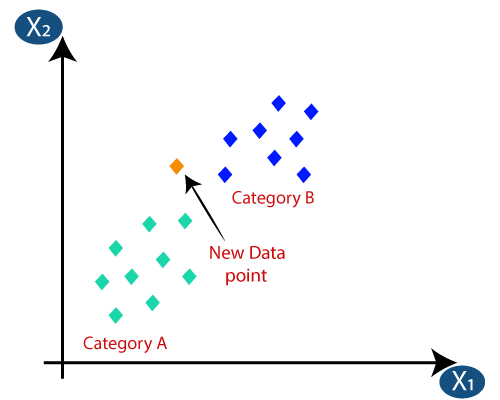
مصدر
4. Kernel SVM
كما هو مذكور أعلاه ، لا يمكن تطبيق آلة متجه الدعم الخطي إلا على البيانات الخطية في الطبيعة. ومع ذلك ، فإن جميع البيانات الموجودة في العالم لا يمكن فصلها خطيًا. ومن ثم ، نحتاج إلى تطوير آلة متجه دعم لحساب البيانات التي يمكن فصلها أيضًا بشكل غير خطي. هنا تأتي خدعة Kernel ، والمعروفة أيضًا باسم Kernel Support Vector Machine أو Kernel SVM.
في Kernel SVM ، نختار نواة مثل RBF أو Gaussian Kernel. يتم تعيين جميع نقاط البيانات إلى بُعد أعلى ، حيث تصبح قابلة للفصل خطيًا. بهذه الطريقة ، يمكننا إنشاء حدود قرار بين الفئات المختلفة لمجموعة البيانات.
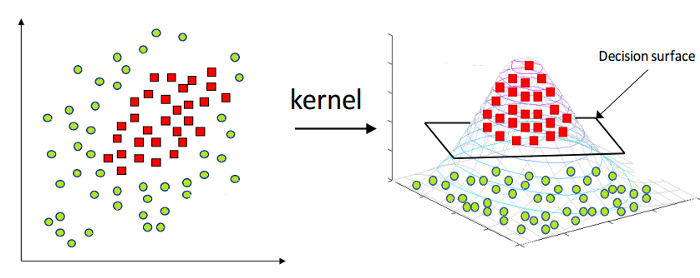
مصدر
ومن ثم ، بهذه الطريقة ، باستخدام المفاهيم الأساسية لآلات المتجهات الداعمة ، يمكننا تصميم Kernel SVM لغير الخطي.
5. تصنيف بايز ساذج
تعود جذور تصنيف Naive Bayes إلى نظرية بايز ، بافتراض أن جميع المتغيرات المستقلة (السمات) لمجموعة البيانات مستقلة. لديهم أهمية متساوية في التنبؤ بالنتيجة. هذا الافتراض من نظرية بايز يعطي الاسم - "ساذج". يتم استخدامه في مهام مختلفة ، مثل تصفية البريد العشوائي ومجالات أخرى من تصنيف النص. يحسب Naive Bayes إمكانية ما إذا كانت نقطة البيانات تنتمي إلى فئة معينة أم لا.
يتم إعطاء صيغة تصنيف Naive Bayes بواسطة ،
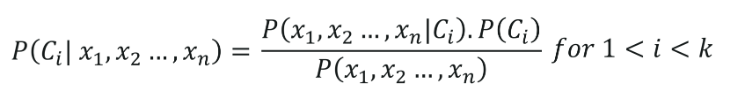
6. تصنيف شجرة القرار
شجرة القرار هي خوارزمية تعلم خاضعة للإشراف مثالية لمشاكل التصنيف ، حيث يمكنها ترتيب الفئات على مستوى محدد. يعمل في شكل مخطط انسيابي حيث يفصل بين نقاط البيانات في كل مستوى. الهيكل النهائي يشبه الشجرة مع العقد والأوراق.

مصدر
سيكون لعقدة القرار فرعين أو أكثر ، وتمثل الورقة تصنيفًا أو قرارًا. في المثال أعلاه لشجرة القرار ، من خلال طرح العديد من الأسئلة ، يتم إنشاء مخطط انسيابي ، والذي يساعدنا في حل المشكلة البسيطة المتمثلة في التنبؤ بالذهاب إلى السوق أم لا.
7. التصنيف العشوائي للغابات
بالرجوع إلى خوارزمية التصنيف الأخيرة لهذه القائمة ، فإن الغابة العشوائية ليست سوى امتداد لخوارزمية شجرة القرار. الغابة العشوائية هي طريقة تعلم جماعية مع أشجار القرار المتعددة. يعمل بنفس طريقة عمل أشجار القرار.
