
الانحدار التدريجي في التعلم الآلي: كيف يعمل؟
نشرت: 2021-01-28جدول المحتويات
مقدمة
يعد تحسين الخوارزميات أحد أهم أجزاء التعلم الآلي. تحتوي جميع الخوارزميات في التعلم الآلي تقريبًا على خوارزمية تحسين في قاعدتها والتي تعمل بمثابة جوهر الخوارزمية. كما نعلم جميعًا ، فإن التحسين هو الهدف النهائي لأي خوارزمية حتى مع أحداث الحياة الواقعية أو عند التعامل مع منتج قائم على التكنولوجيا في السوق.
يوجد حاليًا الكثير من خوارزميات التحسين التي يتم استخدامها في العديد من التطبيقات مثل التعرف على الوجوه ، والسيارات ذاتية القيادة ، والتحليل المستند إلى السوق ، وما إلى ذلك. وبالمثل ، في التعلم الآلي ، تلعب خوارزميات التحسين هذه دورًا مهمًا. إحدى خوارزمية التحسين المستخدمة على نطاق واسع هي خوارزمية Gradient Descent والتي سنناقشها في هذه المقالة.
ما هو الانحدار؟
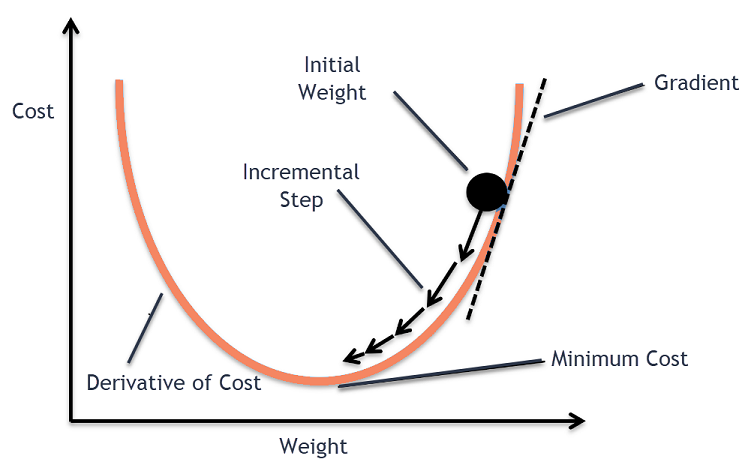
في التعلم الآلي ، تعد خوارزمية Gradient Descent واحدة من أكثر الخوارزميات استخدامًا ، ومع ذلك فهي تُذهل معظم القادمين الجدد. من الناحية الرياضية ، يعد Gradient Descent خوارزمية تحسين تكرارية من الدرجة الأولى تُستخدم للعثور على الحد الأدنى المحلي لوظيفة قابلة للتفاضل. بعبارات بسيطة ، تُستخدم خوارزمية نزول التدرج هذه للعثور على قيم معلمات الوظيفة (أو المعاملات) التي تُستخدم لتقليل دالة التكلفة إلى أدنى مستوى ممكن. تُستخدم دالة التكلفة لتحديد الخطأ بين القيم المتوقعة والقيم الحقيقية لنموذج التعلم الآلي المبني.
حدس نزول التدرج
ضع في اعتبارك وعاءًا كبيرًا تحفظ فيه الفواكه أو تأكل الحبوب. سيكون هذا الوعاء هو دالة التكلفة (و).
الآن ، سيكون التنسيق العشوائي على أي جزء من سطح الوعاء هو القيم الحالية لمعاملات دالة التكلفة. الجزء السفلي من الوعاء هو أفضل مجموعة من المعاملات وهو أدنى قيمة للدالة.
الهدف هنا هو حساب القيم المختلفة للمعاملات مع كل تكرار وتقييم التكلفة واختيار المعاملات التي لها قيمة دالة تكلفة أفضل (قيمة أقل). في التكرارات المتعددة ، يتبين أن قاع الوعاء يحتوي على أفضل المعاملات لتقليل دالة التكلفة.

