
كيفية اختيار طريقة اختيار الميزة للتعلم الآلي
نشرت: 2021-06-22جدول المحتويات
مقدمة اختيار الميزة
يستخدم نموذج التعلم الآلي الكثير من الميزات التي لا يُعد سوى عدد قليل منها مهمًا. هناك انخفاض في دقة النموذج إذا تم استخدام ميزات غير ضرورية لتدريب نموذج بيانات. علاوة على ذلك ، هناك زيادة في تعقيد النموذج وانخفاض في قدرة التعميم مما يؤدي إلى نموذج متحيز. يتناسب قول "أحيانًا الأقل هو الأفضل" مع مفهوم التعلم الآلي. واجهت المشكلة الكثير من المستخدمين حيث وجدوا صعوبة في تحديد مجموعة الميزات ذات الصلة من بياناتهم وتجاهل جميع مجموعات الميزات غير ذات الصلة. يتم تسمية الميزات الأقل أهمية بحيث لا تساهم في المتغير المستهدف.
لذلك ، فإن إحدى العمليات المهمة هي اختيار الميزات في التعلم الآلي . الهدف هو تحديد أفضل مجموعة ممكنة من الميزات لتطوير نموذج التعلم الآلي. هناك تأثير كبير على أداء النموذج من خلال اختيار الميزة. إلى جانب تنظيف البيانات ، يجب أن يكون اختيار الميزة هو الخطوة الأولى في تصميم النموذج.
يمكن تلخيص اختيار الميزة في "التعلم الآلي " على أنه
- التحديد التلقائي أو اليدوي لتلك الميزات التي تساهم بشكل أكبر في متغير التنبؤ أو الإخراج.
- قد يؤدي وجود ميزات غير ذات صلة إلى انخفاض دقة النموذج حيث سيتعلم من الميزات غير ذات الصلة.
فوائد اختيار الميزة
- يقلل فرط احتواء البيانات: يؤدي عدد أقل من البيانات إلى تقليل التكرار. لذلك هناك فرص أقل لاتخاذ قرارات بشأن الضوضاء.
- يحسن دقة النموذج: مع وجود فرصة أقل للبيانات المضللة ، تزداد دقة النموذج.
- يتم تقليل وقت التدريب: تؤدي إزالة الميزات غير ذات الصلة إلى تقليل تعقيد الخوارزمية نظرًا لوجود نقاط بيانات أقل فقط. لذلك ، فإن الخوارزميات تتدرب بشكل أسرع.
- يتم تقليل تعقيد النموذج مع تفسير أفضل للبيانات.
طرق اختيار الميزات الخاضعة للإشراف وغير الخاضعة للإشراف
الهدف الرئيسي من خوارزميات اختيار الميزة هو تحديد مجموعة من أفضل الميزات لتطوير النموذج. يمكن تصنيف طرق اختيار الميزات في التعلم الآلي إلى طرق خاضعة للإشراف وغير خاضعة للإشراف.
- الطريقة الخاضعة للإشراف: تُستخدم الطريقة الخاضعة للإشراف لاختيار الميزات من البيانات المصنفة وتستخدم أيضًا لتصنيف الميزات ذات الصلة. وبالتالي ، هناك زيادة في كفاءة النماذج التي تم إنشاؤها.
- طريقة غير خاضعة للإشراف : تُستخدم طريقة اختيار الميزة هذه للبيانات غير المسماة.
قائمة الأساليب تحت الإشراف
يمكن تصنيف الأساليب الخاضعة للإشراف لاختيار الميزات في التعلم الآلي إلى

1. طرق التغليف
يقوم هذا النوع من خوارزمية اختيار الميزة بتقييم عملية أداء الميزات بناءً على نتائج الخوارزمية. تُعرف أيضًا باسم الخوارزمية الجشعة ، وهي تدرب الخوارزمية باستخدام مجموعة فرعية من الميزات بشكل متكرر. عادة ما يتم تحديد معايير التوقف من قبل الشخص الذي يقوم بتدريب الخوارزمية. تتم إضافة الميزات وإزالتها في النموذج بناءً على التدريب المسبق للنموذج. يمكن تطبيق أي نوع من خوارزمية التعلم في استراتيجية البحث هذه. النماذج أكثر دقة مقارنة بطرق التصفية.
