
كتاب تمهيدي لـ GraphQL: تطور تصميم واجهة برمجة التطبيقات (الجزء الثاني)
نشرت: 2022-03-10في الجزء الأول ، نظرنا في كيفية تطور واجهات برمجة التطبيقات خلال العقود القليلة الماضية وكيف تراجعت كل واحدة عن الأخرى. تحدثنا أيضًا عن بعض عيوب استخدام REST لتطوير عملاء الأجهزة المحمولة. في هذه المقالة ، أرغب في إلقاء نظرة على المكان الذي يبدو أن تصميم واجهة برمجة تطبيقات عميل الجوّال يتجه إليه - مع التركيز بشكل خاص على GraphQL.
هناك ، بالطبع ، الكثير من الأشخاص والشركات والمشاريع التي حاولت معالجة أوجه القصور في REST على مر السنين: HAL و Swagger / OpenAPI و OData JSON API وعشرات من المشاريع الأصغر أو الداخلية الأخرى سعت جميعها إلى جلب النظام إلى عالم REST دون المواصفات. بدلاً من أخذ العالم على ما هو عليه واقتراح تحسينات تدريجية ، أو محاولة تجميع قطع متباينة كافية لجعل REST في ما أحتاجه ، أود تجربة تجربة فكرية. بالنظر إلى فهم التقنيات التي نجحت ولم تنجح في الماضي ، أود أن أتناول قيود اليوم ولغاتنا الأكثر تعبيرًا بشكل كبير لمحاولة رسم واجهة برمجة التطبيقات التي نريدها. دعنا نعمل من تجربة المطور إلى الوراء بدلاً من التنفيذ إلى الأمام (أنا أنظر إليك SQL).
الحد الأدنى من حركة مرور HTTP
نحن نعلم أن تكلفة كل طلب شبكة (HTTP / 1) مرتفعة وفقًا لعدد غير قليل من المقاييس بدءًا من زمن الوصول إلى عمر البطارية. من الناحية المثالية ، سيحتاج عملاء واجهة برمجة التطبيقات الجديدة الخاصة بنا إلى طريقة لطلب جميع البيانات التي يحتاجونها في أقل عدد ممكن من الرحلات ذهابًا وإيابًا.
الحد الأدنى من الحمولات
نعلم أيضًا أن العميل العادي محدود الموارد ، في النطاق الترددي ووحدة المعالجة المركزية والذاكرة ، لذلك يجب أن يكون هدفنا إرسال المعلومات التي يحتاجها عملائنا فقط. للقيام بذلك ، سنحتاج على الأرجح إلى طريقة تمكن العميل من طلب أجزاء معينة من البيانات.
انسان قارئ
لقد تعلمنا من أيام SOAP أنه ليس من السهل التفاعل مع API ، وسوف يتشاجر الناس عند ذكرها. تريد فرق الهندسة استخدام نفس الأدوات التي اعتمدنا عليها لسنوات مثل curl و wget و Charles وعلامة تبويب الشبكة في متصفحاتنا.
الأدوات الغنية
شيء آخر تعلمناه من XML-RPC و SOAP هو أن عقود العميل / الخادم وأنظمة الكتابة ، على وجه الخصوص ، مفيدة بشكل مذهل. إذا كان ذلك ممكنًا على الإطلاق ، فإن أي واجهة برمجة تطبيقات جديدة تتمتع بخفة تنسيق مثل JSON أو YAML مع إمكانية الاستبطان لعقود أكثر تنظيماً وأمانًا.
الحفاظ على التفكير المحلي
على مر السنين ، توصلنا إلى اتفاق على بعض المبادئ التوجيهية في كيفية تنظيم قواعد الكود الكبيرة - وأهمها "فصل الاهتمامات". لسوء الحظ بالنسبة لمعظم المشاريع ، يميل هذا إلى الانهيار في شكل طبقة وصول إلى البيانات المركزية. إذا أمكن ، يجب أن يكون لدى الأجزاء المختلفة من التطبيق خيار إدارة احتياجات البيانات الخاصة بها جنبًا إلى جنب مع وظائفها الأخرى.