بهذه الطريقة ، تعمل خوارزمية النسب المتدرجة لتنتج أدنى تكلفة.
انضم إلى دورة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
إجراء نزول التدرج
تبدأ عملية نزول التدرج اللوني بتخصيص القيم مبدئيًا لمعاملات دالة التكلفة. يمكن أن تكون قيمة قريبة من 0 أو قيمة عشوائية صغيرة.
المعامل = 0.0
بعد ذلك ، يتم الحصول على تكلفة المعاملات من خلال تطبيقها على دالة التكلفة وحساب التكلفة.
التكلفة = f (معامل)
بعد ذلك ، يتم حساب مشتق دالة التكلفة. يتم الحصول على مشتق دالة التكلفة من خلال المفهوم الرياضي لحساب التفاضل. يعطينا ميل الدالة عند النقطة المعطاة حيث يتم حساب مشتقها. هذا المنحدر ضروري لمعرفة الاتجاه الذي سيتم فيه نقل المعامل في التكرار التالي للحصول على قيمة تكلفة أقل. يتم ذلك من خلال ملاحظة علامة المشتق المحسوب.
دلتا = مشتق (تكلفة)
بمجرد أن نعرف الاتجاه الذي ينحدر من المنحدر المحسوب ، نحتاج إلى تحديث قيم المعامل. لهذا ، تُعرف المعلمة باسم معلمة التعلم ، يتم استخدام alpha (α). يستخدم هذا للتحكم إلى أي مدى يمكن أن تتغير المعاملات مع كل تحديث.
المعامل = المعامل - (alpha * delta)
مصدر
بهذه الطريقة ، تتكرر هذه العملية حتى تصل تكلفة المعاملات إلى 0.0 أو قريبة بدرجة كافية من الصفر. هذا هو الإجراء الخاص بخوارزمية النسب المتدرج.
أنواع خوارزميات النسب المتدرج
في العصر الحديث ، هناك ثلاثة أنواع أساسية من الانحدار المتدرج التي تُستخدم في التعلم الآلي الحديث وخوارزميات التعلم العميق. يتمثل الاختلاف الرئيسي بين كل نوع من هذه الأنواع الثلاثة في التكلفة والكفاءة الحسابية. اعتمادًا على كمية البيانات المستخدمة ، وتعقيد الوقت ، والدقة ، فيما يلي الأنواع الثلاثة.
- نزول دفعة متدرجة
- الانحدار العشوائي
- نزول دفعة صغيرة متدرجة
نزول دفعة متدرجة
هذا هو الإصدار الأول والأساسي من خوارزميات نزول التدرج حيث يتم استخدام مجموعة البيانات بأكملها مرة واحدة لحساب دالة التكلفة وتدرجها. نظرًا لاستخدام مجموعة البيانات بأكملها دفعة واحدة لتحديث واحد ، يمكن أن يكون حساب التدرج اللوني في هذا النوع بطيئًا للغاية وغير ممكن مع مجموعات البيانات التي نفدت سعة ذاكرة الجهاز.
وبالتالي ، يتم استخدام خوارزمية نزول الدُفعة هذه فقط لمجموعات البيانات الأصغر وعندما يكون عدد أمثلة التدريب كبيرًا ، لا يُفضل نزول التدرج الدُفعي. بدلاً من ذلك ، يتم استخدام خوارزميات Stochastic و Mini Batch Gradient Descent.

الانحدار العشوائي
هذا نوع آخر من خوارزمية نزول التدرج حيث تتم معالجة مثال تدريب واحد فقط لكل تكرار. في هذا ، فإن الخطوة الأولى هي ترتيب مجموعة بيانات التدريب بالكامل بشكل عشوائي. بعد ذلك ، يتم استخدام مثال تدريب واحد فقط لتحديث المعاملات. هذا على عكس نزول التدرج الدُفعي الذي يتم فيه تحديث المعلمات (المعاملات) فقط عند تقييم جميع أمثلة التدريب.
