
الكشف عن الأخبار الزائفة في التعلم الآلي [موضح بمثال الترميز]
نشرت: 2021-02-08الأخبار الكاذبة هي واحدة من أكبر القضايا في العصر الحالي للإنترنت ووسائل التواصل الاجتماعي. في حين أنها نعمة أن الأخبار تتدفق من زاوية من العالم إلى أخرى في غضون ساعات قليلة ، فمن المؤلم أيضًا رؤية العديد من الأشخاص والمجموعات ينشرون أخبارًا كاذبة.
يمكن استخدام تقنيات التعلم الآلي باستخدام معالجة اللغة الطبيعية والتعلم العميق لمعالجة هذه المشكلة إلى حد ما. سننشئ نموذجًا لاكتشاف الأخبار الوهمية باستخدام التعلم الآلي في هذا البرنامج التعليمي.
بنهاية هذا المقال ستعرف ما يلي:
- معالجة البيانات النصية
- تقنيات معالجة البرمجة اللغوية العصبية
- عد الموجهة و TF-IDF
- عمل تنبؤات وتصنيف نص الخبر
انضم إلى دورة AI & ML عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع حياتك المهنية.
جدول المحتويات
البيانات والمشكلة
سنستخدم بيانات تحدي Kaggle Fake News لإنشاء مصنف. تتكون مجموعة البيانات من 4 ميزات وهدف ثنائي واحد. الميزات الأربعة هي كما يلي:
- المعرف : معرف فريد لمقال إخباري
- العنوان : عنوان المقال الإخباري
- المؤلف : مؤلف المقال الإخباري
- النص : نص المقال ؛ يمكن أن تكون غير مكتملة
والهدف هو "التسمية" الذي يحتوي على قيم ثنائية 0 و 1. حيث يعني الرقم 0 أنه مصدر موثوق للأخبار ، أو بعبارة أخرى ، غير مزيف. 1 يعني أنها قطعة من الأخبار الكاذبة وغير موثوقة. تتكون مجموعة البيانات لدينا من 20800 مثيل. دعنا نتعمق في الأمر.

المعالجة المسبقة للبيانات وتنظيفها
| استيراد الباندا كما pd df = pd.read_csv ( "fake-news / train.csv" ) df.head () |
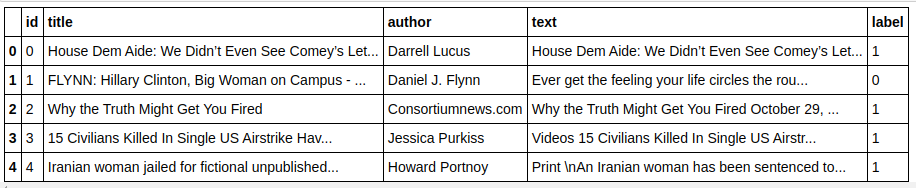
| X = df.drop ( "التسمية" ، المحور = 1 ) # الميزات y = df [ 'label' ] # الهدف |
نحن بحاجة إلى إسقاط المثيلات التي تحتوي على بيانات مفقودة الآن.
| df = df.dropna () |
![]()
كما نرى ، فقد أسقطت جميع الحالات التي تحتوي على بيانات مفقودة.
| الرسائل = df.copy () messages.reset_index (inplace = صحيح ) Messages.head ( 10 ) |
دعنا نلقي نظرة على البيانات مرة واحدة.
| الرسائل ['text'] [6] |

كما نرى هناك حاجة لعمل الخطوات التالية:
- إزالة كلمات الإيقاف: هناك الكثير من الكلمات التي لا تضيف أي قيمة إلى أي نص بغض النظر عن البيانات. على سبيل المثال ، "أنا" ، "أ" ، "أنا" ، إلخ. هذه الكلمات ليس لها قيمة إعلامية ، وبالتالي يمكن إزالتها لتقليل حجم مجموعاتنا حتى نتمكن من التركيز فقط على الكلمات / الرموز المميزة ذات القيمة الفعلية .
- اشتقاق الكلمات: إن الستم والليممات هما طريقتان لتقليل الكلمات إلى جذورها أو جذورها. الميزة الرئيسية لهذه الخطوة هي تقليل حجم المفردات. على سبيل المثال ، سيتم تقليل كلمات مثل Play ، Play ، Played إلى "Play". يقوم الاشتقاق فقط باقتطاع الكلمات إلى أقصر كلمة ولا يأخذ في الاعتبار الجانب النحوي للنص. من ناحية أخرى ، يأخذ Lemmatization الاعتبار النحوي أيضًا وبالتالي ينتج عنه نتائج أفضل بكثير. ومع ذلك ، عادةً ما يكون Lemmatization أبطأ من الاشتقاق لأنه يحتاج إلى الرجوع إلى القاموس وأخذ الجانب النحوي في الاعتبار.