التقنيات المستخدمة في طرق التغليف هي:
- اختيار إلى الأمام: عملية الاختيار إلى الأمام هي عملية تكرارية حيث يتم إضافة ميزات جديدة تعمل على تحسين النموذج بعد كل تكرار. يبدأ بمجموعة فارغة من الميزات. يستمر التكرار ويتوقف حتى تتم إضافة ميزة لا تؤدي إلى تحسين أداء النموذج.
- الاختيار / الحذف العكسي: العملية هي عملية تكرارية تبدأ بجميع الميزات. بعد كل تكرار ، تتم إزالة الميزات الأقل أهمية من مجموعة الميزات الأولية. معيار إيقاف التكرار هو عندما لا يتحسن أداء النموذج أكثر مع إزالة الميزة. يتم تنفيذ هذه الخوارزميات في حزمة mlxtend.
- الإزالة ثنائية الاتجاه : يتم تطبيق كلتا الطريقتين في الاختيار الأمامي وتقنية الإزالة العكسية في وقت واحد في طريقة الإزالة ثنائية الاتجاه للوصول إلى حل فريد واحد.
- اختيار الميزات الشاملة: يُعرف أيضًا باسم نهج القوة الغاشمة لتقييم مجموعات الميزات الفرعية. يتم إنشاء مجموعة من المجموعات الفرعية المحتملة ويتم إنشاء خوارزمية تعلم لكل مجموعة فرعية. يتم اختيار هذه المجموعة الفرعية التي يعطي نموذجها أفضل أداء.
- استبعاد الميزة العودية (RFE): يُطلق على الطريقة اسم الجشع لأنها تختار الميزات من خلال التفكير المتكرر في مجموعة الميزات الأصغر والأصغر. يتم استخدام مجموعة أولية من الميزات لتدريب المقدّر ويتم الحصول على أهميتها باستخدام سمة_قيمة_خاصية_ميزة. ثم يتم اتباعها من خلال إزالة الميزات الأقل أهمية تاركًا وراءها فقط العدد المطلوب من الميزات. يتم تنفيذ الخوارزميات في حزمة scikit-Learn.
الشكل 4: مثال على رمز يوضح تقنية حذف الميزة العودية
2. الأساليب المضمنة
تتميز طرق اختيار الميزة المضمنة في التعلم الآلي بميزة معينة على طرق التصفية والغلاف من خلال تضمين تفاعل الميزة وكذلك الحفاظ على تكلفة حسابية معقولة. التقنيات المستخدمة في الطرق المضمنة هي:
- التنظيم: يتجنب النموذج التلاعب في البيانات عن طريق إضافة عقوبة إلى معلمات النموذج. تضاف المعاملات مع العقوبة مما يؤدي إلى أن تكون بعض المعاملات صفرًا. لذلك تتم إزالة الميزات التي لها معامل صفري من مجموعة الميزات. نهج اختيار الميزة يستخدم Lasso (تنظيم L1) والشبكات المرنة (L1 و L2 تنظيم).
- SMLR (الانحدار اللوجستي المتناثر متعدد الحدود): تنفذ الخوارزمية تنظيمًا متناثرًا بواسطة ARD المسبق (تحديد الملاءمة التلقائي) للانحدار اللوجستي الكلاسيكي متعدد الجنسيات. يقدّر هذا التنظيم أهمية كل ميزة ويقلل الأبعاد غير المفيدة للتنبؤ. يتم تنفيذ الخوارزمية في SMLR.
- ARD (الانحدار التلقائي لتحديد الملاءمة): ستحول الخوارزمية أوزان المعامل نحو الصفر وتستند إلى انحدار Bayesian Ridge. يمكن تنفيذ الخوارزمية في scikit-Learn.
- أهمية الغابة العشوائية: خوارزمية اختيار الميزة هذه عبارة عن تجميع لعدد محدد من الأشجار. يتم تصنيف الاستراتيجيات القائمة على الأشجار في هذه الخوارزمية على أساس زيادة شوائب العقدة أو تقليل النجاسة (شائبة جيني). تتكون نهاية الشجر من العقد الأقل نقصًا في النجاسة ، وتتكون بداية الشجر من عُقد ذات نقص أكبر في النجاسة. لذلك ، يمكن تحديد الميزات المهمة من خلال تقليم الشجرة أسفل عقدة معينة.