يتميز الانحدار العشوائي (SGD) بميزة أن هذا النوع من التحديث المتكرر يعطي معدل تحسن مفصل. ومع ذلك ، في بعض الحالات ، قد يكون هذا مكلفًا من الناحية الحسابية لأنه يعالج مثالًا واحدًا فقط لكل تكرار مما قد يتسبب في أن يكون عدد التكرارات كبيرًا جدًا.
نزول دفعة صغيرة متدرجة
هذه خوارزمية تم تطويرها مؤخرًا وهي أسرع من كل من خوارزميات الدُفعات والنزول العشوائي. يفضل في الغالب لأنه مزيج من الخوارزميات المذكورة سابقًا. في هذا ، فإنه يفصل مجموعة التدريب إلى عدة دفعات صغيرة ويقوم بإجراء تحديث لكل من هذه الدُفعات بعد حساب التدرج اللوني لتلك الدفعة (كما هو الحال في SGD).
بشكل عام ، يختلف حجم الدُفعة بين 30 إلى 500 ولكن لا يوجد أي حجم ثابت لأنها تختلف باختلاف التطبيقات. ومن ثم ، حتى لو كانت هناك مجموعة بيانات تدريب ضخمة ، فإن هذه الخوارزمية تعالجها على دفعات صغيرة "ب". وبالتالي ، فهي مناسبة لمجموعات البيانات الكبيرة مع عدد أقل من التكرارات.
إذا كان 'm' هو عدد أمثلة التدريب ، فعندئذٍ إذا كان b == m فإن نزول الدُفعة الصغيرة سيكون مشابهًا لخوارزمية Batch Gradient Descent.
متغيرات الانحدار المتدرج في التعلم الآلي
مع هذا الأساس لـ Gradient Descent ، كان هناك العديد من الخوارزميات الأخرى التي تم تطويرها من هذا. يتم تلخيص عدد قليل منهم أدناه.
نزول الفانيليا المتدرج
هذا هو أحد أبسط أشكال تقنية الانحدار. اسم الفانيليا يعني نقي أو بدون أي غش. في هذا ، يتم اتخاذ خطوات صغيرة في اتجاه الحد الأدنى من خلال حساب التدرج اللوني لدالة التكلفة. على غرار الخوارزمية المذكورة أعلاه ، يتم إعطاء قاعدة التحديث بواسطة ،
المعامل = المعامل - (alpha * delta)
نزول متدرج مع زخم
في هذه الحالة ، تكون الخوارزمية بحيث نعرف الخطوات السابقة قبل اتخاذ الخطوة التالية. يتم ذلك عن طريق إدخال مصطلح جديد وهو نتاج التحديث السابق وثابت يعرف باسم الزخم. في هذا ، يتم إعطاء قاعدة تحديث الوزن بواسطة ،
تحديث = ألفا * دلتا
السرعة = التحديث السابق * الزخم
المعامل = المعامل + السرعة - التحديث
ADAGRAD
يشير مصطلح ADAGRAD إلى خوارزمية التدرج التكيفي. كما يقول الاسم ، فإنه يستخدم تقنية تكيفية لتحديث الأوزان. هذه الخوارزمية أكثر ملاءمة للبيانات المتفرقة. يغير هذا التحسين معدلات التعلم الخاصة به فيما يتعلق بتكرار تحديثات المعلمة أثناء التدريب. على سبيل المثال ، فإن المعلمات ذات التدرجات الأعلى تكون ذات معدل تعلم أبطأ بحيث لا ينتهي بنا الأمر إلى تجاوز الحد الأدنى للقيمة. وبالمثل ، فإن التدرجات المنخفضة لديها معدل تعلم أسرع للحصول على تدريب أسرع.
آدم
خوارزمية تحسين تكيفية أخرى لها جذورها في خوارزمية نزول التدرج هي خوارزمية ADAM التي تعني تقدير اللحظات التكيفية. إنه مزيج من كل من ADAGRAD و SGD مع خوارزميات الزخم. إنه مبني من خوارزمية ADAGRAD وهو مبني على مزيد من الجوانب السلبية. بعبارات بسيطة ADAM = ADAGRAD + الزخم.