- إزالة كل شيء بعيدًا عن القيم الأبجدية: القيم غير الأبجدية ليست مفيدة كثيرًا هنا لذا يمكن إزالتها. ومع ذلك ، يمكنك استكشاف المزيد لمعرفة ما إذا كان وجود أنواع رقمية أو أنواع أخرى من البيانات له أي تأثير على الهدف.
- الأحرف الصغيرة للكلمات: الكلمات الصغيرة لتقليل المفردات.
- قم بترميز الجمل: توليد الرموز المميزة من الجمل.
| من sklearn.feature_extraction.text استيراد CountVectorizer ، TfidfVectorizer ، HashingVectorizer من كلمات إيقاف استيراد nltk.corpus من nltk.stem.porter استيراد PorterStemmer إعادة الاستيراد ps = PorterStemmer () corpus = [] بالنسبة إلى i في النطاق (0 ، len (الرسائل)): review = re.sub ('[^ a-zA-Z]'، ''، الرسائل ['text'] [i]) مراجعة = review.lower () مراجعة = review.split () review = [ps.stem (word) للكلمة قيد المراجعة إذا لم تكن كلمة في stopwords.words ('english')] review = '' .join (مراجعة) corpus.append (مراجعة) |
دعونا نلقي نظرة على مجموعتنا الآن.
| الجسم [ 3 ] |
![]()
كما نرى ، الكلمات الآن مشتقة من جذورها.
TF-IDF Vectorizer
الآن نحن بحاجة إلى تحويل الكلمات إلى بيانات رقمية والتي تسمى أيضًا Vectorization. أسهل طريقة للتوجيه هي استخدام حقيبة الكلمات. لكن Bag of Words يخلق مصفوفة متفرقة ، وبالتالي هناك الكثير من ذاكرة المعالجة المطلوبة. علاوة على ذلك ، لا يأخذ BoW في الاعتبار تكرار الكلمات مما يجعله خوارزمية سيئة.
TF-IDF (تردد المصطلح - تردد المستند العكسي) هو طريقة أخرى لتوجيه الكلمات التي تأخذ ترددات الكلمات في الاعتبار. على سبيل المثال ، الكلمات الشائعة مثل "نحن" و "خاصتنا" و "ال" موجودة في كل مستند / مثيل وبالتالي فإن قيمة BoW ستكون عالية جدًا وبالتالي مضللة. سيؤدي هذا إلى نموذج سيء. TF-IDF هو مضاعفة تردد المدى وتردد المستندات العكسي.
يأخذ مصطلح "تردد" في الاعتبار تواتر الكلمات في المستند ويأخذ "تردد المستند العكسي" في الاعتبار الكلمات الموجودة في المجموعة بأكملها. قللت الكلمات الموجودة في المجموعة بأكملها من الأهمية لأن قيمة IDF أقل بكثير. الكلمات الموجودة على وجه التحديد في وثيقة واحدة لها قيمة IDF عالية مما يجعل إجمالي قيمة TF-IDF عالية.
| ## TFi df Vectorizer من sklearn.feature_extraction.text استيراد TfidfVectorizer tfidf_v = TfidfVectorizer (max_features = 5000 ، ngram_range = ( 1 ، 3 )) X = tfidf_v.fit_transform (corpus) .toarray () y = الرسائل [ 'label' ] |
في الكود أعلاه ، نقوم باستيراد TF-IDF Vectorizer من وحدة استخراج ميزة Sklearn. نجعل هدفه بتمرير max_features كـ 5000 و ngram_range كـ (1،3). تحدد المعلمة max_features الحد الأقصى لعدد متجهات الميزات التي نريد إنشاءها وتحدد المعلمة ngram_range مجموعات ngram التي نريد تضمينها. في حالتنا ، سنحصل على 3 مجموعات من كلمة واحدة وكلمتين و 3 كلمات. دعنا نلقي نظرة على بعض الميزات التي تم إنشاؤها.

| tfidf_v.get_feature_names () [: 20 ] |

كما نرى ، هناك أنواع متعددة من التركيبات المتكونة. هناك أسماء ميزات بها رمز واحد ، ورمزان ، وأيضًا مع 3 رموز.