3. طرق التصفية
يتم تطبيق الطرق خلال خطوات المعالجة المسبقة. الطرق سريعة جدًا وغير مكلفة وتعمل بشكل أفضل في إزالة الميزات المكررة والمترابطة والمكررة. بدلاً من تطبيق أي طرق تعلم خاضعة للإشراف ، يتم تقييم أهمية الميزات بناءً على خصائصها المتأصلة. التكلفة الحسابية للخوارزمية أقل مقارنة بطرق التجميع لاختيار الميزة. ومع ذلك ، في حالة عدم وجود بيانات كافية لاشتقاق الارتباط الإحصائي بين الميزات ، فقد تكون النتائج أسوأ من طرق التجميع. لذلك ، يتم استخدام الخوارزميات على البيانات عالية الأبعاد ، مما قد يؤدي إلى تكلفة حسابية أعلى إذا تم تطبيق طرق التجميع.

الأساليب المستخدمة في طرق التصفية هي :
- كسب المعلومات : يشير كسب المعلومات إلى مقدار المعلومات المكتسبة من الميزات لتحديد القيمة المستهدفة. ثم يقيس الانخفاض في قيم الانتروبيا. يتم حساب اكتساب المعلومات لكل سمة مع مراعاة القيم المستهدفة لاختيار الميزة.
- اختبار Chi-square: طريقة Chi-square (X 2 ) تُستخدم عمومًا لاختبار العلاقة بين متغيرين فئتين. يستخدم الاختبار لتحديد ما إذا كان هناك فرق كبير بين القيم الملاحظة من السمات المختلفة لمجموعة البيانات إلى قيمتها المتوقعة. تنص الفرضية الصفرية على عدم وجود ارتباط بين متغيرين.
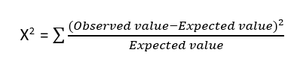
مصدر
صيغة اختبار Chi-Square
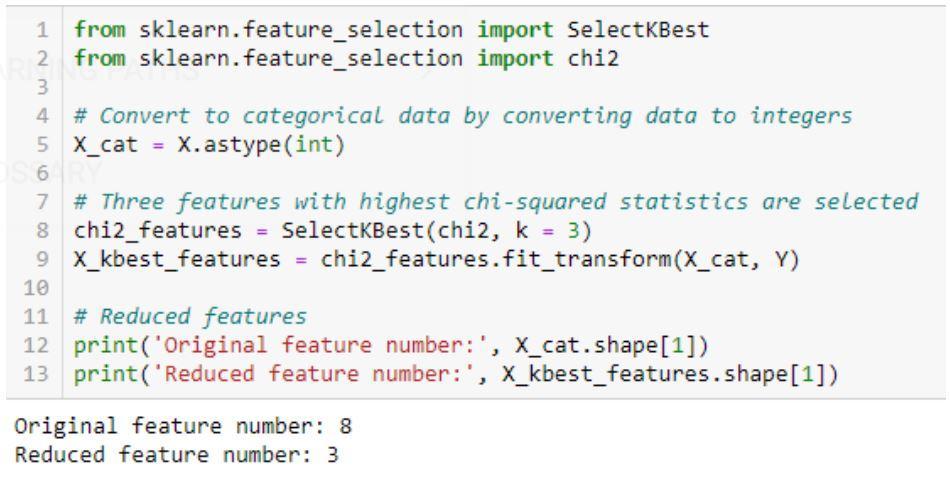
تنفيذ خوارزمية Chi-Squared: sklearn ، scipy
مثال على رمز اختبار Chi-Square
مصدر
- CFS (اختيار الميزات المستندة إلى الارتباط): تتبع الطريقة " تنفيذ CFS (اختيار الميزات القائمة على الارتباط): scikit-feature
انضم إلى دورات AI & ML عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
- FCBF (مرشح قائم على الارتباط السريع): مقارنة بالطرق المذكورة أعلاه للإغاثة و CFS ، فإن طريقة FCBF أسرع وأكثر كفاءة. في البداية ، يتم حساب عدم اليقين المتماثل لجميع الميزات. باستخدام هذه المعايير ، يتم بعد ذلك فرز الميزات وإزالة الميزات الزائدة.