نظرًا لأننا نصمم واجهة برمجة تطبيقات تتمحور حول العميل ، فلنبدأ بالشكل الذي قد يبدو عليه لجلب البيانات في واجهة برمجة تطبيقات مثل هذه. إذا علمنا أننا بحاجة إلى القيام بأدنى حد من الرحلات ذهابًا وإيابًا وأننا بحاجة إلى أن نكون قادرين على تصفية الحقول التي لا نريدها ، فنحن بحاجة إلى طريقة لاجتياز مجموعات كبيرة من البيانات ولطلب الأجزاء منها فقط مفيد لنا. تبدو لغة الاستعلام وكأنها مناسبة هنا.
لا نحتاج إلى طرح أسئلة حول بياناتنا بنفس الطريقة التي تستخدمها مع قاعدة البيانات ، لذلك تبدو اللغة الضرورية مثل SQL كأداة خاطئة. في الواقع ، تتمثل أهدافنا الأساسية في اجتياز العلاقات الموجودة مسبقًا وتحديد المجالات التي يجب أن نكون قادرين على القيام بها بشيء بسيط نسبيًا وتوضيحيًا. لقد استقرت الصناعة جيدًا على JSON للبيانات غير الثنائية ، لذا فلنبدأ بلغة استعلام تعريفية شبيهة بـ JSON. يجب أن نكون قادرين على وصف البيانات التي نحتاجها ، ويجب أن يعرض الخادم JSON الذي يحتوي على هذه الحقول.

تفي لغة الاستعلام التعريفي بمتطلبات كل من الحد الأدنى من الحمولات والحد الأدنى من حركة مرور HTTP ، ولكن هناك فائدة أخرى ستساعدنا في تحقيق هدف آخر من أهداف التصميم الخاصة بنا. يمكن معالجة العديد من اللغات التقريرية والاستعلام وغير ذلك بكفاءة كما لو كانت بيانات. إذا قمنا بالتصميم بعناية ، فإن لغة الاستعلام الخاصة بنا ستسمح للمطورين بتفكيك الطلبات الكبيرة وإعادة دمجها بأي طريقة تكون منطقية لمشروعهم. سيساعدنا استخدام لغة استعلام مثل هذه على المضي قدمًا نحو هدفنا النهائي المتمثل في الحفاظ على التفكير المحلي.
هناك الكثير من الأشياء المثيرة التي يمكنك القيام بها بمجرد أن تصبح استفساراتك "بيانات". على سبيل المثال ، يمكنك اعتراض جميع الطلبات وتجميعها على نحو مشابه لكيفية قيام Virtual DOM بتجميع تحديثات DOM ، كما يمكنك استخدام مترجم لاستخراج الاستعلامات الصغيرة في وقت الإنشاء للتخزين المؤقت للبيانات مسبقًا أو يمكنك إنشاء نظام ذاكرة تخزين مؤقت متطور مثل Apollo Cache.
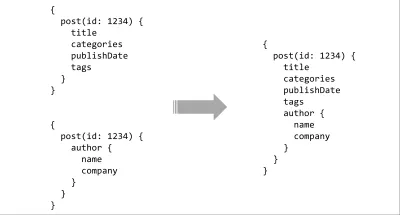
العنصر الأخير في قائمة أمنيات API هو الأدوات. لقد حصلنا بالفعل على بعض من هذا باستخدام لغة استعلام ، ولكن القوة الحقيقية تأتي عندما تقوم بإقرانها بنظام كتابة. مع وجود مخطط مكتوب بسيط على الخادم ، هناك إمكانيات لا حصر لها تقريبًا للأدوات الغنية. يمكن تحليل الاستعلامات والتحقق من صحتها بشكل ثابت مقابل العقد ، ويمكن أن توفر عمليات تكامل IDE تلميحات أو إكمال تلقائي ، ويمكن للمجمعين إجراء تحسينات في وقت البناء على الاستعلامات ، أو يمكن تجميع مخططات متعددة معًا لتشكيل سطح واجهة برمجة تطبيقات متجاور.