بهذه الطريقة ، هناك العديد من المتغيرات الأخرى لخوارزميات نزول التدرج التي تم تطويرها ويتم تطويرها في العالم مثل AMSGrad و ADAMax.
خاتمة
في هذه المقالة ، رأينا الخوارزمية وراء واحدة من أكثر خوارزميات التحسين شيوعًا في التعلم الآلي ، وهي خوارزميات نزول التدرج مع أنواعها ومتغيراتها التي تم تطويرها.
توفر upGrad برنامج PG تنفيذي في التعلم الآلي والذكاء الاصطناعي وماجستير العلوم في التعلم الآلي والذكاء الاصطناعي الذي قد يوجهك نحو بناء مستقبل مهني. ستشرح هذه الدورات التدريبية الحاجة إلى التعلم الآلي والخطوات الإضافية لجمع المعرفة في هذا المجال والتي تغطي مفاهيم متنوعة تتراوح من الانحدار التدريجي في التعلم الآلي.
أين يمكن أن تساهم خوارزمية الانحدار في الحد الأقصى؟
يعد التحسين داخل أي خوارزمية للتعلم الآلي أمرًا تدريجيًا لنقاء الخوارزمية. تساعد خوارزمية نزول التدرج في تقليل أخطاء دالة التكلفة وتحسين معلمات الخوارزمية. على الرغم من استخدام خوارزمية النسب المتدرج على نطاق واسع في التعلم الآلي والتعلم العميق ، يمكن تحديد فعاليتها من خلال كمية البيانات ومقدار التكرارات والدقة المفضلة ومقدار الوقت المتاح. بالنسبة لمجموعات البيانات صغيرة الحجم ، يكون الانحدار الدفعي هو الأمثل. يثبت هبوط التدرج العشوائي (SGD) أنه أكثر كفاءة لمجموعات البيانات التفصيلية والأكثر شمولاً. في المقابل ، يتم استخدام Mini Batch Gradient Descent لتحسين أسرع.
ما هي التحديات التي تواجه في الانحدار النسب؟
يُفضل النزول المتدرج لتحسين نماذج التعلم الآلي لتقليل وظيفة التكلفة. ومع ذلك ، فإن لها عيوبها كذلك. افترض أن التدرج اللوني قد تضاءل بسبب الحد الأدنى من وظائف الإخراج لطبقات النموذج. في هذه الحالة ، لن تكون التكرارات فعالة كما لن يقوم النموذج بإعادة التدريب بالكامل ، وتحديث أوزانه وانحيازاته. في بعض الأحيان ، يؤدي تدرج الخطأ إلى تراكم الكثير من الأوزان والتحيزات للحفاظ على التكرارات محدثة. ومع ذلك ، يصبح هذا التدرج أكبر من أن تتم إدارته ويسمى التدرج المتفجر. يجب معالجة متطلبات البنية التحتية ، وتوازن معدل التعلم ، والزخم.
هل يتقارب الانحدار دائمًا؟
التقارب هو عندما تقلل خوارزمية نزول التدرج دالة التكلفة الخاصة بها بنجاح إلى المستوى الأمثل. تحاول خوارزمية نزول التدرج تقليل دالة التكلفة من خلال معلمات الخوارزمية. ومع ذلك ، يمكن أن تهبط على أي من النقاط المثلى وليس بالضرورة النقطة التي تحتوي على أفضل نقطة عالمية أو محلية. أحد أسباب عدم وجود تقارب مثالي هو حجم الخطوة. يؤدي حجم الخطوة الأكثر أهمية إلى مزيد من التذبذبات وقد يؤدي إلى الانحراف عن المستوى العالمي الأمثل. ومن ثم ، قد لا يتقارب النسب المتدرج دائمًا مع أفضل ميزة ، لكنه لا يزال يهبط على أقرب نقطة مميزة.