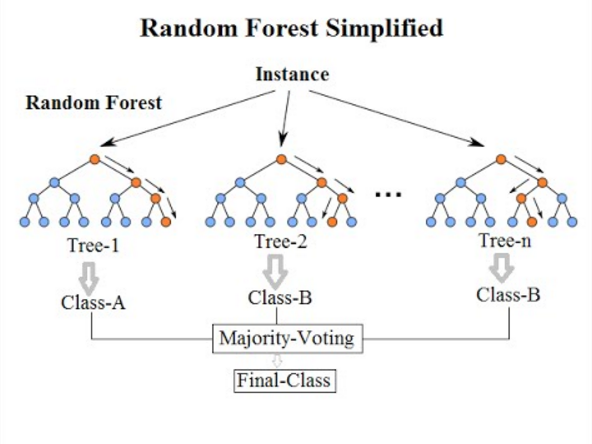
مصدر
تعد خوارزمية Random Forest تقدمًا في خوارزمية شجرة القرار الحالية ، والتي تعاني من مشكلة رئيسية تتمثل في " التجهيز الزائد ". يعتبر أيضًا أسرع وأكثر دقة مقارنةً بخوارزمية شجرة القرار.
اقرأ أيضًا: أفكار ومواضيع لمشروع التعلم الآلي
خاتمة
وبالتالي ، في هذه المقالة حول طرق التعلم الآلي للتصنيف ، فهمنا أساسيات التصنيف والتعلم الخاضع للإشراف وأنواع ومقاييس التقييم لنماذج التصنيف وأخيرًا ملخصًا لجميع نماذج التصنيف الأكثر شيوعًا التعلم الآلي.
إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT -ب حالة الخريجين ، 5+ مشاريع التخرج العملية العملية والمساعدة في العمل مع الشركات الكبرى.
س 1. ما الخوارزميات الأكثر استخدامًا في التعلم الآلي؟
يستخدم التعلم الآلي العديد من الخوارزميات المختلفة ، والتي يمكن تصنيفها على نطاق واسع إلى ثلاثة أنواع رئيسية - خوارزميات التعلم الخاضع للإشراف ، وخوارزميات التعلم غير الخاضعة للإشراف ، وخوارزميات التعلم المعزز. الآن ، لتضييق نطاق بعض الخوارزميات الأكثر استخدامًا وتسميتها ، الخوارزميات التي يجب ذكرها هي الانحدار الخطي ، والانحدار اللوجستي ، و SVM ، وأشجار القرار ، وخوارزمية الغابة العشوائية ، و kNN ، ونظرية Naive Bayes ، و K-Means ، وتقليل الأبعاد ، وخوارزميات تعزيز التدرج. تستحق خوارزميات XGBoost و GBM و LightGBM و CatBoost إشارة خاصة في خوارزميات تعزيز التدرج. يمكن تطبيق هذه الخوارزميات لحل أي نوع من مشاكل البيانات تقريبًا.
س 2. ما هو التصنيف والانحدار في التعلم الآلي؟
يتم استخدام خوارزميات التصنيف والانحدار على نطاق واسع في التعلم الآلي. ومع ذلك ، هناك العديد من الاختلافات بينهما ، والتي تحدد في النهاية استخدامها أو الغرض منها. يتمثل الاختلاف الرئيسي في أنه بينما تُستخدم خوارزميات التصنيف لتصنيف القيم المنفصلة أو التنبؤ بها مثل ذكر-أنثى أو صواب-خطأ ، يتم استخدام خوارزميات الانحدار للتنبؤ بالقيم المستمرة غير المنفصلة مثل الراتب والعمر والسعر وما إلى ذلك. أشجار القرار ، تعد Random Forest و Kernel SVM والانحدار اللوجستي من أكثر خوارزميات التصنيف شيوعًا ، بينما يعد الانحدار الخطي البسيط والمتعدد ودعم الانحدار المتجه والانحدار متعدد الحدود وانحدار شجرة القرار من أكثر خوارزميات الانحدار شيوعًا المستخدمة في التعلم الآلي.
س 3. ما هي المتطلبات الأساسية لتعلم التعلم الآلي؟
لبدء التعلم الآلي ، لا تحتاج إلى أن تكون عالم رياضيات ماهرًا أو مبرمجًا خبيرًا. ومع ذلك ، نظرًا لاتساع المجال ، فقد تشعر بالخوف عندما تكون على وشك البدء في رحلة التعلم الآلي الخاصة بك. في مثل هذه الحالات ، يمكن أن تساعدك معرفة المتطلبات الأساسية في بداية سلسة. المتطلبات الأساسية هي في الأساس المهارات الأساسية التي تحتاج إلى اكتسابها لفهم مفاهيم التعلم الآلي. لذلك أولاً وقبل كل شيء ، تأكد من تعلم كيفية البرمجة باستخدام Python. بعد ذلك ، سيكون الفهم الأساسي للإحصاء والرياضيات ، وخاصة الجبر الخطي وحساب التفاضل والتكامل متعدد المتغيرات ، ميزة إضافية.