قد يبدو تصميم واجهة برمجة تطبيقات تجمع بين لغة استعلام ونظام كتابة اقتراحًا مثيرًا ، لكن الناس جربوا هذا ، بأشكال مختلفة ، لسنوات. دفعت XML-RPC للردود المكتوبة في منتصف التسعينيات وخليفتها ، SOAP ، سيطرت لسنوات! في الآونة الأخيرة ، هناك أشياء مثل مجرّد MongoDB لـ Meteor و RethinkDB (RIP) Horizon و Netflix's Falcor المذهل الذي كانوا يستخدمونه لـ Netflix.com لسنوات وآخرها هناك GraphQL على Facebook. بالنسبة لبقية هذا المقال ، سأركز على GraphQL لأنه بينما تقوم مشاريع أخرى مثل Falcor بأشياء مماثلة ، يبدو أن مشاركة أفكار المجتمع تفضلها بشكل كبير.
ما هي GraphQL؟
أولاً ، يجب أن أقول إنني كذبت قليلاً. واجهة برمجة التطبيقات التي أنشأناها أعلاه كانت GraphQL. GraphQL هي مجرد نظام كتابة لبياناتك ، ولغة استعلام لاجتيازها - والباقي هو مجرد تفاصيل. في GraphQL ، تصف بياناتك كرسم بياني للترابط ، ويطلب العميل تحديدًا المجموعة الفرعية من البيانات التي يحتاجها. هناك الكثير من الحديث والكتابة حول كل الأشياء المذهلة التي تتيحها GraphQL ، لكن المفاهيم الأساسية سهلة الإدارة وغير معقدة.
لجعل هذه المفاهيم أكثر واقعية ، وللمساعدة في توضيح كيف تحاول GraphQL معالجة بعض المشكلات في الجزء الأول ، فإن بقية هذه المقالة ستنشئ واجهة برمجة تطبيقات GraphQL يمكنها تشغيل المدونة في الجزء الأول من هذه السلسلة. قبل القفز إلى الكود ، هناك بعض الأشياء التي يجب مراعاتها حول GraphQL.
GraphQL هي مواصفات (ليست تطبيقًا)
GraphQL ليست سوى مواصفات. إنه يحدد نظام الكتابة إلى جانب لغة استعلام بسيطة ، وهذا كل شيء. أول شيء ينبثق عن هذا هو أن GraphQL ليست مرتبطة بأي شكل من الأشكال بلغة معينة. هناك أكثر من عشرين تطبيقًا في كل شيء بدءًا من Haskell وحتى C ++ ، والتي تعد JavaScript واحدًا منها فقط. بعد وقت قصير من الإعلان عن المواصفات ، أصدر Facebook تطبيقًا مرجعيًا في JavaScript ، ولكن نظرًا لعدم استخدامه داخليًا ، يمكن أن تكون التطبيقات في لغات مثل Go و Clojure أفضل أو أسرع.
لا تذكر مواصفات GraphQL العملاء أو البيانات
إذا قرأت المواصفات ، ستلاحظ أن شيئين غائبين بشكل واضح. أولاً ، بخلاف لغة الاستعلام ، لا يوجد ذكر لعمليات تكامل العميل. أدوات مثل Apollo و Relay و Loka وما شابه ذلك ممكنة بسبب تصميم GraphQL ، لكنها ليست بأي حال من الأحوال جزءًا منها أو مطلوبة لاستخدامها. ثانيًا ، لا يوجد ذكر لأي طبقة بيانات معينة. يمكن لخادم GraphQL نفسه ، وهو يفعل في كثير من الأحيان ، جلب البيانات من مجموعة غير متجانسة من المصادر. يمكنه طلب البيانات المخزنة مؤقتًا من Redis ، وإجراء بحث عن العنوان من USPS API واستدعاء الخدمات المصغرة القائمة على protobuff ولن يعرف العميل أبدًا الفرق.
الإفصاح التدريجي عن التعقيد
لدى GraphQL تقاطع نادر بين القوة والبساطة. إنها تقوم بعمل رائع في جعل الأشياء البسيطة بسيطة والأشياء الصعبة ممكنة. يمكن أن يكون تشغيل الخادم وتقديم البيانات المكتوبة عبر HTTP مجرد بضعة أسطر من التعليمات البرمجية بأي لغة يمكنك تخيلها.