عدم اليقين المتماثل = كسب المعلومات لـ x | y مقسومًا على مجموع الانتروبيا الخاصة بهم. تنفيذ FCBF: skfeature
- درجة فيشر: تُعرّف حصة فيشر (FIR) على أنها المسافة بين متوسطات العينة لكل فئة لكل ميزة مقسومة على الفروق. يتم اختيار كل ميزة بشكل مستقل وفقًا لدرجاتها وفقًا لمعيار Fisher. هذا يؤدي إلى مجموعة من الميزات دون المستوى الأمثل. تشير درجة فيشر الأكبر إلى ميزة تم اختيارها بشكل أفضل.
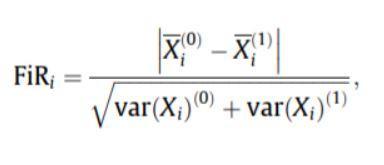
مصدر
صيغة نقاط فيشر
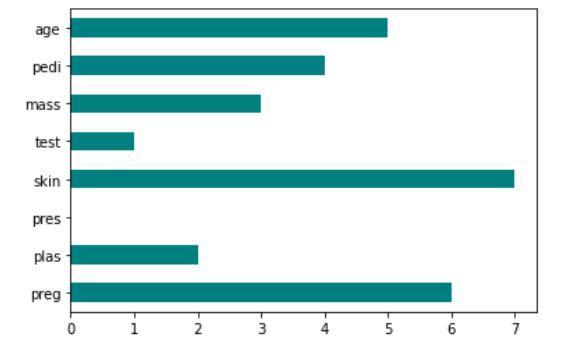
تنفيذ مقياس فيشر: ميزة scikit
يظهر إخراج الكود تقنية نقاط فيشر
مصدر
معامل ارتباط بيرسون: هو مقياس لقياس الارتباط بين المتغيرين المستمرين. تتراوح قيم معامل الارتباط من -1 إلى 1 الذي يحدد اتجاه العلاقة بين المتغيرات.
- حد التباين: تتم إزالة الميزات التي لا يتوافق تباينها مع الحد المعين. تتم إزالة الميزات التي لا تحتوي على أي تباين من خلال هذه الطريقة. الافتراض الذي تم أخذه في الاعتبار هو أن ميزات التباين الأعلى من المحتمل أن تحتوي على مزيد من المعلومات.
الشكل 15: مثال على رمز يوضح تنفيذ حد التباين
- متوسط الفرق المطلق (MAD): تحسب الطريقة المتوسط المطلق
الاختلاف عن متوسط القيمة.
مثال على الكود ومخرجاته يوضح تنفيذ متوسط الفروق المطلقة (MAD)
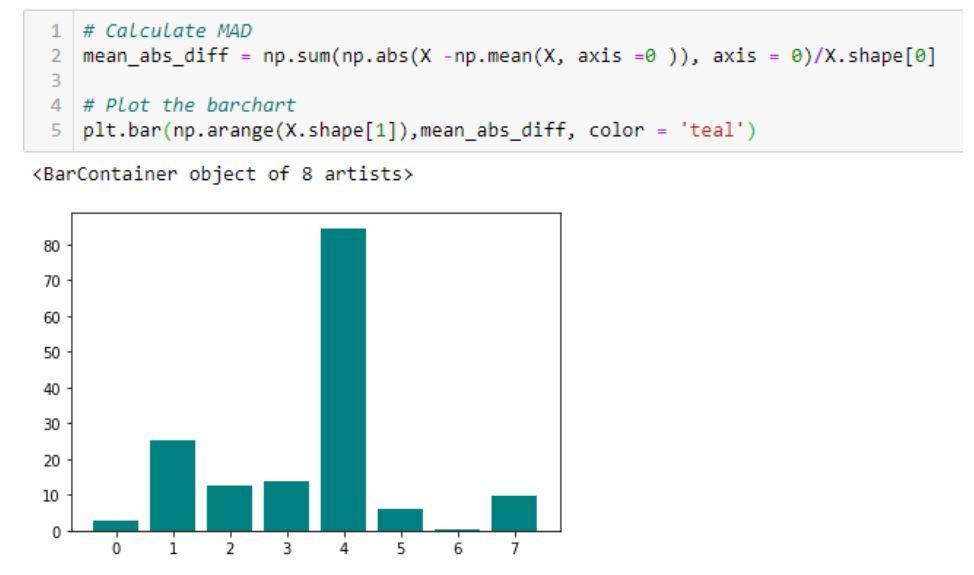
مصدر
- نسبة التشتت: يتم تعريف نسبة التشتت على أنها نسبة المتوسط الحسابي (AM) إلى المتوسط الهندسي (GM) لميزة معينة. تتراوح قيمته من +1 إلى ∞ كـ AM ≥ GM لميزة معينة.