صنع إطار بيانات
| ## قسّم مجموعة البيانات إلى تدريب واختبار من sklearn.model_selection استيراد train_test_split X_train، X_test، y_train، y_test = train_test_split (X، y، test_size = 0.33 ، random_state = 0 ) count_df = pd.DataFrame (X_train ، الأعمدة = tfidf_v.get_feature_names ()) count_df.head () |
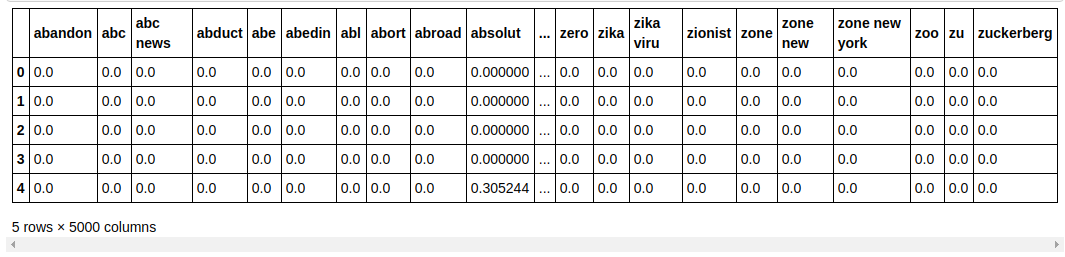
نقوم بتقسيم مجموعة البيانات إلى تدريب واختبار حتى نتمكن من اختبار أداء النموذج على بيانات غير مرئية. نقوم بعد ذلك بإنشاء إطار بيانات جديد يحتوي على متجهات الميزات الجديدة فيه.
النمذجة والضبط
خوارزمية MultinomialNB
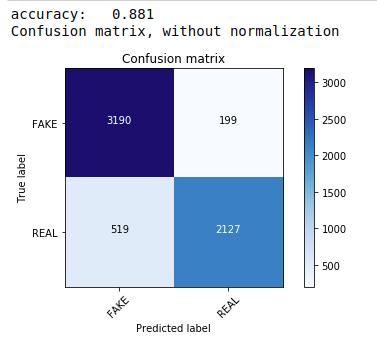
أولاً ، نستخدم نظرية Multinomial Naive Bayes وهي الخوارزمية الأكثر شيوعًا والأسهل المفضلة لتصنيف بيانات النص. نحن نلائم بيانات التدريب ونتوقع بيانات الاختبار. لاحقًا نحسب ونرسم مصفوفة الارتباك ونحصل على دقة تبلغ 88.1٪.
| من sklearn.naive_bayes استيراد MultinomialNB من sklearn استيراد المقاييس استيراد numpy كـ np استيراد أدوات itertools من sklearn.metrics استيراد plot_confusion_matrix المصنف = MultinomialNB () classifier.fit (X_train ، y_train) pred = classifier.predict (X_test) النتيجة = metrics.accuracy_score (y_test، pred) طباعة ( "الدقة:٪ 0.3f" ٪ درجة) سم = metrics.confusion_matrix (y_test، pred) plot_confusion_matrix (سم ، الفئات = [ 'FAKE' ، 'REAL' ]) |
مصنف متعدد الحدود مع ضبط Hyperparameter
لدى MultinomialNB معلمة ألفا يمكن ضبطها بشكل أكبر. ومن ثم نقوم بتشغيل حلقة لتجربة مصنفات MultinomialNB متعددة بقيم ألفا مختلفة والتحقق من درجات الدقة الخاصة بها. ونتحقق مما إذا كانت النتيجة الحالية أكبر من النتيجة السابقة. إذا كان الأمر كذلك ، فسنقوم بتعيين المصنف على أنه المصنف الحالي.
| الدرجة السابقة = 0 لألفا في np.arange ( 0 ، 1 ، 0.1 ): sub_classifier = MultinomialNB (alpha = alpha) sub_classifier.fit (X_train، y_train) y_pred = sub_classifier.predict (X_test) النتيجة = metrics.accuracy_score (y_test، y_pred) إذا كانت النتيجة> الدرجات السابقة: المصنف = المصنف الفرعي print ( "Alpha: {}، Score: {}" .format (alpha، Score)) |
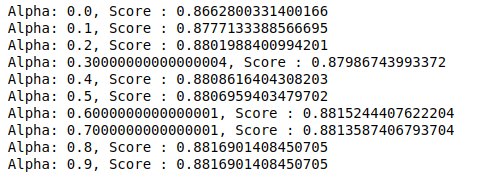
ومن ثم يمكننا أن نرى أن قيمة ألفا البالغة 0.9 أو 0.8 أعطت أعلى درجة دقة.