على سبيل المثال ، يمكن لخادم GraphQL التفاف واجهة برمجة تطبيقات REST موجودة ، ويمكن لعملائه الحصول على بيانات مع طلبات GET العادية تمامًا كما تتفاعل مع الخدمات الأخرى. يمكنك مشاهدة العرض هنا. أو ، إذا كان المشروع يحتاج إلى مجموعة أكثر تعقيدًا من الأدوات ، فمن الممكن استخدام GraphQL للقيام بأشياء مثل المصادقة على مستوى الحقل أو اشتراكات النشر / الاشتراكات أو الاستعلامات المجمعة مسبقًا / المخزنة مؤقتًا.
مثال على التطبيق
الهدف من هذا المثال هو إظهار قوة وبساطة GraphQL في 70 سطرًا تقريبًا من JavaScript ، وليس كتابة برنامج تعليمي شامل. لن أخوض في الكثير من التفاصيل حول بناء الجملة والدلالات ولكن كل التعليمات البرمجية هنا قابلة للتشغيل ، وهناك رابط إلى نسخة قابلة للتنزيل من المشروع في نهاية المقالة. إذا كنت ترغب في التعمق أكثر بعد المرور بهذا الأمر ، فلدي مجموعة من الموارد على مدونتي ستساعدك على بناء خدمات أكبر وأكثر قوة.
بالنسبة للعرض التوضيحي ، سأستخدم JavaScript ، لكن الخطوات متشابهة جدًا في أي لغة. لنبدأ ببعض البيانات النموذجية باستخدام Mocky.io المذهل.
المؤلفون
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }المشاركات
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] تتمثل الخطوة الأولى في إنشاء مشروع جديد باستخدام برمجية وسيطة express و express-graphql .
bash npm init -y && npm install --save graphql express express-graphql ولإنشاء ملف index.js بخادم سريع.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); لبدء العمل مع GraphQL ، يمكننا البدء بنمذجة البيانات في REST API. في ملف جديد يسمى schema.js أضف ما يلي:

const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); يحدد الكود أعلاه الأنواع الموجودة في استجابات JSON لواجهة برمجة التطبيقات الخاصة بنا لأنواع GraphQL. يتوافق GraphQLObjectType مع Object JavaScript ، بينما تتوافق GraphQLString مع String JavaScript وما إلى ذلك. النوع الخاص الوحيد الذي يجب الانتباه إليه هو GraphQLSchema في الأسطر القليلة الماضية. GraphQLSchema هي عملية تصدير على مستوى الجذر لـ GraphQL - نقطة البداية لطلبات البحث لاجتياز الرسم البياني. في هذا المثال الأساسي ، نقوم بتعريف query فقط ؛ هذا هو المكان الذي ستحدد فيه الطفرات (يكتب) والاشتراكات.
بعد ذلك ، سنقوم بإضافة المخطط إلى خادمنا السريع في ملف index.js . للقيام بذلك ، سنضيف البرمجيّة الوسيطة express-graphql المخطط.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); في هذه المرحلة ، على الرغم من أننا لا نعيد أي بيانات ، فلدينا خادم GraphQL عامل يوفر مخططه للعملاء. لتسهيل بدء تشغيل التطبيق ، سنضيف أيضًا نص البداية إلى package.json .
"scripts": { "start": "nodemon index.js" }, تشغيل المشروع والانتقال إلى https: // localhost: 5000 / يجب أن يعرض مستكشف بيانات يسمى GraphiQL. سيتم تحميل GraphiQL افتراضيًا طالما أن رأس HTTP Accept غير مضبوط على application/json . سيؤدي استدعاء عنوان URL هذا باستخدام fetch أو cURL باستخدام application/json إلى عرض نتيجة JSON. لا تتردد في التلاعب بالوثائق المضمنة وكتابة استعلام.