تشير نسبة التشتت الأعلى إلى قيمة أعلى لـ Ri وبالتالي ميزة أكثر صلة. على العكس من ذلك ، عندما يقترب Ri من 1 ، فإنه يشير إلى ميزة ذات صلة منخفضة.
- الاعتماد المتبادل: تستخدم الطريقة لقياس الاعتماد المتبادل بين متغيرين. يمكن استخدام المعلومات التي تم الحصول عليها من متغير واحد للحصول على معلومات للمتغير الآخر.
- نقاط لابلاسيان: غالبًا ما تكون البيانات من نفس الفصل قريبة من بعضها البعض. يمكن تقييم أهمية الميزة من خلال قدرتها على الحفاظ على المنطقة. يتم احتساب نقاط لابلاسيان لكل ميزة. أصغر القيم تحدد أبعاد مهمة. تنفيذ درجة لابلاسيان: ميزة scikit.
خاتمة
يمكن تلخيص اختيار الميزة في عملية التعلم الآلي كإحدى الخطوات المهمة نحو تطوير أي نموذج للتعلم الآلي. تؤدي عملية خوارزمية اختيار الميزة إلى تقليل أبعاد البيانات مع إزالة الميزات غير ذات الصلة أو المهمة للنموذج قيد الدراسة. يمكن للميزات ذات الصلة تسريع وقت تدريب النماذج مما يؤدي إلى أداء عالٍ.
إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT -ب حالة الخريجين ، 5+ مشاريع التخرج العملية العملية والمساعدة في العمل مع الشركات الكبرى.
كيف تختلف طريقة التصفية عن طريقة التغليف؟
تساعد طريقة التضمين في قياس مدى فائدة الميزات بناءً على أداء المصنف. من ناحية أخرى ، تقوم طريقة التصفية بتقييم الصفات الجوهرية للميزات باستخدام الإحصائيات أحادية المتغير بدلاً من أداء التحقق المتبادل ، مما يعني أنها تحكم على أهمية الميزات. نتيجة لذلك ، تكون طريقة الغلاف أكثر فاعلية لأنها تحسن أداء المصنف. ومع ذلك ، بسبب عمليات التعلم المتكررة والتحقق المتبادل ، فإن تقنية الغلاف تكون أكثر تكلفة من الناحية الحسابية من طريقة التصفية.
ما هو التحديد المتسلسل للأمام في التعلم الآلي؟
إنه نوع من تحديد الميزات المتسلسلة ، على الرغم من أنه أكثر تكلفة بكثير من اختيار المرشح. إنها تقنية بحث جشعة تقوم باختيار الميزات بشكل متكرر بناءً على أداء المصنف من أجل اكتشاف مجموعة الميزات المثالية. يبدأ بمجموعة ميزة فرعية فارغة ويستمر في إضافة ميزة واحدة في كل جولة. يتم اختيار هذه الميزة الواحدة من بين مجموعة من جميع الميزات غير الموجودة في مجموعة الميزات الفرعية الخاصة بنا ، وهي الميزة التي تؤدي إلى أفضل أداء مصنف عند دمجها مع الميزات الأخرى.
ما هي قيود استخدام طريقة التصفية لاختيار الميزة؟
يعتبر أسلوب التصفية أقل تكلفة من الناحية الحسابية من طرق اختيار الغلاف والميزة المضمنة ، ولكن له بعض العيوب. في حالة الأساليب أحادية المتغير ، تتجاهل هذه الإستراتيجية بشكل متكرر ترابط السمات أثناء اختيار الميزات وتقييم كل ميزة بشكل مستقل. عند المقارنة بالطريقتين الأخريين لاختيار الميزة ، قد يؤدي ذلك أحيانًا إلى ضعف أداء الحوسبة.