تفسير النتائج
الآن دعونا نرى ما تعنيه قيم معامل المصنف. سنحفظ أولاً جميع أسماء الميزات في متغير آخر.
| ## G et F أسماء الميزات feature_names = cv.get_feature_names () |
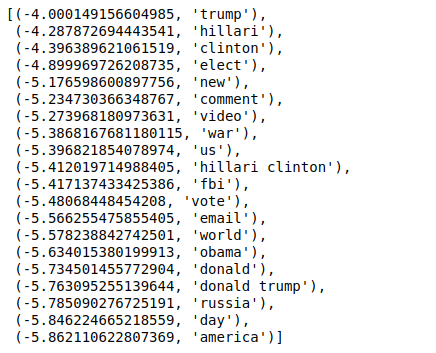
الآن ، عندما نفرز القيم بترتيب عكسي ، نحصل على قيم بحد أدنى للقيمة -4. هذه تدل على الكلمات الأكثر واقعية أو الأقل تزييفًا.
| ### M حقيقية مرتبة (zip (classifier.coef_ [ 0 ]، feature_names)، reverse = True ) [: 20 ] |
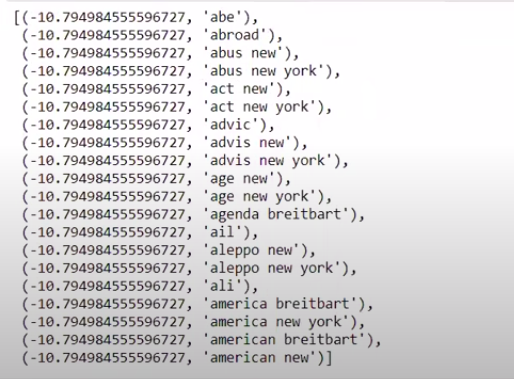
عندما نقوم بفرز القيم بترتيب غير عكسي ، نحصل على قيم بحد أدنى للقيمة -10. هذه تشير إلى الكلمات الأقل واقعية أو الأكثر زيفًا.
| ### M حقيقية مرتبة (zip (classifier.coef_ [ 0 ]، feature_names)) [: 20 ] |
خاتمة
في هذا البرنامج التعليمي ، استخدمنا خوارزميات ML فقط ولكنك تستخدم طرق شبكات عصبية أخرى أيضًا. علاوة على ذلك ، لتوجيه البيانات النصية ، استخدمنا ناقل TF-IDF. هناك المزيد من المتجهات مثل Count Vectorizer و Hashing Vectorizer وما إلى ذلك والتي يمكن أن تكون أفضل في القيام بالمهمة. جرب وجرب الخوارزميات والتقنيات الأخرى لترى ما إذا كان بإمكانك تحقيق نتائج أفضل أم لا.
إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT -ب حالة الخريجين ، 5+ مشاريع التخرج العملية العملية والمساعدة في العمل مع الشركات الكبرى.
لماذا هناك حاجة لاكتشاف الأخبار الكاذبة؟
في حالتها الحالية ، تعد منصات الوسائط الاجتماعية قوية وقيمة للغاية لأنها تتيح للمستخدمين مناقشة وتبادل الأفكار بالإضافة إلى مواضيع النقاش مثل الديمقراطية والتعليم والصحة. ومع ذلك ، فإن بعض الكيانات تستخدم مثل هذه المنصات بشكل سيئ ، لتحقيق مكاسب مالية في بعض الظروف ولإنتاج وجهات نظر متحيزة ، وتغيير العقليات ، ونشر السخرية أو السخرية في حالات أخرى. الأخبار الكاذبة هو مصطلح لهذه الظاهرة. أدى انتشار العناصر المنشورة على الإنترنت التي لا تلتزم بالواقع إلى ظهور عدد كبير من المشكلات في السياسة والرياضة والصحة والعلوم وغيرها من المجالات.
ما هي الشركات التي تستخدم بشكل رئيسي اكتشاف الأخبار المزيفة؟
يتم استخدام الكشف عن الأخبار المزيفة على منصات مثل وسائل التواصل الاجتماعي والمواقع الإخبارية. إن وسائل الإعلام الاجتماعية العملاقة مثل Facebook و Instagram و Twitter عرضة للأخبار المزيفة لأن غالبية مستخدميها يعتمدون عليها كمصادر أخبار يومية للحصول على أحدث المعلومات. تستخدم الشركات الإعلامية أيضًا تقنيات الكشف المزيف لتحديد مصداقية المعلومات التي لديها. البريد الإلكتروني هو وسيلة أخرى يمكن للأفراد من خلالها تلقي الأخبار ، مما يجعل من الصعب التعرف عليهم والتحقق من صحتها. تشتهر الخدع والبريد العشوائي والبريد غير الهام بأنها تُنقل عبر البريد الإلكتروني. نتيجة لذلك ، تستخدم غالبية منصات البريد الإلكتروني الكشف عن الأخبار الكاذبة لتحديد البريد العشوائي والبريد غير الهام.