الشيء الوحيد المتبقي لإكمال الخادم هو توصيل البيانات الأساسية بالمخطط. للقيام بذلك ، نحتاج إلى تحديد وظائف resolve . في GraphQL ، يتم تشغيل استعلام من أعلى لأسفل لاستدعاء وظيفة resolve أثناء عبوره للشجرة. على سبيل المثال ، للاستعلام التالي:
query homepage { posts { title } } ستستدعي GraphQL أولاً posts.resolve(parentData) ثم posts.title.resolve(parentData) . لنبدأ بتحديد المحلل في قائمة منشورات المدونة الخاصة بنا.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); أنا أستخدم حزمة isomorphic-fetch هنا لتقديم طلب HTTP لأنه يوضح بشكل جيد كيفية إرجاع الوعد من المحلل ، ولكن يمكنك استخدام أي شيء تريده. ستعيد هذه الوظيفة مجموعة من المنشورات إلى نوع المدونة. وظيفة التحليل الافتراضية لتطبيق JavaScript في GraphQL هي parentData.<fieldName> . على سبيل المثال ، المحلل الافتراضي لحقل اسم المؤلف سيكون:
rawAuthorObject => rawAuthorObject.nameيجب أن يوفر محلل التجاوز الفردي البيانات لكائن المنشور بأكمله. ما زلنا بحاجة إلى تحديد محلل المؤلف ولكن إذا قمت بتشغيل استعلام لجلب البيانات المطلوبة للصفحة الرئيسية ، فيجب أن تراها تعمل.
نظرًا لأن سمة المؤلف في واجهة برمجة تطبيقات منشوراتنا هي مجرد معرف المؤلف ، فعندما تبحث GraphQL عن كائن يعرّف الاسم والشركة ويعثر على سلسلة ، فإنه سيعود null . لإرسال رسالة إلى المؤلف ، نحتاج إلى تغيير مخطط النشر الخاص بنا ليبدو كما يلي:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });الآن ، لدينا خادم GraphQL يعمل بكامل طاقته ويلتف بواجهة برمجة تطبيقات REST. يمكن تنزيل المصدر الكامل من رابط Github هذا ، أو تشغيله من لوحة تشغيل GraphQL هذه.
قد تتساءل عن الأدوات التي ستحتاج إلى استخدامها لاستهلاك نقطة نهاية GraphQL مثل هذه. هناك الكثير من الخيارات مثل Relay و Apollo ولكن للبدء ، أعتقد أن الأسلوب البسيط هو الأفضل. إذا لعبت مع GraphiQL كثيرًا ، فربما لاحظت أن لها عنوان URL طويل. عنوان URL هذا هو مجرد نسخة مشفرة من استعلامك عن طريق URI. لإنشاء استعلام GraphQL في JavaScript ، يمكنك القيام بشيء مثل هذا:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);أو ، إذا كنت ترغب في ذلك ، يمكنك نسخ ولصق عنوان URL مباشرة من GraphiQL مثل هذا:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageنظرًا لأن لدينا نقطة نهاية GraphQL وطريقة لاستخدامها ، يمكننا مقارنتها بواجهة برمجة تطبيقات RESTish الخاصة بنا. بدا الكود الذي نحتاج إلى كتابته لجلب بياناتنا باستخدام RESTish API كما يلي:
باستخدام RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };استخدام واجهة برمجة تطبيقات GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);باختصار ، استخدمنا GraphQL من أجل:
- تقليل تسعة طلبات (قائمة التدوينات وأربع منشورات مدونة ومؤلف كل منشور).
- تقليل كمية البيانات المرسلة بنسبة كبيرة.
- استخدم أدوات مطور مذهلة لبناء استفساراتنا.
- اكتب كود أكثر نظافة في عميلنا.
عيوب في GraphQL
بينما أعتقد أن الدعاية لها ما يبررها ، فلا يوجد حل سحري ، وبقدر ما تتمتع به GraphQL من عظمة ، فهي لا تخلو من العيوب.
تكامل البيانات
تبدو GraphQL أحيانًا كأداة تم إنشاؤها لغرض الحصول على بيانات جيدة. غالبًا ما يعمل بشكل أفضل كنوع من العبّارة ، حيث يجمع الخدمات المتباينة أو الجداول شديدة التسوية. إذا كانت البيانات التي تعود من الخدمات التي تستهلكها فوضوية وغير منظمة ، فإن إضافة خط أنابيب لتحويل البيانات أسفل GraphQL يمكن أن يمثل تحديًا حقيقيًا. نطاق وظيفة حل GraphQL هو فقط البيانات الخاصة بها والبيانات التابعة لها. إذا احتاجت مهمة تنسيق إلى الوصول إلى البيانات الموجودة في أحد الأشقاء أو الوالدين في الشجرة ، فقد يكون ذلك صعبًا بشكل خاص.
معالجة الأخطاء المعقدة
يمكن لطلب GraphQL تشغيل عدد عشوائي من الاستعلامات ، ويمكن أن يصل كل استعلام إلى عدد عشوائي من الخدمات. في حالة فشل أي جزء من الطلب ، بدلاً من فشل الطلب بالكامل ، تقوم GraphQL ، افتراضيًا ، بإرجاع بيانات جزئية. من المحتمل أن تكون البيانات الجزئية هي الاختيار الصحيح تقنيًا ، ويمكن أن تكون مفيدة وفعالة بشكل لا يصدق. العيب هو أن معالجة الأخطاء لم تعد بسيطة مثل التحقق من رمز حالة HTTP. يمكن إيقاف تشغيل هذا السلوك ، ولكن في أغلب الأحيان ، ينتهي الأمر بالعملاء مع حالات خطأ أكثر تعقيدًا.
التخزين المؤقت
على الرغم من أنه غالبًا ما يكون استخدام استعلامات GraphQL الثابتة فكرة جيدة ، إلا أنه بالنسبة لمؤسسات مثل Github التي تسمح بالاستعلامات التعسفية ، فإن التخزين المؤقت للشبكة باستخدام أدوات قياسية مثل Varnish أو Fastly لن يكون ممكنًا بعد الآن.
تكلفة وحدة المعالجة المركزية عالية
إن تحليل استعلام والتحقق منه والتحقق منه هو عملية مرتبطة بوحدة المعالجة المركزية والتي يمكن أن تؤدي إلى مشاكل في الأداء في اللغات ذات الخيوط الفردية مثل JavaScript.
هذه ليست سوى مشكلة لتقييم الاستعلام وقت التشغيل.
خواطر ختامية
ميزات GraphQL ليست ثورة - بعضها موجود منذ ما يقرب من 30 عامًا. ما يجعل GraphQL قوية هو أن مستوى الصقل والتكامل وسهولة الاستخدام يجعلها أكثر من مجرد مجموع أجزائها.
يمكن تحقيق العديد من الأشياء التي تنجزها GraphQL ، بالجهد والانضباط ، باستخدام REST أو RPC ، لكن GraphQL تقدم أحدث واجهات برمجة التطبيقات إلى العدد الهائل من المشاريع التي قد لا يكون لديها الوقت أو الموارد أو الأدوات للقيام بذلك بأنفسهم. من الصحيح أيضًا أن GraphQL ليست حلاً سحريًا ، ولكن عيوبها تميل إلى أن تكون طفيفة ومفهومة جيدًا. بصفتي شخصًا أنشأ خادم GraphQL معقدًا بشكل معقول ، يمكنني القول بسهولة أن الفوائد تفوق التكلفة بسهولة.
تركز هذه المقالة بشكل كامل تقريبًا على سبب وجود GraphQL والمشكلات التي تحلها. إذا أثار هذا اهتمامك بمعرفة المزيد عن دلالاتها وكيفية استخدامها ، فأنا أشجعك على التعلم بأي طريقة تناسبك بشكل أفضل سواء كانت مدونات أو youtube أو مجرد قراءة المصدر (How To GraphQL جيد بشكل خاص).
إذا كنت قد استمتعت بهذه المقالة (أو إذا كنت تكرهها) وترغب في إعطائي ملاحظات ، فيرجى العثور علي على Twitter كـebaerbaerbaer أو LinkedIn على ericjbaer.